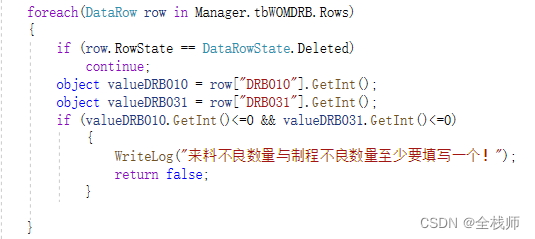
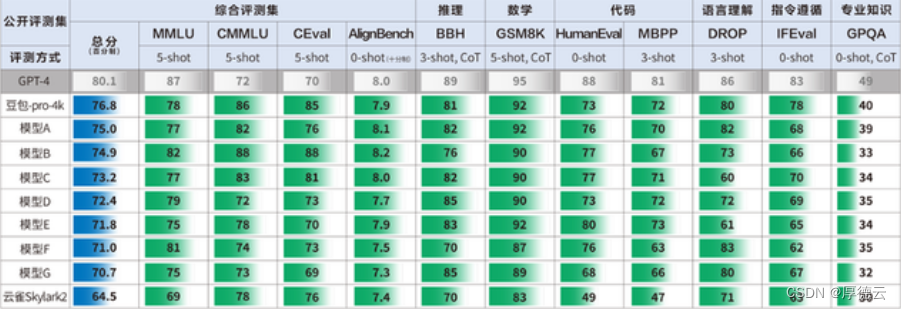
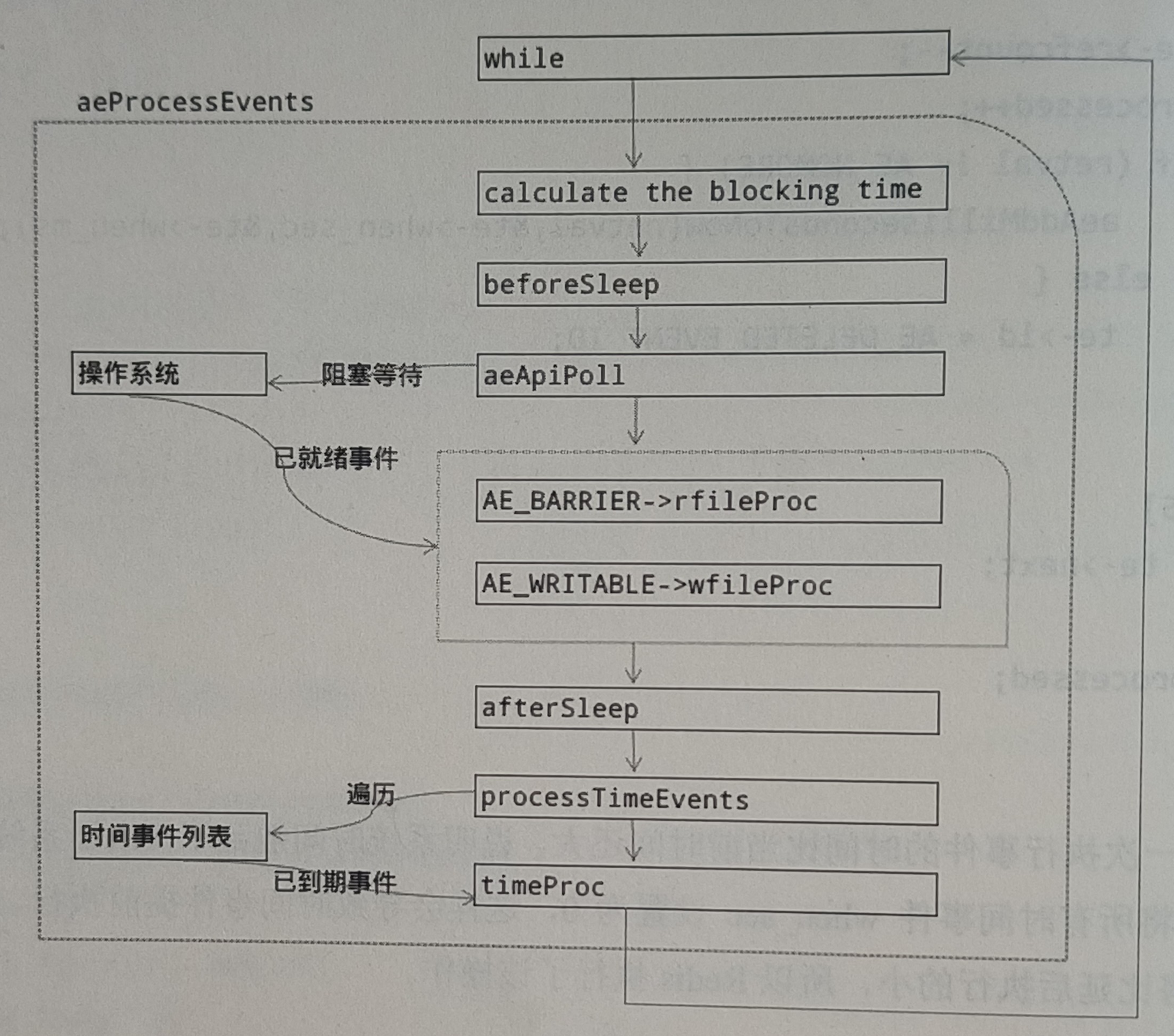
数据集简介:
训练集共有2160张猫的图片, 分为12类. train_list.txt是其标注文件
测试集共有240张猫的图片. 不含标注信息.
