一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
详细说明
概述
参数
返回值
特性
实现细节(CPython)
安全性
示例
注意事项
相关函数
参考文献
记忆策略
常用场景
场景 1:比较两个对象是否是同一个对象
场景 2:跟踪对象的生命周期
场景 3:检测对象的共享与复制
场景 4:检测变量是否指向None
巧妙用法
巧妙使用 1:检测对象是否被回收
巧妙使用 2:基于对象ID的唯一性生成哈希值
巧妙使用 3:对象池管理
巧妙使用 4:缓存机制
综合技巧
巧妙用法 1:与 weakref 模块结合,用于对象生命周期管理
巧妙用法 2:与 inspect 模块结合,用于调试和跟踪对象
巧妙用法 3:与 gc 模块结合,用于垃圾回收调试
巧妙用法 4:与自定义装饰器结合,实现缓存优化
巧妙用法 5:与 __slots__ 结合,优化内存使用
详细说明
概述
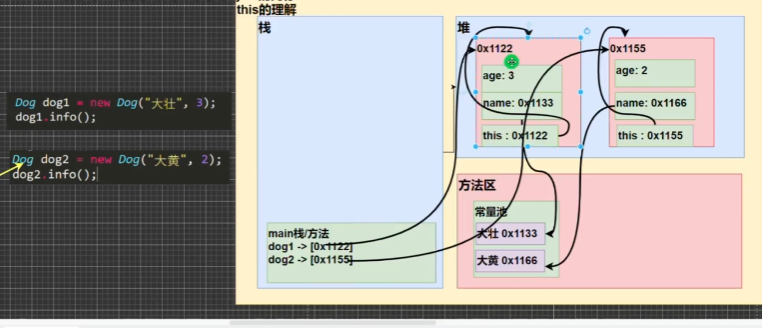
id(object) 函数用于返回对象的“标识值”。该标识值是一个整数,在对象的生命周期中保证唯一且恒定。
参数
- object:任何Python对象。
返回值
id(object) 返回一个整数,表示对象的唯一标识值。
特性
- 唯一性:在对象的生命周期中,标识值是唯一的。
- 恒定性:在对象的生命周期中,标识值是恒定不变的。
- 范围:两个生命周期不重叠的对象可能具有相同的id值。
实现细节(CPython)
在CPython实现中,id() 返回对象在内存中的地址。因此,标识值实际上是对象指针的内存地址。
安全性
调用id()函数时会引发一个审计事件 builtins.id,伴随的参数是返回的标识值。这意味着在一些受限或敏感的环境中(例如某些安全模式或沙盒环境),调用此函数可能有额外的安全审查或限制。
示例
以下是一些使用 id() 函数的示例:
a = [1, 2, 3]
b = a
c = [1, 2, 3]
print(id(a)) # 输出类似于 140437284863232
print(id(b)) # 输出与 id(a) 相同,因为 b 是对 a 的引用
print(id(c)) # 输出不同的值,因为 c 是一个新的列表对象注意事项
- 使用id()时要意识到,虽然返回值在对象生命周期内是唯一的,但当对象被销毁后,内存地址可能会被新的对象重用,因此在不同的时间点,相同的id值并不保证代表同一个对象。
- 在调试或需要精确追踪对象引用的场景中,id()函数非常有用。
相关函数
- hash(object):返回对象的哈希值。
- is 运算符:比较两个对象的标识值是否相同。
参考文献
- Python 官方文档 - id() 函数(https://docs.python.org/3/library/functions.html#id)
- PEP 578 -- Python Runtime Audit Hooks(https://www.python.org/dev/peps/pep-0578/)
通过理解 id(object) 函数,可以更好地掌握Python中对象的内存管理和引用机制。
记忆策略
功能联想法:记住 id 函数是返回对象的唯一标识值时,可以联想到它的功能是与“标识”(identifier)相关的。在英语中,“标识”一词为 identifier,而 id 是它的缩写。
常用场景
以下是 id(object) 函数在实际编程中几个最有用的使用场景,并且每行代码都有详细的注释。
场景 1:比较两个对象是否是同一个对象
在Python中,使用 id() 可以判断两个对象是否实际上是同一个对象。这比使用 == 更深入,因为 == 比较的是对象的值,而 id() 比较的是对象的身份。
a = [1, 2, 3] # 创建一个列表对象
b = a # 将 b 引用到 a,实际上 b 和 a 是同一个对象
c = [1, 2, 3] # 创建另一个列表对象,内容相同但对象不同
# 比较对象的标识值
print(id(a) == id(b)) # 输出 True,a 和 b 是同一个对象
print(id(a) == id(c)) # 输出 False,a 和 c 是不同的对象
# 使用 `is` 运算符进行同样的比较
print(a is b) # 输出 True,a 和 b 是同一个对象
print(a is c) # 输出 False,a 和 c 是不同的对象场景 2:跟踪对象的生命周期
通过 id() 函数可以跟踪对象在程序运行过程中的生命周期,特别是在调试时可以确认对象是否被创建或销毁。
class MyClass:
pass
def create_and_print_id():
obj = MyClass() # 创建一个对象
obj_id = id(obj) # 获取对象的标识值
print(f'Object ID inside function: {obj_id}') # 打印对象的标识值
return obj_id
obj_id_outside = create_and_print_id()
print(f'Object ID outside function: {obj_id_outside}') # 再次打印对象的标识值
# 尝试再次创建对象并比较标识值
new_obj = MyClass()
new_obj_id = id(new_obj)
print(f'New Object ID: {new_obj_id}') # 打印新创建对象的标识值
# 检查是否与之前的对象标识值相同
print(obj_id_outside == new_obj_id) # 输出 False,如果是不同对象场景 3:检测对象的共享与复制
在某些情况下,了解对象是共享的(引用相同的对象)还是被复制的(创建了新对象),对调试和优化代码很重要。
