go语言之http2.0client源码分析
- client.Get
- NewRequest
- do request
- http2.Transport.
- RoundTrip
- GetClientConn
- newClientConn
- ReadFrame
- processHeaders
- write request
上一篇分析了http2.0的实现之后,这里分析一下client的实现。
package main
import (
"crypto/tls"
"crypto/x509"
"fmt"
"io/ioutil"
"net/http"
"os"
"strings"
"time"
"golang.org/x/net/http2"
)
func main() {
t := &http2.Transport{
TLSClientConfig: &tls.Config{
InsecureSkipVerify: true,
},
}
client := http.Client{Transport: t, Timeout: 15 * time.Second}
resp, err := client.Get("https://localhost:8084/")
if err != nil {
fmt.Printf("Failed get: %s\r\n", err)
return
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Printf("Failed reading response body: %s\r\n", err)
}
fmt.Printf("Client Got response %d: %s %s\r\n", resp.StatusCode, resp.Proto, string(body))
}
需要注意的是这里的http2.Transport.然后其他应该和普通的请求一样的。
client.Get
func (c *Client) Get(url string) (resp *Response, err error) {
// 默认是GET请求
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
// 发起请求
return c.Do(req)
}
NewRequest
// NewRequest wraps NewRequestWithContext using the background context.
func NewRequest(method, url string, body io.Reader) (*Request, error) {
return NewRequestWithContext(context.Background(), method, url, body)
}
func NewRequestWithContext(ctx context.Context, method, url string, body io.Reader) (*Request, error) {
// 判断方法
if method == "" {
// We document that "" means "GET" for Request.Method, and people have
// relied on that from NewRequest, so keep that working.
// We still enforce validMethod for non-empty methods.
method = "GET"
}
// 是否可靠的method
if !validMethod(method) {
return nil, fmt.Errorf("net/http: invalid method %q", method)
}
if ctx == nil {
return nil, errors.New("net/http: nil Context")
}
// 根据url进行解析
u, err := urlpkg.Parse(url)
if err != nil {
return nil, err
}
// 判断body类型加上判断
rc, ok := body.(io.ReadCloser)
if !ok && body != nil {
rc = io.NopCloser(body)
}
// The host's colon:port should be normalized. See Issue 14836.
// 获取host
u.Host = removeEmptyPort(u.Host)
// 实例化Request
req := &Request{
ctx: ctx,
Method: method,
URL: u,
Proto: "HTTP/1.1",
ProtoMajor: 1,
ProtoMinor: 1,
Header: make(Header),
Body: rc,
Host: u.Host,
}
// 设置body 判断类型
if body != nil {
switch v := body.(type) {
case *bytes.Buffer:
req.ContentLength = int64(v.Len())
buf := v.Bytes()
req.GetBody = func() (io.ReadCloser, error) {
r := bytes.NewReader(buf)
return io.NopCloser(r), nil
}
case *bytes.Reader:
req.ContentLength = int64(v.Len())
snapshot := *v
req.GetBody = func() (io.ReadCloser, error) {
r := snapshot
return io.NopCloser(&r), nil
}
case *strings.Reader:
req.ContentLength = int64(v.Len())
snapshot := *v
req.GetBody = func() (io.ReadCloser, error) {
r := snapshot
return io.NopCloser(&r), nil
}
default:
// This is where we'd set it to -1 (at least
// if body != NoBody) to mean unknown, but
// that broke people during the Go 1.8 testing
// period. People depend on it being 0 I
// guess. Maybe retry later. See Issue 18117.
}
// For client requests, Request.ContentLength of 0
// means either actually 0, or unknown. The only way
// to explicitly say that the ContentLength is zero is
// to set the Body to nil. But turns out too much code
// depends on NewRequest returning a non-nil Body,
// so we use a well-known ReadCloser variable instead
// and have the http package also treat that sentinel
// variable to mean explicitly zero.
if req.GetBody != nil && req.ContentLength == 0 {
req.Body = NoBody
req.GetBody = func() (io.ReadCloser, error) { return NoBody, nil }
}
}
return req, nil
}
do request
func (c *Client) do(req *Request) (retres *Response, reterr error) {
// 去掉一些校验
var (
deadline = c.deadline()
reqs []*Request
resp *Response
copyHeaders = c.makeHeadersCopier(req)
reqBodyClosed = false // have we closed the current req.Body?
// Redirect behavior:
redirectMethod string
includeBody bool
)
uerr := func(err error) error {
// the body may have been closed already by c.send()
if !reqBodyClosed {
req.closeBody()
}
var urlStr string
if resp != nil && resp.Request != nil {
urlStr = stripPassword(resp.Request.URL)
} else {
urlStr = stripPassword(req.URL)
}
return &url.Error{
Op: urlErrorOp(reqs[0].Method),
URL: urlStr,
Err: err,
}
}
for {
// 添加req
reqs = append(reqs, req)
var err error
var didTimeout func() bool
// 判断发送请求
if resp, didTimeout, err = c.send(req, deadline); err != nil {
// c.send() always closes req.Body
reqBodyClosed = true
if !deadline.IsZero() && didTimeout() {
err = &httpError{
// TODO: early in cycle: s/Client.Timeout exceeded/timeout or context cancellation/
err: err.Error() + " (Client.Timeout exceeded while awaiting headers)",
timeout: true,
}
}
return nil, uerr(err)
}
var shouldRedirect bool
redirectMethod, shouldRedirect, includeBody = redirectBehavior(req.Method, resp, reqs[0])
if !shouldRedirect {
return resp, nil
}
req.closeBody()
}
}
可以看出来主要就是send方法去发送请求。然后看一下send方法
// send issues an HTTP request.
// Caller should close resp.Body when done reading from it.
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
req := ireq // req is either the original request, or a modified fork
if !deadline.IsZero() {
forkReq()
}
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
resp, err = rt.RoundTrip(req)
if err != nil {
stopTimer()
if resp != nil {
log.Printf("RoundTripper returned a response & error; ignoring response")
}
if tlsErr, ok := err.(tls.RecordHeaderError); ok {
// If we get a bad TLS record header, check to see if the
// response looks like HTTP and give a more helpful error.
