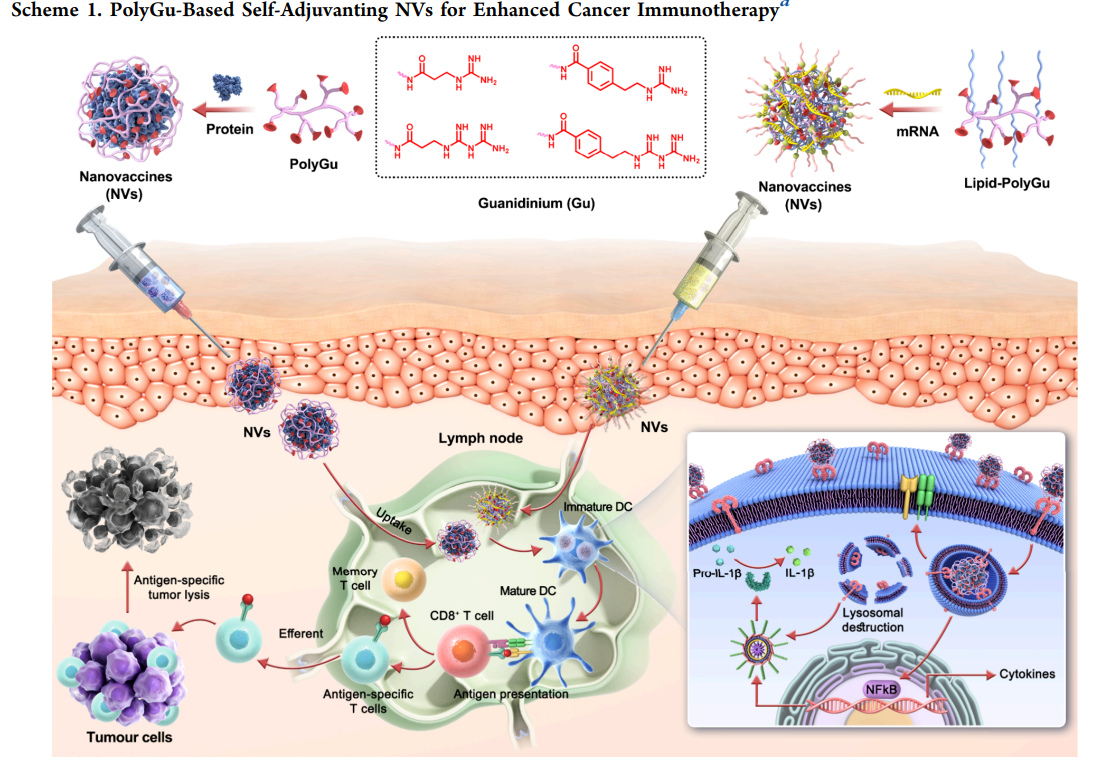
动态规划(Dynamic Programming,DP)是运筹学的一个分支,主要用于解决包含重叠子问题和最优子结构性质的问题。它的核心思想是将一个复杂的问题分解为若干个子问题,并保存子问题的解,以便在需要时直接利用,从而避免重复计算,提高算法效率。
原理:
- 动态规划算法将一个复杂的问题分解为若干个子问题,并保存每个子问题的解。当需要求解某个子问题时,如果之前已经求解过,则可以直接利用之前的解,从而避免重复计算。
- 通过求解子问题的最优解来获得原问题的最优解。子问题的解通常存储在表格中,表格的行和列代表问题的不同阶段和状态。
基本步骤:
- 确定状态:首先,需要明确问题的状态表示。状态通常是与问题求解相关的变量的集合,它们的变化描述了问题的进展。
- 状态转移方程:找到子问题之间的关系,并建立状态转移方程。状态转移方程描述了从一个状态转移到另一个状态所需的条件和结果。
- 初始化边界条件:确定基本情况的解,为后续的状态转移提供依据。这通常涉及确定初始状态和某些特殊情况下的解。
- 逐步推导:根据状态转移方程,从小规模问题开始逐步推导,直到求解出原问题的最优解。
应用场景:
- 动态规划算法适用于具有重叠子问题和最优子结构性质的问题。例如,背包问题、生产经营问题、资金管理问题、资源分配问题、最短路径问题等。
- 在实际应用中,动态规划算法的效率通常比其他算法设计思想更高,特别是在问题规模较大的情况下。
实现方式:
- 动态规划算法可以用多种编程语言实现,如C++、Python等。实现时,需要定义一个表格来存储子问题的解,并根据状态转移方程逐步推导原问题的解。
- 递推关系是从次小的问题开始到较大的问题之间的转化,因此动态规划往往可以用递归程序来实现。但由于递推可以充分利用前面保存的子问题的解来减少重复计算,所以对于大规模问题来说,有递归不可比拟的优势。
三要素:
- 在确定动态规划算法时,最重要的是确定三个要素:问题的阶段、每个阶段的状态以及从前一个阶段转化到后一个阶段之间的递推关系。这三个要素共同构成了动态规划算法的基本框架。
背包问题实例
假设有一个背包,容量为V,现有n个物品,每个物品的重量为wi,价值为vi。要求在不超过背包容量的前提下,选取一些物品放入背包,使得背包中的物品总价值最大。
确定状态
首先我们的理解什么 是状态,状态被定义为:与问题求解相关的变量集合,描述了问题的进展。这是什么意思呢?
