博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
目录
一、引言
二、pytorch介绍
2.1 pytorch历史
2.2 pytorch特点
2.2.1 支持GPU加速的张量计算库
2.2.2 包含自动求导系统的动态图机制
2.3 pytorch安装
三、pytorch实战
3.1 引入依赖的python库
3.2 定义三层神经网络
3.3 训练数据准备
3.4 实例化模型、定义损失函数与优化器
3.5 启动训练,迭代收敛
3.6 模型评估
3.7 可以直接跑的代码
四、总结
一、引言
要深入了解大模型底层原理,先要能手撸transformer模型结构,在这之前,pytorch、tensorflow等深度学习框架必须掌握,之前做深度学习时用的tensorflow,做aigc之后接触pytorch多一些,今天写一篇pytorch的入门文章吧,感兴趣的可以一起聊聊。
二、pytorch介绍
2.1 pytorch历史
PyTorch由facebook人工智能研究院研发,2017年1月被提出,是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
2.2 pytorch特点
Pytorch是一个python包,提供两个高级功能:
2.2.1 支持GPU加速的张量计算库
张量(tensor):可以理解为多位数组,是Pytorch的基本计算单元,Pytorch的特性就是可以基于GPU快速完成张量的计算,包括求导、切片、索引、数学运算、线性代数、归约等

import torch
import torch.nn.functional as F
# 1. 张量的创建
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(x) #tensor([[1, 2, 3],[4, 5, 6]])
print(y) #tensor([[1, 2, 3],[4, 5, 6]])
# 2. 张量的运算
z=x+y
print(z) #tensor([[2, 4, 6],[8, 10, 12]])
# 3. 张量的自动求导
x = torch.tensor(3.0, requires_grad=True)
print(x.grad) #None
y = x**2
y.backward()
print(x.grad) #tensor(6.)2.2.2 包含自动求导系统的动态图机制
Pytorch提供了一种独一无二的构建神经网络的方式:动态图机制
不同于TensorFlow、Caffe、CNTK等静态神经网络:网络构建一次反复使用,如果修改了网络不得不重头开始。
在Pytorch中,使用了一种“反向模式自动微分的技术(reverse-mode auto-differentiation)”,允许在零延时或开销的情况下任意更改网络。
2.3 pytorch安装
这里建议大家采用conda创建环境,采用pip管理pytorch包
1.建立名为pytrain,python版本为3.11的conda环境
conda create -n pytrain python=3.11
conda activate pytrain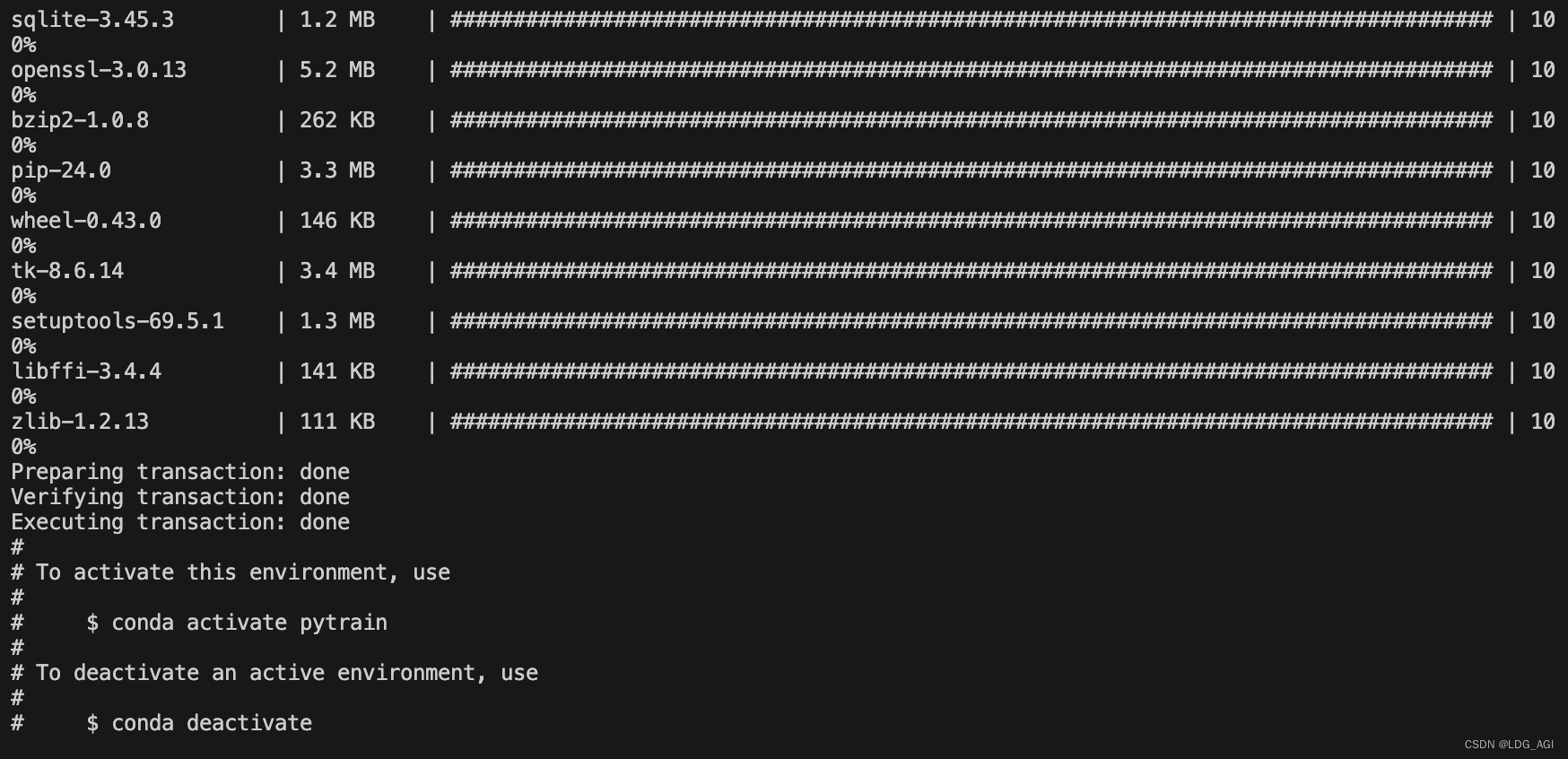
2.采用pip下载torch和torchvision包
pip install torch torchvision torchmetrics -i https://mirrors.cloud.tencent.com/pypi/simple
这里未指定版本,默认下载最新版本torch-2.3.0、torchvision-0.18.0以及其他一堆依赖。
三、pytorch实战
动手实现一个三层DNN网络:
3.1 引入依赖的python库
这里主要是torch、torch.nn网络、torch.optim优化器、torch.utils.data数据处理等