import copy
original_list = [1, 2, 3] # 创建一个原始列表对象
shared_list = original_list # 共享原始列表
copied_list = copy.deepcopy(original_list) # 深复制原始列表
print(id(original_list)) # 输出原始列表的标识值
print(id(shared_list)) # 输出与原始列表相同的标识值,因为是同一个对象
print(id(copied_list)) # 输出不同的标识值,因为是深复制的新对象
# 使用 `is` 运算符进行同样的检查
print(original_list is shared_list) # 输出 True,两个引用指向同一个对象
print(original_list is copied_list) # 输出 False,两个引用指向不同的对象场景 4:检测变量是否指向None
当需要确认一个变量是否指向 None 时,可以通过 id() 来确认。
none_var = None # 创建一个 `None` 类型的变量
some_var = 42 # 创建一个非 None 的变量
none_id = id(None) # 获取 `None` 的标识值
# 检查变量的标识值是否与 `None` 的标识值相同
print(id(none_var) == none_id) # 输出 True,因为 none_var 是 None
print(id(some_var) == none_id) # 输出 False,因为 some_var 不是 None以上是几个常见且实用的 id(object) 函数的使用场景,每个例子都包括详细的注释,帮助理解其用法和作用。
巧妙用法
id(object) 函数虽然看似简单,但在一些特定场景下可以通过巧妙的应用来解决问题或优化代码。以下是一些一般人可能想不到的使用技巧:
巧妙使用 1:检测对象是否被回收
在某些情况下,你可能需要确认一个对象是否已经被垃圾回收器回收。通过 id() 和弱引用(weakref 模块),你可以实现这一目的。
import weakref
class MyClass:
pass
# 创建对象并获取其标识值
obj = MyClass()
obj_id = id(obj)
# 创建弱引用
weak_ref = weakref.ref(obj)
# 删除原始引用
del obj
# 检查对象是否已经被回收
if weak_ref() is None:
print(f'Object with id {obj_id} has been garbage collected.')
else:
print(f'Object with id {obj_id} is still alive.')巧妙使用 2:基于对象ID的唯一性生成哈希值
在一些应用场景中,可能需要为对象生成唯一的哈希值。虽然Python的hash()函数已经提供了对象的哈希值,但在某些情况下,基于对象ID生成哈希值可能更实用。
class UniqueHasher:
def __init__(self, obj):
self.obj = obj
self.obj_id = id(obj)
def __hash__(self):
return self.obj_id
my_obj = UniqueHasher([1, 2, 3])
print(hash(my_obj)) # 输出对象的唯一哈希值,基于其 id巧妙使用 3:对象池管理
在需要管理大量对象实例的场景中,可以使用 id() 来跟踪和管理对象池,确保对象的唯一性和复用性。
class ObjectPool:
def __init__(self):
self._pool = {}
def get(self, obj_class):
obj = obj_class()
obj_id = id(obj)
if obj_id not in self._pool:
self._pool[obj_id] = obj
return self._pool[obj_id]
class MyClass:
pass
pool = ObjectPool()
obj1 = pool.get(MyClass)
obj2 = pool.get(MyClass)
print(id(obj1)) # 输出 obj1 的标识值
print(id(obj2)) # 输出 obj2 的标识值,应该与 obj1 一样
# 因为 obj1 和 obj2 实际上是同一个对象
print(obj1 is obj2) # 输出 True巧妙使用 4:缓存机制
通过 id() 可以实现基于对象唯一标识的缓存机制,特别适用于需要频繁访问相同对象的场景。
class CachedObject:
_cache = {}
def __new__(cls, value):
obj_id = id(value)
if obj_id in cls._cache:
return cls._cache[obj_id]
new_obj = super(CachedObject, cls).__new__(cls)
cls._cache[obj_id] = new_obj
return new_obj
def __init__(self, value):
self.value = value
# 初始化并缓存对象
obj1 = CachedObject([1, 2, 3])
obj2 = CachedObject([1, 2, 3])
print(id(obj1)) # 输出 obj1 的标识值
print(id(obj2)) # 输出 obj2 的标识值,应该与 obj1 一样
# 因为 obj1 和 obj2 实际上是同一个对象
print(obj1 is obj2) # 输出 True通过这些巧妙的使用技巧,id(object) 函数可以在对象管理、内存优化、缓存机制等多个方面发挥意想不到的作用。
