0 概述
0.1 明确气候与气象的概念
气候(Climate):是指一个地区大气物理特征的长期平均状态,具有一定的稳定性,且周期长。根据世界气象组织(WMO)的规定,一个标准气候计算时间为 30 年。
气象(Meteorology):指发生在天空中的风、云、雨、雪、霜、露、闪电、打雷等一切大气的物理现象,具有一定的波动性,且周期短。气象条件的变化往往引发天气状况的改变。
0.2 gma 气候气象函数包 (climet) 基本情况
gma 气候气象函数包 climet(climate 和 meteorology)是针对于气候气象相关计算的工具集合。目前主要包括 4 大部分共计15个函数,每个函数都提供详细的内置帮助(可使用help(gma.climet.~)查看,也可到 gma 官方网站 查看) ,主要分类为:
| 函数组 | 子类 | 子函数 |
|---|---|---|
| 气候气象指数 | - | SPI、SPEI、PAP |
| 气候诊断 | Diagnosis | MKMutationTest、Buishand、Pettitt、SNHT |
| 参考蒸散量 | ET0 | Hargreaves、PenmanMonteith、Thornthwaite |
| 其他函数 | Other | DaylightHours、Declination、HourAngle、RDBSunAndEarth、SolarRadiationFluxOA |
1 气象气候函数的主要计算过程
1.1 运行环境
系统: Window 10+ (X64),自 1.1.0 开始支持 Linux(X64)。
Python 版本:3.8 ~ 3.10
gma 版本: 1.1.2 +
安装:pip install gma
1.2 以SPI为例的计算过程
详见:图解 gma 气候标准化指数运算过程的数组变化流程:以 SPI 为例。
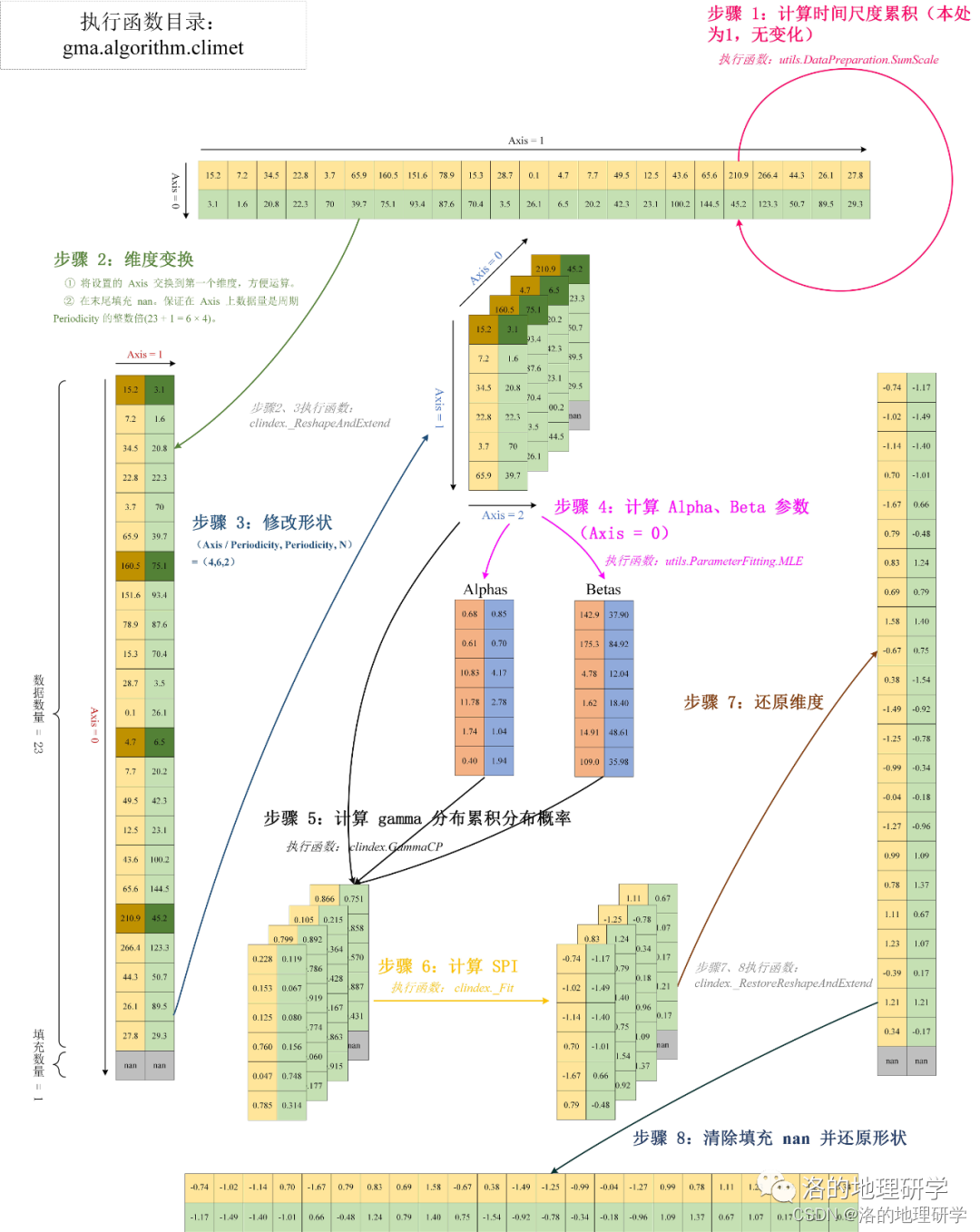
由图可知,gma 在运算过程中,仅对数组形状进行变换,未使用循环迭代。
2 主要问题及解决方案
从目前收到的反馈可知,主要问题有两点。一个是运算出现 nan ,另一个是栅格运算过程中出现的 内存不足 (MemoryError)。
2.1 出现 nan 的原因和解决方案
| 序号 | 可能的原因 | 解决方案 |
|---|---|---|
| 1 | 数据太少 | 参考 0.1 中描述,气候数据请保证足够的数据量。气候指标请保证数据至少有3个周期;月尺度ET0计算保证至少有1年有效数据。当有效数据不足时,gma会直接返回全 nan 数组! |
| 2 | 周期设置太长 | 参考 1.2 中图解,周期的长短决定了周期中每个时段参与拟合计算的数据数量,周期越长,其数量越少,越容易出现 nan!长周期情况下,请增加数据数量! |
| 3 | 数据本身不满足分布 | 此种情况可:1、检查并优化数据。2、选择合适的分布函数 Distribution,可选的分布包括:‘Gamma’ (Maximum Likelihood Estimation):伽马分布(参数估计:最大似然估计);‘LogLogistic’ (L-Moment Estimation(PWD)):对数逻辑斯蒂分布(参数估计:L-矩估计(概率加权矩));‘Pearson3’ (L-Moment Estimation):泊松 III 分布(参数估计:L-矩估计)。 |
