文章目录
- 1. 集合框架
- 2. ArrayList和LinkedList
- 2.1 源码分析
- 2.2 ArrayList list=new ArrayList(10)中的list扩容几次?
- 2.3 如何实现数组和List之间的转换
- 2.4 ArrayList和LinkedList的区别
- 2.5 如何保证ArrayList的线程安全?
- 2.6 CopyOnWriteArrayList是如何实现线程安全的?
- 3. HashMap
- 3.1 红黑树的特性
- 3.2 HashMap的实现原理
- 3.3 HashMap在JDK7和JDK8中有什么区别?
- 3.4 HashMap线程不安全的原因
- 3.5 HashMap的put方法执行流程
- 3.6 HashMap扩容机制
- 3.7 为何HashMap的数组长度一定是2的次幂
- 3.8 HashMap为什么选择0.75作为默认加载因子?
- 3.9 HashMap在JD7情况下的多线程死循环问题
- 3.10 HashSet和HashMap的区别
- 3.11 HashTable和HashMap的区别
- 3.12 ConcurrentHashMap的底层实现
1. 集合框架

2. ArrayList和LinkedList
2.1 源码分析
- 成员变量
//Default initial capacity. private static final int DEFAULT_CAPACITY = 10; //Shared empty array instance used for empty instances. private static final Object[] EMPTY_ELEMENTDATA = {}; /** * Shared empty array instance used for default sized empty instances. We * distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when * first element is added. */ private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; /** * The array buffer into which the elements of the ArrayList are stored. * The capacity of the ArrayList is the length of this array buffer. Any * empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA * will be expanded to DEFAULT_CAPACITY when the first element is added. */ transient Object[] elementData; // non-private to simplify nested class access /** * The size of the ArrayList (the number of elements it contains). * * @serial */ private int size;
- DEFAULT_CAPACITY=10; 默认初始的容量是10
- EMPTY_ELEMENTDATA={}; 用于空实例的共享空数组实例
- DEFAULTCAPACITY_EMPTY_ELEMENTDATA={};用于默认大小的空实例的共享空数组实例
- Object[] elementData; 存储元素的数组缓冲区
- int size; ArrayList的大小(它包含的元素数量)
- 构造函数
/** * Constructs an empty list with the specified initial capacity. * * @param initialCapacity the initial capacity of the list * @throws IllegalArgumentException if the specified initial capacity * is negative */ public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } } /** * Constructs an empty list with an initial capacity of ten. */ public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } /** * Constructs a list containing the elements of the specified * collection, in the order they are returned by the collection's * iterator. * * @param c the collection whose elements are to be placed into this list * @throws NullPointerException if the specified collection is null */ public ArrayList(Collection<? extends E> c) { elementData = c.toArray(); if ((size = elementData.length) != 0) { // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class); } else { // replace with empty array. this.elementData = EMPTY_ELEMENTDATA; } }
- 第一个构造函数是带初始化容量的构造函数,可以按照指定的容量初始化数组。
- 第二个是无参构造函数,默认创建一个空集合。
- 第三个是将Collection对象转换成数组,然后将数组的地址赋给elementData。
-
源码分析

- 结论
- 底层数组结构:ArrayList底层是用动态数组实现的;
- 初始容量:ArrayList初始容量是0,当第一次添加数组的时候才会初始化容量为10;
- 扩容逻辑:ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组;
- 添加逻辑
- 确保数组已使用长度(size)加1之后足够存下下一个数据;
- 计算数组的容量,如果当前数组已使用长度+1后大于当前的数组容量,则调用grow方法进行扩容(原来的1.5倍);
- 确保新增的数据有地方存储后,则将新元素添加到位于size的位置上。
- 返回添加成功boolean;
