参考资料:活用pandas库
1、向量化函数
使用apply时,可以按行或按列应用函数。如果想应用自定义的函数,必须重写它,因为整列或整行传递到了函数的第一个参数中。可以利用向量化函数和装饰器对所有函数进行向量化。对代码进行向量化也可以提升运行性能。
# 导入pandas库
import pandas as pd
#创建一个DataFrame
df=pd.DataFrame({
'a':[10,20,30],
'b':[20,30,40]
})
# 创建自定义函数
def avg_2(x,y):
return (x+y)/2.对于向量函数,我们希望向上述自定函数中的x和y分别传入一个值向量,结果应该是给定x值和y值得平均值,并且顺序保持不变,即能写成avg_2(df['a'],df['b']),并且结果类似于[15,25,35]。
使用numpy库的vetorize函数。把要向量化的函数传递给np.vectorize,创建新函数。
如果函数是自定义的,也可以使用python装饰器“自动”把函数向量化。装饰器是函数,它们以其他函数为输入并修改其行为。
# 导入 numpy库
import numpy as np
# 自定义函数
# 此函数无法用于向量计算,但可以用于单个值的计算
def avg_2_mod(x,y):
"""
当x不等于20时,计算平均值
"""
if(x==20):
return np.NaN
else:
return (x+y)/2
# np.vectorize创建向量化函数
avg_2_mod_vec=np.vectorize(avg_2_mod)
print(avg_2_mod_vec(df['a'],df['b']))
# 装饰器
# 为了使用vectorize装饰器,要在函数定义之前使用@符号
@np.vectorize
def v_avg_2_mod(x,y):
"""
当x不等于20时,计算平均值
和前面一样,但这里使用vectorize装饰器
"""
if x==20:
return np.nan
else:
return (x+y)/2
# 可以直接使用此向量化的函数
print(v_avg_2_mod(df['a'],df['b']))2、lambda函数
有时,apply方法中使用的函数非常简单,无须单独创建。
编写lambda函数需要使用lambda关键字。由于apply函数会把整行或整列作为第一个参数传递过来,所以lambda函数只有一个参数x。然后可以直接编写函数,而不必定义它,而且结果结果会自动返回。
虽然可以编写复杂的lambda函数,但通常只在需要单行计算时,才会使用lambda函数。如果lambda函数中包含过多代码,会难以阅读。
import re
docs=pd.read_csv(r"...\data\doctors.csv",header=None)
p=re.compile('\w+\s+\w+')
# 方法1,先编写一个函数,在调用apply应用它
# 自定义函数
def get_name(s):
return p.match(s).group()
docs['name_func']=docs[0].apply(get_name)
print(docs)
# 方法2,直接用lambda函数
docs['name_lamb']=docs[0].apply(lambda x: p.match(x).group())
print(docs)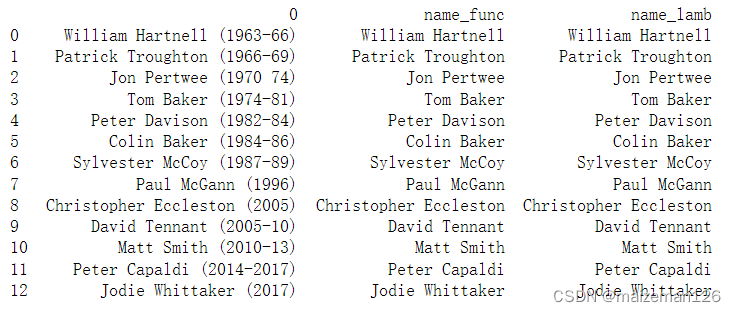
![[数智人文实战] 02.舆情分析之词云可视化、文本聚类和LDA主题模型文本挖掘](https://img-blog.csdnimg.cn/20200306163821515.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)