2024年2月16日,OpenAI发布视频生成AI大模型Sora。消息一经发出,业界再一次被之震撼。
OpenAI官网描述:Sora是一个根据文本指令生成真实与虚拟场景的AI模型,可根据用户指令生成时长达1分钟的高清视频,能生成具有多个角色、包含特定运动的复杂场景,即能够理解和模拟运动中的物理世界。
过去的一年,伴随ChatGPT及GPTs的热潮,文生图、文生视频和图生视频等各类产品也相继涌现。为何Sora一经发出,如同ChatGPT一般又一次掀起了浪花?
一 性能表现
与其它文生视频产品相比,能生成时长达60s的具有连贯性以及人物、场景长期一致性的视频,是Sora的显著优势。
要知道,此前的1月24日和2月15日,谷歌研究人员分别公布了视频生成模型Lumiere和Gemini 1.5的演示视频。前者可生成画质非常高清的真实图片,并且可实现一键换装以及根据图片和提示词生成动态视频,后者在图像识别、多轮对话方面表现出惊人的逆天能力。然而,不曾想,仅仅是十天后,Sora的悄然问世,便立即抢走了Lumiere和Gemini 1.5的风头。究其原因,主要还是看产品的整体性能表现。
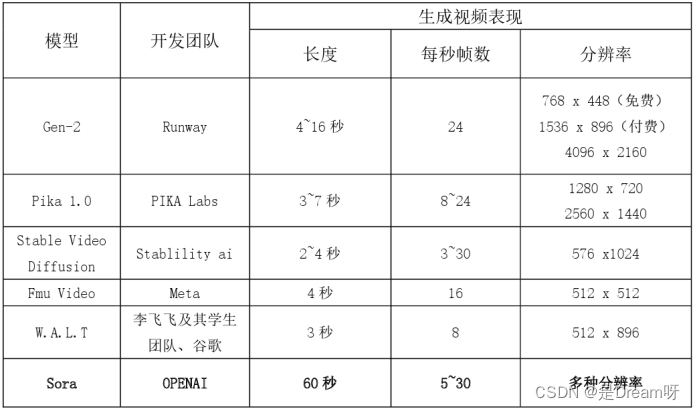
尽管Lumiere和Gemini 1.5已经足够惊艳,但在生成视频的时长和连贯性方面并未未有突破性进展(生成视频的时长仅限于5s)。同样地,其它同类产品,如Runway、Pika等,都还在突破几秒内的连贯性(连贯性极其影响视频的真实性)。而Sora可以直接生成长达60s、每秒帧数可达30FPS的视频,在生成时长和连贯性方面简直是碾压其它同类。不仅如此,Sora还可以生成多种分辨率的视频,包括1920x1080(宽屏)和1080x1920(垂直)的视频以及介于二者之间的所有分辨率的视频,最高可达2048x2048。这使得Sora模型可以创建适应的视频内容。参见下表1。
表1 多种AI视频模型生成视频的时长和分辨率比较
当然,Sora还有超越其它AI视频模型的优势,包括:既能准确呈现细节,又能理解物体在物理世界中的存在,并生成具有丰富情感的角色,甚至模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
二 实现方式
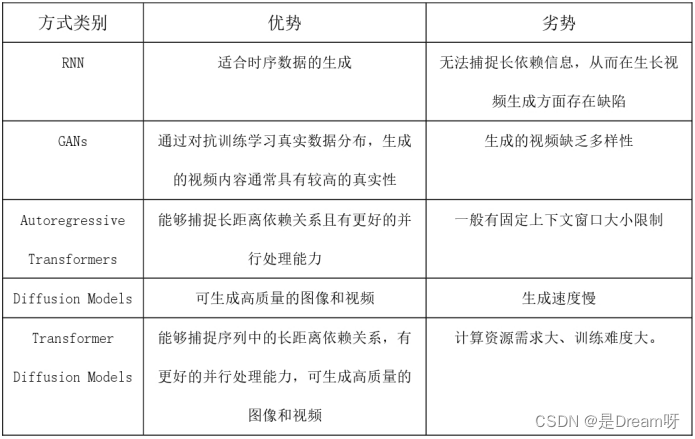
以往,生成视频的实现方式主要有循环神经网络RNN(Recurrent Neural Network)、生成对抗网络GANs(Generative Adversarial Networks)、自回归变换器(Autoregressive Transformers)和扩散模型(Diffusion Models)。总体而言,基于这些实现方式的视频生成模型缺点比较明显,如支持视觉数据的类别少、视频时间短、视频尺寸固定等等。
而Sora是基于Transformer的Diffusion Model模型架构训练而成的,集Transformer的“生成式”和Diffusion Model的“扩散式”之长处于一体。Transformer由于其自注意力机制,能够捕捉序列中的长距离依赖关系,使得它在处理视频这种具有复杂时空依赖性的数据方面具有优势。同时,由于自注意力机制特性,基于Transformer的模型可以通过矩阵运算进行高效的并行计算,因而具有并行处理大规模数据并更快地生成视频的能力。通过结合扩散模型,Transformer Diffusion Models能够在生成视频时保留更多的细节和纹理信息,可生成更高质量的视频。正是由于采用了Transformer Diffusion Models,Sora能够生成多样化的视频和图像,并解决了先前其它方法在视频长度、尺寸和固定大小方面的限制。参见下表2。
表2 各种生成视频的实现方式比较
三 Sora的视频生成原理
Sora模型的视频生成原理总体上分三步曲。首先是通过视频压缩网络(Video Compression Network),将视频或图片压缩成紧凑的形式(即降维)。其次是进行时空潜在补丁提取(Spacetime latent patches),将视图信息分解成一个个小的单元,每个单元都包含了视图中一部分的空间和时间信息,以便在后续步骤中进行有针对性的处理。最后是视频生成,通过对输入文本或图片进行解码加码,由Transformer模型(即ChatGPT基础转换器)决定如何将这些单元转换或组合,从而形成完整的视频。
步骤一:视频压缩网络
如下图1所示,Sora模型通过视频压缩网络技术,将输入的视频或图片压缩成一个低维度的表示形式。这一过程类似于将不同尺寸和分辨率的照片“标准化”,便于处理和存储。

