本文简要介绍了发表于ECCV 2022的论文“Don’t Forget Me: Accurate Background Recovery for Text Removal via Modeling Local-Global Context”的相关工作。该论文针对文本擦除中存在的复杂背景修复的问题,提出了CTRNet,它利用局部和全局的语义建模提升模型的背景还原能力,它设计了Low-level Contextual Guidance(LCG)和High-level Contextual Guidance(HCG)去挖掘不同的语义表征,然后通过Local-Global Content Modeling(LGCM)进行局部与全局的特征建模,从而提升文本擦除的能力。
一、研究背景
文本擦除在近几年得到了越来越多的关注,这项技术在隐私保护、视觉信息翻译和图片内容编辑等方面都有着很重要的作用;而且在教育、办公领域,文本擦除可以用于文档还原。因此,文字擦除不仅仅是给自然场景中的文字打上马赛克这样简单,而是要考虑在擦掉文字的同时保持文本区域背景的原特征,这就为这个任务带来了挑战。目前已有的工作如EraseNet[1],PERT[2], MTRNet++[3]等都是直接通过image-to-image的方式,它们对复杂文本背景的恢复效果并不是非常好,前景与背景经常存在明显的差异。本文受到Image Inainting领域相关工作[4][5]的启发,提出了一个通过挖掘不同语义表征去指引文本擦除的模型CTRNet,它设计了两种不同的语义表征,并通过局部-全局的特征建模提升了模型的性能。
二、方法介绍
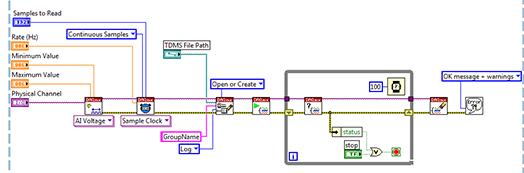
本文提出了一个全新的两阶段文本擦除网络CTRNet,它设计了两种不同的语义表征作为擦除指引,其中文本图像的Structure作为Low-level Contextual Guidance,而深层语义特征作为High-level Contextual Guidance;得到两种表征后,再通过Local- Global Content Modeling(LGCM)进行局部与全局的特征建模,最终再通过解码器得到最终的擦除结果。CTRNet的流程图如图1所示。

图1 CTRNet整体结构流程图

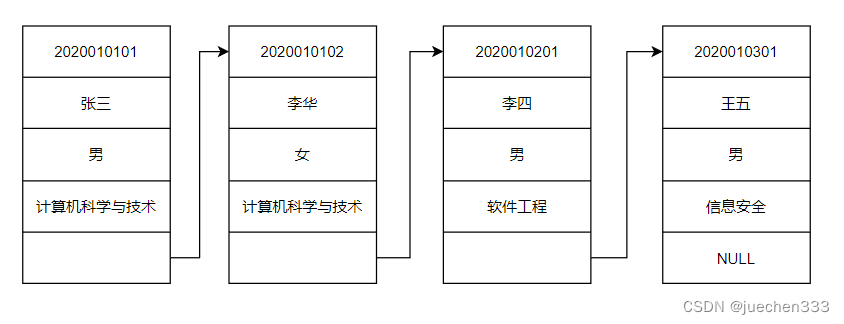
图2 数据示意图
2.1 文本感知分支与Soft Mask
CTRNet是一个两阶段的模型,即先进行文本检测得到文本位置,然后再根据检测结果对图片中各个文本进行擦除。该模型使用的是PAN [6]进行文本检测,在实现过程中,PAN会和整个擦除网络一起进行优化。此外,考虑到常规的0-1 Mask(Hard Mask)会在前景与背景的边界有明显的不连续问题,我们提出在训练和前向的过程中用Soft Mask代替原本的Hard Mask。示意图如图2(b),(c)所示。
2.2 Low-level Contextual Guidance(LCG)