// See golang.org/issue/11111.
if string(tlsErr.RecordHeader[:]) == "HTTP/" {
err = errors.New("http: server gave HTTP response to HTTPS client")
}
}
return nil, didTimeout, err
}
if resp == nil {
return nil, didTimeout, fmt.Errorf("http: RoundTripper implementation (%T) returned a nil *Response with a nil error", rt)
}
if resp.Body == nil {
// The documentation on the Body field says “The http Client and Transport
// guarantee that Body is always non-nil, even on responses without a body
// or responses with a zero-length body.” Unfortunately, we didn't document
// that same constraint for arbitrary RoundTripper implementations, and
// RoundTripper implementations in the wild (mostly in tests) assume that
// they can use a nil Body to mean an empty one (similar to Request.Body).
// (See https://golang.org/issue/38095.)
//
// If the ContentLength allows the Body to be empty, fill in an empty one
// here to ensure that it is non-nil.
if resp.ContentLength > 0 && req.Method != "HEAD" {
return nil, didTimeout, fmt.Errorf("http: RoundTripper implementation (%T) returned a *Response with content length %d but a nil Body", rt, resp.ContentLength)
}
resp.Body = io.NopCloser(strings.NewReader(""))
}
if !deadline.IsZero() {
resp.Body = &cancelTimerBody{
stop: stopTimer,
rc: resp.Body,
reqDidTimeout: didTimeout,
}
}
return resp, nil, nil
}
可以看出来这个最终调用的rt.RoundTrip去获取的resp,这里我们传入的是http2.Transport.
http2.Transport.
这里首先看一下这个结构体
// Transport is an HTTP/2 Transport.
//
// A Transport internally caches connections to servers. It is safe
// for concurrent use by multiple goroutines.
type Transport struct {
// DialTLS specifies an optional dial function for creating
// TLS connections for requests.
//
// If DialTLS is nil, tls.Dial is used.
//
// If the returned net.Conn has a ConnectionState method like tls.Conn,
// it will be used to set http.Response.TLS.
DialTLS func(network, addr string, cfg *tls.Config) (net.Conn, error)
// TLSClientConfig specifies the TLS configuration to use with
// tls.Client. If nil, the default configuration is used.
TLSClientConfig *tls.Config
// ConnPool optionally specifies an alternate connection pool to use.
// If nil, the default is used.
ConnPool ClientConnPool
// DisableCompression, if true, prevents the Transport from
// requesting compression with an "Accept-Encoding: gzip"
// request header when the Request contains no existing
// Accept-Encoding value. If the Transport requests gzip on
// its own and gets a gzipped response, it's transparently
// decoded in the Response.Body. However, if the user
// explicitly requested gzip it is not automatically
// uncompressed.
DisableCompression bool
// AllowHTTP, if true, permits HTTP/2 requests using the insecure,
// plain-text "http" scheme. Note that this does not enable h2c support.
AllowHTTP bool
// MaxHeaderListSize is the http2 SETTINGS_MAX_HEADER_LIST_SIZE to
// send in the initial settings frame. It is how many bytes
// of response headers are allowed. Unlike the http2 spec, zero here
// means to use a default limit (currently 10MB). If you actually
// want to advertise an unlimited value to the peer, Transport
// interprets the highest possible value here (0xffffffff or 1<<32-1)
// to mean no limit.
MaxHeaderListSize uint32
// StrictMaxConcurrentStreams controls whether the server's
// SETTINGS_MAX_CONCURRENT_STREAMS should be respected
// globally. If false, new TCP connections are created to the
// server as needed to keep each under the per-connection
// SETTINGS_MAX_CONCURRENT_STREAMS limit. If true, the
// server's SETTINGS_MAX_CONCURRENT_STREAMS is interpreted as
// a global limit and callers of RoundTrip block when needed,
// waiting for their turn.
StrictMaxConcurrentStreams bool
// ReadIdleTimeout is the timeout after which a health check using ping
// frame will be carried out if no frame is received on the connection.
// Note that a ping response will is considered a received frame, so if
// there is no other traffic on the connection, the health check will
// be performed every ReadIdleTimeout interval.
// If zero, no health check is performed.
ReadIdleTimeout time.Duration
// PingTimeout is the timeout after which the connection will be closed
// if a response to Ping is not received.
// Defaults to 15s.
PingTimeout time.Duration
// WriteByteTimeout is the timeout after which the connection will be
// closed no data can be written to it. The timeout begins when data is
// available to write, and is extended whenever any bytes are written.
WriteByteTimeout time.Duration
// CountError, if non-nil, is called on HTTP/2 transport errors.
// It's intended to increment a metric for monitoring, such
// as an expvar or Prometheus metric.
// The errType consists of only ASCII word characters.
CountError func(errType string)
// t1, if non-nil, is the standard library Transport using
// this transport. Its settings are used (but not its
// RoundTrip method, etc).
t1 *http.Transport
connPoolOnce sync.Once
connPoolOrDef ClientConnPool // non-nil version of ConnPool
}
然后看一下具体实现的RoundTrip方法.
RoundTrip
func (t *Transport) RoundTrip(req *http.Request) (*http.Response, error) {
return t.RoundTripOpt(req, RoundTripOpt{})
}
// RoundTripOpt is like RoundTrip, but takes options.
func (t *Transport) RoundTripOpt(req *http.Request, opt RoundTripOpt) (*http.Response, error) {
if !(req.URL.Scheme == "https" || (req.URL.Scheme == "http" && t.AllowHTTP)) {
return nil, errors.New("http2: unsupported scheme")
}
addr := authorityAddr(req.URL.Scheme, req.URL.Host)
for retry := 0; ; retry++ {
// 获取连接
cc, err := t.connPool().GetClientConn(req, addr)
if err != nil {
t.vlogf("http2: Transport failed to get client conn for %s: %v", addr, err)
return nil, err
}
reused := !atomic.CompareAndSwapUint32(&cc.reused, 0, 1)
traceGotConn(req, cc, reused)
// 获取响应
res, err := cc.RoundTrip(req)
if err != nil && retry <= 6 {
// 重试
if req, err = shouldRetryRequest(req, err); err == nil {
// After the first retry, do exponential backoff with 10% jitter.
