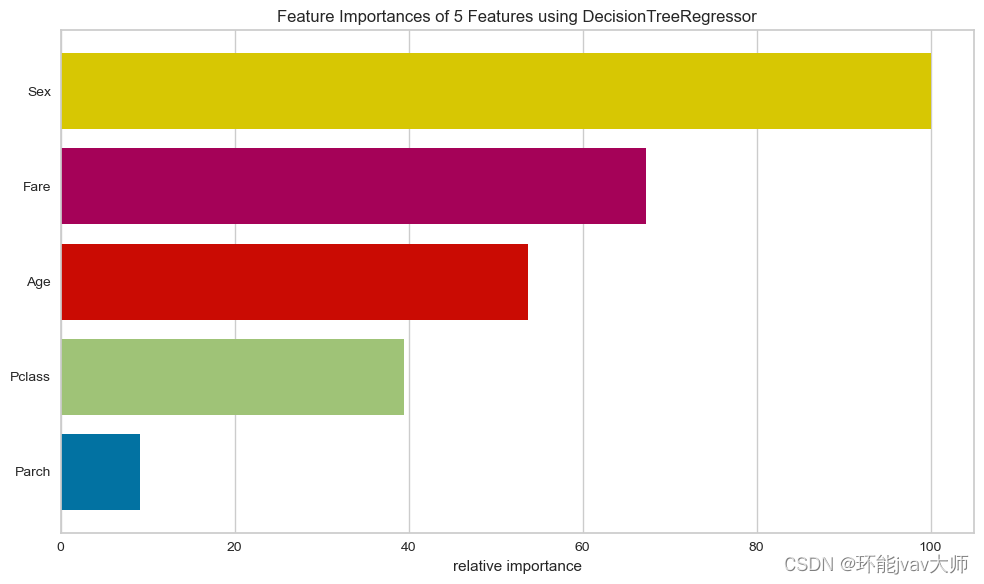
torch.Tensor.scatter 有 4 个参数:
scatter(dim, index, src, reduce=None)先忽略 Reduce,最后再解释。先从最简单的开始。我们有一个 (2,4) 形状的张量,里面填充了 1:
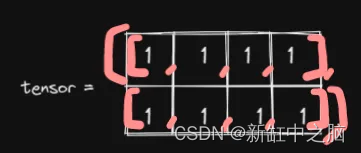
粉红色的符号表示张量结构
并且我们传入相应的参数并得到输出:
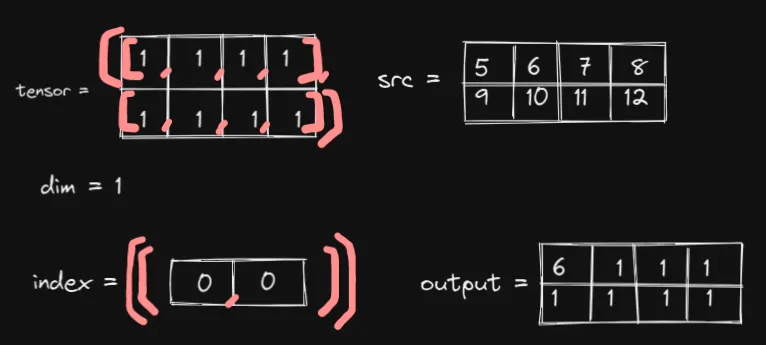
注意index张量结构
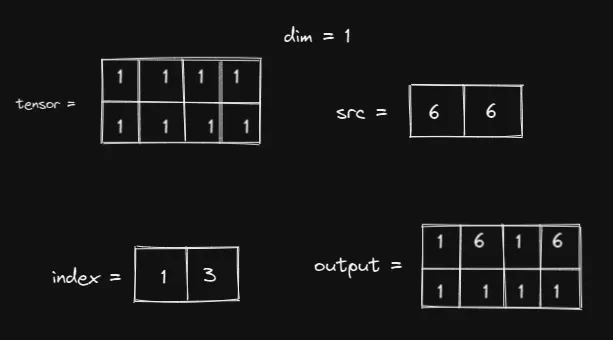
现在我们增加index张量的第二个值,并比较输出:
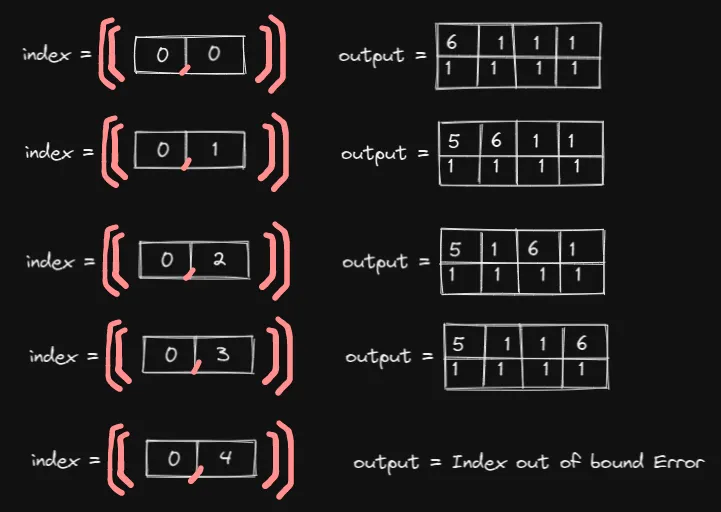
观察数字 6 在output张量中的移动情况
好的,数字 6 由index张量内的第二个值控制。但是,如何控制呢?
