Hudi之数据读写深入探究
1. Hudi数据写入
1-1. 写操作
Hudi数据湖中的数据更新、插入和删除操作,是一个基于Apache Hadoop的库,为数据湖提供了一种有效的方法来处理更新和增量数据,并支持基于时间的快照和增量数据处理。Hudi支持三种主要的数据操作模式:UPSERT(更新或插入)、INSERT(插入)、BULK_INSERT(批量插入)。
1-1-1. UPSERT(更新或插入)
UPSERT是指将数据更新到现有数据集中,写入数据时检查数据是否已存在,如果数据不存在,则插入新数据,这涉及到数据的读取、对比和合并。这种操作模式适用于需要实时更新或修复数据的场景。使用Hudi的UPSERT功能,可以轻松地将新数据合并到现有数据集中,并在必要时更新已存在的记录。这种方式确保了数据集的一致性和准确性。
- 性能特点:
- 数据读取和对比: 为了确定哪些记录需要更新,Hudi必须读取现有数据文件。这会导致额外的I/O开销。
- 索引维护: Hudi使用索引(如布隆过滤器或哈希索引)来快速查找现有记录,减少数据读取时间,但索引维护本身也增加了开销。
- 合并过程: 数据合并需要计算和重写数据文件,这增加了CPU和I/O负载。
- 索引处理:
- 索引查找: UPSERT操作依赖索引来快速查找现有记录,以确定哪些记录需要更新。Hudi通常使用布隆过滤器或哈希索引来加速这一过程。
- 索引维护: 在数据更新和插入后,Hudi还需要维护这些索引,以确保后续查询和写入操作的效率。
- 适用场景:
适用于需要频繁更新数据的场景,如实时数据流处理、在线交易系统等。
1-1-2. INSERT(插入)
INSERT操作用于将新数据插入到数据湖中,而不进行任何更新。这种模式适用于将新数据加载到数据湖中,而无需考虑现有数据集的变化。使用Hudi的INSERT功能,可以快速地将新数据加载到数据湖中,并确保数据的完整性和可靠性。INSERT操作仅仅是将新数据写入到数据湖中,所以无需检查或更新现有数据。是一个简单的追加操作。
性能特点:
- 简化写入路径: 不需要读取现有数据或进行对比,直接写入新数据,大大简化了写入路径。
- 更低的I/O开销: 由于没有数据读取和合并过程,I/O开销显著降低。
- 更高的吞吐量: 因为写入过程简单,INSERT操作通常能实现更高的吞吐量。
索引处理:
- 无需索引查找: INSERT操作仅将新数据写入,不需要查找现有记录。
- 索引维护: 虽然INSERT操作不需要查找索引,但在数据写入后,Hudi会更新索引,以确保新数据可被后续查询和操作快速访问。
适用场景:
适用于每次写入都是新数据的场景,如批量数据加载、传感器数据收集等。
1-1-3. BULK_INSERT(批量插入)
BULK_INSERT操作类似于INSERT操作,是优化的INSERT操作。可以一次性插入大量数据,从而提高数据加载的效率。这种模式适用于需要高性能地加载大批量数据的场景。Hudi的BULK_INSERT功能可以有效地处理大规模数据加载任务,并确保数据加载的速度和稳定性。
性能特点:
- 优化的文件写入: BULK_INSERT通过优化数据文件的分配和组织方式,最大化写入效率。
- 并行写入: 利用并行处理技术,将大量数据拆分成多个部分并行写入,极大地提高了写入速度。
- 最小化索引开销: BULK_INSERT在写入过程中减少了索引维护的负担,进一步提升了性能。
索引处理:
- 无需索引查找: BULK_INSERT与INSERT类似,不需要查找现有记录。
- 延迟索引维护: 为了优化批量写入性能,BULK_INSERT通常会延迟索引更新,或采用批量更新的方式,减少索引维护的频率和开销。
适用场景:
适用于需要高效地加载大量数据的场景,如数据湖初始化、大规模数据迁移、数据仓库批量导入等。
1-1-4. 写操作性能对比总结
| 操作类型 | I/O开销 | CPU开销 | 写入吞吐量 | 磁盘空间利用 | 内存消耗 | 并发处理能力 | 网络开销 |
|---|---|---|---|---|---|---|---|
| INSERT-写入 | 最低 | 几乎无需计算 | 吞吐量较高 | 低 | 低 | 一般 | 低 |
| BULK_INSERT-批量写 | 需要更多I/O | 有一些计算需求 | 吞吐量最高 | 较低 | 较低 | 高 | 低 |
| UPSERT-更新或写入 | 最高 | 需要较高的计算资源 | 吞吐量最低 | 高 | 较高 | 低 | 高 |
2. Hudi数据写流程
2-1. 数据写入步骤
-
数据准备
当新数据到达时(我们称之为增量数据),首先需要将其转换成Hudi的内部格式。这些数据通常会包含两个重要的键
- 记录键(Record Key): 唯一标识每条记录。
- 分区键(Partition Key): 决定数据应该放在哪个“分区”(类似于文件夹)。
-
