AOP、注解、EL表达、若依权限,Security原理综合分析
案例一:更新、创建增强
需求产生
每个表中均有创建时间、创建人、修改时间、修改人等字段。
在操作时候手动赋值,就会导致编码相对冗余、繁琐,那能不能对于这些公共字段在某个地方统一处理,来简化开发呢?
答案是可以的,我们使用AOP切面编程,实现功能增强,来完成公共字段自动填充功能。
实现思路
有四个公共字段,需要在新增/更新中进行赋值操作, 具体情况如下:
| 数据库字段名 | 数据库字段类型 | 实体类字段名 | 实体类字段类型 | 操作 |
|---|---|---|---|---|
| create_time | datetime | createTime | java.util.Date | 创建的时候赋值 |
| create_by | varchar | createBy | String | 创建的时候赋值 |
| update_time | datetime | updateTime | java.util.Date | 更新的时候赋值 |
| update_by | varchar | updateBy | String | 更新的时候赋值 |
分析
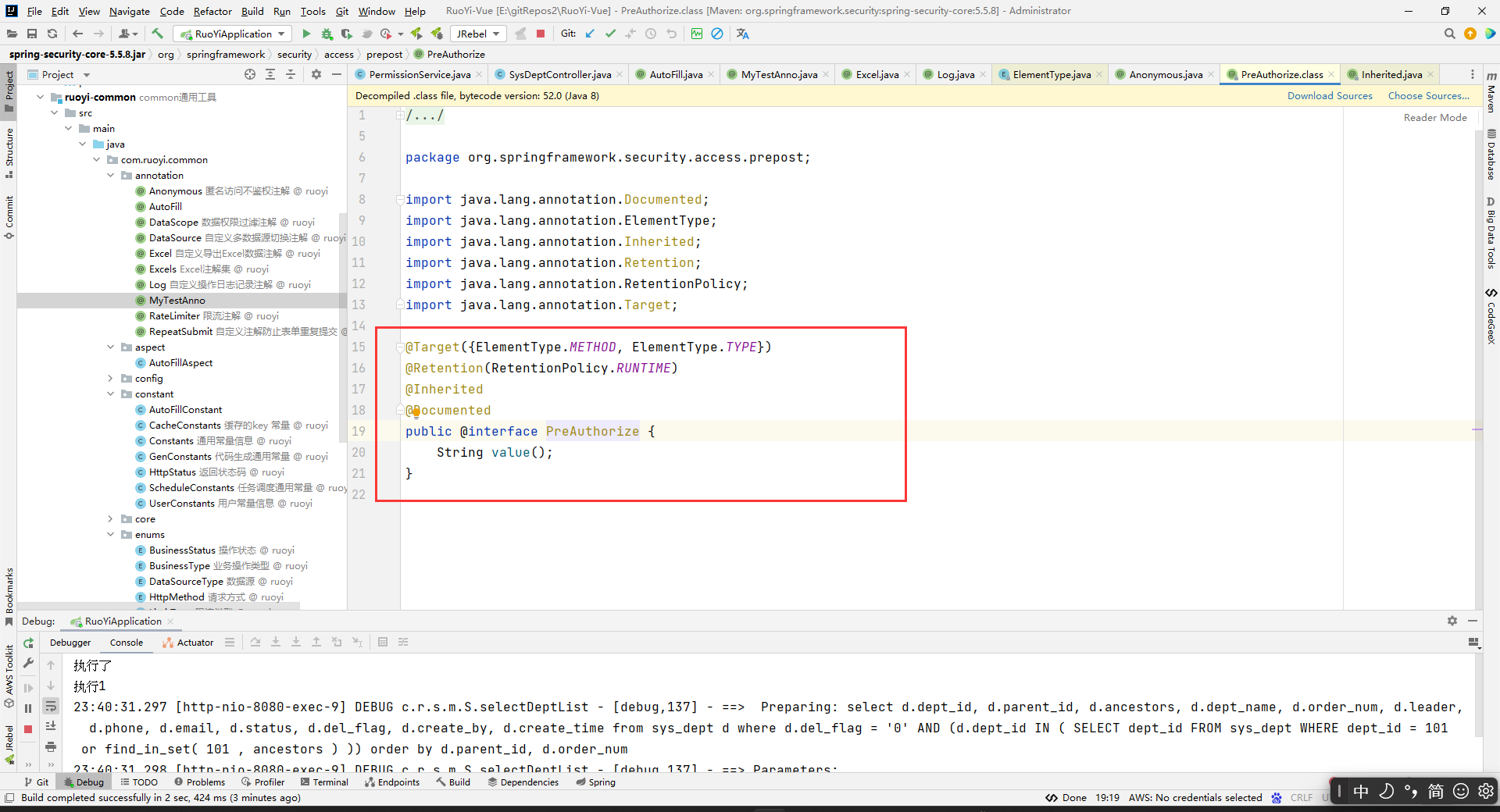
- 自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法
- 自定义切面类 AutoFillAspect,统一拦截加入了 AutoFill 注解的方法,通过反射为公共字段赋值
- 使用。在 Mapper 层需要为createTime、createBy、updateTime、updateBy赋值的方法上加入 AutoFill 注解
操作
-
引入依赖
<!-- aspects切面 --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aspects</artifactId> </dependency>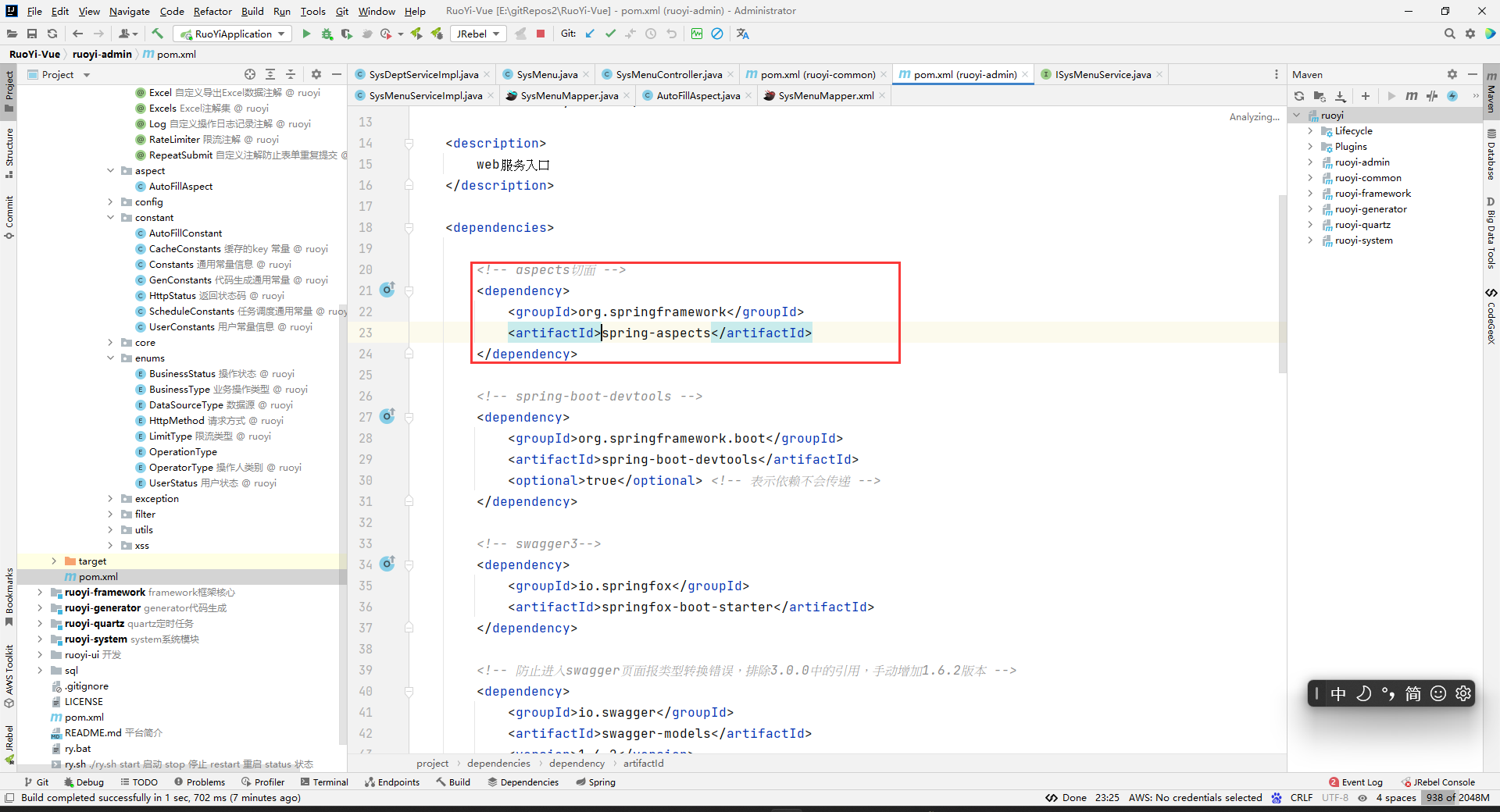
-
在common的constant包下创建AutoFillConstant类。一般常量我们都使用常量类来管理。
package com.ruoyi.common.constant; /** * @Author yimeng * @Date 2024/4/29 9:45 * @PackageName:com.ruoyi.common.constant.autoFill * @ClassName: AutoFillConstant * @Description: 公共字段自动填充相关常量 * @Version 1.0 */ public class AutoFillConstant { /** * 实体类中的方法名称 */ public static final String SET_CREATE_TIME = "setCreateTime"; public static final String SET_UPDATE_TIME = "setUpdateTime"; public static final String SET_CREATE_BY = "setCreateBy"; public static final String SET_UPDATE_BY = "setUpdateBy"; }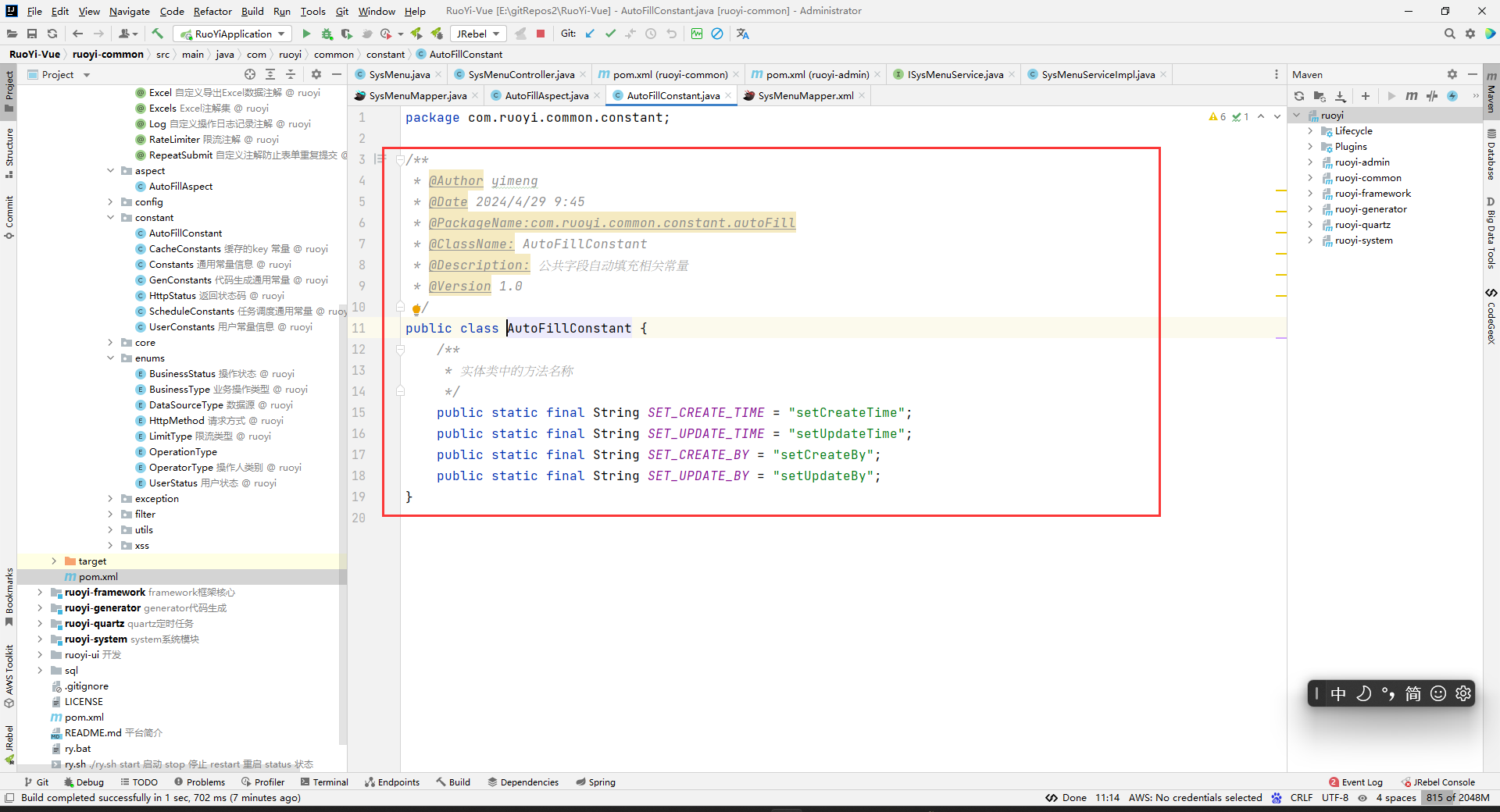
-
在common的enums包下创建OperationType类。一般用于可选一类东西的时候,都用枚举,就像下拉框一样,你可以在多个同类值中选择你要的,你就用下拉框,后端的话,我们一般可以用枚举类。
package com.ruoyi.common.enums; /** * @Author yimeng * @Date 2024/4/29 9:46 * @PackageName:com.ruoyi.common.enums * @ClassName: OperationType * @Description: 数据库操作类型 * @Version 1.0 */ public enum OperationType { /** * 插入操作 */ INSERT, /** * 更新操作 */ UPDATE, }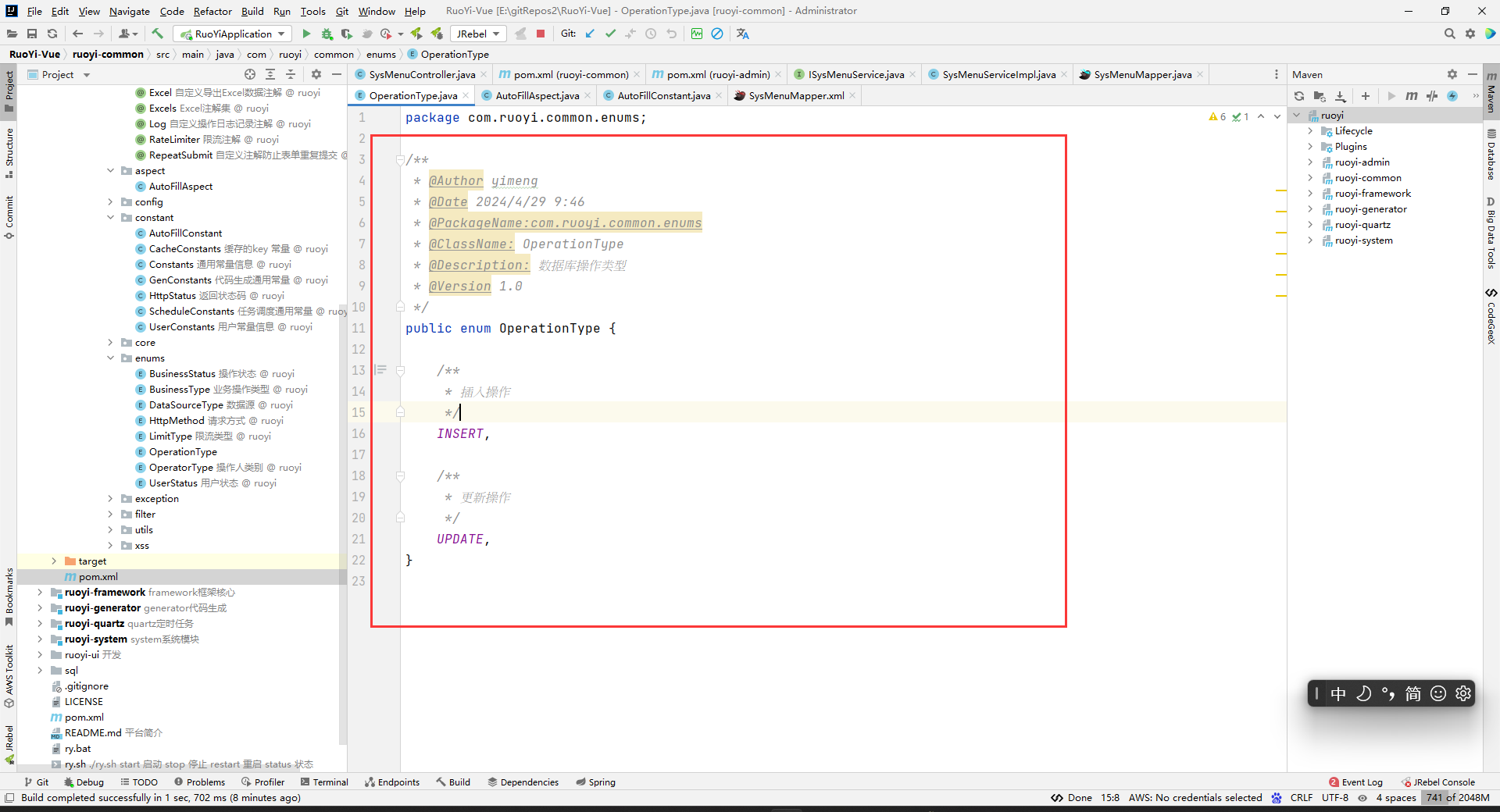
-
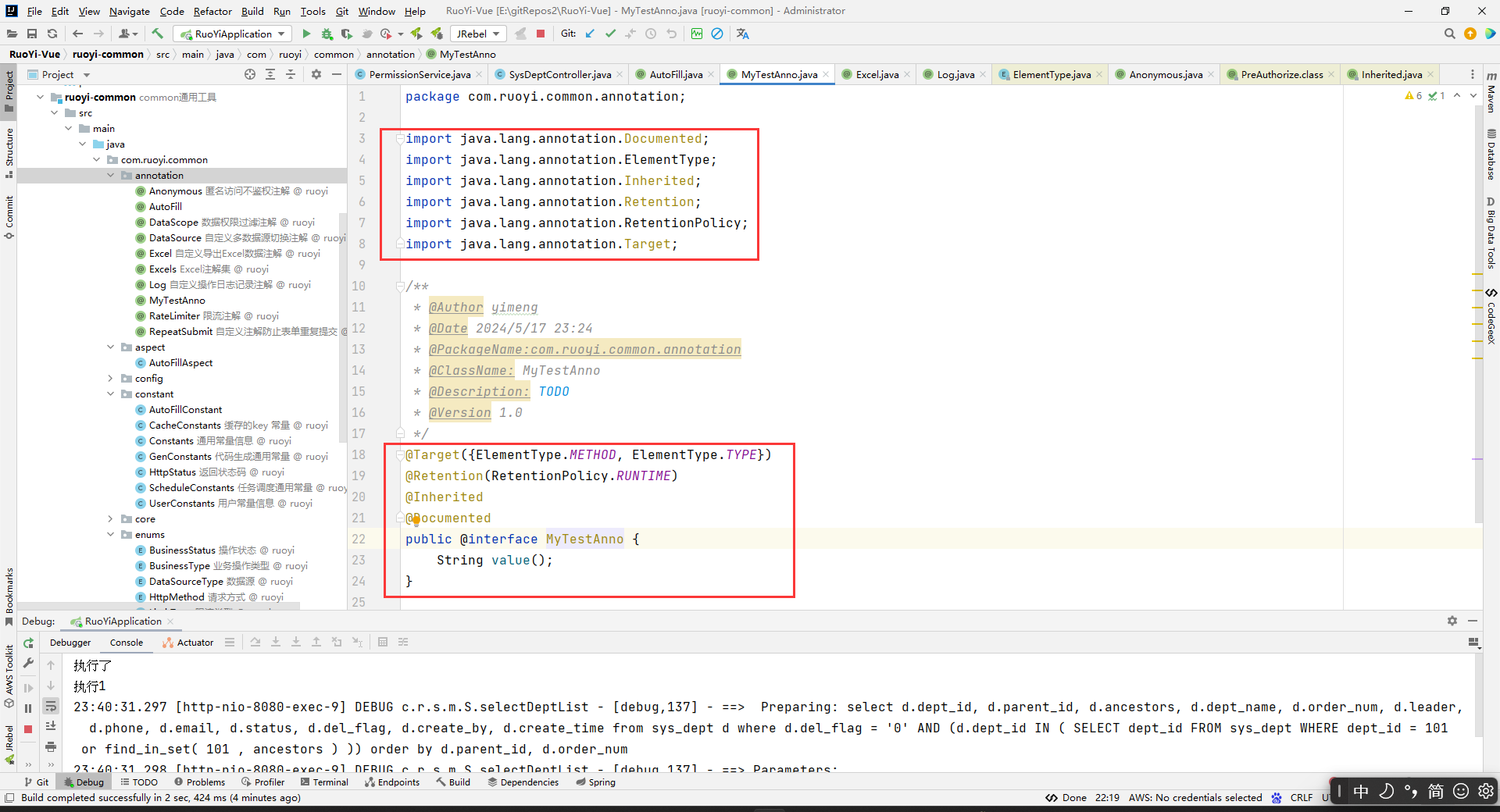
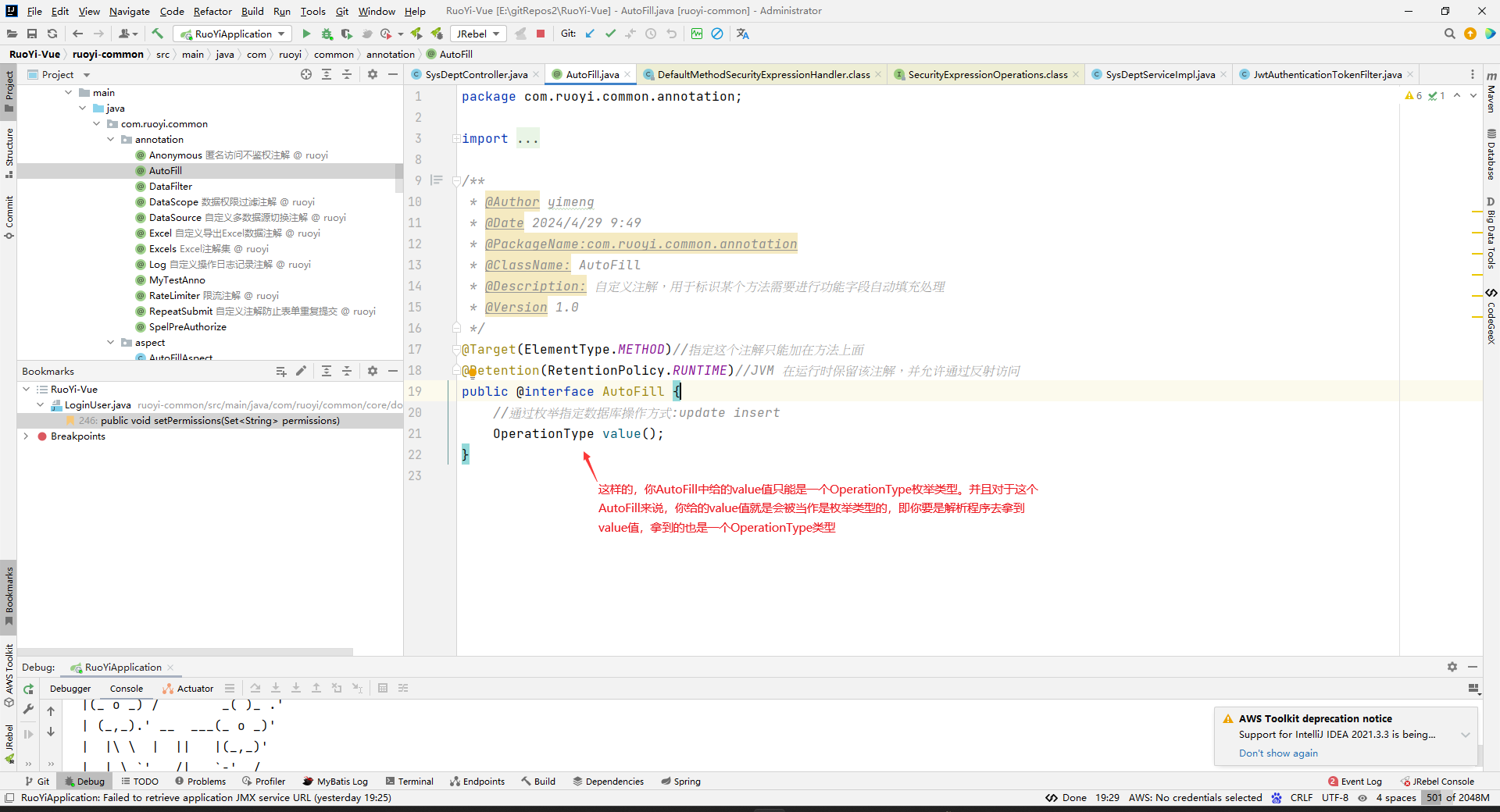
在annotation包下创建AutoFill注解。
package com.ruoyi.common.annotation; import com.ruoyi.common.enums.OperationType; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; /** * @Author yimeng * @Date 2024/4/29 9:49 * @PackageName:com.ruoyi.common.annotation * @ClassName: AutoFill * @Description: 自定义注解,用于标识某个方法需要进行功能字段自动填充处理 * @Version 1.0 */ @Target(ElementType.METHOD)//指定这个注解只能加在方法上面 @Retention(RetentionPolicy.RUNTIME)//JVM 在运行时保留该注解,并允许通过反射访问。 public @interface AutoFill { //通过枚举指定数据库操作方式:update insert OperationType value(); }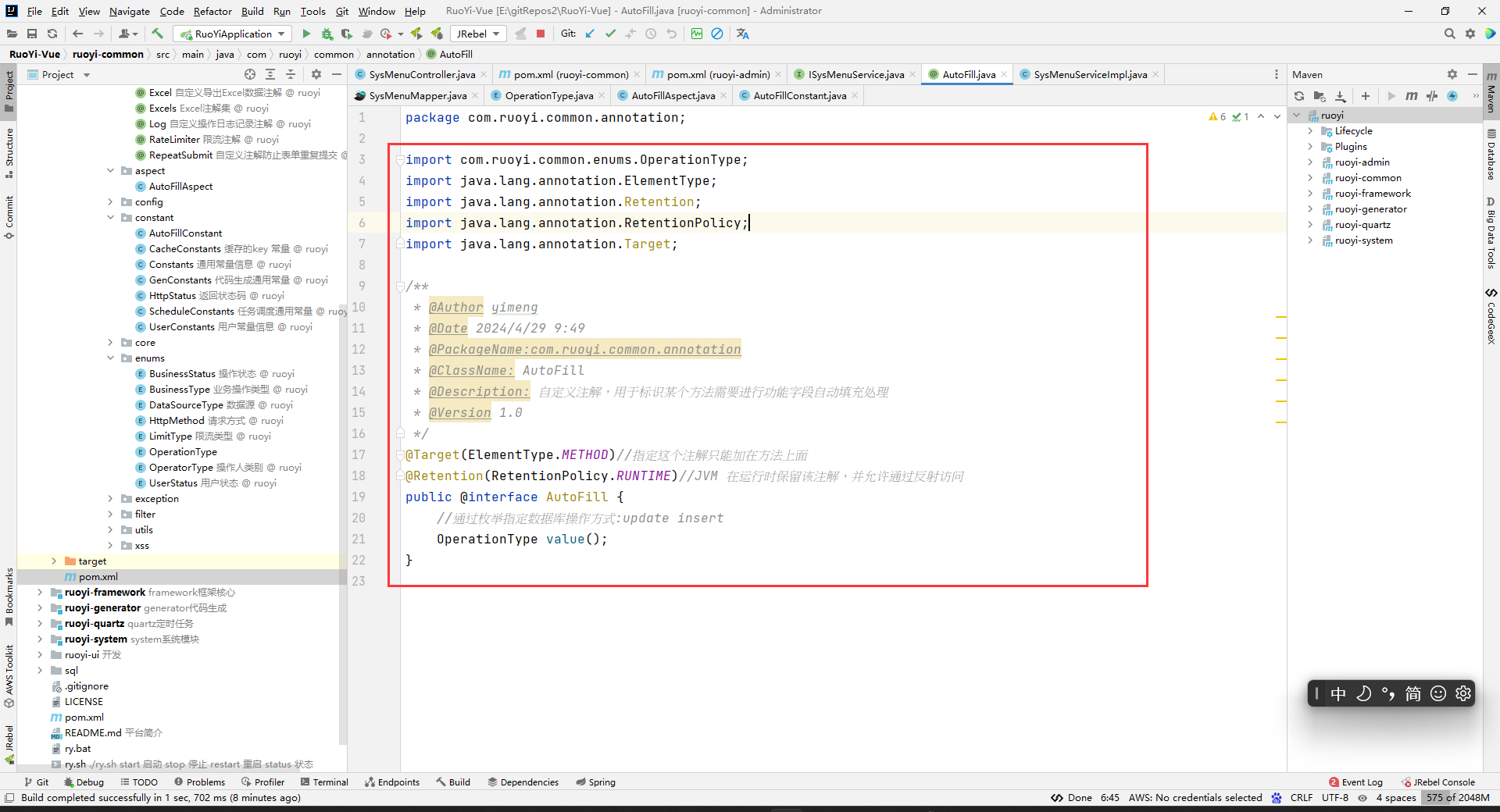
-
在aspect包下创建AutoFillAspect自定义切面类
package com.ruoyi.common.aspect; import com.ruoyi.common.annotation.AutoFill; import com.ruoyi.common.constant.AutoFillConstant; import com.ruoyi.common.enums.OperationType; import com.ruoyi.common.utils.SecurityUtils; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.aspectj.lang.annotation.Pointcut; import org.aspectj.lang.reflect.MethodSignature; import org.springframework.stereotype.Component; import java.lang.reflect.Method; import java.util.Date; /* 问题1:数据库字段的命名 答:create_time、update_time、create_by、update_by 问题2:数据库字段的类型(和上面对应) 答:datetime、datetime、varchar、varchar 问题3:实体类字段的类型(和上面对应) 答:Date、Date、String、String 问题3:创建的时候给更新时间吗? 答:创建的时候给更新时间和创建时间 问题4:使用 答:在 com.ruoyi.任意深度的包.mapper 层的方法上加上注解@AutoFill。约定方法的实参第一个要是被操作的表对应的实体类。注解可以选择的value值为INSERT、UPDATE。 问题5:各注解的效果 答: @AutoFill(INSERT) 创建的时候自动填充create_time、create_by、update_time、update_by字段 @AutoFill(UPDATE) 更新的时候自动填充update_time、update_by字段 */ /** * @Author yimeng * @Date 2024/4/29 9:53 * @PackageName:com.ruoyi.common.aspect * @ClassName: AutoFillAspect * @Description: 自定义切面,实现公共字段自动填充处理逻辑 * @Version 1.0 */ @Aspect//声明是切面 @Component//bean交给spring容器管理 //@Slf4j public class AutoFillAspect { /** * 定义切入点 */ //切点表达式(com.ruoyi..mapper: 表示匹配com.ruoyi包下任意深度子包中的mapper包。