评估算法的优劣一般会用到以下参数:
TN: 真反例 FN: 假反例
TP: 真正例 FP: 假正例
| 正样本 | 负样本 | |
|---|---|---|
| 预测正样本 | TP | FP |
| 预测负样本 | FN | TN |
-
**精确率/查准率(precision):**预测正确的正样本个数与预测为正样本的个数的比值
precision = TP/(TP+FP) -
召回率/查全率/检出率(recall):通常用来评估实验的完整性。预测正确的正样本个数与实际正样本个数的比值
recall = TP/(TP+FN) -
准确率(accuracy):通常用来评估实验的质量。预测正确的样本个数与所有样本个数的比值;
accuracy = (TP+TN)/(TP+TN+FP+FN) -
误检率:预测错误的正样本个数与预测为正样本的个数的比值
rate-wj = 1-precision = FP/(TP+FP) -
漏检率:未预测到的正样本个数与实际正样本个数的比值
rate-lj = 1-recall = FN/(TP+FN) -
错误率:预测错误的样本个数与所有样本个数的比值
rate-error = 1-accuracy=(FP+FN)/(TP+TN+FP+FN) -
平准计算时间:预测样本总时间与待预测样本总数目的比值
-
F值: 评估模型性能的综合指标
F1 = (2precisionrecall)/(precision+recall) -
ap(Average Precision) ap就是平均精准度,对PR曲线上的Precision值求均值
11-points 法

mmdetection计算ap的 示例代码:
def eval_map(det_results,
gt_bboxes,
gt_labels,
gt_ignore=None,
scale_ranges=None,
iou_thr=0.5,
dataset=None,
print_summary=True):
"""Evaluate mAP of a dataset.
Args:
det_results (list): a list of list, [[cls1_det, cls2_det, ...], ...]
gt_bboxes (list): ground truth bboxes of each image, a list of K*4
array.
gt_labels (list): ground truth labels of each image, a list of K array
gt_ignore (list): gt ignore indicators of each image, a list of K array
scale_ranges (list, optional): [(min1, max1), (min2, max2), ...]
iou_thr (float): IoU threshold
dataset (None or str or list): dataset name or dataset classes, there
are minor differences in metrics for different datsets, e.g.
"voc07", "imagenet_det", etc.
print_summary (bool): whether to print the mAP summary
Returns:
tuple: (mAP, [dict, dict, ...])
"""
assert len(det_results) == len(gt_bboxes) == len(gt_labels)
if gt_ignore is not None:
assert len(gt_ignore) == len(gt_labels)
for i in range(len(gt_ignore)):
assert len(gt_labels[i]) == len(gt_ignore[i])
area_ranges = ([(rg[0]**2, rg[1]**2) for rg in scale_ranges]
if scale_ranges is not None else None)
num_scales = len(scale_ranges) if scale_ranges is not None else 1
eval_results = []
num_classes = len(det_results[0]) # positive class num
gt_labels = [
label if label.ndim == 1 else label[:, 0] for label in gt_labels
]
for i in range(num_classes):
# get gt and det bboxes of this class
cls_dets, cls_gts, cls_gt_ignore = get_cls_results(
det_results, gt_bboxes, gt_labels, gt_ignore, i)
# calculate tp and fp for each image
tpfp_func = (
tpfp_imagenet if dataset in ['det', 'vid'] else tpfp_default)
tpfp = [
tpfp_func(cls_dets[j], cls_gts[j], cls_gt_ignore[j], iou_thr,
area_ranges) for j in range(len(cls_dets))
]
tp, fp = tuple(zip(*tpfp))
# calculate gt number of each scale, gts ignored or beyond scale
# are not counted
num_gts = np.zeros(num_scales, dtype=int)
for j, bbox in enumerate(cls_gts):
if area_ranges is None:
num_gts[0] += np.sum(np.logical_not(cls_gt_ignore[j]))
else:
gt_areas = (bbox[:, 2] - bbox[:, 0] + 1) * (
bbox[:, 3] - bbox[:, 1] + 1)
for k, (min_area, max_area) in enumerate(area_ranges):
num_gts[k] += np.sum(
np.logical_not(cls_gt_ignore[j]) &
(gt_areas >= min_area) & (gt_areas < max_area))
# sort all det bboxes by score, also sort tp and fp
cls_dets = np.vstack(cls_dets)
num_dets = cls_dets.shape[0]
sort_inds = np.argsort(-cls_dets[:, -1])
tp = np.hstack(tp)[:, sort_inds]
fp = np.hstack(fp)[:, sort_inds]
# calculate recall and precision with tp and fp
tp = np.cumsum(tp, axis=1)
fp = np.cumsum(fp, axis=1)
eps = np.finfo(np.float32).eps
recalls = tp / np.maximum(num_gts[:, np.newaxis], eps)
precisions = tp / np.maximum((tp + fp), eps)
# calculate AP
if scale_ranges is None:
recalls = recalls[0, :]
precisions = precisions[0, :]
num_gts = num_gts.item()
mode = 'area' if dataset != 'voc07' else '11points'
ap = average_precision(recalls, precisions, mode)
eval_results.append({
'num_gts': num_gts,
'num_dets': num_dets,
'recall': recalls,
'precision': precisions,
'ap': ap
})
if scale_ranges is not None:
# shape (num_classes, num_scales)
all_ap = np.vstack([cls_result['ap'] for cls_result in eval_results])
all_num_gts = np.vstack(
[cls_result['num_gts'] for cls_result in eval_results])
mean_ap = [
all_ap[all_num_gts[:, i] > 0, i].mean()
if np.any(all_num_gts[:, i] > 0) else 0.0
for i in range(num_scales)
]
else:
aps = []
for cls_result in eval_results:
if cls_result['num_gts'] > 0:
aps.append(cls_result['ap'])
mean_ap = np.array(aps).mean().item() if aps else 0.0
if print_summary:
print_map_summary(mean_ap, eval_results, dataset)
return mean_ap, eval_results
under area curve 法
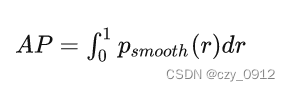
- map map就是多类别平均精准度







![关系数据库-2-[mysql8]python3操作mysql](https://img-blog.csdnimg.cn/391f66203d4842fbbf786b26d8084dd2.png)