今天,我们将介绍一个强大的Python库——Mechanize,通过它,我们可以轻松实现网页浏览的自动化。
Mechanize是一个用于模拟浏览器行为的Python库。它允许你自动化地与网站进行交互,就像真实用户一样。你可以使用它填写表单、点击按钮、处理Cookies等操作。Mechanize的强大之处在于它的简单性和灵活性,让你能够轻松地构建复杂的网络爬虫。
为什么选择Mechanize?
与其他网页抓取库相比,Mechanize有其独特的优势:
- 模拟浏览器行为:可以处理重定向、cookie等,像真实用户一样与网页交互。
- 自动表单填写:方便快速地填写和提交网页表单。
- 简单易用:相比Selenium,Mechanize更轻量级,使用起来更简单。
Mechanize的核心概念和原理
在使用Mechanize之前,我们需要了解一些核心概念:
- 浏览器对象(Browser):这是Mechanize的核心类,模拟浏览器的所有操作。
- 表单对象(Form):用于表示网页中的表单,可以进行填写和提交操作。
- 链接对象(Link):表示网页中的链接,可以进行点击操作。
安装和基本使用
首先,你需要安装Mechanize库。你可以通过pip进行安装:
pip install mechanize
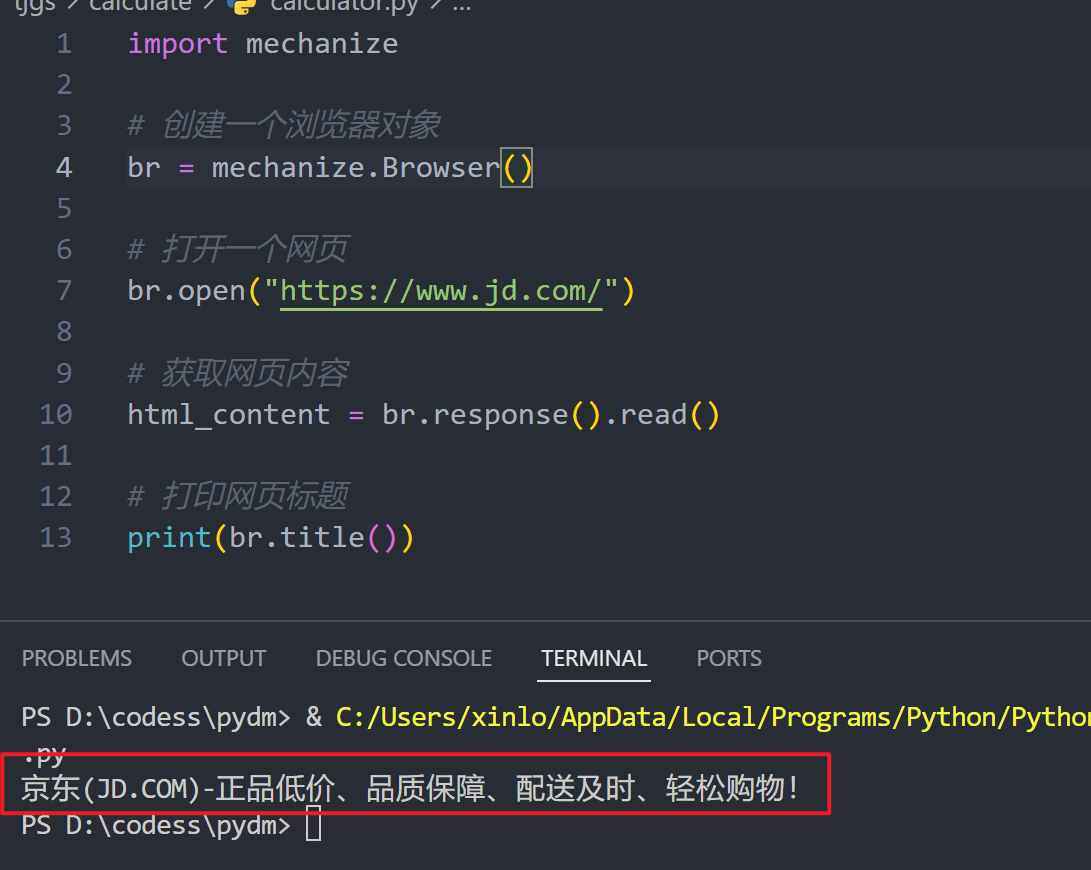
安装完成后,让我们来看一个简单的例子,了解如何使用Mechanize打开一个京东网页并提取首页信息。
import mechanize
# 创建一个浏览器对象
br = mechanize.Browser()
# 打开一个网页
br.open("https://www.jd.com/")
# 获取网页内容
html_content = br.response().read()
# 打印网页标题
print(br.title())
在这个例子中,我们创建了一个浏览器对象,并使用它打开了https://www.jd.com/这个网页,然后获取并打印了网页的标题。
丰富的案例代码
案例1:自动化登录
假设我们需要自动登录一个网站,并提取登录后的数据。以下是实现这个任务的代码:
import mechanize
# 创建浏览器对象
br = mechanize.Browser()
br.set_handle_robots(False) # 忽略robots.txt
# 打开登录页面
br.open("http://example.com/login")
# 选择登录表单
br.select_form(nr=0)
# 填写表单
br["username"] = "your_username"