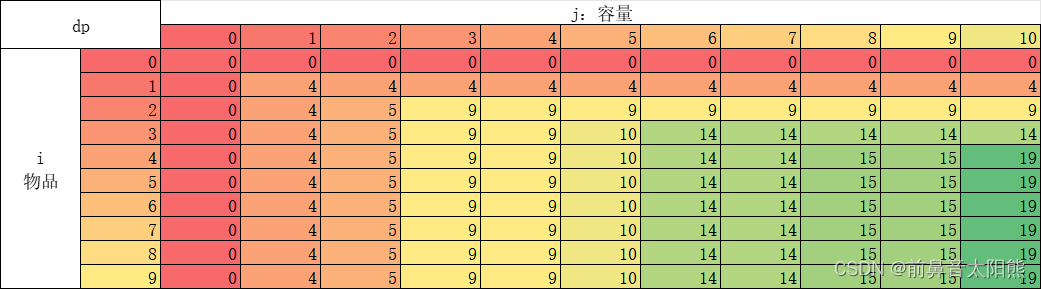
状态通常定义为一个二维数组 dp[i][j],其中 i 表示前 i 个物品,j 表示背包的容量为 j。dp[i][j] 表示在前 i 个物品中选择一些物品放入容量为 j 的背包中所能获得的最大价值。
这就是状态,状态就是某一时刻个体或系统的特定情况,而程序要做的就是用合适的数据结构来表示这种情况。我们可以画一个图:

当背包里有前3个物品时的状态:d[3][10] = 14,即放前三个物品在容量为10的包里,容量之和小于10,所以都能放下: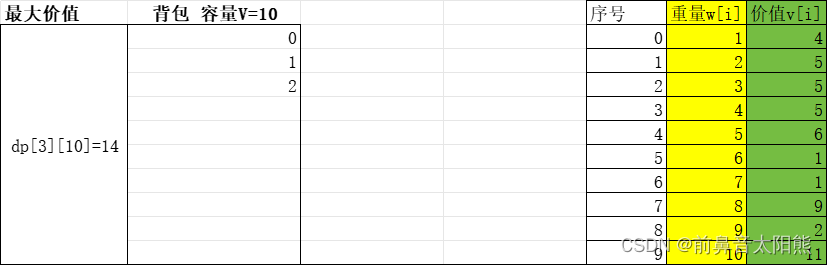
状态转移方程
状态转移就是个体或者系统从一个前续状态通过什么方式或过程转变为后续状态
对于第 i 个物品,我们有两种选择:
- 不选择第 i 个物品,那么 dp[i][j] 的值就等于 dp[i-1][j],即前 i-1个物品在容量为 j 的背包中的最大价值。
- 选择第 i 个物品,那么 dp[i][j] 的值就等于 dp[i-1][j-w[i]] + v[i],其中 w[i] 是第 i 个物品的重量,v[i] 是第 i 个物品的价值。这表示在选择了第 i 个物品后,背包的剩余容量是j-w[i],我们需要从前 i-1 个物品中选择一些物品放入这个剩余容量的背包中,以获得最大的价值。
综合以上两种选择,我们得到状态转移方程:
dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[i]] + v[i])
注意:当 j < w[i] 时,无法选择第 i 个物品,因此 dp[i][j] 的值只能等于 dp[i-1][j]。
简单来说,就是不断的选择和组合,如果还有空间,那么就把新物体放进来,并判断新放入的物体的价值与未放入时的价值哪个大,取大的值:
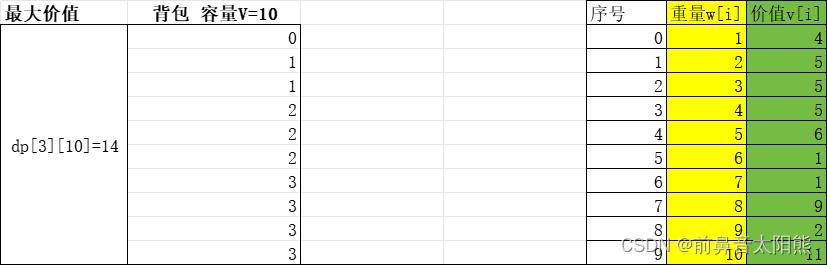
上面的图是做示例,实际代码运算的过程并不是这样,上面的图大家看到容量已被沾满,但是价值并没有最大,那是因为我们只是按顺序放入,但并不是每一步都求解了最大价值。后面 大家看代再结合这个图来理解。
初始化边界条件
- 当没有物品可选时(即 i = 0),无论背包容量 j 为多少,背包中的价值都为0,即 dp[0][j] = 0。
- 当背包容量为0时(即 j= 0),无法放入任何物品,因此无论有多少物品可选,背包中的价值都为0,即dp[i][0] = 0。
这就是边界条件,边界条件是确定状态的范围。
最终我们得出的结果是:

代码实现
上代码:
/**
* 动态规划求解背包问题
* @param weights 重量
* @param values 价值
* @param v 背包容量
* @return
*/
public static int cal(int[] weights,int[] values,int v){
int iMax = weights.length;
int jMax = v;
//初始化二位数组 作为存储结果的矩阵
int[][] dp = new int[iMax + 1][jMax + 1];
for (int i = 1; i < iMax + 1; i++) {
for (int j = 1; j < jMax + 1 ; j++) {
if(weights[i-1] <= j){
//空间足够
dp[i][j] = Math.max(dp[i-1][j],dp[i-1][j-weights[i-1]]+values[i-1]);
}else{
//空间不够
dp[i][j] = dp[i-1][j];
}
}
}
//返回矩阵右下角的值,即为最终结果
return dp[iMax][jMax];
}
上面就是代码实现,当然数据量大之后还要优化性能。代码很简洁,对吗?
是的,就是这么简单,但是理解起来可能对很多人是有困难的,这个时候大家可以自己画图,同时结合debug去跟代码,这样就能很好的去理解原理了,上一个辅助理解的图(其实就是个二维矩阵):