*.*: 表示匹配mapper包下所有类的所有方法。@annotation(com.ruoyi.common.annotation.AutoFill): 表示匹配带有com.ruoyi.common.annotation.AutoFill注解的方法。要两个条件都满足才能被这个方法切入)。这里写的这个方法名是任意的,叫什么都行,不用写什么方法体内容,这里主要是把execution(* com.ruoyi..mapper.*.*(..)) && @annotation(com.ruoyi.common.annotation.AutoFill)进行抽取而已,然后下面的@Before("autoFillPointCut()")就相当于是写了@Before("execution(* com.ruoyi..mapper.*.*(..)) && @annotation(com.ruoyi.common.annotation.AutoFill)"). @Pointcut("execution(* com.ruoyi..mapper.*.*(..)) && @annotation(com.ruoyi.common.annotation.AutoFill)") public void autoFillPointCut(){} /** * 定义前置通知,在通知中进行公共字段的赋值 */ //前置通知,在执行操作之前.注意:前置通知执行后会自动执行我们的目标方法的,所以这里不用我们在这个增强方法里面调用目标方法去执行。不像环绕通知,环绕通知需要我们手动去调用目标方法,不然将不会自动去执行目标方法 @Before("autoFillPointCut()")//匹配上切点表达式的时候,执行通知方法。这里的@Before内写的是上面抽取的方法名。 public void autoFill(JoinPoint joinPoint){//连接点,哪个方法被拦截到了,以及拦截到的方法参数值和类型 // log.info("开始进行公共字段自动填充..."); /** * 通知内容 */ //1.获取到当前被拦截的方法上的数据库操作类型 MethodSignature signature = (MethodSignature) joinPoint.getSignature();//方法签名对象,Signature是接口转为MethodSignature子接口 AutoFill autoFill = signature.getMethod().getAnnotation(AutoFill.class);//获得方法上的注解对象 OperationType operationType = autoFill.value();//获得写在mapper方法上的数据库操作类型。被OperationType注解管理。 //2.获取到当前被拦截的方法的参数,也就是实体对象 Object[] args = joinPoint.getArgs();//获得连接点的参数,有多个参数,约定第一个参数是实体 if(args == null || args.length == 0){ return; } Object entity = args[0];//数据库操作方法中,约定实体类必须是第一个参数,获取实体 //3.准备赋值的数据 Date now = new Date(); String userName = SecurityUtils.getUsername(); //4.获取class对象 Class<?> clazz = entity.getClass(); //5.根据当前不同的操作类型,为对应的属性通过反射来赋值 if(operationType == OperationType.INSERT){ //为公共字段赋值 try { //获取set方法 //规范化,防止写错,所以将方法名写为常量类。 //注意:getDeclaredMethod方法不能获取到父类继承的方法,但是getMethod可以获取到,所以这里用getMethod方法。 // Method setCreateTime = clazz.getDeclaredMethod(AutoFillConstant.SET_CREATE_TIME, Date.class); Method setCreateTime = clazz.getMethod(AutoFillConstant.SET_CREATE_TIME, Date.class); Method setCreateBy = clazz.getMethod(AutoFillConstant.SET_CREATE_BY, String.class); Method setUpdateTime = clazz.getMethod(AutoFillConstant.SET_UPDATE_TIME, Date.class); Method setUpdateBy = clazz.getMethod(AutoFillConstant.SET_UPDATE_BY, String.class); //通过反射为对象属性赋值 setCreateTime.invoke(entity,now); setCreateBy.invoke(entity,userName); setUpdateTime.invoke(entity,now); setUpdateBy.invoke(entity,userName); } catch (Exception e) { e.printStackTrace(); } }else if(operationType == OperationType.UPDATE){ //为公共字段赋值 try { //获取set方法 Method setUpdateTime = clazz.getMethod(AutoFillConstant.SET_UPDATE_TIME, Date.class); Method setUpdateBy = clazz.getMethod(AutoFillConstant.SET_UPDATE_BY, String.class); //通过反射为对象属性赋值 setUpdateTime.invoke(entity,now); setUpdateBy.invoke(entity,userName); } catch (Exception e) { e.printStackTrace(); } } } }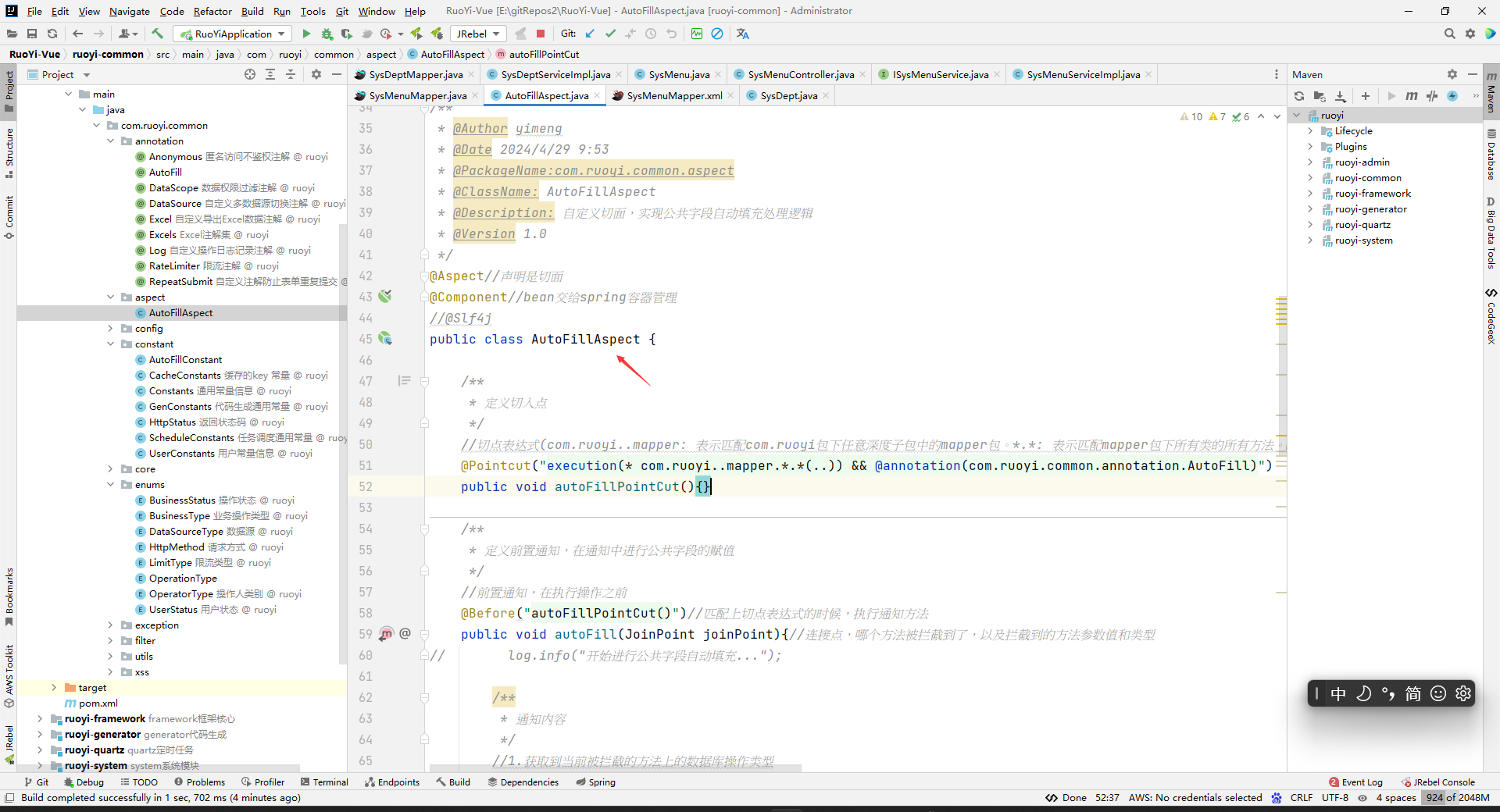
使用:
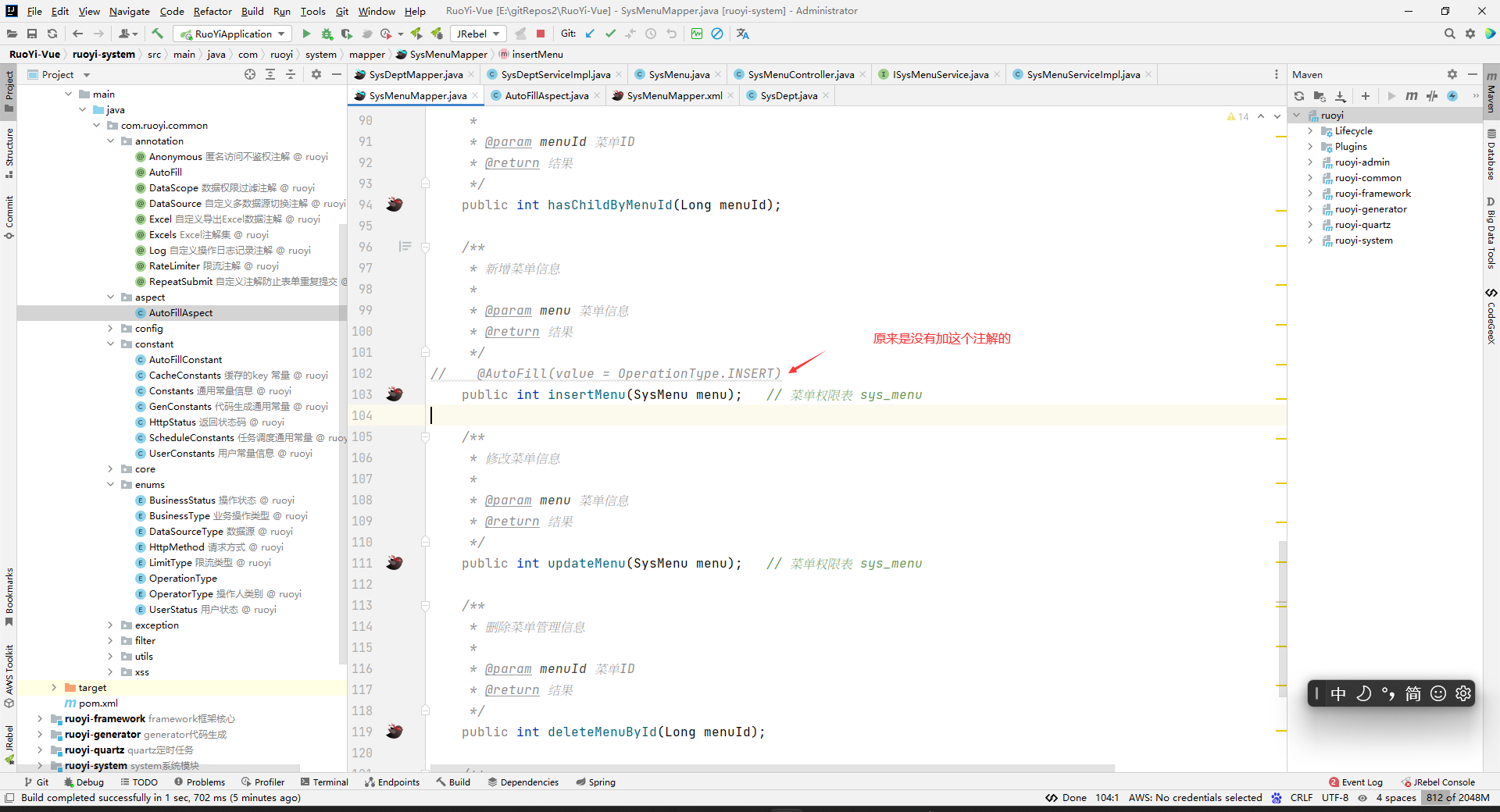
public interface SysMenuMapper{ /** * 新增菜单信息 * * @param menu 菜单信息 * @return 结果 */ @AutoFill(value = OperationType.INSERT) public int insertMenu(SysMenu menu); }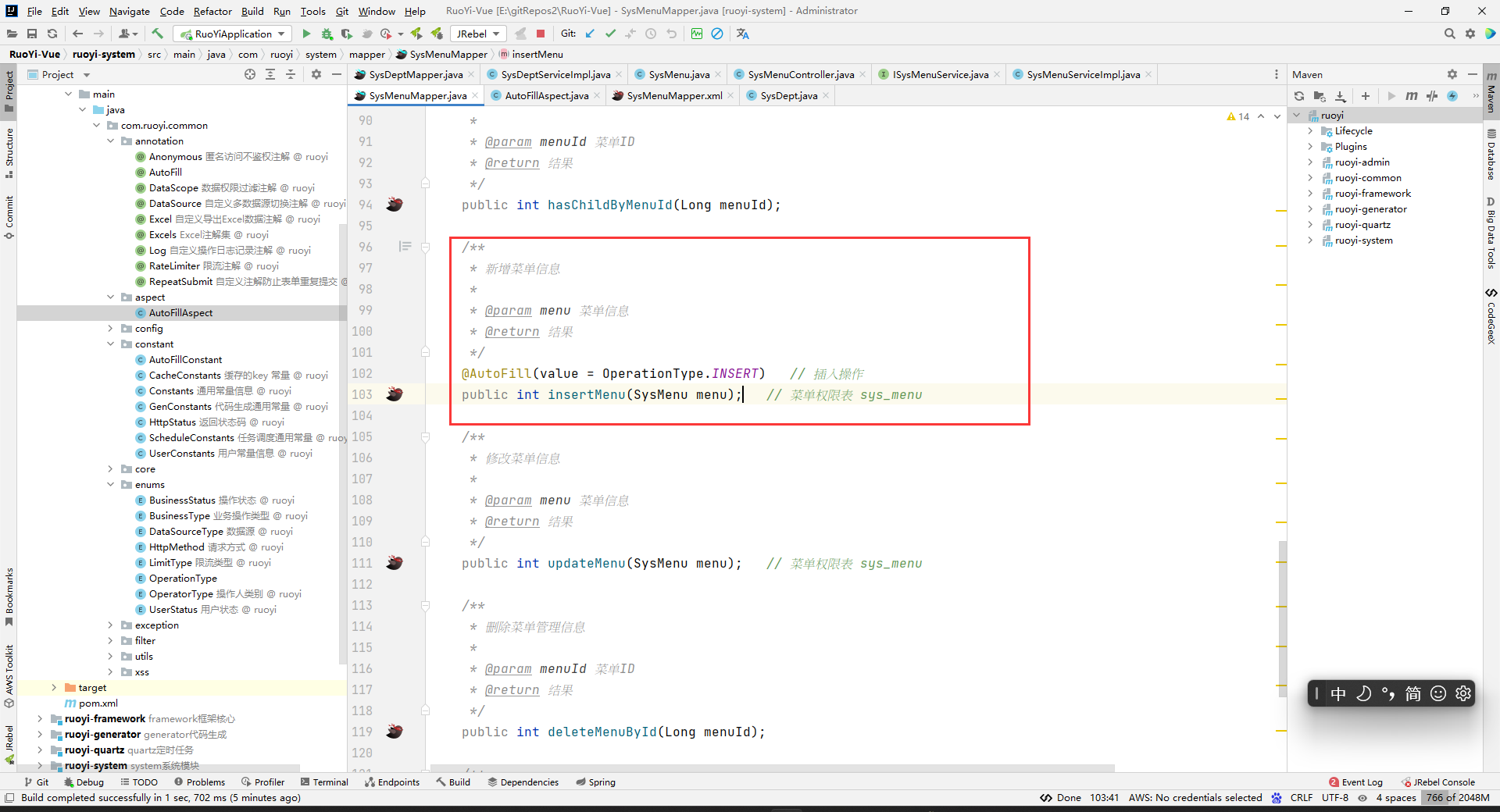
原来代码:
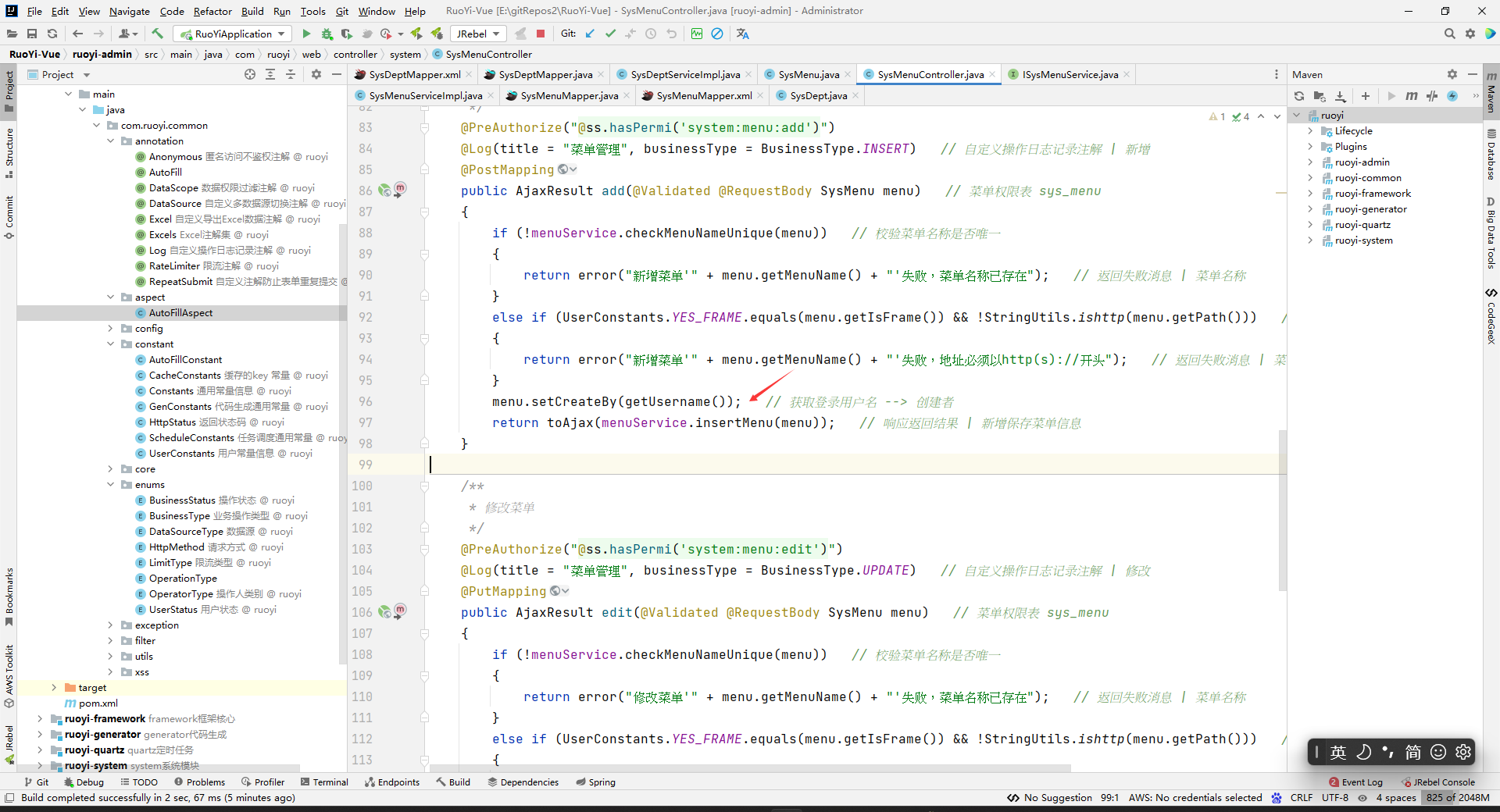
原来效果:
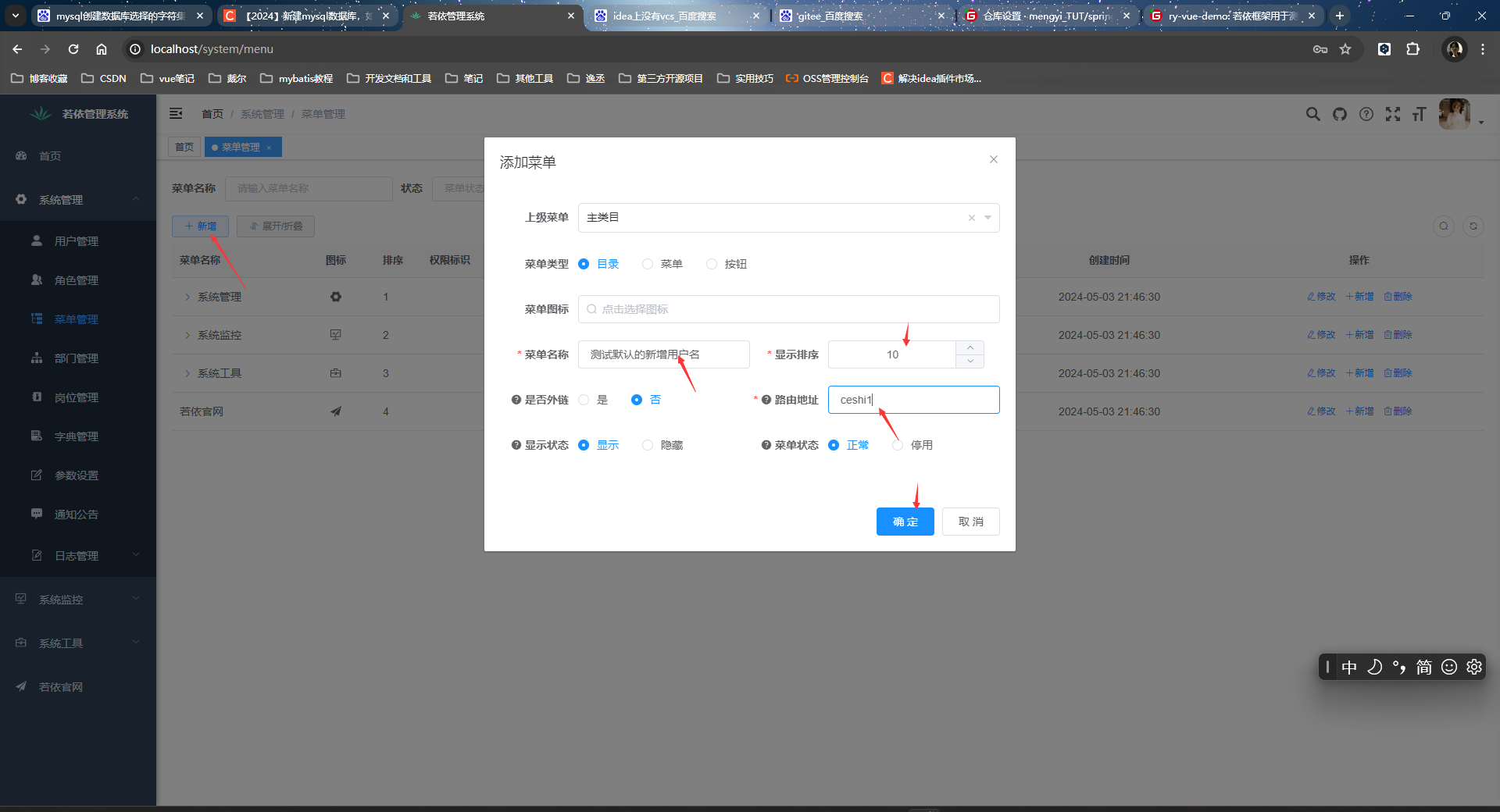
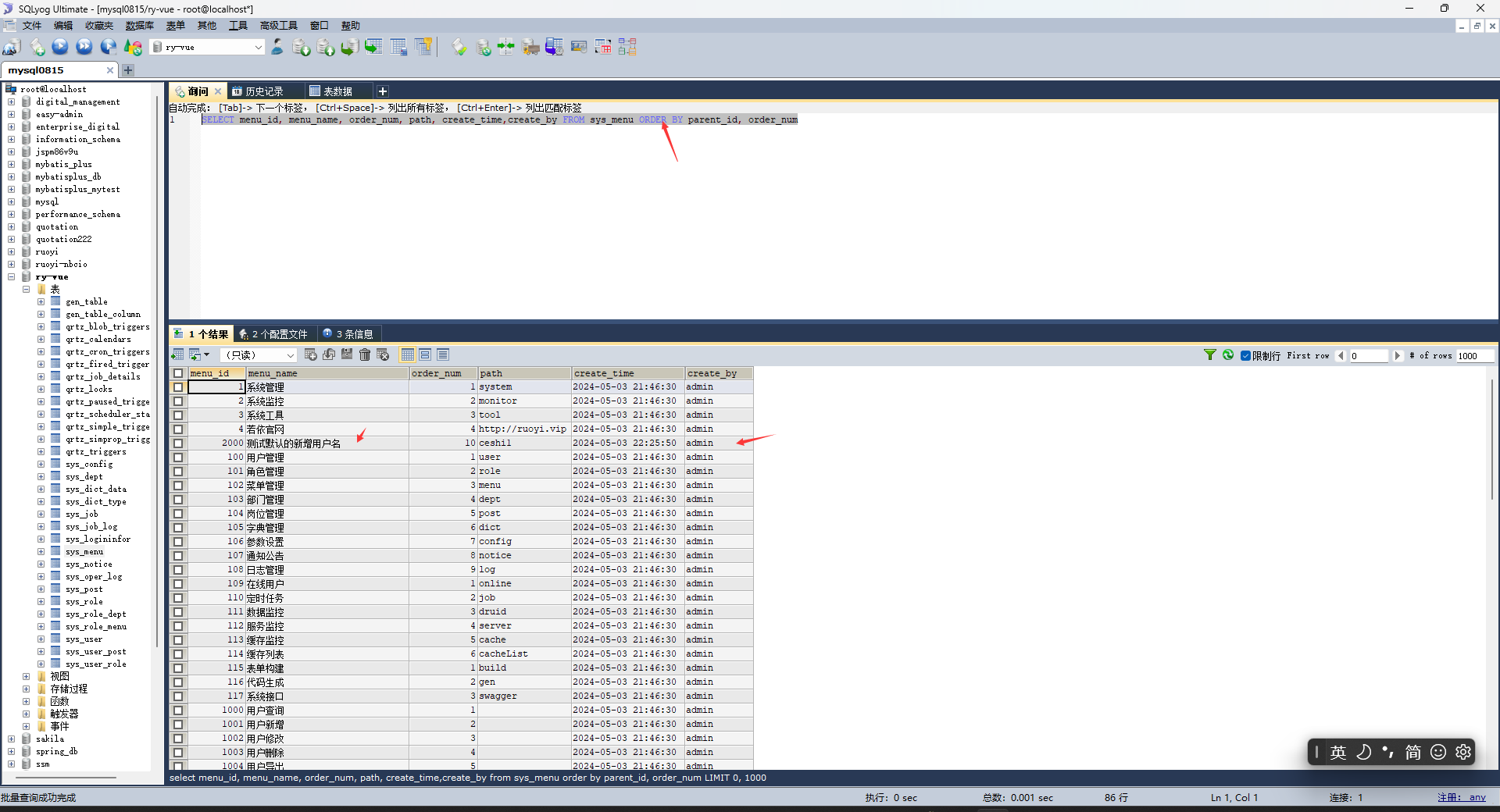
原因是因为控制层给了操作人姓名:
注释后的效果:
使用我们的注解后的效果(这个时候service层的setCreateBy()还是被注释的状态哈):
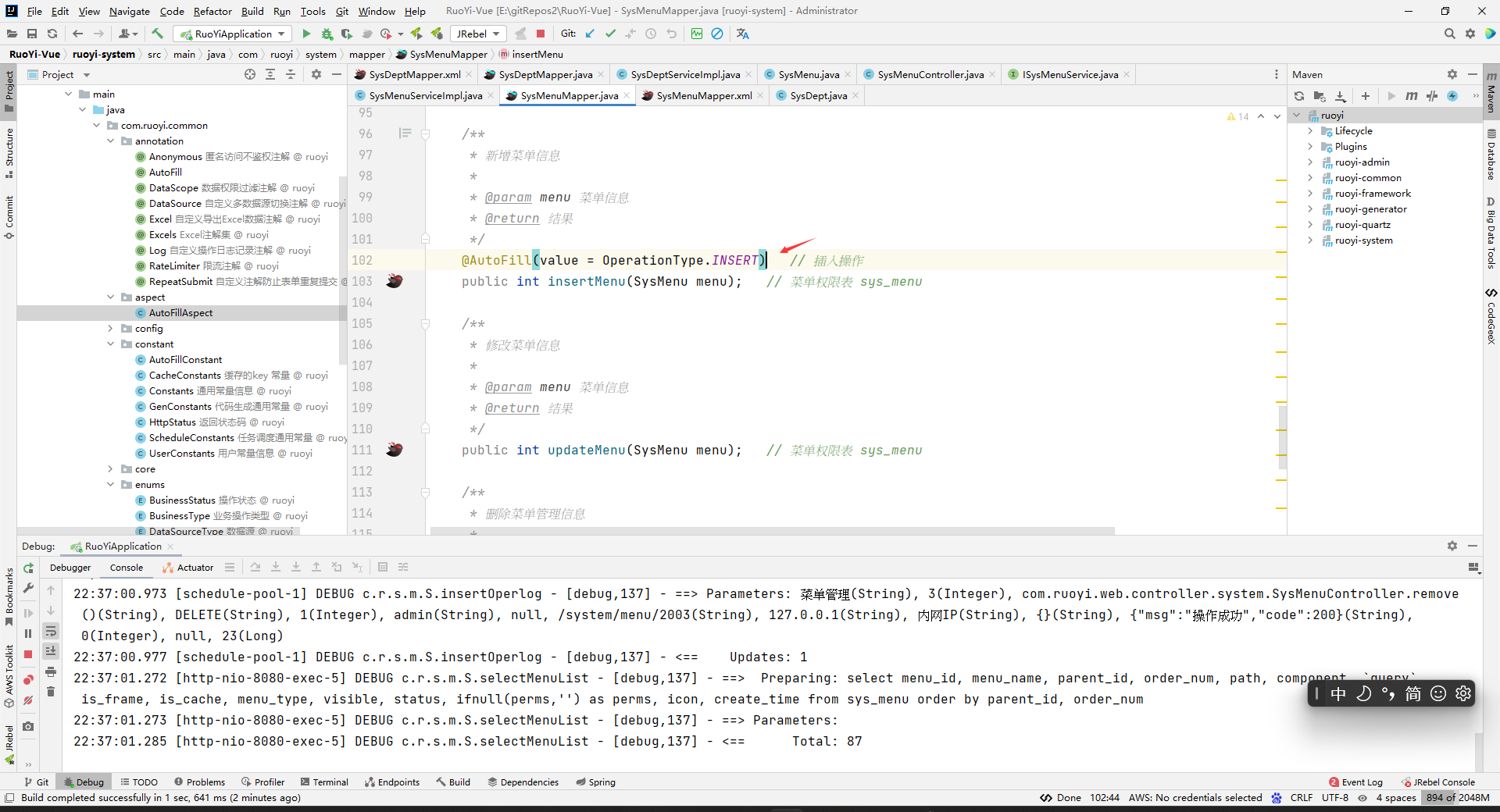
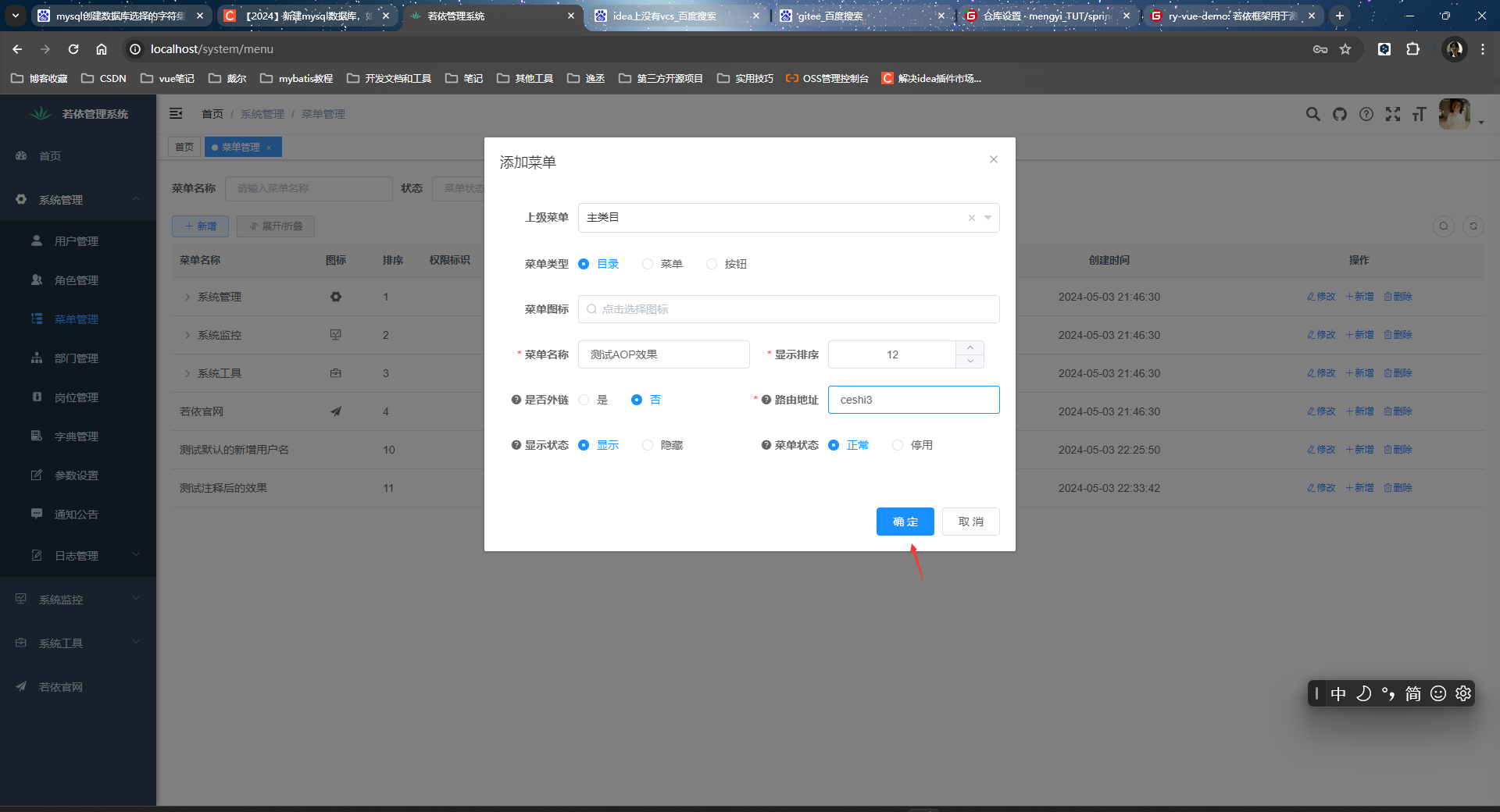
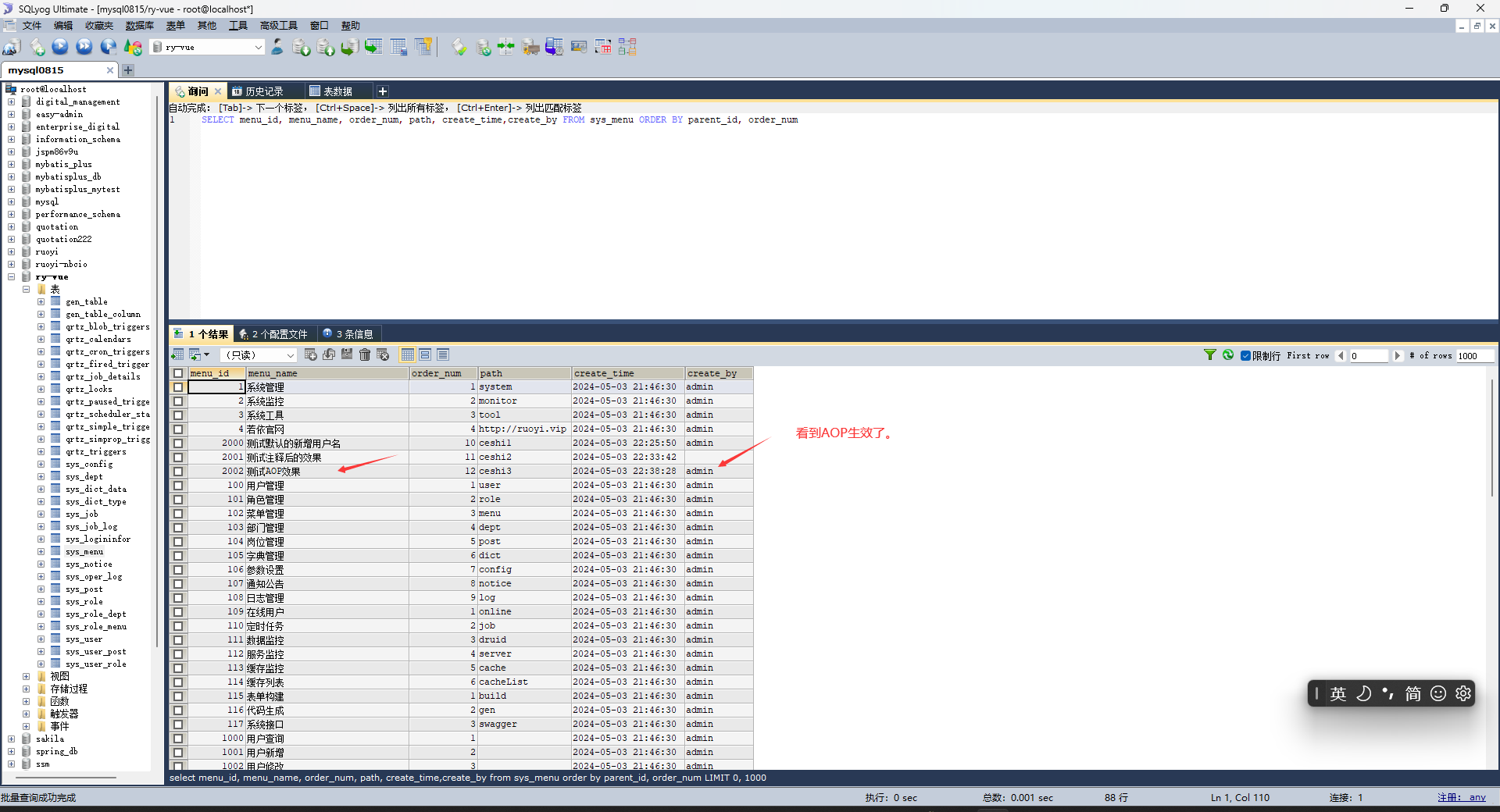
注意:只有加在mapper层,注解才会生效。
展示一下在其他地方使用这个注解:
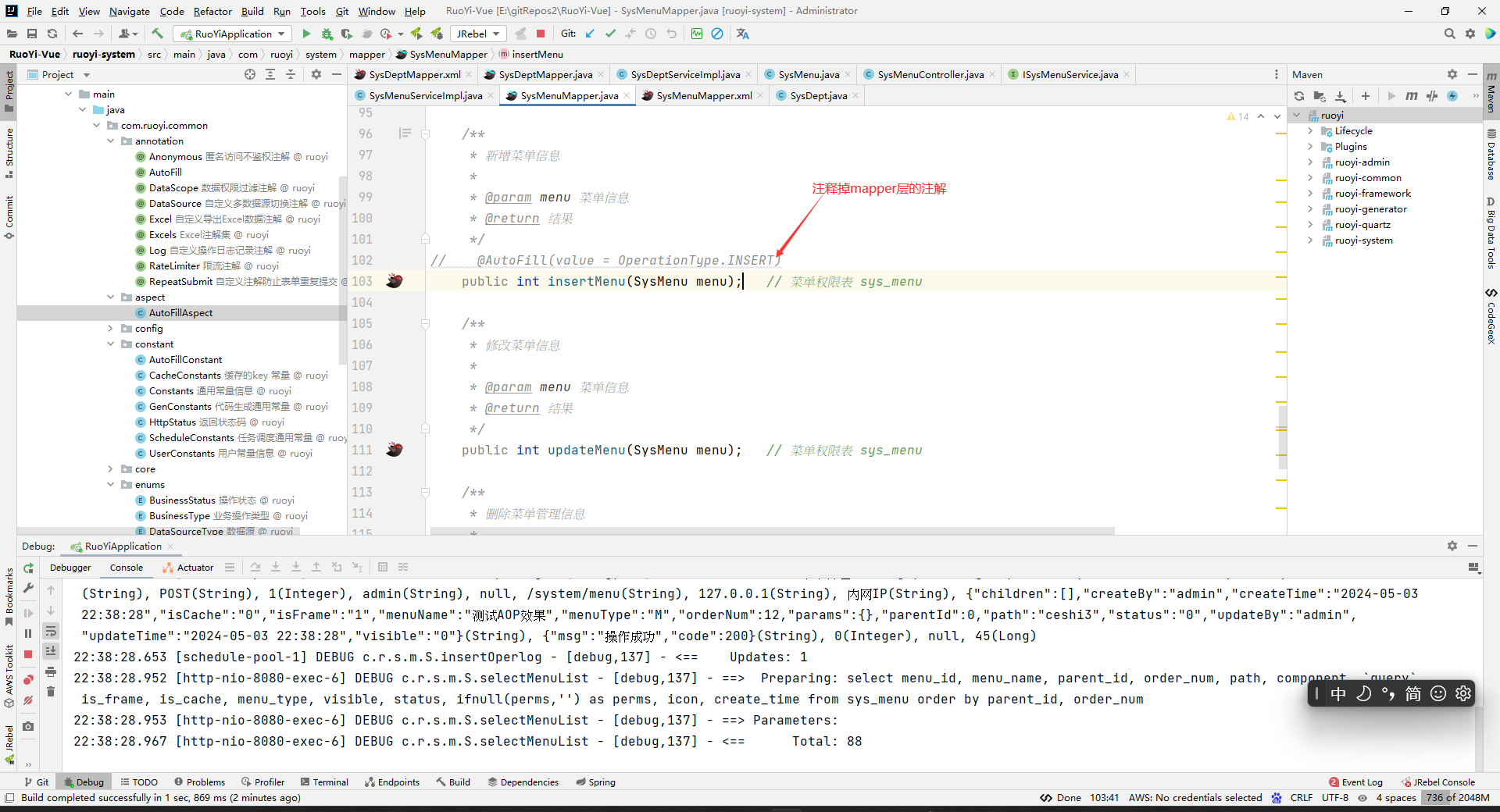
注意:上面为什么我们没有给时间,结果也有创建时间呢?