scala> spark.sql("SELECT _hoodie_record_key,_hoodie_partition_path,role_cn,tianfu FROM hudi_ro_view").show() +------------------+----------------------+--------+-------------------+ |_hoodie_record_key|_hoodie_partition_path| role_cn| tianfu| +------------------+----------------------+--------+-------------------+ | 4| zhuangbei=皮甲| 盗贼| 狂徒|刺杀|敏锐| | 5| zhuangbei=皮甲| 武僧| 酒仙|踏风|织雾| | 6| zhuangbei=皮甲| 德鲁伊|恢复|平衡|野性|守护| | 7| zhuangbei=皮甲|恶魔猎手| 复仇|浩劫| | 11| zhuangbei=板甲|死亡骑士| 鲜血|冰霜|邪恶| | 12| zhuangbei=板甲| 战士| 武器|狂暴|防护| | 13| zhuangbei=板甲| 圣骑士| 神圣|防护|惩戒| | 8| zhuangbei=锁甲| 猎人| 兽王|生存|射击| | 9| zhuangbei=锁甲| 萨满| 恢复|增强|元素| | 10| zhuangbei=锁甲| 龙人| 湮灭|恩护|增辉| | 1| zhuangbei=布甲| 法师| 冰法|火法|奥法| | 2| zhuangbei=布甲| 牧师| 神牧|戒律|暗牧| | 3| zhuangbei=布甲| 术士| 毁灭|痛苦|恶魔| +------------------+----------------------+--------+-------------------+
-
分区划分
Hudi会根据分区键来决定每条记录属于哪个分区。这一步确保数据按照分区键被组织好,使得后续处理更加高效。
-
建立索引
Hudi使用索引来加速查找记录。常见的索引类型有:
- 布隆过滤器(Bloom Filter): 快速检查某条记录是否可能在某个文件中。
- 哈希索引(Hash Index): 在内存中快速定位记录键。
在执行UPSERT操作时,索引用于确定哪些新记录需要更新已有记录,哪些是全新的记录。
-
查找匹配记录
Hudi利用索引快速找到与新数据记录键匹配的旧数据文件。这一步骤大大减少了需要扫描的数据量,从而提高处理速度。
-
读取现有数据
找到匹配的旧记录后,Hudi会读取这些旧记录,准备与新数据进行合并。
-
数据合并
Hudi将新数据与旧数据合并。这一过程可以自定义,但通常包括以下情况:
- 更新现有记录: 用新数据中的信息更新旧记录。
- 插入新记录: 如果没有找到匹配的旧记录,则直接插入新记录。
-
写入新的数据文件
合并后的数据会被写入新的数据文件中。这些文件通常按照分区组织,以便于后续查询和管理。
-
更新索引
新数据文件写入后,Hudi会更新索引,反映最新的记录位置和状态。这确保未来的UPSERT和查询操作能够高效进行。
-
提交事务
Hudi将每次UPSERT操作视为一个事务。只有当所有步骤成功完成后,Hudi才会提交事务,确保数据一致性。如果有任何一步失败,Hudi会回滚操作,以保证数据不会出错。
-
清理和优化
最后,Hudi会执行一些维护工作,保持系统的高效运行:
- 清理旧数据文件: 删除不再需要的旧文件,释放存储空间。
- 文件压缩和合并: 为了提高存储和查询性能,Hudi可能会将多个小文件合并成一个大文件,减少碎片。
2-2. Copy On Write (COW)
Copy On Write (COW) :这是一种写入数据的技术,它不直接在原始数据上进行修改,而是在写入新数据时创建副本(Copy),然后在副本上进行修改(Write)。
工作原理:
- 数据准备和索引查找: 和标准UPSERT流程一致,首先准备新数据并通过索引查找现有数据文件中需要更新的记录。
- 数据合并: 读取需要更新的现有数据文件,将新数据和旧数据进行合并。
- 写入新文件: 合并后的数据被写入新的数据文件,旧的数据文件被标记为无效或删除。
- 索引更新: 更新索引以反映新数据文件的位置和状态。
- 事务提交和清理: 提交事务并清理旧数据文件。
性能特征:
- 写入开销: 写入性能相对较低,因为每次更新都需要重写整个数据文件。
- 查询性能: 查询性能较好,因为每个数据文件都是完整的,无需额外的合并操作。
- 存储效率: 存储效率相对较低,尤其是在频繁更新的场景下,因为每次更新都会产生大量的新文件和旧文件碎片。
适用场景:
适用于读操作频繁而写操作相对较少的场景,例如批量数据加载、定期数据更新等。
Copy On Write模式的UPSERT
(1)首先对记录按照记录键(record key)进行去重,确保每个键值只出现一次。
(2)创建索引(HoodieKey => HoodieRecordLocation),这个索引用于区分哪些记录需要更新,哪些需要插入。通过这个索引,可以快速定位到记录的位置和状态。
(3)对于需要更新的记录,找到其对应的最新文件(FileSlice)的基本文件(base file),将更新后的数据与原始数据进行合并(merge),然后写入新的基本文件(新的FileSlice)。这个步骤确保了数据的一致性和持久性。
(4)对于需要插入的记录,会扫描当前分区的所有小文件(SmallFile,即小于一定大小的基本文件),然后将新记录与这些小文件进行合并,生成新的FileSlice。如果当前分区没有小文件,则直接创建新的文件组(FileGroup)和FileSlice来存储插入的记录。
2-3. Merge On Read (MOR)
Merge On Read (MOR):这是一种写入数据的技术,它在读取数据时进行合并,而不是在写入时立即合并。
工作原理:
- 数据准备和索引查找: 和标准UPSERT流程一致,首先准备新数据并通过索引查找现有数据文件中需要更新的记录。
- 数据写入增量文件: 新数据和更新数据被写入增量文件(delta files),而不是重写整个数据文件。
