会搭建深度学习环境和依赖包安装
使用Anaconda创建环境、在pytorch官网安装pytorch、安装依赖包
会使用常见操作,例如matmul,sigmoid,softmax,relu,linear
matmul操作见文章torch.matmul()的用法
sigmoid,softmax,relu都是常用的激活函数,linear是线性层:
from torch import nn
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Sigmoid(),
nn.Softmax(),
nn.ReLU(),
nn.Linear(1024, 64)
)
dataset,dataloader,损失函数,优化器的使用
dataset,dataloader
官方文档是这么写的:
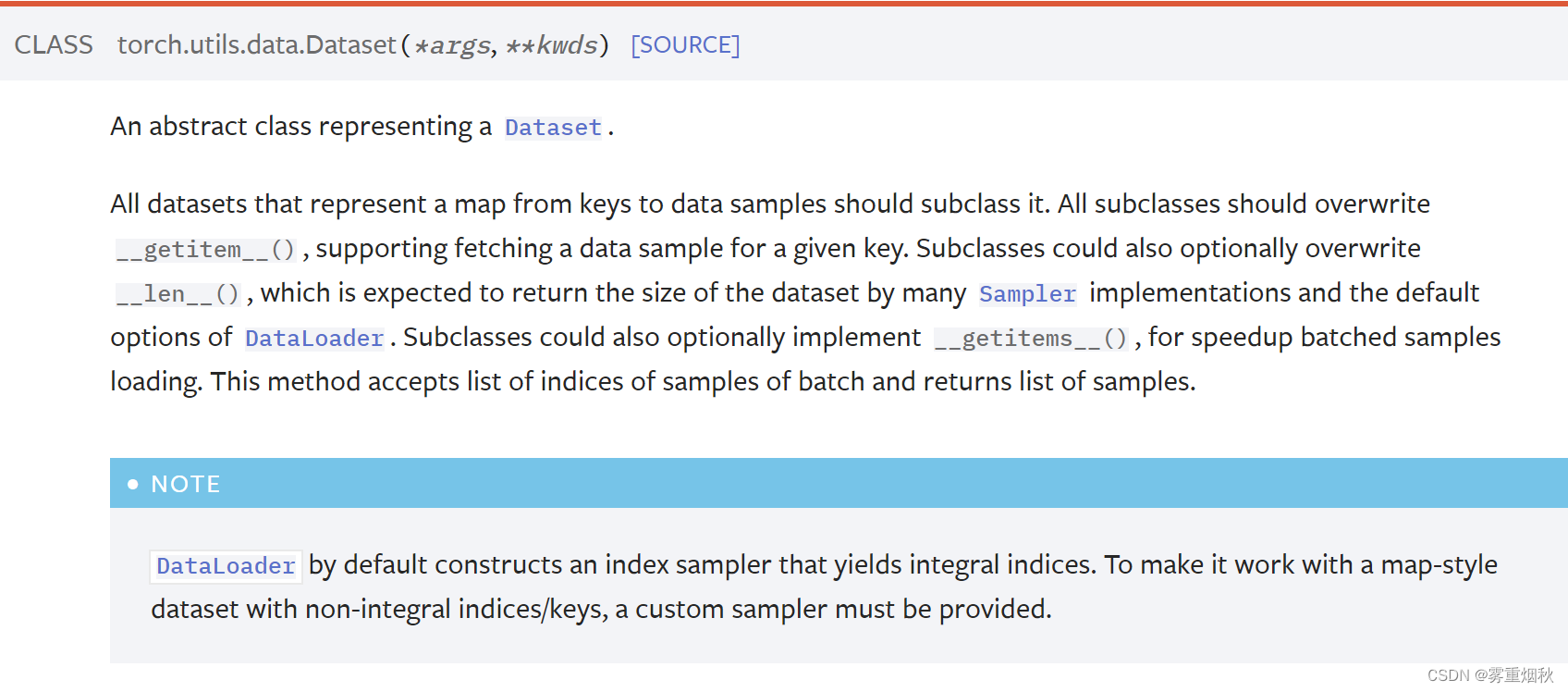
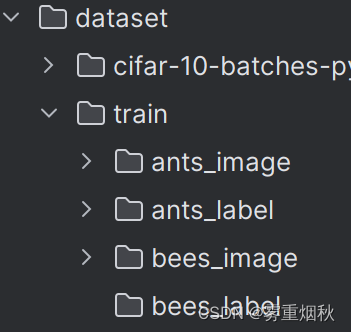
当我们自定义一个dataset的时候,需要继承Dataset,重写__getitem__()方法,也可以重写__len__()方法,下面是一个例子,我们的数据集存放成这种形式,每一个image图片都对应一个相同名称的label文件,如0013035.jpg和0013035.txt就分别是一个图片和它的label:
import torchvision.transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.imgs = os.listdir(self.image_path)
self.labels = os.listdir(self.label_path)
def __getitem__(self, item):
img_name = self.imgs[item]
img_item_path = os.path.join(self.image_path, img_name)
label_item_path = os.path.join(self.label_path, self.convert_to_txt_path(img_name))
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.read().strip()
return img, label
def convert_to_txt_path(self, image_path):
# 使用正则表达式匹配文件名中的点和扩展名,并替换为'.txt'
label_path = re.sub(r'\.[^.]+?$', '.txt', image_path)
return label_path
def __len__(self):
return len(self.imgs)
root_dir = "dataset/train"
ants_image_dir = "ants_image"
bees_image_dir = "bees_image"
ants_label_dir = "ants_label"
bees_label_dir = "bees_label"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img, target = train_dataset[0]
transform = torchvision.transforms.ToTensor()
print(transform(img).shape)
print(target)
我们使用dataloader来读取这个数据集,我们需要对jpg格式的dataset进行处理,将其转换为相同大小的tensor,再读取:
import torchvision.transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.imgs = os.listdir(self.image_path)
self.labels = os.listdir(self.label_path)
def __getitem__(self, item):
img_name = self.imgs[item]
img_item_path = os.path.join(self.image_path, img_name)
label_item_path = os.path.join(self.label_path, self.convert_to_txt_path(img_name))
img = Image.open(img_item_path)
transcompose = torchvision.transforms.Compose([torchvision.transforms.Resize((300, 300)), torchvision.transforms.ToTensor()])
img = transcompose(img)
with open(label_item_path, 'r') as f:
label = f.read().strip()
return img, label
def convert_to_txt_path(self, image_path):
# 使用正则表达式匹配文件名中的点和扩展名,并替换为'.txt'
label_path = re.sub(r'\.[^.]+?$', '.txt', image_path)
return label_path
def __len__(self):
return len(self.imgs)
root_dir = "dataset/train"
ants_image_dir = "ants_image"
bees_image_dir = "bees_image"