以下是幕后发生的事情。
首先,我们将index形状扩展为与 src 相同的形状:
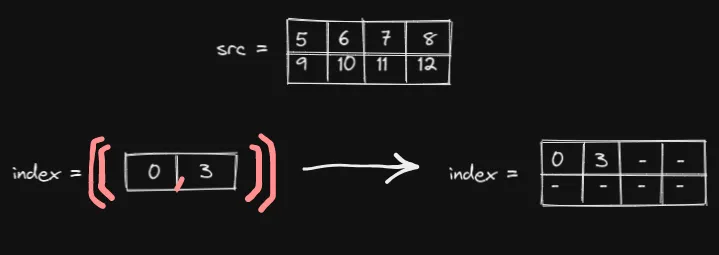
它实际上不需要扩展。但这将有助于我们理解
如果 index 中有值,则从 src 中提取相应的值。
如果没有值,则不执行任何操作。
这里有 0 和 3,因此提取 5 和 6:
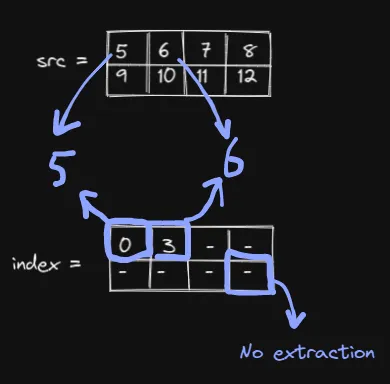
这意味着index的结构必须是 src 的子结构。否则,你将收到错误:
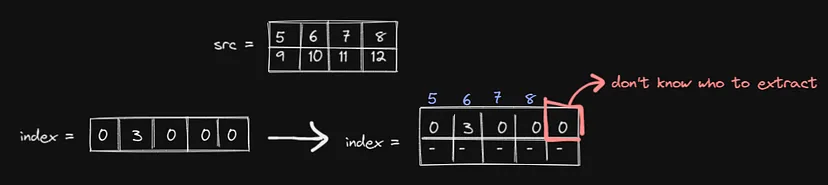
蓝色数字是提取的数字
你可以从官方文档中找到此属性的介绍:
# scatter
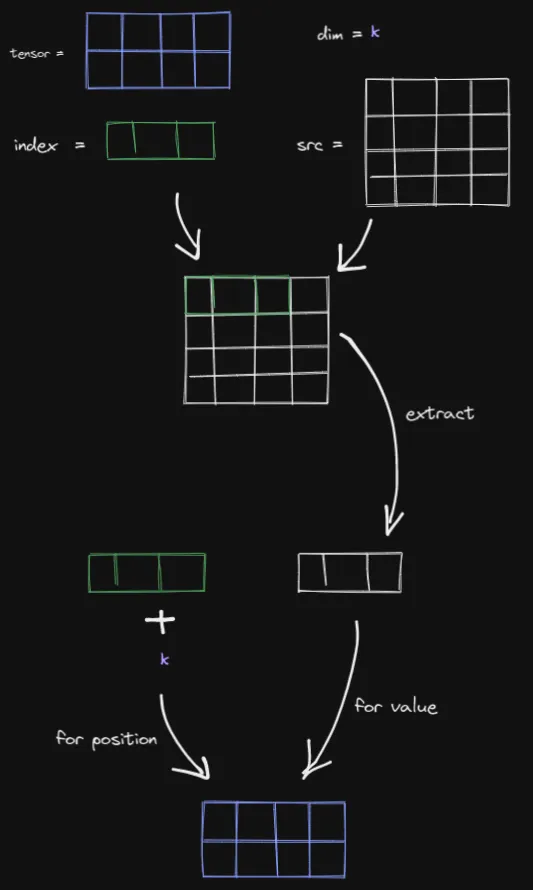
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2请注意, [i][j][k] 用于对 index 和 src 进行切片。
现在,回到原始示例,我们提取了 5 和 6。5 和 6 放在哪里?答案是:0 和 3。
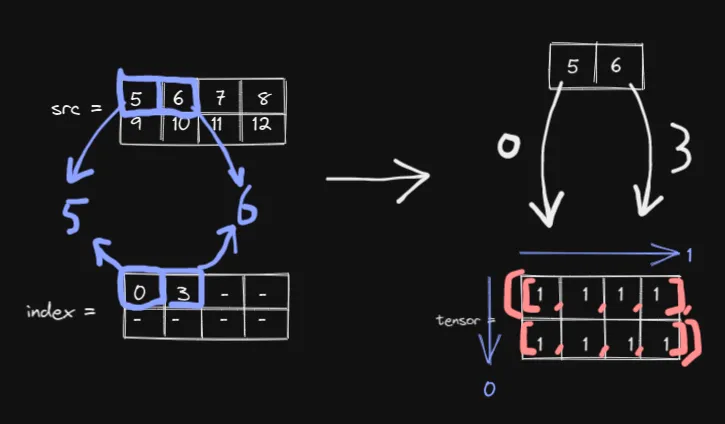
将 5 放到 0,将 6 放到 3
“放入 0” 和 “放入 3” 是什么意思? dim 参数会告诉我们。 在我们的例子中, dim=1 , 表示索引将用于切分张量的列,即上图中的蓝色箭头。
那么行呢? 与 5 和 6 相同:
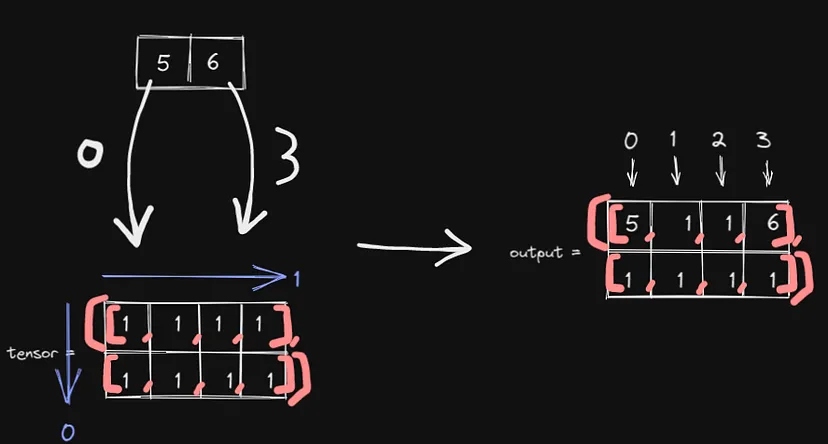
你可以这样想:
- 我们从 src 中得到 5 和 6。
