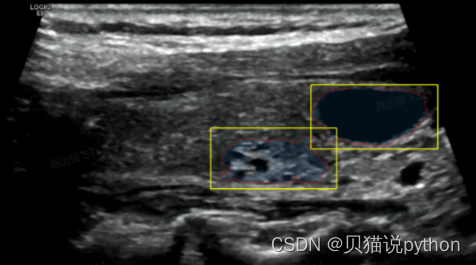
1、输入每张图片的多个检测框,得到这张图片的sam 分割结果
import numpy as np
import matplotlib.pyplot as plt
import os
join = os.path.join
import torch
from segment_anything import sam_model_registry
from skimage import io, transform
import torch.nn.functional as F
import argparse
@torch.no_grad()
def medsam_inference(medsam_model, img_embed, box_1024, H, W):
box_torch = torch.as_tensor(box_1024, dtype=torch.float, device=img_embed.device)
if len(box_torch.shape) == 2:
box_torch = box_torch[:, None, :] # (B, 1, 4)
sparse_embeddings, dense_embeddings = medsam_model.prompt_encoder(
points=None,
boxes=box_torch,
masks=None,
)
low_res_logits, _ = medsam_model.mask_decoder(
image_embeddings=img_embed, # (B, 256, 64, 64)
image_pe=medsam_model.prompt_encoder.get_dense_pe(), # (1, 256, 64, 64)
sparse_prompt_embeddings=sparse_embeddings, # (B, 2, 256)
dense_prompt_embeddings=dense_embeddings, # (B, 256, 64, 64)
multimask_output=False,
)
low_res_pred = torch.sigmoid(low_res_logits) # (1, 1, 256, 256)
low_res_pred = F.interpolate(
low_res_pred,
size=(H, W),
mode="bilinear",
align_corners=False,
) # (1, 1, gt.shape)
low_res_pred = low_res_pred.squeeze().cpu().numpy() # (256, 256)
medsam_seg = (low_res_pred > 0.5).astype(np.uint8)
return medsam_seg
# %% load model and image
parser = argparse.ArgumentParser(
description="run inference on testing set based on MedSAM"
)
parser.add_argument(
"-i",
"--data_path",
type=str,
default="assets/img_demo.png",
help="path to the data folder",
)
parser.add_argument(
"-o",
"--seg_path",
type=str,
default="assets/",
help="path to the segmentation folder",
)
parser.add_argument(
"--box",
type=list,
default=[95, 255, 190, 350],
help="bounding box of the segmentation target",
)
parser.add_argument("--device", type=str, default="cuda:0", help="device")
parser.add_argument(
"-chk",
"--checkpoint",
type=str,
default="work_dir/MedSAM/medsam_vit_b.pth",
# default="/home/syy/code/sam/MedSAM-LiteMedSAM/carotid_MedSAM-Lite-Box-20240508-1808/medsam_lite_best1.pth",
help="path to the trained model",
)
args = parser.parse_args()
device = args.device
medsam_model = sam_model_registry["vit_b"](checkpoint=args.checkpoint)
medsam_model = medsam_model.to(device)
medsam_model.eval()
print("=====================================> 模型加载完毕")
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
import sys
import os
import random
import os
import xml.etree.ElementTree as ET
import cv2
def parse_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
image_name = root.find('filename').text
boxes = []
labels = []
for obj in root.findall('object'):
label = obj.find('name').text
bbox = obj.find('bndbox')
x1 = int(bbox.find('xmin').text)
y1 = int(bbox.find('ymin').text)
x2 = int(bbox.find('xmax').text)
y2 = int(bbox.find('ymax').text)
boxes.append((x1, y1, x2, y2))
labels.append(label)
return image_name, boxes, labels
def process_xmls(xmls_dir):
results = []
xml_lists = os.listdir(xmls_dir)
xml_lists.sort()
for xml_file in xml_lists[0:200]:
if xml_file.endswith('.xml'):
xml_path = os.path.join(xmls_dir, xml_file)
result = parse_xml(xml_path)
results.append(result)
return results
def show_mask(mask, ax, random_color=False):