| 4 | 其他异常数据 | 例如 gamma 分布要求数据必须为正数,如果原始值有负数(或0),可能造成结果 nan。gma 内部并未进行此类处理,因此,在计算之前,可将数据整体平移,保证所有有效值均大于 0。 |
2.2 内存不足解决方案
内存不足主要出现在栅格数据计算上。请大家注意,gma 为了提高运算效率,其中未使用任何循环迭代(参考 1.2)!这样做极大减少了运算时间,但同时带来了更多的内存占用,当电脑内存太小时(相对于计算数据),大概率发生引发 MemoryError 内存错误!
因此,如果不想拆分文件,那么主要的解决方法就是循环(计算过程需要更长的时间)! 以 gma 教程 | 气候气象 | 计算标准化降水指数(SPI) 为例,若栅格运算出现 MemoryError ,则可参考尝试采用如下方法循环计算:
import gma
import numpy as np
# 读取数据集
PRESet = gma.Open('PRE_Luoyang_1981-2020.tif')
## 建立一个 半精度浮点数 数组存储结果
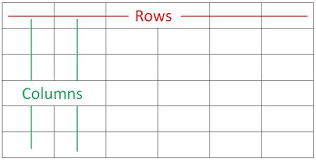
Rows = PRESet.Rows
Columns = PRESet.Columns
Bands = PRESet.Bands
### 由于 数据的 NoData 可能超过 float16 的数据范围,因此这里定义一个不可能出现在计算结果中的值作为 NoData 标记。
SPI = np.full((Bands, Rows, Columns), -99, dtype = np.float16)
# 确定需要计算的尺度
Scales = [1,3,6,12,24,60]
# 循环 6 个尺度
for i in Scales:
## 循环计算结果
for r in range(Rows):
for c in range(Columns):
## 每次读取 1 个位置
TempData = PRESet.ToArray(r, c, 1, 1)
## 跳过 NoData 区域(不适合 NoData 为 np.nan 或 np.inf 的数据)
if TempData[0, 0, 0] == PRESet.NoData:
continue
SPI[:, r, c] = gma.climet.SPI(TempData, Scale = i)
# 保存所有结果中的非全 nan 波段。即:去除时间尺度累积时序列前无效的波段。
gma.rasp.WriteRaster(fr'.\1981-2020_SPI{i}.tif',
SPI[i-1:],
Projection = PRESet.Projection,
Transform = PRESet.GeoTransform,
DataType = 'Float32',
NoData = -99)
其他迭代方法这里不做列举,可自行探索,按需修改。
ToArray 的参数解释请使用 help 获取或参考网址: ToArray 。
为何使用半精度浮点数(float16)?
