相关博客
【自然语言处理】【大模型】语言模型物理学 第3.3部分:知识容量Scaling Laws
【自然语言处理】Transformer中的一种线性特征
【自然语言处理】【大模型】DeepSeek-V2论文解析
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
【自然语言处理】BitNet b1.58:1bit LLM时代
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
论文名称:Your Transformer is Secretly Linear
论文地址:https://arxiv.org/pdf/2405.12250
一、简介
- 本文揭示了transformer decoder独有的一种线性特征。分析相邻层的embedding变换,发现其具有接近完美的线性关系。
- 由于transformer层输出的范数一直很小,当移除残差链接时,线性度下降。
- 实验显示,当移除特别接近于线性的模块或者使用线性近似这些模块,对loss或者模型表现几乎没有影响。
- 通过在预训练中引入基于cosine相似度的正则化项来降低层的线性度,改善了模型在TinyStories和SuperGLUE上的效果。
二、线性评分
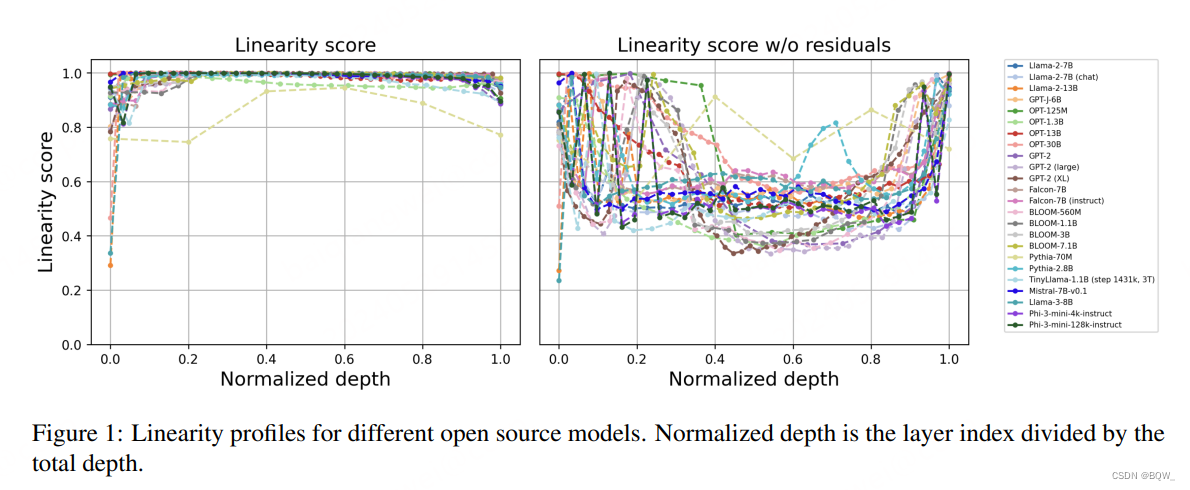
将Procrustes相似度推广到任意线性变换,从而实现了一种评估两组向量线性依赖程度的度量指标。
令
X
,
Y
∈
R
n
×
d
X,Y\in\mathbb{R}^{n\times d}
X,Y∈Rn×d表示embedding集合。为了计算线性评分,先计算规范化矩阵
X
~
=
X
/
∥
X
∥
2
,
Y
~
=
Y
/
∥
Y
∥
2
\tilde{X}=X/\parallel X\parallel_2,\tilde{Y}=Y/\parallel Y\parallel_2
X~=X/∥X∥2,Y~=Y/∥Y∥2。那么线性评分为
linearity_score
=
1
−
min
A
∈
R
d
×
d
∥
X
~
A
−
Y
~
∥
2
2
\text{linearity\_score}=1-\min_{A\in R^{d\times d}}\parallel\tilde{X}A-\tilde{Y}\parallel_2^2 \\
linearity_score=1−A∈Rd×dmin∥X~A−Y~∥22
这个形式与Procrustes相似度几乎一致。仅有的差别是在考虑最小化时考虑所有线性变换,而不仅仅是正交变换,从而找出最优映射的均分误差。
这种方式在评估embedding线性度方面更具鲁棒性。不同于 L 2 L_2 L2范数,其缺少尺度不变性,Procrustes normalization能够提供一个介于[0,1]的有界度量指标。令人惊讶的是,所有测试的transformer decoders的线性分数都接近于1,也就表明embedding的变换高度地线性(如上图1左所示)。
通过将每层的embedding值减去前一层embedding来评估main stream的线性度(即是否使用残差链接的embedding),发现线性程度显著下降。此外,每个块对于范数的贡献较低会导致相邻层的embedding的cos相似度接近。
从另一个角度来看,看似线性块的组合可能导致非线性的结果。之前的一些研究也表明,应用了注意力头的transformer可以跨神经网络组件编码复杂特征。这也表明线性变换的累计影响可能会编码复杂的非线性表示。
三、预训练和微调中的线性动态
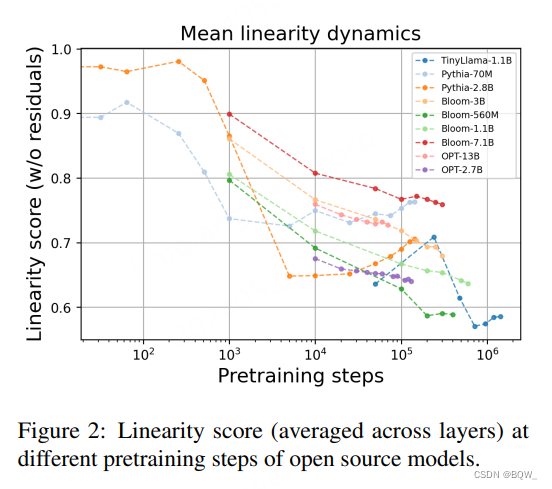
进一步探索在预训练和微调过程中的线性度动态。
如上图2所示,随着模型预训练的进行,main stream的线性度逐步下降。这种现象在所有测试的模型中都存在,这表明其是transformer-decoder学习动态的一个基础性质。
跨各种任务的微调阶段与预训练阶段相反,所有模型在微调过程中的线性度会增加。这个发现表明,任务相关的微调倾向于强化transformer模型中的线性特征。
四、使用正则化预训练改善线性度
为了理解transformer模型中线性度的影响,使用尺寸大小为150M和650M的Mistral架构进行预训练实验。这些模型在精心挑选的干净数据集上预训练,包括TinyStories和Tiny-textbooks。
引入特定的loss项来调整transformer层之间embedding的关系:
-
MSE正则化项
对连续层之间的embedding使用MSE正则化项,最小化这些embedding的距离,促进层间一致性。
L MSE = λ ∑ ( ∥ emb i − emb i − 1 ∥ 2 ) L_{\text{MSE}}=\lambda\sum(\parallel\text{emb}_i-\text{emb}_{i-1} \parallel^2) \\ LMSE=λ∑(∥embi−embi−1∥2) -
Cosine相似度正则化项
使用cosine相似度正则化项将相邻层的embedding角度差异降低至0。
L cosine = λ ∑ ( 1 − cos ( emb i , emb i − 1 ) ) L_{\text{cosine}}=\lambda\sum(1-\cos(\text{emb}_i,\text{emb}_{i-1})) \\ Lcosine=λ∑(1−cos(embi,embi−1))
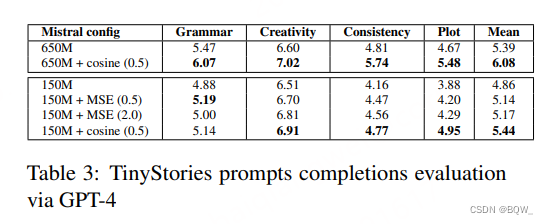
使用基于cosine的方法能够实现最好的结果,能够使得cosine相似度接近于1。该方法在增强模型效果方面很有前景。通过GPT-4在TinyStories、线性探针技术和SuperGLUE基准上评估方法有效性。结果如下表2和下表3所示。