if retry == 0 {
t.vlogf("RoundTrip retrying after failure: %v", err)
continue
}
backoff := float64(uint(1) << (uint(retry) - 1))
backoff += backoff * (0.1 * mathrand.Float64())
select {
case <-time.After(time.Second * time.Duration(backoff)):
t.vlogf("RoundTrip retrying after failure: %v", err)
continue
case <-req.Context().Done():
err = req.Context().Err()
}
}
}
if err != nil {
t.vlogf("RoundTrip failure: %v", err)
return nil, err
}
return res, nil
}
}
从代码可以看出来,主要就是从t.connPool().GetClientConn中去获取连接,然后获取到了连接之后再调用RoundTrip方法。
GetClientConn
首先看一下t.connPool()方法,
func (t *Transport) connPool() ClientConnPool {
t.connPoolOnce.Do(t.initConnPool)
return t.connPoolOrDef
}
func (t *Transport) initConnPool() {
if t.ConnPool != nil {
t.connPoolOrDef = t.ConnPool
} else {
t.connPoolOrDef = &clientConnPool{t: t}
}
}
可以看出了t.connPool()其实就是返回了clientConnPool这个结构体,然后调用clientConnPool这个GetClientConn方法。
func (p *clientConnPool) GetClientConn(req *http.Request, addr string) (*ClientConn, error) {
return p.getClientConn(req, addr, dialOnMiss)
}
这个req就是之前实例化的request,然后addr就是填入的"localhost:8084"。
func (p *clientConnPool) getClientConn(req *http.Request, addr string, dialOnMiss bool) (*ClientConn, error) {
// TODO(dneil): Dial a new connection when t.DisableKeepAlives is set?
// 判断是否要新建一个连接 isConnectionCloseRequest 代表这个连接已经被关闭因为需要新建一个连接
if isConnectionCloseRequest(req) && dialOnMiss {
// It gets its own connection.
traceGetConn(req, addr)
const singleUse = true
cc, err := p.t.dialClientConn(req.Context(), addr, singleUse)
if err != nil {
return nil, err
}
return cc, nil
}
for {
p.mu.Lock()
// 进行连接复用 判断域名下面是否有可用的连接
for _, cc := range p.conns[addr] {
// 判断连接是否可以复用
if cc.ReserveNewRequest() {
// When a connection is presented to us by the net/http package,
// the GetConn hook has already been called.
// Don't call it a second time here.
if !cc.getConnCalled {
traceGetConn(req, addr)
}
cc.getConnCalled = false
p.mu.Unlock()
return cc, nil
}
}
if !dialOnMiss {
p.mu.Unlock()
return nil, ErrNoCachedConn
}
traceGetConn(req, addr)
// 新创建一个连接
call := p.getStartDialLocked(req.Context(), addr)
p.mu.Unlock()
<-call.done
if shouldRetryDial(call, req) {
continue
}
cc, err := call.res, call.err
if err != nil {
return nil, err
}
if cc.ReserveNewRequest() {
return cc, nil
}
}
}
这里的这样逻辑就是首先判断这个这个域名下面是否有已经可以使用的连接,也就是循环p.conns.如果没有那么调用getStartDialLocked去生成一个新的连接。
// requires p.mu is held.
func (p *clientConnPool) getStartDialLocked(ctx context.Context, addr string) *dialCall {
if call, ok := p.dialing[addr]; ok {
// A dial is already in-flight. Don't start another.
return call
}
// 生成一个新的结构体
call := &dialCall{p: p, done: make(chan struct{}), ctx: ctx}
if p.dialing == nil {
p.dialing = make(map[string]*dialCall)
}
// 存到缓存中
p.dialing[addr] = call
// 去创建tcp连接
go call.dial(call.ctx, addr)
return call
}
// run in its own goroutine.
func (c *dialCall) dial(ctx context.Context, addr string) {
const singleUse = false // shared conn
// 生成连接
c.res, c.err = c.p.t.dialClientConn(ctx, addr, singleUse)
close(c.done)
c.p.mu.Lock()
delete(c.p.dialing, addr)
if c.err == nil {
c.p.addConnLocked(addr, c.res)
}
c.p.mu.Unlock()
}
func (t *Transport) dialClientConn(ctx context.Context, addr string, singleUse bool) (*ClientConn, error) {
host, _, err := net.SplitHostPort(addr)
if err != nil {
return nil, err
}
tconn, err := t.dialTLS(ctx)("tcp", addr, t.newTLSConfig(host))
if err != nil {
return nil, err
}
return t.newClientConn(tconn, singleUse)
}
可以看出来这里是通过dialTLS去生成底层的tcp连接,在生成完了之后,在调用newClientConn去封装一层,注意这里的singleUse传入的是false.然后看一下newClientConn 这个方法。
newClientConn
func (t *Transport) newClientConn(c net.Conn, singleUse bool) (*ClientConn, error) {
// 实例化ClientConn
cc := &ClientConn{
t: t,
tconn: c,
readerDone: make(chan struct{}),
nextStreamID: 1,
maxFrameSize: 16 << 10, // spec default
initialWindowSize: 65535, // spec default
maxConcurrentStreams: initialMaxConcurrentStreams, // "infinite", per spec. Use a smaller value until we have received server settings.
peerMaxHeaderListSize: 0xffffffffffffffff, // "infinite", per spec. Use 2^64-1 instead.
streams: make(map[uint32]*clientStream),
singleUse: singleUse,
wantSettingsAck: true,
pings: make(map[[8]byte]chan struct{}),
reqHeaderMu: make(chan struct{}, 1),
}
if d := t.idleConnTimeout(); d != 0 {
cc.idleTimeout = d
cc.idleTimer = time.AfterFunc(d, cc.onIdleTimeout)
}
if VerboseLogs {
t.vlogf("http2: Transport creating client conn %p to %v", cc, c.RemoteAddr())
}
cc.cond = sync.NewCond(&cc.mu)
// 流控
cc.flow.add(int32(initialWindowSize))
// TODO: adjust this writer size to account for frame size +
// MTU + learn/http/go/crypto/tls record padding.
