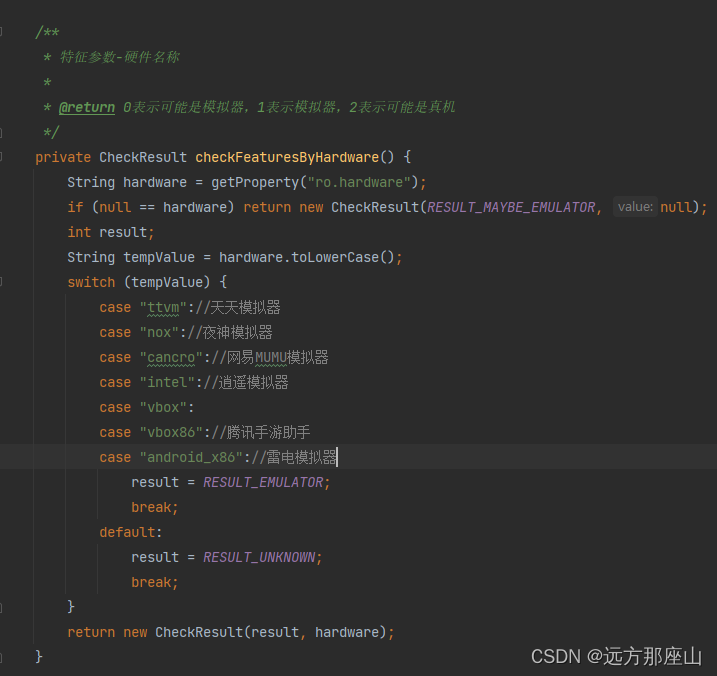
文章目录
- 1. 什么是序列线性规划?
- 2. SLP算法逻辑
- 2.1 非线性规划问题
- 2.2 通过泰勒级数展开线性化
- 2.3 步长边界Step Bounds
- 2.4 序列线性规划的迭代逻辑
- 3. 演算示例
- 4. 涉及代码
- 4.1 绘制可行域
- 4.2 求解序列线性规划
- 4.3 计算步长边界更新公式
- 参考资料
1. 什么是序列线性规划?
Successive Linear Programming (SLP) 序列线性规划,有时也称为 Sequential Linear Programming,它是一种用于近似解决非线性优化问题的优化技术1,最早的相关资料来自1961年,由Shell Oil公司的Griffith和Stewart提出,起初SLP的计算方法被称为数学近似规划法(Mathematical Approximation Programming,MAP),该方法从最优解的某个估值出发,求解模型的一系列通过泰勒级数展开的一阶近似(线性规划)问题,从而实现对非线性规划问题的有效求解2。
2. SLP算法逻辑
2.1 非线性规划问题
非线性规划(Nonlinear Programming,NLP)是数学优化中的一个分支,涉及目标函数和/或约束条件是非线性的优化问题。与线性规划不同,非线性规划问题中,变量和函数之间的关系是非线性的,这使得问题的复杂性和求解难度大大增加。
考虑这么一个非线性问题:
minimize g 0 ( x ) + A 0 y = h ( x , y ) subject to g ( x ) + A 1 y = b 1 ( m 1 rows ) , A 2 x + A 3 y = b 2 ( m 2 rows ) , l x < x < u x , l y < y < u y . \begin{array}{ll} \operatorname{minimize} & g_0(x)+A_0 y=h(x, y) \\ \text {subject to} & \\ & g(x)+A_1 y=b_1\left(m_1 \text { rows }\right), \\ & \left.A_2 x+A_3 y=b_2 \text { (} m_2 \text { rows }\right), \\ & l^x<x<u^x, l^y<y<u^y .\end{array} minimizesubject tog0(x)+A0y=h(x,y)g(x)+A1y=b1(m1 rows ),A2x+A3y=b2 (m2 rows ),lx<x<ux,ly<y<uy.
