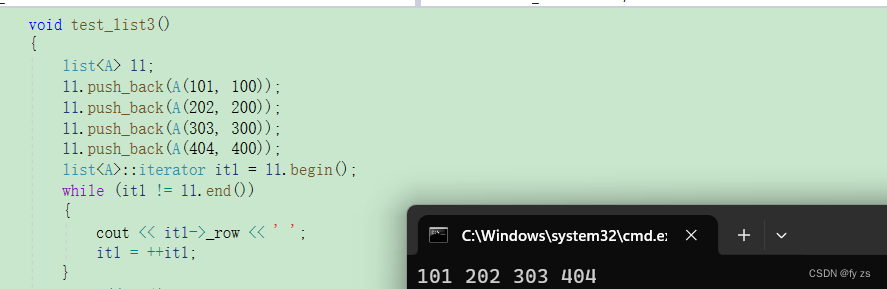
1. 引言
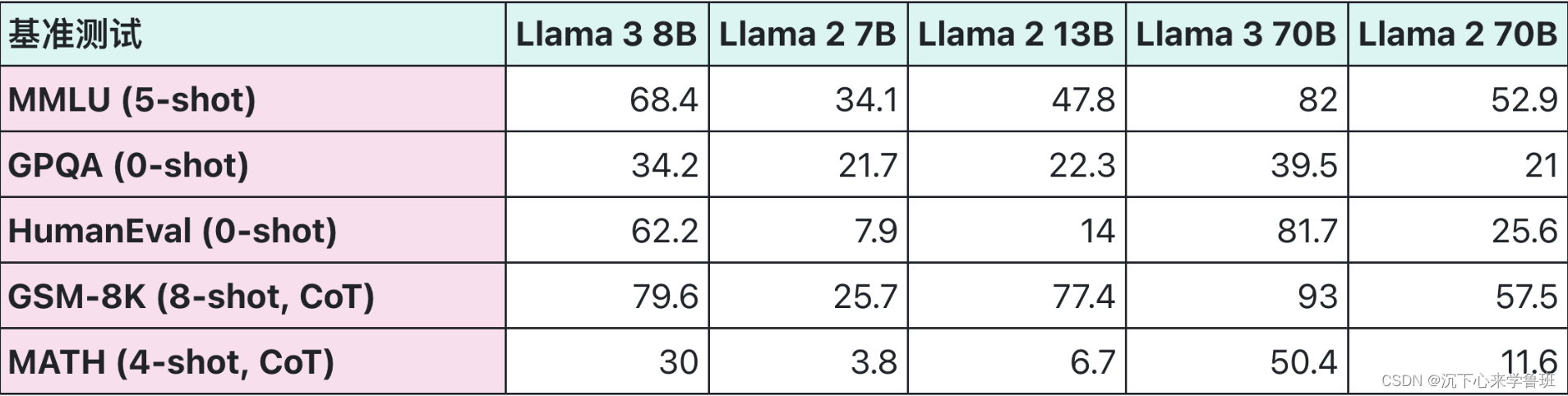
现在国内外的主流模型,在新模型发布时都会给出很多评测数据,用以说明当前模型在不同数据集上的测评表现(如下面llama3发布的评测数据)。
这些评测数据是如何给出来的呢?这篇文章会用一个最小化的流程来还原下模型的评测过程,大致分为以下三步:
- 选择评测数据和指标
- 生成预测答案
- 计算评测分数
2. 评测数据和指标
2.1 评测数据
此次评测,我们选用multifieldqa_zh数据集,这是一个包含多个领域问题、答案和相应上下文信息的数据集。数据示例如下:
{
"input": "《孔子世家谱》的编修工作历时多久?",
"context": "孔子世家谱\n《孔子世家谱》:随着新版《孔子世家谱》补遗卷在2008年12月31日停止收集孔子后裔资料,历时10年的《孔子世家谱》第五次大修后裔资料收集工作全面完成。编修补遗卷是《孔子世家谱》第五次大修的最后一步,因为不少后裔族人得到修谱消息较晚或身份考证过程较长,未能及时录入总谱,为避免这部分孔子后裔资料失传,孔子世家谱续修工作协会决定编修一部补遗卷。从2008年10月决定编修补遗卷到目前,最终有1.1万多人填报了后裔资料登记表。\n编修 民国十七年,孔族中人倡修合族大谱,几经筹备,于民国十九年在孔庙开馆,正式进行。全谱成于民国二十六年十一月,由孔德成任总裁,参加工作人员60余人,历时7年而成。开始时在孔庙举行仪式,陈奉告文牲醴,恭行祭告,并由族长宣读誓词。谱成,再次举行了告祭仪式。 根据这部家谱,凡属孔裔不论散居何地,只要能查考的,一律载明属于何户何支,编排得有条不紊,清晰明确。所以凡今存60岁以上的孔裔,都能在谱中查到自己的名字,并可依序上溯到每一位祖先,直至孔子。 内容 序言 孔子后人取名,正式订出行辈是在明朝:明初朱元璋赐孔氏八个辈字:公、彦、承、弘、闻、贞、尚、胤,供起名用。后因洪武元年(1368年)孔子的第55代孙孔希学及洪武十七年(1384年)孔子的第56代孙孔讷先后袭封衍圣公。这样就把“希”和“言”旁加上去为十个字,即:希、言、公、彦、承,弘、闻、贞、尚、胤(后清代为避帝讳,将弘改为宏,胤改为衍)。明天启(1621年—1627年)年间,这十个字已不够用,由第64代衍圣公孔胤植(孔衍植)奏准。后续二十个字即:“兴毓传继广,昭宪庆繁祥,令德维垂佑,钦绍念显扬 ”,民国八年(1919年)由七十五代衍圣公孔令贻又立二十个字咨请当时的北洋政府核准公布。亦即第八十六代至一百零五代。即“建道敦安定,懋修肈彝常,裕文焕景瑞,永锡世绪昌”。到现在为止已知最小辈是“钦”字辈。因此,不少孔孟后人从名字上就能看出来辈分大小。这并非是孔孟传人一直必须使用的,而是在清乾隆九年(1744年),由礼部调查整理,报皇帝钦定其作为孔孟后裔行辈的顺序的。在此之前,孔子家谱非常繁芜,而这个政府下达的规定使得起名比先前更加规范,又由于是经皇帝提倡,使得中国其他大家族谱系的也开始效仿这种规范的方法。 全谱共分四集,108卷,总计154册,其主要内容如下: 首卷 另列有序、又序、旧序、职名、卷次、目录、事宜、凡例,60户及各支派捐输总数,颁谱部数,姓源,宗派总论,圣祖至四十二代图,中兴祖至今二十派图,二十派至分60户图,嫡裔考,嫡宗图又南宗图,伪孔辨,内院至孔图与外院伪孔图等。 初集 以始祖孔子为卷一,中兴祖孔仁玉为卷二,卷三至卷六十二为自大宗户次第分为60户,每户一卷,共62卷。 二集 为中兴祖后支派,包括南宗在内共三十四支派,分布全国各省县,以始迁地为支派名,共34卷。 三集 为中兴祖前支派,共十派、10卷。 四集 为上代失叙各支,分布范围更广,多达77处,共2卷。 除总谱外,还有各户支谱,不再评叙。 入谱标准 虽然凡属孔裔均可入谱,但也有不准入谱的限制,主要是必须按照规定行辈因字取名,如有乱用不遵者,必须改正,否则不准入谱。 此外,还有以下若干不准入谱的条件,如:养异姓为子者、赘婿冒姓者、子随母嫁者、流入僧道者、下贱者、不孝不悌干犯名义者等。 