如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,如果你下载别人已经训练好网络结构的权重,通常能够进展得相当快,可以用这个作为预训练模型,然后转换到你感兴趣的任务上。有时候这些训练过程需要花费好几周,并且需要很多GPU,其他人已经做过了,并且经历了非常痛苦的寻最优过程,这就意味着你可以使用花费了别人好几周甚至几个月做出来的开源的权重参数,把它当作一个很好的初始化用在你自己的神经网络上,用迁移学习把公共的数据集知识迁移到你自己的问题上。
简单来说,预训练模型(Pre-Trained Model)是前人为了解决类似问题创造出来的模型。你在解决问题的时候,不用从零开始训练一个新模型,可以从在类似问题中训练过的模型入手。
比如,如果你想做一辆自动驾驶汽车,可以花数年时间从零开始构建一个性能优良的图像识别算法,也可以从Google在ImageNet数据集上训练得到的Inception Model(一种预训练模型)起步来识别图像。
一个预训练模型可能对于你的应用中并不是100%的准确对口,但是它可以为你节省大量时间。于是,我们转而采用预训练模型,这样就不需要重新训练整个结构,只需要针对其中的几层进行训练即可。
举个芯片图像分类的例子:
在芯片图像的分类上,对采集的芯片图像进行三分类,分别为芯片焊盘、芯片焊球以及连接丝图像。这是一个三分类问题,现在没有大量的图片,训练集很小,该怎么办呢?这里建议从网上下载一些神经网络开源的实现,不仅要把代码下载下来,还要把权重下载下来。有许多训练好的网络都可以下载。
ImageNet数据集已经被广泛用作训练集,因为它规模足够大(包括120万幅图片),有助于训练普适模型。ImageNet的训练目标是将所有的图片正确地划分到1000个分类条目下。这1000个分类基本上都来源于我们的日常生活,比如猫狗的种类、各种家庭用品、日常通勤工具等。
采用在ImageNet数据集上预先训练好的VGG-16模型,VGG-16网络架构模型是由13个卷积层、5个最大池化层以及3个全连接层构成的。它有1000个不同的类别,因此这个网络会有一个Softmax层,它可以输出1000个可能的类别之一。在VGG-16结构的基础上,可以去掉最后三个全连接层,创建你自己的自定义层,只需要训练最后三层的权重,前面这些层的权重都可以冻结。
比如要识别芯片图像,如芯片底盘、芯片引脚丝、焊接球这三类,可以采用VGG-16模型,加载预训练权值,然后随机初始化三层全连接层的权值,学习数据集图像与芯片图像之间的特征空间迁移;最后的一个全连接层由ImageNet的1 000个输出类调整为芯片底盘、焊接球和芯片引脚丝3个输出类。通过使用其他人预训练的权重,很可能得到很好的性能,即使只有一个小的数据集。同时可以大大减少训练时间。
在迁移学习中,这些预训练的网络对于ImageNet数据集外的图片也表现出了很好的泛化性能。通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上,如图6-1所示。因为预训练模型已经训练得很好,我们就不会在短时间内修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(Fine Tuneing)。
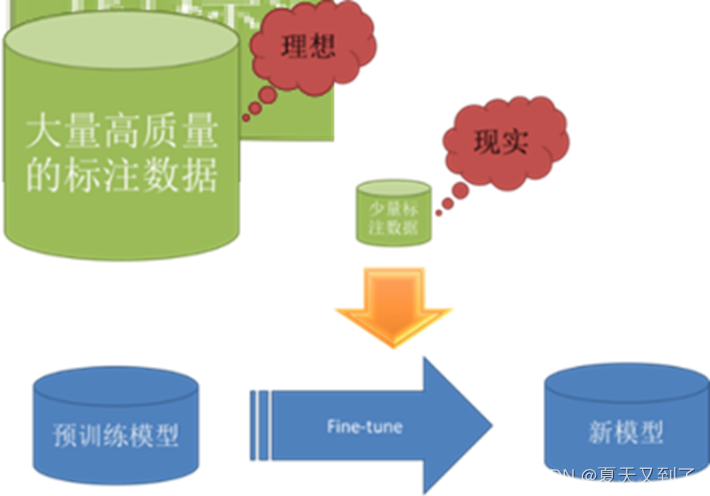
图6-1
但也要记住一点,在选择预训练模型的时候需要非常仔细,如果你的问题与预训练模型训练情景下有很大出入,那么模型所得到的预测结果将会非常不准确。举例来说,如果把一个原本用于语音识别的模型用来进行用户识别,那么结果肯定是不理想的。
《PyTorch深度学习与企业级项目实战(人工智能技术丛书)》(宋立桓,宋立林)【摘要 书评 试读】- 京东图书 (jd.com)本文节选自《PyTorch深度学习与企业级项目实战》,获出版社和作者授权发布。
https://blog.csdn.net/brucexia/article/details/138782385