其中, h ( x , y ) h(x,y) h(x,y) 是目标函数, x = [ x 1 , x 2 , . . . , x n 1 ] x=[x_1,x_2,...,x_{n_1}] x=[x1,x2,...,xn1] 是非线性变量,与目标函数的非线性关系体现在非线性函数 g 0 ( ) g_0() g0() 上,与 m 1 m_1 m1 条非线性约束的非线性关系体现在 g ( x ) = ( g 1 ( x ) , g 2 ( x ) , . . . , g m 1 ( x ) ) g(x)=(g_1(x),g_2(x),...,g_{m_1}(x)) g(x)=(g1(x),g2(x),...,gm1(x)) 上,变量 x x x 的上下界为 l x = [ l 1 x , l 2 x , . . . , l n 1 x ] , u x = [ u 1 x , u 2 x , . . . , u n 1 x ] l^x=[l_1^x,l_2^x,...,l_{n_1}^x],u^x=[u_1^x,u_2^x,...,u_{n_1}^x] lx=[l1x,l2x,...,ln1x],ux=[u1x,u2x,...,un1x]。
另一部分变量 y = [ y 1 , y 2 , . . . , y n 2 ] y=[y_1,y_2,...,y_{n_2}] y=[y1,y2,...,yn2] 是线性变量,与目标函数、约束条件的关系都是线性的,上式中的 m 2 m_2 m2 行约束是线性函数,同理, y y y 也有相对应的上下界,上下界的向量值允许是正无穷或负无穷。
任何非线性规划可以用上述形式表示3,对于非线性规划,允许 m 2 = 0 m_2=0 m2=0,即没有线性约束;而像诸如不等式的松弛变量,以及广义逻辑约束线性化的辅助变量,均是线性叠加的形式,归到 y y y 当中。
非线性规划的特点:
- 多个局部最优解:线性规划问题(凸优化)的局部最优解是全局最优解,然后非线性规划问题通常存在多个局部最优解,因此要找到全局最优解并不容易;
- 计算复杂性:由于非线性函数的存在,规划问题的求解可能涉及复杂的计算和迭代过程,通常需要使用高级的优化算法和数值方法,例如梯度法、序列线性规划、序列二次规划、元启发式等。
2.2 通过泰勒级数展开线性化
使用泰勒级数展开的前提是所有的非线性函数 g 0 ( x ) , g 1 ( x ) , . . . g m 1 ( x ) g_0(x),g_1(x),...g_{m_1}(x) g0(x),g1(x),...gm1(x) 在任何地方都是可微的,可微性条件保证了依靠梯度进行优化的算法能够正常运行并收敛到最优解。
给定一个初始基点 ( x a , y a ) (x^a,y^a) (xa,ya),用点 x a x^a xa 处的一阶泰勒展开式替代非线性规划问题中的非线性函数,得到 L P LP LP 问题。如下,定义所有非线性函数一阶导的雅可比矩阵为: J ( x a ) = ( ∂ g / ∂ x a ) J(x^a)=\left(\partial g / \partial x^a\right) J(xa)=(∂g/∂xa)。
用一阶泰勒展开式 g ( x a ) + J ( x a ) ( x − x a ) g(x^a)+J(x^a)(x-x^a) g(xa)+J(xa)(x−xa) 近似替代 g ( x ) g(x) g(x),得到如下的线性规划问题(SLP问题):
minimize g 0 ( x a ) + ∇ g 0 ( x a ) ( x − x a ) + A 0 y subject to J ( x a ) ( x − x a ) + A 1 y = b 1 − g ( x a ) A 2 x + A 3 y = b 2 l x < x < u x , l y < y < u y \begin{array}{ll} \operatorname{minimize} & g_0(x^a) + \nabla g_0(x^a) (x-x^a)+A_0 y \\ \text {subject to} & \\ & J(x^a) (x-x^a)+A_1 y=b_1-g(x^a) \\ & A_2 x+A_3 y=b_2 \\ &l^x<x<u^x, l^y<y<u^y \end{array} minimizesubject tog0(xa)+∇g0(xa)(x−xa)+A0yJ(xa)(x−xa)+A1y=b1−g(xa)A2x+A3y=b2lx<x<ux,ly<y<uy
其中,目标函数的 g 0 ( x a ) g_0(x^a) g0(xa) 是常量可以省略。显然的,求解近似线性规划问题的解并不一定是非线性规划问题的可行解,但随着迭代次数增加, x x x 和基点差距缩小,这种不可行性也会随之降低。