cc.bw = bufio.NewWriter(stickyErrWriter{
conn: c,
timeout: t.WriteByteTimeout,
err: &cc.werr,
})
cc.br = bufio.NewReader(c)
// 实例化framer 这个tcp中的最小单元
cc.fr = NewFramer(cc.bw, cc.br)
if t.CountError != nil {
cc.fr.countError = t.CountError
}
// header头 是使用hpack算法
cc.fr.ReadMetaHeaders = hpack.NewDecoder(initialHeaderTableSize, nil)
// 最大header的size
cc.fr.MaxHeaderListSize = t.maxHeaderListSize()
// TODO: SetMaxDynamicTableSize, SetMaxDynamicTableSizeLimit on
// henc in response to SETTINGS frames?
cc.henc = hpack.NewEncoder(&cc.hbuf)
if t.AllowHTTP {
cc.nextStreamID = 3
}
if cs, ok := c.(connectionStater); ok {
state := cs.ConnectionState()
cc.tlsState = &state
}
// 发送初始化设置请求
initialSettings := []Setting{
{ID: SettingEnablePush, Val: 0},
{ID: SettingInitialWindowSize, Val: transportDefaultStreamFlow},
}
if max := t.maxHeaderListSize(); max != 0 {
initialSettings = append(initialSettings, Setting{ID: SettingMaxHeaderListSize, Val: max})
}
cc.bw.Write(clientPreface)
cc.fr.WriteSettings(initialSettings...)
cc.fr.WriteWindowUpdate(0, transportDefaultConnFlow)
cc.inflow.add(transportDefaultConnFlow + initialWindowSize)
cc.bw.Flush()
// 判断是否成功
if cc.werr != nil {
cc.Close()
return nil, cc.werr
}
// 异步进行读取
go cc.readLoop()
return cc, nil
}
这里可以看出来主要是发一个初始化的请求之后,就返回了,然后进行异步读取,也就是readLoop这个方法。
// readLoop runs in its own goroutine and reads and dispatches frames.
func (cc *ClientConn) readLoop() {
rl := &clientConnReadLoop{cc: cc}
defer rl.cleanup()
cc.readerErr = rl.run()
if ce, ok := cc.readerErr.(ConnectionError); ok {
cc.wmu.Lock()
cc.fr.WriteGoAway(0, ErrCode(ce), nil)
cc.wmu.Unlock()
}
}
func (rl *clientConnReadLoop) run() error {
cc := rl.cc
gotSettings := false
readIdleTimeout := cc.t.ReadIdleTimeout
var t *time.Timer
if readIdleTimeout != 0 {
t = time.AfterFunc(readIdleTimeout, cc.healthCheck)
defer t.Stop()
}
for {
// 读取frame
f, err := cc.fr.ReadFrame()
if t != nil {
t.Reset(readIdleTimeout)
}
if err != nil {
cc.vlogf("http2: Transport readFrame error on conn %p: (%T) %v", cc, err, err)
}
if se, ok := err.(StreamError); ok {
if cs := rl.streamByID(se.StreamID); cs != nil {
if se.Cause == nil {
se.Cause = cc.fr.errDetail
}
rl.endStreamError(cs, se)
}
continue
} else if err != nil {
cc.countReadFrameError(err)
return err
}
if VerboseLogs {
cc.vlogf("http2: Transport received %s", summarizeFrame(f))
}
if !gotSettings {
if _, ok := f.(*SettingsFrame); !ok {
cc.logf("protocol error: received %T before a SETTINGS frame", f)
return ConnectionError(ErrCodeProtocol)
}
gotSettings = true
}
// 根据f的类型去进行不同的操作
// 这里也可以看出frame的类型有哪些
switch f := f.(type) {
case *MetaHeadersFrame:
err = rl.processHeaders(f)
case *DataFrame:
err = rl.processData(f)
case *GoAwayFrame:
err = rl.processGoAway(f)
case *RSTStreamFrame:
err = rl.processResetStream(f)
case *SettingsFrame:
err = rl.processSettings(f)
case *PushPromiseFrame:
err = rl.processPushPromise(f)
case *WindowUpdateFrame:
err = rl.processWindowUpdate(f)
case *PingFrame:
err = rl.processPing(f)
default:
cc.logf("Transport: unhandled response frame type %T", f)
}
if err != nil {
if VerboseLogs {
cc.vlogf("http2: Transport conn %p received error from processing frame %v: %v", cc, summarizeFrame(f), err)
}
return err
}
}
}
ReadFrame
// ReadFrame reads a single frame. The returned Frame is only valid
// until the next call to ReadFrame.
//
// If the frame is larger than previously set with SetMaxReadFrameSize, the
// returned error is ErrFrameTooLarge. Other errors may be of type
// ConnectionError, StreamError, or anything else from the underlying
// reader.
func (fr *Framer) ReadFrame() (Frame, error) {
fr.errDetail = nil
if fr.lastFrame != nil {
fr.lastFrame.invalidate()
}
// 读取frame的header
fh, err := readFrameHeader(fr.headerBuf[:], fr.r)
if err != nil {
return nil, err
}
if fh.Length > fr.maxReadSize {
return nil, ErrFrameTooLarge
}
// 读取内容
payload := fr.getReadBuf(fh.Length)
if _, err := io.ReadFull(fr.r, payload); err != nil {
return nil, err
}
// 根据frame不同的类型获取不同的parse
f, err := typeFrameParser(fh.Type)(fr.frameCache, fh, fr.countError, payload)
if err != nil {
if ce, ok := err.(connError); ok {
return nil, fr.connError(ce.Code, ce.Reason)
}
return nil, err
}
// 检验frame的顺序
if err := fr.checkFrameOrder(f); err != nil {
return nil, err
}
if fr.logReads {
fr.debugReadLoggerf("http2: Framer %p: read %v", fr, summarizeFrame(f))
}
if fh.Type == FrameHeaders && fr.ReadMetaHeaders != nil {
return fr.readMetaFrame(f.(*HeadersFrame))
}
return f, nil
}
先看看读取frame的header。从这里也可以看出fram的请求头,分别是leagth,type,flags,streamId,valid.这五个字段。
func readFrameHeader(buf []byte, r io.Reader) (FrameHeader, error) {
_, err := io.ReadFull(r, buf[:frameHeaderLen])
if err != nil {
return FrameHeader{}, err
}
return FrameHeader{
Length: (uint32(buf[0])<<16 | uint32(buf[1])<<8 | uint32(buf[2])),
Type: FrameType(buf[3]),
Flags: Flags(buf[4]),
StreamID: binary.BigEndian.Uint32(buf[5:]) & (1<<31 - 1),
valid: true,
}, nil
}
然后看一下typeFrameParser,这个其实就是根据从map中获取不同的解析方法,
func typeFrameParser(t FrameType) frameParser {
if f := frameParsers[t]; f != nil {
return f
}
return parseUnknownFrame
}
var frameParsers = map[FrameType]frameParser{
FrameData: parseDataFrame,
FrameHeaders: parseHeadersFrame,
FramePriority: parsePriorityFrame,
FrameRSTStream: parseRSTStreamFrame,
FrameSettings: parseSettingsFrame,
FramePushPromise: parsePushPromise,
FramePing: parsePingFrame,
FrameGoAway: parseGoAwayFrame,
FrameWindowUpdate: parseWindowUpdateFrame,
FrameContinuation: parseContinuationFrame,
}
这里选择parseDataFrame和parseHeadersFrame看一下。
func parseDataFrame(fc *frameCache, fh FrameHeader, countError func(string), payload []byte) (Frame, error) {
if fh.StreamID == 0 {
// DATA frames MUST be associated with a stream. If a
// DATA frame is received whose stream identifier
// field is 0x0, the recipient MUST respond with a
// connection error (Section 5.4.1) of type
// PROTOCOL_ERROR.