- 写入基准文件: 基准数据文件(base files)保持不变,仅当数据文件达到一定条件时才会进行合并。
- 合并操作: 查询时,Hudi会将增量文件和基准文件合并(on-read merge)以提供最新的数据视图。
- 索引更新: 更新索引以反映增量文件的位置和状态。
- 事务提交和清理: 提交事务,并根据配置策略定期合并和清理增量文件和基准文件。
性能特征:
- 写入开销: 写入性能较高,因为新数据只需写入增量文件,无需重写整个数据文件。
- 查询性能: 查询性能相对较低,因为需要在读取时进行合并操作,尤其是在增量文件较多时。
- 存储效率: 存储效率较高,因为更新操作不会产生大量的重写文件,但需要定期合并增量文件以减少碎片。
适用场景:
适用于写操作频繁、实时数据更新的场景,例如实时数据流处理、事件驱动系统等。
Merge On Read模式的UPSERT
(1)首先对记录按照记录键(record key)进行去重(可选),确保每个键值只出现一次。
(2)创建索引(HoodieKey => HoodieRecordLocation),这个索引用于区分哪些记录需要更新,哪些需要插入。通过这个索引,可以快速定位到记录的位置和状态。
(3)对于需要插入的记录:
- 如果日志文件(log file)不可建立索引(默认情况),系统会尝试合并分区内最小的基本文件(不包含日志文件的FileSlice),生成新的FileSlice。如果没有基本文件,则创建新的文件组(FileGroup)、FileSlice和基本文件(base file)。
- 如果日志文件可建立索引,则尝试追加小的日志文件。如果没有小的日志文件,则新建一个FileGroup、FileSlice和基本文件。
(4)对于需要更新的记录:
- 写入对应的文件组(FileGroup)和文件片段(FileSlice),直接追加最新的日志文件。如果最新的日志文件是当前最小的小文件,则会合并基本文件,生成新的文件片段。
(5)当日志文件的大小达到一定阈值时,会创建一个新的日志文件(roll over)。
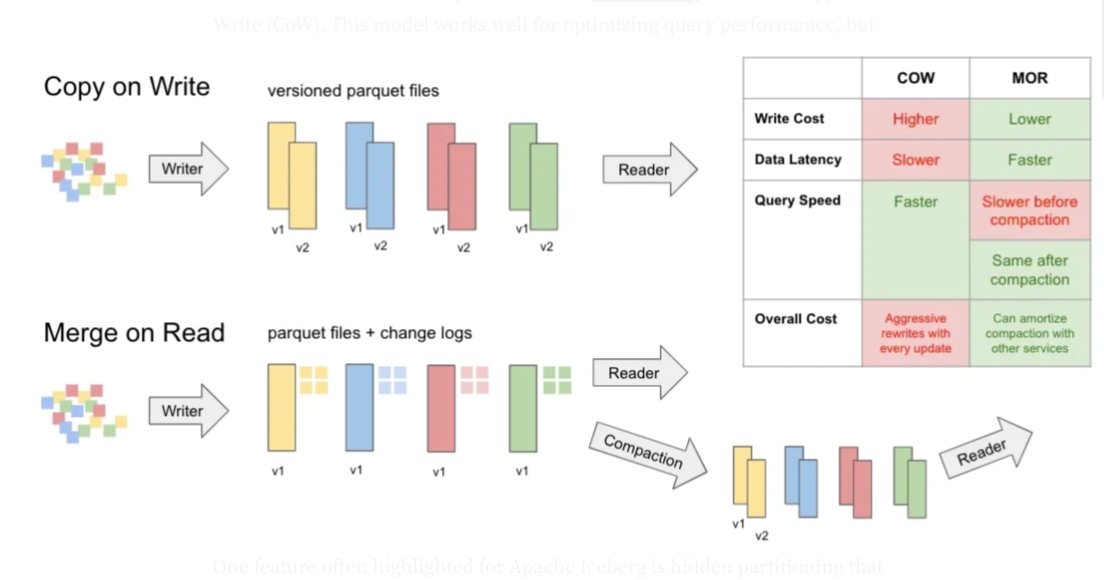
2-4. COW vs MOR 对比表
| 维度 | Copy On Write (COW) | Merge On Read (MOR) |
|---|---|---|
| 写入性能 | 中等:每次写入都需要重写整个文件,因此写入开销较大。 | 高:新数据写入增量文件,无需重写基准文件,因此写入速度快。 |
| 查询性能 | 高:查询时数据文件是完整的,不需要额外的合并操作,读取速度快。 | 中等到低:查询时需要合并增量文件和基准文件,尤其是增量文件较多时,查询速度可能较慢。 |
| 存储效率 | 中等:频繁重写文件可能导致存储碎片化,增加存储需求。 | 高:通过增量文件和基准文件的方式,减少了重写文件的开销,存储效率更高。 |
| 适用场景 | 读操作频繁,写操作较少:适用于批量数据加载、定期更新等场景。 | 写操作频繁,需实时数据更新:适用于实时数据流处理、事件驱动系统等场景。 |
| 实现复杂度 | 较低:操作相对简单,不需要处理增量文件和基准文件的合并。 | 较高:需要处理增量文件和基准文件的合并,逻辑较为复杂。 |
| 资源消耗 | I/O和存储开销较高:每次写入都涉及重写整个文件,导致较高的I/O和存储消耗。 | I/O消耗较低:写入只需写增量文件,但查询时的合并操作可能增加计算负担。 |
| 数据一致性 | 高:数据文件是完整的,无需额外处理即可保证一致性。 | 高:读取时需要合并操作才能获得一致的数据视图,但通过事务保证一致性。 |
| 延迟 | 写入延迟较高:需要重写文件,导致写入操作延迟增加。 | 写入延迟较低:增量文件写入速度快,延迟较低。 |
| 合并频率 | 不需要频繁合并:文件生成后即为最终文件。 | 需要定期合并:增量文件和基准文件的合并需要定期进行,以优化查询性能。 |
| 数据恢复 | 较简单:数据文件直接反映最新数据,恢复操作较简单。 | 较复杂:需要合并增量文件和基准文件,恢复操作更复杂。 |
| 文件管理 | 较简单:主要关注删除旧文件和清理碎片。 | 较复杂:需要处理增量文件和基准文件的关系。 |
| 实时分析 | 支持有限:适合批处理和定期分析。 | 强大支持:适合实时数据流处理和分析。 |
| 存储空间 | 可能较高:由于频繁的文件重写,存储需求较大。 | 相对较低:通过增量文件管理更高效,减少存储需求。 |
| 数据老化 | 需要定期清理:老旧文件需要手动清理。 | 自动管理:通过增量文件和基准文件的合并,自动管理老旧数据。 |
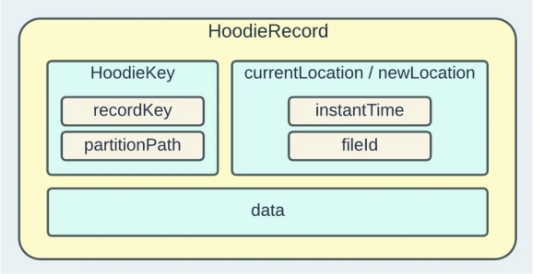
2-5. HoodieKey
HoodieKey是Hudi中一个重要的概念,HoodieKey就像是数据的身份证,它帮助Hudi准确地管理和追踪数据的变更,它是数据的唯一标识,用于在数据湖中追踪和管理数据的变更。想象一下你有一个大仓库,里面摆放着各种货物,而每一件货物都有一个独特的编号,这个编号就是HoodieKey。它告诉你这件货物的唯一身份。
现在,这个仓库经常有新货物进来,也有旧货物出去,这就是数据的变更。当有新的货物进来时,你需要确保它有一个唯一的编号,这样你才能在仓库中找到它。而当有货物出去时,你也需要记录下它的编号,以便知道它是什么时候离开了仓库。
