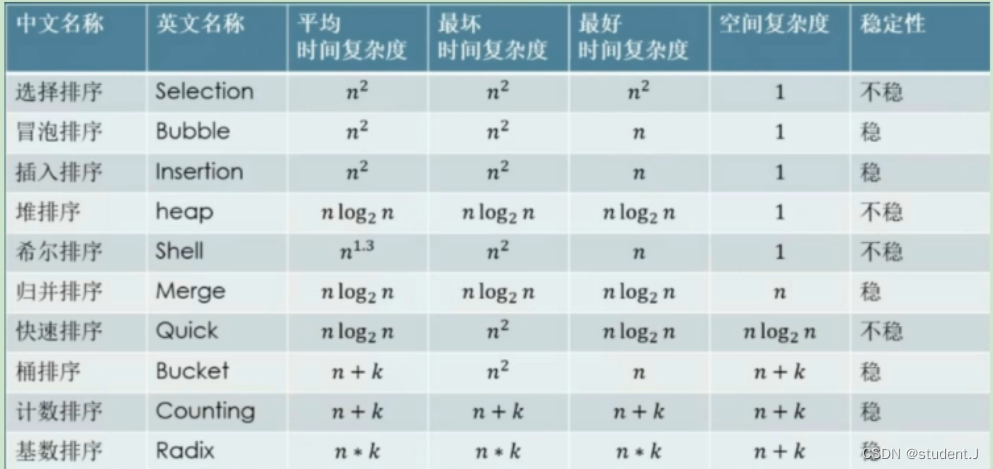
mat文件参数解读
Color_para:颜色参数,用于描述图像的颜色属性,比如图像的亮度、对比度等信息。
亮度属性、对比度属性、饱和度属性(颜色越鲜艳)、色调属性(色调越偏向蓝色)、色温属性(色温越高,色彩偏白)、色调偏移属性(颜色的相对变化程度)、标志位或者缩放因子
Exp_para:表情参数,用于描述人脸的表情状态,比如微笑、皱眉等。
Illum_para:光照参数,用于描述图像中的光照情况,比如光照强度、光照方向等。
Pose_Para:姿态参数,用于描述人脸的姿态,包括头部的旋转、倾斜等。
Pt2d:关键点参数,即关键点坐标,用于描述人脸上的关键点位置,比如眼睛、鼻子、嘴巴等。
roi:感兴趣区域参数,用于描述图像中感兴趣的区域,通常用矩形框来表示。
Shape_para:形状参数,用于描述人脸的形状特征,比如脸部的轮廓、轮廓曲线等。
Tex_para:纹理参数,用于描述人脸的纹理特征,比如肤色、皱纹等。
专有名词
Binned labels:离散化的标签,用于分类任务,通过将连续值映射到预定义的区间中获得。
bins = np.array(range(-99, 102, 3))
这里定义了一个从 -99 到 102 的数组,步长为 3,表示将范围 [-99, 102) 分成宽度为 3 的区间。
映射到离散区间:
binned_pose = np.digitize([yaw, pitch, roll], bins) - 1
np.digitize 函数用于将 yaw、pitch 和 roll 的连续值映射到上述定义的区间中。
- 1 的操作是为了将结果的索引从0开始。
示例:
假设 yaw = 10, pitch = -15, roll = 45,通过分箱后的结果 binned_pose 可能是 [36, 28, 48]。这里 36 表示 yaw 落在区间 [9, 12),28 表示 pitch 落在区间 [-18, -15),48 表示 roll 落在区间 [45, 48)。
用途:
这种离散化处理通常用于分类任务,因为分类模型需要离散的标签。比如在人脸姿态估计中,模型可以被训练来预测某个姿态角度落在哪个区间。
Continuous Labels
Continuous labels 指的是原始的连续数值标签,在你的代码中是指 yaw、pitch 和 roll 以度为单位的实际角度值。
具体操作:
获取连续标签:
cont_labels = torch.FloatTensor([yaw, pitch, roll])
这里 cont_labels 是一个包含 yaw、pitch 和 roll 的浮点数张量(Tensor)。
示例:
假设 yaw = 10, pitch = -15, roll = 45,则 cont_labels 的结果是 torch.FloatTensor([10, -15, 45])。
用途:
连续标签通常用于回归任务,因为回归模型需要预测的是连续数值。比如在姿态估计任务中,如果需要精确预测头部的角度,就需要使用连续标签进行训练和评估。
总结
Binned Labels:离散化的标签,用于分类任务,通过将连续值映射到预定义的区间中获得。
Continuous Labels:连续的原始标签,用于回归任务,直接使用原始的连续数值。
在你的代码中,最终返回了 img、labels(binned labels)、cont_labels(continuous labels)和 self.X_train[index]:
return img, labels, cont_labels, self.X_train[index]
这意味着模型可以同时使用离散化的标签进行分类训练,并且还可以使用连续的标签进行精确预测。
datasets所需要的300W_LP的Matlab文件中的所需要的元素有Pose_para与pt2d
pt2d = utils.get_pt2d_from_mat(mat_path)


pose = utils.get_ypr_from_mat(mat_path)