2.3 步长边界Step Bounds
如前面所述,用一阶泰勒展开式替代原非线性函数的误差随着 x − x a x-x^a x−xa 越大而越大,而只要 ∣ x − x a ∣ |x-x^a| ∣x−xa∣ 足够小,则一阶泰勒展开式的误差也逐步缩小,即认为非线性函数在 ( x , x a ) (x, x^a) (x,xa) 的极小范围内是近乎线性的。因此,为了减小误差,应对从基点出发的搜索范围 ∣ x − x a ∣ |x-x^a| ∣x−xa∣ 进行限制,用 d = x − x a d=x-x^a d=x−xa 表示搜索范围,用 ( − s , s ) (-s,s) (−s,s) 表示搜索范围的边界,也称为步长边界Step Bounds, s s s 是与 x x x 维度相同的正向量。
显然,搜索范围内的解 x a + d x^a+d xa+d 同样落在 [ l x , u x ] [l^x,u^x] [lx,ux] 范围内,因此可得:
l x − x a ≤ d ≤ u x − x a → max ( l x − x a , − s ) ≤ d ≤ min ( u x − x a , s ) l^x-x^a\leq d\leq u^x-x^a\\\\ \rightarrow \max(l^x-x^a,-s)\leq d\leq \min(u^x-x^a, s) lx−xa≤d≤ux−xa→max(lx−xa,−s)≤d≤min(ux−xa,s)
在搜索范围的限制下,求解的SLP形式的线性规划问题用符号表示为 L P ( x a , s ) LP(x^a,s) LP(xa,s),基于 x a x^a xa 求得的新解为 ( d a , y a + 1 ) (d^a,y^{a+1}) (da,ya+1),即得到的后继点为 ( x a + 1 , y a + 1 ) (x^{a+1},y^{a+1}) (xa+1,ya+1),其中 x a + 1 = x a + d a x^{a+1}=x^a+d^a xa+1=xa+da。
然而,对于SLP算法而言,步长 d d d 的选择至关重要,如果设置的步长边界过大,则SLP将在很长一段时间内在当前最优解附近振荡(精度不高);如果设置的步长边界过小,则SLP的收敛速度将会非常缓慢。因此,Griffith和Stewart也在1961年的文献中强调了在迭代时步长边界在最优点附近应降低的必要性,以控制解的震荡并强制收敛3。
通常的做法是自适应地调整步长边界,这里介绍一个简单的更新步长边界的算法1,显然的,对于 L P ( x a , s ) LP(x^a, s) LP(xa,s) 得到的新解,总是比初始基点会更好;同理,由于是近似替代非线性函数,因此也希望得到的新解放在非线性规划当中,是变得更优。因此可以通过如下逻辑更新步长边界:
- 计算新解
(
x
a
+
1
,
y
a
+
1
)
(x^{a+1},y^{a+1})
(xa+1,ya+1) 和旧解
(
x
a
,
y
a
)
(x^a,y^a)
(xa,ya),在SLP和NLP问题中对目标函数的改进量之间关系,计算如下公式:
h N L P ( x a + 1 , y a + 1 ) − h N L P ( x a , y a ) h S L P ( x a + 1 , y a + 1 ) − h S L P ( x a , y a ) \frac{h_{NLP}(x^{a+1},y^{a+1})-h_{NLP}(x^a,y^a)}{h_{SLP}(x^{a+1},y^{a+1})-h_{SLP}(x^a,y^a)} hSLP(xa+1,ya+1)−hSLP(xa,ya)hNLP(xa+1,ya+1)−hNLP(xa,ya) - 如果上述式子接近 1 1 1,例如在 [ 0.75 , 1.25 ] [0.75,1.25] [0.75,1.25] 范围内,则说明线性近似的准确性较高,继续增大步长边界;反之,如果上述式子的值偏离 1 1 1,例如 ( − ∞ , 0.75 ) ∪ ( 1.25 , + ∞ ) (-\infin,0.75)\cup (1.25,+\infin) (−∞,0.75)∪(1.25,+∞),说明近似线性函数与原来的非线性函数差距较大,此时应减少步长边界。
2.4 序列线性规划的迭代逻辑
综上所述,序列线性规划的完整迭代逻辑如下:
- 获取非线性规划问题的一个初始可行解 ( x a , y a ) (x^a,y^a) (xa,ya) 作为基点;
- 给定步长边界 ( − s , s ) (-s,s) (−s,s),求解一阶泰勒展开式近似的线性规划问题 L P ( x a , s ) LP(x^a, s) LP(xa,s);获取最优点 ( x a + 1 , y a + 1 ) (x^{a+1}, y^{a+1}) (xa+1,ya+1);