HoodieKey就像是每件货物的编号一样,它帮助Hudi追踪和管理数据的变更。每条数据都有一个唯一的HoodieKey,用于标识它的身份。当有新数据写入时,Hudi会根据HoodieKey来确定它是新增还是更新,从而正确地处理数据。同时,Hudi还可以根据HoodieKey来进行数据的查询、合并和版本控制,确保数据的一致性和完整性。
HUDI的Key生成策略通常包括以下几个方面:
- Record Key(记录键):每条记录都有一个唯一的Record Key,用于在数据集中唯一标识一条记录。通常情况下,Record Key由用户指定,并且应该具有足够的唯一性,以便HUDI可以根据Record Key来进行数据的插入、更新和删除操作。
- Partition Key(分区键):HUDI可以根据Partition Key将数据分割成不同的分区,以便更高效地管理和查询数据。Partition Key通常根据业务需求来选择,可以是日期、地理位置、业务类型等。HUDI根据Partition Key来组织数据存储,使得可以针对不同的分区进行并行处理。
- FileID(文件标识):HUDI在存储数据时会将数据分成多个文件,每个文件都有一个唯一的FileID用于标识。FileID通常由HUDI根据文件创建时间或其他规则生成,确保每个文件都具有唯一性。
- Commit Time(提交时间):HUDI还可以根据数据的提交时间来生成Key,以便对数据进行版本控制和追溯。通过Commit Time,可以了解到每条数据的写入时间,以及数据的变更历史。
综合利用Record Key、Partition Key、FileID和Commit Time等信息,HUDI可以生成唯一的Key来标识和管理数据的变更,从而实现对大规模数据变更的高效管理和处理。
3. Hudi的删除策略
3-1. 物理删除(Physical Delete)
物理删除直接从数据文件中移除记录,不再保留这些数据。这种删除方式可以减少存储空间,但可能影响查询性能,特别是在需要频繁合并数据文件时。
工作原理:
- 标记待删除记录:首先,Hudi将待删除的记录标记为删除状态。通过记录键(Record Key)识别待删除的记录。
- 生成删除文件:将标记删除的记录写入一个删除日志文件(Delete Log File)。
- 数据文件合并:在下一次Compaction(合并)操作时,删除标记的记录将从数据文件中移除。
优缺点:
- 优点:可以减少存储空间,最终只保留有效的数据。
- 缺点:需要频繁合并数据文件,可能会影响写入和查询性能。
3-2. 逻辑删除(Logical Delete)
逻辑删除只是将记录标记为删除状态,但不实际从数据文件中移除。这种方式通常通过添加一个删除标记字段来实现,在查询时过滤掉这些标记为删除的记录。
工作原理:
- 标记删除状态:在待删除的记录上添加一个删除标记字段,设置为true或其他表示删除的状态。
- 查询过滤:查询时,通过过滤条件排除标记为删除的记录。
- 保留数据:实际数据依然保存在文件中,只是在查询时不再返回这些记录。
优缺点:
- 优点:删除操作快速且不需要合并数据文件,适用于需要保留历史数据的场景。
- 缺点:会占用额外的存储空间,因为删除的数据实际上仍然存在。
4. Hudi读数据
4-1. 快照查询(Snapshot Query)
快照查询提供了一个数据集的最新视图,包括所有已提交的插入、更新和删除操作。它是最常用的查询模式,适用于需要读取最新完整数据的场景。
读取所有 partiiton 下每个 FileGroup 最新的 FileSlice 中的文件,Copy On Write 表读 parquet 文件,Merge On Read 表读 parquet + log 文件
工作原理
- 数据版本管理:Hudi通过时间戳管理数据版本,快照查询只会读取最新提交的文件。
- 合并操作:在Merge On Read(MOR)模式下,快照查询会将基准文件(Base Files)和增量文件(Delta Files)合并,确保返回的数据是最新的。
- 查询执行:快照查询直接读取最新的数据文件,无需用户手动处理版本和合并。
示例
val hudiOptions = Map(
"hoodie.datasource.query.type" -> "snapshot"
)
val snapshotDF = spark.read.format("hudi")
.options(hudiOptions)
.load("path_to_hudi_table")
snapshotDF.show()
优缺点
- 优点:简单易用,直接获取最新数据。
- 缺点:在MOR模式下,合并操作可能会增加查询延迟。
4-2. 增量查询(Incremental Query)
增量查询用于获取从指定时间点或提交开始的数据变更,包括插入、更新和删除操作。适用于需要增量加载数据到其他系统或进行增量处理的场景。
当前的 Spark data source 可以指定消费的起始和结束 commit 时间,读取 commit 增量的数据集。但是内部的实现不够高效:拉取每个 commit 的全部目标文件再按照系统字段 hoodie_commit_time apply 过滤条件
工作原理
- 提交点(Commit Point)管理:Hudi为每次写操作生成一个唯一的提交点标识,增量查询可以基于这个提交点进行数据过滤。
- 读取变更数据:增量查询只读取从上一个提交点以来的变更数据,包括新增、更新和删除的记录。
示例
val hudiOptions = Map(
"hoodie.datasource.query.type" -> "incremental",