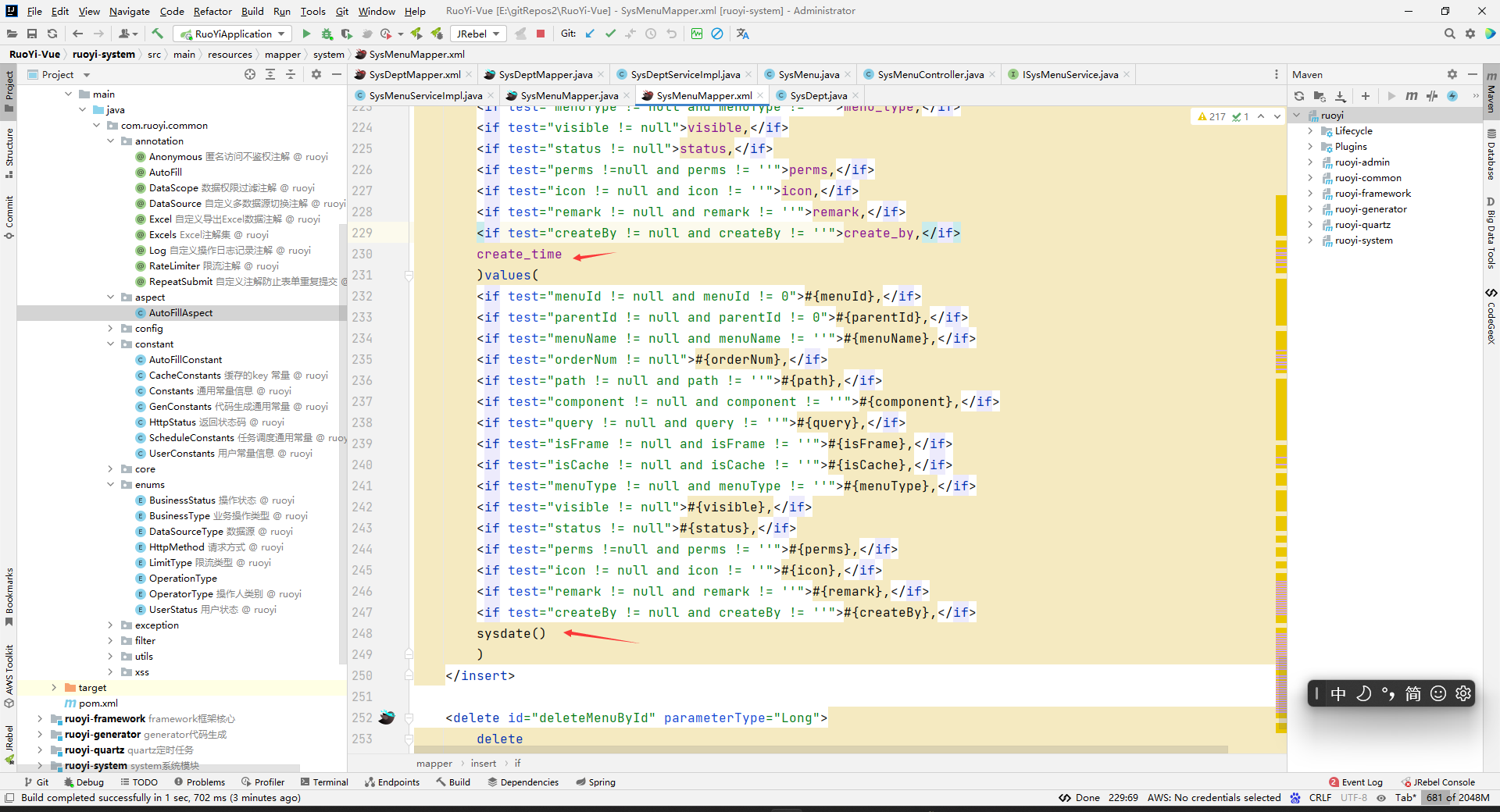
因为这个版本的若依的时间是在sql中写的:
案例二:数据权限增强
前置知识点(AOP的其他写法)
案例二我们要使用AOP实现权限管理。
Spring-aop实现切入有两种方式,一种是路径切入(使用execution(……)),一种是注解切入(使用@annotation(……))。(案例一中的既用了路径切入也用了注解切入,要满足两个条件才能进行切入)。
写法一:
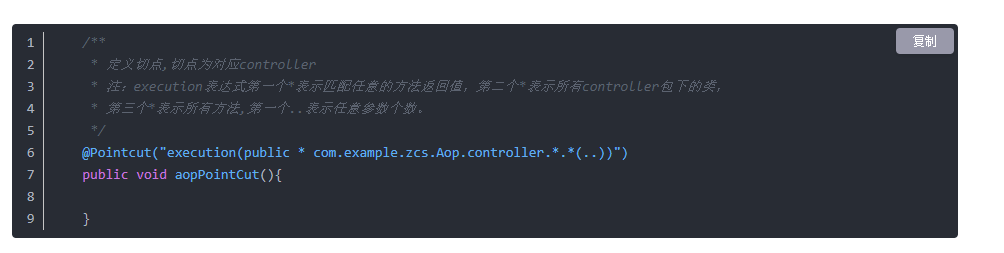
写法二:

案例一中获取注解对象的做法是下面这样的:
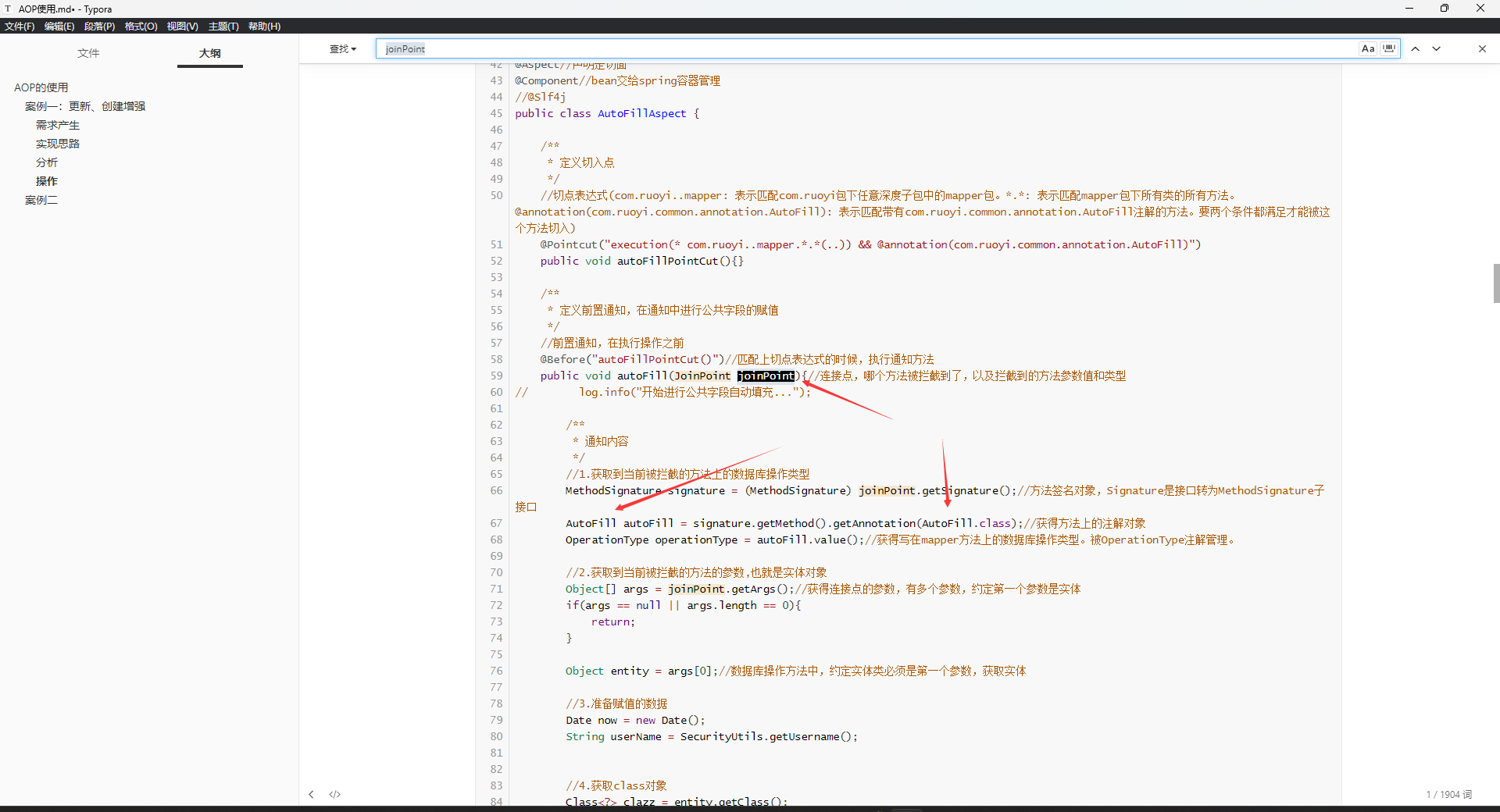
分析:先抽取表达式,即那个切点表达式+注解,表达式写在随便一个方法上,方法的方法体没有意义,所以不写,写了也没有用。然后增强的内容上使用那个抽取的表达式。这样的效果就是在目标方法执行前,先进行增强,这里是前置增强(看@Before注解里面写的方法,代表上面的被抽取的表达式,这个表达式就是用于确定增强方法的。还有一点需要注意:AOP增强内容的这些方法,参数里面都可以直接写JoinPoint的,如果你要用到目标方法的一些东西,那么就直接写这个参数,然后去使用它的方法调用原方法就行了)。上面前置增强的效果是,在执行目标方法之前,会先执行autoFill(JoinPoint joinPoint)方法,autoFill(JoinPoint joinPoint)这个方法里面我们通过joinPoint拿到了方法上面的注解,然后利于注解中的值来进行对应的增强。注意,因为前置增强不需要调用目标方法也会自动去执行原来的目标方法。所以这里不用使用joinPoint调用原方法。
上面这种既展示了普通的切点表达式来进行匹配,也展示了普通的注解的方式来进行匹配方法,用了&&符号来让两个条件都满足才进行增强。因为@Pointcut也是支持SpringEL表达式的写法的,所以值写EL表达式也行,因为内部的解析程序考虑到了EL表达式的写法。
下面要展示的是另一种注解匹配的写法,也一样可以获取到注解中的内容。
相当于传了一个注解过来,然后注解中带着一些数据。
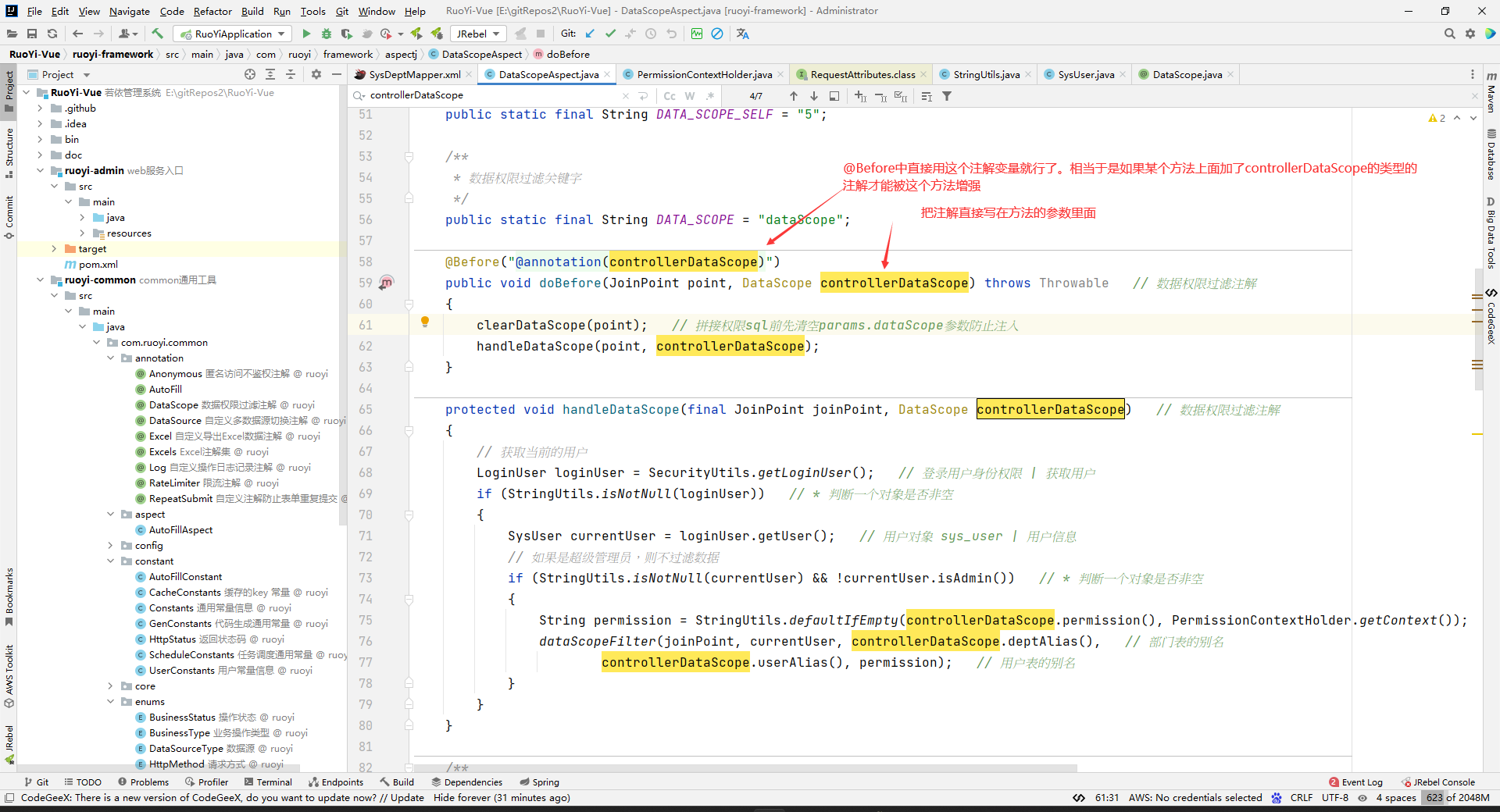
注意:这种写法的话,要求参数名和@annotation注解中的名字要一样才行(如果需要JoinPoint,那么就要把JoinPoint写在方法的第一个参数才行)。比如下面这样:
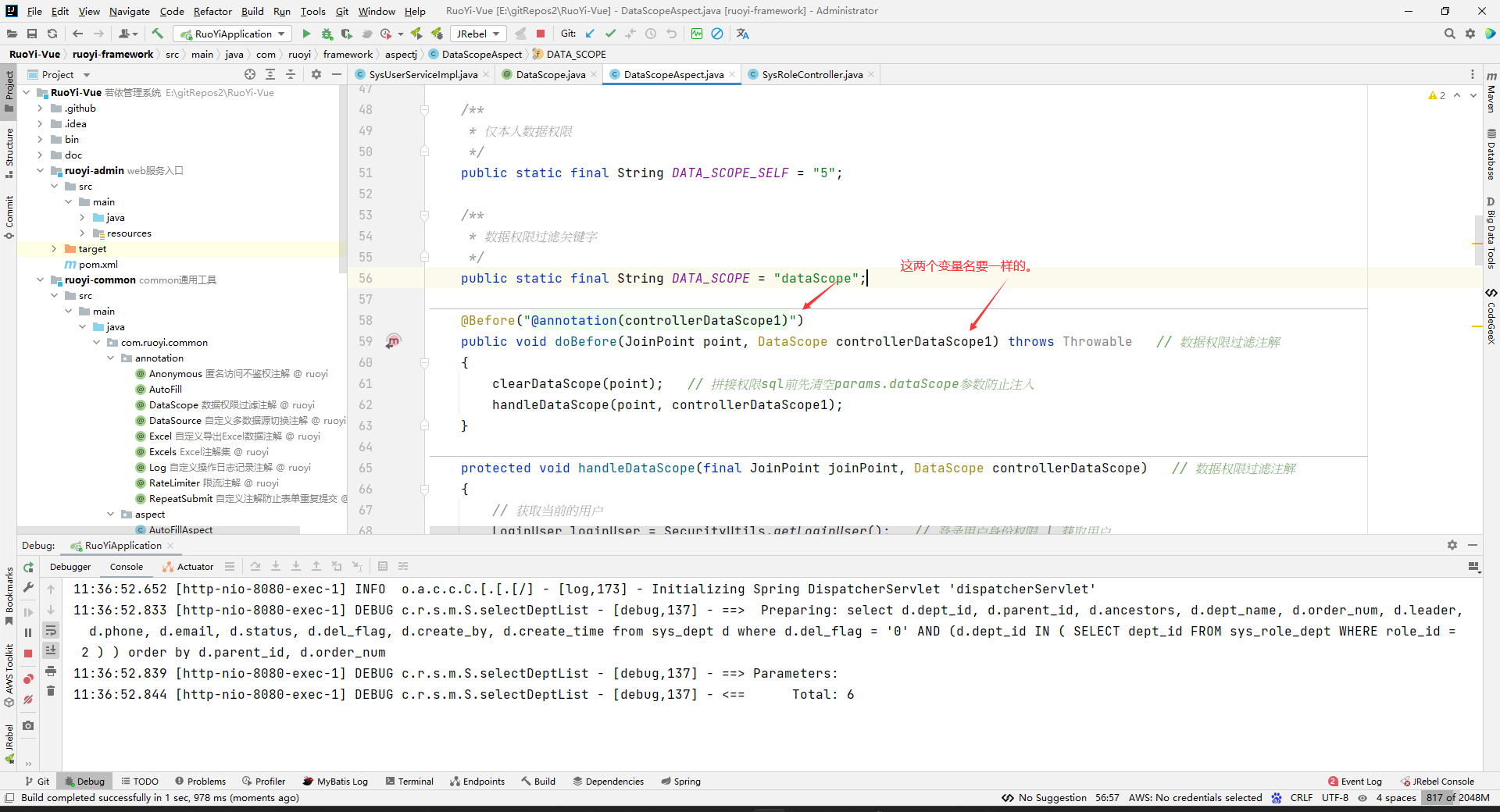
这种写法,就是,不用抽取。直接把注解写在方法参数里面,然后@annotation内写方法参数中的这个注解参数的参数名。这种写法spring能自动知道,要去切这个注解对应的方法。
上面的写法就相当于是下面这样的写法(下面这个写法和上面写法的执行结果是一样的,但是如果要获取注解中的数据,把注解写在方法形参里面的写法使用起来更加顺滑一点。):
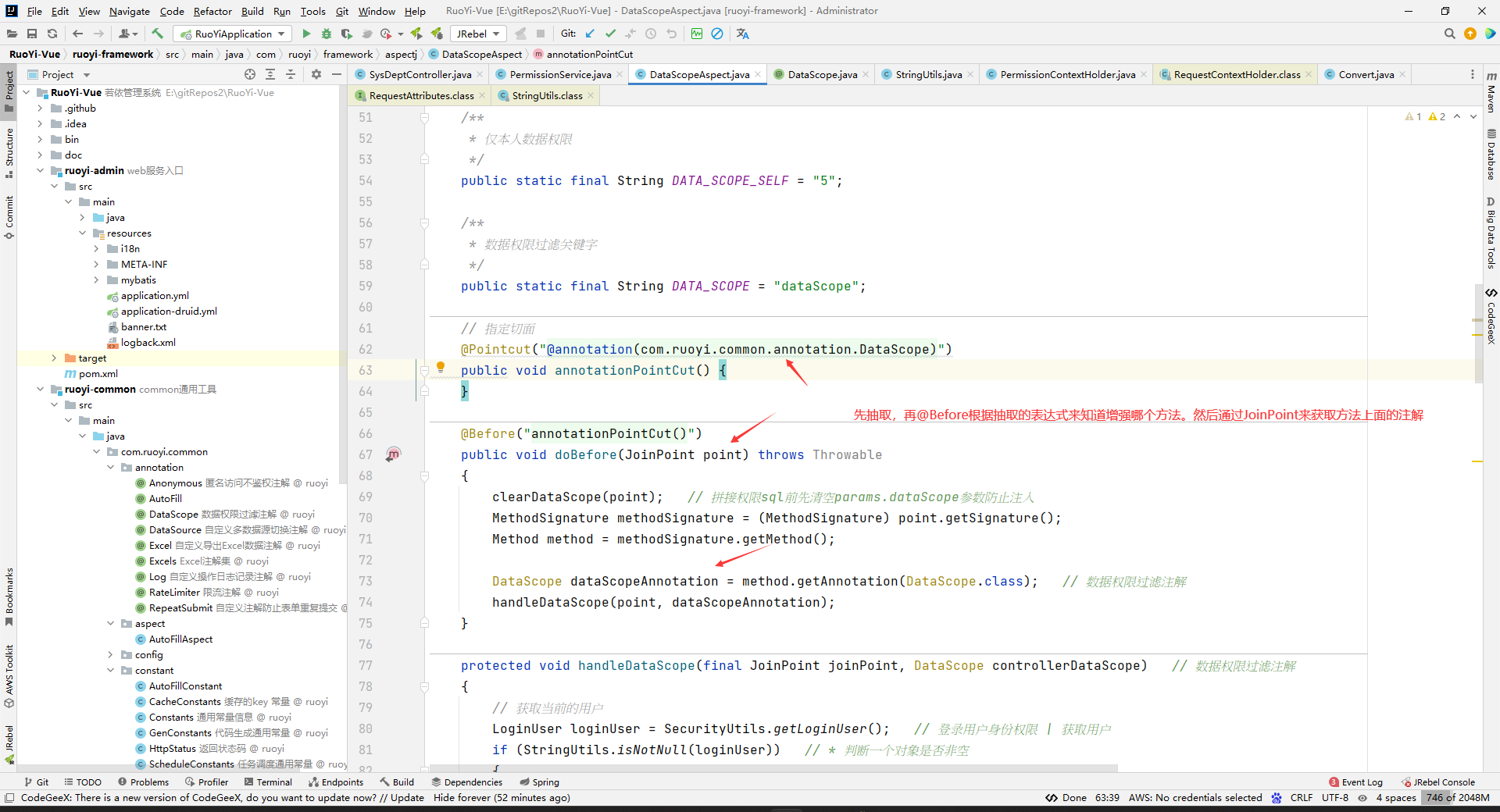
案例引入
若依中是怎么来实现数据权限的?
我们先来看数据权限使用的地方:
controller层:
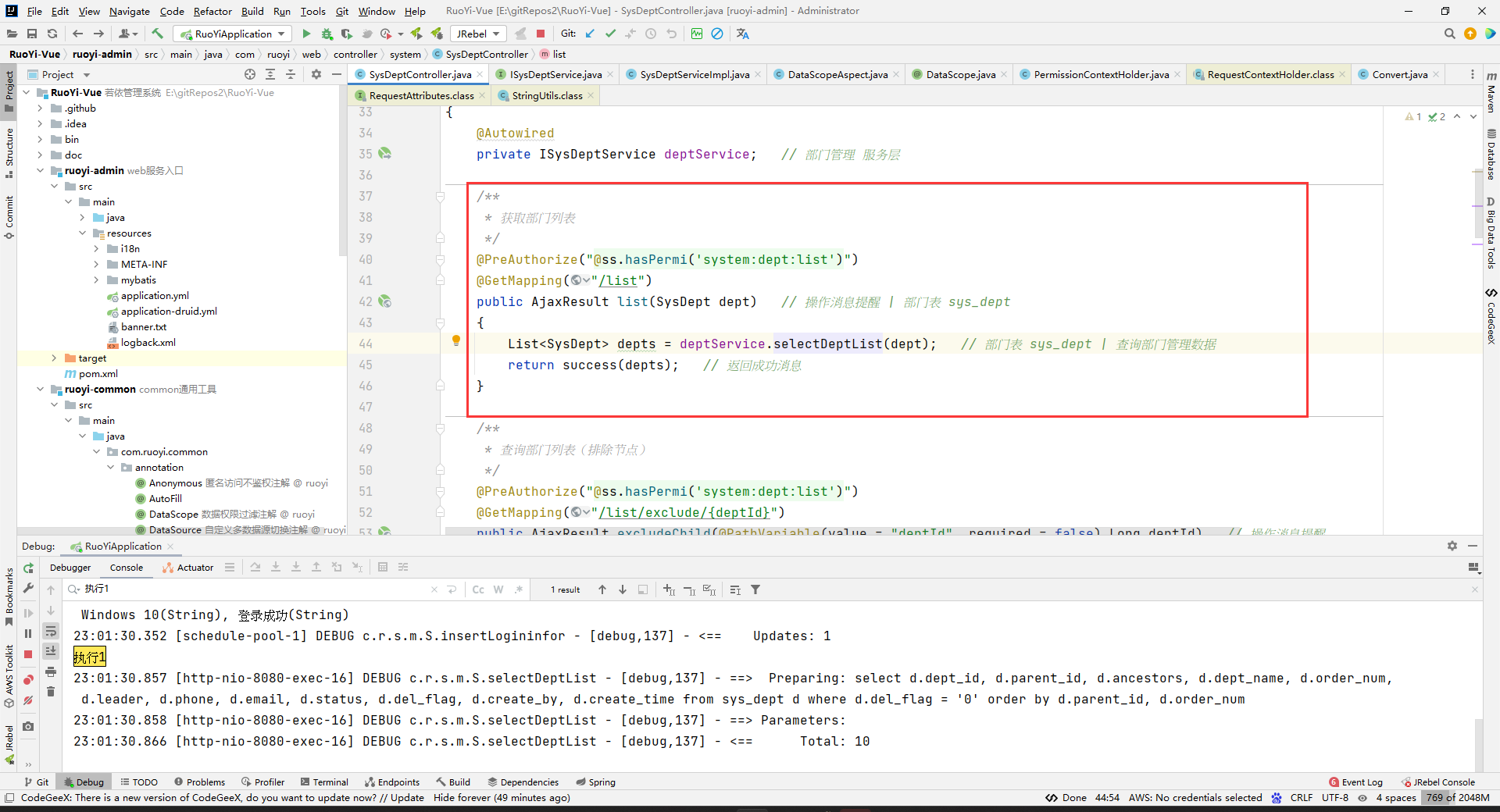
service接口,只有方法声明(没什么特殊的):
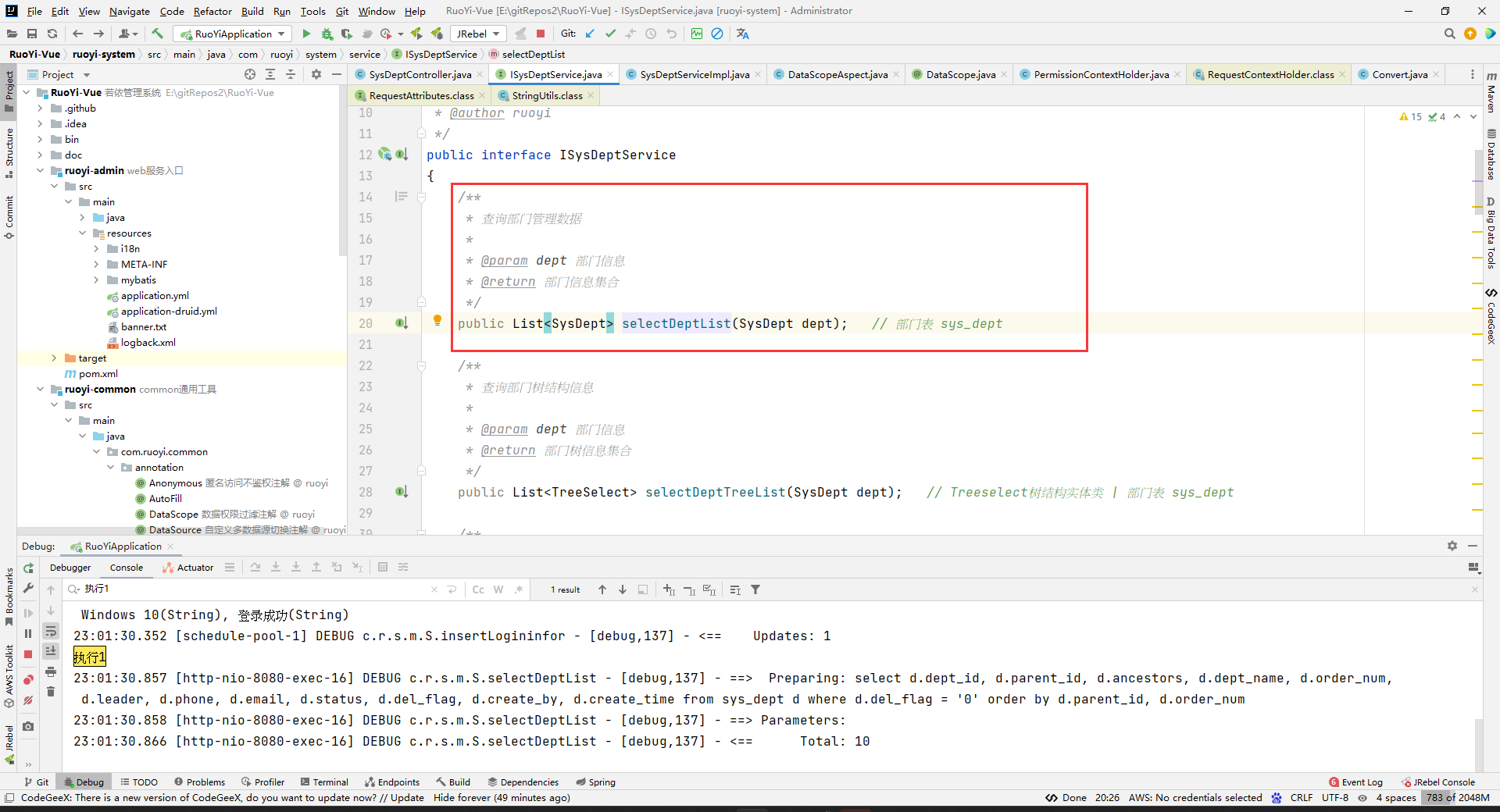
然后就是service层的实现了,实现的方法上面有一个注解。
(总之就是,注解的作用就相当于是把一些值放到了注解里面,然后注解挂在方法上面了而已,然后解析程序去拿这个数据而已,如果没有解析注解的程序,那么这个注解将不会有任何作用,只是挂一个信息到方法上而已。注解和注释的区别就是:注解是给程序看的,程序可以看到并使用这个信息,当然不使用也行。但是注释是给开发者看的,程序是看不到注释的信息的。注解的作用,其实就是挂一个信息到某个方法或者某个类上而已,到时候解析程序可以通过反射去拿到注解,并且获取到注解里面的数据,然后进行对应的解析操作。):
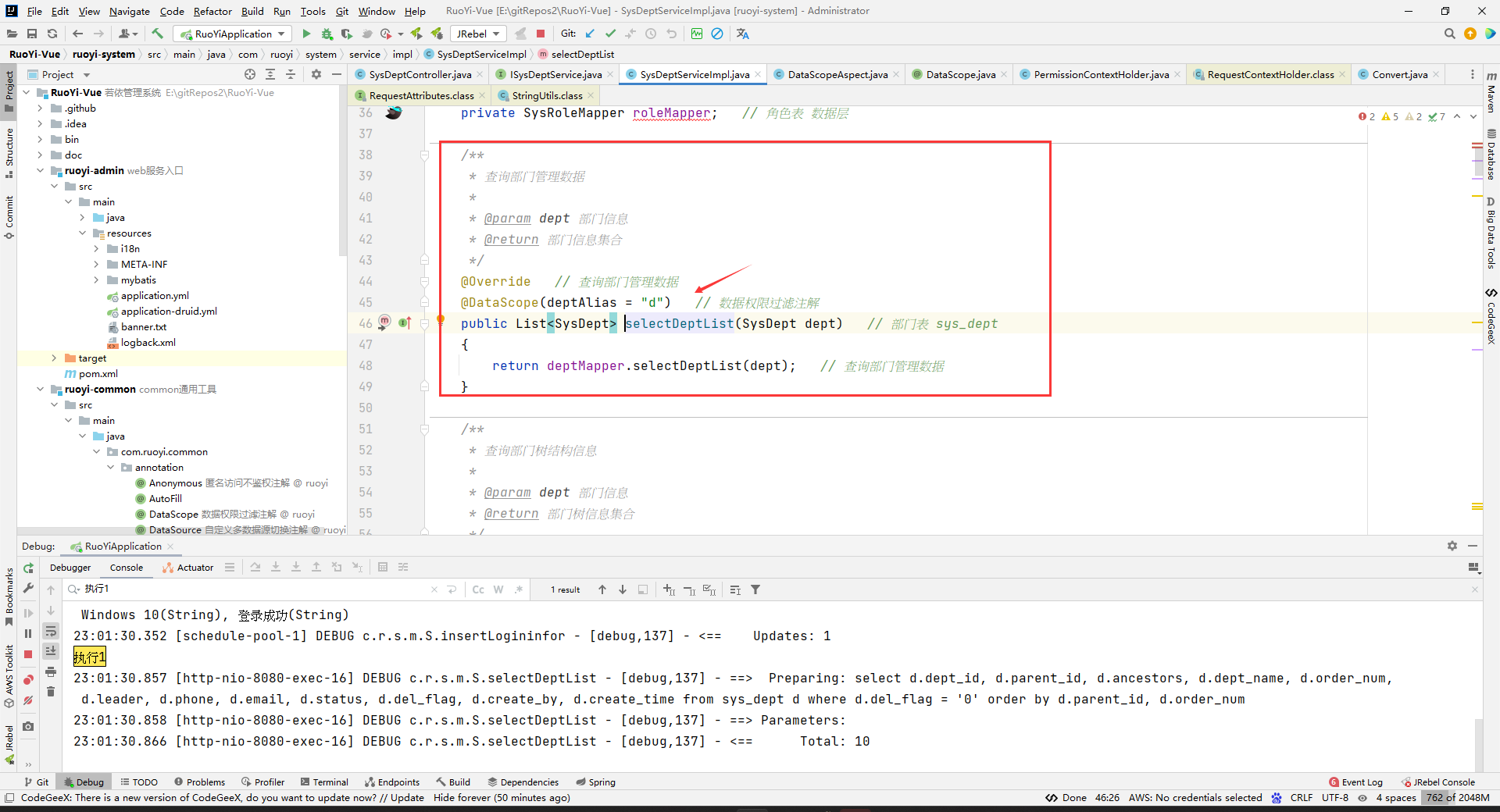
然后就是mapper接口(没有什么特殊的):
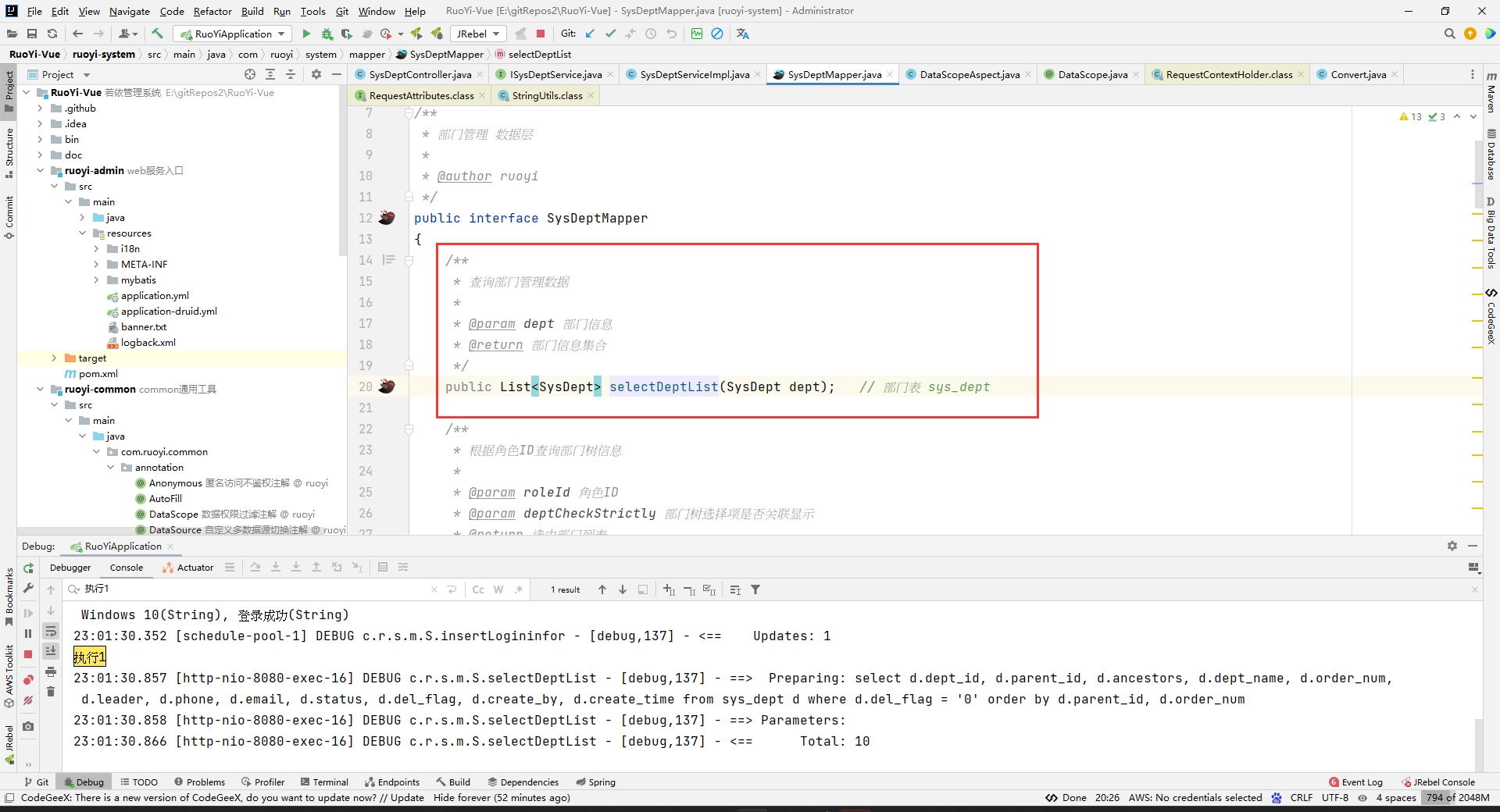
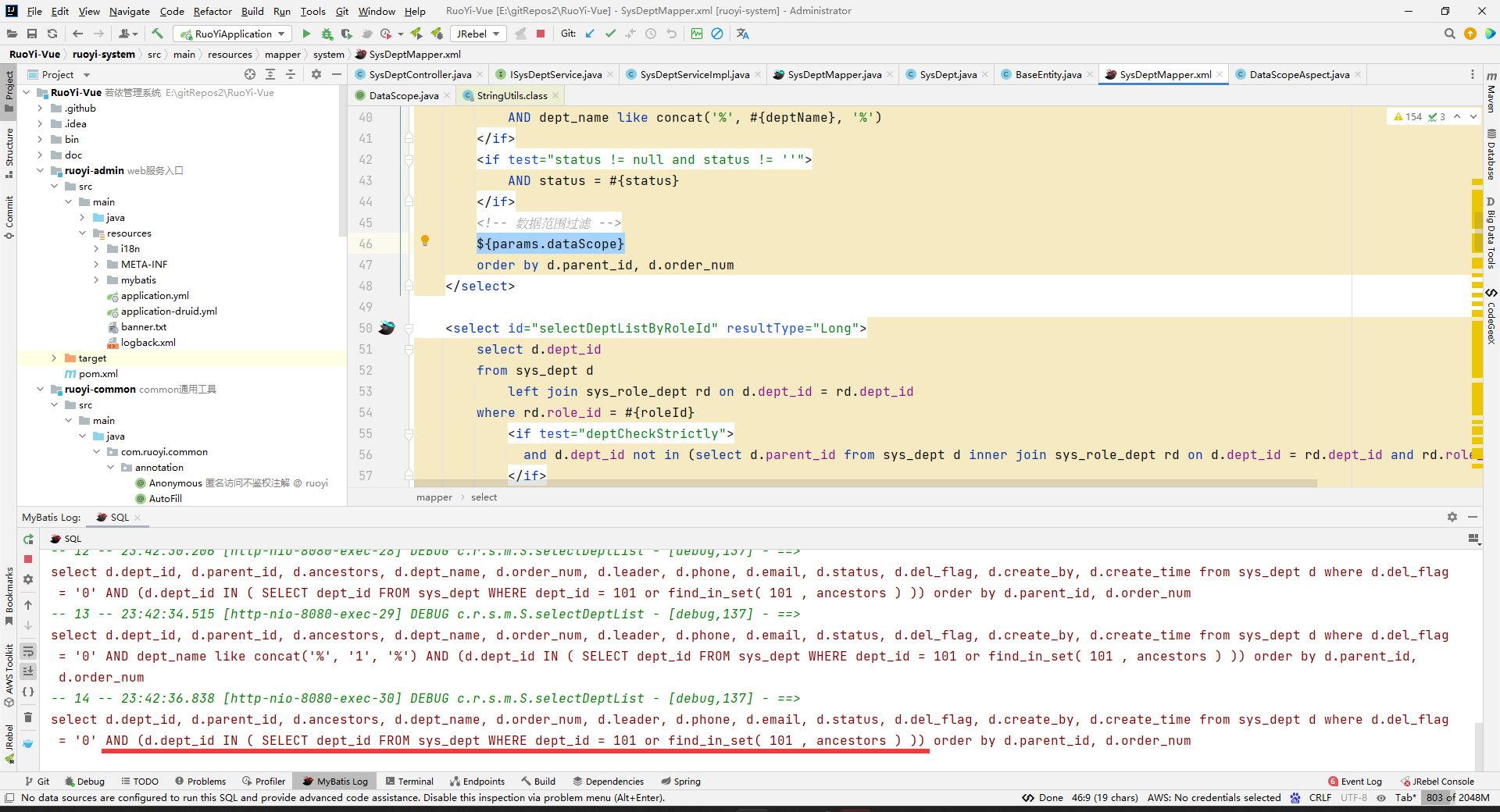
然后发现xml中有一个${params.dataScope}:
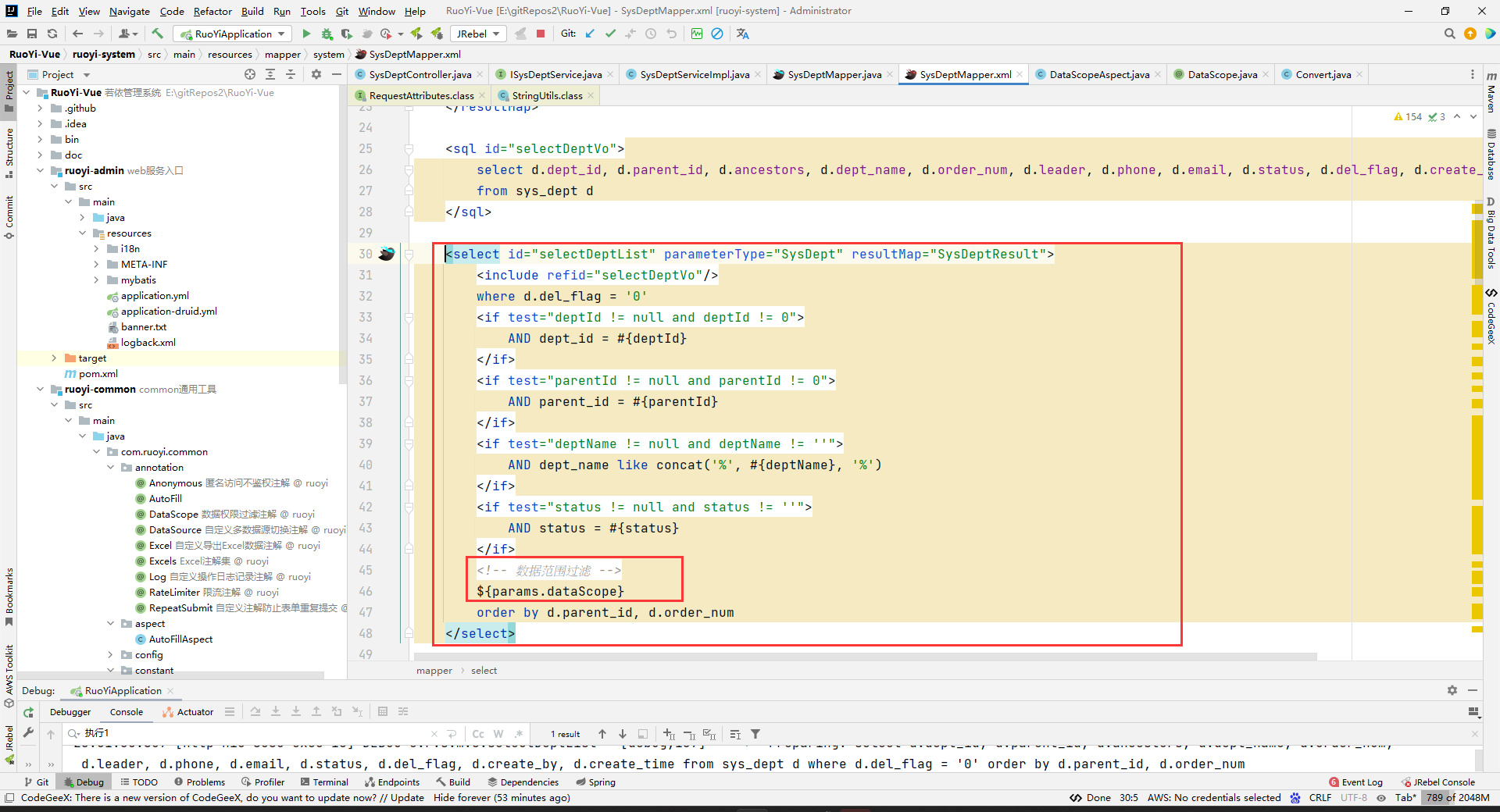
通过我们对xml中写占位符的经验,我们知道KaTeX parse error: Expected 'EOF', got '#' at position 53: …sql注入问题。那么为什么不用#̲{}呢?因为这个虽然不会sql…{},但是注意使用这个的话,我们代码中要注意排除sql注入问题。
因为,mapper层的方法长这样:
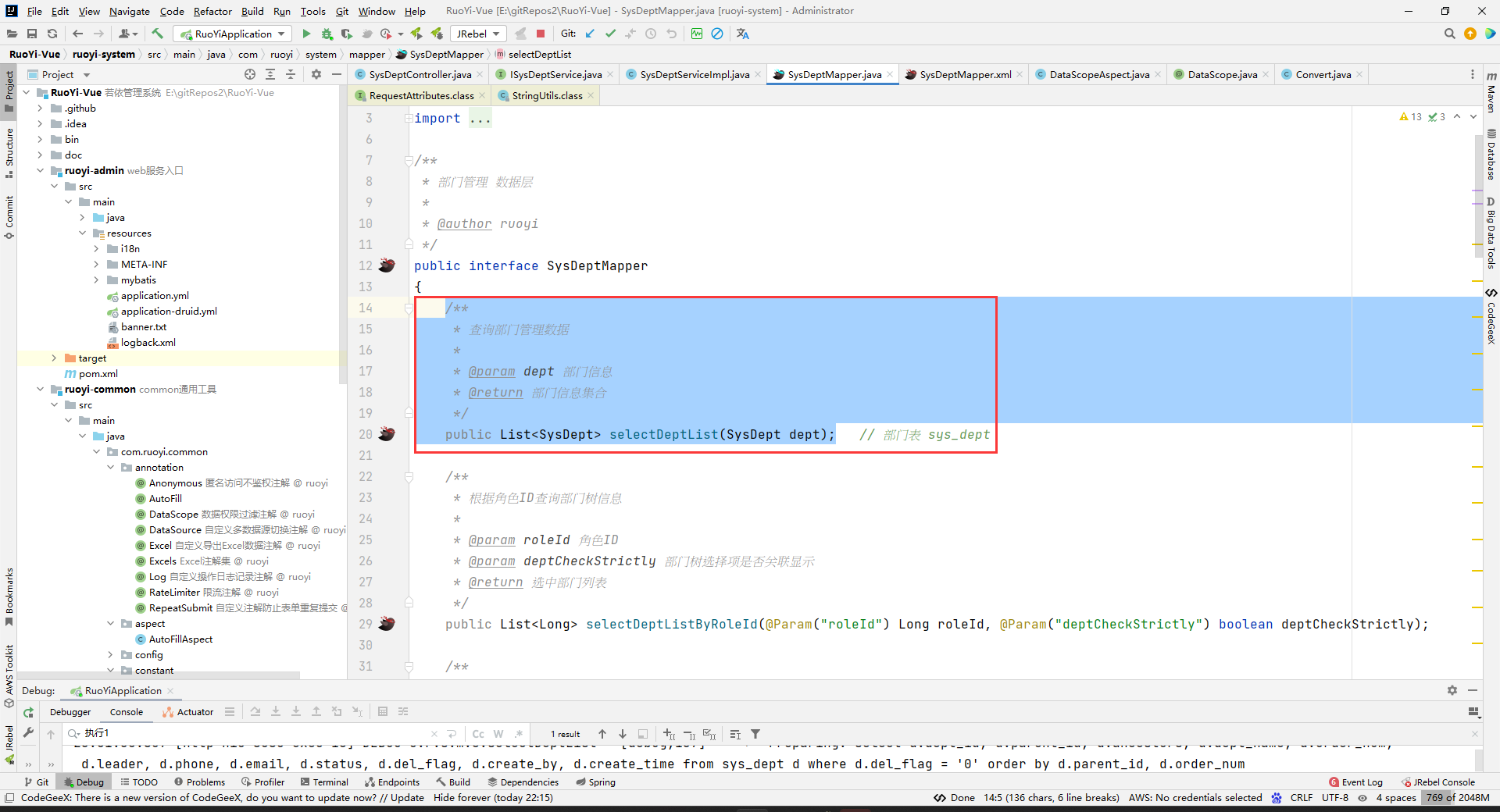
所以,我们可以确定${params.dataScope}表示的是,取dept对象中的params属性的dataScope属性值。
我们找了SysDept找不到params变量
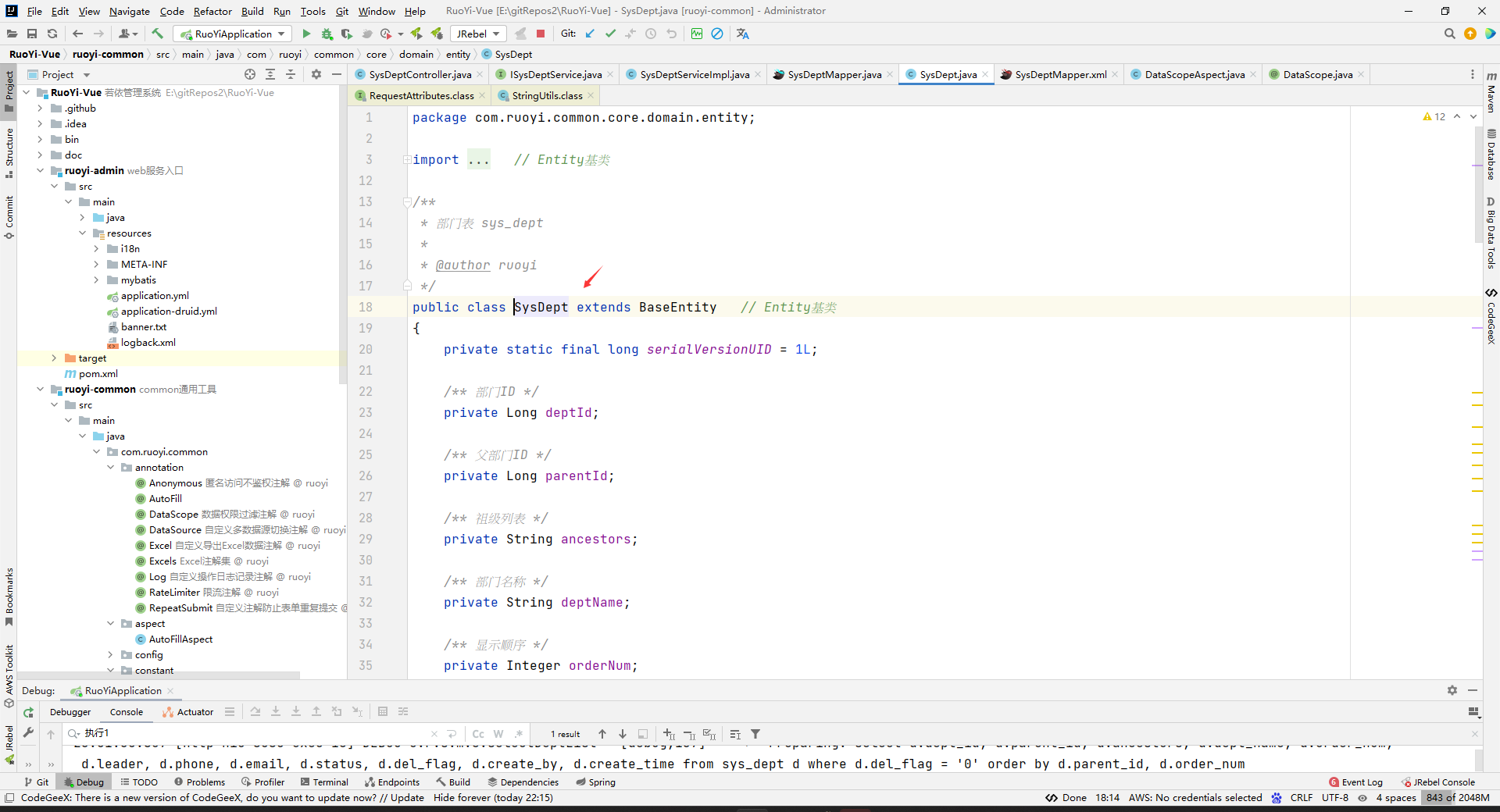
但是,我们在父类中可以看到params变量了:


params.dataScope其实不止是取某个对象的某个属性,他也可以表示取“属性名叫params的map中键为dataScope的值”。
所以是OK的。
然后我们看看一个奇怪的现象:
我们看看请求:
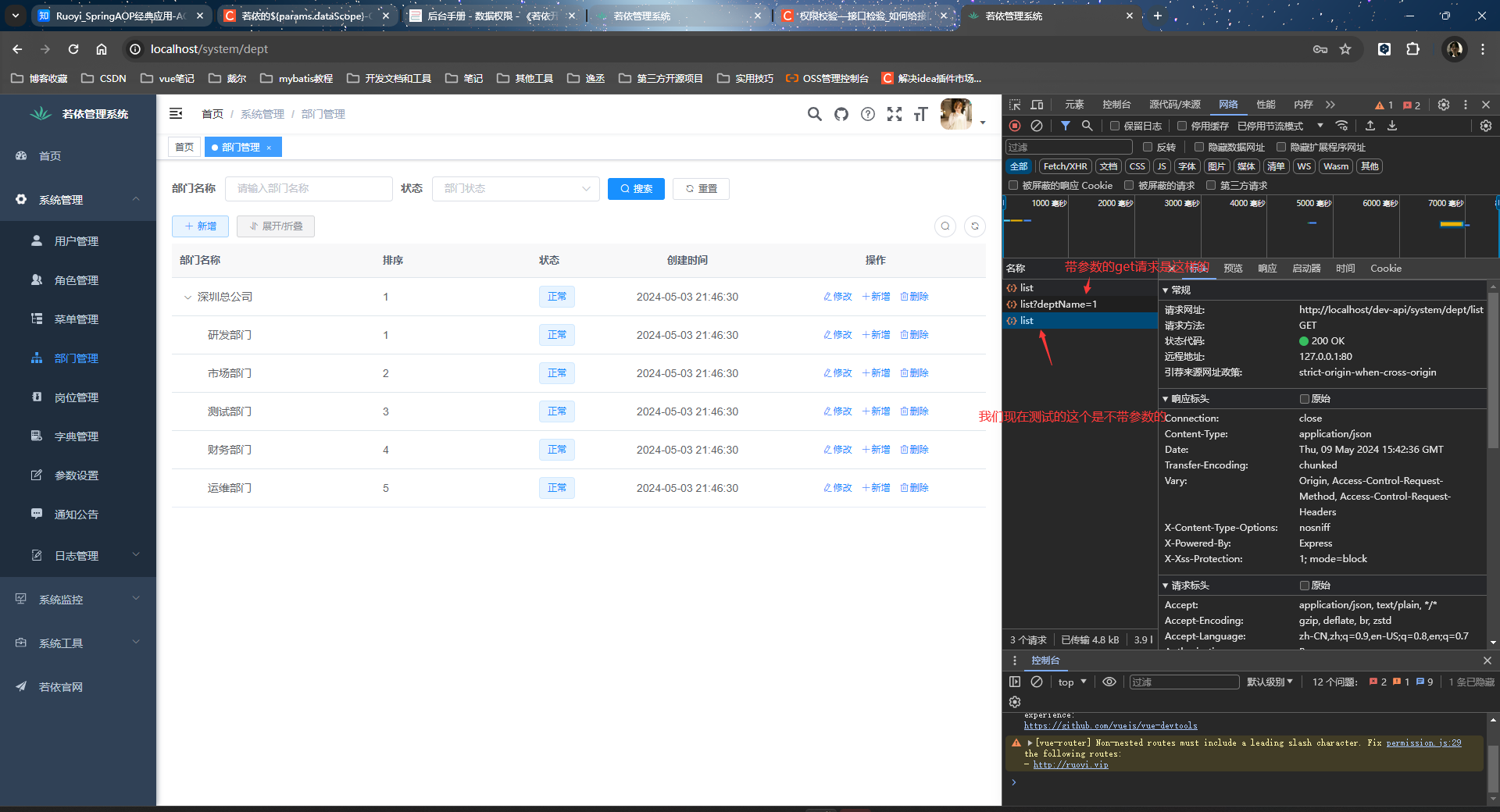
我们看到执行的sql竟然被增强了,即params.dataScope被给了值
但是这个值是怎么来的呢?
答:AOP切入的。
课外知识点:java中 ${} 和 #{} 有什么区别
前言
${}和 #{} 都是 MyBatis 中用来替换参数的,它们都可以将用户传递过来的参数,替换到 MyBatis 最终生成的 SQL 中,但它们区别却是很大的,接下来我们一起来看。1.功能不同
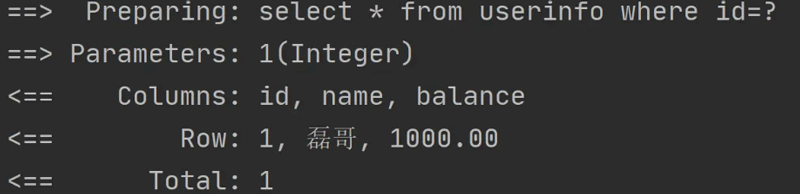
${} 是将参数直接替换到 SQL 中,比如以下代码:
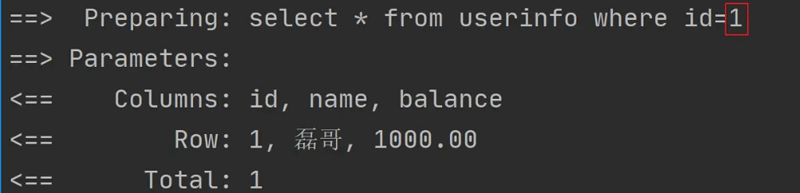
<select id="getUserById" resultType="com.example.demo.model.UserInfo"> select * from userinfo where id=${id} </select>最终生成的执行 SQL 如下:
从上图可以看出,之前的参数 ${id} 被直接替换成具体的参数值 1 了。
而 #{} 则是使用占位符的方式,用预处理的方式来执行业务。比如,我们将上面的案例改造为 #{} 的形式,实现代码如下:
<select id="getUserById" resultType="com.example.demo.model.UserInfo"> select * from userinfo where id=#{id} </select>最终生成的 SQL 如下:
即,有问号的。
区别
比如下面代码:
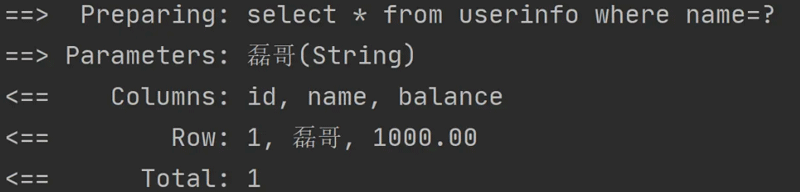
<select id="getUserByName" resultType="com.example.demo.model.UserInfo"> select * from userinfo where name=${name} </select>以上程序执行时,生成的 SQL 语句如下:
这样就会导致程序报错,因为传递的参数是字符类型的,而在 SQL 的语法中,如果是字符类型需要给值添加单引号,否则就会报错,而
${}是直接替换,不会自动添加单引号,所以执行就报错了。前面的例子里面,没有加单引号也能正确,是因为,填充的是数值,数值在sql中不需要加什么引号,直接把值写上去就行了。上面出错的代码使用 #{} 来做就可以成功执行,因为 #{} 采用的是占位符预执行的,所以不存在任何问题,它的实现代码如下:
比如:
<select id="getUserByName" resultType="com.example.demo.model.UserInfo"> select * from userinfo where name=#{name} </select>以上程序最终生成的执行 SQL 如下:
但是在我们需要传一个sql关键字给xml中的sql的时候,占位符就做不到了。
比如,当我们要根据价格从高到低(倒序)、或从低到高(正序)查询,并且排序可以切换时,如下图所示:
这时我们就需要传递排序的关键字了。即,要传sql中的一些sql字符,而不是只传值的时候,我们可以使用
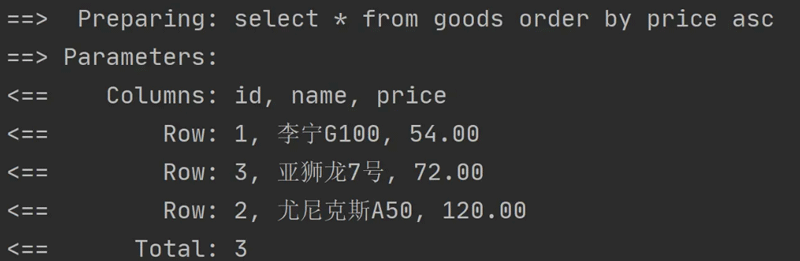
${}来实现:比如:
