codeFormer
原始动机
- 高度不确定性,模糊到高清,存在一对多的映射
- 纹理细节丢失
- 人脸身份信息丢失
模型实现
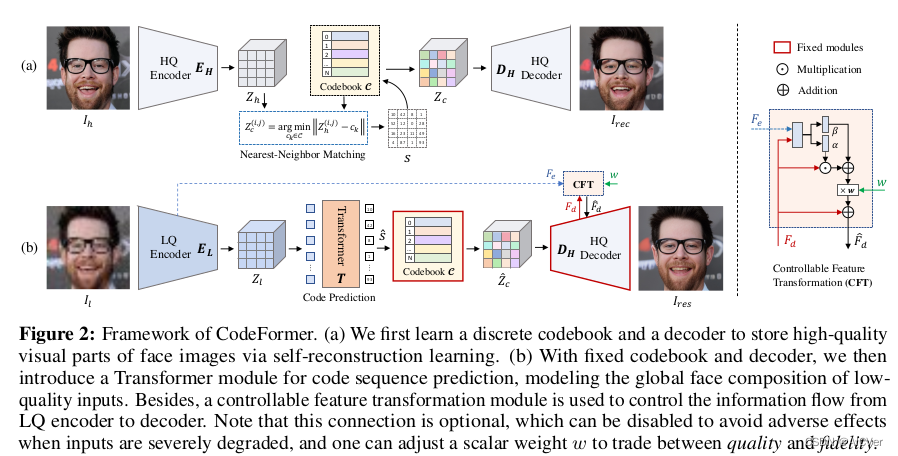
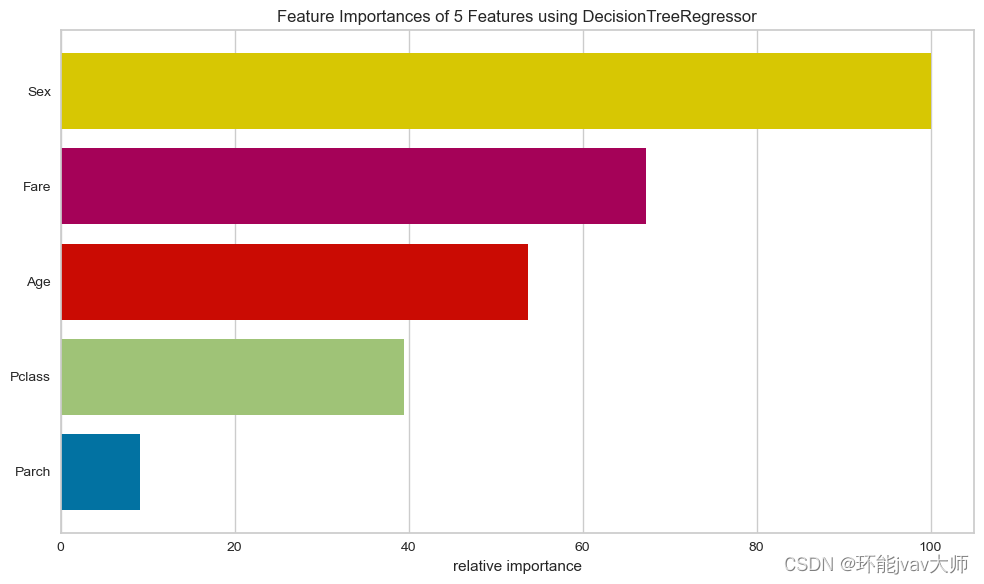
- 训练VQGAN 从而得到HQ码本空间作为本文的离散人脸先验。为了降低LQ-HQ映射之间的不确定性,我们设计尽量小的码本空间和尽量短的Code序列作为人脸的离散表达。因此,我们采用了大的压缩比 (32倍),即将原来的人脸图片压缩为的离散Code序列。该设计使得码本中Code具有更丰富的上下文信息,有助于提升网络表达能力以及鲁棒性。
- 嵌入Transformer模块,对特征全局建模,以达成更好的Code序列预测。该阶段固定Decoder和Codebook,只需学习Transformer模块并微调Encoder。将原本的复原任务转变为离散Code序列预测任务,改变了复原任务的固有范式,这也是本文的主要贡献之一。
- 引入权重控制,平衡图片质量与真实还原。当调小,模型输出质量更高;当调大,模型输出能保持更好的身份一致性。