import torch # 导入pytorch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.utils.data import DataLoader, TensorDataset # 数据集模块3.2 定义三层神经网络
引入nn.Module类,编写构造函数定义网络结构,编写前向传播过程定义激活函数。
- 通过继承torch.nn.Module类,对神经网络层进行构造,Module类在pytorch中非常重要,他是所有神经网络层和模型的基类。
- 定义模型构造函数__init__:在这里定义网络结构,输入为每一层的节点数,采用torch.nn.Linear这个类,定义全连接线性层,进行线性变换,通过第一层节点输入数据*权重矩阵(n * [n,k] = k),加偏置项,再配以激活函数得到下一层的输入。
- 定义前向传播forward过程:采用relu、sigmod、tanh等激活函数,对每一层计算得到的原始值归一化输出。一般建议采用relu。sigmod的导数在0、1极值附近会接近于0,产生“梯度消失”的问题,较长的精度会导致训练非常缓慢,甚至无法收敛。relu导数一直为1,更好的解决了梯度消失问题。
# 定义三层神经网络模型
class ThreeLayerDNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ThreeLayerDNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 第一层全连接层
self.fc2 = nn.Linear(hidden_size, hidden_size) # 第二层全连接层
self.fc3 = nn.Linear(hidden_size, output_size) # 输出层
self.sigmoid = nn.Sigmoid() # 二分类输出层使用Sigmoid激活函数
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用ReLU激活函数
x = torch.relu(self.fc2(x)) # 中间层也使用ReLU激活函数
x = torch.sigmoid(self.fc3(x)) # 二分类输出层使用Sigmoid激活函数
return x3.3 训练数据准备
- 定义输入的特征数、隐层节点数、输出类别数,样本数,
- 采用torch.randn、torch.randint函数构造训练数据,
- 采用TensorDataset、DataLoader类分别进行张量数据集构建以及数据导入
# 数据准备
input_size = 1000 # 输入特征数
hidden_size = 512 # 隐藏层节点数
output_size = 2 # 输出类别数
num_samples = 1000 # 样本数
# 示例数据,实际应用中应替换为真实数据
X_train = torch.randn(num_samples, input_size)
y_train = torch.randint(0, output_size, (num_samples,))
# 数据加载
dataset = TensorDataset(X_train, y_train)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)3.4 实例化模型、定义损失函数与优化器
损失函数与优化器是机器学习的重要概念,先看代码,nn来自于torch.nn,optim来自于torch.optim,均为torch封装的工具类
# 实例化模型
model = ThreeLayerDNN(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 适合分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001)损失函数:用于衡量模型预测值与真实值的差距,是模型优化的目标。常见损失函数为
- 均方误差损失(MSE):用于回归问题,衡量预测值与真实值之间的平方差的平均值。