- 结论
2.2 ArrayList list=new ArrayList(10)中的list扩容几次?
根据ArrayList的有参构造函数,该代码只是声明和实例化了一个ArrayList,指定了容量为10,未扩容。
2.3 如何实现数组和List之间的转换
- 数组 --> List
-
源码
//数组转List public static void main(String[] args){ String[] strs = {"aaa","bbb","ccc"}; List<String> list = Arrays.asList(strs); for(String str : list){ System.out.println(str); } } //asList方法源码 @SafeVarargs @SuppressWarnings("varargs") public static <T> List<T> asList(T... a) { return new ArrayList<>(a); } -
总结:
- 数组转List使用JDK中的java.util.Arrays工具类的asList方法。
- 数组转List,修改数组内容,List会受到影响。因为他的底层是是应用Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把传入的这个数组进行了包装而已,最终指向的都是同一内存地址。
-
- List --> 数组
- 源码
//List转数组 public static void main(String[] args){ List<String> list = new ArrayList<>(); list.add("aaa"); list.add("bbb"); list.add("ccc"); String[] strs = list.toArray(new String[list.size()]); for(String str : strs){ System.out.println(str); } } //toArray方法 public Object[] toArray() { return Arrays.copyOf(elementData, size); } @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { if (a.length < size) // Make a new array of a's runtime type, but my contents: return (T[]) Arrays.copyOf(elementData, size, a.getClass()); System.arraycopy(elementData, 0, a, 0, size); if (a.length > size) a[size] = null; return a; } - 总结
- List转数组,使用List的toArray方法。无参toArray方法返回Object数组,传入初始化长度的数组对象,返回该对象数组。
- List用了toArray转数组后,如果修改了List内容,数组不会受影响。当调用了toArray以后,在底层它进行了数组的深拷贝,跟原来的元素没有关系了,所以即使List修改之后,数组也不受影响。
- 源码
2.4 ArrayList和LinkedList的区别
- 底层数组结构
- ArrayList是动态数组实现的;
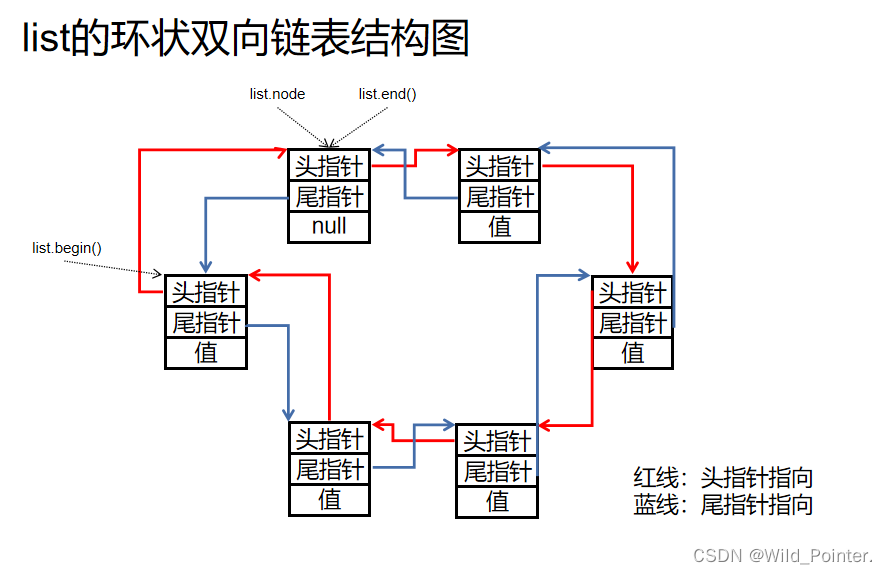
- LinkedList是双向链表实现的;
- 操作数据效率
- 查询:ArrayList按照索引[下标]查询数据。可以进行随机访问,时间复杂度为O(1);当ArrayList进行未知索引访问时,也要进行遍历数组,时间复杂度为O(n); LinkedList要遍历整个链表,时间复杂度为O(n);
- 新增和删除
- ArrayList尾部插入和删除时,时间复杂度为O(1);其余部分增删需要移动数组元素,时间复杂度为O(n);
- LinkedList头尾节点的增删时间复杂度时O(1),其余需要遍历链表,时间复杂度为O(n)。但是,LinkedList的add()方法默认为尾插法。
- 内存空间占有
- ArrayList底层是数组,内存连续,节省空间;
- LinkedList是双向链表,需要存储数据和两个指针,更占用内存。
- 线程安全
- ArrayList和LinkedList都不是线程安全的。
- 如果要保证线程安全,有两种方案(所有保证线程的思路):
- 在方法内使用局部变量保证线程安全;
- 使用线程安全的ArrayList和LinkedList。
2.5 如何保证ArrayList的线程安全?