countError("frame_data_stream_0")
return nil, connError{ErrCodeProtocol, "DATA frame with stream ID 0"}
}
f := fc.getDataFrame()
f.FrameHeader = fh
var padSize byte
if fh.Flags.Has(FlagDataPadded) {
var err error
payload, padSize, err = readByte(payload)
if err != nil {
countError("frame_data_pad_byte_short")
return nil, err
}
}
if int(padSize) > len(payload) {
// If the length of the padding is greater than the
// length of the frame payload, the recipient MUST
// treat this as a connection error.
// Filed: https://github.com/http2/http2-spec/issues/610
countError("frame_data_pad_too_big")
return nil, connError{ErrCodeProtocol, "pad size larger than data payload"}
}
f.data = payload[:len(payload)-int(padSize)]
return f, nil
}
其实这里的核心就是把payload中的内容放到f.data中去。
func parseHeadersFrame(_ *frameCache, fh FrameHeader, countError func(string), p []byte) (_ Frame, err error) {
hf := &HeadersFrame{
FrameHeader: fh,
}
if fh.StreamID == 0 {
// HEADERS frames MUST be associated with a stream. If a HEADERS frame
// is received whose stream identifier field is 0x0, the recipient MUST
// respond with a connection error (Section 5.4.1) of type
// PROTOCOL_ERROR.
countError("frame_headers_zero_stream")
return nil, connError{ErrCodeProtocol, "HEADERS frame with stream ID 0"}
}
var padLength uint8
if fh.Flags.Has(FlagHeadersPadded) {
if p, padLength, err = readByte(p); err != nil {
countError("frame_headers_pad_short")
return
}
}
if fh.Flags.Has(FlagHeadersPriority) {
var v uint32
p, v, err = readUint32(p)
if err != nil {
countError("frame_headers_prio_short")
return nil, err
}
hf.Priority.StreamDep = v & 0x7fffffff
hf.Priority.Exclusive = (v != hf.Priority.StreamDep) // high bit was set
p, hf.Priority.Weight, err = readByte(p)
if err != nil {
countError("frame_headers_prio_weight_short")
return nil, err
}
}
if len(p)-int(padLength) < 0 {
countError("frame_headers_pad_too_big")
return nil, streamError(fh.StreamID, ErrCodeProtocol)
}
hf.headerFragBuf = p[:len(p)-int(padLength)]
return hf, nil
}
然后看parseHeadersFrame其实内容也是差不多,就是将内容放到hf.headerFragBuf中去,然后将hf进行返回。
然后就是进行对不同的frame进行处理.也就是
switch f := f.(type) {
case *MetaHeadersFrame:
err = rl.processHeaders(f)
case *DataFrame:
err = rl.processData(f)
case *GoAwayFrame:
err = rl.processGoAway(f)
case *RSTStreamFrame:
err = rl.processResetStream(f)
case *SettingsFrame:
err = rl.processSettings(f)
case *PushPromiseFrame:
err = rl.processPushPromise(f)
case *WindowUpdateFrame:
err = rl.processWindowUpdate(f)
case *PingFrame:
err = rl.processPing(f)
default:
cc.logf("Transport: unhandled response frame type %T", f)
}
这里还是一样,可以看看processHeaders和processData 这两个方法。
processHeaders
func (rl *clientConnReadLoop) processHeaders(f *MetaHeadersFrame) error {
cs := rl.streamByID(f.StreamID)
if cs == nil {
// We'd get here if we canceled a request while the
// server had its response still in flight. So if this
// was just something we canceled, ignore it.
return nil
}
if cs.readClosed {
rl.endStreamError(cs, StreamError{
StreamID: f.StreamID,
Code: ErrCodeProtocol,
Cause: errors.New("protocol error: headers after END_STREAM"),
})
return nil
}
if !cs.firstByte {
if cs.trace != nil {
// TODO(bradfitz): move first response byte earlier,
// when we first read the 9 byte header, not waiting
// until all the HEADERS+CONTINUATION frames have been
// merged. This works for now.
traceFirstResponseByte(cs.trace)
}
cs.firstByte = true
}
if !cs.pastHeaders {
cs.pastHeaders = true
} else {
return rl.processTrailers(cs, f)
}
// 写入response
res, err := rl.handleResponse(cs, f)
if err != nil {
if _, ok := err.(ConnectionError); ok {
return err
}
// Any other error type is a stream error.
rl.endStreamError(cs, StreamError{
StreamID: f.StreamID,
Code: ErrCodeProtocol,
Cause: err,
})
return nil // return nil from process* funcs to keep conn alive
}
if res == nil {
// (nil, nil) special case. See handleResponse docs.
return nil
}
cs.resTrailer = &res.Trailer
cs.res = res
// 通知异步协程
close(cs.respHeaderRecv)
if f.StreamEnded() {
rl.endStream(cs)
}
return nil
}
抛开一些特殊的处理逻辑,这里的主要逻辑是调用handleResponse获取res,然后close掉cs.respHeaderRecv,通知异步协程处理res然后看一下handleResponse这个方法
// may return error types nil, or ConnectionError. Any other error value
// is a StreamError of type ErrCodeProtocol. The returned error in that case
// is the detail.