ants_label_dir = "ants_label"
bees_label_dir = "bees_label"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img, target = train_dataset[0]
print(img.shape)
print(target)
train_dataloader = DataLoader(train_dataset, batch_size=64, drop_last=True)
for data in train_dataloader:
try:
imgs, target = data
except Exception as e:
print(f"跳过异常文件: {e}")
使用公开数据集的示例如下:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
损失函数
Loss的用法实际上就两行代码的事情,以下是示例:
import torch
from torch.nn import L1Loss, MSELoss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float)
targets = torch.tensor([1, 2, 5], dtype=torch.float)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
loss_mse = MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
优化器
优化器的使用也很简单,但要注意,在每一步训练之前都需要用optim.zero_grad()将梯度置零,避免梯度累加造成问题,用loss.backward()得到梯度以后用optim.step()更新参数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32,5, padding=2),
MaxPool2d(2),
Conv2d(32, 32,5, padding=2),
MaxPool2d(2),
Conv2d(32, 64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
network = Network()
optim = torch.optim.SGD(network.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = network(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print(running_loss)
gpu手写和预测一个模型
gpu写模型
这里采用to(device)的方式使用gpu,对模型、损失函数和读数据部分使用to(device)调用gpu,其他和cpu并无区别:
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *
# 定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为: {}".format(train_data_size))
print(f"测试数据集的长度为: {test_data_size}")
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
# 搭建神经网络
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
network = Network()
network.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 30
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("-----------第 {} 轮训练开始----------".format(i+1))
# 训练步骤开始
network.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数: {}, loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
network.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(network, "network_{}.pth".format(i))
print("模型已保存")
writer.close()
gpu预测模型
把读取到的模型和数据用to(device)设置成gpu运行
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
# 定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_path = "dog.png"
image = Image.open(img_path)
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
# 搭建神经网络
class Network(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("network_29.pth").to(device)
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
image = image.to(device)
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))