"hoodie.datasource.read.begin.instanttime" -> "20230101000000",
"hoodie.datasource.read.end.instanttime" -> "20230102000000"
)
val incrementalDF = spark.read.format("hudi")
.options(hudiOptions)
.load("path_to_hudi_table")
incrementalDF.show()
优缺点
- 优点:高效地获取数据变更,适合实时数据同步和流处理。
- 缺点:需要维护提交点信息,管理复杂度较高。
4-3. 流式查询(Streaming Query)
流式查询通过持续监控Hudi表的变更,实现实时数据流处理。适用于需要实时响应数据变化的场景,如实时分析、实时监控等。可用于同步 CDC 数据,日常的数据同步 ETL pipeline。
工作原理
- 流处理引擎集成:流式查询通常与流处理引擎(如Apache Spark Structured Streaming)集成,自动处理数据变更。
- 增量加载:通过持续增量加载数据,实时反映数据变化。
示例
import org.apache.spark.sql.streaming.Trigger
val streamingDF = spark.readStream.format("hudi")
.option("hoodie.datasource.query.type", "incremental")
.load("path_to_hudi_table")
val query = streamingDF.writeStream
.format("console")
.trigger(Trigger.ProcessingTime("10 seconds"))
.start()
query.awaitTermination()
优缺点
- 优点:实时处理数据变更,适用于实时数据处理和分析。
- 缺点:需要设置流处理环境,管理复杂度较高。
4-4. 查询方式对比分析
| 维度 | Snapshot Query | Incremental Query | Streaming Query |
|---|---|---|---|
| 数据视图 | 最新视图,包含所有已提交的变更 | 从指定提交点开始的增量变更 | 持续的实时数据变更 |
| 适用场景 | 读取最新完整数据,批处理和定期分析 | 增量加载数据到其他系统,增量处理 | 实时分析、实时监控 |
| 实现复杂度 | 低,直接读取最新数据 | 中,需要管理提交点信息 | 高,需要设置和管理流处理环境 |
| 查询延迟 | 可能较高(特别是MOR模式) | 较低,仅读取变更数据 | 极低,实时反映数据变化 |
| 资源消耗 | 中等,视数据量和合并操作复杂度而定 | 较低,仅处理变更数据 | 较高,持续处理实时数据 |
| 数据一致性 | 高,返回最新提交的一致性数据 | 高,基于提交点的一致性数据 | 高,实时保证数据一致性 |
| 性能优化 | 通过索引和合并策略优化查询性能 | 通过选择合适的提交点和过滤条件优化性能 | 通过设置合适的触发器和流处理参数优化性能 |
5. 魔兽世界demo代码演示
现在有一个MySQL数据库,存储了一张魔兽世界的中的职业信息表,现在通过spark把MySQL的数据读取,然后写入到hudi,通过这个简单的demo示例体会整个过程
代码运行环境这里不过多介绍,最基础的实验环境可以是spark单机,hudi依赖+MySQL连接器放入spark的jars目录中,存储使用本地存储
5-1. 环境准备
- MySQL信息
MariaDB [wow]> desc wow_info;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| role | varchar(255) | YES | | NULL | |
| role_cn | varchar(255) | YES | | NULL | |
| role_pinyin | varchar(255) | YES | | NULL | |
| zhuangbei | varchar(255) | YES | | NULL | |
| tianfu | varchar(255) | YES | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
MariaDB [wow]> select * from wow_info;
+----+------+--------------+-------------+-----------+-----------------------------+
| id | role | role_cn | role_pinyin | zhuangbei | tianfu |
+----+------+--------------+-------------+-----------+-----------------------------+
| 1 | fs | 法师 | fashi | 布甲 | 冰法|火法|奥法 |
| 2 | ms | 牧师 | mushi | 布甲 | 神牧|戒律|暗牧 |
| 3 | ss | 术士 | shushi | 布甲 | 毁灭|痛苦|恶魔 |
| 4 | dz | 盗贼 | daozei | 皮甲 | 狂徒|刺杀|敏锐 |
| 5 | ws | 武僧 | wuseng | 皮甲 | 酒仙|踏风|织雾 |
