目录
1、flask-sqlalchemy
1.1、flask_sqlalchemy 与sqlalchemy 的关系
1.1.1、 基本定义与用途
1.2、flask_sqlalchemy 的使用
1.2.1、安装相关的库
1.2.2、项目准备
1.2.3、创建ORM模型
1.2.3.1、使用db.create_all()创建表的示例
1.2.3.2、创建多表关联ORM模型
1.2.4、直接执行SQl语句
1.2.5、新增数据
1.2.6、修改数据
1.2.6、删除数据
1.2.6、查询数据
注:slqalchemy详细使用说明见文章:Python 之SQLAlchemy使用详细说明-CSDN博客
1、flask-sqlalchemy
1.1、flask_sqlalchemy 与sqlalchemy 的关系
1.1.1、 基本定义与用途
- sqlalchemy:
- 是一款Python编程语言下的开源软件,提供了SQL工具包及对象关系映射(ORM)工具。
- 允许开发人员通过Python类与对象来操作数据库,从而避免了直接编写SQL语句的复杂性。
- 支持多种数据库系统,如SQLite、MySQL、PostgreSQL等。
- flask_sqlalchemy:
- 是sqlalchemy的一个扩展或封装,专门用于Flask web框架。
- 简化了在Flask应用中与数据库交互的过程,例如配置、初始化、使用ORM等。
- 使得在Flask中集成数据库变得更为方便和直观。
1.1.2、关系与区别
- 关系:
- flask_sqlalchemy基于sqlalchemy进行了扩展和优化,使其更适应于Flask框架的使用场景。
- 两者都提供了ORM功能,允许通过Python对象来操作数据库。
- 区别:
- 用途:sqlalchemy是一个通用的数据库ORM工具,而flask_sqlalchemy则专门为Flask框架设计。
- 配置:在Flask中使用flask_sqlalchemy时,可以通过Flask的配置文件来配置数据库连接信息,而sqlalchemy则需要单独进行配置。
- 初始化:flask_sqlalchemy在初始化时会与Flask应用对象关联,而sqlalchemy则直接创建引擎和会话。
- 简化操作:flask_sqlalchemy在Flask应用中提供了更简洁的数据库操作方式,如定义模型、查询等。
1.1.3、使用建议
- 如果开发一个基于Flask的web应用,并且需要与数据库进行交互,那么推荐使用flask_sqlalchemy,因为它提供了与Flask框架更好的集成和更简洁的使用方式。
- 如果需要在一个非Flask项目中使用ORM,或者需要更灵活和定制化的数据库操作,那么可以选择直接使用sqlalchemy。
1.2、flask_sqlalchemy 的使用
sqlalchemy官方文档:Session API — SQLAlchemy 2.0 Documentation
falsk-sqlalchemy官方文档:Flask-SQLAlchemy — Flask-SQLAlchemy Documentation (3.1.x)
说明:因为flask-sqlalchemy是基于sqlalchemy扩展与flask集成,所以flask-sqlalchemy的使用很多都是基于sqlalchemy进行封装的,如果了解sqlalchemy那么使用flask-sqlalchemy就会很简单。
1.2.1、安装相关的库
说明:本文中所有的代码示例,相关软件和库的版本如下:
- Python:3.9
- Flask :2.3.3
- Flask-Migrate :4.0.5
- Flask-SQLAlchemy :3.1.1
1、安装flask
pip install flask
2、安装数据库迁移工具Flask-Migrate,安装这个库的同时也会安装Flask-SQLAlchemy
pip install Flask-Migrate
1.2.2、项目准备
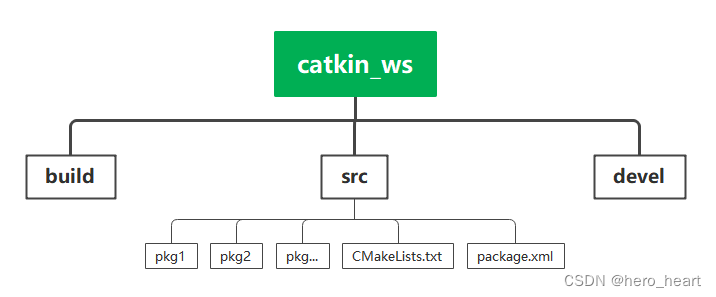
说明:下面会通过一些示例来说明flask-sqlalchemy的常见使用。首先需要新建三个py文件,文件目录结构如下:
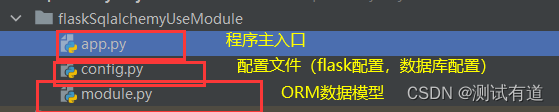