- 5 在 src 中的位置为 (0,0)。6 在 src 中的位置为 (0,1)。
- dim=1 ,因此将使用 0 和 3 分别替换 (0,0) 和 (0,1) 的“第零”值。
- 将 5 的 (0,0) 替换为 (0,0)。将 6 的 (0,1) 替换为 (0,3)。
- 5 在 tensor 中的位置为 (0,0)。6 在 tensor 中的位置为 (0,3)。
- tensor[0][0] = src[0][0] , tensor[0][3] = src[0][1]
因此,你可以想象为什么当索引为 [[0,0]] 时我们只得到一个 6。该单元格更新了两次,从 1 到 5,从 5 到 6:
tensor[0][0] = src[0][0] , tensor[0][0] = src[0][1]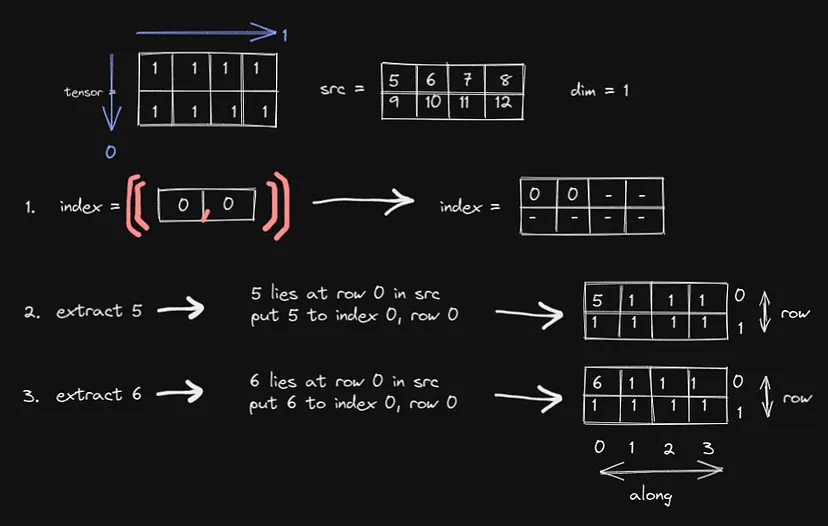
如果 dim=0 会怎么样?我们来试试。
- 我们从 src 中得到 5 和 6。
- 5 在 src 中的位置为 (0,0)。6 在 src 中的位置为 (0,1)。
- dim=0,因此 0 和 3(来自索引)将分别用于替换 (0,0) 和 (0,1) 的“第零”值。
- 将 5 的 (0,0) 替换为 (0,0)。将 6 的 (0,1) 替换为 (3,1)。
- 5 在张量中位于 (0,0)。6 在张量中位于 (3,1)。
- tensor[0][0] = src[0][0] , tensor[3][1] = src[0][1]
- tensor[3][1] 出现越界错误。
看下面的图,提取的箭头解释了它是如何工作的。
1、逆向思维
现在逆向思考,我们只有输入和输出,我们如何设置参数才能得到想要的结果?
