一、每日一题
表: Employee
+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | salary | int | +-------------+------+ 在 SQL 中,id 是该表的主键。 该表的每一行都包含有关员工工资的信息。
查询 Employee 表中第 n 高的工资。如果没有第 n 个最高工资,查询结果应该为 null 。
查询结果格式如下所示。
示例 1:
输入: Employee table: +----+--------+ | id | salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+ n = 2 输出: +------------------------+ | getNthHighestSalary(2) | +------------------------+ | 200 | +------------------------+
示例 2:
输入: Employee 表: +----+--------+ | id | salary | +----+--------+ | 1 | 100 | +----+--------+ n = 2 输出: +------------------------+ | getNthHighestSalary(2) | +------------------------+ | null | +------------------------+
解答:
import pandas as pd
def nth_highest_salary(employee: pd.DataFrame, N: int) -> pd.DataFrame:
# 检查N是否为负数
if N <= 0:
return pd.DataFrame({f'getNthHighestSalary({N})': ['None']})
employee = employee.sort_values(by = 'salary', ascending = False)
# 去除重复的工资
employee = employee.drop_duplicates(subset = ['salary'])
# 选择第N高的工资,如果不存在则返回null
if len(employee) >= N:
return pd.DataFrame({f'getNthHighestSalary({N})': [int(employee.iloc[N - 1]['salary'])]})
else:
return pd.DataFrame({f'getNthHighestSalary({N})': {None}})
# 示例数据
data = {
'id': [1, 2, 3, 4, 5],
'salary': [1000, 2000, 3000, 2000, 1000]
}
df = pd.DataFrame(data)
# 获取第二高薪水
result = nth_highest_salary(df, 2)
print(result)
# 获取负数情况的处理
result_neg = nth_highest_salary(df, -1)
print(result_neg)
# 获取零的情况处理
result_zero = nth_highest_salary(df, 0)
print(result_zero)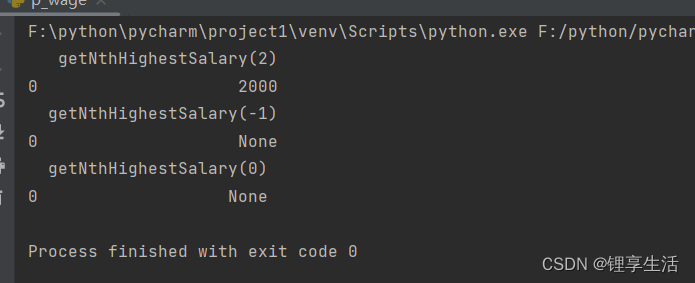
题源:Leetcode
二、 总结
在这个代码中,{N} 被 f'...' 中的 f-string 语法替换为具体值。这个修改会确保在 DataFrame 的列名中包含实际的 N 值。












![[自动驾驶技术]-8 Tesla自动驾驶方案之硬件(AI Day 2022)](https://img-blog.csdnimg.cn/direct/c646f2e5766f4121a681b6dec990148f.png)
![[码蹄集新手训练营]MT1016-MT1020](https://img-blog.csdnimg.cn/direct/acb48d2bc84d4d16b7c20375945e4994.jpeg#pic_center)