世系 50世祖燧人氏(配华胥氏) 49世祖伏羲(配女娲) 48世祖少典 47世祖黄帝(姬轩辕) 46世祖少昊(又名玄嚣) 45世祖蟜极 44世祖帝喾(姬夋/姬夒/姬夔) 43世祖契(一作卨,商部族首任首领) 42世祖昭明(商部族首领) 41世祖相土(商部族首领) 40世祖昌若(商部族首领) 39世祖曹圉(商部族首领) 38世祖冥(商部族首领) 37世祖王亥(又名振,王恒之兄,商部族首领) 36世祖上甲微(简称微,商部族首领) 35世祖报乙(商部族首领) 34世祖报丙(商部族首领) 33世祖报丁(商部族首领) 32世祖主壬(一作示壬,商部族首领) 31世祖主癸(一作示癸,商部族首领) 30世祖商王成汤(子天乙,又名子履,商朝开国君主,原为商部族首领) 29世祖商太子太丁(子丁,又名子以跌) 28世祖商王太甲(子至) 27世祖商王太庚(子辩) 26世祖商王太戊(子伷) 25世祖商王仲丁(子庄) 24世祖商王祖乙(子滕) 23世祖商王祖辛(子旦) 22世祖商王祖丁(子新) 21世祖商王小乙(子敛) 20世祖商王武丁(子昭) 19世祖商王祖甲(子载) 18世祖商王康丁(子嚣) 17世祖商王武乙(子瞿) 16世祖商王文丁(子托) 15世祖商王帝乙(子羡) 14世祖微仲(又称宋微仲,本名子衍,商王帝乙之子,周朝时期宋国开国君主微子启之弟,宋国第二任君主) 13世祖宋公稽(子稽) 12世祖宋丁公(子申) 11世祖宋前湣公(子共) 10世祖弗父何(子何) 9世祖宋父周(子周) 8世祖世子胜(子胜) 7世祖正考父(子正) 6世祖孔父嘉(子嘉) 5世祖木金父(子木) 4世祖(高祖)祁父(子祁) 3世祖(曾祖)防叔(子防,孔姓族人称他为“孔防叔”,畏华氏之逼而奔鲁国,故孔氏为鲁人也) 2世祖(祖父)伯夏(子夏) 1世祖(父亲)叔梁纥(子纥,孔姓族人称之为“孔纥”) 孔子(前551年—前479年):汉族,名丘,字仲尼,春秋末期鲁国陬邑昌平乡(今山东省曲阜市南辛镇)人,中国古代伟大的思想家、教育家,儒家学派创始人,尊称“至圣”、“文圣”;编撰了中国第一部编年体史书《春秋》;卒年73岁,葬于曲阜城北泗水之上(即今日孔林所在地);孔子的言行、思想主要载于语录体散文集《论语》及《史记·孔子世家》;他首改“子姓”为“孔姓”,是真正的孔姓始祖 1世孙(儿子)孔鲤 2世孙(孙子)孔伋 3世孙(曾孙)孔白 4世孙(玄孙)孔求 5世孙孔箕 6世孙孔穿 7世孙孔谦(又名孔慎、孔顺) 8世孙孔腾(汉高祖刘邦封孔腾为奉祀君,孔子后代始有封号)、孔鲋、孔树 9世孙孔忠(孔腾子) 10世孙孔武(孔忠长子)、孔安国(孔忠次子) 11世孙孔延年(孔武子) 12世孙孔霸(孔延年子,被汉元帝封为褒成侯,孔子后裔再获封号) 13世孙孔福(孔霸长子,被汉成帝封为殷绍嘉侯)、孔捷(孔霸子)、孔喜(孔霸子)、孔光(孔霸子) 14世孙孔房(孔福子,褒成侯)、孔永(孔捷子)、孔放(孔光子) 15世孙孔均(原名孔莽,孔房子,褒成侯) 16世孙孔志,褒成侯 17世孙孔损,褒亭侯 18世孙孔曜,奉圣亭侯 19世孙孔完(孔曜长子,褒成侯,无子)、孔赞(孔曜次子) 20世孙孔羡(孔赞子),宗圣侯 21世孙孔震,奉圣亭侯 22世孙孔嶷,奉圣亭侯 23世孙孔抚,奉圣亭侯 24世孙孔懿,奉圣亭侯 25世孙孔鲜,奉圣亭侯 26世孙孔乘,崇圣大夫 27世孙孔灵珍,崇圣侯 28世孙孔文泰,崇圣侯 29世孙孔渠,崇圣侯 30世孙孔长孙,恭圣侯 31世孙孔嗣悊(孔长孙次子、孔英悊之弟,绍圣侯) 32世孙孔德伦,褒圣侯 33世孙孔崇基,褒圣侯 34世孙孔璲之,初封褒圣侯,后改封文宣公(为历史上的首任文宣公)兼兖州长史 35世孙孔萱,文宣公 36世孙孔齐卿,文宣公 37世孙孔惟晊,文宣公 38世孙孔策,文宣公 39世孙孔振,文宣公 40世孙孔昭俭,文宣公 41世孙孔光嗣,泗水主簿 42世孙孔仁玉(中兴祖),文宣公兼曲阜县令 43世孙孔宜,文宣公兼曲阜主簿、赞善大夫 44世孙孔延世(孔宜长子,孔延泽之兄,文宣公兼曲阜县令)、孔延泽(孔宜次子) 45世孙孔圣祐(孔延世子,文宣公兼知曲阜县事,无子) 【注】以下文字中姓名加黑者为受封衍圣公等世袭职位者 45世孙衍圣公孔宗愿(孔延泽子、孔圣祐从弟,宋仁宗宝元二年(1039年),孔圣祐三十五岁卒,无子,孔宗愿袭爵文宣公,授国子监主簿,知仙源县事(宋代曲阜县曾改为仙源县,今属山东省)。仁宗至和二年(1055年)直集贤院,曾上书申明历代对孔子及其嫡裔封号的混乱状况,建议革唐代之失误,法汉代之旧制,改至圣文宣王四十五代孙孔宗愿为衍圣公。获准,成为历史上第一位衍圣公。孔子嫡长孙衍圣公之封号,从此相沿至民国二十四年(1935年),持续880年(公元1055年—1935年)) 46世孙奉圣公孔若蒙(孔宗愿长子,宋神宗熙宁元年(公元1068年)袭封衍圣公,兼曲阜县主簿。