图3
2.3 High-level Contextual Guidance
除了Low-level的结构语义先验外,我们还加入了HCG。在图像翻译以及图像修复的任务中,Perceptual/Style Loss验证了高层语义监督的有效性,因此我们认为这些语义可以作为额外的先验直接用于特征的解码与最终结果的生成,于是便在CTRNet中结合了一个HCG模块去学习并利用高层的语义特征。

2.4 Local-global Content Modeling (LGCM)
当模型进行文本擦除并合成相应背景的时候,除了参考本身的文本区域内容外,还需要利用区域周围以及整图各部分的信息作为参考。结合CNN提取局部特征的能力以及Transformer的全局建模能力,本文设计了LGCM模块,结构如图3(b)所示。其中CNN block进行下采样,而后Transformer-Encoder则是捕获全局像素之间的长距离关联,最后再通过上采样得到最终建模后的特征。此外LGCM模块还通过SPADE操作(图1中的Incor)结合了HCG得到的高层语义特征作为先验。
如图1所示,LGCM是一个迭代式的结构,CTRNet一共级联了8个LGCM模块。最终得到的特征用于解码得到最后的文本擦除结果。
2.5 损失函数

Perceptual/Style Loss

Adversarial Loss

三、实验
实验主要是在SCUT-EnsText以及SCUT-Syn两个公开数据集上进行。此外本文还采集了一个In-house的试卷数据集进行实验验证CTRNet的泛化性。
A. 对于各模块的消融实验结果如表1所示,可视化对比如图4所示
表1


图4
B. 与之前SOTA方法的对比实验结果如表2与图5所示—SCUT-EnsText
表2


图5
C. 与之前SOTA方法的对比实验结果如表3与图6所示—SCUT-Syn
表3


图6
D. 此外,还进行了与一些Image Inpainting方法的对比,结果如表4和图7所示
表4


图7
E.还在in-house手写试卷数据集上验证了CTRNet的有效性,如图8所示。

图8
四、总结与讨论
本文针对文本擦除中复杂背景的恢复问题提出了CTRNet,通过设计了两种不同形式的监督使得模型能学习到不同的语义表征,然后通过一个LGCM模块进行局部全局的特征建模并有效结合学习到的语义表征,以此在解码的时候能同时利用文本区域和整图其他区域的信息并恢复更加自然、合理的文本背景。在各个数据集上的实验也验证了该模型的有效性。
五、相关资源
论文地址:https://link.springer.com/chapter/10.1007/978-3-031-19815-1_24
代码地址:https://github.com/lcy0604/CTRNet
六、参考文献
[1] Liu, Chongyu, et al. "EraseNet: End-to-end text removal in the wild." IEEE Transactions on Image Processing 29 (2020): 8760-8775.
[2] Wang, Yuxin, et al. "PERT: A Progressively Region-based Network for Scene Text Removal."arXiv preprint arXiv:2106.13029 (2021).
[3] Tursun, Osman, et al. "MTRNet++: One-stage mask-based scene text eraser."Computer Vision and Image Understanding 201 (2020): 103066.
[4] Liu, Hongyu, et al. "Rethinking image inpainting via a mutual encoder-decoder with feature equalizations."European Conference on Computer Vision. Springer, Cham, 2020.
[5] Ren, Yurui, et al. "Structureflow: Image inpainting via structure-aware appearance flow."Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[6] Wang, Wenhai, et al. "Efficient and accurate arbitrary-shaped text detection with pixel aggregation network." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[7] Xu, Li, et al. "Structure extraction from texture via relative total variation."ACM transactions on graphics (TOG) 31.6 (2012): 1-10.
[8] Zhang, Wendong, et al. "Context-aware image inpainting with learned semantic priors."Proceedings of the International Joint Conference on Artificial Intelligence, 2021.
原文作者: Chongyu Liu, Lianwen Jin, Yuliang Liu, Canjie Luo, Bangdong Chen, Fengjun Guo, and Kai Ding