2024年中青杯数学建模竞赛B题论文和代码已完成,代码为B题全部问题的代码,论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解)、模型的评价等等
2024中青杯数学建模竞赛B题论文和代码获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/xg2r5sf8m1s3hl5d
B 题:药物属性预测:
机器学习、深度学习、图神经网络
B 题:药物属性预测
近年来,随着网络技术的快速发展和大数据挖掘技术的成熟,人们的数据分析能力也在逐步提升,可以采集的数据规模越来越大。尤其是伴随着电商和短视频媒体的发展,产生了大量的图结构数据。图结构数据的研究非常有价值,由于图结构数据的复杂性,使得这方面的研究工作十分具有挑战性。
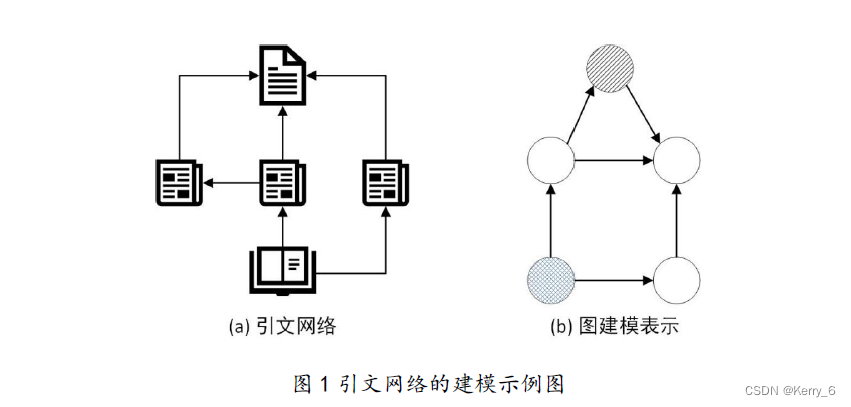
现实世界中有很多问题都可以使用图来建模,图数据是目前模式识别与机器学习领域重要的研究对象。例如,网上购物软件采用基于图深度学习的方法可以精准地向用户推荐喜欢的商品,图在推荐系统上的建模能力比较强;在生物医疗上,可以图深度学习技术设计新药物或者探究药物间的相互作用;而在引文网络中,论文通过引用关系被相互连接,并可通过分析这些关系将它们分组,正如图1 所示。这些例子展示了基于图的学习系统在不同领域的应用潜力和价值。图是一种功能强大的结构,可以用来建模几乎任何类型的数据。社交网络、文本文档、万维网、化学化合物和蛋白质-蛋白质相互作用网络,通常都是用图表表示的数据的例子[2].由于图形结构的丰富数据,图上的机器学习最近成为一项非常重要的任务。近年来,越来越多的学者关注图表示学习的研究工作,图表示学习主要应用在图分类、节点分类和链路预测等任务中。
附件是药物分子的数据(图数据),请您利用传统方法建立药物分子的分类模型,并给出分类精度及其结果分析。
传统药物分子分类方法依赖于复杂的化学属性分析和生物实验,不仅耗时耗力,而且难以处理大规模的分子数据。因此,发展一种高效、准确的分子分类方法成为了当前科研的一个热点。与此同时,一些研究人员将神经网络应用到药物分子挖掘中,提出图神经网络,这种方法能够端到端进行模型的优化学习,在图分类准确度有较大提升。请您给出一种图神经网络模型对附件中的数据进行分类,并给出分类精度及其结果分析。
现有图神经网络模型在处理具有节点特征稀疏性和信息冗余的图结构数据时面临挑战,这限制了模型在复杂网络分析中的应用效果。请您尝试给出一种新的药物分子分类方法突破这种限制,给出试验结果,并进行分析讨论。
1.1 总体分析
下面是对2024中青杯B题的一个问题分析:
这个题目旨在利用机器学习和深度学习技术解决药物分子分类的问题,探索利用图结构数据对药物进行高效、准确的分类。题目不仅要求使用传统方法和现有的图神经网络模型,还需要提出创新性的方法来突破现有模型的局限。整体而言,这个问题贴近当前的科研前沿,具有一定的理论价值和实际应用意义。给定的数据集为模型训练和验证提供了基础,题目设置合理,难度适中。
1.2 第一个子问题分析
题目要求使用传统方法建立药物分子分类模型,传统方法通常指基于人工提取的特征和经典的机器学习算法,如决策树、支持向量机等。这种方法的优点是可解释性强,缺点是需要人工设计特征,难以捕捉数据中的复杂模式。
在具体实现时,需要对药物分子数据进行预处理,提取与分类相关的化学结构特征,如分子量、极性、官能团等。然后使用这些特征训练经典的机器学习模型,如逻辑回归、随机森林等,并在测试集上评估模型的性能。
传统方法的分类结果需要进行全面分析,包括模型的准确率、精确率、召回率等指标,以及在不同类别上的表现。同时还需分析特征的重要性,探讨哪些化学特征对分类更为关键。最后需总结传统方法的优缺点,为下一步使用深度学习模型打下基础。
1.3 第二个子问题分析:
题目要求使用图神经网络模型对药物分子数据进行分类,图神经网络是一种processed结构化数据的新型深度学习模型,能够直接处理图结构数据,自动学习节点和边的表示。与传统方法相比,它不需要人工设计特征,能够端到端地优化模型参数。
在实现时,需要先将药物分子数据转换为图结构表示,每个节点代表一个原子,边表示原子之间的化学键。然后设计合适的图神经网络模型,如图卷积神经网络(GCN)或图注意力网络(GAT)等,对节点和边的表示进行编码,最终得到整个图的表示向量,用于分类。
在评估图神经网络模型时,需要对比其与传统方法的准确率、泛化能力等,分析深度学习模型在药物分类任务上的优势所在。另外还需探讨模型对数据噪声和缺失值的鲁棒性,以及在大规模数据集上的计算效率等实际应用考虑因素。
1.4 第三个子问题分析
现有图神经网络在处理节点特征稀疏和信息冗余的图数据时仍有不足,这将影响模型在复杂网络分析中的应用效果。节点特征稀疏意味着节点的属性信息不完整,而信息冗余则表示图中存在大量无用或重复的边缘信息。
为突破这一限制,可以尝试设计新的图神经网络架构,增强模型对稀疏特征的鲁棒性,如引入注意力机制或外部知识;或者在模型输入时加入降噪、去冗余的预处理步骤;亦可结合经典的图理论方法,提出混合模型等。
实现新模型后,需要在给定数据集上进行全面的实验评估,测试新模型在准确率、泛化能力、计算效率等方面的表现,与现有模型进行对比分析。最后需要总结新模型的创新之处,指出其在应对特殊类型图数据时的优势,并讨论在其他领域中的潜在应用前景。
这个问题设置合理且具有一定的开放性,参赛者需要掌握机器学习、深度学习和图论的基础知识,并具备一定的建模能力和创新意识,才能很好地完成该题。
2024中青杯数学建模B题论文和代码获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/xg2r5sf8m1s3hl5d






![页面加载不出来,报错[@umijs/runtime] load component failed](https://img-blog.csdnimg.cn/direct/a8128ccc9b7b42c3ae50ba83aeecf5d1.png)