目录
- mapping是什么
- 动态mapping
- 默认动态mapping
- 设计自己的mapping检测模板
- 运行时字段
- dynamic
参考ES 7版本官方文档
官方7.17文档
挑了一些我觉得重要的点总结
如有谬误,欢迎指正
mapping是什么
在ES里创建一个索引
PUT demo_index
{
"mappings": {
"dynamic": false
"properties": {
"demo_id": {
"type": "text"
}
}
}
}
上面的properties里定义了字段demo_id,它的类型是text。dynamic选择了false说明mapping不需要动态规则来匹配,这种情况下进行搜索时和普通的关系型数据库搜索非常类似。
mapping类似于数据库中的表结构定义,定义以下这些内容
- 定义字段名称
- 定义字段数据类型
- 字段、倒排索引的相关配置
但是和比如mysql这样的数据相比还是有很多不同之处,搜索的字段类型可以提前定义好,也可以不定义让ES来推测,也可在搜索的时候动态加入新字段。
GET /demo_index/_mapping
查看mapping
动态mapping
如果你想使用动态mapping就将上面提到的dynamic字段设置为true或者runtime
默认动态mapping
ES允许直接插入文档,不需要提前定义类型、字段 ,当你查询的时候会自动推测匹配显示出来。
curl -X PUT "localhost:9200/data/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{ "count": 5 }
使用kibana的话直接PUT data/_doc/1 … 就行
自动检测类型和添加字段就是动态mapping,ES有默认的检测规则,我们自己也可以定义自己的规则。
设计自己的mapping检测模板
这一块比较复杂
match_mapping_type
这个可以理解为根据字段默认检测出来的类型进行匹配
用的官方文档的案例:
可以看到当默认检测出来的字段类型为integer时,将替换为long类型;如果检测出来的类型为text或者keyword类型,将会替换为string类型。
PUT demo_index
{
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}
这张图是在默认检测下,从Json解析出来的数据类型和ES里的数据的对应关系。需要注意的是dynamic字段设置为true和runtime的对应关系是略有不同的。
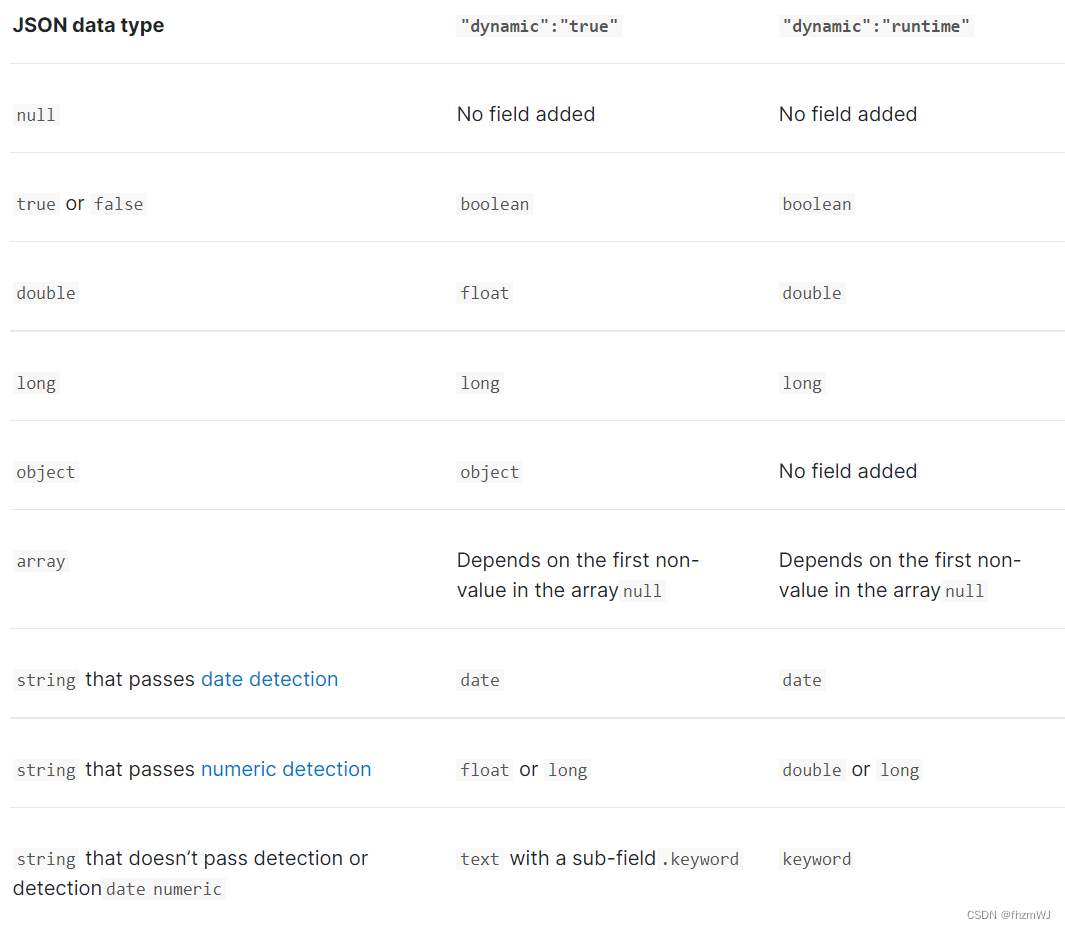
math/unmatch
根据字段名称去匹配字段类型
如下,如果JSON解析出来的字段匹配long_*并且不匹配*_text,并且默认检测出来的类型是long,那么将其匹配为string类型。
PUT demo-index
{
"mappings": {
"dynamic_templates": [
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "long_*",
"unmatch": "*_text",
"mapping": {
"type": "long"
}
}
}
]
}
}
除了使用简单的通配符来进行匹配之外,还可以使用正则表达式:
"match_pattern": "regex",
"match": "^profit_\d+$"
path_match/path_unmatch
这个是根据字段路径匹配,我理解是用于匹配多层级的对象。
这里产生的效果就是name对象去掉middle字段。
PUT demo-index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