//
// As a special case, handleResponse may return (nil, nil) to skip the
// frame (currently only used for 1xx responses).
func (rl *clientConnReadLoop) handleResponse(cs *clientStream, f *MetaHeadersFrame) (*http.Response, error) {
if f.Truncated {
return nil, errResponseHeaderListSize
}
regularFields := f.RegularFields()
strs := make([]string, len(regularFields))
header := make(http.Header, len(regularFields))
res := &http.Response{
Proto: "HTTP/2.0",
ProtoMajor: 2,
Header: header,
StatusCode: statusCode,
Status: status + " " + http.StatusText(statusCode),
}
// 删除一些异常判断
cs.bufPipe.setBuffer(&dataBuffer{expected: res.ContentLength})
cs.bytesRemain = res.ContentLength
res.Body = transportResponseBody{cs}
return res, nil
}
可以看出来这个主要就是创建了http.Response这个方法,写入proto等信息,然后进行返回。
然后看一下processData这个方法
func (rl *clientConnReadLoop) processData(f *DataFrame) error {
cc := rl.cc
cs := rl.streamByID(f.StreamID)
// 从server端传过来的数据
data := f.Data()
// 是否有数据需要写入
if f.Length > 0 {
if cs.isHead && len(data) > 0 {
cc.logf("protocol error: received DATA on a HEAD request")
rl.endStreamError(cs, StreamError{
StreamID: f.StreamID,
Code: ErrCodeProtocol,
})
return nil
}
// Check connection-level flow control.
cc.mu.Lock()
if cs.inflow.available() >= int32(f.Length) {
cs.inflow.take(int32(f.Length))
} else {
cc.mu.Unlock()
return ConnectionError(ErrCodeFlowControl)
}
// Return any padded flow control now, since we won't
// refund it later on body reads.
var refund int
if pad := int(f.Length) - len(data); pad > 0 {
refund += pad
}
didReset := false
var err error
if len(data) > 0 {
// 写入到bufPipe
if _, err = cs.bufPipe.Write(data); err != nil {
// Return len(data) now if the stream is already closed,
// since data will never be read.
didReset = true
refund += len(data)
}
}
if refund > 0 {
cc.inflow.add(int32(refund))
if !didReset {
cs.inflow.add(int32(refund))
}
}
cc.mu.Unlock()
if refund > 0 {
cc.wmu.Lock()
cc.fr.WriteWindowUpdate(0, uint32(refund))
if !didReset {
cc.fr.WriteWindowUpdate(cs.ID, uint32(refund))
}
cc.bw.Flush()
cc.wmu.Unlock()
}
if err != nil {
rl.endStreamError(cs, err)
return nil
}
}
if f.StreamEnded() {
rl.endStream(cs)
}
return nil
}
这个时候已经服务端传过来的数据,已经存到Data中了,然后length大于0.最后是写入到 cs.bufPipe.Write中去。
write request
这个上面读取的逻辑接下来看一下写入的逻辑。也就是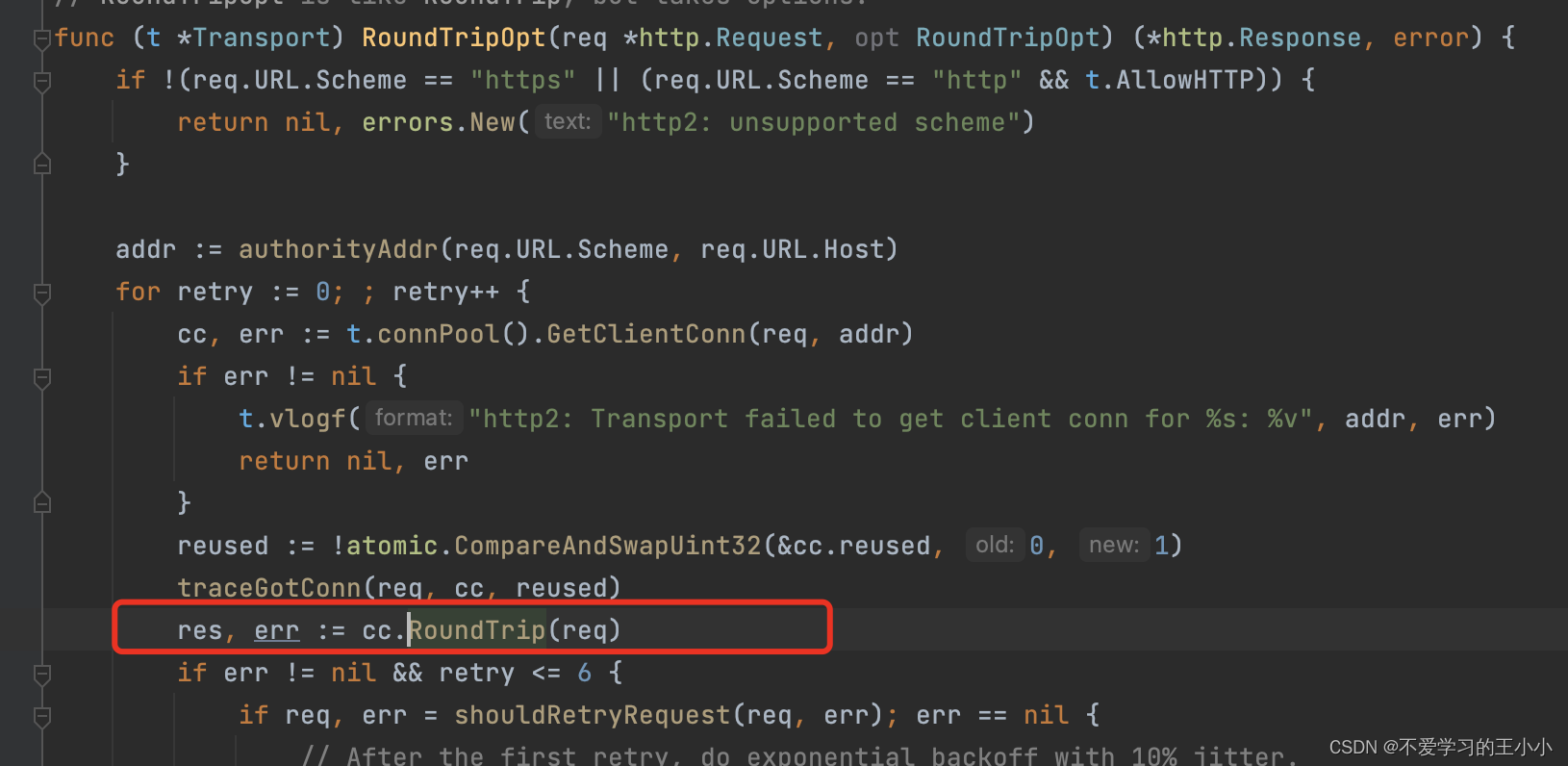
这里已经拿到了连接,看一下ClientConn中的RoundTrip方法。
func (cc *ClientConn) RoundTrip(req *http.Request) (*http.Response, error) {
ctx := req.Context()
cs := &clientStream{
cc: cc,
ctx: ctx,
reqCancel: req.Cancel,
isHead: req.Method == "HEAD",
reqBody: req.Body,
reqBodyContentLength: actualContentLength(req),
trace: httptrace.ContextClientTrace(ctx),
peerClosed: make(chan struct{}),
abort: make(chan struct{}),
respHeaderRecv: make(chan struct{}),
donec: make(chan struct{}),
}
// 发起请求
go cs.doRequest(req)
waitDone := func() error {
select {
case <-cs.donec:
return nil
case <-ctx.Done():
return ctx.Err()
case <-cs.reqCancel:
return errRequestCanceled
}
}
handleResponseHeaders := func() (*http.Response, error) {
res := cs.res
if res.StatusCode > 299 {
// On error or status code 3xx, 4xx, 5xx, etc abort any
