这篇发表于2020 WWW 上的会议论文,提出一种MNS方式的负样本采样方法。众所周知,MF方法难以解决冷启动问题,于是进化出双塔模型,但是以双塔模型为基础的召回模型的好坏十分依赖负样本的选取。为了解决Batch内负样本带来的选择性偏差问题,本文提出MNS方法融合了批采样和均匀采样。实验表明,配合这种负样本的采样的双塔模型的召回能力得到了明显提升。

1. 贡献
-
本文提出一种新颖的负样本采样方法——
MNS(Mixed Negative Sampling),用于缓解训练模型负样本的selection bias问题。
![[图片]](https://img-blog.csdnimg.cn/direct/adb0c2e2733f4952a5c6d25f54467dac.png)

-
MNS这一方法的主要是与之前通用的batch / unigram sampling methods(这两部分详见后面的介绍) 相比较。
2. 思想
2.1 历史方法
有许多工作在研究基于Embedding的信息检索。其中的典型工作就是MF。
- MF的关键问题在于冷启动;(i.e. it’s hard for this method to generalize to items that have no user interaction.)
于是人们想到的方法是利用content feature 去建模,从而避免这种对互动的依赖,从而引出了双塔模型。content feature 范围很广。作者在文中给出了一些示例:For instance, content features of an app could be text descriptions, creators, categories, etc.
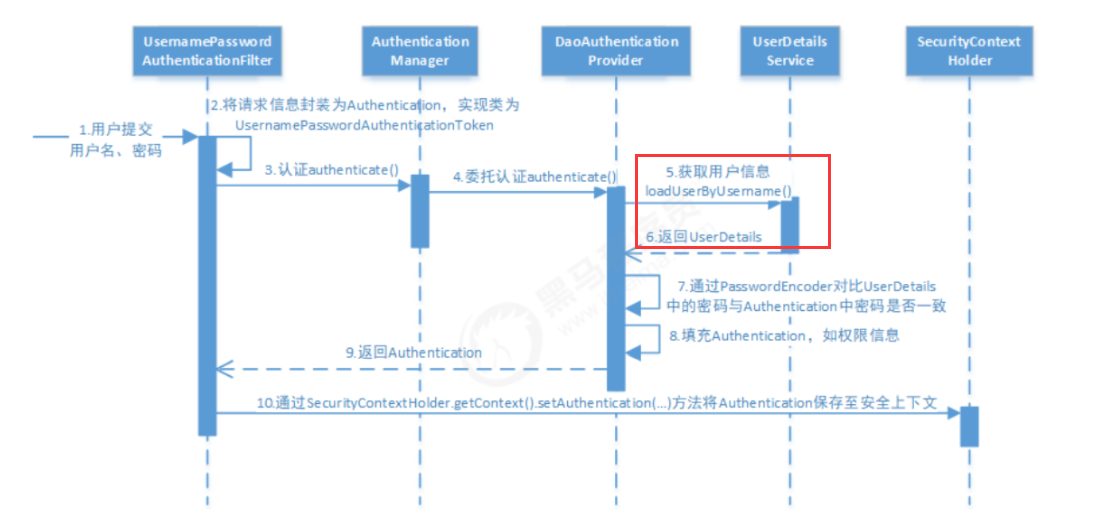