- 判断近似线性规划的最优解是否满足以下终止条件:
- 当 h S L P ( x a + 1 , y a + 1 ) − h S L P ( x a , y a ) h_{SLP}(x^{a+1},y^{a+1})-h_{SLP}(x^a,y^a) hSLP(xa+1,ya+1)−hSLP(xa,ya) 足够小:说明一阶泰勒展开式的斜率趋于 0 0 0,此时认为到了非线性函数的局部最优点;
- 新解基本满足非线性规划问题的KKT条件:达到了非线性规划问题的局部最优点;
- 新解在非线性规划问题上可行,且 h N L P ( x a + 1 , y a + 1 ) − h N L P ( x a , y a ) h_{NLP}(x^{a+1},y^{a+1})-h_{NLP}(x^a,y^a) hNLP(xa+1,ya+1)−hNLP(xa,ya) 足够小;
- 步长边界足够小:同理,斜率趋向于 0 0 0;
- 如果不满足上面的终止条件,用新的解更新为新的初始点,通过前面提到的步长边界更新方法,将步长边界更新为 s ′ s' s′,回到第2步。
由于SLP算法是基于局部线性化来求解的,因此极易陷入局部最优解,最终会收敛到距离初始点最近的局部最优解。
3. 演算示例
给定如下一个简单的非线性规划问题4:
min f ( x 1 , x 2 ) = ( x 1 + 1 ) × ( x 2 + 1 ) s.t. g ( x 1 , x 2 ) = − 0.25 ( x 1 ) 2 + x 1 − x 2 + 3 ≤ 0 h ( x 1 , x 2 ) = 0.4 × x 1 + 0.6 × x 2 − 5 ≤ 0 x 1 ≥ 0 , x 2 ≥ 1 \begin{array}{cl}\min & f\left(x_1, x_2\right)=\left(x_1+1\right) \times\left(x_2+1\right) \\ \text { s.t. } & g(x_1,x_2)= -0.25\left(x_1\right)^2 +x_1-x_2+3\leq 0 \\ & h(x_1,x_2)=0.4 \times x_1+0.6 \times x_2-5\leq 0 \\ & x_1 \geq 0, x_2 \geq 1\end{array} min s.t. f(x1,x2)=(x1+1)×(x2+1)g(x1,x2)=−0.25(x1)2+x1−x2+3≤0h(x1,x2)=0.4×x1+0.6×x2−5≤0x1≥0,x2≥1
非线性规划问题的可行域如下灰色区域所示,目标函数如下图中等高线所示,显然,最小化目标函数值的最优解应该落在灰色区域靠下的位置,根据目标值曲线可知,最优解是 ( x 1 = 0 , x 2 = 3 ) (x_1=0,x_2=3) (x1=0,x2=3)。接下来,我们用序列线性规划进行迭代求解最优值。
部分数值计算结果与参考资料有出入,以本文的为准,读者也可根据文末的代码自主验证。

(1)计算非线性函数的一阶导
由于需要利用到一阶导对非线性函数进行线性近似,因此需要计算非线性函数 f , g f,g f,g 对于非线性变量的一阶导(雅可比矩阵),在上述例子中, x 1 , x 2 x_1,x_2 x1,x2 都是非线性变量,因此求得的一阶导如下:
∇ f ( x 1 , x 2 ) = [ x 2 + 1 , x 1 + 1 ] ∇ g ( x 1 , x 2 ) = [ − 0.5 x 1 + 1 , − 1 ] \begin{gathered}\nabla f\left(x_1, x_2\right)=\left[x_2+1, x_1+1\right] \\ \nabla g\left(x_1, x_2\right)=\left[-0.5 x_1+1,-1\right]\end{gathered} ∇f(x1,x2)=[x2+1,x1+1]∇g(x1,x2)=[−0.5x1+1,−1]
线性函数 h h h 不需要展开。
(2)设定初始基点和步长边界
设定初始的步长边界 s = 15 s=15 s=15,初始点 ( x 1 = 1 , x 2 = 5 ) (x_1=1,x_2=5) (x1=1,x2=5),将初始点代入上述式子,得到非线性函数在初始点处的梯度如下:
∇ f ( x 1 , x 2 ) = [ 6 , 2 ] ∇ g ( x 1 , x 2 ) = [ 0.5 , − 1 ] \begin{gathered}\nabla f\left(x_1, x_2\right)=\left[6, 2\right] \\ \nabla g\left(x_1, x_2\right)=\left[0.5,-1\right]\end{gathered} ∇f(x1,x2)=[6,2]∇g(x1,x2)=[0.5,−1]