// ongoing write, assuming that the server doesn't care
// about our request body. If the server replied with 1xx or
// 2xx, however, then assume the server DOES potentially
// want our body (e.g. full-duplex streaming:
// golang.org/issue/13444). If it turns out the server
// doesn't, they'll RST_STREAM us soon enough. This is a
// heuristic to avoid adding knobs to Transport. Hopefully
// we can keep it.
cs.abortRequestBodyWrite()
}
res.Request = req
res.TLS = cc.tlsState
if res.Body == noBody && actualContentLength(req) == 0 {
// If there isn't a request or response body still being
// written, then wait for the stream to be closed before
// RoundTrip returns.
if err := waitDone(); err != nil {
return nil, err
}
}
return res, nil
}
// 进行等待事件的发生
for {
select {
case <-cs.respHeaderRecv:
return handleResponseHeaders()
case <-cs.abort:
select {
case <-cs.respHeaderRecv:
// If both cs.respHeaderRecv and cs.abort are signaling,
// pick respHeaderRecv. The server probably wrote the
// response and immediately reset the stream.
// golang.org/issue/49645
return handleResponseHeaders()
default:
waitDone()
return nil, cs.abortErr
}
case <-ctx.Done():
err := ctx.Err()
cs.abortStream(err)
return nil, err
case <-cs.reqCancel:
cs.abortStream(errRequestCanceled)
return nil, errRequestCanceled
}
}
}
看一下doRequest的这个方法.
// doRequest runs for the duration of the request lifetime.
//
// It sends the request and performs post-request cleanup (closing Request.Body, etc.).
func (cs *clientStream) doRequest(req *http.Request) {
err := cs.writeRequest(req)
cs.cleanupWriteRequest(err)
}
这里主要是writeRequest这个方法.cleanupWriteRequest方法主要是检测发完送连接的状态。
// writeRequest sends a request.
//
// It returns nil after the request is written, the response read,
// and the request stream is half-closed by the peer.
//
// It returns non-nil if the request ends otherwise.
// If the returned error is StreamError, the error Code may be used in resetting the stream.
func (cs *clientStream) writeRequest(req *http.Request) (err error) {
cc := cs.cc
ctx := cs.ctx
if err := checkConnHeaders(req); err != nil {
return err
}
// Acquire the new-request lock by writing to reqHeaderMu.
// This lock guards the critical section covering allocating a new stream ID
// (requires mu) and creating the stream (requires wmu).
if cc.reqHeaderMu == nil {
panic("RoundTrip on uninitialized ClientConn") // for tests
}
select {
case cc.reqHeaderMu <- struct{}{}:
case <-cs.reqCancel:
return errRequestCanceled
case <-ctx.Done():
return ctx.Err()
}
cc.mu.Lock()
if cc.idleTimer != nil {
cc.idleTimer.Stop()
}
cc.mu.Unlock()
continueTimeout := cc.t.expectContinueTimeout()
if continueTimeout != 0 {
if !httpguts.HeaderValuesContainsToken(req.Header["Expect"], "100-continue") {
continueTimeout = 0
} else {
cs.on100 = make(chan struct{}, 1)
}
}
// Past this point (where we send request headers), it is possible for
// RoundTrip to return successfully. Since the RoundTrip contract permits
// the caller to "mutate or reuse" the Request after closing the Response's Body,
// we must take care when referencing the Request from here on.
