目录
前置建表
编辑
一、分组的概念
二、分组案例
三、分组的过滤HAVING子句
前置建表
CREATE TABLE student (
id int NOT NULL AUTO_INCREMENT COMMENT '主键',
code varchar(255) NOT NULL COMMENT '学号',
name varchar(255) DEFAULT NULL COMMENT '姓名',
sex enum('男','女') DEFAULT NULL COMMENT '性别',
age int(0) NULL COMMENT '年龄',
PRIMARY KEY (`id`)
);
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (1, '20220101', '张三', '男', 12);
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (2, '202202', '李四', '男', 14);
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (3, '202203', '王五', '女', 10);
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (4, '202204', '张三飞', '男', 20);
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (5, '202205', '小丽', '女', 10);
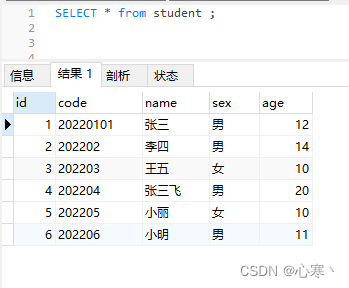
INSERT INTO `test`.`student`(`id`, `code`, `name`, `sex`, `age`) VALUES (6, '202206', '小明', '男', 11);数据如下
一、分组的概念
有时需要在数据中找到变化的趋势,这就需要数据库服务器在产生所需要的结果集之前对数据进行一些加工。这时可以使用group by子句请求数据库服务器对数据进行分组。
GROUP BY子句指示
MySQL
分组数据,然后对每个组而不是整个结果集进行聚集。在具体使用GROUP BY
子句前,需要知道一些重要的规定。
1、GROUP BY
子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
2、如果在
GROUP BY
子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
3、GROUP BY
子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT
中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
4、
除聚集计算语句外,
SELECT
语句中的每个列都必须在
GROUP BY
子句中给出。
5、
如果分组列中具有
NULL
值,则
NULL
将作为一个分组返回。如果列中有多行NULL
值,它们将分为一组。
6、
GROUP BY
子句必须出现在
WHERE
子句之后,
ORDER BY
子句之前。
二、分组案例
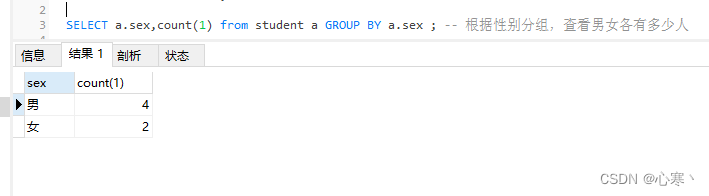
SELECT a.sex,count(1) from student a GROUP BY a.sex ; -- 根据性别分组,查看男女各有多少人
SELECT a.age,count(1) from student a GROUP BY a.age ; -- 根据年龄分组,查看各个年龄有多少人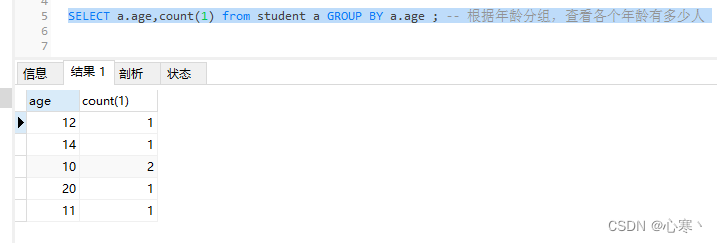
当然GROUP BY还可以结合函数,case when等语法实现分组,如以下案例
SELECT CASE
WHEN a.age>12 THEN
'大于12岁'
ELSE
'小于等于12岁'
END 条件,count(1) from student a GROUP BY CASE
WHEN a.age>12 THEN
'大于12岁'
ELSE
'小于等于12岁'
END ; -- 查询大于12岁和小于等于12岁有多少人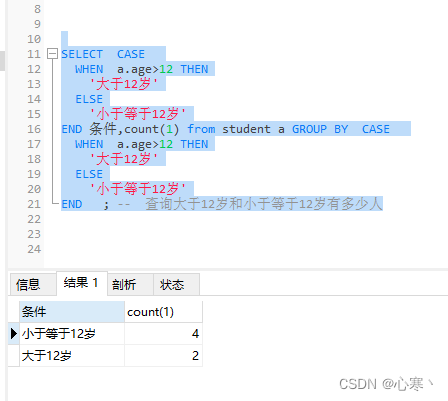
如果获取分组信息之后,还需要获取汇总值,则可以结合WITH ROLLUP关键字来实现
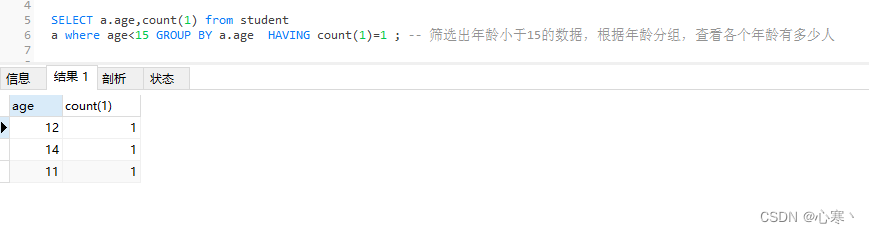
SELECT a.age,count(1) from student a where age<15 GROUP BY a.age HAVING count(1)=1 ; -- 筛选出年龄小于15的数据,根据年龄分组,查看各个年龄有多少人
三、分组的过滤HAVING子句
除了能用GROUP BY
分组数据外,
MySQL还允许过滤分组,规定包括哪些分组,排除哪些分组。必须基于完整的分组进行过滤。 我们已经看到了WHERE
子句的作用
。但是,在这个例
子中
WHERE
不能完成任务,因为
WHERE
过滤指定的是行而不是分组。事实上,WHERE
没有分组的概念。那么,不使用WHERE
使用什么呢?
MySQL
为此目的提供了另外的子句,那就是HAVING
子句。
HAVING
非常类似于
WHERE
。事实上,目前为止所学过的所有类型的WHERE
子句都可以用
HAVING
来替代。唯一的差别是WHERE过滤行,而
HAVING
过滤分组。
SELECT a.sex,count(1) from student a GROUP BY a.sex HAVING count(1)>2; -- 根据性别分组,获取分组之后count大于2的数据

HAVING支持所有
WHERE
操作符
(包括通配符条件和带多个操作符的子句)。有关WHERE
的所有这些技术和选项都适用于HAVING。它们的句法是相同的,只是关键字有差别。
HAVING和WHERE
的差别
这里有另一种理解方法,
WHERE
在数据分组前进行过滤,HAVING
在数据分组后进行过滤。这是一个重要的区别,WHERE
排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING
子句中基于这些值过滤掉的分组。
当然 where和having 子句是可以一起使用的,执行顺序为先where筛选之后再分组然后having筛选
SELECT a.age,count(1) from student a where age<15 GROUP BY a.age HAVING count(1)=1 ; -- 筛选出年龄小于15的数据,根据年龄分组,查看各个年龄有多少人





![buuctf-web-[RoarCTF 2019]Easy Calc1](https://img-blog.csdnimg.cn/img_convert/0c92e4e488b5429dac63ed16dfe5eadc.png)






![[oeasy]python0053_ 续行符_line_continuation_python行尾续行](https://img-blog.csdnimg.cn/img_convert/2e7d9efaeb7ead16b0c25c1e80743717.png)