ArrayList线程不安全,可以通过如下几种方案实现线程安全的ArrayList:
- (不推荐,Vector是一个历史使用 Vector 代替 ArrayList。遗留类)
- 使用 Collections.synchronizedList 包装 ArrayList,然后操作包装后的 list。
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>()); - 使用 CopyOnWriteArrayList 代替 ArrayList。
CopyOnWriteArrayList 是java.util.concurrent包下的一个线程安全的ArrayList实现。它通过在修改操作时创建一个新的数组来实现线程安全,适用于读多写少的场景。List<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
2.6 CopyOnWriteArrayList是如何实现线程安全的?
- CopyOnWriteArrayList就是线程安全版本的ArrayList。
- CopyOnWriteArrayList采用了一种读写分离的并发策略,CopyOnWriteArrayList容器允许并发读,读操作是无锁的,性能较高。至于写操作,比如向容器中添加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。适合读多写少的场景。
3. HashMap

3.1 红黑树的特性
- 性质1:节点要么是红色的,要么是黑色的;
- 性质2:根节点是黑色;
- 性质3:叶子节点都是黑色的空节点;
- 性质4:红黑树中红色节点的子节点都是黑色节点;
- 性质5:从任意一节点到叶子节点的所有路径都包含相同数量的黑色节点。

3.2 HashMap的实现原理
HashMap的数据结构:底层使用hash表数据结构,即数组+链表/红黑树。
- 当向HashMap中put元素时,利用key的hashCode重新hash计算出对象的元素在数组中的下标;
- 在存储时,如果出现hash值相同的key,此时有两种情况:
- 如果key相同,则覆盖原始值;
- 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中;
- 获取value值时,直接找到hash值对应的下标,再进一步判断key值是否相同,从而寻找到对应值。
3.3 HashMap在JDK7和JDK8中有什么区别?
主要表现在解决哈希冲突上。
- JDK8之前采用的是拉链法。(拉链法:将链表和数组结合,数组桶位连接一个链表,遇到哈希冲突时,直接加入到链表中);
- JDK8在解决哈希冲突时,当链表长度大于阈值(默认为8)且数组长度大于64时,将链表转变为红黑树,以减少搜索时间,扩容resize()时,红黑树拆分成的树的节点数小于临界值6个,则退化为链表。
3.4 HashMap线程不安全的原因
HashMap线程不安全的主要原因是在多线程环境下,当同时进行读取或修改操作时可能会导致数据不一致或者丢失。主要是因为HashMap的内部结构是基于数据和链表或红黑树组成的,而数组的扩容、链表的插入和删除等操作都不是原子操作,如果在多线程环境下没有正确地进行同步操作,就会出现线程安全问题。
主要导致HashMap线程不安全的原因:
- 非同步方法
HashMap类本身没有任何同步机制(如synchronized关键字或使用java.util.concurrent包中的同步工具)。当多个线程同时访问和修改HashMap时,如果没有外部的同步控制,线程会以无序的方式操作HashMap,可能会导致数据不一致。 - 结构修改与迭代器失效
当HashMap在进行扩容、节点迁移等结构修改操作时,如果其他线程同时读取或修改,可能会导致正在使用的迭代器、foreach循环或其他依赖于内部结构稳定的视图突然失效,会抛出ConcurrentModifcationException异常。 - 并发写入冲突
多个线程同时尝试插入或删除键值对时,可能会引发数据安全问题。- 数据丢失:两个线程同时尝试插入同一个键,其中一个线程得知可能会被另一个线程覆盖,造成数据丢失。
- 链表节点顺序混乱:虽然在JDK8及之后版本中,插入节点改为了尾插法,避免了“死循环”链表问题,但并发插入仍可能会导致链表节点顺序不符合预期,映像查找性能。
- 扩容期间的竞态:当HashMap的容量需要动态增加时,会触发resize扩容操作。这个过程中涉及到计算哈希、移动节点等操作。如果多个线程同时参与resize,可能会导致节点被错误的复制、覆盖,或者链表断裂,进而引发数据丢失或进一步的逻辑混乱。
- 哈希碰撞下的链表/树操作
当多个键哈希到同一个桶位时,会形成链表(在JDK8及之后,链表长度超过阈值且数组超过64时会转换成红黑树)。并发环境下,对链表或树的插入、删除操作如果没有适当的同步控制,可能会导致节点状态错误、链表链接错误或树结构破坏。