宋哲宗元祐元年(公元1086年)将爵号改为“奉圣公”,专主祀事)、孔若虚(孔宗愿次子,宋哲宗元符元年(公元1098年),废掉孔若蒙的爵位,由其弟孔若虚(字公实)袭封奉圣公)、孔若愚(孔宗愿第三子) 47世孙衍圣公孔端友(孔若蒙长子,1104年(崇宁三年),被授为朝奉郎、直秘阁、袭封奉圣公,勾管祀事。宋徽宗大观年间(公元1107年—1110年)复改封孔端友为衍圣公。1128年(建炎二年)十一月,金兵大举南下,因宋朝的济南知州长刘豫叛宋,形势急转直下,孔端友在从父孔传的支持下,除留胞弟孔端操留守阙里林庙外,遂恭负传家宝“孔子及亓官夫人楷木像”、“唐吴道子绘孔子佩剑图”和“至圣文宣王庙祀朱印”等,率近支族人端木、瓒等南渡,成为南宗的开创者)、孔端操(孔若蒙次子)、孔端立(孔若愚子) 48世孙衍圣公孔璠(孔端操次子,1128年(宋朝建炎二年)十一月,金兵大举南下,宋朝的济南知州长刘豫叛宋,金国天会八年(1130年)七月二十七日金太宗下诏,立扶持宋朝降臣、原济南知府刘豫为皇帝,建立“伪齐”政权,管辖黄河故道以南的今山东、河南、陕西等地区。九月九日正式成立刘豫伪齐政权。十一月,废用天会年号,改用阜昌年号,并以天会八年(即1130年)十一月十三日后为阜昌元年。伪齐阜昌三年(1132年),补迪功郎,袭封衍圣公,主管祀事,成为北宗衍圣公的继承人。金国天会十五年(1137年),金熙宗废伪齐。金国天眷三年(1140年),金熙宗诏求孔子后,加孔璠承奉郎,袭封衍圣公,主奉祀事)、孔玠(孔端操长子,南宗。1132年(绍兴二年)夏随宋室南渡浙江衢州的衍圣公孔端友逝世,孔端友无子,同年,以孔端友胞弟孔端操长子孔玠袭封为衍圣公)、孔琥(孔端立子) 49世孙衍圣公孔拯(孔璠长子)、孔摠(又名孔詌,孔璠次子)、孔搢(孔玠子,南宗)、孔拂(孔琥子) 50世孙衍圣公孔元措(孔摠长子)、孔元用(孔拂次子)、孔文远(孔搢子,南宗)、孔元紘(一作孔元綋,孔摠次子)、孔元孝(孔拂长子) 51世孙衍圣公孔之全(孔元用子)、孔万春(孔文远子,南宗)、孔之厚(孔元孝子)、孔之固(孔元紘子) 52世孙衍圣公孔浈(孔之固子,元宪宗元年(1251年)袭封衍圣公,后(1252年)被人告称乃驱口贱民李姓所生,因而被夺爵,此后衍圣公之爵中断达43年之久,直到元贞元年(1295年)孔治被元成宗封衍圣公为止)、孔治(孔之全子。孔浈被废爵后,曲阜没有衍圣公,孔治代管祭祀事三十余年。元贞元年(1295年),元成宗诏令孔治为中议大夫,袭封衍圣公)、孔洙(孔万春子,南宗。1241年(宋淳祐元年),授承奉郎、袭封衍圣公。1276年(宋德祐二年,元至元十三年),宋恭帝降元。1282年(至元十九年)秋,元世祖诏命衢州第六代衍圣公(孔子53世嫡长孙)孔洙赴京,令他载爵去曲阜奉祀。孔洙以先祖庐墓在衢州,且衢州已建家庙,不忍举家北上为由,愿意让爵给曲阜族弟孔治。元世祖同意了孔洙的请求,称赞他“宁违荣而不违道,真圣人后也”,便改封他为国子监祭酒,提举浙东道学校事。从此,南宗不再有衍圣公的封爵,此封爵仅北宗所有,孔洙为南宗末代衍圣公)、孔浣(孔之厚子) 53世孙衍圣公孔思诚(孔治子)、孔思晦(孔浣子)、孔思许(孔津子,孔之言孙,孔仁玉的第11世孙,南宗) 54世孙衍圣公孔克坚(孔思晦子)、孔克忠(孔思俊子,孔洙孙,南宗) 55世孙衍圣公孔希学(孔克坚子)、孔希路(孔克忠子,南宗) 56世孙衍圣公孔讷(孔希学子)、孔议(孔希路子,南宗) 57世孙衍圣公孔公鉴(孔讷子)、孔公诚(孔议子,南宗) 58世孙衍圣公孔彦缙(孔公鉴子)、孔彦绳(孔公诚子,南宗。1505年(弘治十八年),衢州知府沈杰向明孝宗朱祐樘上疏,称:“衢州圣庙,自孔洙让爵之后,衣冠礼仪,猥同氓庶。今访得洙六世孙孔彦绳(孔子第58世嫡长孙),请授于官,俾主祭事。”沈杰还奏请孝宗下诏减轻孔家祭田税赋,孝宗准奏。次年,即1506年(正德元年)接位的武宗朱厚照秉承先皇旨意,封孔彦绳为世袭翰林院五经博士,钦定子孙世袭。这样,衢州孔子后裔在失去爵位224年之后,又得到了封号。