训练集图像(部分)

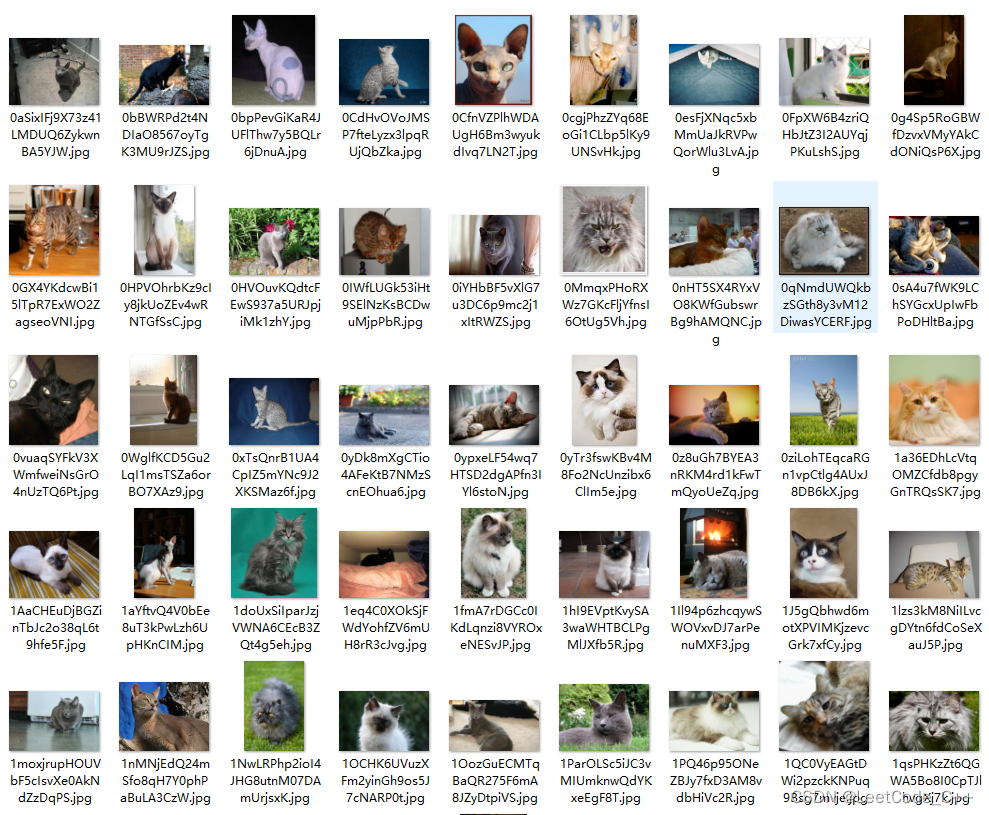
验证集图像(部分)

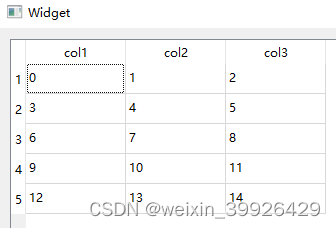
标签

部分代码:
# 定义训练数据集
class TrainData(Dataset):
def __init__(self):
super().__init__()
self.color_jitter = T.ColorJitter(brightness=0.05, contrast=0.05, saturation=0.05, hue=0.05)
self.normalize = T.Normalize(mean=0, std=1)
self.random_crop = T.RandomCrop(224, pad_if_needed=True)
def __getitem__(self, index):
# 读取图片
image_path = train_paths[index]
image = np.array(Image.open(image_path)) # H, W, C
try:
image = image.transpose([2, 0, 1])[:3] # C, H, W
except:
image = np.array([image, image, image]) # C, H, W
# 图像增广
features = self.color_jitter(image.transpose([1, 2, 0]))
features = self.random_crop(features)
features = self.normalize(features.transpose([2, 0, 1])).astype(np.float32)
# 读取标签
labels = train_labels[index]
return features, labels
def __len__(self):
return len(train_paths)
# 定义验证数据集
class ValidData(Dataset):
def __init__(self):
super().__init__()
self.normalize = T.Normalize(mean=0, std=1)
def __getitem__(self, index):
# 读取图片
image_path = valid_paths[index]
image = np.array(Image.open(image_path)) # H, W, C
try:
image = image.transpose([2, 0, 1])[:3] # C, H, W
except:
image = np.array([image, image, image]) # C, H, W
# 图像变换
features = cv2.resize(image.transpose([1, 2, 0]), (256, 256)).transpose([2, 0, 1]).astype(np.float32)
features = self.normalize(features)
# 读取标签
labels = valid_labels[index]
return features, labels
def __len__(self):
return len(valid_paths)# 调用resnet50模型
paddle.vision.set_image_backend('cv2')
model = paddle.vision.models.resnet50(pretrained=True, num_classes=12)
# 定义数据迭代器
train_dataloader = DataLoader(train_data, batch_size=256, shuffle=True, drop_last=False)
# 定义优化器
opt = paddle.optimizer.Adam(learning_rate=1e-4, parameters=model.parameters(), weight_decay=paddle.regularizer.L2Decay(1e-4))