(3)迭代求解序列线性规划
将上面的初始设定,代入非线性规划问题当中转化为SLP问题,根据前面的步长边界关系式可知:
max ( l x − x a , − s ) ≤ d ≤ min ( u x − x a , s ) → max ( l x , − s + x a ) ≤ x ≤ min ( u x , s + x a ) \max(l^x-x^a,-s)\leq d\leq \min(u^x-x^a, s)\\\\\rightarrow \max(l^x,-s+x^a)\leq x\leq \min(u^x, s+x^a) max(lx−xa,−s)≤d≤min(ux−xa,s)→max(lx,−s+xa)≤x≤min(ux,s+xa)
得到的SLP问题如下:
min f ( 1 , 5 ) + ∇ f ⊤ [ x 1 − 1 , x 2 − 5 ] g ( 1 , 5 ) + ∇ g ⊤ [ x 1 − 1 , x 2 − 5 ] ≤ 0 h ( x 1 , x 2 ) = 0.4 × x 1 + 0.6 × x 2 − 5 ≤ 0 0 ≤ x 1 ≤ 15 + 1 1 ≤ x 2 ≤ 15 + 5 ⇓ min 12 + 6 ( x 1 − 1 ) + 2 ( x 2 − 5 ) − 1.25 + 0.5 ( x 1 − 1 ) − ( x 2 − 5 ) ≤ 0 0.4 x 1 + 0.6 x 2 − 5 ≤ 0 0 ≤ x 1 ≤ 16 1 ≤ x 2 ≤ 20 \begin{array}{cl}\min & f(1,5)+\nabla f^{\top}[x_1-1,x_2-5] \\ & g(1,5) +\nabla g^{\top} [x_1-1,x_2-5]\leq 0 \\ & h(x_1,x_2)=0.4 \times x_1+0.6 \times x_2-5\leq 0 \\ & 0\leq x_1\leq 15+1\\ & 1\leq x_2 \leq 15+5 \end{array}\\\\ \Downarrow\\\\ \begin{array}{cl}\min & 12+6(x_1-1)+2(x_2-5) \\ & -1.25 + 0.5(x_1-1)-(x_2-5) \leq 0 \\ & 0.4 x_1+0.6 x_2-5\leq 0 \\ & 0\leq x_1\leq 16\\ & 1\leq x_2 \leq 20 \end{array} minf(1,5)+∇f⊤[x1−1,x2−5]g(1,5)+∇g⊤[x1−1,x2−5]≤0h(x1,x2)=0.4×x1+0.6×x2−5≤00≤x1≤15+11≤x2≤15+5⇓min12+6(x1−1)+2(x2−5)−1.25+0.5(x1−1)−(x2−5)≤00.4x1+0.6x2−5≤00≤x1≤161≤x2≤20
求解上述线性规划问题(这里用SCIP求解,代码见第4节),得到最优结果: f ∗ = 2.5 , x 1 ∗ = 0 , x 2 ∗ = 3.25 f^*=2.5,x_1^*=0,x_2^*=3.25 f∗=2.5,x1∗=0,x2∗=3.25。上面提到的步长边界更新策略,计算得到:
h N L P ( x a + 1 , y a + 1 ) − h N L P ( x a , y a ) h S L P ( x a + 1 , y a + 1 ) − h S L P ( x a , y a ) = 0.82 \frac{h_{NLP}(x^{a+1},y^{a+1})-h_{NLP}(x^a,y^a)}{h_{SLP}(x^{a+1},y^{a+1})-h_{SLP}(x^a,y^a)}=0.82 hSLP(xa+1,ya+1)−hSLP(xa,ya)hNLP(xa+1,ya+1)−hNLP(xa,ya)=0.82
上式中 h N L P ( x a + 1 , y a + 1 ) − h N L P ( x a , y a ) = − 7.75 h_{NLP}(x^{a+1},y^{a+1})-h_{NLP}(x^a,y^a)=-7.75 hNLP(xa+1,ya+1)−hNLP(xa,ya)=−7.75, h S L P ( x a + 1 , y a + 1 ) − h S L P ( x a , y a ) = − 9.5 h_{SLP}(x^{a+1},y^{a+1})-h_{SLP}(x^a,y^a)=-9.5 hSLP(xa+1,ya+1)−hSLP(xa,ya)=−9.5,以及步长边界 s = 15 s=15 s=15 都不接近于 0 0 0,且新解不满足原非线性规划问题的KKT条件,因此对步长边界进行更新,由于 0.82 0.82 0.82 接近 1 1 1,认为线性近似后的优化趋势一致,于是进一步扩大步长边界,这里将步长边界更新为 s = 30 s=30 s=30。