<select id="getAll" resultType="com.example.demo.model.Goods"> select * from goods order by price ${sort} </select>以上代码生成的执行 SQL 和运行结果如下:
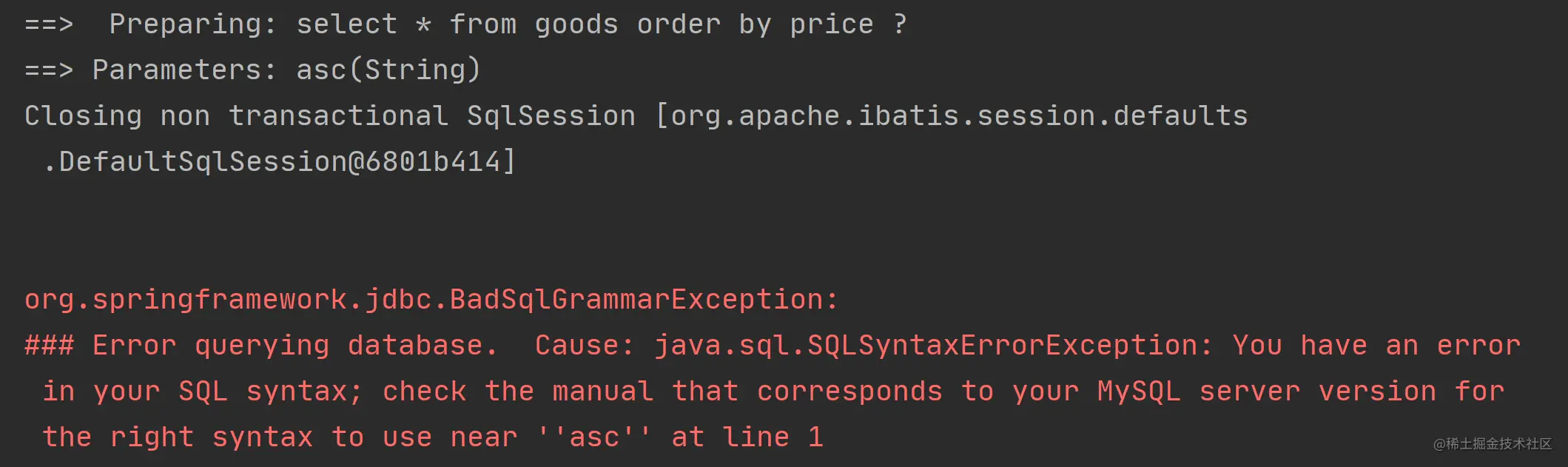
但是,如果将代码中的 ${} 改为 #{},那么程序执行就会报错,#{} 的实现代码如下:
<select id="getAll" resultType="com.example.demo.model.Goods"> select * from goods order by price #{sort} </select>以上代码生成的执行 SQL 和运行结果如下:
总结
**从上述的执行结果我们可以看出:**当传递的是普通参数时,需要使用 #{} 的方式,而当传递的是 SQL 命令或 SQL 关键字时,需要使用
${}来对 SQL 中的参数进行直接替换并执行。除此之外,
${}和 #{} 最主要的区别体现在安全方面,当使用${}会出现安全问题,也就是 SQL 注入的问题,而使用 #{} 因为是预处理的,所以不会存在安全问题。这个例子就不举了,之前学习的时候学过。


若依AOP如何做到数据权限
内容1
下面我们来探究一下若依AOP如何做到数据权限的。
点击查询
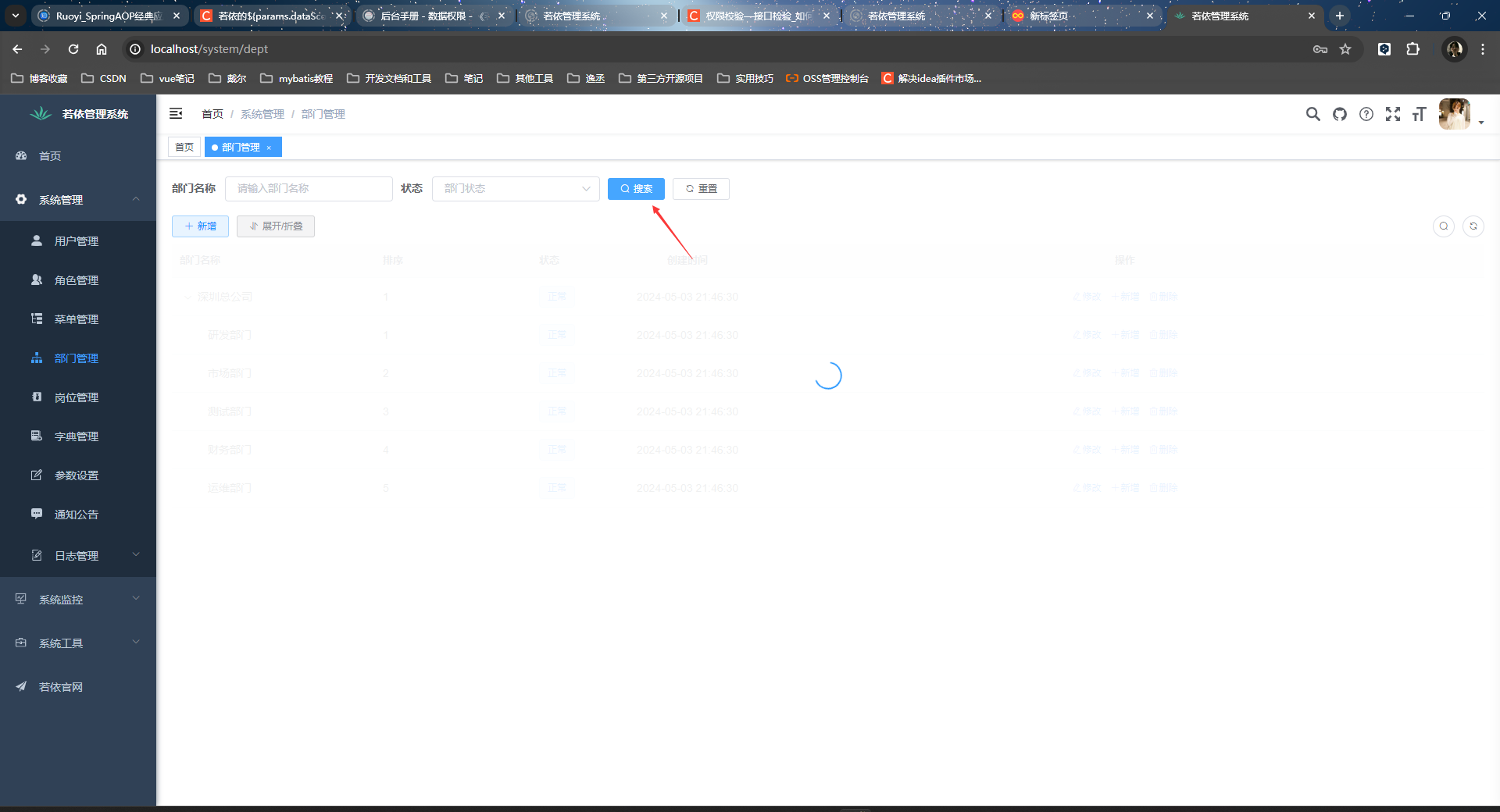
控制层方法看到param中还没有数据:
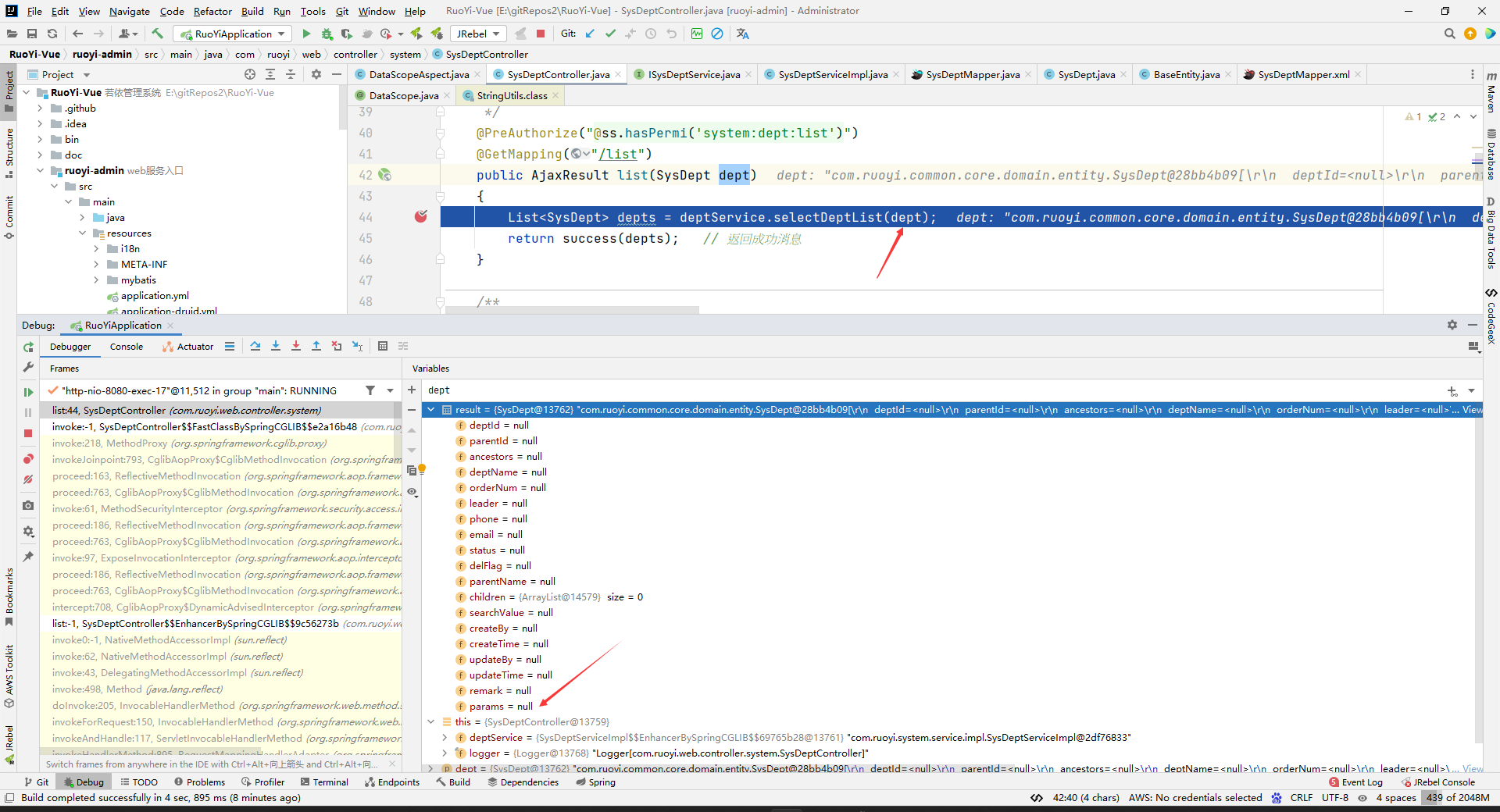
在service层中就看到了数据:
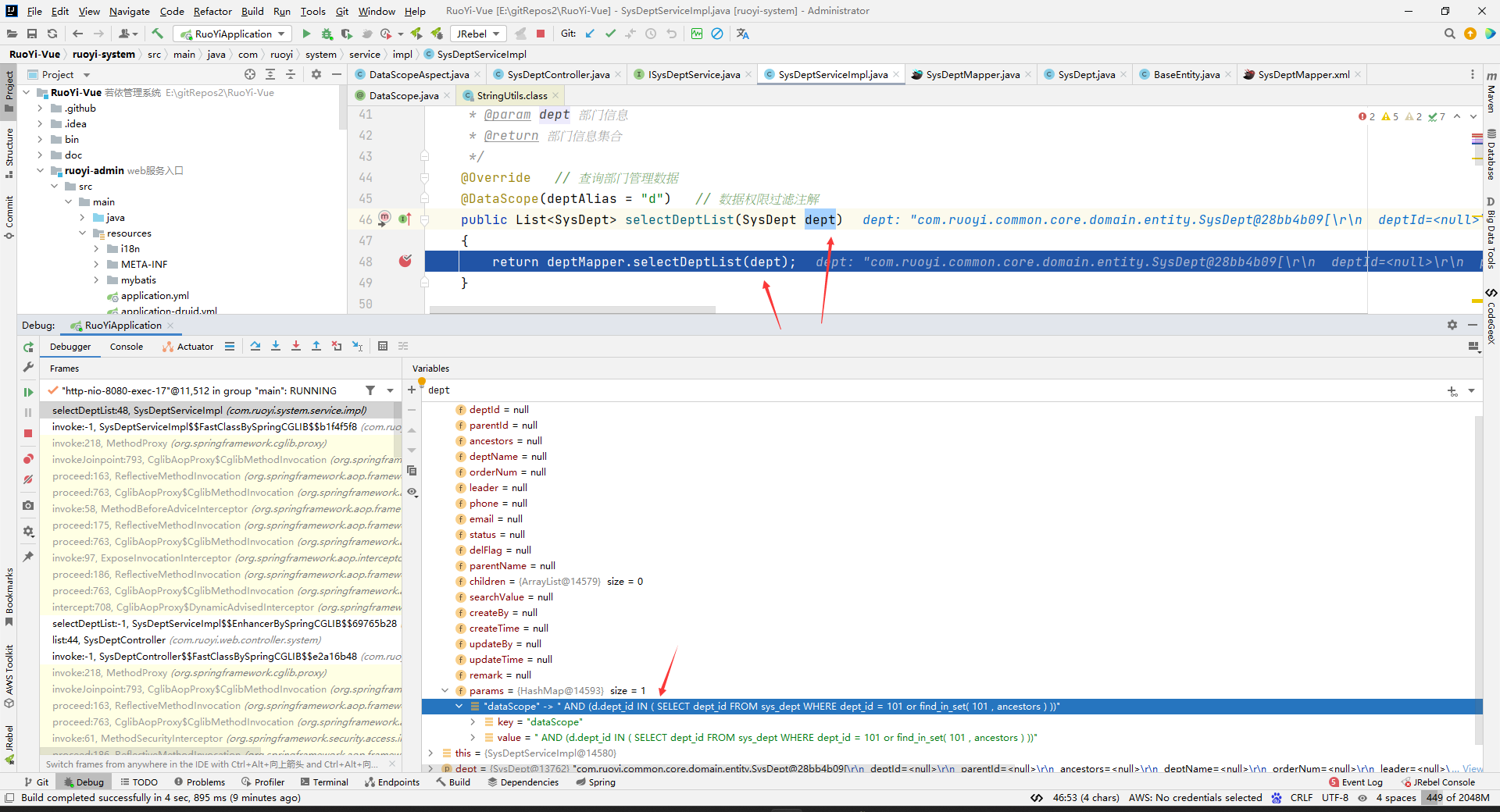
说明在这个service层原来的方法体中的语句执行前就执行了增强语句。
所以我们找能切到这个方法的切面类:
package com.ruoyi.framework.aspectj;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import com.ruoyi.common.annotation.DataScope;
import com.ruoyi.common.core.domain.BaseEntity;
import com.ruoyi.common.core.domain.entity.SysRole;
import com.ruoyi.common.core.domain.entity.SysUser;
import com.ruoyi.common.core.domain.model.LoginUser;
import com.ruoyi.common.core.text.Convert;
import com.ruoyi.common.utils.SecurityUtils;
import com.ruoyi.common.utils.StringUtils;
import com.ruoyi.framework.security.context.PermissionContextHolder;
/**
* 数据过滤处理
*
* @author ruoyi
*/
@Aspect
@Component
public class DataScopeAspect
{
/**
* 全部数据权限
*/
public static final String DATA_SCOPE_ALL = "1";
/**
* 自定数据权限
*/
public static final String DATA_SCOPE_CUSTOM = "2";
/**
* 部门数据权限
*/
public static final String DATA_SCOPE_DEPT = "3";
/**
* 部门及以下数据权限
*/
public static final String DATA_SCOPE_DEPT_AND_CHILD = "4";
/**
* 仅本人数据权限
*/
public static final String DATA_SCOPE_SELF = "5";
/**
* 数据权限过滤关键字
*/
public static final String DATA_SCOPE = "dataScope";
// 指定切面(抽取表达式)
@Pointcut("@annotation(com.ruoyi.common.annotation.DataScope)")
public void annotationPointCut() {
}
@Before("annotationPointCut()")
public void doBefore(JoinPoint point) throws Throwable
{
System.out.println("执行1");
clearDataScope(point);
MethodSignature methodSignature = (MethodSignature) point.getSignature();
Method method = methodSignature.getMethod();
DataScope dataScopeAnnotation = method.getAnnotation(DataScope.class);
handleDataScope(point, dataScopeAnnotation);
}
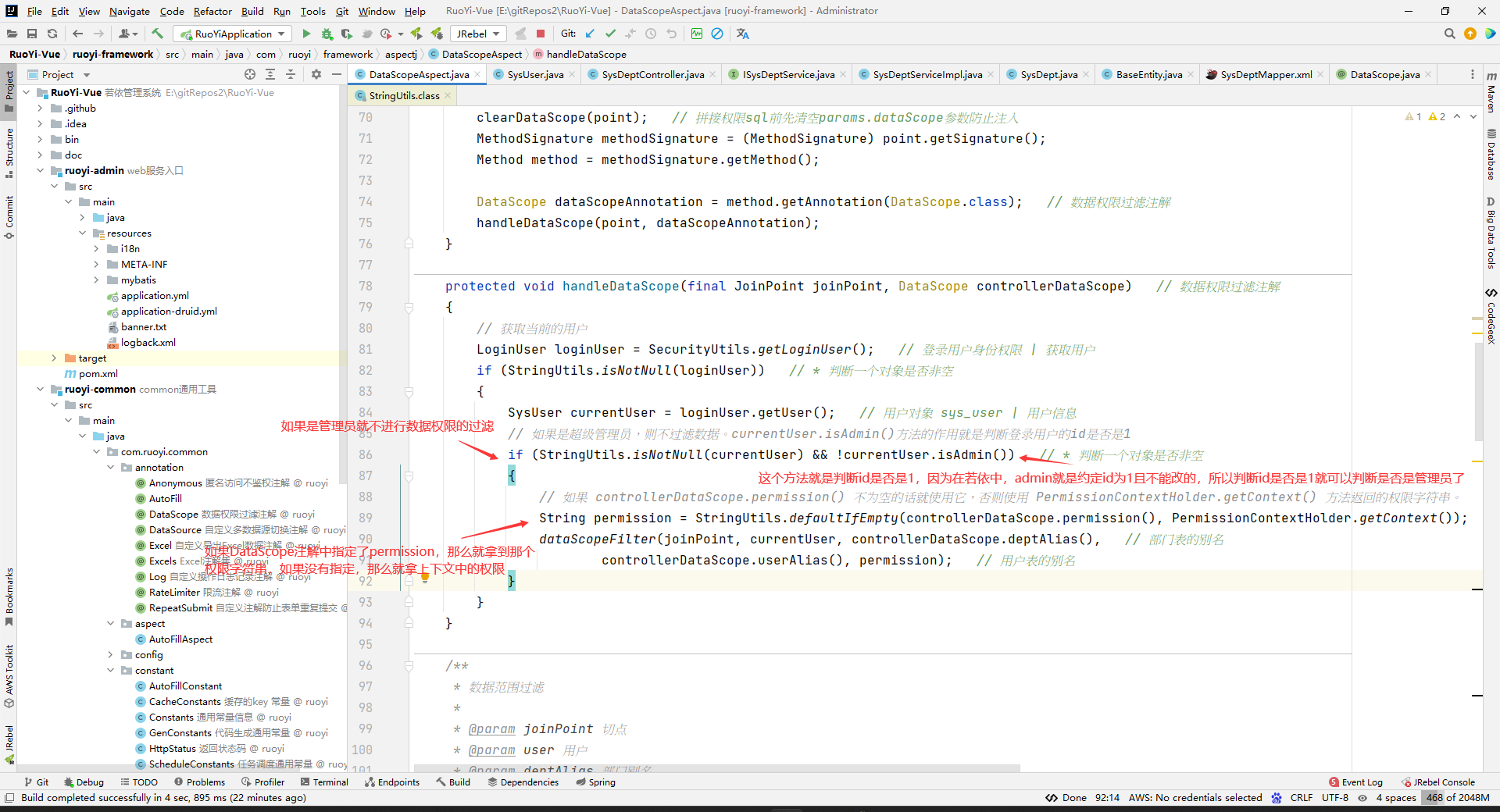
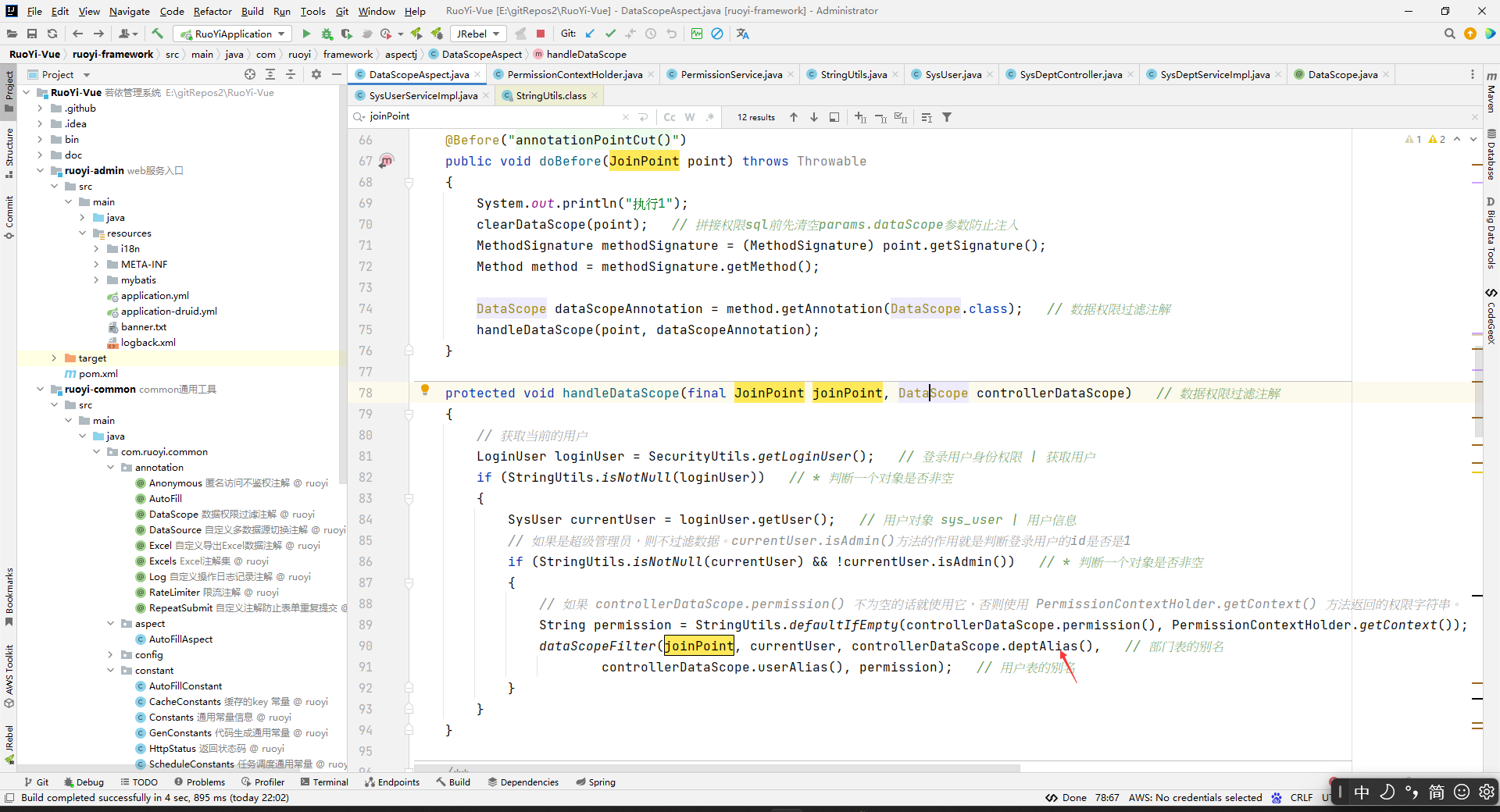
protected void handleDataScope(final JoinPoint joinPoint, DataScope controllerDataScope)
{
// 获取当前的用户
LoginUser loginUser = SecurityUtils.getLoginUser();
if (StringUtils.isNotNull(loginUser))
{
SysUser currentUser = loginUser.getUser();
// 如果是超级管理员,则不过滤数据
if (StringUtils.isNotNull(currentUser) && !currentUser.isAdmin())
{
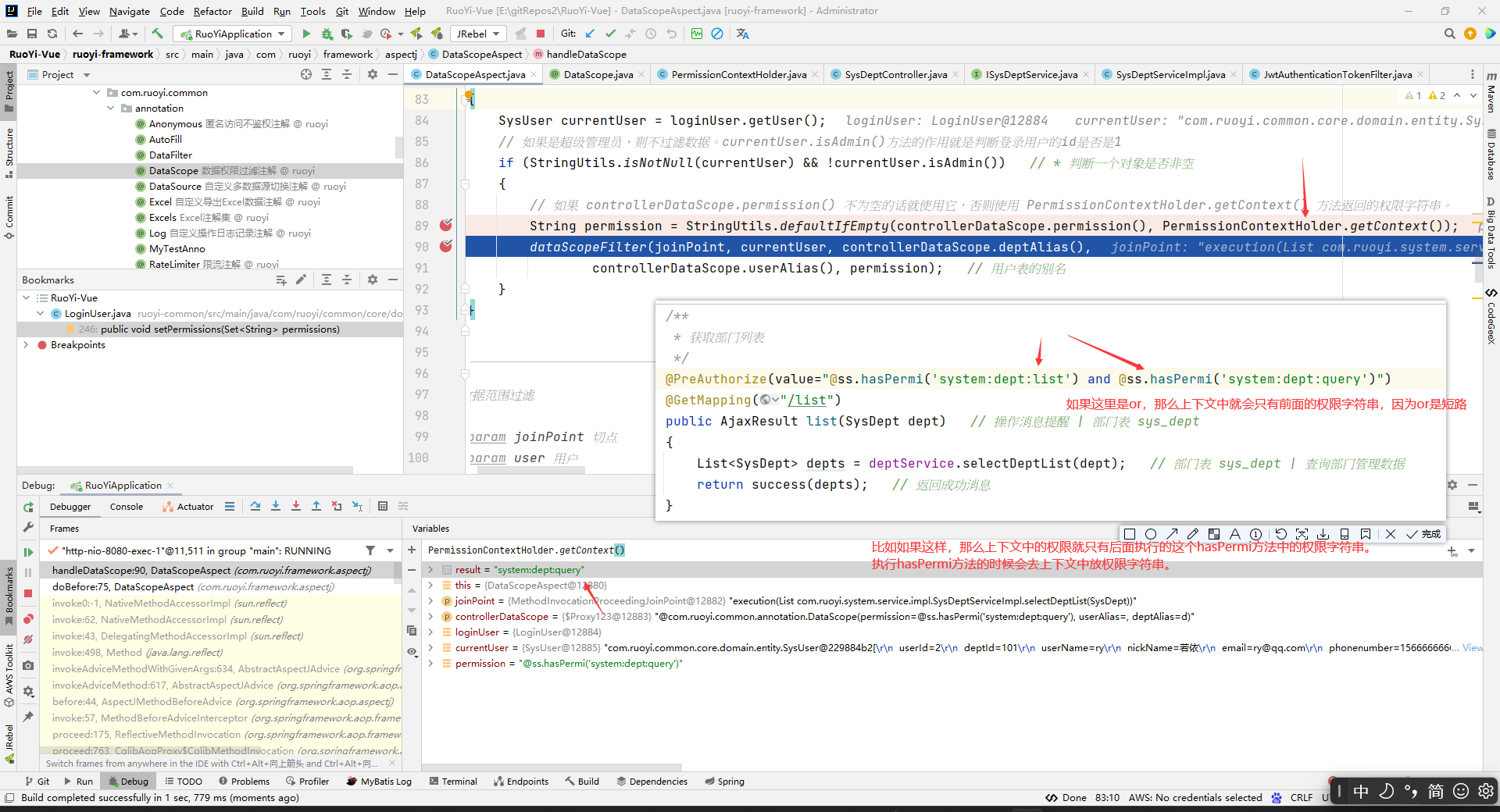
// 如果 controllerDataScope.permission() 不为空的话就使用它,否则使用 PermissionContextHolder.getContext() 方法返回的权限字符串。
// permission的值是:如果被切的方法上面的DataScope中指定了permission的值,那么就用这个权限字符。如果被切的方法上面的DataScope中没有指定permission,那么这里的permission值就是上下文中的权限(上下文中的权限是指最新的放到上下文中的权限,上下文中的权限只能放一个哈。你后面放到上下文中的权限会替换先放到上下文中的权限)。一般设置到上下文中的权限不会被覆盖的,security的认为正确的使用应该就是这样的,因为,一般我们只要现在控制层就行了,多层限制是没有意义的,所以一般你正常使用就不会覆盖上下文中已经设置的权限字符串。然后这里为什么要让DataScope中设置的权限字符串限制优先级大于控制层呢?其实就是为了让你如果要特别限制这个数据接口访问权限,不是直接用前面控制层方法权限来当作访问这个数据接口访问权限,你就可以在这里特别指定只有存在某个权限才能访问这个数据接口访问权限。即,提供了一个你可以操作的可能性。
String permission = StringUtils.defaultIfEmpty(controllerDataScope.permission(), PermissionContextHolder.getContext());
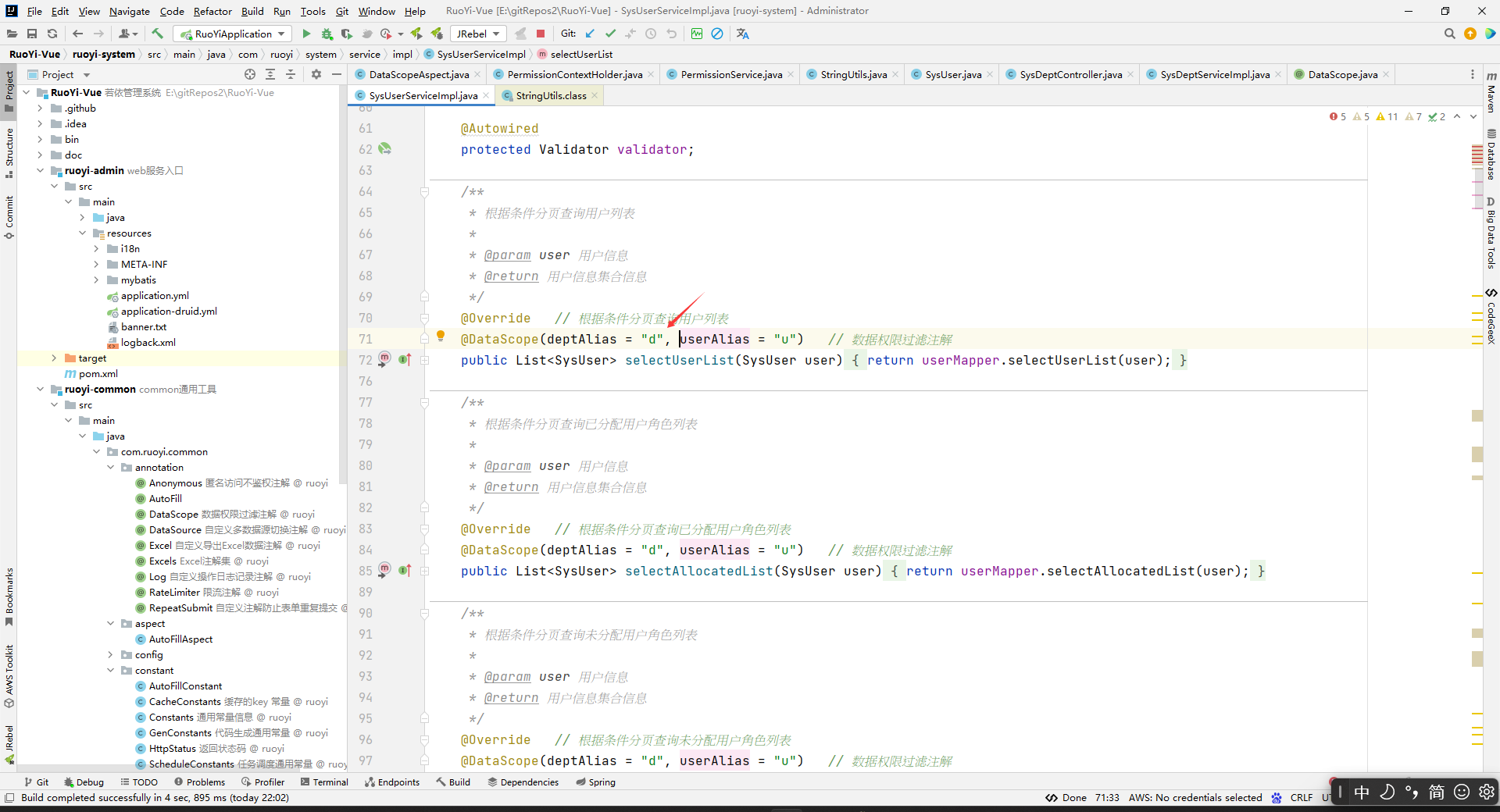
dataScopeFilter(joinPoint, currentUser, controllerDataScope.deptAlias(),
controllerDataScope.userAlias(), permission);
}
}
}
/**
* 数据范围过滤
*
* @param joinPoint 切点
* @param user 用户
* @param deptAlias 部门别名
* @param userAlias 用户别名
* @param permission 权限字符
*/
public static void dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias, String permission)
{
StringBuilder sqlString = new StringBuilder();
List<String> conditions = new ArrayList<String>();
for (SysRole role : user.getRoles())