初步研究Pose_300W_LP datasets.py
1、打开图像:
使用PIL.Image库打开图像文件,并将其转换为指定的图像模式。
2、获取标注数据:
通过标注文件路径获取2D点坐标和姿势信息。
3、裁剪图像:
松散地裁剪脸部区域,计算裁剪边界时加入随机性以增强数据的多样性。
4、姿势角度转换:
将姿势信息从弧度转换为角度。
5、随机图像增强:
随机翻转图像以增加训练数据的多样性。
随机模糊图像以模拟图像模糊效果。
姿势值分箱:
将姿势角度进行分箱处理,以便进行分类任务。

返回结果:
返回处理后的图像、分箱后的标签、连续的姿势标签以及图像文件名。
问题1 k值怎么取
以下几点解释了为什么选择这个范围的k值是有道理的:
增强数据多样性:
在图像数据处理中,特别是在人脸检测和姿态估计任务中,增加数据的多样性可以有效提高模型的泛化能力。通过随机调整裁剪边界,可以生成各种不同的训练样本,帮助模型更好地适应不同的场景和条件。
适度随机扩展:
选择0.2到0.4的范围可以确保裁剪边界的扩展适度。太小的范围可能导致扩展不明显,无法显著增加数据多样性;而太大的范围可能导致裁剪区域包含过多背景信息,甚至丢失关键的脸部特征。
平衡背景和主体:
扩展裁剪边界时,适度的k值可以在包含足够背景信息的同时,仍然保持脸部作为主体。这有助于模型在学习时能够识别脸部特征和背景特征之间的关系,而不会被过多的背景信息干扰。
防止过拟合:
通过引入随机性,模型可以在训练过程中看到更广泛的输入变化,这有助于减少过拟合。在实际应用中,测试数据的分布可能与训练数据有所不同,通过这种随机裁剪可以使模型更具鲁棒性。
实验验证:
选择0.2到0.4的范围可能是基于实验验证得出的经验值。在实际操作中,数据科学家和工程师们通常会通过一系列实验来确定最优的参数范围,以达到最佳的模型性能。
综上所述,k值在0.2到0.4之间的选择是一种折中的方案,既能有效增加训练数据的多样性,又能保持裁剪后图像的有效性,从而有助于提高模型的性能和鲁棒性。
def __getitem__(self, index):
# 打开图像文件
img = Image.open(os.path.join(self.data_dir, self.X_train[index] + self.img_ext))
img = img.convert(self.image_mode)
# 获取标注文件路径
mat_path = os.path.join(self.data_dir, self.y_train[index] + self.annot_ext)
# 松散地裁剪脸部区域
pt2d = utils.get_pt2d_from_mat(mat_path)
x_min = min(pt2d[0,:])
y_min = min(pt2d[1,:])
x_max = max(pt2d[0,:])
y_max = max(pt2d[1,:])
# k = 0.2 到 0.40 之间的随机值
k = np.random.random_sample() * 0.2 + 0.2
x_min -= 0.6 * k * abs(x_max - x_min)
y_min -= 2 * k * abs(y_max - y_min)
x_max += 0.6 * k * abs(x_max - x_min)
y_max += 0.6 * k * abs(y_max - y_min)
img = img.crop((int(x_min), int(y_min), int(x_max), int(y_max)))
# 获取以弧度表示的姿势
pose = utils.get_ypr_from_mat(mat_path)
# 转换为角度
pitch = pose[0] * 180 / np.pi
yaw = pose[1] * 180 / np.pi
roll = pose[2] * 180 / np.pi
# 随机翻转图像
rnd = np.random.random_sample()
if rnd < 0.5:
yaw = -yaw
roll = -roll
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 随机模糊图像
rnd = np.random.random_sample()
if rnd < 0.05:
img = img.filter(ImageFilter.BLUR)
# 将值分箱
bins = np.array(range(-99, 102, 3))
binned_pose = np.digitize([yaw, pitch, roll], bins) - 1
# 获取目标张量
labels = binned_pose
cont_labels = torch.FloatTensor([yaw, pitch, roll])
# 应用变换
if self.transform is not None:
img = self.transform(img)
return img, labels, cont_labels, self.X_train[index]