第二次迭代,此时初始点为 ( x 1 = 0 , x 2 = 3.25 ) , s = 30 (x_1=0,x_2=3.25), s=30 (x1=0,x2=3.25),s=30,计算非线性函数在该初始点的梯度:
∇ f ( x 1 , x 2 ) = [ 4.25 , 1 ] ∇ g ( x 1 , x 2 ) = [ 1 , − 1 ] \begin{gathered}\nabla f\left(x_1, x_2\right)=\left[4.25, 1\right] \\ \nabla g\left(x_1, x_2\right)=\left[1,-1\right]\end{gathered} ∇f(x1,x2)=[4.25,1]∇g(x1,x2)=[1,−1]
得到新的序列线性规划问题:
min 4.25 + 4.25 ( x 1 − 0 ) + ( x 2 − 3.25 ) − 0.25 + ( x 1 − 0 ) − ( x 2 − 3.25 ) ≤ 0 0.4 x 1 + 0.6 x 2 − 5 ≤ 0 0 ≤ x 1 ≤ 30 1 ≤ x 2 ≤ 33.25 \begin{array}{cl}\min & 4.25+4.25(x_1-0)+(x_2-3.25) \\ & -0.25 +(x_1-0)-(x_2-3.25) \leq 0 \\ & 0.4 x_1+0.6 x_2-5\leq 0 \\ & 0\leq x_1\leq 30\\ & 1\leq x_2 \leq 33.25 \end{array} min4.25+4.25(x1−0)+(x2−3.25)−0.25+(x1−0)−(x2−3.25)≤00.4x1+0.6x2−5≤00≤x1≤301≤x2≤33.25
求解得最优结果: f ∗ = 4 , x 1 ∗ = 0 , x 2 ∗ = 3 f^*=4,x_1^*=0,x_2^*=3 f∗=4,x1∗=0,x2∗=3。判断是否更新步长边界,计算:
h N L P ( x a + 1 , y a + 1 ) − h N L P ( x a , y a ) h S L P ( x a + 1 , y a + 1 ) − h S L P ( x a , y a ) = 0.5 \frac{h_{NLP}(x^{a+1},y^{a+1})-h_{NLP}(x^a,y^a)}{h_{SLP}(x^{a+1},y^{a+1})-h_{SLP}(x^a,y^a)}=0.5 hSLP(xa+1,ya+1)−hSLP(xa,ya)hNLP(xa+1,ya+1)−hNLP(xa,ya)=0.5
因此拒绝该新解,并将步长边界降低。由于拒绝了该新解,因此新一轮迭代的起始点为 ( 0 , 3.25 ) (0,3.25) (0,3.25),与第二次迭代一致,因此本轮迭代的 SLP 问题与上述模型一致,只需缩小 x 1 , x 2 x_1,x_2 x1,x2 的定义域。
显然的,由于 0 ≤ 0 + s , 3 ≤ 3.25 + s 0\leq 0+s,3\leq 3.25+s 0≤0+s,3≤3.25+s,不论如何缩小步长边界 s ≥ 0 s\geq 0 s≥0 的值,上述式子恒成立,即近似线性规划的最优解总是 ( 0 , 3 ) (0,3) (0,3)。此时满足算法终止条件,得到最终的非线性规划的近似结果为 ( x 1 = 0 , x 2 = 3 ) (x_1=0,x_2=3) (x1=0,x2=3)。
4. 涉及代码
4.1 绘制可行域
由于对可行域进行填充的逻辑是,将函数值范围落在 [ − 1 e 10 , 0 ] [-1e10, 0] [−1e10,0] 的部分进行填充,即填充函数值小于等于 0 0 0 的部分,因此所有约束应转化为 ≤ 0 \leq 0 ≤0 的函数形式。
import numpy as np
import matplotlib.pyplot as plt
# 定义目标函数
def objective_function(x1, x2):
return (x1 + 1) * (x2 + 1)
# 定义约束函数
def constraint1(x1, x2):
return -(0.25*x1**2 - x1 + x2 -3)
def constraint2(x1, x2):
return 0.4*x1+0.6*x2-5
def constraint3(x1, x2):
return 1 - x2
# 创建网格
x1 = np.linspace(0, 10, 400)
x2 = np.linspace(0, 10, 400)
X1, X2 = np.meshgrid(x1, x2)