从此,“世袭翰林院五经博士”的爵位,由孔彦绳的子孙世袭下去) 59世孙衍圣公孔承庆(孔彦缙子)、孔承美(孔彦绳子,南宗,世袭翰林院五经博士) 60世孙衍圣公孔宏绪(原名孔弘绪,孔承庆长子)、孔宏泰(原名孔弘泰,孔承庆次子)、孔宏章(原名孔弘章,孔承美子,南宗,世袭翰林院五经博士) 61世孙衍圣公孔闻韶(孔宏绪子)、孔闻音(孔宏章子,南宗,世袭翰林院五经博士) 62世孙衍圣公孔贞干(孔闻韶长子)、孔贞宁(孔闻韶次子、孔尚坦之父)、孔贞运(孔闻音子,南宗,世袭翰林院五经博士) 63世孙衍圣公孔尚贤(孔贞干子,生有二子:孔胤椿、孔胤桂,皆无子而早夭)、孔尚乾(孔贞运子,南宗,世袭翰林院五经博士) 64世孙衍圣公孔衍植(原名孔胤植,孔尚坦子)、孔衍桢(原名孔胤桢,孔尚乾子,南宗,世袭翰林院五经博士) 65世孙衍圣公孔兴燮(孔衍植子)、孔兴燫(孔衍桢子,南宗,世袭翰林院五经博士) 66世孙衍圣公孔毓圻(孔兴燮子)、孔毓垣(孔兴燫子,南宗,世袭翰林院五经博士) 67世孙衍圣公孔传铎(孔毓圻子)、孔传锦(孔毓垣子,南宗,世袭翰林院五经博士) 68世孙衍圣公孔继濩(孔传铎子)、孔继涛(孔传锦子,南宗,世袭翰林院五经博士) 69世孙衍圣公孔广棨(孔继濩子)、孔广杓(孔继涛子,南宗,世袭翰林院五经博士) 70世孙衍圣公孔昭焕(孔广棨子)、孔昭烜(孔广杓子,南宗,世袭翰林院五经博士) 71世孙衍圣公孔宪培(孔昭焕长子,孔宪增之兄,无子)、孔宪坤(孔昭烜子,南宗,世袭翰林院五经博士) 72世孙衍圣公孔庆镕(孔宪增子,过继给孔宪培,1794年袭爵)、孔庆仪(孔宪型子,孔传锦的第5世孙,南宗。同治三年(1864年)承袭世袭翰林院五经博士,民国二年(1913年),中华民国北洋政府颁布《崇圣典例》,改南宗五经博士孔庆仪为大成至圣先师南宗奉祀官,世袭) 73世孙衍圣公孔繁灏(孔庆镕子)、孔繁豪(孔庆仪子,孔繁英之兄,无子,南宗。1923年冬,孔庆仪去世,其子孔繁豪袭任大成至圣先师南宗奉祀官。中华民国国民政府北伐后,孔繁豪仍任大成至圣先师南宗奉祀官,享简任官的职位及待遇,约比照司长级,视特任官官阶为低,与孟子“亚圣”、颜子“复圣”、曾子“宗圣”、子思“述圣”奉祀官同等级) 74世孙衍圣公孔祥珂(孔繁灏子)、孔祥楷(孔繁英子,过继给孔繁豪,南宗。1944年10月,孔繁豪去世,无子,民国三十六年(1947年)乃以其二弟孔繁英长子孔祥楷受封大成至圣先师南宗奉祀官。民国三十八年(1949年)5月6日,国民政府失去对衢州的统治,孔祥楷未随国民政府迁台,南宗奉祀官世职遂废。孔祥楷目前健在,现为中国大陆浙江省政协委员、衢州孔氏南宗家庙管理委员会主任) 75世孙衍圣公孔令贻(孔祥珂子,清光绪三年(1877年)承袭衍圣公,民国二年(1913年),中华民国北洋政府颁布《崇圣典例》,保留衍圣公爵位,仍由北宗的前清衍圣公孔令贻袭爵,1919年11月8日病逝于北京太仆寺街衍圣公府) 76世孙衍圣公孔德成(孔令贻子,母王氏夫人,1920年2月23日出生,出生百日后,奉中华民国北洋政府徐世昌大总统令,承袭衍圣公爵位;中华民国国民政府北伐后,孔德成有感于世袭衍圣公爵位不宜存于民国,遂于1935年主动请求政府撤销爵号,中华民国国民政府以为道统不可废,乃改衍圣公作大成至圣先师奉祀官,享特任官的职位及待遇,相当于部长,故而孔德成为历史上的末代衍圣公,首任大成至圣先师奉祀官;1936年,娶前清名宦孙家鼐的孙女孙琪芳为妻;1949年国民政府退守台湾,孔德成随迁往台湾,复建台北孔庙,历任大成至圣先师奉祀官、考试院院长、总统府资政,兼任台湾大学中文系教授,开设商周青铜彝器、三礼、金文的综合研究等课程;2008年10月28日上午10点50分在台湾佛教慈济综合医院台北分院因心肺功能衰竭,安详辞世,享年八十九岁,安葬在台湾的新北市三峡区龙泉公墓) 77世孙孔维益(孔德成子,早卒,未袭封) 78世孙大成至圣先师奉祀官孔垂长(孔维益子,2009年9月25日正式袭封大成至圣先师奉祀官,享特任官待遇) 79世孙孔佑仁(孔垂长子,2006年元旦生于台湾) 79世之后的辈分字:钦,绍,念,显,扬,建,道,敦,安,定,懋,修,肈,彝,常,裕,文,焕,景,瑞,永,锡,世,绪,昌 版本 1937版 前言 孔氏之有谱自宋元丰始也。其后六十年一大修著为例,比清乾隆甲子重修,距今百数十年矣。支派之繁衍,人事之递(shi)嬗(shan),年湮(yin)世远,散漫无稽,斯可憾已。 岁戊辰廼承先母陶太夫人命集族耆彦公议重修,体例率旧而所录加扩焉。盖旧谱以博采难周,仅志鲁籍六十户,时为之也。今则交通便而声气易达,爰举流寓外省者并录之,因而兼以创矣。惟创也,而征集考徼以至编纂其繁迹有倍蓰(xǐ)于前者。故七历寒暑而始告成,呜呼难已。