rasa3.6的DIETClassifier实体提取器不准确,使用RegexEntityExtractor的实体提取器替换。在实战过程解决以下两个问题:
1、RegexEntityExtractor实体提取器的应用
首先在domain.yml中明确对应的实体以及意图:
version: "3.0"
entities:
- line_name
intents:
- ask_train_time
以询问地铁运营时间的意图为例,在nlu.yml中填写对应的数据
version: "3.0"
nlu:
- intent: ask_train_time
examples: |
- 地铁[1号线](line_name)是否还在运营
- 地铁[1号线](line_name)还在运营吗
- 地铁[1号线](line_name)的首末班车时间
- 地铁[1号线](line_name)什么时候出发
- 地铁[1号线](line_name)什么时候截止
如果要使用Lookup Tables,在nlu中继续添加line_name对应的查找表:
- lookup: line_name
examples: |
- 1号线
- 2号线
- 3号线
- 12号线
- 月球线
- fb线
- 生命线
在config.yml的pipeline中配置RegexFeaturizer和RegexEntityExtractor:
recipe: default.v1
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: zh
pipeline:
- name: RegexFeaturizer
#...
#其他的一些组件
#这里我们配置多个抽取器来保证实体抽取的结果
- name: RegexEntityExtractor
use_word_boundaries: False
use_lookup_tables: True
use_regexes: True
- name: DIETClassifier
epochs: 50
#...
对rasa nlu进行测试:

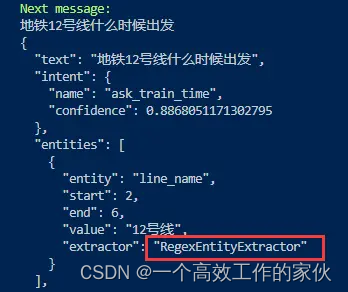
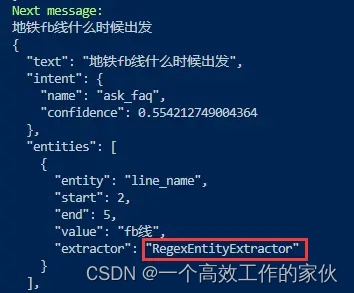
可以看到因为我们在Lookup Table中也重复配置了1号线,因此该实体同时被两个抽取器提取到。明显可以看出,在DIETClassifier抽取的实体中是包含confidence_entity这个属性的;而在RegexEntityExtractor对应的抽取结果中则并不包含该属性,这也说明这是基于正则进行匹配的,因此其对应的置信度默认为1。
对Lookup Table中的其他实体名称进行测试:
这里先不管意图的识别是否正确,至少在Lookup Table中的实体都被识别出来了。
当然,笔者这里也测试了utterance中需要识别两个实体一个意图的例子。
在nlu.yml中将数据进行更新
version: "3.0"
nlu:
- intent: ask_train_time
examples: |
- 地铁[1号线](line_name)[八宝山](station)站是否还在运营
- 地铁[1号线](line_name)[八宝山](station)站还在运营吗
- 地铁[1号线](line_name)[八宝山](station)站的首末班车时间
- 地铁[1号线](line_name)[八宝山](station)站什么时候出发
- 地铁[1号线](line_name)[八宝山](station)站什么时候截止
- lookup: line_name
examples: |
- 2号线
- 3号线
- 12号线
- 生命线
- lookup: station
examples: |
- 建国门
- 古城
- 月球
测试结果:

出现的原例完全由语义正常识别
2、多个提取器针对相同的实体类型,很可能会多次提取实体
实体提取器主要是从用户消息中提取实体,例如人名或位置。如果开发者想使用多个实体提取器,我们建议每个提取器都针对一组独立的实体类型。例如,使用Duckling提取日期和时间, 使用DIETClassifier提取人名。否则,如果多个提取器针对相同的实体类型,很可能会多次提取实体。例如,如果开发者使用两个或多个通用提取器,如MitieEntityExtractor、 DIETClassifier或CRFEntityExtractor,则训练数据中的实体类型将由它们全部找到并提取。如果填充的槽类型都是text类型 ,那么管道中的只有最后一个提取器是起作用的。如果插槽的类型为list,则所有结果都将添加到列表中,包括重复项。比如