| 6 | xd | 德鲁伊 | xiaode | 皮甲 | 恢复|平衡|野性|守护 |
| 7 | dh | 恶魔猎手 | emolieshou | 皮甲 | 复仇|浩劫 |
| 8 | lr | 猎人 | lieren | 锁甲 | 兽王|生存|射击 |
| 9 | sm | 萨满 | saman | 锁甲 | 恢复|增强|元素 |
| 10 | long | 龙人 | longren | 锁甲 | 湮灭|恩护|增辉 |
| 11 | dk | 死亡骑士 | siwangqishi | 板甲 | 鲜血|冰霜|邪恶 |
| 12 | zs | 战士 | zhanshi | 板甲 | 武器|狂暴|防护 |
| 13 | sq | 圣骑士 | shengqi | 板甲 | 神圣|防护|惩戒 |
+----+------+--------------+-------------+-----------+-----------------------------+
5-2. 代码开发
- 编写Scala任务
[root@wangting ~]# mkdir -p ~/hudi_test/
[root@wangting ~]# cd hudi_test/
[root@wangting hudi_test]# vim MySQLToHudi.scala
MySQLToHudi.scala内容
import org.apache.spark.sql.{SparkSession, DataFrame}
object MySQLToHudi {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("MySQLToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 设置MySQL连接参数
val mysqlOptions = Map(
"url" -> "jdbc:mysql://wangtingmysql:3306/wow",
"dbtable" -> "wow_info",
"user" -> "root",
"password" -> "123456"
)
// 读取MySQL数据
val mysqlDF: DataFrame = spark.read.format("jdbc").options(mysqlOptions).load()
// 定义Hudi表路径,一般为hdfs路径
val hudiTablePath = "file:///root/hudi_test/hudi_wow_info"
// 写入Hudi表
mysqlDF.write
.format("org.apache.hudi")
.option("hoodie.table.name", "hudi_wow_info")
.option("hoodie.datasource.write.operation", "bulk_insert")
.option("hoodie.datasource.write.recordkey.field", "id")
.option("hoodie.datasource.write.precombine.field", "id")
.option("hoodie.datasource.write.partitionpath.field", "zhuangbei")
.option("hoodie.datasource.write.table.type", "COPY_ON_WRITE")
.option("hoodie.datasource.write.hive_style_partitioning", "true")
.option("hoodie.upsert.shuffle.parallelism", "4")
.option("hoodie.bulkinsert.shuffle.parallelism", "4")
.mode("overwrite")
.save(hudiTablePath)
spark.stop()
}
}
代码中将存储文件写入到本地
file:///root/hudi_test/hudi_wow_info环境,便于测试查看
5-3. 上线运行
运行:
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0,mysql:mysql-connector-java:5.1.37
# 加载开发完毕的MySQLToHudi功能(:load)
scala> :load /root/hudi_test/MySQLToHudi.scala
Loading /root/hudi_test/MySQLToHudi.scala...
import org.apache.spark.sql.{SparkSession, DataFrame}
defined object MySQLToHudi
# 执行main方法,进行数据读写(对象名加main方法)
scala> MySQLToHudi.main(Array())
498361 [Executor task launch worker for task 0.0 in stage 9.0 (TID 227)] WARN org.apache.hadoop.metrics2.impl.MetricsConfig
执行完毕后,查看存储文件:
[root@wangting ~]# cd /root/hudi_test/hudi_wow_info