1、app.py
"""
主程序入口
"""
from module import db
from flask_migrate import Migrate
from flask import Flask
import config
app = Flask(__name__)
# 绑定配置文件
app.config.from_object(config)
# 初始化db
db.init_app(app)
# 使用数据库迁移来管理数据库模型的更改
# 在Flask中,数据库迁移是对数据库模式或结构进行更改时,通过执行一系列有序的迁移脚本来保持数据的一致性和完整性
# ORM模型映射成数据库表的三步,需要在控制台执行下面命令:
# 1、flask db init : 初始化ORM模型,只需要执行一次即可(即首次执行)
# 2、flask db migrate: 识别ORM模型的改变,生成迁移脚本
# 3、flask db upgrade: 运行迁移脚本,同步到数据库中
migrate = Migrate(app, db)
if __name__ == '__main__':
app.run(debug=True)2、config.py文件
- 注意:数据库的主机地址,用户密码需要换成自己的
"""
配置文件
"""
# 设置秘钥用于session加密,秘钥越长安全性越高
# 在Flask应用中配置一个密钥,用于对会话数据进行加密和签名。密钥的选择很重要,应该是足够随机和安全的。
SECRET_KEY = "asfjlahfdasnflbbFA"
# 数据库配置信息
# MySQL所在的主机名
HOSTNAME = "172.22.70.174"
# MySQL监听的端口号,默认3306
PORT = 3306
# 连接MySQL的用户名
USERNAME = "root"
# 连接MySQL的密码
PASSWORD = ""
# MySQL上创建的数据库名称
DATABASE = "test1"
DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)
SQLALCHEMY_DATABASE_URI = DB_URI
# 数据库连接池的大小,默认为5
SQLALCHEMY_POOL_SIZE = 10
# 等待数据库连接的超时时间(秒),默认为10
SQLALCHEMY_POOL_TIMEOUT = 30
# 用于配置 SQLAlchemy 引擎选项的 Flask 配置参数
# SQLAlchemy 引擎选项允许你控制数据库连接的各种行为,例如连接池的大小、超时设置、SSL 配置等
SQLALCHEMY_ENGINE_OPTIONS = {
'pool_size': 10, # 连接池大小
'max_overflow': 5, # 当连接池中的连接都被使用时,额外创建的连接数
'pool_recycle': 3600, # 多久之后自动回收连接(秒)
# 你还可以添加其他 SQLAlchemy 引擎选项,例如 SSL 配置等
# 'connect_args': {'sslmode': 'require', ...}
}3、module.py
"""
ORM数据模型
"""
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()1.2.3、创建ORM模型
db.create_all()创建表和使用Migrate管理迁移数据库的区别:
- db.create_all()
- 通常用于创建新表(如果表存在不会做任何事情,只是创建对应的ORM映射关系,注意:这不会更改已经存在的表结构 )
- Migrate
- 能够跟踪数据库模式的变化,并能够轻松地升级、降级或回滚这些变化。
使用 Flask-Migrate 的命令来创建和管理迁移。这通常涉及以下步骤:
1.初始化迁移仓库:
- 在项目的根目录下运行 flask db init 命令来创建一个迁移仓库。注意:这个只需要运行一次,也就是首次运行的时候。
2.生成迁移脚本
- 当你修改了 Flask-SQLAlchemy 模型(例如添加新表、字段或约束)时,你需要生成一个新的迁移脚本。这可以通过运行 flask db migrate 命令来完成。这个命令会检查当前的模型与上一次迁移之后的数据库状态之间的差异,并生成一个 Python 脚本,该脚本描述了如何将这些差异应用到数据库上。