3.5 HashMap的put方法执行流程
- 源码
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //初始化与扩容 //检查当前table是否为空或长度为0,若满足条件,则调用resize()方法进行初始化或扩容。扩容后更新table和其长度n if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //定位节点 //根据hash值和table长度计算出索引i(通过位运算实现哈希冲突的分散) //检查索引i处的节点p是否为空。若为空,直接在该位置创建一个新节点(newNode(hash, key, value, null)),表示当前位置没有发生哈希冲突 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //处理哈希冲突 else { Node<K,V> e; K k; //若节点p非空 //检查节点key是否匹配 //如果节点p的哈希值、键与给定key相等(或通过equals方法判断相等),则找到了已存在的键值对节点e,跳至e!=null处处理。 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //处理红黑树节点 //若节点p是一个红黑树节点(TreeNode类型),则调用putTreeVal方法将新键值对插入到红黑树中,找到对应的节点e。 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //遍历链表节点: //节点p为链表节点。从p开始遍历链表,查找是否存在与给定key相等的节点。遍历过程中计数器binCount记录链表长度,用于判断是否需要将链表转换为红黑树。 //找到匹配节点e或链表末尾时,终止遍历。若未找到匹配节点,将新节点添加到链表末尾。 else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } //更新/插入节点 //已存在节点(e != null): //若找到已存在的节点e,即HashMap中已存在与给定key相等的键值对: //若onlyIfAbsent为false或旧value为null,更新节点e的value为给定value。 //调用afterNodeAccess(e)进行后续操作(如统计访问次数等,由子类实现)。 //返回旧value。 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount;//表示结构已被修改 if (++size > threshold)//size是否大于阈值 resize(); afterNodeInsertion(evict); return null; } - 执行过程
- 判断键值对数组table是都为空或为null,否则执行resize()进行扩容(初始化);
- 根据键值key计算hash值得到数组索引;
- 判断table[i]==null,条件成立,直接新建节点添加
- 如果table[i]==null不成立
- 判断table[i]首个元素是否和key一样,如果相同直接覆盖value
- 判断table[i]是否为treeNode,即table[i]是否为红黑树,如果是红黑树,则直接在树中插入键值对
- 遍历table[i],链表的尾部直接插入数据,然后判断链表长度是否大于8且数组长度大于64,体哦阿健成立则把链表转换成红黑树,在红黑树中执行插入操作,遍历过程中若发现key已经存在直接覆盖value;
- 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold(数组长度*0.75),如果超过则及进行扩容。
3.6 HashMap扩容机制
- 在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据或初始化数组长度为16,以后每次扩容都是达到了扩容阈值(数组长度*0.75)
- 每次扩容的时候,都是扩容之前容量的2倍
- 扩容之后,会创建一个数组,需要把原来数组中的数据移动到新的数组中
- 没有hash冲突的节点,则直接使用e.hash & (newCap-1)计算新数组的索引位置
- 如果是红黑树,走红黑树的添加
- 如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash * oldCap)是否为0,该元素的位置要么停留在原始位置上,要么移动到原始位置+增加的数组大小这个位置上。
3.7 为何HashMap的数组长度一定是2的次幂
- 计算索引的效率更高:如果是2的n次幂,可以直接使用位于运算代替取模运算;
- 扩容时重新计算索引效率更高:hash & oldCap==0的元素留在原来位置,否选择新位置 = 就位置 + oleCap;