[root@wangting hudi_wow_info]# ll
total 16
drwxr-xr-x 2 root root 4096 May 28 16:36 zhuangbei=布甲
drwxr-xr-x 2 root root 4096 May 28 16:36 zhuangbei=板甲
drwxr-xr-x 2 root root 4096 May 28 16:36 zhuangbei=皮甲
drwxr-xr-x 2 root root 4096 May 28 16:36 zhuangbei=锁甲
[root@wangting hudi_wow_info]# ls zhuangbei=布甲/
1a0d1d0d-123a-4148-bde4-3d19ecab9668-0_0-0-0_20240528163634383.parquet
可以看到文件的存储格式:
1a0d1d0d-123a-4148-bde4-3d19ecab9668-0_0-0-0_20240528163634383.parquet1a0d1d0d-123a-4148-bde4-3d19ecab9668-0 -> fileId
0-0-0 -> writeToken
20240528163634383 -> instantTime
parquet -> fileExtension
5-4. Hudi读取数据
Apache Spark 来读取 Hudi 表 读取数据
// 启动
spark-shell \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0,mysql:mysql-connector-java:5.1.37
// 读取数据
import org.apache.spark.sql.Dataset
import org.apache.spark.sql.Row
val basePath = "file:///root/hudi_test/hudi_wow_info"
val hoodieROViewDF: Dataset[Row] = spark.read.format("org.apache.hudi").load(s"$basePath/*")
// 查询数据
hoodieROViewDF.createOrReplaceTempView("hudi_ro_view")
spark.sql("SELECT * FROM hudi_ro_view").show()
命令行展示:
[root@wangting jars]# spark-shell \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
> --packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0,mysql:mysql-connector-java:5.1.37
scala> import org.apache.spark.sql.Dataset
import org.apache.spark.sql.Dataset
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val basePath = "file:///root/hudi_test/hudi_wow_info"
basePath: String = file:///root/hudi_test/hudi_wow_info
scala> val hoodieROViewDF: Dataset[Row] = spark.read.format("org.apache.hudi").load(s"$basePath/*")
119318 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
119328 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
hoodieROViewDF: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 9 more fields]
scala> hoodieROViewDF.createOrReplaceTempView("hudi_ro_view")
scala> spark.sql("SELECT * FROM hudi_ro_view").show()
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+--------+-----------+-------------------+---------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| id|role| role_cn|role_pinyin| tianfu|zhuangbei|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+--------+-----------+-------------------+---------+
| 20240528163634383|20240528163634383...| 4| zhuangbei=皮甲|1a0d1d0d-123a-414...| 4| dz| 盗贼| daozei| 狂徒|刺杀|敏锐| 皮甲|