这是我们的input张量:
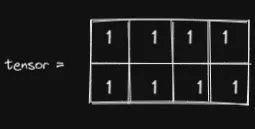
我们希望通过调用 scatter 方法获得以下output张量:
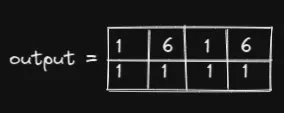
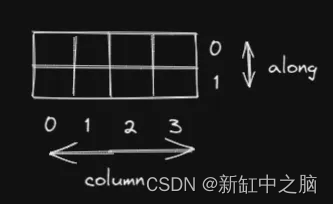
如果 dim=0,我们将沿行方向切片:
输出中的两个 6 来自 src,它们是根据索引中的非空值提取的。因此,src 需要至少包含两个 6:
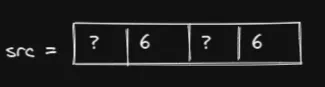
并且index至少应为:

我们不能将 ? 在index中留空,它们必须是一个值。我们现在只有两个选项:0 和 1,因为输入张量只有两行。如果我们将 ? 放入 src 中,则得到:
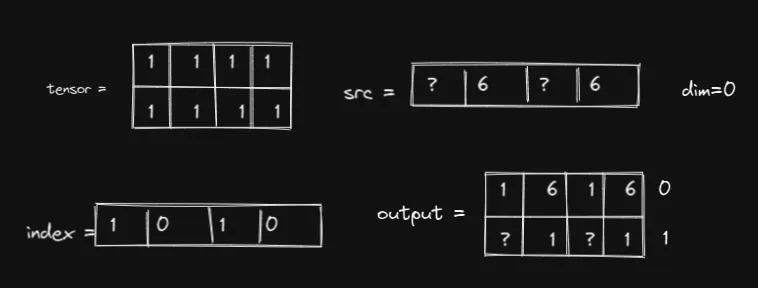
如果我们放入 0,我们会得到:
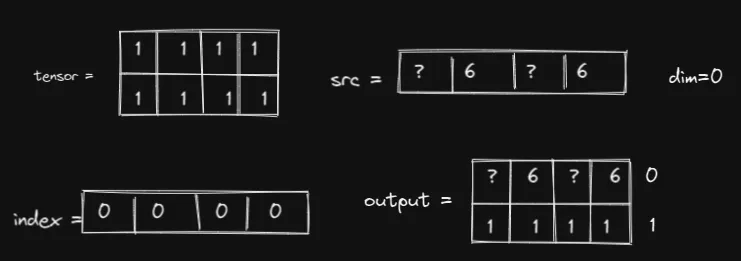
在这两种情况下,src 中的 ? 必须为 1,否则我们将无法获得所需的输出。
如果 dim=1,且输入和输出相同,会怎么样?