// 加载头部
err = cs.encodeAndWriteHeaders(req)
<-cc.reqHeaderMu
if err != nil {
return err
}
// 判断是否有body
hasBody := cs.reqBodyContentLength != 0
if !hasBody {
cs.sentEndStream = true
} else {
if continueTimeout != 0 {
traceWait100Continue(cs.trace)
timer := time.NewTimer(continueTimeout)
select {
case <-timer.C:
err = nil
case <-cs.on100:
err = nil
case <-cs.abort:
err = cs.abortErr
case <-ctx.Done():
err = ctx.Err()
case <-cs.reqCancel:
err = errRequestCanceled
}
timer.Stop()
if err != nil {
traceWroteRequest(cs.trace, err)
return err
}
}
if err = cs.writeRequestBody(req); err != nil {
if err != errStopReqBodyWrite {
traceWroteRequest(cs.trace, err)
return err
}
} else {
cs.sentEndStream = true
}
}
traceWroteRequest(cs.trace, err)
var respHeaderTimer <-chan time.Time
var respHeaderRecv chan struct{}
if d := cc.responseHeaderTimeout(); d != 0 {
timer := time.NewTimer(d)
defer timer.Stop()
respHeaderTimer = timer.C
respHeaderRecv = cs.respHeaderRecv
}
// Wait until the peer half-closes its end of the stream,
// or until the request is aborted (via context, error, or otherwise),
// whichever comes first.
for {
select {
case <-cs.peerClosed:
return nil
case <-respHeaderTimer:
return errTimeout
case <-respHeaderRecv:
respHeaderRecv = nil
respHeaderTimer = nil // keep waiting for END_STREAM
case <-cs.abort:
return cs.abortErr
case <-ctx.Done():
return ctx.Err()
case <-cs.reqCancel:
return errRequestCanceled
}
}
}
针对没有body的情况,这里主要是调用了encodeAndWriteHeaders这个方法。
func (cs *clientStream) encodeAndWriteHeaders(req *http.Request) error {
cc := cs.cc
ctx := cs.ctx
cc.wmu.Lock()
defer cc.wmu.Unlock()
// If the request was canceled while waiting for cc.mu, just quit.
// 判断连接的状态
select {
case <-cs.abort:
return cs.abortErr
case <-ctx.Done():
return ctx.Err()
case <-cs.reqCancel:
return errRequestCanceled
default:
}
// Encode headers.
//
// we send: HEADERS{1}, CONTINUATION{0,} + DATA{0,} (DATA is
// sent by writeRequestBody below, along with any Trailers,
// again in form HEADERS{1}, CONTINUATION{0,})
trailers, err := commaSeparatedTrailers(req)
if err != nil {
return err
}
hasTrailers := trailers != ""
contentLen := actualContentLength(req)
hasBody := contentLen != 0
// 加载header
hdrs, err := cc.encodeHeaders(req, cs.requestedGzip, trailers, contentLen)
if err != nil {
return err
}
// Write the request.
endStream := !hasBody && !hasTrailers
cs.sentHeaders = true
err = cc.writeHeaders(cs.ID, endStream, int(cc.maxFrameSize), hdrs)
traceWroteHeaders(cs.trace)
return err
}
这里是使用hpack加载了头部。然后调用writeHeaders写入到了连接中。
// requires cc.wmu be held
func (cc *ClientConn) writeHeaders(streamID uint32, endStream bool, maxFrameSize int, hdrs []byte) error {
first := true // first frame written (HEADERS is first, then CONTINUATION)
for len(hdrs) > 0 && cc.werr == nil {
chunk := hdrs
if len(chunk) > maxFrameSize {
chunk = chunk[:maxFrameSize]
}
hdrs = hdrs[len(chunk):]
endHeaders := len(hdrs) == 0
if first {
cc.fr.WriteHeaders(HeadersFrameParam{
StreamID: streamID,
BlockFragment: chunk,
EndStream: endStream,
EndHeaders: endHeaders,
})
first = false
} else {
cc.fr.WriteContinuation(streamID, endHeaders, chunk)
}
}
cc.bw.Flush()
return cc.werr
}
最后是调用cc.fr.WriteHeaders写入。其中cc.fr 就是frame。然后看一下frame的WriteHeaders的具体的实现。
// WriteHeaders writes a single HEADERS frame.
//
// This is a low-level header writing method. Encoding headers and
// splitting them into any necessary CONTINUATION frames is handled
// elsewhere.
//
// It will perform exactly one Write to the underlying Writer.
// It is the caller's responsibility to not call other Write methods concurrently.
func (f *Framer) WriteHeaders(p HeadersFrameParam) error {
if !validStreamID(p.StreamID) && !f.AllowIllegalWrites {
return errStreamID
}
var flags Flags
if p.PadLength != 0 {
flags |= FlagHeadersPadded
}
if p.EndStream {
flags |= FlagHeadersEndStream
}
if p.EndHeaders {
flags |= FlagHeadersEndHeaders
}
if !p.Priority.IsZero() {
flags |= FlagHeadersPriority
}
f.startWrite(FrameHeaders, flags, p.StreamID)
if p.PadLength != 0 {
f.writeByte(p.PadLength)
}
if !p.Priority.IsZero() {
v := p.Priority.StreamDep
if !validStreamIDOrZero(v) && !f.AllowIllegalWrites {
return errDepStreamID
}
if p.Priority.Exclusive {
v |= 1 << 31
}
f.writeUint32(v)
f.writeByte(p.Priority.Weight)
}
f.wbuf = append(f.wbuf, p.BlockFragment...)
f.wbuf = append(f.wbuf, padZeros[:p.PadLength]...)
return f.endWrite()
}
func (f *Framer) startWrite(ftype FrameType, flags Flags, streamID uint32) {
// Write the FrameHeader.
f.wbuf = append(f.wbuf[:0],
0, // 3 bytes of length, filled in in endWrite
0,
0,
byte(ftype),
byte(flags),
byte(streamID>>24),
byte(streamID>>16),
byte(streamID>>8),
byte(streamID))
}
func (f *Framer) endWrite() error {
// Now that we know the final size, fill in the FrameHeader in
// the space previously reserved for it. Abuse append.
length := len(f.wbuf) - frameHeaderLen
if length >= (1 << 24) {
return ErrFrameTooLarge
}
_ = append(f.wbuf[:0],
byte(length>>16),
byte(length>>8),
byte(length))
if f.logWrites {
f.logWrite()
}
n, err := f.w.Write(f.wbuf)
if err == nil && n != len(f.wbuf) {
err = io.ErrShortWrite
}
return err
}
最后分别调用startWrite 和endWrite完成写入。然后就是异步协程等待通知。





![【SpringBoot高级篇】SpringBoot集成RocketMQ消息队列]](https://img-blog.csdnimg.cn/fea2a79aafb5459880a838e38d727ac9.png)