{
// 获取角色的数据范围。这里我们的数据权限是和角色绑定的,用户是绑定角色的,所以我们要获取当前用户的角色,然后拿到所有权限的并集。
String dataScope = role.getDataScope();
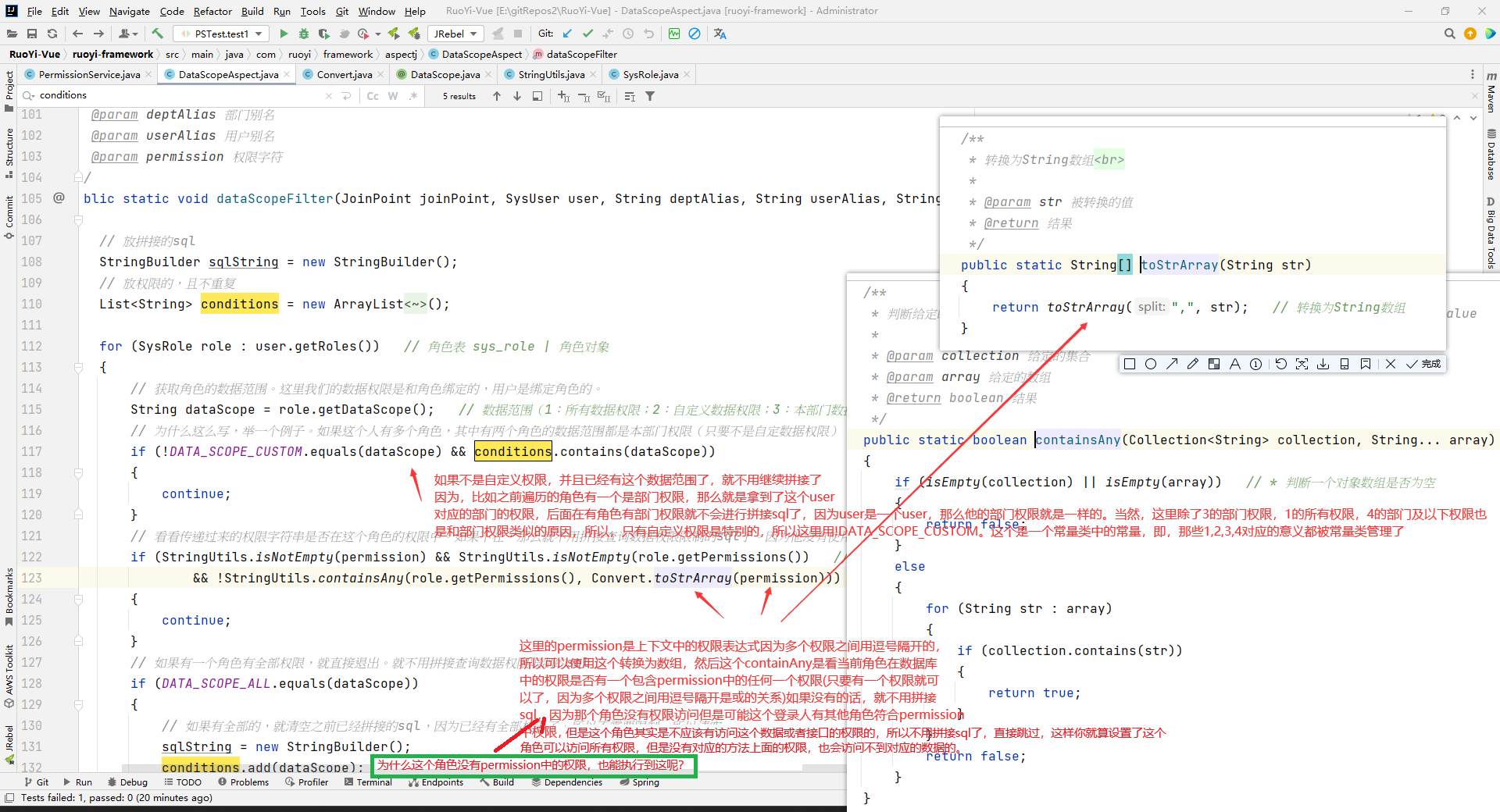
// 为什么这么写,举一个例子。如果这个人有多个角色,其中有两个角色的数据范围都是本部门权限(只要不是自定数据权限),那么就这两个角色能看到的访问就是一样的,所以没有必要多次拼接一样的sql。所以,这里这段代码主要是为了避免重复拼接而已。除了自定义权限外,你多个角色都有设置部门数据权限,其实和一个角色设置了部门数据权限是一样的效果(全部数据权限、部门及以下数据权限、仅本人数据权限也是同样的道理,自己可以理解一下。)。
if (!DATA_SCOPE_CUSTOM.equals(dataScope) && conditions.contains(dataScope))
{
continue;
}
// 如果这里的permission是空,那么都有拼接sql的权限,因为你没有限制嘛。控制层的接口大家都可以访问,这个数据接口大家也都能访问,那么你就拼sql就行了,不限制。
// 如果角色的权限是空,那么不会限制拼接sql。相当于是没有权限限制。但是注意,如果用户只有这个空权限的角色,是那么这个用户是看不到任何菜单的。
// 如果不存在当前遍历的角色中的权限有任何一个权限和permission中的任何一个权限匹配,那么就不拼接sql。注意这个permission字符串可能是有逗号的,逗号的话,我们只要当前遍历角色的所有权限中只有有一个符合permission中逗号分隔的权限的其中一个就行了。
// 总之意思就是,你角色要有权限才能有查看这个数据。比如,你用户有一个角色数据权限是,可以看部门的DATA_SCOPE_ALL权限的,即可以看全部的数据权限,但是这个角色只有一个查看用户管理的菜单权限,没有查看部门list的权限字符,但是DataScope注解又写在查看部门list的service方法上,所以当遍历这个角色的时候,会执行continue,即不会拼接sql,你就看不到全部数据了。你这个用户还有一个角色是,可以看到用户的部门权限(即数据权限是DATA_SCOPE_DEPT),并且是有查看部门list的权限,所以,执行到这里的时候permission中就是system:dept:list,并且你的role.getPermissions()中有对应的权限,那么就会拼接对应的sql,所以就可以看到部门对应的数据。所以这个用户有上面两个角色,就只能看到它所在部门的权限了。
if (StringUtils.isNotEmpty(permission) && StringUtils.isNotEmpty(role.getPermissions())
&& !StringUtils.containsAny(role.getPermissions(), Convert.toStrArray(permission)))
{
continue;
}
// 如果有一个角色有全部权限,就直接退出。就不用拼接查询数据权限限制的sql了。
if (DATA_SCOPE_ALL.equals(dataScope))
{
// 如果有全部的,就清空之前已经拼接的sql,因为已经有全部权限了,所以不需要限制,所以清空。
sqlString = new StringBuilder();
conditions.add(dataScope);
break;
}
// 如果是自定义的数据权限,那么就看你这个角色绑定的部门角色表中的部门id列表,即,查询的时候要加上查询角色部门表的限制条件。
else if (DATA_SCOPE_CUSTOM.equals(dataScope))
{
sqlString.append(StringUtils.format(
" OR {}.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = {} ) ", deptAlias,
role.getRoleId()));
}
// 部门数据权限。上面的自定义的数据权限是可以选择某些具体部门下的,这个部门数据权限是能看到用户所在的本部门下的数据。
else if (DATA_SCOPE_DEPT.equals(dataScope))
{
sqlString.append(StringUtils.format(" OR {}.dept_id = {} ", deptAlias, user.getDeptId()));
}
// 部门及以下数据权限。可以看到本部门和本部门的下级部门的数据。部门和部门之间的父子关系是用parentId来维系的。find_in_set中存这这个部门的父级id们。下面拼接的sql意思是,找到部门表所有数据中部门id和当前用户的部门id一样的数据或者ancestors字段包含当前用户的部门id的数据。
else if (DATA_SCOPE_DEPT_AND_CHILD.equals(dataScope))
{
sqlString.append(StringUtils.format(
" OR {}.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = {} or find_in_set( {} , ancestors ) )",
deptAlias, user.getDeptId(), user.getDeptId()));
}
// 仅本人数据权限。只能看到登录者自己的数据。
else if (DATA_SCOPE_SELF.equals(dataScope))
{
if (StringUtils.isNotBlank(userAlias))
{
sqlString.append(StringUtils.format(" OR {}.user_id = {} ", userAlias, user.getUserId()));
}
else
{
// 数据权限为仅本人,但是给没有userAlias别名。那么不会查询任何数据。
sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));
}
}
conditions.add(dataScope);
}
// 多角色情况下,如果所有角色都没有查看这个数据的权限,这个时候sqlString也会为空,所以要限制一下,不查询任何数据。因为dept_id=0不存在,所以可以用这个方式来让它不查询任何数据。
if (StringUtils.isEmpty(conditions))
{
sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));
}
// 拿到实体类。然后把数据给到param这个Map<String, Object>中去,到时候会拼接给xml中去的。
if (StringUtils.isNotBlank(sqlString.toString()))
{
// 拿到实体类
Object params = joinPoint.getArgs()[0];
if (StringUtils.isNotNull(params) && params instanceof BaseEntity)
{
BaseEntity baseEntity = (BaseEntity) params;
// 把sqlString从索引位置 4(第五个字符,因为索引从 0 开始)开始,截取到字符串的末尾。这样可以去除“ OR ”
baseEntity.getParams().put(DATA_SCOPE, " AND (" + sqlString.substring(4) + ")");
}
}
}
/**
* 拼接权限sql前先清空params.dataScope参数防止注入
*/
private void clearDataScope(final JoinPoint joinPoint)
{
Object params = joinPoint.getArgs()[0];
if (StringUtils.isNotNull(params) && params instanceof BaseEntity)
{
BaseEntity baseEntity = (BaseEntity) params;
baseEntity.getParams().put(DATA_SCOPE, "");
}
}
}
解析:
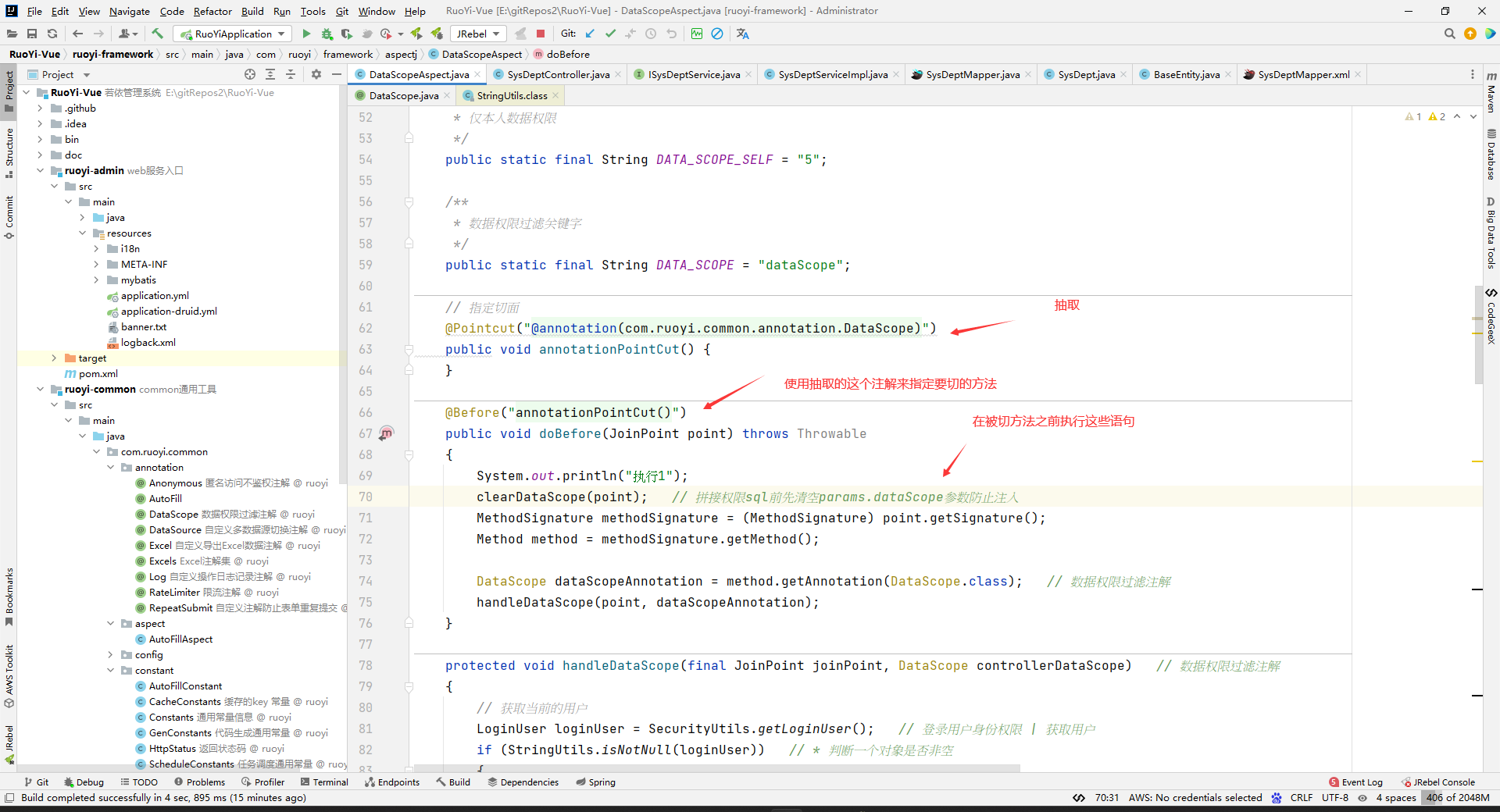
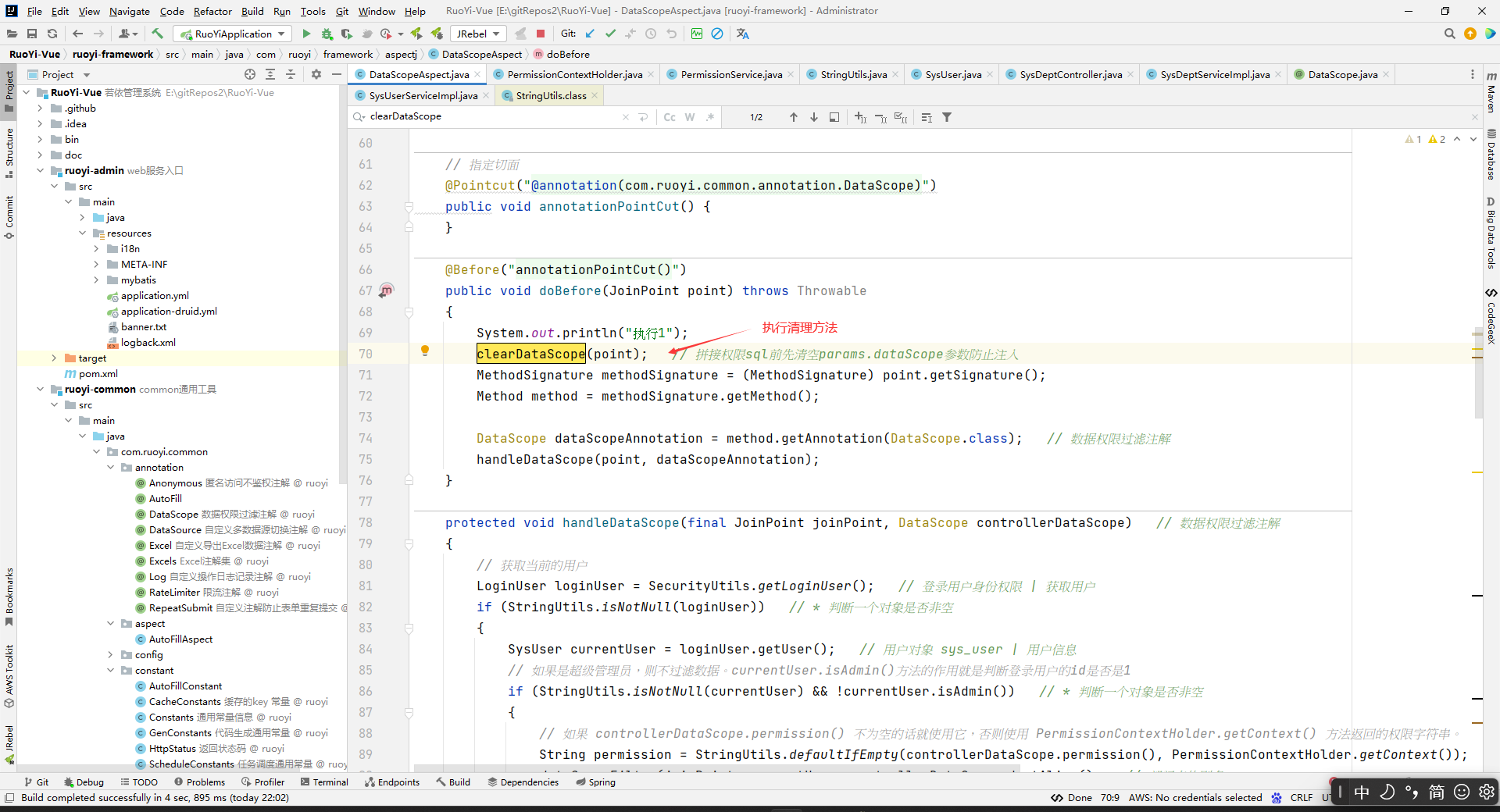
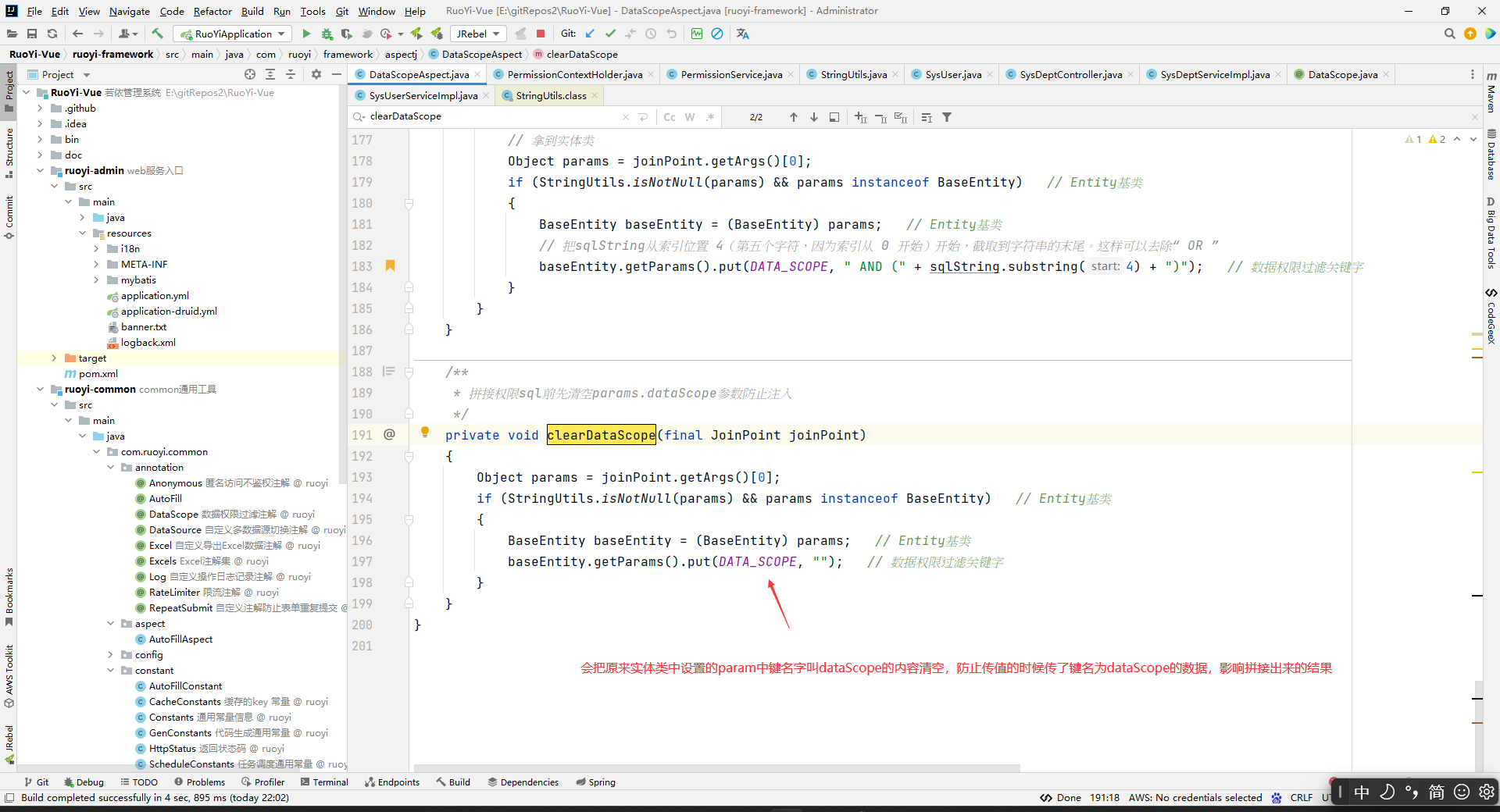
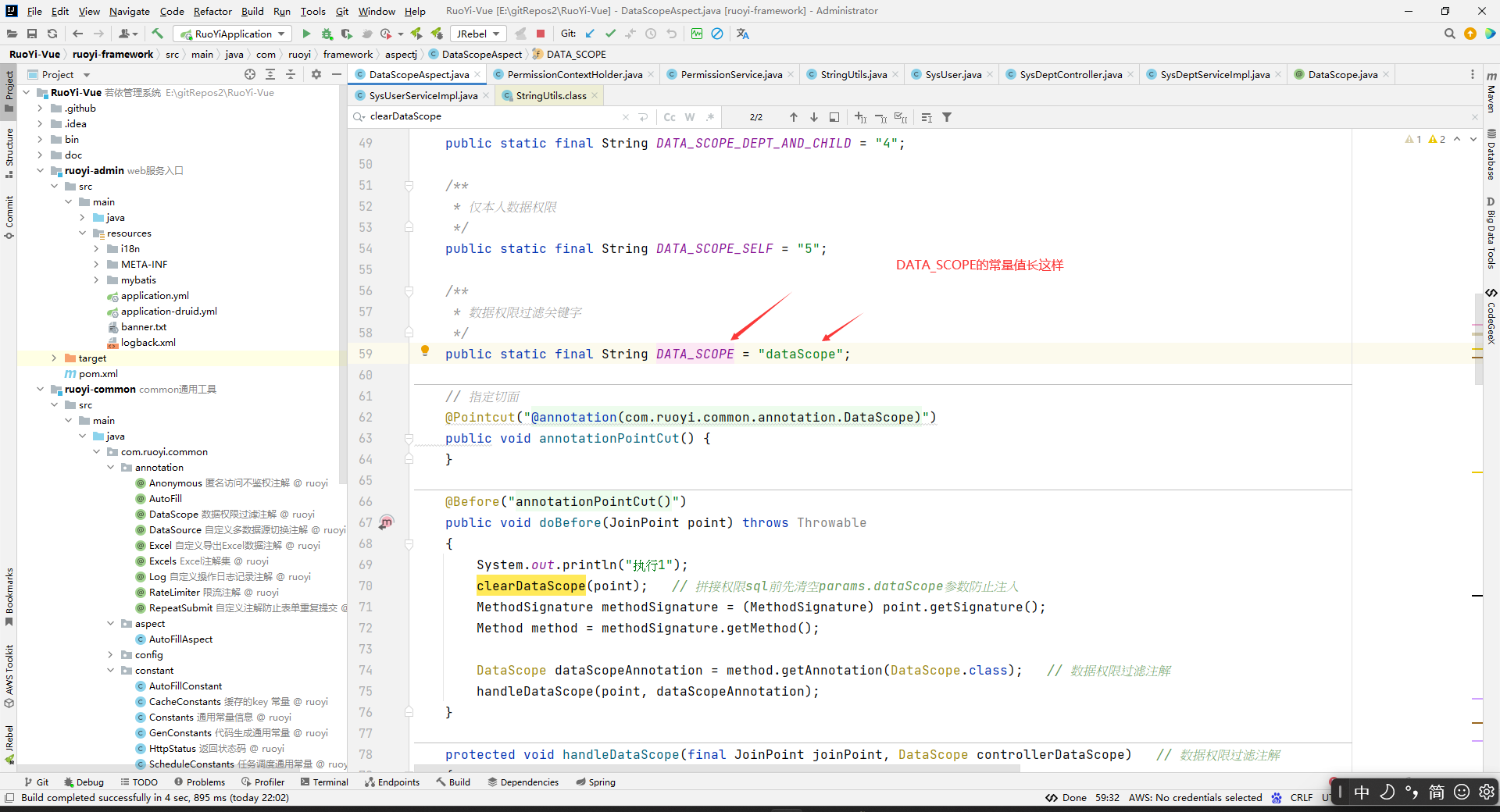
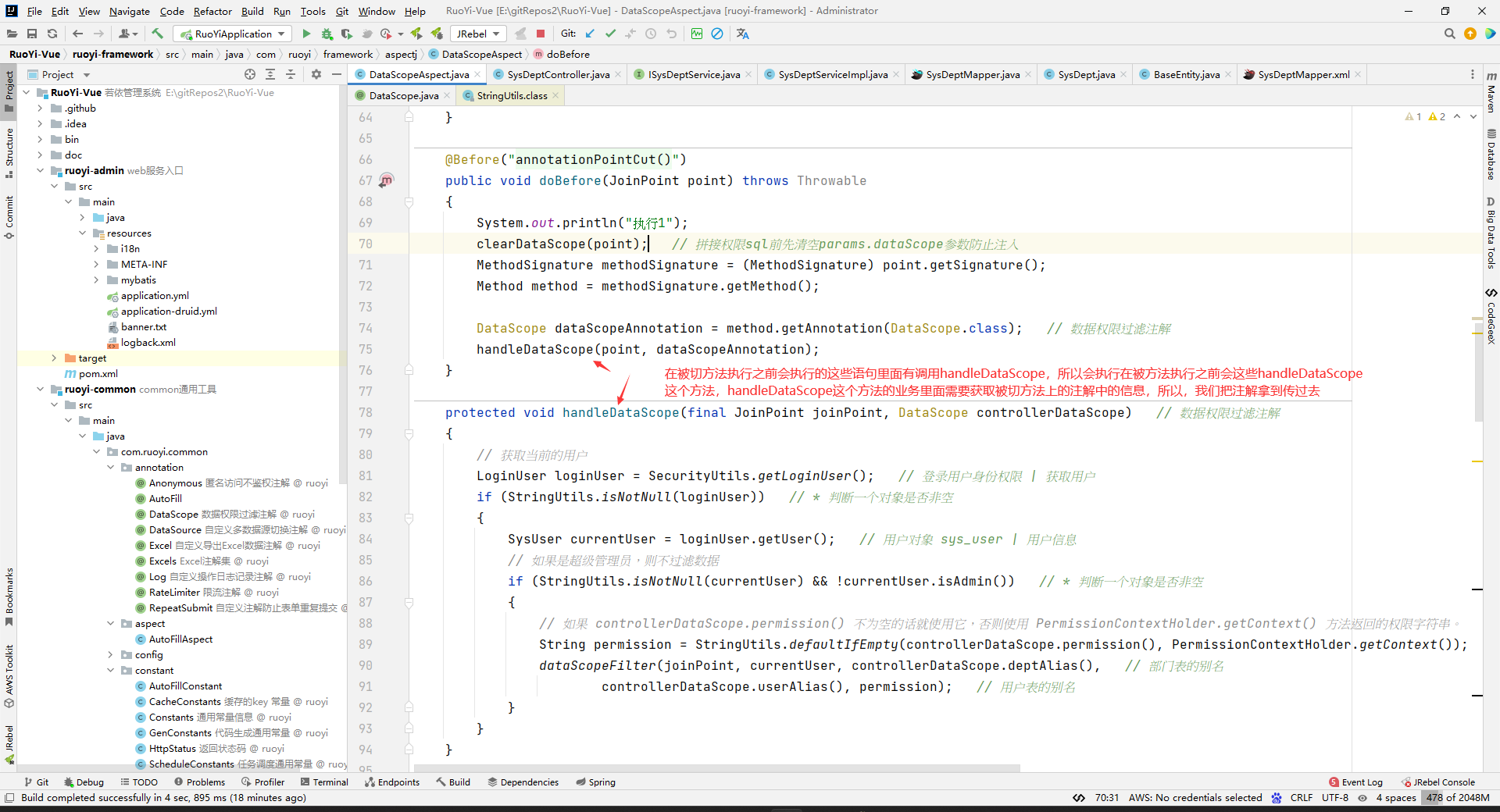
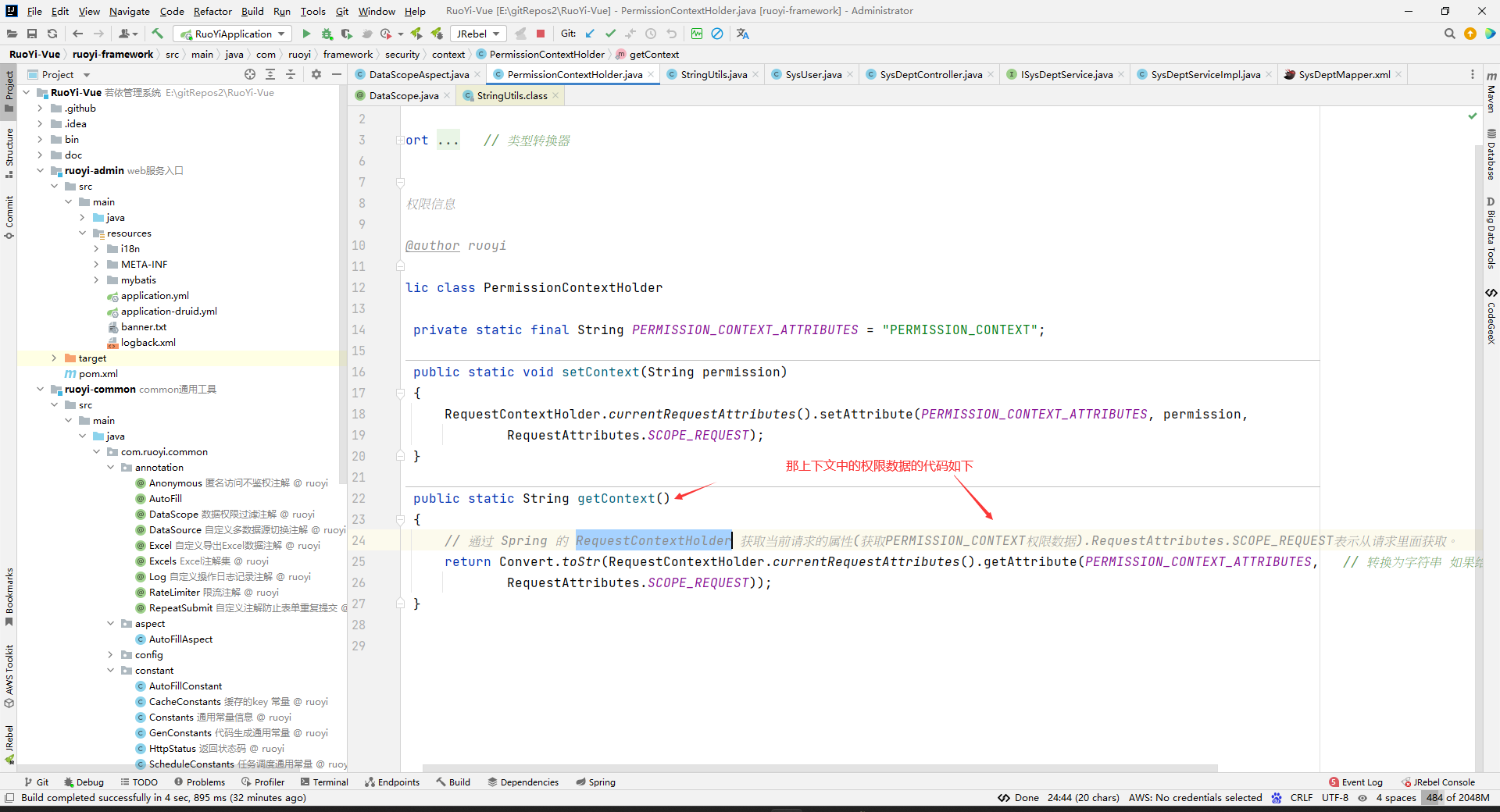
那么这个上下文中的PERMISSION_CONTEXT对应的值是什么时候放进去的呢?