图1 视频压缩示意图
然后,Sora将这些压缩后的视图数据进一步分解成所谓的“时空补丁”(Spacetime Patches),每个补丁都携带了一部分视频的空间和时间信息,形成了视觉内容的基本构建模块。通过这种方法,Sora在保留原始视觉信息丰富性的基础上,也可将不同的原始视频(不同长度、不同分辨率、不同风格等)处理成一致的格式。
步骤二:时空潜在补丁提取
经过预先训练好的转换器(Transformer模型),将提取步骤一生成的时空潜在补丁的信息,形成众多的补丁“清单”,这些补丁清单记录了视图信息表示与其语义之间的对应关系,为后续的视频生成提供了知识素材。
步骤三:视频生成的Transformer模型
在Sora的视频生成过程中,Transformer模型接收时空潜在补丁(这些时空潜在补丁来自于一段与生成目标视频同样时长,但是内容完全是随机噪声的视频)。随后,Sora根据给定的文本提示开始不断修改这段视频中的各个补丁(在这个过程中,Sora利用了从大量的视频和图片数据中学习到的知识,来决定如何逐步去除噪声),将噪声视频转变成接近文本描述的内容,然后再将这些片段转换或组合以生成最终的视频内容。
四 Sora的技术创新
从发布的技术报告来看,与ChatGPT如出一辙,在底层技术层面,Sora并没有过多的独创,而是充分利用了已有的先进技术。但是在应用体验方面,则注入了与其它同类产品不同的创新。
Sora视频生成三步曲中,视频压缩借鉴的是论文“High-Resolution Image Synthesis with Latent Diffusion Models”中的思想。时空潜在补丁的“补丁”(patches和Visual patches)概念引自论文“Vivit:A video vision transformer”(即ViT)(谷歌,2021年)。而Transformer Diffusion Model模型结构最初由论文“Diffusion Models with Transformers”(William Peebles, Saining Xie 2022年)提出。
但在视频的尺寸选择、语言理解能力、多模态输入和多样化视频生成方面,Sora模型具有独到之处。
以往的生成视频模型,都会把视频的尺寸和时长裁剪到标准尺寸,比如256256的4秒视频。而Sora可以直接生成不同尺寸的视频。比如横屏的19201080,竖屏的1080*1920。这使得Sora能够根据设备的屏幕尺寸,生成不同分辨率的视频。这主要缘自视频网络压缩技术应用过程中的低维空间的“标准化”(见上文)。
Sora的技术报告中提到,借鉴了DALL·E3中使用的重新标注技术,对模型训练集里的所有视频重新生成了更详细更准确的文本说明。同时,使用了GPT模型,将用户简短的Prompt扩展成更加详细的说明文字。通过这些数据增强的方式提高了Sora模型对语言的理解能力。
在输入方面,不仅可以输入文本提示,还可以输入图片和视频,典型的多模态支持。视频生成方面,Sora模型可以编辑、增补和拼接视频,也可向前或向后拓展视频内容。
五 未来期望与启发
当然,从视频生成的表现来看,Sora模型仍然有许多不足,如在模拟复杂场景的物理现象、理解特定因果关系、处理空间细节、以及准确描述随时间变化的事件方面,仍存在一定的问题。但随着训练数据的增多和模型的迭代升级,相信这些不足都将逐步得到改善。
无庸置疑的是,Sora模型及其后续升级版,都将加速AIGC在视频产业方面的发展与应用, 对众多如影视、直播、媒体、广告、动漫、艺术设计等多个行业产生深远影响。特别是在短视频盛行的当下,Sora已经可以承担短视频的摄影、导演和剪辑等任务。
然而,对OpenAI公司而言,在其致力于开发通用人工智能使命的征程中,Sora不只是一个视频生成工具。正如Sora的技术文档里有一句话:“我们的结果表明,扩展视频生成模型是向着构建通用物理世界模拟器迈进的有希望的路径”。由此可见,OpenAI最终想做的是打造一个通用的“物理世界模拟器”。从这个意义上,Sora模型的定位在于形成一个世界模型为真实世界建模。
数字孪生,更多的是通过对物理世界的数字化,形成对物理世界的“镜像”,以此增加对物理世界运行状态的掌握和规律把控,并通过在数字虚拟世界的指令干预,以调整、干预和优化物理世界的运行。而“世界模型”,则有望将人类的的思想世界和心理世界充分进行具象化,并与真实的物理世界的状态和运行进行比照,最终形成人类对物理世界状态和运行的期盼与改造策略。由此,Sora模型不仅是一个视频生成模型,而且是一个客观世界模拟器,开户了模拟世界之路。