事既蒇(chǎn)将以付梓,余忝属主鬯(chǎng,祭祀用的一种酒器。又同‘畅’),乃薰沐告庙,更为族人申以言曰:谱所以昭宗法也。孔氏之先远出殷商,至我祖圣祖孔子而道集大成,单传七世厥后渐繁,五季逆末构变,孔祚几尽。鲁之宗亲仅四十二代祖温如公以藐孤存焉,是为孔氏中兴祖。后五传而至端友公,以从宋南渡家于衢,是谓南宗,元至元间洙公北逊。由元迄今几六百年,承袭罔替,是谓北宗,有六十户。南宗则衢州一支之外,凡宋时南渡、与晋唐代南徙者,沿有十余支。然派分南北流出一源。故合散为聚汇一谱,详本支序昭穆,粲乎秩然,莫之或紊。俾(bì)览斯谱者,咸晓然于积之厚者,流自光则尊祖敬宗之心庶乎油然而生矣。虽然犹未尽也,有世统焉,有道统焉。世统吾所私也,道统吾虽不得而私然,亦不得而诿也。 自我圣祖作师垂教,三世祖阐而述之道之行,如日月经天矣。厥后代有闻人,或以学显或以行著,悉附传于谱,后之人履其庭读其书其可不懔懔弗荷弗构之,戒而思善其继述乎?矧(shěn)道之隆污,天下兴亡系焉。自世运陵夷邪说纷起,宗法失而伦常斁(dù),社会风俗江河日下,君子忧之则缵绪翼教导民正,谓求其所以为谱者,归氏学圣人之道者也。言深且旨而况圣人之后哉!吾族人其宜有以知所勉矣。 中华民国二十六年岁在丁丑春二月,七十六代孙特任大成至圣奉祀官孔德成谨序。 序 披阅谱牒历三甲子迁延而未续纂缺典也,全国族人支繁,派别散居而无联,属憾事也。惟然则合修大谱之议亟亟矣。民国戊辰秋余与族人宪滢、繁朴倡修合族大谱。请于宗子,宗子韪之。于是敦请族彦,推定临时职员相于从事筹备焉。其于各地族人披露以报章,号召以广告,不数月而声气通矣。筹备二载端倪粗具,乃告庙开馆,时庚午年十月十日也,阅七年谱事蒇。从此缺典补遗憾释矣! 嗟乎,我孔氏自圣祖至今繁衍生息于神州大陆已二千四百八十八年矣。其间历蒙帝王名臣大儒优遇,争称为神明世胄者,皆由我圣祖集群圣之大成而为儒道宗师也。即其间经暴秦焚坑之摧残,五季厮养之戕害,终能濒危得安将绝复续者,抑以大圣之泽百世不迁者也。考我家乘宋以前祗具册写,自四十六代宗翰祖始创为刊印。至明弘治二年首次重修,并定为六十年一大修,三十年一小修;大修以甲子为期,小修以甲午为期。清顺治十年未及甲子又重修,迨后康熙、乾隆两甲子均重修勿替,可谓极重视谱牒矣。惟四次重修皆于六十户编纂加详,而流寓各支弗与焉。推其故,盖因当时交通未便,调查维难,又鉴于逆末之变,兢兢于杜奸冒防伪人,宁从其缺毋任其滥也。此次合修虽曰绍述究同创举,而风声所树全国景从者则以交通便利,既异畴昔民族团结复应时势之需要而咸具同情,故用力省成功易,殆运会使然。与从此合远为近,万派归纳于一本,大宗领小宗昭穆不紊。吾族人各本敬宗睦族之化,除畛域联为一体,谓非极美极盛之事乎?国之人有读是谱者,察其体制辨其伦次,则宗法可资而考镜矣,而洙泗流泽之绵延,人文之孳息亦得其大凡,足补国史所未及或亦关心采择者之所乐闻也。然则此谱之成又岂独孔氏一族之幸哉!是役历十年之久余始终佐其事,既竣而谨为之序。 民国丁丑年仲春之吉,六十七代孙、家庭族长孔传堉谨撰。 2009版 目录 K0 总谱 K1 卷首 K2 大宗户 K3 临沂户 孟村户 K4 道沟户 K5 滕阳户 K6 旧县户 K7 钟吉户 K8 菜庄户 戴庄户 栗园户 K9 时庄户 泗庄户 K10 店北户 西郭户 K11 仙源户 泉南户 齐王户 盛果户 K12 苗孔户 文献户 沂北户 K13 石村户 鲁贤户 沂阳户 孔村户 王堂户 小庄户 宫端户 黉门户 K14 华店户 K15 古城户 岗山户 K16 鲁城户 K17 孔屯户 西城户 旧城户 K18 吕官户 K19 林前户 防西户 林门户 K20 管庄户 大薛户 K21 广文户 K22 小薛户 陶乐户 北公户 K23 纸坊户 董庄户 防上户 高庄户 南宫户 K24 星村户 古柳户 吴孙户 东村户 磨庄户 K25 张曲户 息陬户 K26 西林户 林西户 K27 南宗派 K28 江西新建支 四川阆中支 浙江温岭支 浙江钱塘支 K29 清平孔庄支 广东南海大沥支 河南太康支 K30 江苏吴县与范县支 河南新乡花园村支 河南新乡八里营支 广东番禹支 定陶支 K31 广西灌阳支 成武孔楼支 江苏丰县支 成武孔庄支 平阴孔家集支 寿光支 K32 牟平派 K33 浙江慈溪派 福建闽县支 安徽徽州支 安徽舒城支 K34 浙江衢州派 K35 寿光潍县支 肥城孔庄支 寇县支 河北枣强与恩县支 K36 郓城支 四川大邑支 