综合技巧
id(object) 函数可以与其他函数或方法组合使用,以解决一些复杂的问题或实现巧妙的功能。以下是一些示例,这些示例展示了如何将 id() 与其他函数或方法结合使用,以实现独特且实用的效果。
巧妙用法 1:与 weakref 模块结合,用于对象生命周期管理
通过 id() 和 weakref 模块的结合,可以监控对象的生命周期,实现对象缓存或对象池的自动清理。
import weakref
class MyClass:
pass
class ObjectManager:
def __init__(self):
self._objects = weakref.WeakValueDictionary()
def get_object(self):
obj = MyClass()
obj_id = id(obj)
self._objects[obj_id] = obj
return obj
def is_alive(self, obj):
return id(obj) in self._objects
manager = ObjectManager()
obj1 = manager.get_object()
obj_id1 = id(obj1)
print(manager.is_alive(obj1)) # 输出 True
# 删除引用后检查对象是否仍然存在
del obj1
print(manager.is_alive(obj_id1)) # 输出 False巧妙用法 2:与 inspect 模块结合,用于调试和跟踪对象
通过 id() 和 inspect 模块,可以在调试时更深入地了解对象的状态和属性,帮助识别和解决问题。
import inspect
class MyClass:
def method(self):
pass
# 创建对象
obj = MyClass()
# 获取对象的标识值
obj_id = id(obj)
# 使用 inspect 获取对象的信息
def print_object_info(o):
print(f'Object ID: {id(o)}')
print(f'Object Type: {type(o)}')
print(f'Object Methods: {inspect.getmembers(o, predicate=inspect.ismethod)}')
print_object_info(obj)巧妙用法 3:与 gc 模块结合,用于垃圾回收调试
通过 id() 和 gc 模块,可以检查哪些对象正在被引用,帮助调试内存泄漏问题。
import gc
class MyClass:
pass
# 创建对象并获取其标识值
obj = MyClass()
obj_id = id(obj)
# 强制进行垃圾回收
gc.collect()
# 查找所有对象
all_objects = gc.get_objects()
# 检查对象是否在被引用
is_in_gc = any(id(o) == obj_id for o in all_objects)
print(f'Object with ID {obj_id} is in GC: {is_in_gc}')巧妙用法 4:与自定义装饰器结合,实现缓存优化
通过 id() 和装饰器,可以实现基于对象的缓存优化,避免重复计算。
from functools import wraps
def cache_by_object_id(func):
cache = {}
@wraps(func)
def wrapper(obj, *args, **kwargs):
obj_id = id(obj)
if obj_id not in cache:
cache[obj_id] = func(obj, *args, **kwargs)
return cache[obj_id]
return wrapper
class ComplexCalculator:
def __init__(self, data):
self.data = data
@cache_by_object_id
def expensive_computation(self):
# 假设这是一个耗时的计算
result = sum(self.data)
print("Computed result:", result)
return result
data = [1, 2, 3, 4, 5]
calculator = ComplexCalculator(data)
# 第一次调用会执行计算
result1 = calculator.expensive_computation()
# 第二次调用会使用缓存
result2 = calculator.expensive_computation()
print(result1 == result2) # 输出 True巧妙用法 5:与 __slots__ 结合,优化内存使用
通过 id() 和 __slots__ 特性,可以在对象实例中保存唯一标识符,用于内存优化。
class SlotClass:
__slots__ = ('_unique_id',)
def __init__(self):
self._unique_id = id(self)
@property
def unique_id(self):
return self._unique_id
# 创建对象
obj = SlotClass()
# 获取对象的唯一标识符
print(f'Object Unique ID: {obj.unique_id}')这些组合使用技巧展示了如何将 id(object) 与其他方法和模块结合,以实现更复杂和巧妙的功能。通过这些示例,可以更深入理解和应用 id(object) 函数。
感谢阅读。