3.应用迁移
- 一旦你生成了迁移脚本,你就可以通过运行 flask db upgrade 命令来将这些更改应用到数据库上。同样地,你也可以使用 flask db downgrade 命令来撤销最近的迁移。
1.2.3.1、使用db.create_all()创建表的示例
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'your_database_uri' # 例如:'sqlite:tmp/test.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
# 定义其他方法或关系(如果需要)
# 初始化数据库(如果尚未创建)
# 注意:这不会更改已经存在的表结构
with app.app_context():
db.create_all() # 这通常用于创建新表,但在这里不会做任何事情(因为表已经存在)
# 接下来,你可以像通常一样使用这个模型来查询数据库
# 例如:users = User.query.all()1.2.3.2、创建多表关联ORM模型
说明:先建立t_emp员工表和t_dept部门表两张表,并插入对应数据
1、在module.py文件中新增ORM模型如下:
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Departments(db.Model):
__tablename__ = "t_dept"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False, comment="部门名称")
class Employes(db.Model):
__tablename__ = "t_emp"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False, comment="姓名")
age = db.Column(db.Integer, comment="年龄")
job = db.Column(db.String(20), comment="职位")
salary = db.Column(db.Integer, comment="薪资")
entrydate = db.Column(db.DateTime, comment="入职时间")
managerid = db.Column(db.Integer, comment="直属领导ID")
dept_id = db.Column(db.Integer, db.ForeignKey("t_dept.id"))
# 与表t_dept建立反向引用,在Departments模型中将会生成一个名为 "employes" 的属性,可以通过该属性获取该部门的员工的信息
departemnt = db.relationship(Departments, backref="employes")注意:
- 如果数据库中没有这两张表,需要先生成迁移脚本,然后执行在数据库中创建表。
- 如果表中的字段或者约束等发生了变化,也是执行下面的第二、三命令(此时命令:flask db init 不需要再执行 )
flask db init
flask db migrate
flask db upgrade
执行演示如下:
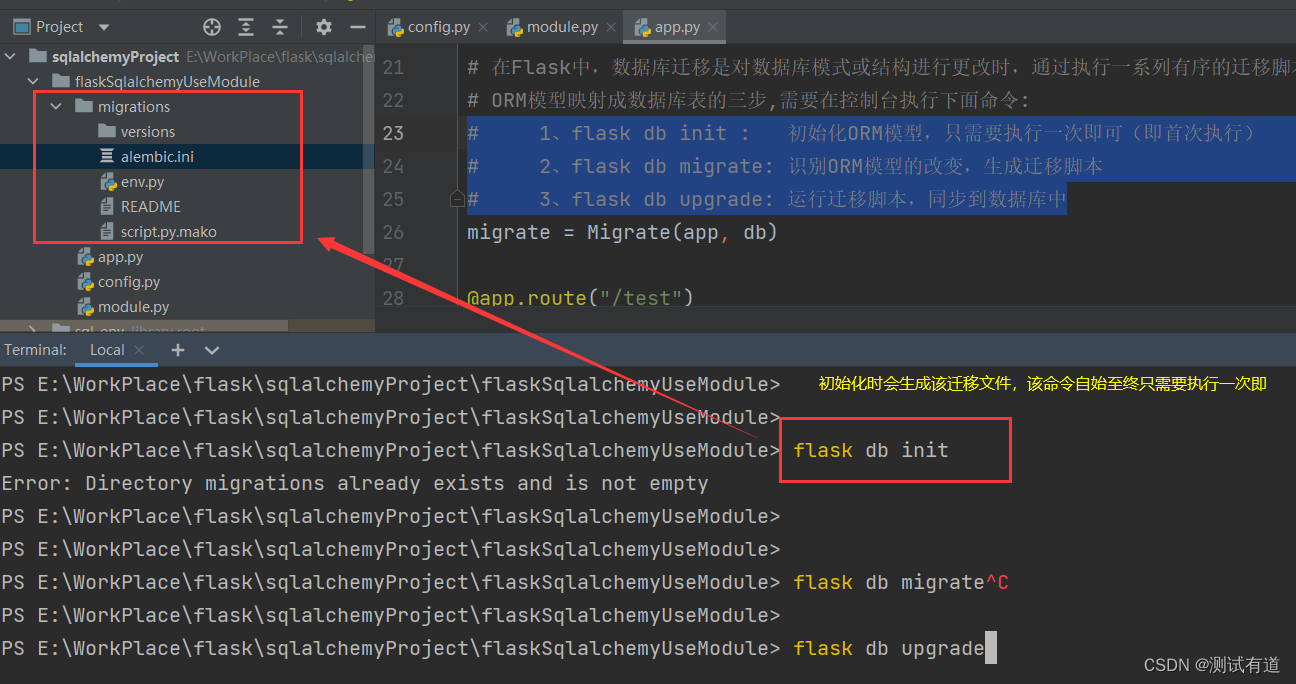
注意:如果创建的表的编码不是utf8mb4,需要修改为utf8mb4,不然插入中文的数据会出现编码错误,执行以下SQL语句:
ALTER TABLE t_dept CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE t_emp CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
2、插入测试数据
INSERT INTO t_dept (name) VALUES ('研发部'), ('市场部'),('财务部'), ('销售部'), ('总经办'), ('人事部');