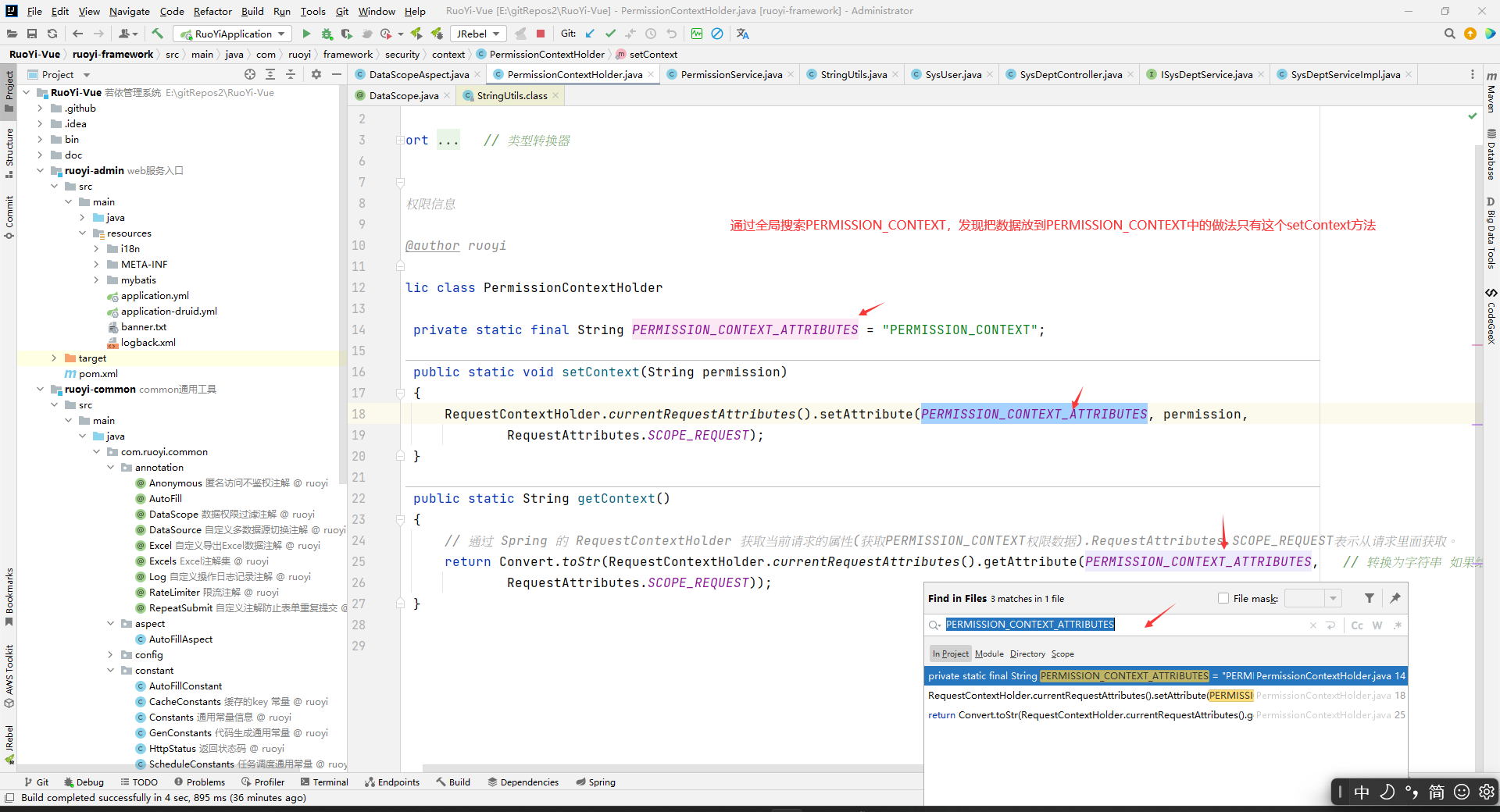
看到两个用的地方都是在PermissionService中:
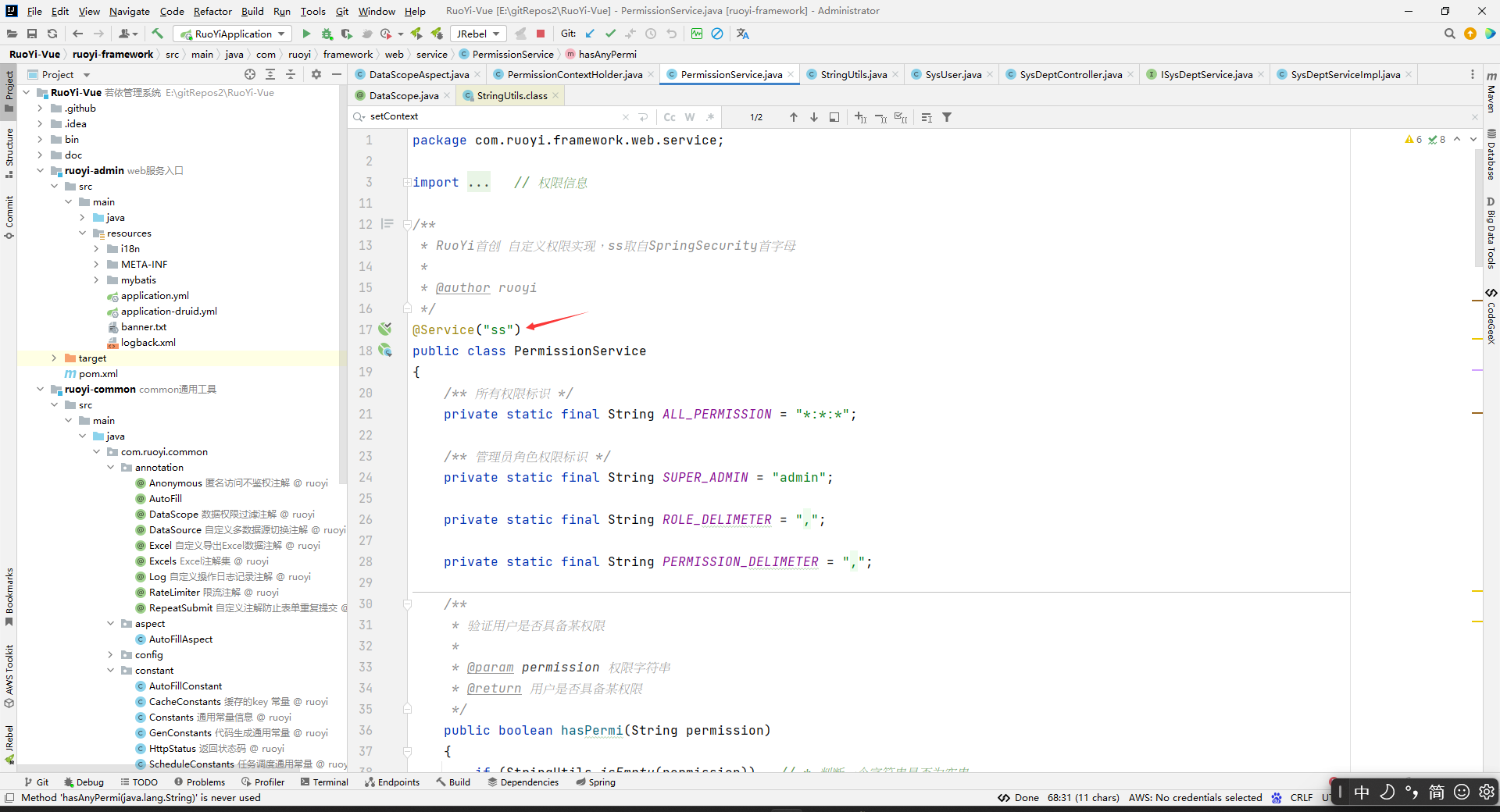
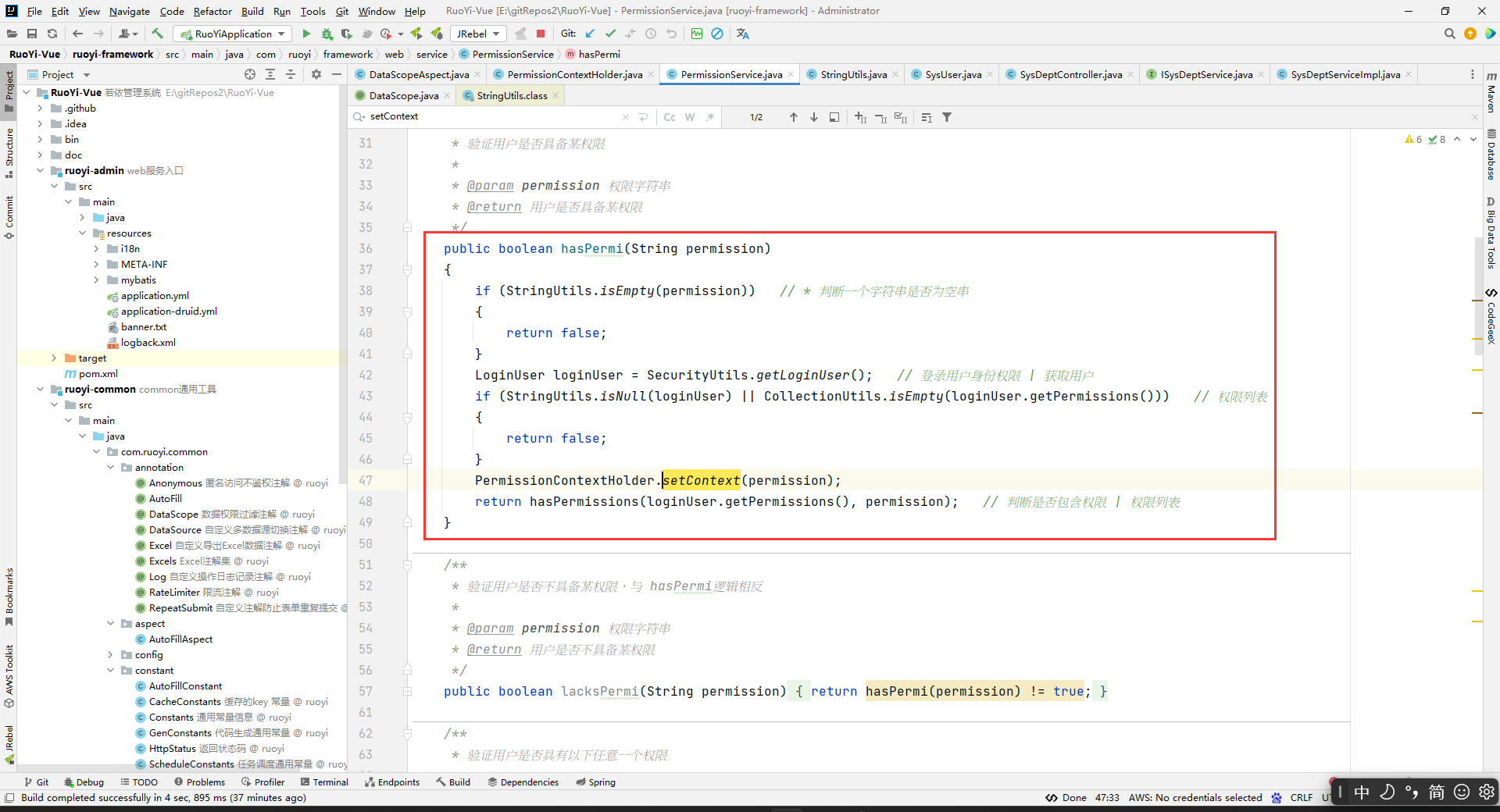
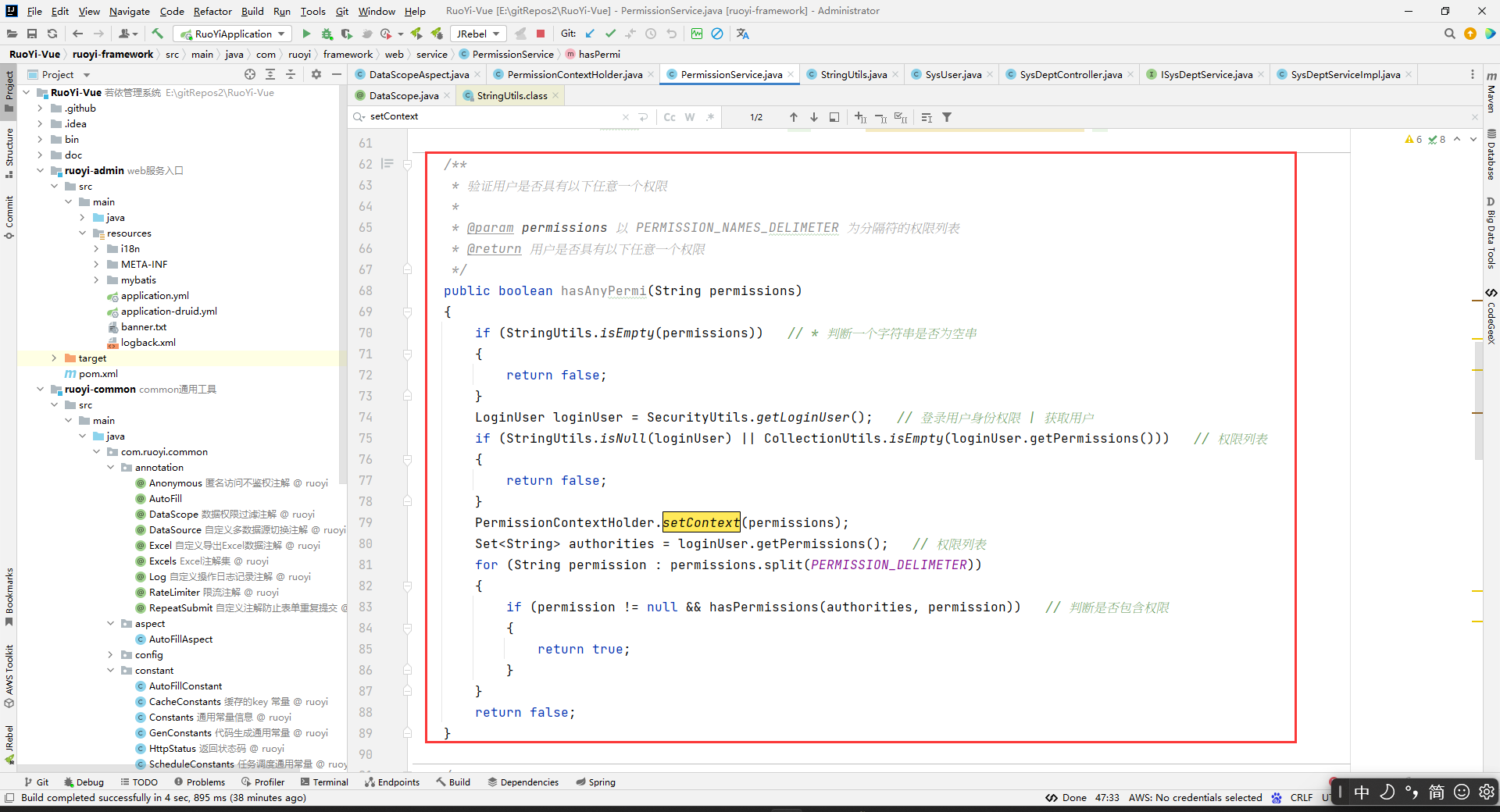
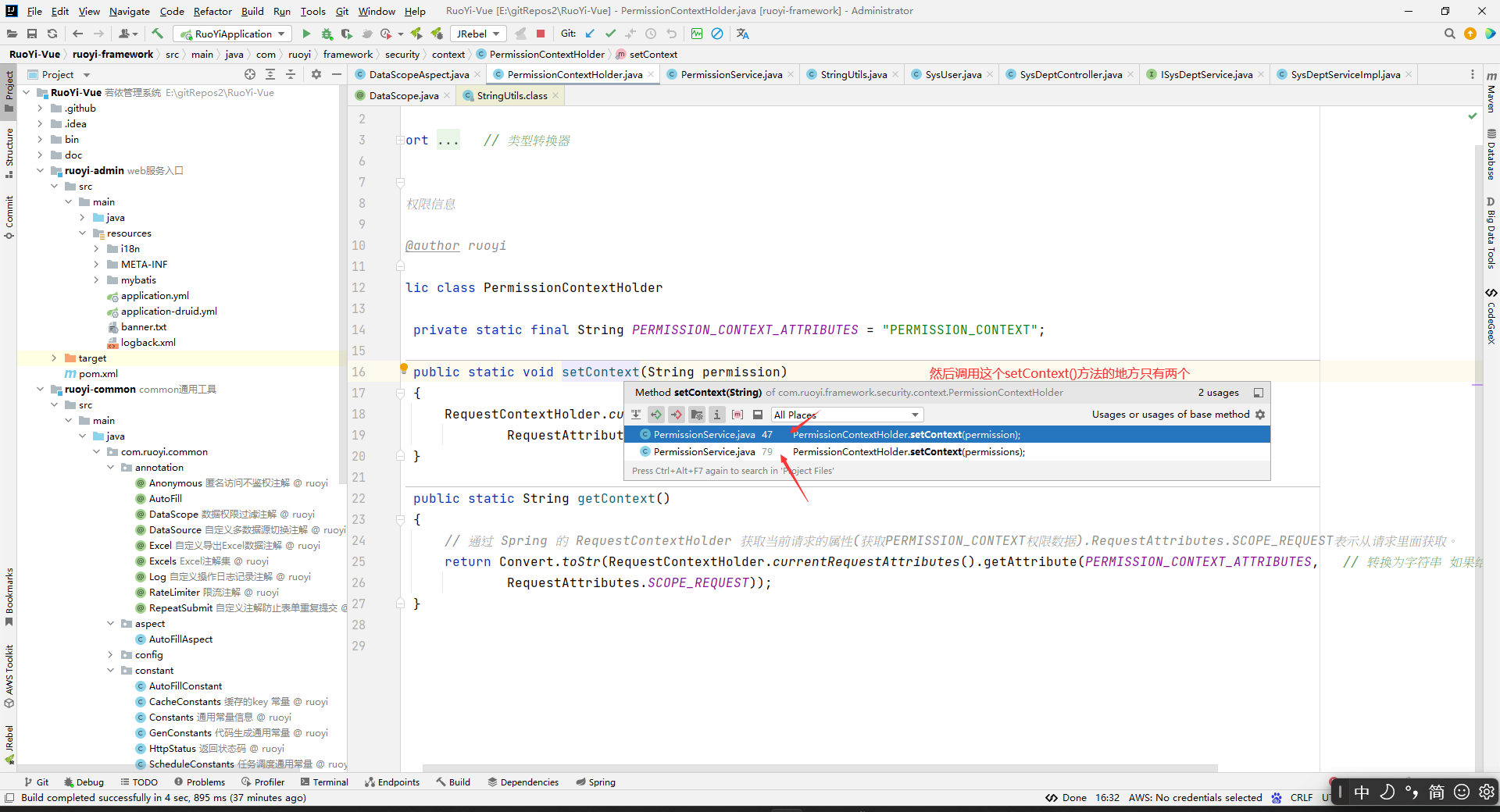
所以把数据存到上下文中去的做法只能是通过hasPermi()或者hasAnyPermi()方法,在方法调用的时候通过形参放到上下文去。
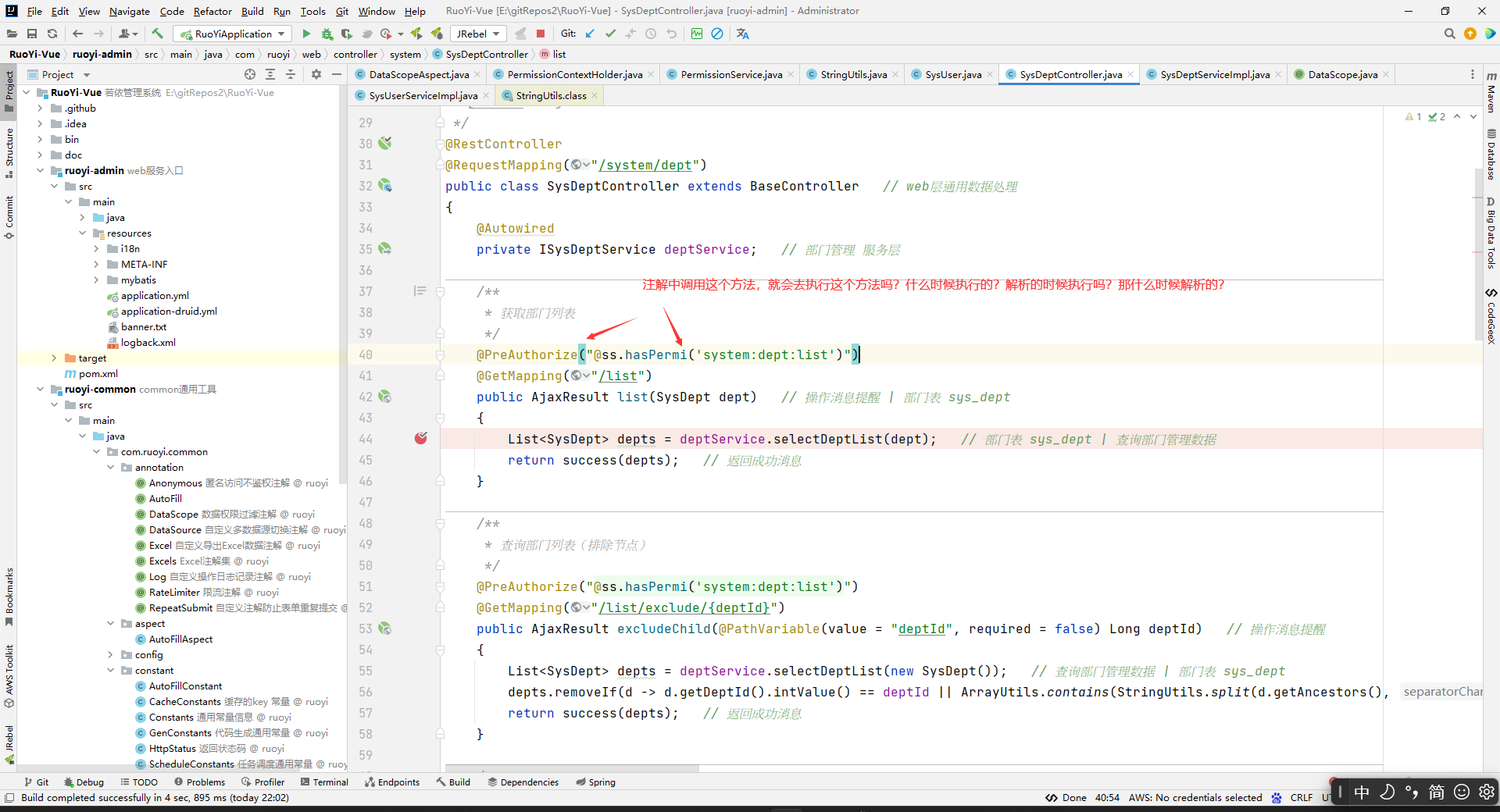
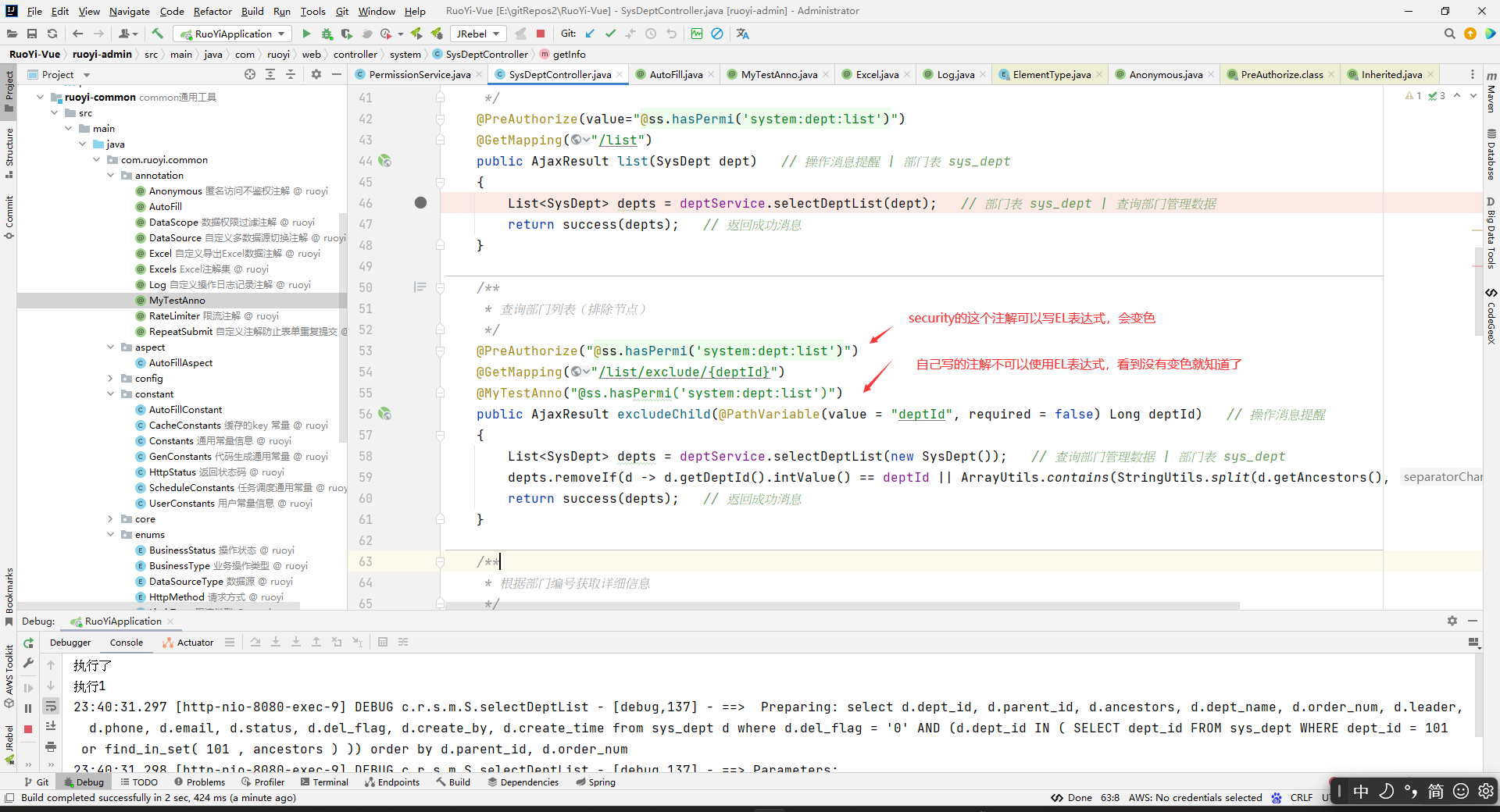
因为hasAnyPermi()方法是灰的,所以没有地方使用。而hasPermi()方法都在控制层中使用:
随便看一个使用的地方,看看是怎么用的:
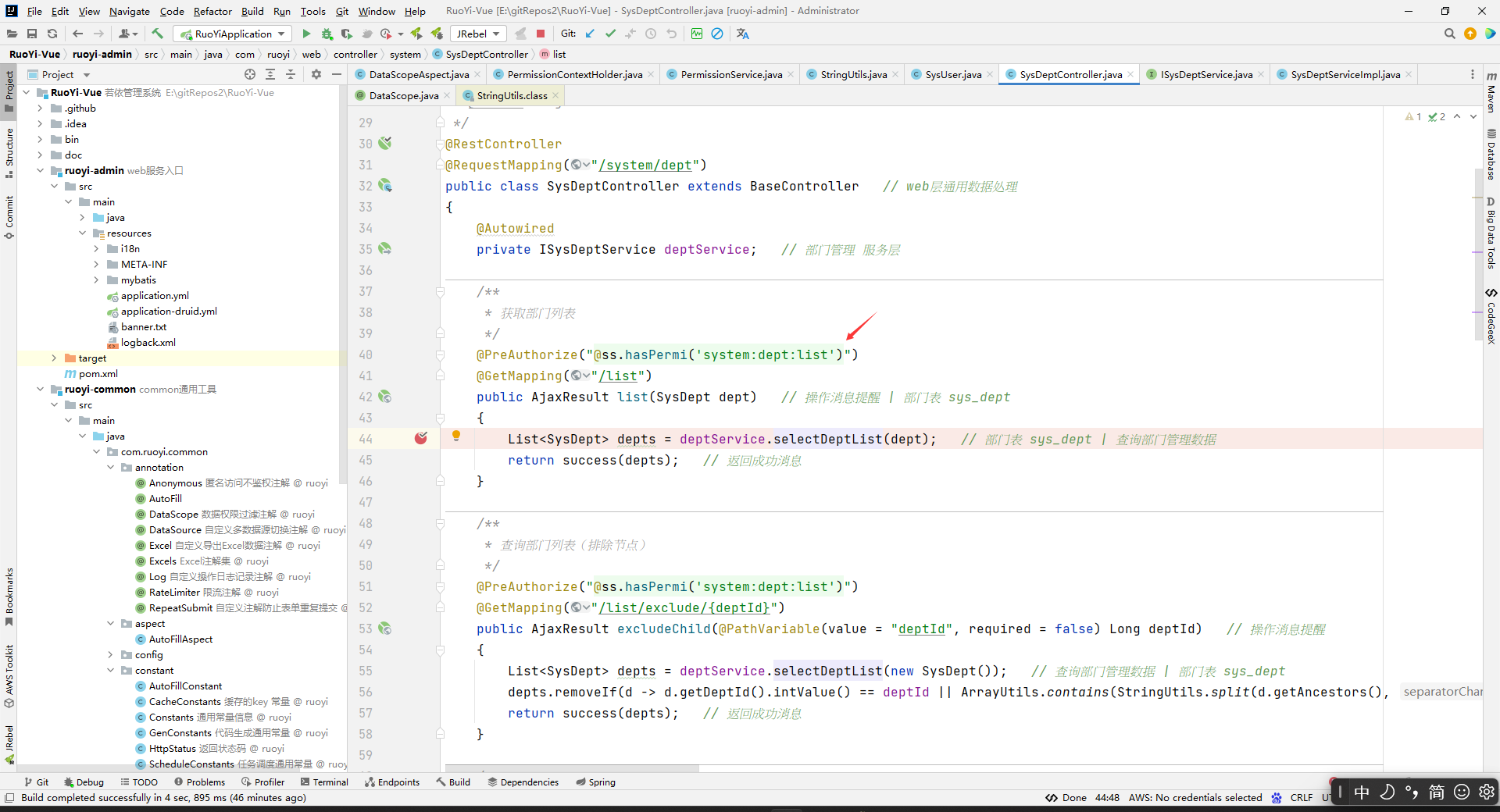
这个是security的注解,这个@PreAuthorize中的@ss.hasPermi()方法会在我们访问对应的方法之前执行。比如,上图中,@ss.hasPermi方法会在list方法被执行前去执行。
所以,前面StringUtils.defaultIfEmpty(controllerDataScope.permission(), PermissionContextHolder.getContext());的效果是:如果DataScope注解中有指定permission,那么就DataScope注解中的permission,如果没有,就看上下文中的权限。然后上下文中的权限只能通过hasPermi方法设置进去,并且是替换的关系,即你后面使用hasPermi方法保存到上下文中的权限字符串会替换之前已经被放进去的权限字符串。然后一般我们hasPermi方法是在控制层中有的,并且一般也不会多次使用hasPermi方法方法,所以上下文中的权限字符串一般就是控制层已经被执行的方法上面设置的hasPermi方法中指定的权限字符串。即,StringUtils.defaultIfEmpty(controllerDataScope.permission(), PermissionContextHolder.getContext());的返回值就是:如果DataScope注解中有指定permission,那么就DataScope注解中的permission,如果没有,一般就是指控制层已经执行的方法上面hasPermi方法中指定的权限字符串。
注意:上下文中只能保存最新放进去的权限字符串。
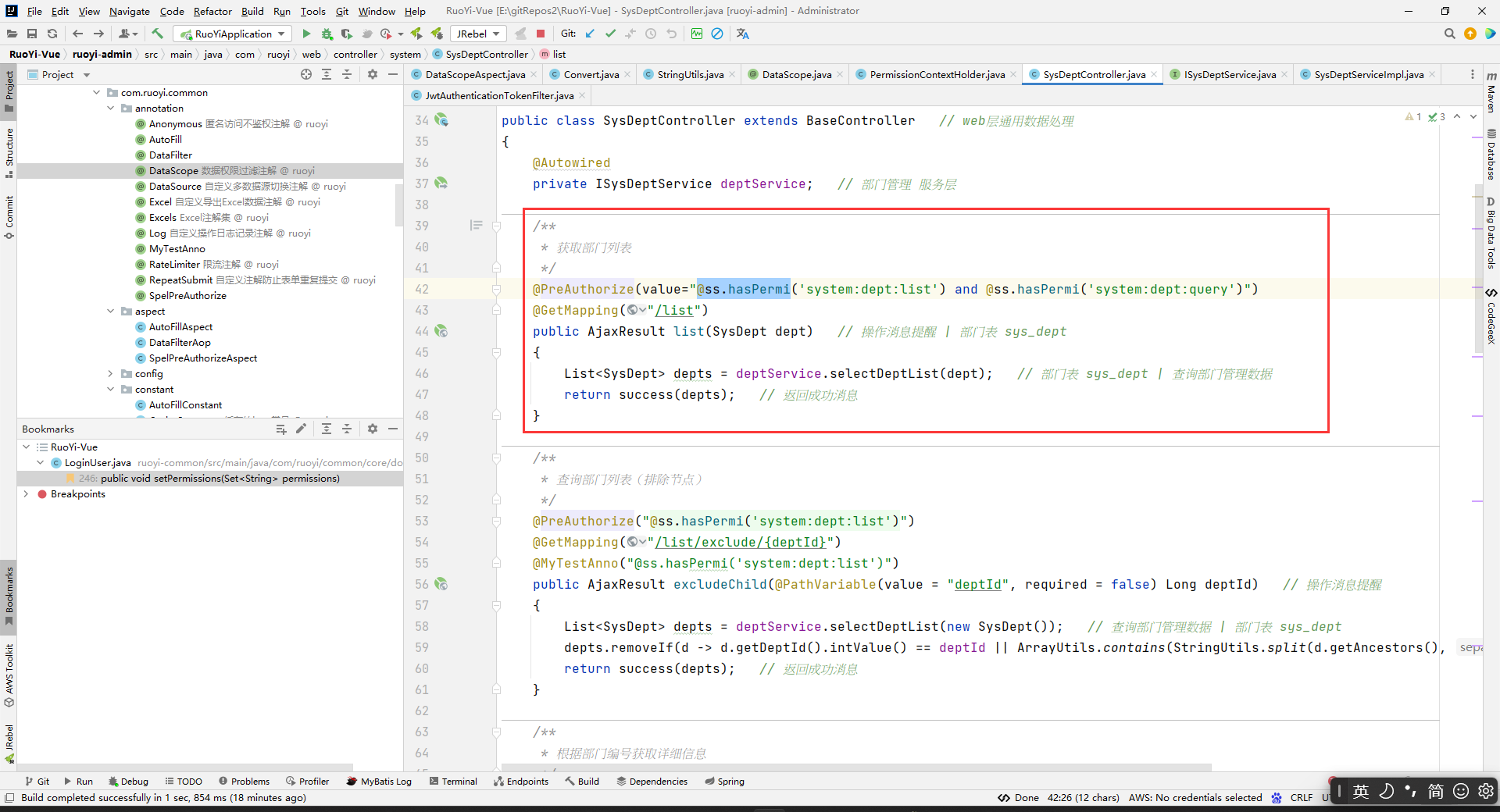
如果这样写:
那么这里StringUtils.defaultIfEmpty(controllerDataScope.permission(), PermissionContextHolder.getContext());的PermissionContextHolder.getContext()中的权限就是最新的权限,不会是system:dept:list。
中间插入一些联想
这里有两个疑惑:
为什么注解中的内容长下面这样?看起来它是方法,但是它设置值是通过看起来像属性一样的使用的?方法里面使用像是方法一样使用?