br["password"] = "your_password"
# 提交表单
br.submit()
# 登录后打开目标页面
br.open("http://example.com/target_page")
# 打印登录后的页面内容
print(br.response().read())
在这个例子中,我们模拟了用户登录操作,包括填写用户名和密码并提交表单。然后,我们打开了登录后的目标页面并打印其内容。
案例2:处理Cookies
有时,网页会使用Cookies来存储用户会话信息。Mechanize可以轻松地处理Cookies。
import mechanize
import http.cookiejar as cookielib
# 创建一个CookieJar对象来存储Cookies
cookie_jar = cookielib.LWPCookieJar()
br = mechanize.Browser()
br.set_cookiejar(cookie_jar)
# 打开一个网页
br.open("http://example.com")
# 显示Cookies
for cookie in cookie_jar:
print(cookie)
这个例子展示了如何使用CookieJar对象来存储和处理Cookies。
综合案例
爬取百度搜索“Python”并解析搜索结果标题。
import mechanize
from bs4 import BeautifulSoup
# 创建一个浏览器对象
br = mechanize.Browser()
# 设置请求头,伪装成Mozilla浏览器
br.addheaders = [('User-agent', 'Mozilla/5.0')]
# 设置各种处理器
br.set_handle_equiv(True) # 解析HTML文档中的meta http-equiv标签
br.set_handle_gzip(True) # 解压缩gzip编码的响应
br.set_handle_redirect(True) # 允许自动处理HTTP重定向
br.set_handle_referer(True) # 在请求头中添加Referer字段
br.set_handle_robots(False) # 不遵循robots.txt文件
# 设置自动刷新的处理,max_time是刷新等待的最长时间
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
# 是否设置debug模式
br.set_debug_http(True)
