文章目录
- LLM训练流程
- LLM中的tokenizers
- BPE
- WordPiece
- Unigram
- SentencePiece(使用BBPE或Unigram)
LLM训练流程
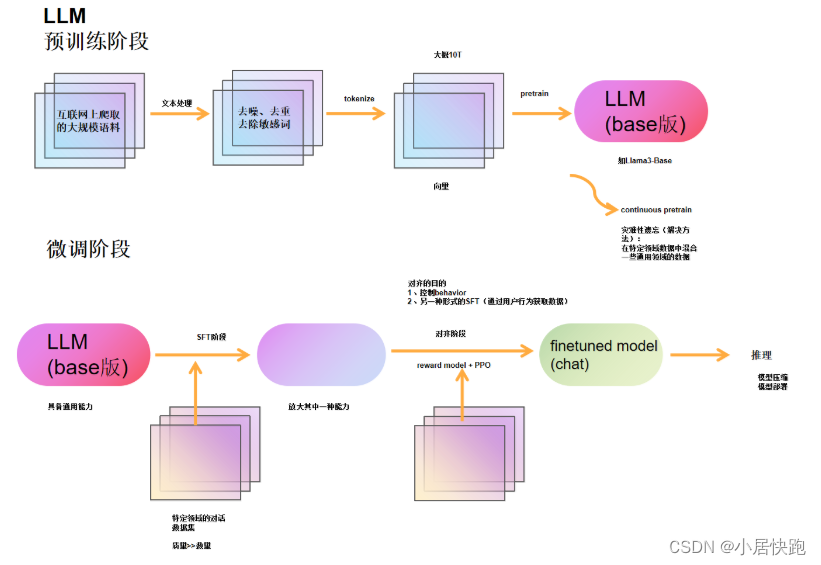
【大语言模型LLM基础之Tokenizer完全介绍-哔哩哔哩】 https://b23.tv/2kdTKxf
LLM中的tokenizers
三种不同分词粒度的Tokenizers
- word-based
- character-based
- subword-based
- WordPiece:BERT、DistilBERT
- Unigram:XLNet、ALBERT
- BPE(Byte-Pair Encoding):GPT-2、RoBERTa
- SentencePiece
BPE
词频统计->词表合并
设置:BPE的合并次数
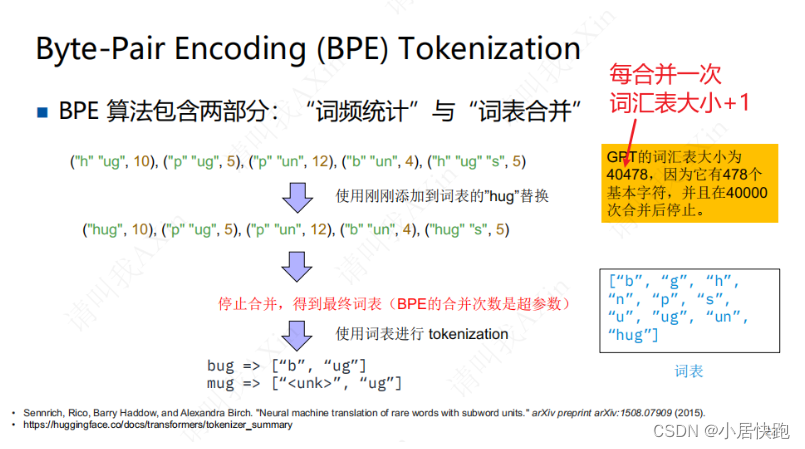
改进:BBPE

WordPiece

Unigram
先初始化一个很大的词表(字母、单词、subword都包括)
设置:删减的次数
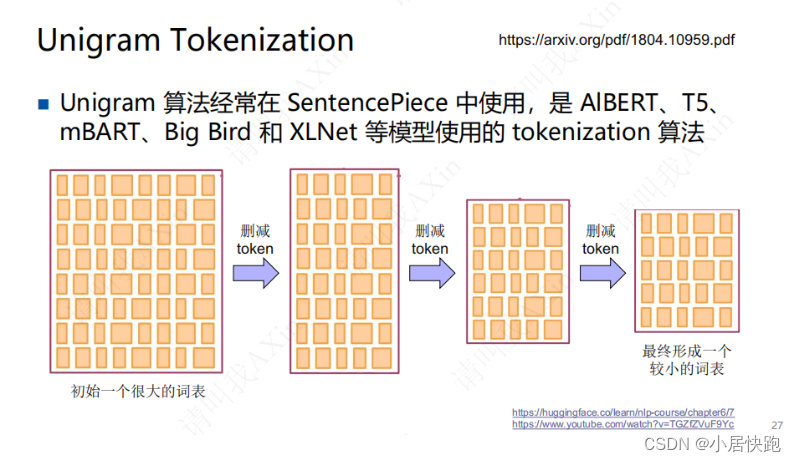
删去对词表的表达能力影响不大的token
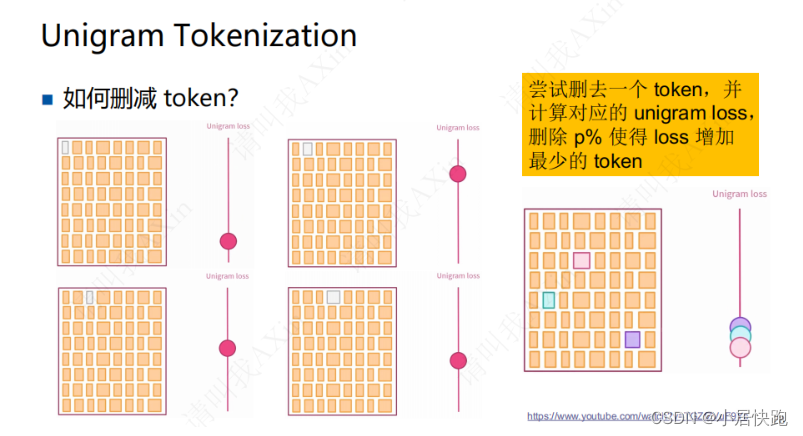
基于统计的划分
loss:负对数似然
SentencePiece(使用BBPE或Unigram)
解决多国语言的分词问题,输入都当做字节流(含空格)










![【PostgreSQL17新特性之-冗余IS [NOT] NULL限定符的处理优化】](https://img-blog.csdnimg.cn/img_convert/d8c52000ffd33b61ebaa1a0113f46d9c.png)