DreamerV3

- 文章希望解决的一个挑战是用固定的hyperparameter来同时处理不同domain的任务。
- 文章发现,通过结合KL balancing 和free bits可以使得world model learn without tuning(是指上面这件事,即不需要对不同任务改变hyperparameter),还发现把large returns 给scaling down(而非amplifying small returns)可以使用固定的policy entropy regularizer。所以从两方面出发可以使得不同domain的任务都可以用相同的一套hyperparameter来train,从而降低tuning的成本。
symlog
- 这里介绍了一个normalize target的技术。是这样的,如果我们使用神经网络来拟合一些映射,然后当target值都是些很大的值比如几百上千的时候,直接用L2 loss会导致损失发散无法收敛,用L1 Loss或Huber loss同样无法使得模型train得很好。通常我们需要对这些target值进行归一化,处理到0-1附近。文章提出使用一个symlog函数来归一化target值比直接用running statistics(可能指的是在强化学习的过程中统计见过数据的均值和方差,减去均值除以方差,这导致归一化过程在训练前期的不稳定从而导致训练前期的不稳定)好 。
- symlog其实就是ln函数配合绝对值,如下:

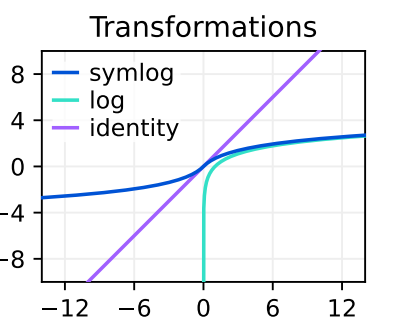
- 可以看到,过了单调的symlog函数后,数值范围被scaling down了,同时也不影响原先的小数值的区分度,这是非线性scaling down的优势。使用symlog进行归一化还有一个好处是当遇到新domain数据具有不同范围时,也无需重新计算归一化,保持symlog函数即可。
world model
- dreamerV3的world model是一个Recurrent State-Space Model (RSSM),它包括以下几个部分:
- 首先当然是一个encoder,把输入的数据
x
x
x 编码成
z
z
z,然后在
z
z
z空间进行其它的处理。然后有一个sequence model编码隐状态
h
h
h,用来记录历史特征,从公式看,前面的encoder也用到了隐状态来编码
z
z
z。除了这两个主要的encoder,其它的就是predictor和decoder了,一个预测reward的predictor,一个是预测是否继续的continue predictor,一个用来train sequence model的dynamic predictor,还有一个是用来train encoder的decoder。


- encoder和decoder用的是CNN(处理图像)和MLP(处理其它低频输入),其它predictor都是MLP。
- 损失函数由3部分组成,一是pred loss,用来计算decoder的输出和x之间的symlog loss,以及reward predictor的输出与label之间的symlog loss,以及continue predictor与label之间的binary classification loss;二是dynamic loss,用来计算dynamic predictor的输出与encoder的输出之间的KL 散度,从而训练dynamic encoder编码更好的h;三是representation loss,同样是计算dynamic predictor的输出与encoder的输出之间的KL 散度,但这个loss是为了训练encoder编码更可预测的z。dynamic loss和representation loss的区别在于,两者都加了一个stop-gradient operator
s
g
(
⋅
)
sg(\cdot)
sg(⋅),不过一个加在dynamic predictor上一个加在encoder上:

- 可以看到,其实dynamic loss和representation loss不是简单的KL 散度,加了一个clip,这个是free bits策略,因为dynamic encoder不包含输入的信息,因此很难预测得和z一模一样。作者认为两者可以有1 nat的距离,加了这个clip,当他们之间的距离小于 1 nat时,不再计算这两个损失,使模型更专注于pred loss,毕竟这才是主要的,其它两个都是辅助而已。作者认为这里用free bits还有利于提高模型的适应性。对3D场景来说,x中包含了很多多余的信息,因此rep loss和dyn loss会很难降到很低,因为要顾及很多多余的信息,而2D场景则相反。因此,其实这两个损失可以看成是两个regularizer。在不同的场景下由于不同的训练难度,这两个regularizer产生的作用会有强弱之分,通常来说权重需要根据不同的场景进行调整。因此当使用free bits时,可以不需要调整,因为当损失低于1时,已经不算这两个损失了。
- 训练初期,encoder和dynamic predictor的输出有可能非常接近导致KL 散度有极端值,从而训练不稳定,为了避免这个,使用的技巧是把他们的输出以0.01:0.99的比例混合一个随机向量,从而使得KL loss保持在正常范围内。
Actor Critic Learning
- 未完待续