CUDA之向量点乘和矩阵乘法
- 计算类似矩阵乘法的数学运算
1. 向量点乘
- 两个向量点乘运算定义如下:
#真正的向量可能很长,两个向量里边可能有多个元素
(X1,Y1,Z1) * (Y1,Y2,Y3) = X1Y1 + X2Y2 + X3Y3
- 这种原始输入是两个数组而输出却缩减为一个(单一值)的运算,在CUDA里边叫规约运算
- 该运算对应的内核函数如下:
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 1024
#define threadsPerBlock 512
__global__ void gpu_dot(float* d_a, float* d_b, float* d_c) {
//Declare shared memory
__shared__ float partial_sum[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
//Calculate index for shared memory
int index = threadIdx.x;
//Calculate Partial Sum
float sum = 0;
while (tid < N)
{
sum += d_a[tid] * d_b[tid];
tid += blockDim.x * gridDim.x;
}
// Store partial sum in shared memory
partial_sum[index] = sum;
// synchronize threads
__syncthreads();
// Calculating partial sum for whole block in reduce operation
int i = blockDim.x / 2;
while (i != 0) {
if (index < i)
partial_sum[index] += partial_sum[index + i];
__syncthreads();
i /= 2;
}
//Store block partial sum in global memory
if (index == 0)
d_c[blockIdx.x] = partial_sum[0];
}
-
每个块都有单独的一份共享内存副本,所以每个线程ID索引到的共享内存只能是当前块自己的那个副本
-
当线线程总数小于元素数量的时候,它也会循环将tid 索引累加偏移到当前线程总数,继续索引下一对元素,并进行计算。每个线程得到的部分和结果被写入到共享内存。我们将继续使用共享内存上的这些线程的部分和计算出当前块的总体部分和
-
在对共享内存中的数据读取之前,必须确保每个线程都已经完成了对共享内存的写入,可以通过 __syncthreads() 同步函数做到这一点
-
计算当前块部分和的方法:
- 1.让一个线程串行循环将这些所有的线程的部分和进行累加
- 2.并行化:每个线程累加2个数的操作,并将每个线程的得到的1个结果覆盖写入这两个数中第一个数的位置,因为每个线程都累加了2个数,因此可以在第一个数中完成操作(此时第一个数就是两个数的和),后边对剩余的部分重复这个过程,类似将所有数对半分组相加吧,一组两个数,加完算出的新的结果作为新的被加数
- 上述并行化的方法是通过条件为
(i!=0)的while循环进行的,后边的计算类似二分法,重复计算中间值与下一值的和,知道总数为0
-
main函数如下:
int main(void)
{
//Declare Host Array
float *h_a, *h_b, h_c, *partial_sum;
//Declare device Array
float *d_a, *d_b, *d_partial_sum;
//Calculate total number of blocks per grid
int block_calc = (N + threadsPerBlock - 1) / threadsPerBlock;
int blocksPerGrid = (32 < block_calc ? 32 : block_calc);
// allocate memory on the host side
h_a = (float*)malloc(N * sizeof(float));
h_b = (float*)malloc(N * sizeof(float));
partial_sum = (float*)malloc(blocksPerGrid * sizeof(float));
// allocate the memory on the device
cudaMalloc((void**)&d_a, N * sizeof(float));
cudaMalloc((void**)&d_b, N * sizeof(float));
cudaMalloc((void**)&d_partial_sum, blocksPerGrid * sizeof(float));
// fill the host array with data
for (int i = 0; i<N; i++) {
h_a[i] = i;
h_b[i] = 2;
}
cudaMemcpy(d_a, h_a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(float), cudaMemcpyHostToDevice);
//Call kernel
gpu_dot << <blocksPerGrid, threadsPerBlock >> >(d_a, d_b, d_partial_sum);
// copy the array back to host memory
cudaMemcpy(partial_sum, d_partial_sum, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost);
// Calculate final dot product on host
h_c = 0;
for (int i = 0; i<blocksPerGrid; i++) {
h_c += partial_sum[i];
}
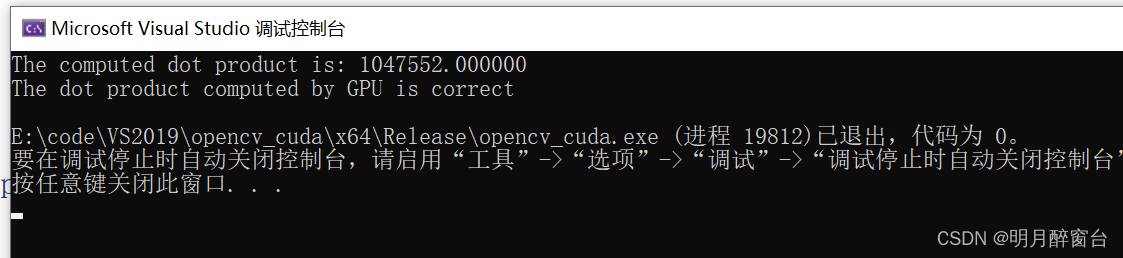
printf("The computed dot product is: %f\n", h_c);
}
- 在main函数中添加如下代码,检查该点乘结果是否正确:
#define cpu_sum(x) (x*(x+1))
if (h_c == cpu_sum((float)(N - 1)))
{