四川邛崃支 河北晋县支 河南考城支 K37 江苏武进支 长清支 河南浚县支 德平南孔家庄支 德平西孔家庄支 K38 江苏镇江支 河南武安支 湖北新洲支 桓台孔家庄支 河南光山支 K39 山西阳城济源支 浙江宁海支 安徽桐城支 K40 浙江婺州支 夏津支 浙江诸暨支 河北南宫冀县支 K41 浙江平阳派 K42 河南郏县派 K43 河南宁陵派 K44 河北献县派 K45 江苏丹阳派 K46 岭南派 K47 广东南雄派 河南洛阳派 K48 江西临江派 K49 湖南平江浏阳派 K50 河南鲁山派 K51 河南河洛派 K52待考 山东支 河北北京天津支 山西支 辽宁支 内蒙古支 吉林支 黑龙江支 江苏上海支 浙江支 福建支 江西支 河南支 湖北支 湖南支 广东支 广西支 四川重庆支 贵州支 云南支 K53待考 安徽支 陕西支 甘肃支 青海支 宁夏支 新疆支 台港澳支 K54 韩国高丽支 特点 一是女性族人、少数民族、外籍孔子后裔首次录入世家谱,不仅有因通婚或生活所迫变更为回族、苗族、水族、哈尼族、景颇族、土族、东乡族、藏族等少数民族的后裔, 还有旅居韩国、美国、新加坡等国家地区的外籍后裔近四万人; 二是信息量增加,以往只收入姓名,这次增加了性别、配偶、学历等个人信息; 三是实现数字化,建立数据库,并被赋予分类统计功能,对研究儒家学说及人口学、社会学、教育学等方面都将具有重要的史料价值。 另外,在续修家谱过程中,寻得了失去联系的分布在台湾屏东、龙潭、桃园等地二百多年的九百多名孔子后裔,以及失散在山西昔阳和河南洛宁超过千年的两支族人,此次全部被录入新谱。 编修进展 据台湾“中央社”报道,世界孔子后裔联谊会总会长孔德墉说,在台湾的孔子后裔约有4000人,而在第5次“孔子世家谱”续修过程中,粗估约有900名台湾人录入世家谱。报道说,新版“孔子世家谱”补遗卷在2008年12月31日停止收集孔子后裔资料,历时10年的孔子世家谱第5次大修后裔资料收集工作全面完成。 “中央社”引述当时媒体报道说,来自台湾的900多名孔子后裔在第5次“孔子世家谱”续修过程中,首次被录入世家谱,这些后裔主要来自台湾的屏东、龙潭、桃园等地,分属20多个支派。 [1] 成就 世界最长家谱,涵盖孔子家族整个传承史的《孔子世家谱》以其延时之长、族系之明,纂辑之广、核查之实,体例之备、保存之全,2005年被吉尼斯世界纪录列为“世界最长家谱”。 孔氏全族之正式有谱,始于宋朝元丰甲子年间(公元1089年),迄今已历九百余年。在此以前也有族谱,不过只收长支,不及旁系。自康熙甲子年(公元1684年)后规定:每逢甲子大修一次,每逢甲午小修一次。所谓小修,即将三十年内孔裔的生死变迁分别填造成册作为大修的底册,亦即为大修做准备。清代康熙、乾隆的甲子年(即公元1684年、1744年)都曾大修。自此以后,孔氏族谱命名为《孔子世家谱》。它最后一次大修是民国十七年(公元1928年),在曲阜孔府组成了以七十六代衍圣公孔德成任总裁的修谱筹备处,着手全国孔氏家族的合修家谱工作,历时七年,完成了现存的从孔子至七十六代近两千五百年的108卷家谱档案。家族谱是古代谱牒的一种,它记述了家族始祖源起,受姓情况,对于研究家族,特别是人物、礼俗等均有重要意义。如《孔子世家谱》中的孔子年谱、孔子姓源考等对于研究孔子的学术思想和生平事迹就具有重要的学术价值。",
"answers": ["7年。"],
"length": 10397,
"dataset": "multifieldqa_zh",
"language": "zh",
"all_classes": null,
"_id": "7c1f7faaa594745757654e934c028f3f4f4910ebef8b2be3"
}
该数据集中有几个重要的字段:
- context: 给定的上下文知识
- input: 针对上下文知识的提问
- answers:针对上述提问的标准回答
针对该数据集的评测方式是:
- 让模型基于context给出的上下文信息,来回答input所提出的问题,并生成预测答案。
- 将预测答案与标准答案answers进行算法比较,即可评测模型回答的准确度。
2.2 评测指标
此次使用F1值作为评测指标,它是一个结合了精确率(Precision)和召回率(Recall)的通用指标。
需要解决的问题:假设模型预测出了一个答案 pred,如何衡量这个预测答案相对于标准答案answers的准确度呢?