PUT demo-index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
官方文档里的这个案例,还使用了copy_to,copy_to可以将值复制到另一个字段里,是一个很实用的功能。
运行时字段
可以在mapping下设置runtime部分,使用script脚本来控制动态字段。
脚本可以访问整个文档,包括原始_source和mapping字段,脚本会查询所有所需字段的值。
PUT demo-index/
{
"mappings": {
"runtime": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
},
"properties": {
"@timestamp": {"type": "date"}
}
}
}
运行时字段在搜索时不会出现在_source里,但是会有这个field,搜索时可以指定这个字段将其值搜索出来
>GET demo-index/_search
{
"fields" : ["day_of_week"],
"query": {
"match": {
...
}
}
}
动态值就会显示在查询结果的hits里的每个hit的fields里
在某些情况下这个功能可以省去reindex, 比如发现mapping里某字段希望修改它的数据类型,或者希望某些字段可以有另外的一种形式,在mapping中不太方便修改,方案可以有进行reindex,但是也可以通过这种动态形式拿到想获取的值(读时建模)。
当设置dynamic字段为runtime时,
PUT demo-index
{
"mappings": {
"dynamic": "runtime",
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
检测到的新字段会自动加入到mapping的fields作为运行时字段。
也可以随时更新或删除运行时字段。要替换现有的运行时字段,在具有相同名称的映射中添加一个新的运行时字段。设置null就可以删除。
PUT demo-index/_mapping
{
"runtime": {
"day_of_week": null
}
}
dynamic
dynamic用于控制是否动态添加新字段,可选项有:
- true:新字段添加到mapping中(默认)。
- runtime:新字段作为运行时字段添加到mapping中,这些字段不可索引,是_source在查询时加载的。
- false:忽略新字段,这些字段不会被索引或搜索,但仍会出现在_source返回的命令和字段中。这些字段不会添加到mapping中,必须显式添加新字段。
- strict:如果检测到新字段,则会抛出异常。必须将新字段显式添加到mapping中。
动态模式 (true)通俗来说就是往index里写入doc,doc里的字段类型对应es里的什么数据类型,将会由默认推测规则来进行自动推测匹配(当然也可以自义定推测规则)。
不需要动态模式(false)的时候,可以按照自己的实际需求去设置mapping,插入doc的时候,字段与mapping里的保持一致,如果doc添加了一个mapping里不存在的字段,新字段不会被自动添加到mapping中,并且指定该字段进行查询时,也无法匹配到结果,可以存储、但是不能索引。
当dynamic设置为false时,显式设置mapping,类似于关系型数据库

![[前端笔记——多媒体与嵌入] 6.HTML 中的图片+视频+音频内容](https://img-blog.csdnimg.cn/c73f87cb32184953a037aed343ce86d2.png)

![[ 华为云 ] 云计算中Region、VPC、AZ 是什么,他们又是什么关系,应该如何抉择](https://img-blog.csdnimg.cn/03464fd9653e40428be191d8d7eaca9f.png)