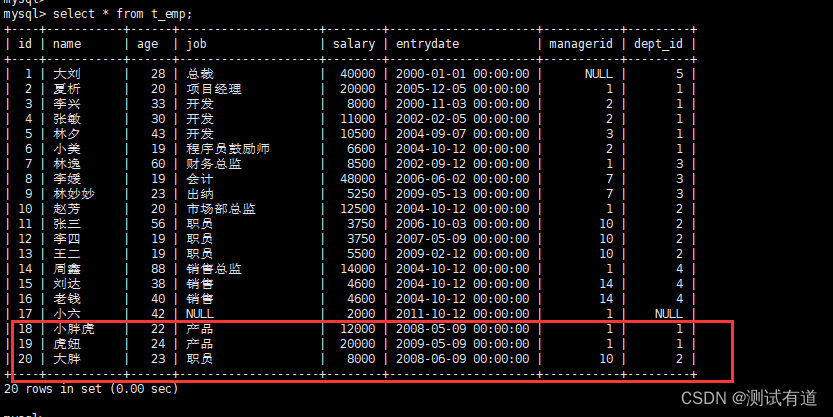
INSERT INTO t_emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES
(1, '大刘', 28, '总裁',40000, '2000-01-01', null,5),
(2, '夏析', 20, '项目经理',20000, '2005-12-05', 1,1),
(3, '李兴', 33, '开发', 8000,'2000-11-03', 2,1),
(4, '张敏', 30, '开发',11000, '2002-02-05', 2,1),
(5, '林夕', 43, '开发',10500, '2004-09-07', 3,1),
(6, '小美', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),
(7, '林逸', 60, '财务总监',8500, '2002-09-12', 1,3),
(8, '李媛', 19, '会计',48000, '2006-06-02', 7,3),
(9, '林妙妙', 23, '出纳',5250, '2009-05-13', 7,3),
(10, '赵芳', 20, '市场部总监',12500, '2004-10-12', 1,2),
(11, '张三', 56, '职员',3750, '2006-10-03', 10,2),
(12, '李四', 19, '职员',3750, '2007-05-09', 10,2),
(13, '王二', 19, '职员',5500, '2009-02-12', 10,2),
(14, '周鑫', 88, '销售总监',14000, '2004-10-12', 1,4),
(15, '刘达', 38, '销售',4600, '2004-10-12', 14,4),
(16, '老钱', 40, '销售',4600, '2004-10-12', 14,4),
(17, '小六', 42, null,2000, '2011-10-12', 1,null);
1.2.4、直接执行SQl语句
说明:在 Flask-SQLAlchemy 中,虽然推荐使用 ORM(对象关系映射)来进行数据库操作,但有时候你可能需要直接执行 SQL 语句。Flask-SQLAlchemy 提供了 db.session.execute() 方法来执行原生的 SQL 语句。
注意:使用 db.session.execute() 方法执行 SQL 语句时,请确保你的 SQL 语句是安全的,特别是当 SQL 语句中包含用户输入时。防止 SQL 注入的最佳做法是使用参数化查询或 ORM 提供的方法。
示例:
# 直接执行 SQL 语句来更新数据
# 注意:使用 execute 方法时,你需要自己确保 SQL 语句的安全性
update_sql = "UPDATE employees SET name='John Doe Jr.' WHERE id=1"
db.session.execute(update_sql)
db.session.commit()
# 直接执行 SQL 语句来查询数据
select_sql = "SELECT * FROM employees WHERE department_id=1"
results = db.session.execute(select_sql).fetchall()
for row in results:
print(row) # 输出查询结果
# 如果你想将查询结果映射到模型类,可以使用 Model.query.from_statement()
# 但这通常不如直接使用 ORM 方法来得直观和简单
# # 注意:在使用 text() 函数时,你需要从 sqlalchemy.sql 导入 text
from sqlalchemy.orm import aliased
EmployesAlias = aliased(Employes)
results = Employes.query.from_statement(text(select_sql)).all()
for employee in results:
print(employee.name) # 假设查询结果包含了员工的名字 1.2.5、新增数据