{
"pred": "故事发生在2095年的日本东京。\n",
"answers": ["故事发生在二十一世纪末的日本。"]
}
一个思路是:由于语言模型是一个词一个词输出的,我们可以把预测结果和标准答案都看成是一个个词组成的序列,如下所示:
pred: 故事/发生/在/2095/年/的/日本/东京/。
answers: 故事/发生/在/二十一/世纪末/的/日本/。
通过对比,可以得到pred和answers中相同词语的个数,进而可以得到:
- 精确率:对预测结果pred而言,模型预测答案正确的比例。
- 召回率: 对样本标签而言,有多少词语被模型预测正确。
而F1 score就是精确率和召回率的调和平均值,其取值范围为 0 到 1,其中,1 表示精确率和召回率均达到完美,计算方式如下所示:
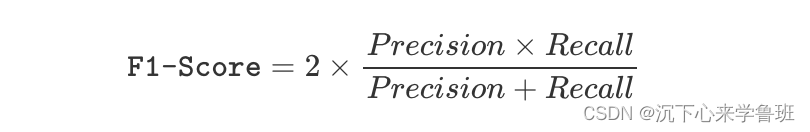
3. 预测
用语言模型来生成预测,主要包括:
- 选定一个待评测模型,这里选用qwen:7b;
- 设计一个提示词,用待测模型来生成预测答案;
- 保存预测答案和真实答案,用于后续评测。
由于本地资源有限,采用ollama运行待测模型qwen:7b,参考之前:迷你版RAG-2.2节。
2.1 设计prompt
不同数据集需要设计的prompt是不同的,下面是针对multifield_zh数据集的提示词:
阅读以下文字并用中文简短回答:\n\n{context}\n\n现在请基于上面的文章回答下面的问题,只告诉我答案,不要输出任何其他字词。\n\n问题:{input}\n回答:
2.2 加载数据集
这个multifield_zh数据集是一行一条数据,为jsonl格式,所以加载时也一行一行读取和json decode,代码如下:
def load_jsonl_dataset(file_path):
data = []
with open(file_path, 'r') as file:
for line in file:
data.append(json.loads(line))
return data
2.3 生成预测
访问本地模型来生成答案,步骤为:
- 对于dataset中每条数据,先使用format函数来填充提示词中的占位符。
- 如果限制了max_length输入长度,则提示词两端各截取一半,中间的舍掉。
- 调用ollama的chat函数与模型交互,生成回答。
- 将预测结果pred和样本标准答案answers保存到中间文件,供后续评测。
生成预测的代码如下:
def get_pred(self, dataset, max_length, max_gen, prompt_format, out_path):
for json_obj in tqdm(dataset):
prompt = prompt_format.format(**json_obj)
if len(prompt) > max_length:
half = int(max_length/2)
prompt = prompt[:half] + prompt[-half:]
pred = self._chat(prompt, max_tokens=max_gen)
print(f"prompt: {prompt}, pred: {pred}")
with open(out_path, "a", encoding="utf-8") as f:
json.dump({"pred": pred, "answers": json_obj["answers"], "all_classes": json_obj["all_classes"], "length": json_obj["length"]}, f, ensure_ascii=False)
f.write('\n')
max_length的作用是控制输入上下文的大小,主要原因是本地跑的模型资源有限,加上数据集中的context比较长(多达6000汉字),控制输入上下文大小可以加快模型的运算,也避免超出token限制。
用tqdm迭代数据集,可以在python的长循环中看到运行的整体进度:

执行完后,得到预测数据,这是一个包含了预测答案pred和真实答案answers的中间数据集。
{"pred": "长沙市在交通方面采取的措施包括建设高铁网络、加快公路网建设、优化城市综合交通体系等。\n", "answers": ["启动南、北横线建设,基本实现乡镇30分钟上高速,行政村、自然村100%通水泥路。"], "all_classes": null, "length": 3119}
{"pred": "鹤壁市的经济社会发展还面临着以下困难和挑战:\n\n1. 经济结构单一,新兴产业和高技术产业比重不大。\n\n2. 产业发展与市场需求不匹配,部分产业市场饱和或市场需求减少。\n\n3. 产业结构调整与环境保护压力交织,推进产业结构优化升级、保护生态环境和实现高质量发展的路径选择复杂。\n", "answers": ["鹤壁市的经济社会发展还面临着经济下行压力加大、转型任务艰巨、风险隐患不容忽视、自身建设需要加强等困难和挑战。"], "all_classes": null, "length": 6190}
{"pred": "历时七年。完成了现存的从孔子至七十六代近两千五百年的108卷家谱档案。\n", "answers": ["7年。"], "all_classes": null, "length": 10397}
{"pred": "从上面的文章中我们可以看出:“十一五”时期我市的港口货物吞吐量增长了多少倍?具体的数据是“实现增加值45.6亿元,占GDP比重由6.2%提高到14.6%”。所以答案是14.6%。\n", "answers": ["2.2倍。"], "all_classes": null, "length": 3687}
……
4. 评测
评测分为以下几步:
- 数据清洗
- 定义评测函数
- 整体评测计算
4.1 数据清洗和分词
分词:这里使用开源的中文分词组件jieba将句子分为词组。
prediction_tokens = list(jieba.cut(prediction, cut_all=False))
ground_truth_tokens = list(jieba.cut(ground_truth, cut_all=False))
效果如下所示:
['鹤壁市', '的', '经济社会', '发展', '还', '面临', '着', '以下', '困难', '和', '挑战', ':', '\n', '\n', '1', '.', ' ', '经济', '结构', '单一', ',', '新兴产业', '和', '高技术', '产业', '比重', '不', '大', '。', '\n', '\n', '2', '.', ' ', '产业', '发展', '与', '市场需求', '不', '匹配', ',', '部分', '产业', '市场', '饱和', '或', '市场需求', '减少', '。', '\n', '\n', '3', '.', ' ', '产业', '结构调整', '与', '环境保护', '压力', ...]