printf("The dot product computed by GPU is correct\n");
}
else
{
printf("Error in dot product computation");
}
// free memory on host and device
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_partial_sum);
free(h_a);
free(h_b);
free(partial_sum);
矩阵乘法
- 矩阵乘法A*B,A的行数需等于B的列数,将A的某行与B的所有的列进行点乘,然后对A的每一行以此类推
- 下面将给出不使用共享内存和使用共享内存的内核函数来计算矩阵乘法
- 先给出不使用共享内存的内核:
//Matrix multiplication using shared and non shared kernal
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <math.h>
#define TILE_SIZE 2
//Matrix multiplication using non shared kernel
__global__ void gpu_Matrix_Mul_nonshared(float* d_a, float* d_b, float* d_c, const int size)
{
int row, col;
col = TILE_SIZE * blockIdx.x + threadIdx.x;
row = TILE_SIZE * blockIdx.y + threadIdx.y;
for (int k = 0; k < size; k++)
{
d_c[row * size + col] += d_a[row * size + k] * d_b[k * size + col];
}
}
- 每个元素的线性索引可以这样计算:用它的行号乘以矩阵的宽度,再加上它的列号即可
- 使用共享内存的内核函数如下:
// Matrix multiplication using shared kernel
__global__ void gpu_Matrix_Mul_shared(float *d_a, float *d_b, float *d_c, const int size)
{
int row, col;
//Defining Shared Memory,共享内存数量=块数
__shared__ float shared_a[TILE_SIZE][TILE_SIZE];
__shared__ float shared_b[TILE_SIZE][TILE_SIZE];
col = TILE_SIZE * blockIdx.x + threadIdx.x;
row = TILE_SIZE * blockIdx.y + threadIdx.y;
for (int i = 0; i< size / TILE_SIZE; i++)
{
shared_a[threadIdx.y][threadIdx.x] = d_a[row* size + (i*TILE_SIZE + threadIdx.x)];
shared_b[threadIdx.y][threadIdx.x] = d_b[(i*TILE_SIZE + threadIdx.y) * size + col];
__syncthreads();
for (int j = 0; j<TILE_SIZE; j++)
d_c[row*size + col] += shared_a[threadIdx.y][j] * shared_b[j][threadIdx.x];
__syncthreads();
}
}
- 主函数代码如下:
int main()
{
const int size = 4;
//Define Host Array
float h_a[size][size], h_b[size][size],h_result[size][size];
//Defining device Array
float *d_a, *d_b, *d_result;
//Initialize host Array
for (int i = 0; i<size; i++)
{
for (int j = 0; j<size; j++)
{
h_a[i][j] = i;
h_b[i][j] = j;
}
}
cudaMalloc((void **)&d_a, size*size*sizeof(int));
cudaMalloc((void **)&d_b, size*size * sizeof(int));
cudaMalloc((void **)&d_result, size*size* sizeof(int));
//copy host array to device array
cudaMemcpy(d_a, h_a, size*size* sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size*size* sizeof(int), cudaMemcpyHostToDevice);
//Define grid and block dimensions
dim3 dimGrid(size / TILE_SIZE, size / TILE_SIZE, 1);
dim3 dimBlock(TILE_SIZE, TILE_SIZE, 1);
//gpu_Matrix_Mul_nonshared << <dimGrid, dimBlock >> > (d_a, d_b, d_result, size);
gpu_Matrix_Mul_shared << <dimGrid, dimBlock >> > (d_a, d_b, d_result, size);
cudaMemcpy(h_result, d_result, size*size * sizeof(int), cudaMemcpyDeviceToHost);
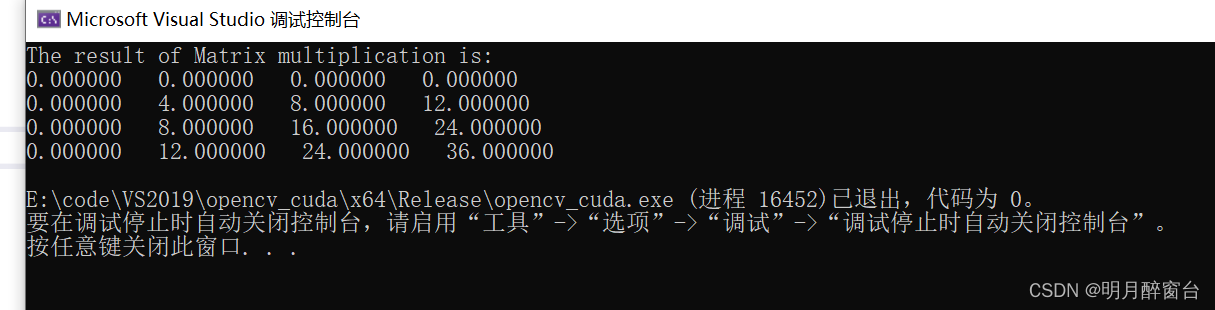
printf("The result of Matrix multiplication is: \n");
for (int i = 0; i< size; i++)
{
for (int j = 0; j < size; j++)
{
printf("%f ", h_result[i][j]);
}
printf("\n");
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_result);
return 0;
}
- ——————END——————