3.8 HashMap为什么选择0.75作为默认加载因子?
- 简单来说,这是对空间成本和时间成本平衡的考虑我们都知道,HashMap的散列构造方式是Hash取余,负载因子决定元素个数达到多少时候扩容假如我们设的比较大,元素比较多,空位比较少的时候才扩容,那么发生哈希冲突的概率就增加了,查找的时间成本就增加了。
- 我们设的比较小的话,元素比较少,空位比较多的时候就扩容了,发生哈希碰撞的概率就降低了,查找时间成本降低但是就需要更多的空间去存储元素,空间成本就增加了。
3.9 HashMap在JD7情况下的多线程死循环问题

[来自:黑马程序员资料]
3.10 HashSet和HashMap的区别
- HashSet实现了Set接口,存储对象;HashMap实现了Map接口,存储的是键值对。
- HashSet底层使用HashMap实现存储的,HashSet封装了一系列HashMap的方法,依靠HashMap来存储元素值。(利用HashMap的key键进行存储),而value值默认为Object对象,所以HashSet也不允许出现重复值,判断标准和HashMap的判断标准相同,两个元素的HashMap相等并且通过equals()方法返回true。
3.11 HashTable和HashMap的区别
- 数据结构不同,HashTable时数组+链表,HashMap在JDK8之后改为数组+链表+红黑树;
- HashTable存储数据的时候不能为null,而HashMap是可以为null,key健只能由一个null值
- Hash算法不同,HashTable是用本地修饰的hashcode值,而hashMao经过了二次hash;
- 扩容方式不同,HashTable是当前容量翻倍+1,HashMap是当前容量翻倍;
- HashTable是线程安全的,操作数据的时候加了锁synchronized,HashMap不是线程安全的,效率更高。
在实际开发中,不建议使用HashTable,在多线程环境中建议使用ConcurrentHashMap。
3.12 ConcurrentHashMap的底层实现
ConcurrentHashMap是Java中线程安全的哈希表实现,它提供了高效的并发访问。其底层实现主要基于数据和链表/红黑树,以及一些复杂的算法和技巧来确保线程安全和高性能。
底层实现原理:
- 分段锁机制:[注意:在jdk8之后,放弃了分段的锁的概念,转而使用更加细粒度的锁策略,结合CAS操作和synchronized关键字来保证线程的安全]。ConcurrentHashMap将数组分割成多个段(Segment),每个段相当于一个小的哈希表。每个段都有自己的锁,不同的段可以被不同的线程同时访问,从而提高并发性能。当多个线程同时访问ConcurrentHashMap时,它们可能会只锁住其中一个或一部分段,而不是整个哈希表。
- 数组+链表/红黑树:每个段内部使用数组来存储键值对,通常使用链表或红黑树来解决哈希冲突。当链表的长度超过一定阈值时,会将链表转换为红黑树,以提高查找、插入和删除操作的性能。
- 扩容机制:与普通的哈希表类似,ConcurrentHashMap在需要扩容时会创建一个更大的数组,并将原有的键值对重新分配到新的数组中。由于ConcurrentHashMap的每个段都是独立的,因此扩容时只需要对部分段进行操作,而不会影响到其他线程对其他段的访问。
- 非阻塞算法:ConcurrentHashMap中使用了一些非阻塞的算法来实现线程安全性,如CAS操作。CAS是一种原子操作,能够在不使用锁的情况下实现多线程间的同步。通过CAS操作,ConcurrentHashMap能够在不阻塞线程的情况下更新数据结构,从而提高并发性能。
- 读写分离:ConcurrentHashMap在读操作和写操作上采用了不同的策略。读操作通常不需要加锁,因此能够实现较高的并发性能;而写操作会涉及到段的锁定,以确保线程安全。
总的来说,ConcurrentHashMap的底层实现利用了分段锁、数组+链表/红黑树、扩容机制、非阻塞算法等技术,以实现高效的并发访问和线程安全的哈希表功能。这些技术使得ConcurrentHashMap能够在多线程环境下提供良好的性能表现。
S操作。CAS是一种原子操作,能够在不使用锁的情况下实现多线程间的同步。通过CAS操作,ConcurrentHashMap能够在不阻塞线程的情况下更新数据结构,从而提高并发性能。
- 读写分离:ConcurrentHashMap在读操作和写操作上采用了不同的策略。读操作通常不需要加锁,因此能够实现较高的并发性能;而写操作会涉及到段的锁定,以确保线程安全。
总的来说,ConcurrentHashMap的底层实现利用了分段锁、数组+链表/红黑树、扩容机制、非阻塞算法等技术,以实现高效的并发访问和线程安全的哈希表功能。这些技术使得ConcurrentHashMap能够在多线程环境下提供良好的性能表现。





![页面加载不出来,报错[@umijs/runtime] load component failed](https://img-blog.csdnimg.cn/direct/a8128ccc9b7b42c3ae50ba83aeecf5d1.png)