# mask 模型预测的分割图 0,1 目标和背景
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.1]) #透明度0.3
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1) #将掩码和颜色相乘,得到最终的带有颜色的掩码图像
ax.imshow(mask_image) # 不显示mask区域
#########################################
# 找到掩码的轮廓
contours, _ = cv2.findContours((mask * 255).astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 对最大的轮廓进行逼近处理,减少轮廓点的数量
reduction_factor = 0.002 #0 #0.005
if contours: #没有会返回空
areas = [cv2.contourArea(cnt) for cnt in contours]
# 找到最大面积的轮廓的索引
max_area_index = np.argmax(areas)
# 获取最大面积的轮廓
largest_contour = contours[max_area_index]
# 对每个轮廓进行逼近处理,减少轮廓
if reduction_factor > 0.000001:
epsilon = reduction_factor * cv2.arcLength(largest_contour, True)
approx = cv2.approxPolyDP(largest_contour, epsilon, True) # 最大轮廓的操作,平滑轮廓点
# 绘制轮廓,减少的点,平滑的不是很好,换一个
print("点有没有减少,len(approx),len(contours)",len(approx),len(largest_contour))
ax.plot(approx[:, 0, 0], approx[:, 0, 1], color='red', linewidth=1)
else:
ax.plot(largest_contour[:, 0, 0], largest_contour[:, 0, 1], color='red', linewidth=0.3)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='yellow', facecolor=(0,0,0,0), lw=1))
def prompt_box_pred(xmls_dir,imgs_dir,save_dir):
# 示例用法
results = process_xmls(xmls_dir)
for ind, res in enumerate(results):
image_name, boxes, labels = res
print(ind,': Image:', image_name)
# 读取图片和xml 文件,获取坐标
img_path = os.path.join(imgs_dir,image_name)
# image = cv2.imread(img_path)
# if image is None:
# print("=======================> 图片路径不存在",img_path)
# continue
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# image_height, image_width = image.shape[:2]
img_np = io.imread(img_path)
if len(img_np.shape) == 2:
img_3c = np.repeat(img_np[:, :, None], 3, axis=-1)
else:
img_3c = img_np
H, W, _ = img_3c.shape
# %% image preprocessing
img_1024 = transform.resize(
img_3c, (1024, 1024), order=3, preserve_range=True, anti_aliasing=True
).astype(np.uint8)
img_1024 = (img_1024 - img_1024.min()) / np.clip(
img_1024.max() - img_1024.min(), a_min=1e-8, a_max=None
) # normalize to [0, 1], (H, W, 3)
# convert the shape to (3, H, W)
img_1024_tensor = (
torch.tensor(img_1024).float().permute(2, 0, 1).unsqueeze(0).to(device)
)
plt.figure(figsize=(10, 10)) #画布的大小
plt.imshow(img_3c)
for box, label in zip(boxes, labels):
x1, y1, x2, y2 = box
print(' Label:', label)
print(' Box:', x1, y1, x2, y2)
input_box = np.array(box)
box_np = np.array([box])
# transfer box_np t0 1024x1024 scale
box_1024 = box_np / np.array([W, H, W, H]) * 1024
# 预测图片的分割标签
with torch.no_grad():
image_embedding = medsam_model.image_encoder(img_1024_tensor) # (1, 256, 64, 64)
medsam_seg = medsam_inference(medsam_model, image_embedding, box_1024, H, W) #分割最后输出原图大小
# print(medsam_seg.shape) #(127, 212)
# print(img_3c.shape) # (127, 212, 3)
show_mask(medsam_seg, plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
# plt.show()
### bbox_inches='tight'表示将图像边缘紧贴画布边缘,pad_inches=0表示不添加额外的边距
plt.savefig(save_dir + image_name,bbox_inches='tight', pad_inches=0) #) # 一张图保存多个框
if __name__ == "__main__":
xmls_dir = '/home/syy/data/甲乳/breast/image2/xmls'
imgs_dir = '/home/syy/data/甲乳/breast/image2/images'
save_dir = "/home/syy/data/甲乳/breast/image2/medsam/"
os.makedirs(save_dir,exist_ok=True)
prompt_box_pred(xmls_dir,imgs_dir,save_dir)