- 交叉熵损失(Cross Entropy Loss):用于分类问题,衡量预测概率分布与真实分布之间的差距。
- 二进制交叉熵损失(Binary Cross-Entropy Loss):是一种用于二分类任务的损失函数,通常用于测量模型的二分类输出与实际标签之间的差距,不仅仅应用于0/1两个数,0-1之间也都能学习
优化器:优化算法用于调整模型参数,以最小化损失函数。常见的优化算法为
- 随机梯度下降(SGD):通过对每个训练样本计算梯度并更新参数,计算简单,但可能会陷入局部最优值。
- Adam:结合了动量和自适应学习率调整的方法,能够快速收敛且稳定性高,广泛应用于各种深度学习任务。
3.5 启动训练,迭代收敛
模型训练可以简单理解为一个“双层for循环”
第一层for循环:迭代的轮数,这里是10轮
第二层for循环:针对每一条样本,前、后向传播迭代一遍网络,1000条样本就迭代1000次。
所以针对10轮迭代,每轮1000条样本,要迭代网络10*1000=10000次。
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 设置为训练模式
running_loss = 0.0
for i, (inputs, labels) in enumerate(data_loader, 0):
optimizer.zero_grad() # 清零梯度
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}')
print('Training finished.')运行后可以看到loss逐步收敛:
3.6 模型评估
通过引入torchmetrics库对模型效果进行评估,主要分为以下几步
- 构造测试集数据;
- 测试集数据加载;
- 将模型切至评估模式;
- 初始化模型准确率与召回率的计算器;
- 循环测试样本,更新准确率与召回率计算器;
- 打印输出
import torchmetrics # 导入torchmetrics
test_num_samples = 200 # 测试样本数
test_X_train = torch.randn(test_num_samples, input_size)
test_y_train = torch.randint(0, output_size, (test_num_samples,))
# 数据加载
test_dataset = TensorDataset(test_X_train,test_y_train)
test_data_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)
# 在模型训练完成后进行评估
# 首先,我们需要确保模型在评估模式下
model.eval()
# 初始化准确率和召回率的计算器
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=output_size)
recall = torchmetrics.Recall(task="multiclass", num_classes=output_size)
with torch.no_grad(): # 确保在评估时不进行梯度计算
for inputs, labels in test_data_loader:
outputs = model(inputs)
preds = torch.softmax(outputs, dim=1)
# 更新指标计算器
accuracy.update(preds, labels)
recall.update(preds, labels)
# 打印准确率和召回率
print(f'Accuracy: {accuracy.compute():.4f}')
print(f'Recall: {recall.compute():.4f}')
print('Evaluation finished.')运行后,可以输出模型的准确率与召回率,由于采用随机生成的测试数据且迭代轮数较少,具体数值不错参考,可以根据自己需要丰富数据。

3.7 可以直接跑的代码
附可以直接运行的代码,先跑起来,再一行行研究!