- 如果对结果没有过高的精度需求,可使用半精度浮点数(float16)。如果对精度有要求,可自行定义其他数据类型,例如单精度浮点数(float32)或双精度浮点数(float64) 。
- 占用空间小。不同数据类型占用空间的大小请参考:NumPy 数组应用初探。
- 建议:使用单精度浮点数(float16)会极大的降低数据精度,因此大多数情况下不推荐使用(上述仅作示例,因为其在 numpy 支持的浮点数中内存占用最少)!
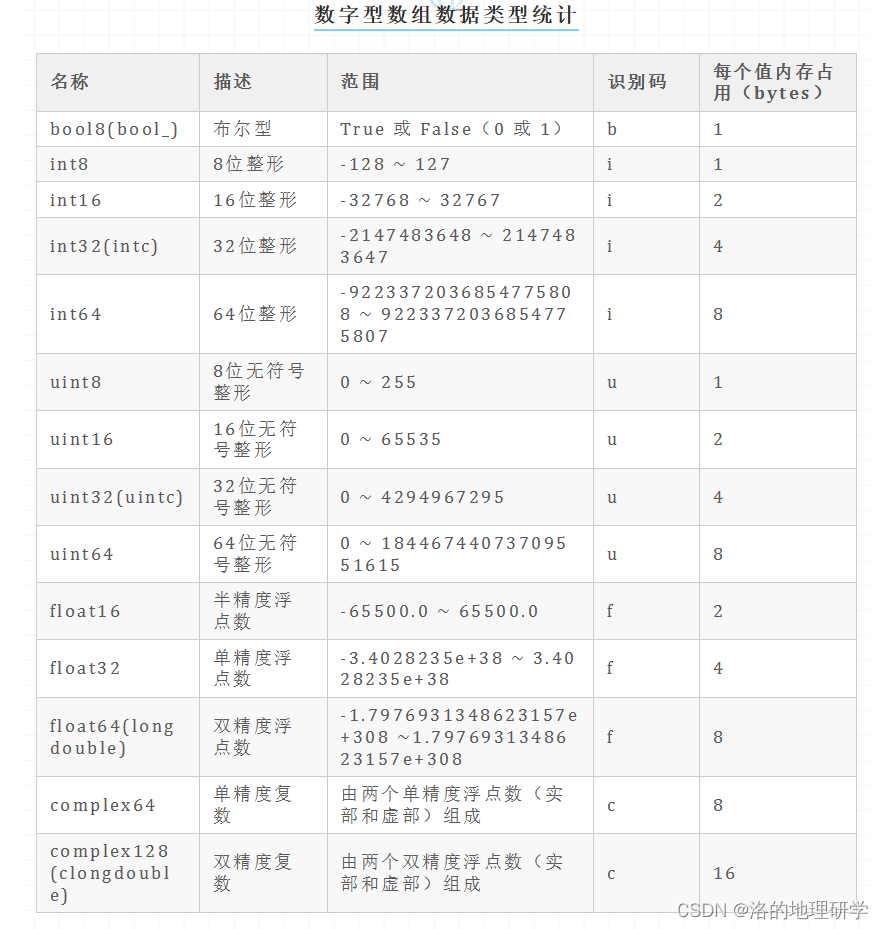
注意:gma 不支持保存半精度浮点数(float16)栅格。在写出栅格时,统一转为单精度浮点数(float32)(gma 标记:‘Float32’)保存。