br.set_debug_redirects(True)
br.set_debug_responses(True)
# 打开百度首页
br.open('http://www.baidu.com')
# 选择搜索表单
br.select_form(name='f')
# 填写搜索关键词
br['wd'] = 'Python'
# 提交搜索表单
br.submit()
# 获取搜索结果页面内容
content = br.response().read()
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(content, 'html.parser')
# 查找所有搜索结果标题
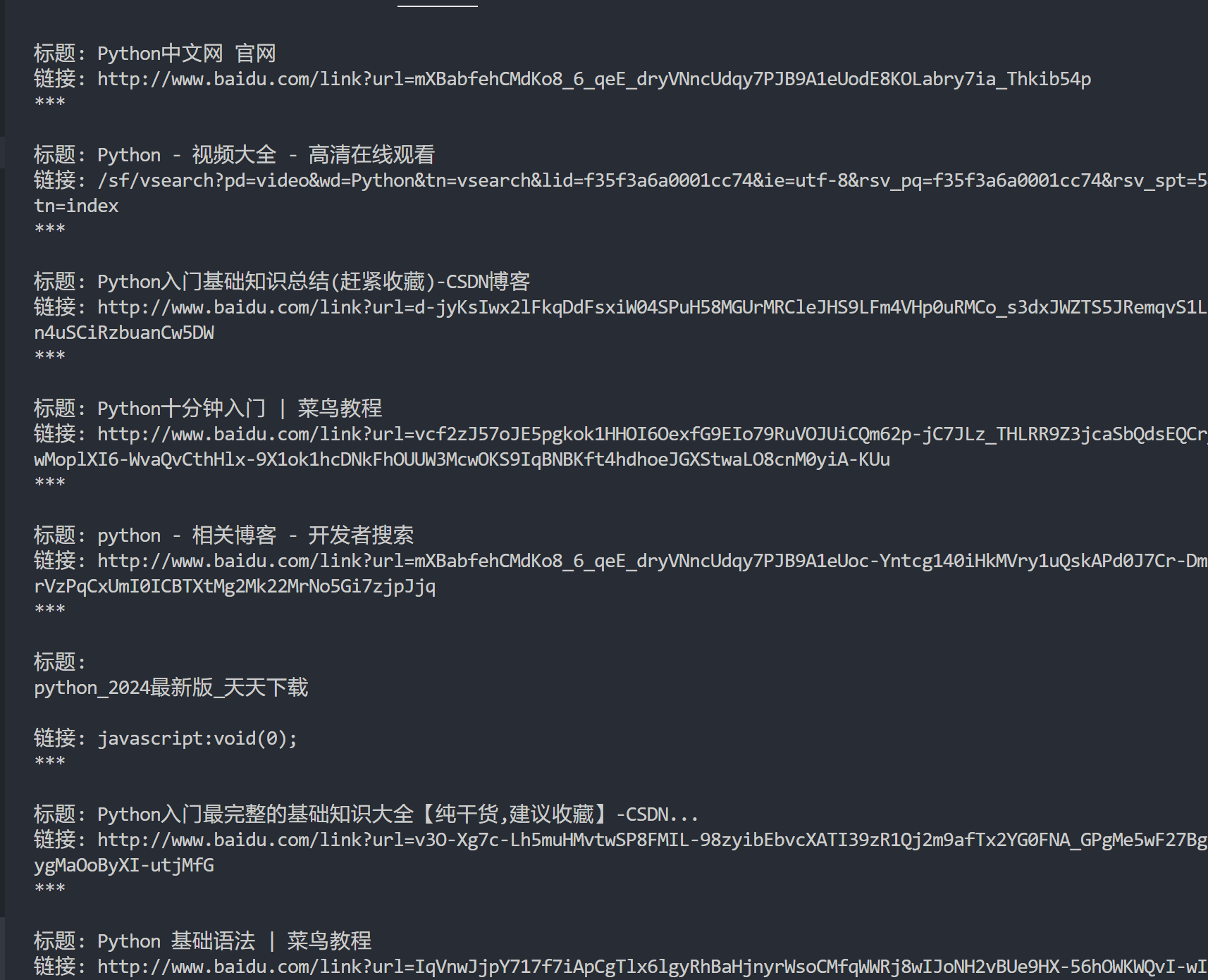
h3_tags = soup.find_all('h3')
# 打印搜索结果标题及链接
for h3 in h3_tags:
h3_link = h3.find('a')
if h3_link:
h3_url = h3_link.get('href')
h3_text = h3_link.get_text()
print(f'标题: {h3_text}\n链接: {h3_url}\n***\n')
代码说明
- 导入必要的库:导入Mechanize和BeautifulSoup。
- 创建浏览器对象:创建一个Mechanize浏览器对象。
- 设置请求头:添加User-Agent以模拟真实的浏览器。
- 设置处理器:配置各种处理器来处理HTML文档、gzip编码、重定向、Referer和robots.txt。
- 设置自动刷新处理:配置自动刷新处理器并设置最大刷新等待时间。
- 设置调试模式:开启HTTP请求、重定向和响应的调试模式。
- 打开百度首页:使用
br.open方法打开百度首页。 - 选择搜索表单:使用
br.select_form方法选择搜索表单。 - 填写搜索关键词:在搜索表单的
wd字段中填写搜索关键词“Python”。 - 提交搜索表单:使用
br.submit方法提交表单。 - 获取搜索结果页面内容:通过
br.response().read()方法获取搜索结果页面的HTML内容。 - 解析页面内容:使用BeautifulSoup解析HTML内容。
- 查找所有搜索结果标题:使用
find_all方法查找所有包含搜索结果标题的<h3>标签。 - 打印搜索结果标题及链接:遍历找到的
<h3>标签,并打印其包含的链接和标题。
Mechanize是一个强大的自动化工具,它能够帮助我们轻松地实现网页的自动化交互。感兴趣的话,大家可以亲自尝试一下。