| 20240528163634383|20240528163634383...| 5| zhuangbei=皮甲|1a0d1d0d-123a-414...| 5| ws| 武僧| wuseng| 酒仙|踏风|织雾| 皮甲|
| 20240528163634383|20240528163634383...| 6| zhuangbei=皮甲|1a0d1d0d-123a-414...| 6| xd| 德鲁伊| xiaode|恢复|平衡|野性|守护| 皮甲|
| 20240528163634383|20240528163634383...| 7| zhuangbei=皮甲|1a0d1d0d-123a-414...| 7| dh|恶魔猎手| emolieshou| 复仇|浩劫| 皮甲|
| 20240528163634383|20240528163634383...| 11| zhuangbei=板甲|1a0d1d0d-123a-414...| 11| dk|死亡骑士|siwangqishi| 鲜血|冰霜|邪恶| 板甲|
| 20240528163634383|20240528163634383...| 12| zhuangbei=板甲|1a0d1d0d-123a-414...| 12| zs| 战士| zhanshi| 武器|狂暴|防护| 板甲|
| 20240528163634383|20240528163634383...| 13| zhuangbei=板甲|1a0d1d0d-123a-414...| 13| sq| 圣骑士| shengqi| 神圣|防护|惩戒| 板甲|
| 20240528163634383|20240528163634383...| 8| zhuangbei=锁甲|1a0d1d0d-123a-414...| 8| lr| 猎人| lieren| 兽王|生存|射击| 锁甲|
| 20240528163634383|20240528163634383...| 9| zhuangbei=锁甲|1a0d1d0d-123a-414...| 9| sm| 萨满| saman| 恢复|增强|元素| 锁甲|
| 20240528163634383|20240528163634383...| 10| zhuangbei=锁甲|1a0d1d0d-123a-414...| 10|long| 龙人| longren| 湮灭|恩护|增辉| 锁甲|
| 20240528163634383|20240528163634383...| 1| zhuangbei=布甲|1a0d1d0d-123a-414...| 1| fs| 法师| fashi| 冰法|火法|奥法| 布甲|
| 20240528163634383|20240528163634383...| 2| zhuangbei=布甲|1a0d1d0d-123a-414...| 2| ms| 牧师| mushi| 神牧|戒律|暗牧| 布甲|
| 20240528163634383|20240528163634383...| 3| zhuangbei=布甲|1a0d1d0d-123a-414...| 3| ss| 术士| shushi| 毁灭|痛苦|恶魔| 布甲|
+-------------------+--------------------+------------------+----------------------+--------------------+---+----+--------+-----------+-------------------+---------+
对比原MySQL表结构,多了_hoodie_commit_time、_hoodie_commit_seqno、_hoodie_record_key、_hoodie_partition_path、_hoodie_file_name
- _hoodie_commit_time: 这个字段记录了最后一次数据提交的时间戳。每次写入操作(如插入、更新或删除)都会生成一个新的提交,这个时间戳就是该提交的记录时间。它对于数据恢复和理解数据的更新历史非常重要。
- _hoodie_commit_seqno: 这个字段包含了一个序列号,用于标识每个提交的顺序。序列号是按提交顺序递增的,它有助于确定不同提交之间的先后顺序,并且在处理增量数据时特别有用。
- _hoodie_record_key: 这是记录键(Record Key)的字段,通常是由表的主键或者由用户定义的某个唯一标识符生成的。在 Hudi 中,这个字段用于唯一标识一条记录,并且在数据去重、更新和删除操作中起到关键作用。
- _hoodie_partition_path: 这个字段表示记录所属的分区路径。在 Hudi 中,数据可以按照分区进行组织,每个分区对应文件系统中的一个目录。这个字段记录了记录所在的分区信息,有助于在查询时进行分区剪枝,提高查询效率。
- _hoodie_file_name: 这个字段包含了存储该记录的 Hudi 文件的文件名。在 Hudi 的文件组织结构中,每个提交都会生成新的数据文件,文件名通常包含了提交的时间戳和其他信息,有助于追踪数据的来源和版本。
这些字段是 Hudi 表的元数据的一部分,它们对于 Hudi 的数据管理、查询优化、增量处理等功能至关重要。在进行数据分析时,这些字段可以提供额外的信息,帮助用户更好地理解和操作数据。
关联上方的底层存储文件
可以看到文件名的fileId、instantTime其实就是对应着数据存储中的_hoodie_file_name、_hoodie_commit_time