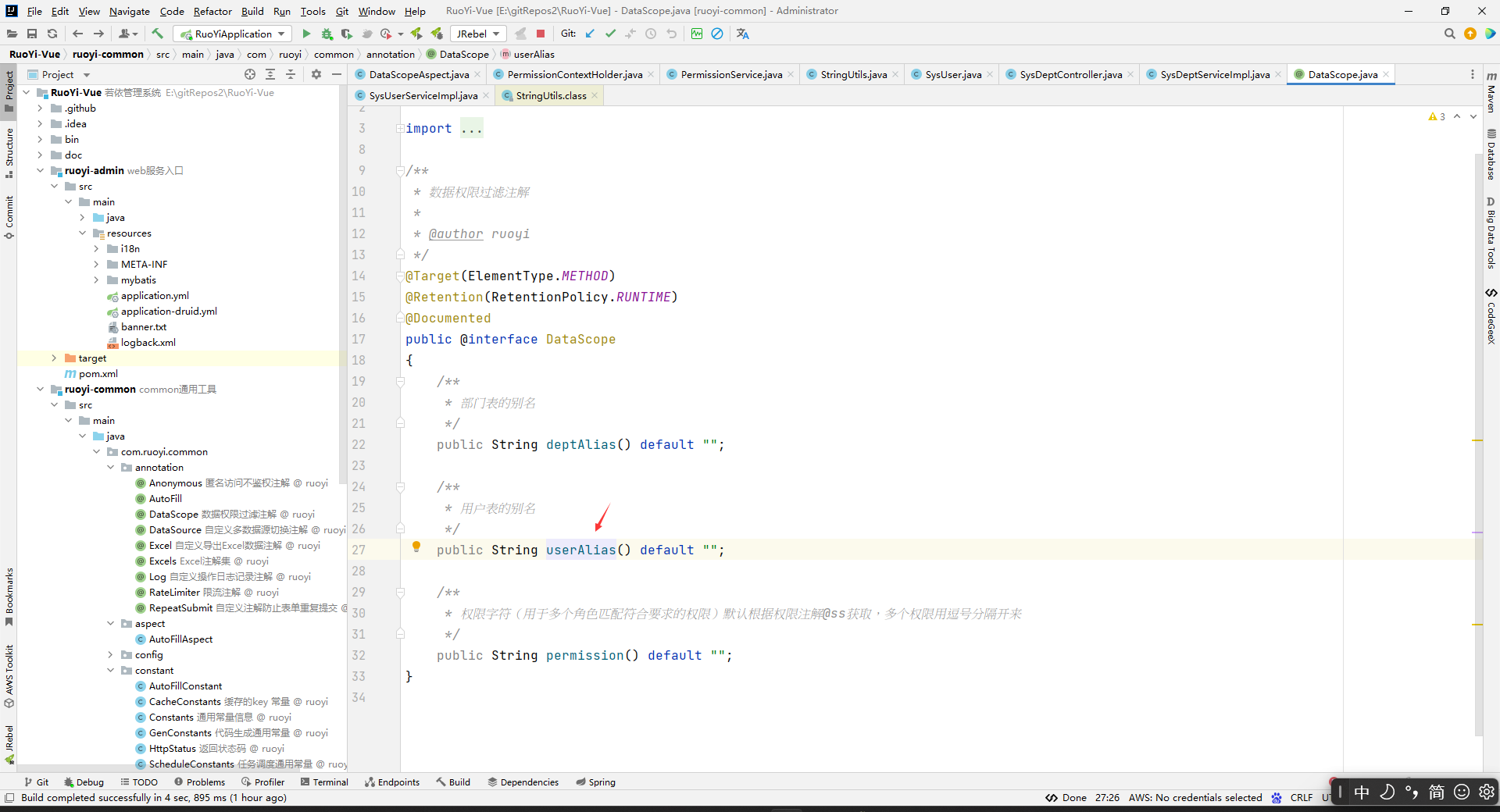
答:在注解中,就是像上面这样用的,就是你定义一个注解,注解中的一些属性就是写成public String deptAlias() default “”;这种的。这个在之前的笔记中有记录的,所以这里不细讲了。总之,你可以理解为注解中deptAlias()这种东西就是注解的一个属性,然后如果这个属性没有default那么你使用注解的时候一定得指定这个注解属性的值才行,如果属性有default,那么你可以在使用注解的地方指定这个属性的值,去覆盖默认值,或者你使用的时候不指定这个值也行,反正他会用默认值的。然后如果你要去拿注解中的属性值,那么你只能通过getAnotation拿到注解实例然后通过“注解实例.deptAlias()”去拿到注解中的deptAlias()属性的值。
@PreAuthorize(“@ss.hasPermi(‘system:dept:list’)”)注解中使用@ss.hasPermi(‘system:dept:list’)这种方式调用方法,是什么效果?是会去执行这个方法吗?然后把执行的结果给注解中的属性吗?是需要解析程序解析的时候才能执行这里面的方法吗?是什么时候执行的?什么时候解析的?
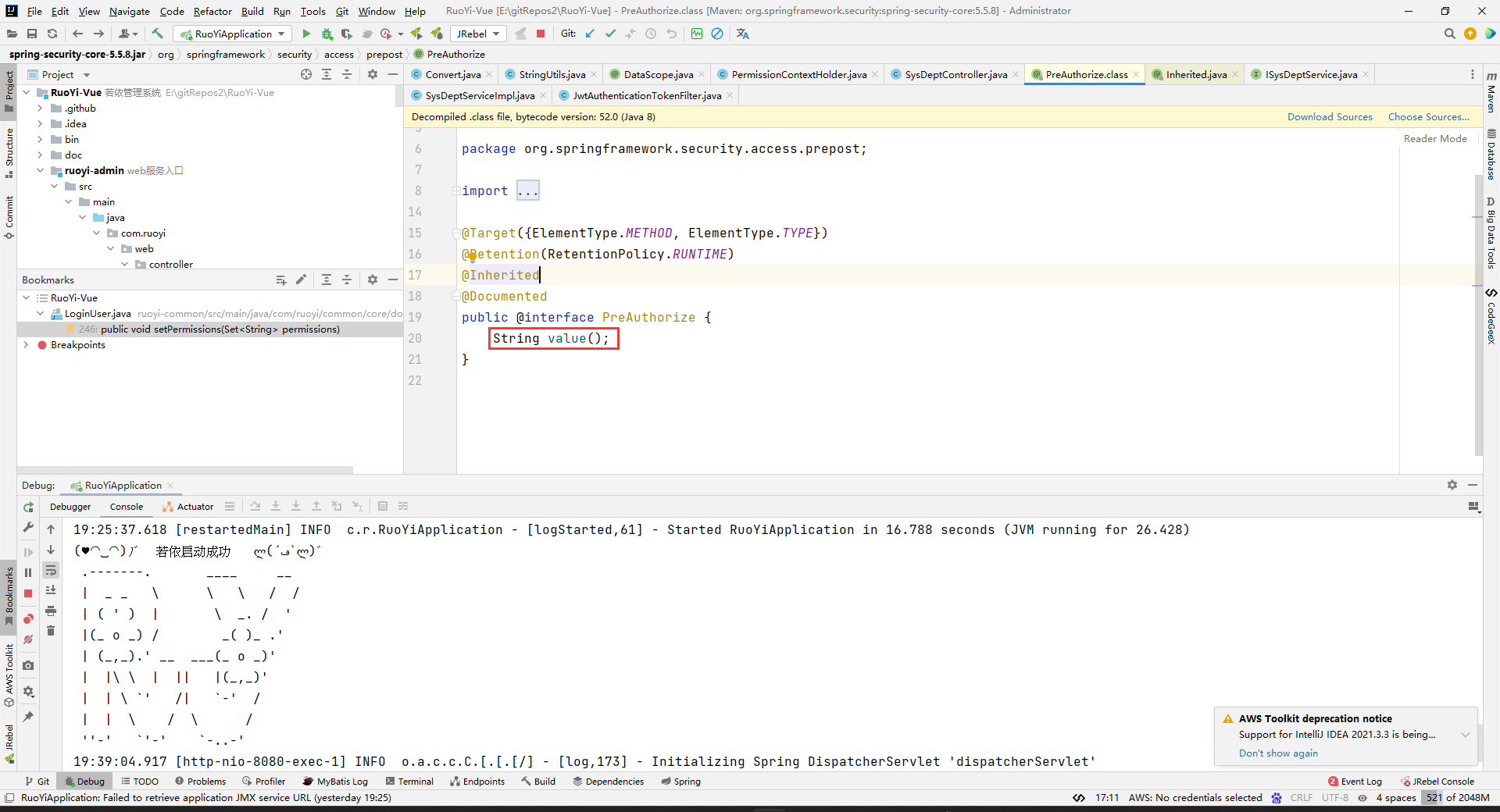
答:上面的这个@PreAuthorize(“@ss.hasPermi(‘system:dept:list’)”)其实相当于是@PreAuthorize(value=“@ss.hasPermi(‘system:dept:list’)”),因为这个@PreAuthorize注解中只有一个value属性,所以可以省略value,这个也是注解那边的知识点。
前面说的@ss.XX是EL表达式的写法,EL表达式更多的知识可以看:https://blog.csdn.net/JokerLJG/article/details/124434854
然后@ss.hasPermi(‘system:dept:list’)这个整体你可以当做是一个值就行了,具体的值是什么,就看@ss.hasPermi(‘system:dept:list’)方法返回什么。
其实@ss.hasPermi(‘system:dept:list’)对于@PreAuthorize注解来说就是一个普通的字符串,但是因为Security底层解析程序是会解析EL表达式的写法的,然后把解析出来的值替换@ss.hasPermi(‘system:dept:list’)字符串作为PreAuthorize的value的值,所以这里@ss.hasPermi(‘system:dept:list’)表面上看就是普通的字符串,是一个EL表达式格式的普通字符串,但是Security实际去执行的时候,会把EL表达式解析并执行,然后把EL表达式执行的返回结果当做@PreAuthorize的value属性的值的。
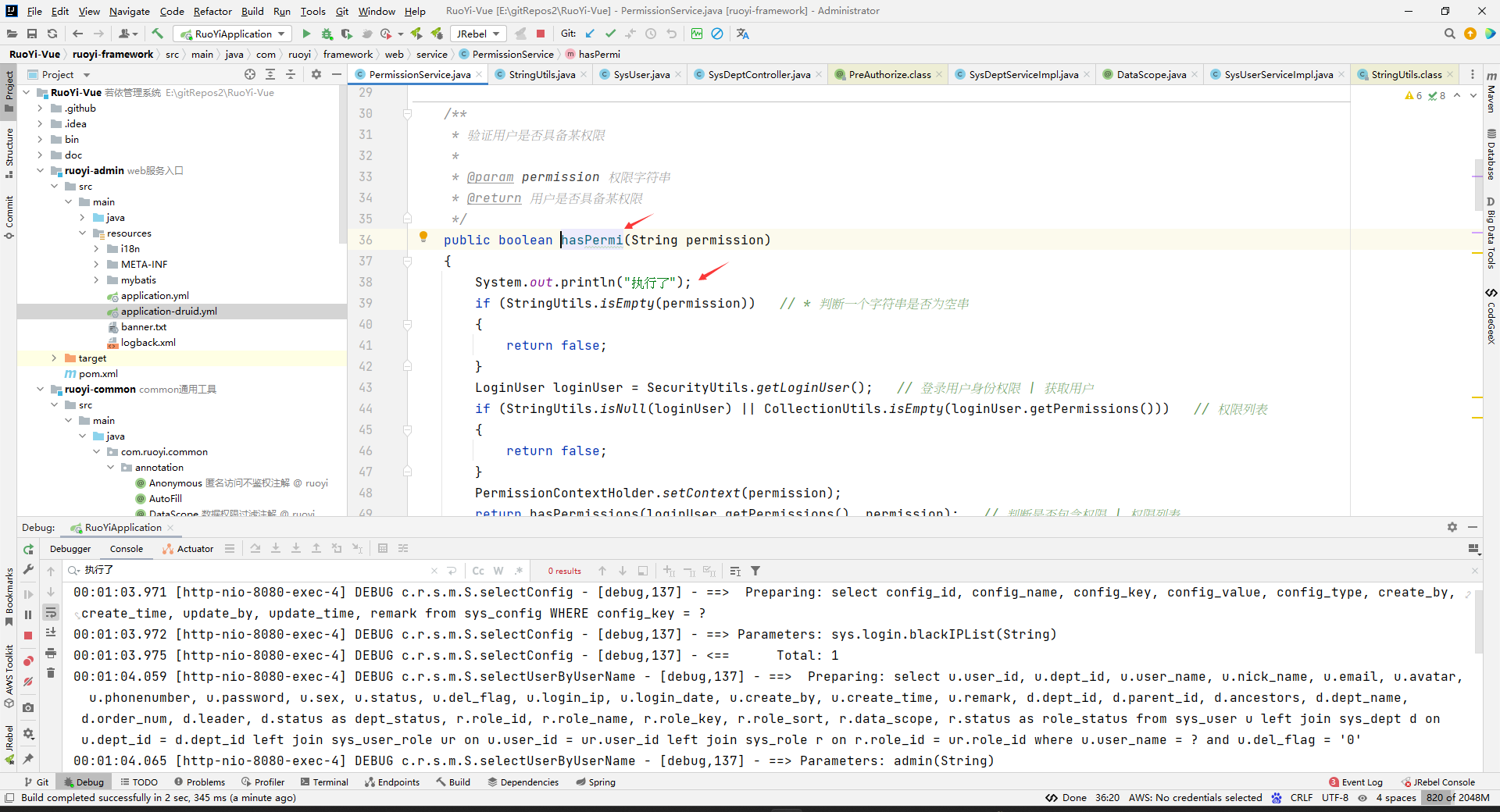
下面我们看看上面的几个问题,第一个什么时候执行。
我在hasPermi(String permission)方法中加了打印语句,发现项目启动的时候,没有去访问加了@PreAuthorize(value=“@ss.hasPermi(‘某某’)”)的接口,所以执行时间不是项目启动时。
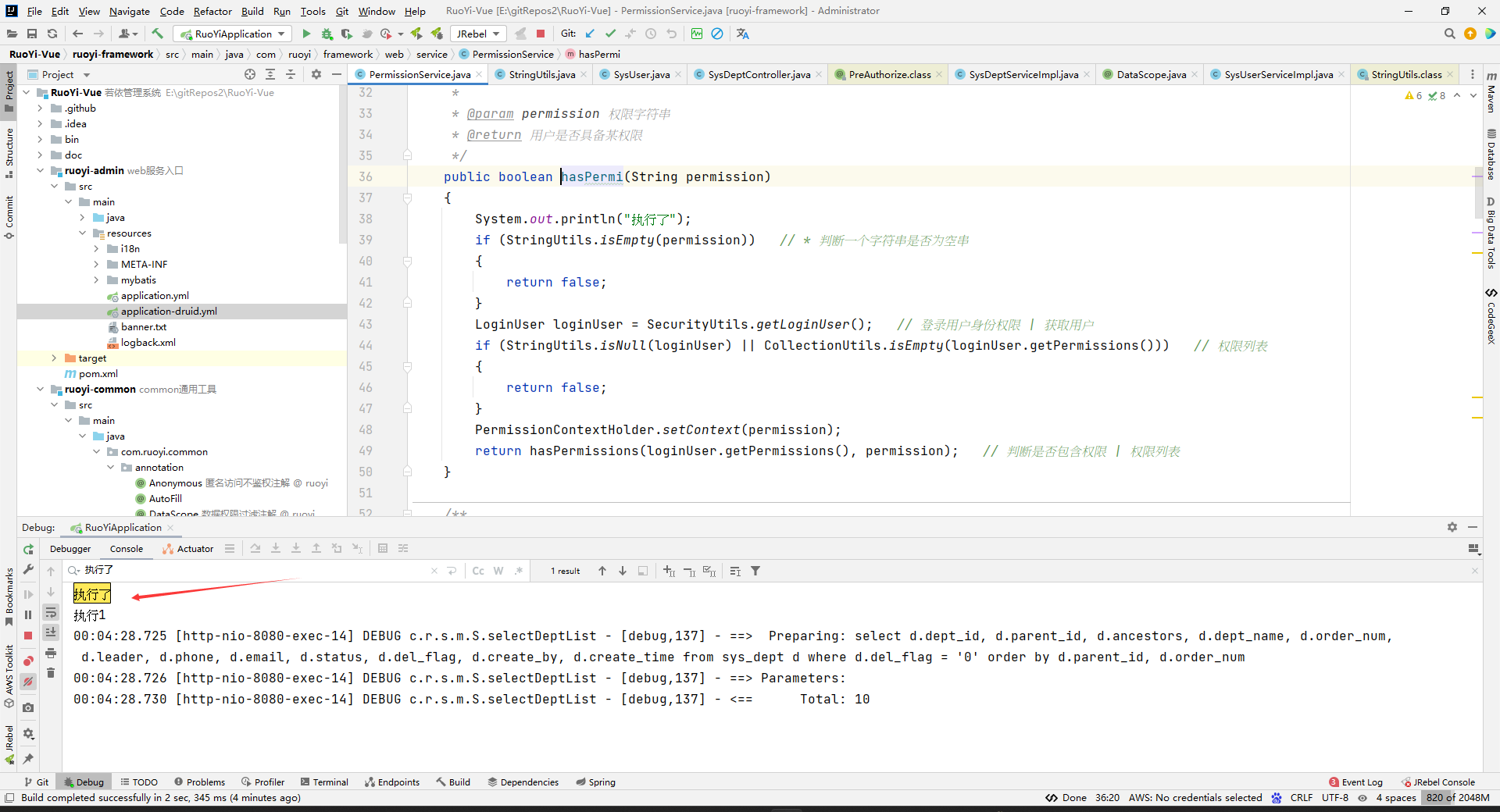
但是,当我们访问某个加了@PreAuthorize(value=“@ss.hasPermi(‘某某’)”)注解的方法,就会出现下面这个打印,说明hasPermi方法是在方法访问前执行的。这里我没有看源码,很有可能底层也是使用AOP切入所有加了这个注解的@PreAuthorize的方法,然后进行一个前置增强,所以A方法上面的@PreAuthorize注解解析的语句块,是在A方法访问前执行的,在解析程序执行的时候会去解析@ss.hasPermi(‘某某’),并调用这个方法。
我自己写了一个注解的测试,自己写的注解不能自动解析EL表达式的(我写的注解中的内容和@PreAuthorize注解的内容都一样(连引入的包都一样)):
我们看看GBT怎么解释的:
它说,SpringSecurity内部的解析程序,实现了对 SpEL(Spring Expression Language)表达式的解析和执行逻辑,所以,注解中写的EL表达式也会被执行。你SpringSecurity注解上写的EL表达式,其实还是普通的字符串,只是,在SpringSecurity的解析程序中,判断了SpringSecurity上面的字符串是不是EL表达式的格式,如果是,那么就当EL表达式去执行,然后把返回值作为@PreAuthorize的value的值。
PreAuthorize中能支持使用and、or、not的,其实只是因为and、or、not等写法都是EL表达式的用法而已。
如果你不相信GBT的回答,你想要看源码来分析是否是这样的,可以看:https://juejin.cn/post/7100750309122637861
Spring Security 中的权限注解很神奇吗?
最近有个小伙伴在微信群里问 Spring Security 权限注解的问题:
很多时候事情就是这么巧,松哥最近在做的 tienchin 也是基于注解来处理权限问题的,所以既然大家有这个问题,咱们就一块来聊聊这个话题。
当然一些基础的知识我就不讲了,对于 Spring Security 基本用法尚不熟悉的小伙伴,可在公众号后台回复 ss,有原创的系列教程。
1. 具体用法
先来看看 Spring Security 权限注解的具体用法,如下:
PreAuthorize("@ss.hasPermi('tienchin:channel:query')") @GetMapping("/list") public TableDataInfo getChannelList() { startPage(); List<Channel> list = channelService.list(); return getDataTable(list); }类似于上面这样,意思就是说,当前用户需要具备
tienchin:channel:query权限,才能执行当前的接口方法。那么要搞明白 @PreAuthorize 注解的原理,我觉得得从两个方面入手:
- 首先明白 Spring 中提供的 SpEL。
- 其次搞明白 Spring Security 中对方法注解的处理规则。
我们一个一个来看。
2. SpEL
Spring Expression Language(简称 SpEL)是一个支持查询和操作运行时对象导航图功能的强大的表达式语言。它的语法类似于传统 EL,但提供额外的功能,最出色的就是函数调用和简单字符串的模板函数。
SpEL 给 Spring 社区提供一种简单而高效的表达式语言,一种可贯穿整个 Spring 产品组的语言。这种语言的特性基于 Spring 产品的需求而设计,这是它出现的一大特色。
在我们离不开 Spring 框架的同时,其实我们也已经离不开 SpEL 了,因为它太好用、太强大了,SpEL 在整个 Spring 家族中也处于一个非常重要的位置。但是很多时候,我们对它的只了解一个大概,其实如果你系统的学习过 SpEL,那么上面 Spring Security 那个注解其实很好理解。
我先通过一个简单的例子来和大家捋一捋 SpEL。
为了省事,我就创建一个 Spring Boot 工程来和大家演示,创建的时候不用加任何额外的依赖,就最最基础的依赖即可。
代码如下:
String expressionStr = "1 + 2"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expressionStr);expressionStr 是我们自定义的一个表达式字符串,这个字符串通过一个 ExpressionParser 对象将之解析为一个 Expression,接下来就可以执行这个 exp 了。
执行的时候有两种方式,对于我们上面这种不带任何额外变量的,我们可以直接执行,直接执行的方式如下:
Object value = exp.getValue(); System.out.println(value.toString());这个打印结果为 3。
我记得之前有个小伙伴在群里问想执行一个字符串表达式,但是不知道怎么办,js 中有 eval 函数很方便,我们 Java 中也有 SpEL,一样也很方便。
不过很多时候,我们要执行的表达式可能比较复杂,这时候上面这种调用方式就不太够用了。
此时我们可以为要调用的表达式设置一个上下文环境,这个时候就会用到 EvaluationContext 或者它的子类,如下:
StandardEvaluationContext context = new StandardEvaluationContext(); System.out.println(exp.getValue(context));当然上面这个表达式不需要设置上下文环境,我举一个需要设置上下文环境的例子。
例如我现在有一个 User 类,如下:
public class User { private Integer id; private String username; private String address; //省略 getter/setter }现在我的表达式是这样:
String expression = "#user.username"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expression); StandardEvaluationContext ctx = new StandardEvaluationContext(); User user = new User(); user.setAddress("广州"); user.setUsername("javaboy"); user.setId(99); ctx.setVariable("user", user); String value = exp.getValue(ctx, String.class); System.out.println("value = " + value);这个表达式就表示获取 user 对象的 username 属性。将来创建一个 user 对象,放到 StandardEvaluationContext 中,并基于此对象执行表达式,就可以打印出来想要的结果。
如果我们将 user 对象设置为 rootObject,那么表达式中就不需要 user 了,如下:
String expression = "username"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expression); StandardEvaluationContext ctx = new StandardEvaluationContext(); User user = new User(); user.setAddress("广州"); user.setUsername("javaboy"); user.setId(99); ctx.setRootObject(user); String value = exp.getValue(ctx, String.class); System.out.println("value = " + value);表达式就一个 username 字符串,将来执行的时候,会自动从 user 中找到 username 的值并返回。
当然表达式也可以是方法,例如我在 User 类中添加如下两个方法:
public String sayHello(Integer age) { return "hello " + username + ";age=" + age; } public String sayHello() { return "hello " + username; }我们就可以通过表达式调用这两个方法,如下:
调用有参的 sayHello:
String expression = "sayHello(99)"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expression); StandardEvaluationContext ctx = new StandardEvaluationContext(); User user = new User(); user.setAddress("广州"); user.setUsername("javaboy"); user.setId(99); ctx.setRootObject(user); String value = exp.getValue(ctx, String.class); System.out.println("value = " + value);就直接写方法名然后执行就行了。
调用无参的 sayHello:
String expression = "sayHello"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expression); StandardEvaluationContext ctx = new StandardEvaluationContext(); User user = new User(); user.setAddress("广州"); user.setUsername("javaboy"); user.setId(99); ctx.setRootObject(user); String value = exp.getValue(ctx, String.class); System.out.println("value = " + value);这些就都好懂了。
甚至,我们的表达式也可以涉及到 Spring 中的一个 Bean,例如我们向 Spring 中注册如下 Bean:
@Service("us") public class UserService { public String sayHello(String name) { return "hello " + name; } }然后通过 SpEL 表达式来调用这个名为 us 的 bean 中的 sayHello 方法,如下:
@Autowired BeanFactory beanFactory; @Test void contextLoads() { String expression = "@us.sayHello('javaboy')"; ExpressionParser parser = new SpelExpressionParser(); Expression exp = parser.parseExpression(expression); StandardEvaluationContext ctx = new StandardEvaluationContext(); ctx.setBeanResolver(new BeanFactoryResolver(beanFactory)); String value = exp.getValue(ctx, String.class); System.out.println("value = " + value); }给配置的上下文环境设置一个 bean 解析器,这个 bean 解析器会自动跟进名字从 Spring 容器中找打响应的 bean 并执行对应的方法。
当然,关于 SpEL 的玩法还有很多,我就不一一列举了。这里主要是想让小伙伴们知道,有这么个技术,方便大家理解 @PreAuthorize 注解的原理。
3. @PreAuthorize
接下来我们就回到 Spring Security 中来看 @PreAuthorize 注解。
权限的实现方式千千万,又有各种不同的权限模型,然而归结到代码上,无非两种:
- 基于 URL 地址的权限处理
- 基于方法注解的权限处理
松哥之前的 vhr 使用的是前者。
@PreAuthorize 注解当然对应的是后者。这次做的 tienchin 项目就是后者,我们来看一个例子:
@PreAuthorize("@ss.hasPermi('tienchin:channel:query')") @GetMapping("/list") public TableDataInfo getChannelList() { startPage(); List<Channel> list = channelService.list(); return getDataTable(list); }注解好说,里边的
@ss.hasPermi('tienchin:channel:query')是啥意思呢?
- ss 是一个注册在 Spring 容器中的 bean,对应的类位于
org.javaboy.tienchin.framework.web.service.PermissionService中。- 很明显,hasPermi 就是这个类中的方法。
这个 hasPermi 方法的逻辑其实很简单:
public boolean hasPermi(String permission) { if (StringUtils.isEmpty(permission)) { return false; } LoginUser loginUser = SecurityUtils.getLoginUser(); if (StringUtils.isNull(loginUser) || CollectionUtils.isEmpty(loginUser.getPermissions())) { return false; } return hasPermissions(loginUser.getPermissions(), permission); } private boolean hasPermissions(Set<String> permissions, String permission) { return permissions.contains(ALL_PERMISSION) || permissions.contains(StringUtils.trim(permission)); }这个判断逻辑很简单,就是获取到当前登录的用户,判断当前登录用户的权限集合中是否具备当前请求所需要的权限。具体的判断逻辑没啥好说的,就是看集合中是否存在某个字符串。
那么这个方法是在哪里调用的呢?