Z = objective_function(X1, X2)
# 绘制目标函数的等高线
plt.figure(figsize=(8, 6))
contour = plt.contour(X1, X2, Z, levels=40, cmap='viridis')
plt.colorbar(contour)
# # 绘制约束条件的边界
constraint1_boundary = constraint1(X1, X2)
constraint2_boundary = constraint2(X1, X2)
constraint3_boundary = constraint3(X1, X2)
plt.contour(X1, X2, constraint1_boundary, levels=[0], colors='r', linestyles='dashed')
plt.contour(X1, X2, constraint2_boundary, levels=[0], colors='b', linestyles='dashed')
plt.contour(X1, X2, constraint3_boundary, levels=[0], colors='g', linestyles='dashed')
# # 填充可行区域
# 填充可行区域
feasible_region = np.maximum(np.maximum(constraint1_boundary, constraint2_boundary), constraint3_boundary)
plt.contourf(X1, X2, feasible_region, levels=[-1e10, 0], colors=['grey'], alpha=0.3)
# 设置图例和标签
plt.xlabel('$x_1$')
plt.ylabel('$x_2$')
plt.title('Objective Function and Constraints')
plt.show()
4.2 求解序列线性规划
以第一阶段的迭代序列线性规划为例的求解代码。
from pyscipopt import Model
model = Model("Example")
x1 = model.addVar(lb=0, ub=16, vtype='C', name='x1')
x2 = model.addVar(lb=1, ub=20, vtype='C', name='x2')
model.addCons(-1.25+0.5*(x1-1)-(x2-5) <= 0)
model.addCons(0.4*x1+0.6*x2 -5 <= 0)
model.setObjective(12+6*(x1-1)+2*(x2-5), sense="minimize")
model.optimize()
status = model.getStatus()
if status == 'optimal':
print("Optimal value:", model.getObjVal())
for v in model.getVars():
print(v, model.getVal(v))
else:
print("* No variable is printed if model status is not optimal")
4.3 计算步长边界更新公式
在指定位置修改公式,以及修改新解,运行后即可得到求解结果。
def func_nlp(x):
return (x[0] + 1)*(x[1] + 1)
def func_slp(x):
return 12+6*(x[0]-1)+2*(x[1]-5)
old_sol = (1, 5)
new_sol = (0, 3.25)
print((func_nlp(new_sol)-func_nlp(old_sol))/(func_slp(new_sol)-func_slp(old_sol)))
参考资料
Cornell University Computational Optimization Open Textbook:SLP ↩︎ ↩︎
WIKIPEDIA: Successive linear programming ↩︎
Palacios-Gomez, F.; Lasdon, L.; Enquist, M. (October 1982). “Nonlinear Optimization by Successive Linear Programming”. Management Science. 28 (10): 1106–1120. doi:10.1287/mnsc.28.10.1106. ↩︎ ↩︎
非线性规划求解方法:序列线性规划(Sequential linear programming) ↩︎