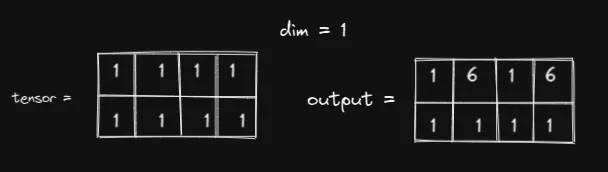
我们沿着列进行切片,因此index内的值可以从 0 到 3 变化。我们想要将输入的第 1 列和第 3 列更改为 6,因此index和 src 应该是:
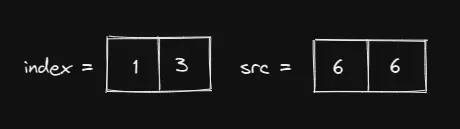
看!多么优雅啊!与 dim=0 的情况相比,这是一个更好的选择。我们不需要将 1 填入 src。
通常,选择一种让我们的参数依赖于输出值的方法不是一个好主意,dim=1 不会使用这种情况。
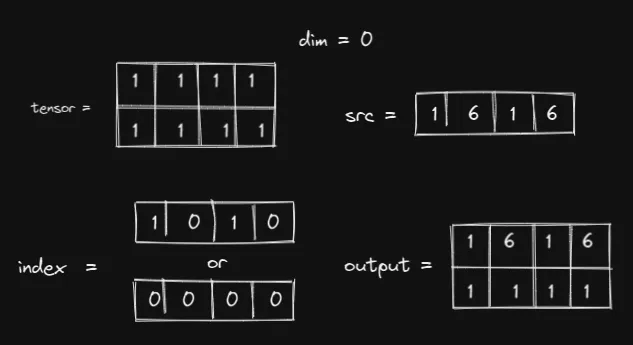
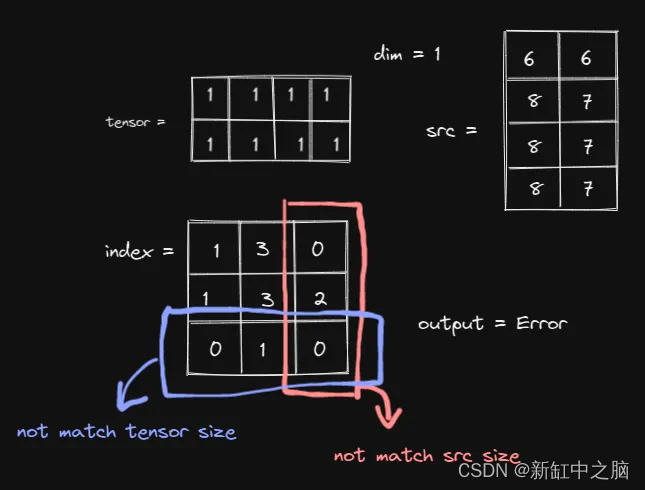
回想一下,index和 src 之间的关系是提取。PyTorch 将根据索引的结构从 src 中提取值。这意味着,src 有多大并不重要,只要 PyTorch 可以从中提取值即可。也就是说,以下选择也有效:
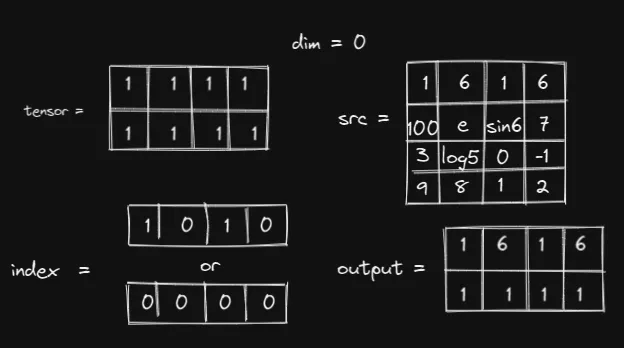
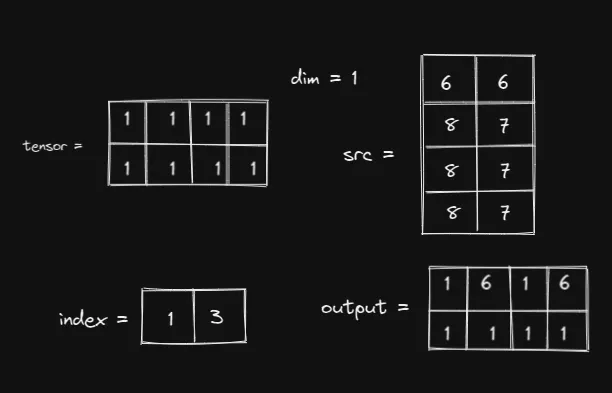
只有当索引太大时才会出现错误。
2、Reduce
终于到了最后一部分,reduce 参数有三个选项:None、add、multiply,如果是 add,赋值就会变成 add and replace,如果是 multiply,赋值就会变成 multiply and replace,很简单很容易理解吧?
原文链接:torch.scatter 深入理解 - BimAnt