['鹤壁市', '的', '经济社会', '发展', '还', '面临', '着', '经济', '下行', '压力', '加大', '、', '转型', '任务艰巨', '、', '风险', '隐患', '不容忽视', '、', '自身', '建设', '需要', '加强', '等', '困难', '和', '挑战', '。']
上面的分词结果中有不少标点符号,为避免这些符号对模型的评测造成干扰,在送评测之前进行数据清洗,其实就是把中文标点符号去掉。
def normalize_zh_aswer(s):
"""小写化,删除标点,删除空格"""
def white_space_fix(text):
return "".join(text.split())
def remove_punc(text):
cn_punctuation = "!?。。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏."
all_punctuation = set(string.punctuation + cn_punctuation)
return ''.join(ch for ch in text if ch not in all_punctuation)
def lower(text):
return text.lower()
return white_space_fix(remove_punc(lower(s)))
经过数据清洗后的分词结果:
['鹤壁市', '的', '经济社会', '发展', '还', '面临', '着', '以下', '困难', '和', '挑战', '1', '经济', '结构', '单一', '新兴产业', '和', '高技术', '产业', '比重', '不', '大', '2', '产业', '发展', '与', '市场需求', '不', '匹配', '部分', '产业', '市场', '饱和', '或', '市场需求', '减少', '3', '产业', '结构调整', '与', '环境保护', '压力', '交织', '推进', '产业结构', '优化', '升级', '保护', '生态环境', '和', '实现', '高质量', '发展', '的', '路径', '选择', '复杂']
['鹤壁市', '的', '经济社会', '发展', '还', '面临', '着', '经济', '下行', '压力', '加大', '转型', '任务艰巨', '风险', '隐患', '不容忽视', '自身', '建设', '需要', '加强', '等', '困难', '和', '挑战']
4.2 单条数据评测
经过前面的处理,已经有两个词语序列prediction(预测答案)和ground_truth(标准答案)。下面分步来计算F1分数。
- 分别统计两个词语序列中的每个词语的出现次数,用&运算符计算两个词语序列的交集。
Counter(prediction) & Counter(ground_truth)
> Counter({'鹤壁市': 1, '的': 1, '经济社会': 1, '发展': 1, '还': 1, '面临': 1, '着': 1, '困难': 1, '和': 1, '挑战': 1, '经济': 1, '压力': 1})
- 计算精确度:两者交集在预测序列中所占比例。
- 计算召回率:两者交集在样本序列中所占比例。
整体代码如下所示:
def f1_score(prediction, ground_truth, **kwargs):
# Counter以dict的形式存储各个句子对应的词与其对应个数,&操作符返回两个Counter中共同的元素的键值对
common = Counter(prediction) & Counter(ground_truth)
num_same = sum(common.values()) # 显示prediction与gt的共同元素的个数
if num_same == 0:
return 0
precision = 1.0 * num_same / len(prediction) # 即模型预测正确的样本数量与总预测样本数量的比值
recall = 1.0 * num_same / len(ground_truth) # 模型正确预测的样本数量与总实际样本数量的比值
f1 = (2 * precision * recall) / (precision + recall)
return f1
通过上面函数计算的f1_score示例,是一个百分比。
0.2962962962962963
3.3 整个数据集评测
方法:依次对每条数据计算F1分数score, 最后取所有数据的平均分保留两位小数作为整个数据集的平均评测分数。
def scorer(dataset, predictions, answers, all_classes):
total_score = 0.
for (prediction, ground_truths) in zip(predictions, answers):
ground_truths = ground_truths[0] if isinstance(ground_truths, list) else ground_truths
score = max(score,qa_f1_zh_score(prediction, ground_truths, all_classes=all_classes))
total_score += score
return round(100 * total_score / len(predictions), 2)
最后分数如下:
"multifieldqa_short_zh": 28.06
由于本地模型的资源和算力有限,加上中间裁剪了上下文数据,所以上面计算出来的本地模型评测分数并不高。不过这里不用关注分数大小,重点在于熟悉模型评测的一个流程。
参考资料
- tiny-universe
- jieba
- jpdm