因作者近期正在投递数据开发岗位,所以会在此记录一些面试过程中的问题,持续更新,直到入职新公司为止
1. 数仓建模的三范式理论
所谓的范式,就是我们在关系建模的时候所遵从的一些规范,而三范式,指的就是三条规范
1.1 优点与缺点
优点:
- 十几年前,磁盘很贵,为了减少磁盘存储
- 以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的
- 一次修改,需要修改多个表,很难保证数据一致性
即使是在当下,第三条仍然是一大优点
缺点:
- 会产生很多张表,导致在获取数据时,需要通过Join拼接出最后的数据
1.2 三范式
1.2.1 第一范式
第一范式1NF核心原则就是:属性不可切。
这里所谓的属性,就是我们表中的字段,字段内容是不可切的,字段必须是原子性的,我们举个例子。
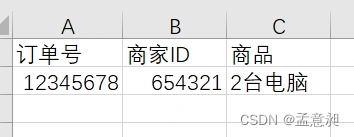
上面这张图就不符合第一范式,因为商品字段仍然可以进行切分,可以将【2台电脑】放在两个字段里存储
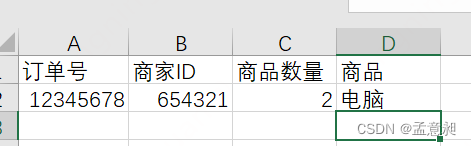
这个时候,就会说已经满足了第一范式(1NF)
1.2.2 第二范式
第二范式2NF核心原则就是:不能存在部分依赖
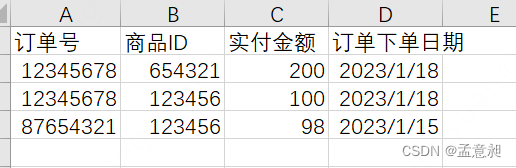
在下面这个例子里,就不符合第二范式,因为【订单号】和【商品ID】作为联合主键,【实付金额】字段会由【订单号】和【商品ID】共同确定,但【订单下单日期】却和【商品ID】字段没有关系,由【订单号】字段就能确定,所以【订单下单日期】就存在部份依赖,这时候就不符合第二范式
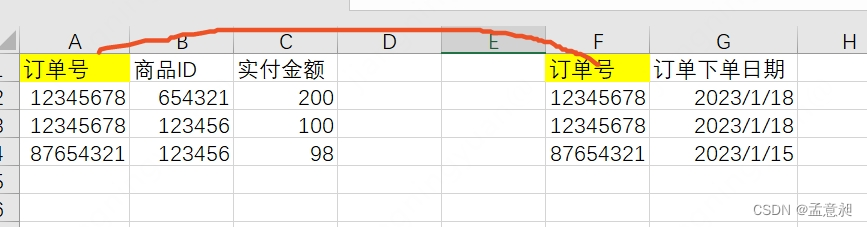
而处理的方法也很简单,只需要在当前表里去掉【订单下单日期】,新建一张表,存放【订单号】和【订单下单日期】就可以了,在使用的时候,可以通过【订单号】进行关联
1.2.3 第三范式
第三范式3NF核心原则:不能存在传递依赖
在下面这个例子里,就不符合第三范式,可以看到【订单下单时间】是【订单号】的时间属性,【店铺ID】也是可以直接通过【订单号】查询得到,但【店铺所在地区】却不是通过【订单号】直接获取,而是由【店铺ID】获得的,所以这里就存在传递依赖,因此不符合第三范式
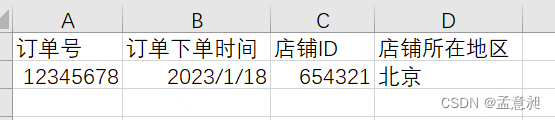
解决方式也很简单,拆成两张表就可以了

1.3. 三范式总结
其实这3个规范条件,说白了就是在确定表里的主键,定好唯一维度,表里也不存其他的信息,字段都是和主键直接有关的内容,也正是因为这样,所以会需要很多张表,才能满足复杂的业务需求

![【SpringBoot高级篇】SpringBoot集成RocketMQ消息队列]](https://img-blog.csdnimg.cn/fea2a79aafb5459880a838e38d727ac9.png)