import torch # 导入pytorch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.utils.data import DataLoader, TensorDataset # 数据集模块
# 定义三层神经网络模型
class ThreeLayerDNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ThreeLayerDNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 第一层全连接层
self.fc2 = nn.Linear(hidden_size, hidden_size) # 第二层全连接层
self.fc3 = nn.Linear(hidden_size, output_size) # 输出层
self.sigmoid = nn.Sigmoid() # 二分类输出层使用Sigmoid激活函数
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用ReLU激活函数
x = torch.relu(self.fc2(x)) # 中间层也使用ReLU激活函数
x = torch.sigmoid(self.fc3(x)) # 二分类输出层使用Sigmoid激活函数
return x
# 数据准备
input_size = 1000 # 输入特征数
hidden_size = 512 # 隐藏层节点数
output_size = 2 # 输出类别数
num_samples = 1000 # 样本数
# 示例数据,实际应用中应替换为真实数据
X_train = torch.randn(num_samples, input_size)
y_train = torch.randint(0, output_size, (num_samples,))
# 数据加载
dataset = TensorDataset(X_train, y_train)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 实例化模型
model = ThreeLayerDNN(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 适合分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 设置为训练模式
running_loss = 0.0
for i, (inputs, labels) in enumerate(data_loader, 0):
optimizer.zero_grad() # 清零梯度
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 更新权重
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(data_loader)}')
print('Training finished.')
#for param in model.parameters():
# print(param.data)
import torchmetrics # 导入torchmetrics
test_num_samples = 200 # 测试样本数
test_X_train = torch.randn(test_num_samples, input_size)
test_y_train = torch.randint(0, output_size, (test_num_samples,))
# 数据加载
test_dataset = TensorDataset(test_X_train,test_y_train)
test_data_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)
# 在模型训练完成后进行评估
# 首先,我们需要确保模型在评估模式下
model.eval()
# 初始化准确率和召回率的计算器
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=output_size)
recall = torchmetrics.Recall(task="multiclass", num_classes=output_size)
with torch.no_grad(): # 确保在评估时不进行梯度计算
for inputs, labels in test_data_loader:
outputs = model(inputs)
# 将输出通过softmax转换为概率分布(虽然CrossEntropyLoss内部做了,但这里为了计算指标明确显示)
preds = torch.softmax(outputs, dim=1)
# 更新指标计算器
accuracy.update(preds, labels)
recall.update(preds, labels)
# 打印准确率和召回率
print(f'Accuracy: {accuracy.compute():.4f}')
print(f'Recall: {recall.compute():.4f}')
print('Evaluation finished.')四、总结
本文先对pytorch深度学习框架历史、特点及安装方法进行介绍,接下来基于pytorch带读者一步步开发一个简单的三层神经网络程序,最后附可执行的代码供读者进行测试学习。个人感觉网络结构部分比tensorflow稍微抽象一点点,不过各有优劣吧,初学者最好对比着学习。下一篇写tensorflow吧,一起讲了大家可以对比着看。喜欢的话期待您的关注、点赞、收藏,您的互动是对我最大的鼓励!
如果还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发