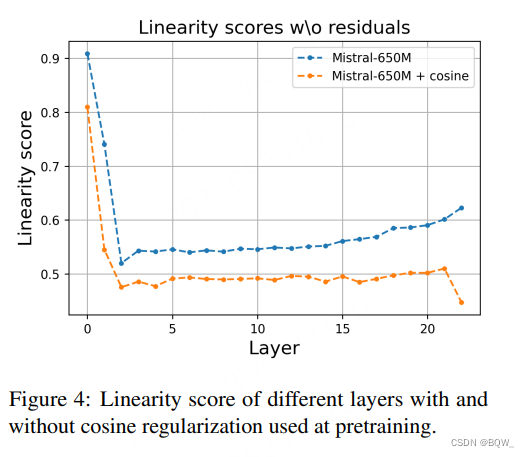
此外,如下图4所示,使用这种正则化项进行预训练后,线性评分更低。




![[数据集][目标检测]猫狗检测数据集VOC+YOLO格式8291张2类别](https://img-blog.csdnimg.cn/direct/f6c3c6434b024d7ab759f369b8627fa4.png)




![[初始计算机]——计算机网络的基本概念和发展史及OSI参考模型](https://img-blog.csdnimg.cn/direct/7d997e4e47c8413293e563cb4d7c2841.png)