2.2 当前方法
新提出的双塔模型(Dual Encoder)方法架构如下:
![[图片]](https://img-blog.csdnimg.cn/direct/5394420c7f014fc1aa0843fda11633b0.png)
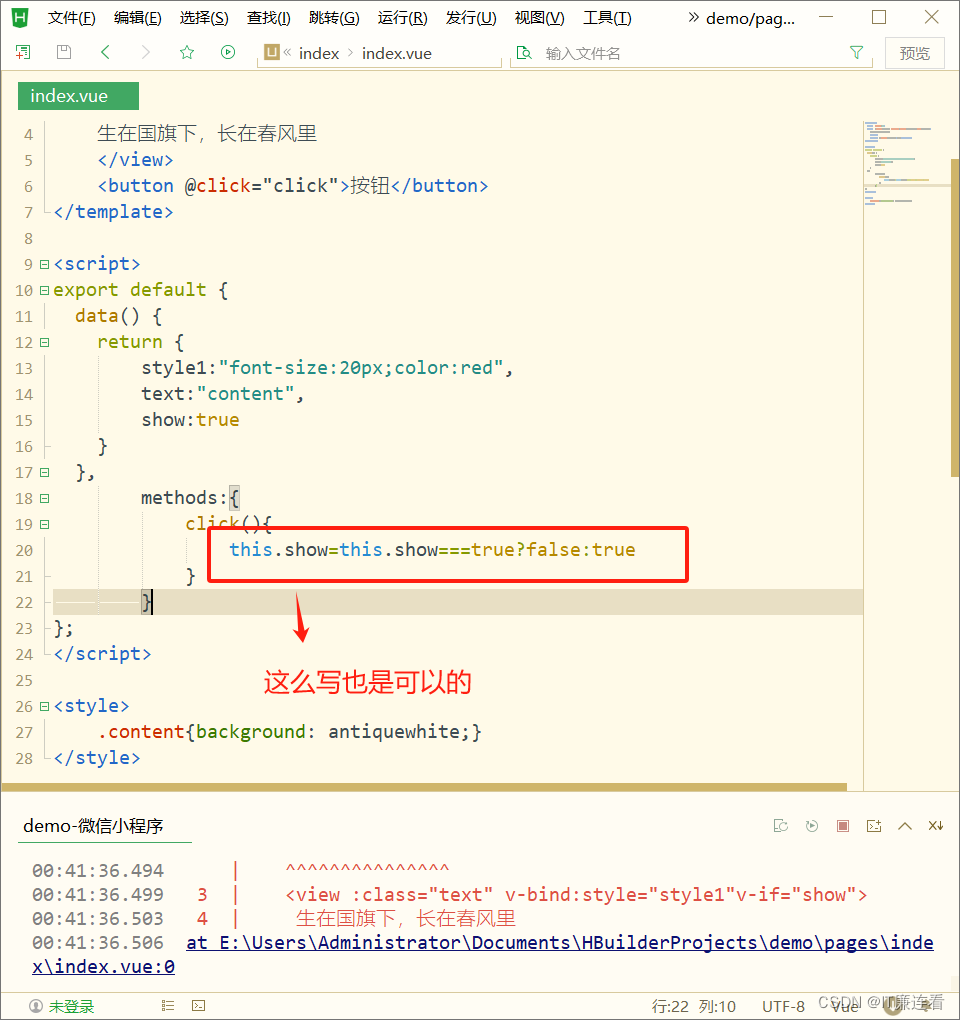
但新的架构又出现了新的问题:大家发现,对于双塔模型来说,其关键在于负样本的选取。
![[图片]](https://img-blog.csdnimg.cn/direct/8d19408f7e3b42fe8215fa9509f09e69.png)
其背后的原因是:
- 正样本(用户参与点击、互动、反馈)很好收集,负样本则很难(一是因为负样本太多,二是因为负样本不直观)。
之前的负样本采样方法主要是:- unigram sampling:
- batch negatives :【也就是用同一batch类的样本做负样本】
batch negatives方法存在的问题有:
(1)训练数据的选择偏差(selection bias)。batch negatives的弊端很明显:因为用同batch内的正样本做为其它对的负样本就会导致负样本选择过于局限的问题(因为正样本要么是新热高时鲜、要么就是质量好的,无法代表用户不想点击的那波负样本)。
![[图片]](https://img-blog.csdnimg.cn/direct/7945ebf0c42445f6b9e30603a11acbfd.png)
(2)采样函数缺少灵活性
batch negatives 方法受限于训练数据的分布,但是这个训练数据又是根据用户的点击得到,很难被直接调整。
同时hierarchical softmax 和 sampled softmax 均不适合训练双塔结构,原因是:

如果我们将召回问题视作是一个多分类问题,也就是如下表述:

那么在反向传播更新梯度的时候,就会遇到一个问题——很难在低时间复杂度的情况下计算出梯度;原因见作者在文中给出的一个推导:

这个推导说明的是:在庞大的语料库中,求出第二项是不切实际的(而这第二项又是更新梯度的关键项)。作者原文用的话是:It is generally impractical to compute the second term over all items in a huge corpus.
综合分析上述种种,本文提出方法:In particular, in addition to the negatives sampled from batch training data, we uniformly sample negatives from the candidate corpus to serve as additional negatives. 该方法简称 MNS。
MNS 的优势在于:
- 通过引入全局负样本(因为作者使用了均匀负采样),缓解选择偏差问题。
- 调整采样分布,通过改变额外的负样本的数目。
MNS的思想简图如下所示:
![[图片]](https://img-blog.csdnimg.cn/direct/795b7fc384674d89a110066e5c0a851c.png)
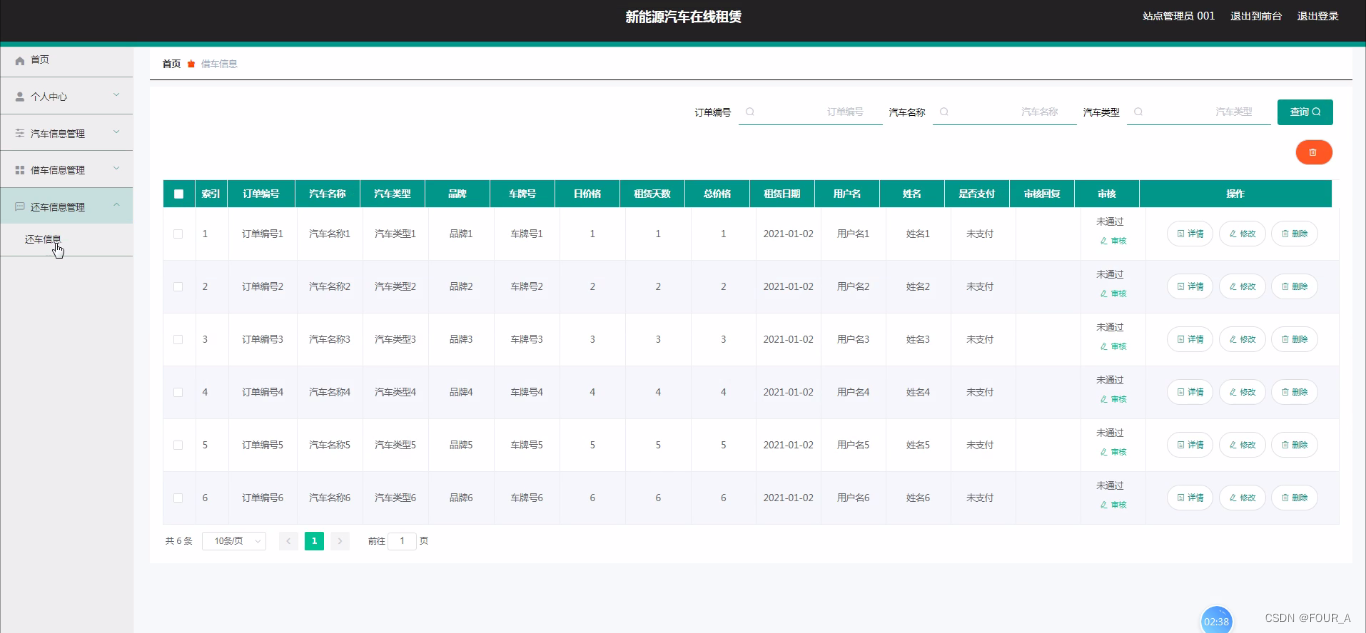
3. 实验
3.1 实验细节

3.2 实验结果
实验结果从如下几个方面进行考量:
- 离线Recall@K指标表明MNS明显地提升了检索质量;在线指标表明带来更多的高质量app安装(本文的场景应该是谷歌play,用于app 推荐)。
- 在线指标(AB实验)
3.2.1 比较模型性能
观察的结论:
- Two-tower with Batch Negatives 比 MLP with Sampled Softmax 的效果都要差。Batch Negatives 的这版模型召回了非常多的不相关的长尾app(这也与作者前文所述的 selection bias 相符合。背后的真实原因就是:Low-quality tail apps do not appear as negatives frequent enough.)
3.2.2 取MNS的超参数
前文说到:要对不常见的样本进行采样,那么采多少条呢?实验证明,在作者的这个场景中,取值是8192,这个可借鉴意义不大。
4. 疑问
- 这里的with various formats 是什么意思?
- unigram distribution是什么意思?
- sampled softmax 是什么意思?
有两篇论文可以参考学习: - label is associated with a rich set of content features.
5. 好句分享
a body of...一群…This paper lies in this line of work.本文就是这一类研究工作之一。Accordingly, sampling batch negatives only from training data will end up with a model lacking resolution for long-tail apps, which seldom appear in the training data.
end up with以 … 结束