需求:演示在t_emp表中插入单条数据和插入多条数据
说明:在app.py文件中进行演示,可以使用函数直接执行的方式,也可以使用请求路由的方式,因为实际使用中都是请求路由,所以这里使用请求路由的方式演示数据的增删改查。
注意:只要涉及到表的数据变化的都需要提交会话
@app.route("/add")
def add():
emp1 = Employes(name="小胖虎", age=22, job="产品", salary=12000, entrydate="2008-05-09", managerid=1, dept_id=1)
emp2 = Employes(name="虎妞", age=24, job="产品", salary=20000, entrydate="2009-05-09", managerid=1, dept_id=1)
emp3 = Employes(name="大胖", age=23, job="职员", salary=8000, entrydate="2008-06-09", managerid=10, dept_id=2)
try:
# 插入一条数据到数据库中
db.session.add(emp1)
# 插入多条数据到数据库中
db.session.add_all([emp2, emp3])
# 提交事务已保存更改到数据库
db.session.commit()
# 如果在添加过程中发生错误,可以执行回归事务
# db.session.rollback()
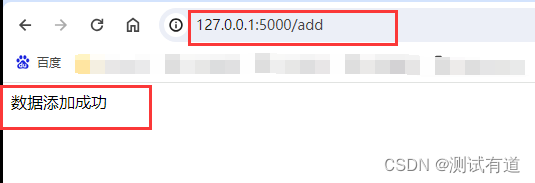
return "数据添加成功"
except Exception as e:
db.session.rollback()
return f"数据添加失败,失败原因:{e}"- 浏览器访问或者使用工具访问接口(如:curl,postman等)
- 数据库查看添加数据是否成功
1.2.6、修改数据
修改数据流程:先查询出数据, 然后修改(想要这些更改被 session 跟踪以便后续可以回滚或提交时使用)。
- 缺点
- 查询和更新分两条语句, 效率低
- 如果并发更新, 可能出现更新丢失问题
所以推荐基于过滤条件的更新,也就是使用 update() 方法,这个方法直接对数据库执行操作,不会触发模型的 events 或 session 的变化;具有如下优势:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
- 会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
@app.route("/update")
def update():
try:
# 1、使用先查询后更新的方式
# 更新t_emp表中id=11的员工姓名为:弓长张
emp = Employes.query.filter_by(id=11).first()
emp.name = "弓长张"
# 提交会话
db.session.commit()
# 2、使用update的方式
# 更新t_emp表中name=小六的员工姓名为:老六
Employes.query.filter(Employes.name == "小六").update({"name": "老六"})
# 提交会话
db.session.commit()
return "数据更新成功"
except Exception as e:
db.session.rollback()
return f"数据更新失败,失败原因:{e}"1.2.6、删除数据
删除数据流程:先查询数据, 再删除
推荐基于过滤条件的删除,也就是使用delete()方法
@app.route("/delete")
def delete():
try:
# 1、使用先查询后删除的方式
# 删除t_emp表中员工姓名为:弓长张 的员工
emp = Employes.query.filter_by(name="弓长张").first()
# 删除数据
db.session.delete(emp)
# 提交会话
db.session.commit()