# 定义损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
# 设置gpu环境
paddle.set_device('gpu:0')
# 整体训练流程
for epoch_id in range(15):
model.train()
for batch_id, data in enumerate(train_dataloader()):
# 读取数据
features, labels = data
features = paddle.to_tensor(features)
labels = paddle.to_tensor(labels)
# 前向传播
predicts = model(features)
# 损失计算
loss = loss_fn(predicts, labels)
# 反向传播
avg_loss = paddle.mean(loss)
avg_loss.backward()
# 更新
opt.step()
# 清零梯度
opt.clear_grad()
# 打印损失
if batch_id % 2 == 0:
print('epoch_id:{}, batch_id:{}, loss:{}'.format(epoch_id, batch_id, avg_loss.numpy()))
model.eval()
print('开始评估')
i = 0
acc = 0
for image, label in valid_data:
image = paddle.to_tensor([image])
pre = list(np.array(model(image)[0]))
max_item = max(pre)
pre = pre.index(max_item)
i += 1
if pre == label:
acc += 1
if i % 10 == 0:
print('精度:', acc / i)
paddle.save(model.state_dict(), 'acc{}.model'.format(acc / i))# 进行预测和提交
# 首先拿到预测文件的路径列表
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
test_path = []
listdir('cat_12_test', test_path)
# 加载训练好的模型
pre_model = paddle.vision.models.resnet50(pretrained=True, num_classes=12)
pre_model.set_state_dict(paddle.load('acc0.9285714285714286.model'))
pre_model.eval()
pre_classes = []
normalize = T.Normalize(mean=0, std=1)
# 生成预测结果
for path in test_path:
image_path = path
image = np.array(Image.open(image_path)) # H, W, C
try:
image = image.transpose([2, 0, 1])[:3] # C, H, W
except:
image = np.array([image, image, image]) # C, H, W
# 图像变换
features = cv2.resize(image.transpose([1, 2, 0]), (256, 256)).transpose([2, 0, 1]).astype(np.float32)
features = normalize(features)
features = paddle.to_tensor([features])
pre = list(np.array(pre_model(features)[0]))
# print(pre)
max_item = max(pre)
pre = pre.index(max_item)
print("图片:", path, "预测结果:", pre)
pre_classes.append(pre)
print(pre_classes)