# 2、使用delete的方式
# 删除t_emp表中员工姓名为:老钱 的员工
Employes.query.filter(Employes.name == "老钱").delete()
db.session.commit()
return "数据删除成功"
except Exception as e:
db.session.rollback()
return f"数据删除失败,失败原因:{e}"1.2.6、查询数据
说明:因为flask-sqlalchemy是基于sqlalchemy扩展的,所以flask-sqlalchemy的使用仅仅是在sqlalchemy之前进行封装了一下,本质还是基于sqlalchemy的,这里的查询可以使用flask-sqlalchemy封装的语法,也可以只有sqlalchemy的语法查询。
这里仅仅展示flsk-sqlalchemy的一些基本查询,具体更加全面的可以参考另一篇关于sqlalchemy使用的文章:Python 之SQLAlchemy使用详细说明-CSDN博客
@app.route("/query")
def query():
try:
# 全表查询t_emp flask-sqlalchemy语法
emps = Employes.query.all()
# sqlalchemy语法
emps_sqlalchemy = db.session.query(Employes).all()
# 模糊查询匹配
# 查询姓刘的员工
res = Employes.query.filter(Employes.name.like("刘%")).all()
# 条件查询
# 查询李四和王二的工资信息
res2 = Employes.query.options(load_only(Employes.name, Employes.salary)).filter(Employes.name == "李四", Employes.name == "王二").all()
# 查询年龄等于20或30的员工信息
res2_1 = Employes.query.filter(or_(Employes.age == 20, Employes.age == 30)).all()
# 或者使用in_()
res2_2 = Employes.query.filter(Employes.age.in_([20, 30]))
# 聚合函数
# 查询每个年龄对应的人数
# 对应的SQL:select age, count(id) as "人数" from t_emp group by age
res3 = db.session.query(Employes.age, func.count(Employes.id).label("nums")).group_by(Employes.age).all()
# 分组查询
# 根据职位分组 , 统计每个职位平均工资
# select job, avg(salary) as "平均工资" from t_emp group by job
res4 = db.session.query(Employes.job, func.avg(Employes.salary).label("avg_salary")).group_by(Employes.job).all()
# 排序查询
# 根据员工年龄从小到大排序,年龄相同的根据工资从高到低排序
# select * from t_emp order by age asc, salary decs
res5 = Employes.query.order_by(Employes.age, Employes.salary.desc()).all()
# 分页查询
# 查询员工信息,每页5条数据,查询第2页的数据
# res6.pages 总页数 res6.page 当前页码 res6.items 当前页的数据 res6.total 总条数
res6 = Employes.query.paginate(page=2, per_page=5)
# 或者使用offset和limit实现
res6_1 = Employes.query.order_by(Employes.age).offset(5).limit(5).all()
return "查询数据成功"
except Exception as e:
return f"查询数据失败,失败的原因:{e}"