大家知道,Spring Security 中处理权限的过滤器是 FilterSecurityInterceptor,所有的权限处理最终都会来到这个过滤器中。在这个过滤器中,将会用到各种投票器、表决器之类的工具,这里我就不细说了,之前的 Spring Security 系列教程都有详细介绍。
在投票器中,我们可以看到专门处理 @PreAuthorize 注解的类 PreInvocationAuthorizationAdviceVoter,我们来看下他里边的核心方法:
@Override public int vote(Authentication authentication, MethodInvocation method, Collection<ConfigAttribute> attributes) { PreInvocationAttribute preAttr = findPreInvocationAttribute(attributes); if (preAttr == null) { return ACCESS_ABSTAIN; } return this.preAdvice.before(authentication, method, preAttr) ? ACCESS_GRANTED : ACCESS_DENIED; }框架的源码写的就是好,你一看名字就知道他想干嘛了!这里就进入到最后一句,调用了一个 Advice 中到前置通知,来判断权限是否满足:
public boolean before(Authentication authentication, MethodInvocation mi, PreInvocationAttribute attr) { PreInvocationExpressionAttribute preAttr = (PreInvocationExpressionAttribute) attr; EvaluationContext ctx = this.expressionHandler.createEvaluationContext(authentication, mi); Expression preFilter = preAttr.getFilterExpression(); Expression preAuthorize = preAttr.getAuthorizeExpression(); if (preFilter != null) { Object filterTarget = findFilterTarget(preAttr.getFilterTarget(), ctx, mi); this.expressionHandler.filter(filterTarget, preFilter, ctx); } return (preAuthorize != null) ? ExpressionUtils.evaluateAsBoolean(preAuthorize, ctx) : true; }现在,当你看到这个 before 方法的时候,应该会觉得比较熟悉了吧。
- 首先获取到 preAttr 对象,这个对象里边其实就保存着你 @PreAuthorize 注解中的内容。
- 接下来跟进当前登录用户信息 authentication 创建一个上下文对象,此时创建出来的上下文对象中就包含了当前用户具备哪些权限。
- 获取过滤器(我们这个项目中无)。
- 获取到权限注解。
- 最后执行表达式,去查看当前用户权限中是否包含请求所需要的权限。
作者:江南一点雨
链接:https://juejin.cn/post/7100750309122637861
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。PreAuthorize中也支持使用他的一些内置方法,关键代码在于DefaultMethodSecurityExpressionHandler中(源码可以看https://blog.csdn.net/python15397/article/details/129268249解析,但是太麻烦了,反正你就理解为Security内部设计了在PreAuthorize内写Security内置的方法也可以被解析执行就行了),也是因为他解析程序中会去解析你写的字符串是不是他内部定义的方法,如果是,那么就去使用那个方法的执行结果作为PreAuthorize的value,这种直接写Security内置方法的写法,我不知道是不是符合EL表达式,反正Security解析程序能解析这些他内置的方法。
SpringSecurity的内置方法:
ok,不深度了解了。


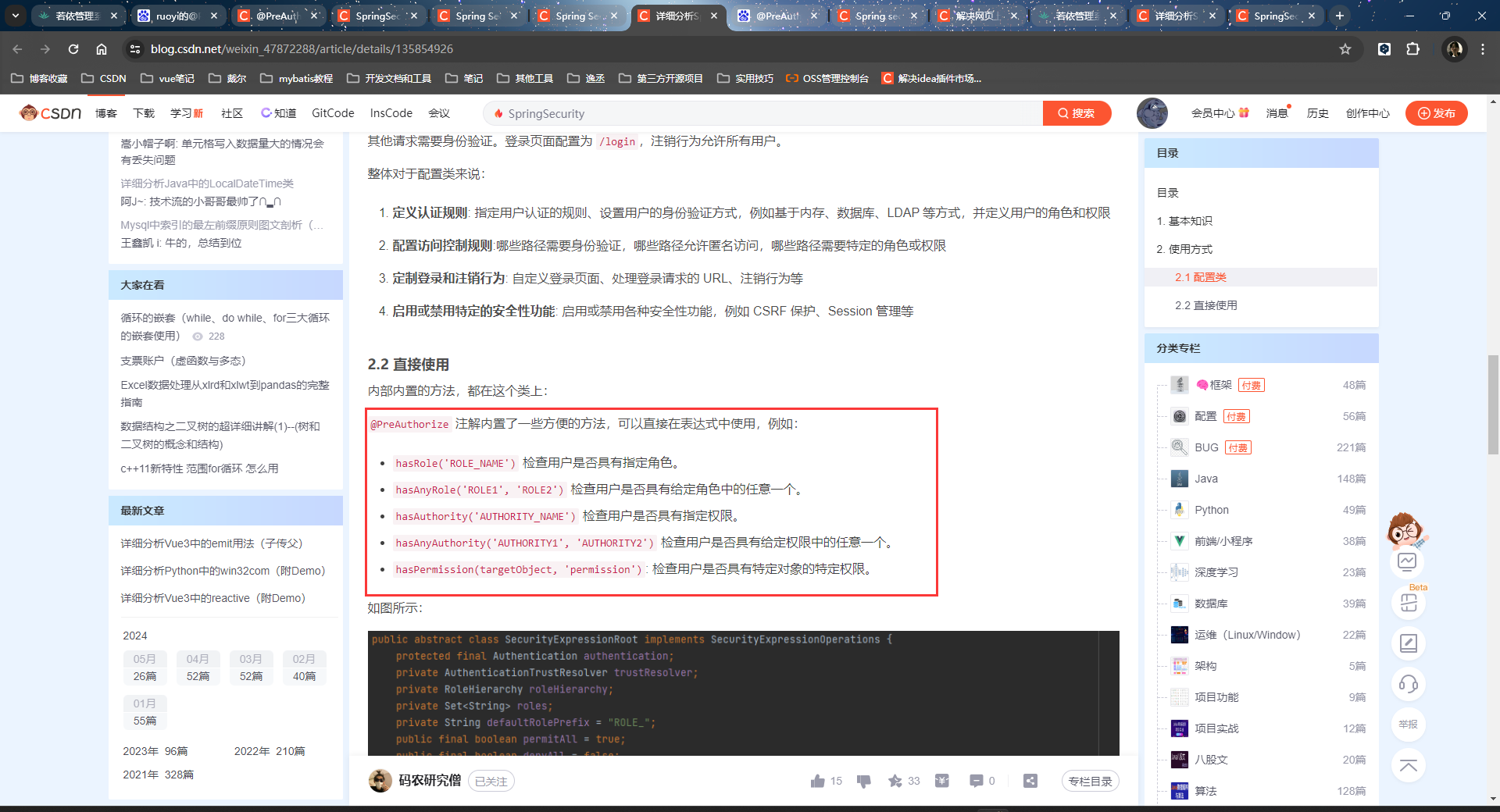
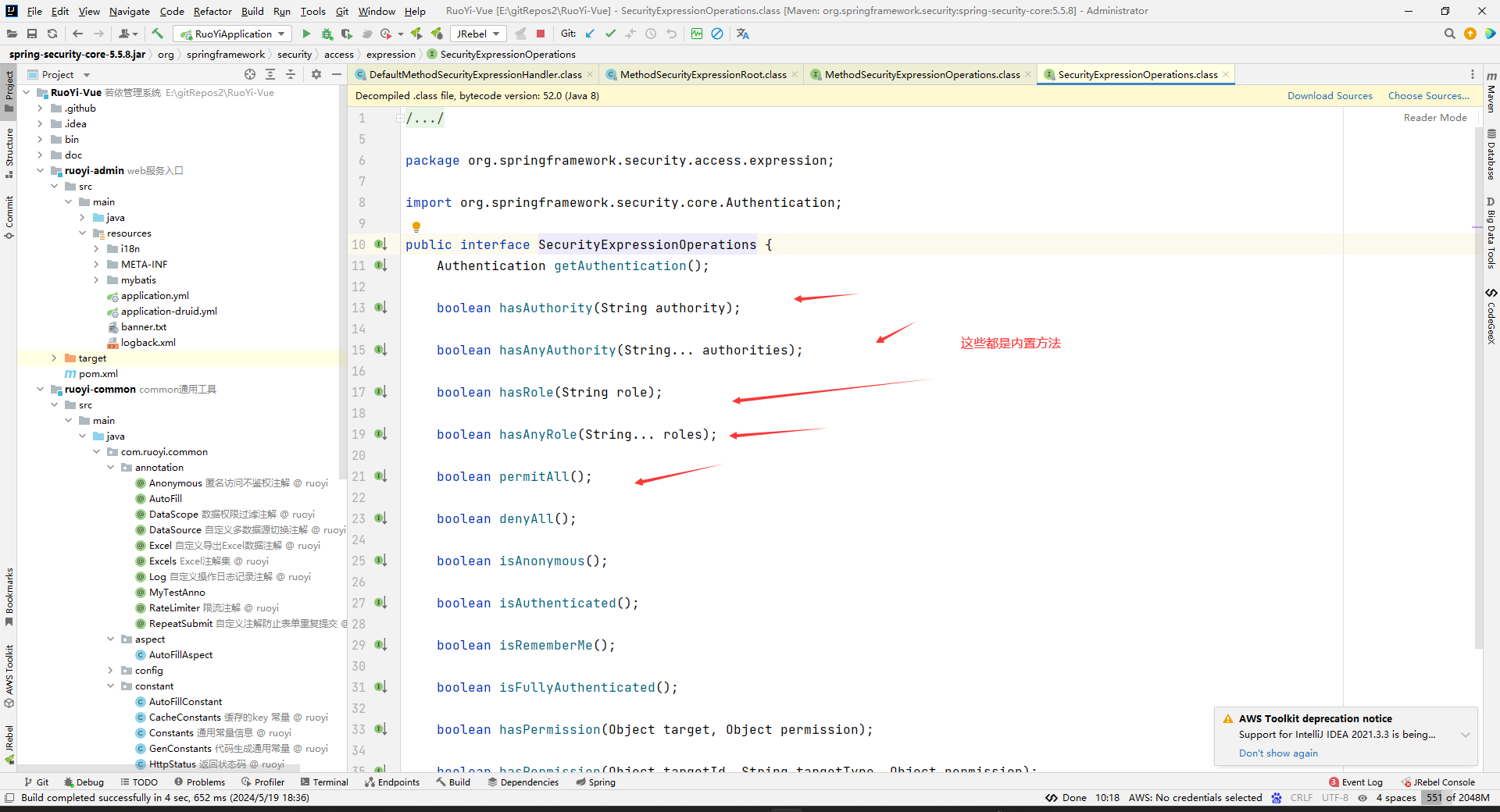
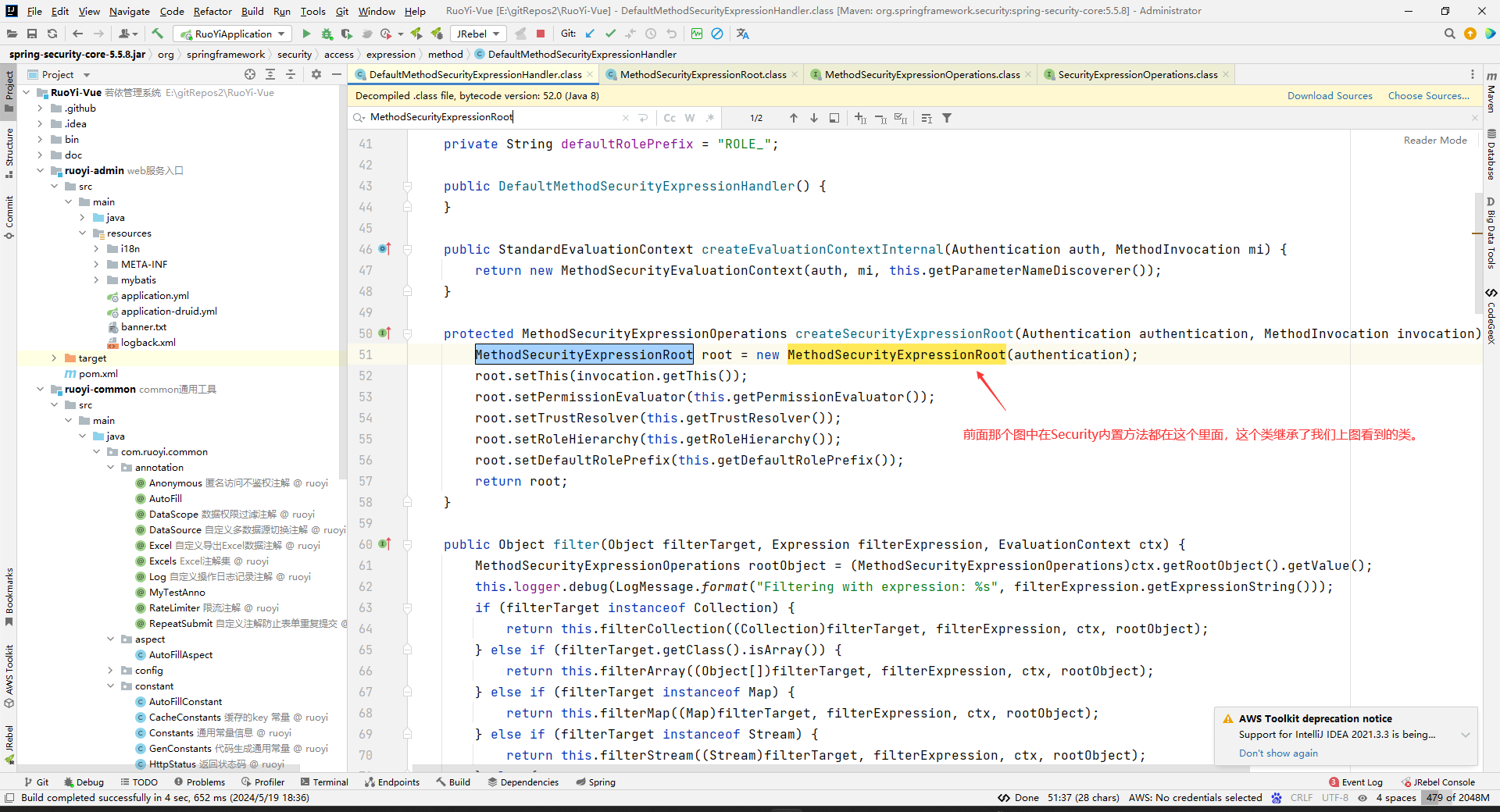
其实上面SpringSecurity内部怎么解析PreAuthorize注解中的字符串都不重要,我们只要知道,PreAuthorize注解中可以写Security内部的方法字符串或者EL表达式,都是因为他的解析程序给用户设计了这种写法而已。用户只要按这个格式来写表达式就行了,具体怎么解析的细节不用知道,只要知道我们这样写能达到的一个效果是什么就行了。
不管我们注解中写任何值也只是一个普通的字符信息,当然这句话的前提是注解中这个属性的返回值是String的哈,这个注解的这个属性返回值是枚举类型,那么你只能给一个枚举类型
比如下面这样:
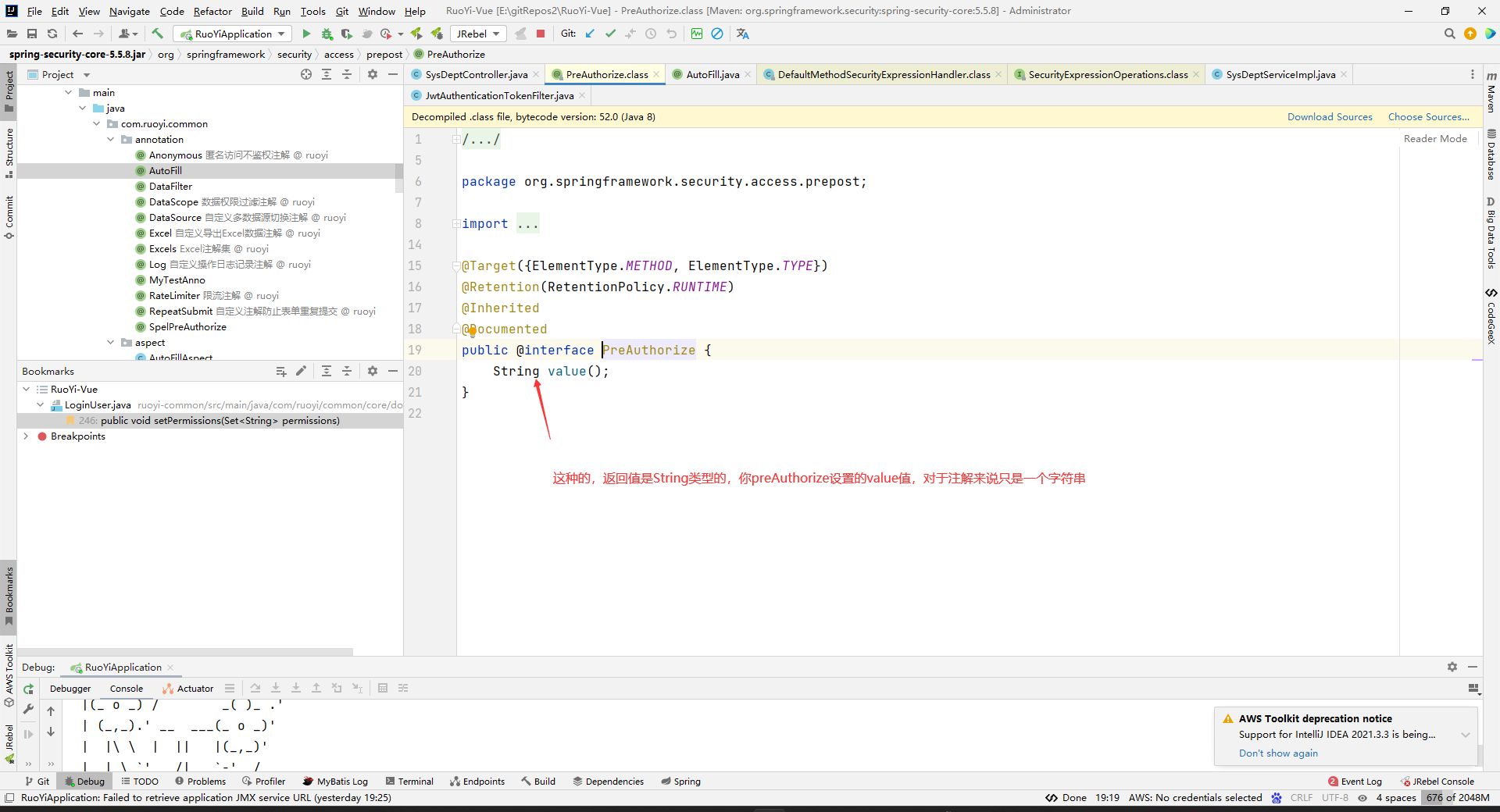
注解只能传递信息,他不能做什么,只是传递一个普通的数据而已,如果没有解析程序注解没有任何作用,上面的@PreAuthorize注解中我们写的字符串能被当做EL表达式解析全是因为解析程序特别设计的原因。注解能给与的只是传递信息而已,传递信息给解析程序。注解和注释的区别就是:注解是告诉程序一个信息的,注解的信息是可以被解析程序使用的,这些信息能产生什么作用全靠解析程序写的情况。而注释只是告诉开发者某些信息的,程序是不能使用注释信息的。
这里插入一下,简单介绍一下自定义注解中使用EL表达式,并且解析的时候去识别并使用EL表达式去执行得到对应的值。
可以看:https://blog.csdn.net/weixin_50117915/article/details/134090078
AOP注解解析EL表达式
有时候在写自定义注解时需要获取到方法上的参数,虽然要获取的参数都是同一个,但是可能因为入参的不同,数据结构的不同,从而导致不能准确的获取到,这时候我们可以通过spel表达式来获取。
spel:Spring Expression Language,这是一个强大的表达式,我们这里只用上了最简单的一种,其他的用法有兴趣的可以自己在网上查找资料。
创建注解
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface DataFilter { String value(); }编写aop
@Aspect @Component public class DataFilterAop { /** * 监控这个注解 */ @Pointcut("@annotation(club.gggd.demo.anno.DataFilter)") public void pointCut() { } /** * 方法执行前 * @param joinPoint */ @Before("pointCut()") public void doBefore(JoinPoint joinPoint) { // 获取方法 MethodSignature signature = (MethodSignature) joinPoint.getSignature(); Method method = signature.getMethod(); // 获取注解 DataFilter annotation = method.getAnnotation(DataFilter.class); String value = annotation.value();// 是一个EL表达式 // 创建 SpEL 上下文 StandardEvaluationContext context = new StandardEvaluationContext(); // 设置方法参数作为变量 Object[] args = joinPoint.getArgs(); String[] parameterNames = signature.getParameterNames(); for (int i = 0; i < args.length; i++) { // 将参数放入上下文。 context.setVariable(parameterNames[i], args[i]);// 这行代码的作用是将方法的参数名作为变量名,将方法的参数值作为变量值,存储到 StandardEvaluationContext 上下文中。 } // 解析 EL 表达式 ExpressionParser parser = new SpelExpressionParser(); Expression expression = parser.parseExpression(value);// 这行代码使用 SpelExpressionParser 对象 parser 解析传入的 value 字符串,这个字符串通常是一个 SpEL 表达式。SpEL 表达式是一种类似于${}符号的表达式语言,可以在运行时动态计算和处理表达式,通常用于配置文件、注解或者动态指定条件逻辑等场景。 Object result = expression.getValue(context);// 这行代码执行已经解析过的 SpEL 表达式,并传入上下文 context,以便表达式计算时可以引用上下文中的变量。执行结果会被赋值给 result 对象,这个对象的类型是 Object,表示可以存储任意类型的结果。 // 处理解析结果 System.out.println("解析到的结果为: " + result); } }在service层编写方法
@Override // 注意:一定要在前面加 # 号,这个是el表达式的固定格式 @DataFilter(value = "#admin.name") public int add(Admin admin, String table) { return mapper.insert(admin); }执行
解析到的结果为: zhangsan额外内容
@Override // 当然也可以直接获取参数 @DataFilter(value = "#table") public int add(Admin admin, String table) { return mapper.insert(admin); }
上面是摘录,下面我自己的实践:
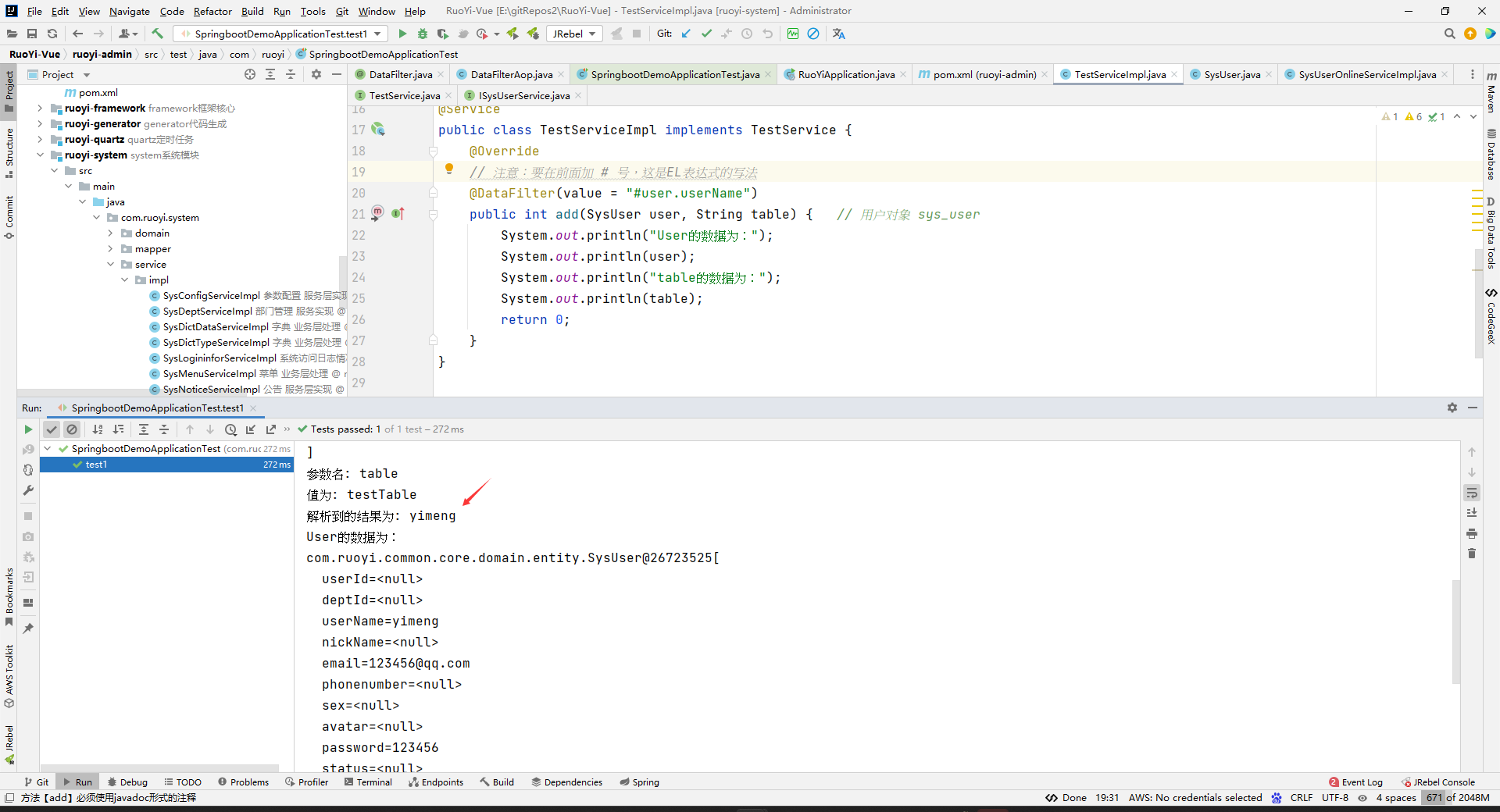
package com.ruoyi; import com.ruoyi.common.core.domain.entity.SysUser; import com.ruoyi.system.service.TestService; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import javax.annotation.Resource; /** * @Author yimeng * @Date 2024/5/21 22:47 * @PackageName:PACKAGE_NAME * @ClassName: com.ruoyi.SpringbootDemoApplicationTest * @Description: TODO * @Version 1.0 */ @RunWith(SpringRunner.class) @SpringBootTest(classes = RuoYiApplication.class) public class SpringbootDemoApplicationTest { @Resource private TestService testService; @Test public void test1() { SysUser sysUser=new SysUser(); sysUser.setUserName("yimeng"); sysUser.setPassword("123456"); sysUser.setEmail("123456@qq.com"); testService.add(sysUser,"testTable"); } }package com.ruoyi.system.service; import com.ruoyi.common.core.domain.entity.SysUser; /** * @Author yimeng * @Date 2024/5/21 22:34 * @PackageName:com.ruoyi.system.service * @ClassName: TestService * @Description: TODO * @Version 1.0 */ public interface TestService { int add(SysUser user, String table); }package com.ruoyi.system.service.impl; import com.ruoyi.common.annotation.DataFilter; import com.ruoyi.common.core.domain.entity.SysUser; import com.ruoyi.system.service.TestService; import org.springframework.stereotype.Service; /** * @Author yimeng * @Date 2024/5/21 22:34 * @PackageName:com.ruoyi.system.service.impl * @ClassName: TestServiceImpl * @Description: TODO * @Version 1.0 */ @Service public class TestServiceImpl implements TestService { @Override // 注意:要在前面加 # 号,这是EL表达式的写法 @DataFilter(value = "#user.userName") public int add(SysUser user, String table) { System.out.println("User的数据为:"); System.out.println(user); System.out.println("table的数据为:"); System.out.println(table); return 0; } }package com.ruoyi.common.annotation; import java.lang.annotation.*; /** * @Author yimeng * @Date 2024/5/21 22:31 * @PackageName:com.ruoyi.common.annotation * @ClassName: DataFilter * @Description: TODO * @Version 1.0 */ @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface DataFilter { String value(); }package com.ruoyi.common.aspect; import com.ruoyi.common.annotation.DataFilter; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.aspectj.lang.annotation.Pointcut; import org.aspectj.lang.reflect.MethodSignature; import org.springframework.expression.Expression; import org.springframework.expression.ExpressionParser; import org.springframework.expression.spel.standard.SpelExpressionParser; import org.springframework.expression.spel.support.StandardEvaluationContext; import org.springframework.stereotype.Component; import java.lang.reflect.Method; /** * @Author yimeng * @Date 2024/5/21 22:32 * @PackageName:com.ruoyi.common.aspect * @ClassName: DataFilterAop * @Description: TODO * @Version 1.0 */ @Aspect @Component public class DataFilterAop { /** * 监控这个注解 */ @Pointcut("@annotation(com.ruoyi.common.annotation.DataFilter)") public void pointCut() { } /** * 方法执行前 * @param joinPoint */ @Before("pointCut()") public void doBefore(JoinPoint joinPoint) { // 获取方法 MethodSignature signature = (MethodSignature) joinPoint.getSignature(); Method method = signature.getMethod(); // 获取注解 DataFilter annotation = method.getAnnotation(DataFilter.class); String value = annotation.value(); // 创建 SpEL 上下文 StandardEvaluationContext context = new StandardEvaluationContext(); // 设置方法参数作为变量 Object[] args = joinPoint.getArgs(); String[] parameterNames = signature.getParameterNames(); for (int i = 0; i < args.length; i++) { System.out.println("参数名: " + parameterNames[i]); System.out.println("值为: " + args[i]); // 将参数放入上下文 context.setVariable(parameterNames[i], args[i]);// 这行代码的作用是将方法的参数名作为变量名,将方法的参数值作为变量值,存储到 StandardEvaluationContext 上下文中。 } // 解析 EL 表达式 ExpressionParser parser = new SpelExpressionParser(); Expression expression = parser.parseExpression(value);// 这行代码使用 SpelExpressionParser 对象 parser 解析传入的 value 字符串,这个字符串通常是一个 SpEL 表达式。SpEL 表达式是一种类似于${}符号的表达式语言,可以在运行时动态计算和处理表达式,通常用于配置文件、注解或者动态指定条件逻辑等场景。 Object result = expression.getValue(context);// 这行代码执行已经解析过的 SpEL 表达式,并传入上下文 context,以便表达式计算时可以引用上下文中的变量。执行结果会被赋值给 result 对象,这个对象的类型是 Object,表示可以存储任意类型的结果。 // 处理解析结果 System.out.println("解析到的结果为: " + result); } }输出结果为:
参数名: user 值为: com.ruoyi.common.core.domain.entity.SysUser@33d08a24[ userId=<null> deptId=<null> userName=yimeng nickName=<null> email=123456@qq.com phonenumber=<null> sex=<null> avatar=<null> password=123456 status=<null> delFlag=<null> loginIp=<null> loginDate=<null> createBy=<null> createTime=<null> updateBy=<null> updateTime=<null> remark=<null> dept=<null> ] 参数名: table 值为: testTable 解析到的结果为: yimeng User的数据为: com.ruoyi.common.core.domain.entity.SysUser@33d08a24[ userId=<null> deptId=<null> userName=yimeng nickName=<null> email=123456@qq.com phonenumber=<null> sex=<null> avatar=<null> password=123456 status=<null> delFlag=<null> loginIp=<null> loginDate=<null> createBy=<null> createTime=<null> updateBy=<null> updateTime=<null> remark=<null> dept=<null> ] table的数据为: testTable
context.setVariable(parameterNames[i], args[i]);相当于是把某个占位符对应什么值给记录了。比如,第一个参数名为:user,值为: com.ruoyi.common.core.domain.entity.SysUser@33d08a24[……]。所以值将会被对应到#user.userName中的user去,然后user.userName就是相当于是拿SysUser对象中的userName属性。所以相当于EL表达式中的占位符#user.userName被这个SysUser中的userName替代了。然后,因为传过来的SysUser中的userName是yimeng,所以解析到的值为yimeng。
如果上面的EL表达式为:
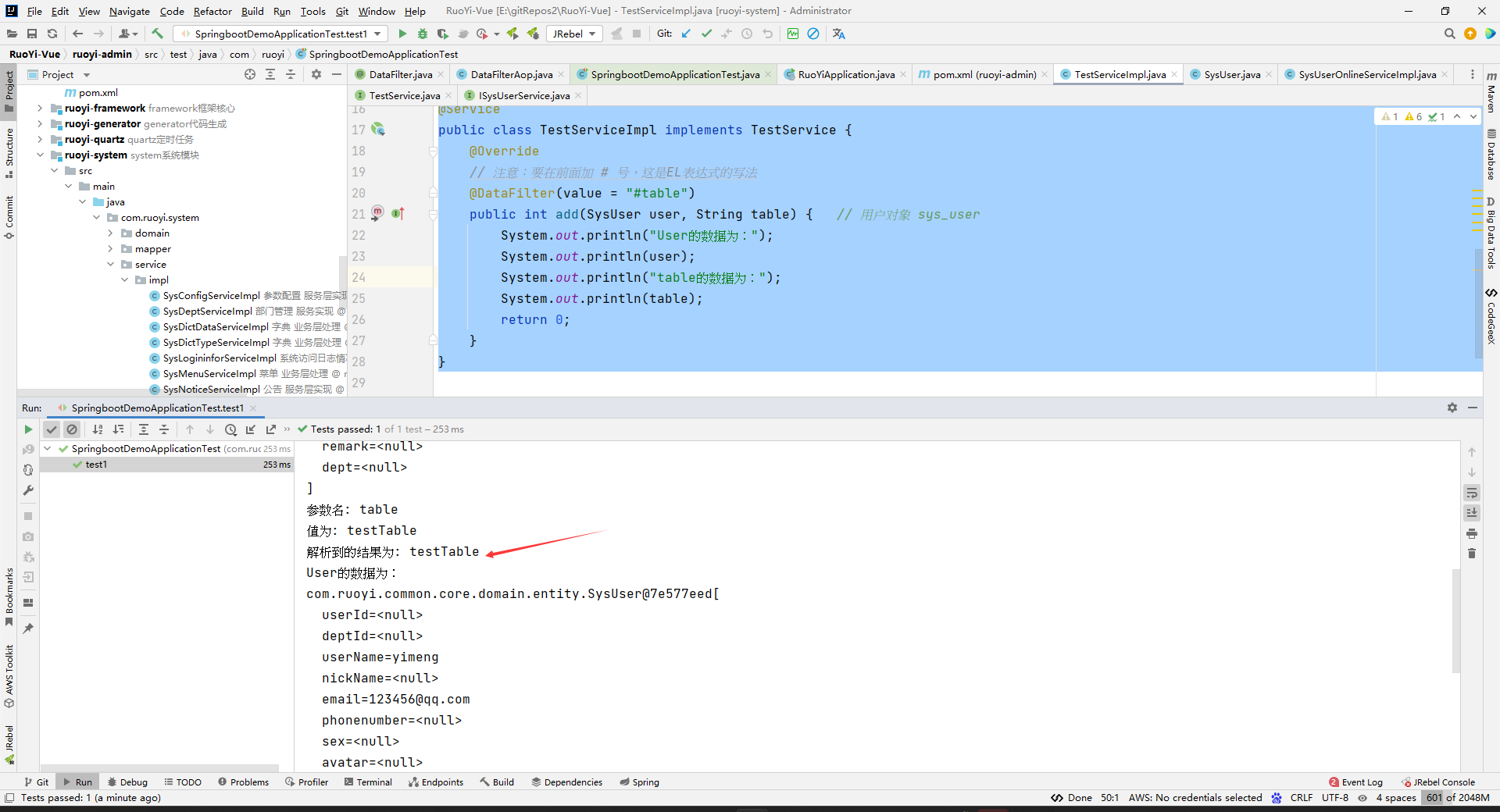
package com.ruoyi.system.service.impl; import com.ruoyi.common.annotation.DataFilter; import com.ruoyi.common.core.domain.entity.SysUser; import com.ruoyi.system.service.TestService; import org.springframework.stereotype.Service; /** * @Author yimeng * @Date 2024/5/21 22:34 * @PackageName:com.ruoyi.system.service.impl * @ClassName: TestServiceImpl * @Description: TODO * @Version 1.0 */ @Service public class TestServiceImpl implements TestService { @Override // 注意:要在前面加 # 号,这是EL表达式的写法 @DataFilter(value = "#table") public int add(SysUser user, String table) { System.out.println("User的数据为:"); System.out.println(user); System.out.println("table的数据为:"); System.out.println(table); return 0; } }那么执行的结果就是:
参数名: user 值为: com.ruoyi.common.core.domain.entity.SysUser@7e577eed[ userId=<null> deptId=<null> userName=yimeng nickName=<null> email=123456@qq.com phonenumber=<null> sex=<null> avatar=<null> password=123456 status=<null> delFlag=<null> loginIp=<null> loginDate=<null> createBy=<null> createTime=<null> updateBy=<null> updateTime=<null> remark=<null> dept=<null> ] 参数名: table 值为: testTable 解析到的结果为: testTable User的数据为: com.ruoyi.common.core.domain.entity.SysUser@7e577eed[ userId=<null> deptId=<null> userName=yimeng nickName=<null> email=123456@qq.com phonenumber=<null> sex=<null> avatar=<null> password=123456 status=<null> delFlag=<null> loginIp=<null> loginDate=<null> createBy=<null> createTime=<null> updateBy=<null> updateTime=<null> remark=<null> dept=<null> ] table的数据为: testTable
原理也是和上面一样的。所以这里不说了。
下面介绍一下EL表达式写spring注入的Bean的方法。
这里我们模拟自己写一个@PreAuthorize注解。
做法如下:
定义@SpelPreAuthorize注解,对标@PreAuthorize
package com.ruoyi.common.annotation; import java.lang.annotation.*; /** * @Author yimeng * @Date 2024/5/22 21:39 * @PackageName:com.ruoyi.common.annotation * @ClassName: SpelPreAuthorize * @Description: TODO * @Version 1.0 */ @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface SpelPreAuthorize { String value() default ""; }定义切面
package com.ruoyi.common.aspect; import com.ruoyi.common.annotation.SpelPreAuthorize; import org.aspectj.lang.JoinPoint; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Before; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.support.DefaultListableBeanFactory; import org.springframework.context.expression.BeanFactoryResolver; import org.springframework.expression.Expression; import org.springframework.expression.spel.standard.SpelExpressionParser; import org.springframework.expression.spel.support.StandardEvaluationContext; import org.springframework.stereotype.Component; /** * @Author yimeng * @Date 2024/5/22 21:42 * @PackageName:com.ruoyi.common.aspect * @ClassName: SpelPreAuthorizeAspect * @Description: TODO * @Version 1.0 */ @Component @Aspect public class SpelPreAuthorizeAspect { /** * 注入spring bean 工厂 */ @Autowired private DefaultListableBeanFactory defaultListableBeanFactory; @Before("@annotation(spelPreAuthorize)") public void perAuthorize(JoinPoint point, SpelPreAuthorize spelPreAuthorize) { String permission = spelPreAuthorize.value(); // 实例化spel表达式解析器 SpelExpressionParser spelExpressionParser = new SpelExpressionParser(); // 解析表达式内容 Expression expression = spelExpressionParser.parseExpression(permission); // 声明StandardEvaluationContext对象,用于设置上下文对象。 // 这行代码创建了一个 StandardEvaluationContext 对象 context,用于设置 SpEL 表达式的计算环境。这个上下文对象可以用来存储变量、函数等信息,以便在表达式计算时引用。 StandardEvaluationContext context = new StandardEvaluationContext(); // 这行代码设置了一个 BeanFactoryResolver 对象作为 context 的 Bean 解析器。这个解析器会根据传入的 DefaultListableBeanFactory 对象 defaultListableBeanFactory 来解析 SpEL 表达式中的 Bean 引用,使得表达式中可以引用 Spring 容器中的 Bean。 context.setBeanResolver(new BeanFactoryResolver(defaultListableBeanFactory)); // 这行代码执行之前解析的 SpEL 表达式 expression,并传入上下文 context,并且告诉程序期望的结果类型为 Boolean.class。这样可以计算表达式并得到一个布尔类型的结果。 Boolean result = expression.getValue(context, Boolean.class); if (!result) { throw new RuntimeException("该用户无访问权限"); } } }定义具体业务逻辑处理类
package com.ruoyi.framework.web.service; import org.springframework.stereotype.Component; import org.springframework.util.PatternMatchUtils; import java.util.Arrays; import java.util.List; /** * @Author yimeng * @Date 2024/5/22 21:41 * @PackageName:com.ruoyi.framework.web.service * @ClassName: MyPermissionService * @Description: TODO * @Version 1.0 */ @Component("mps") public class MyPermissionService { public boolean hasPermission(String permission) { // 写法一:使用List匹配 // List<String> allPermissions = Arrays.asList("user:save", "user:delete", "user:edit");// 假设这里是从数据库中获取登录用户的所有权限列表 // return allPermissions.contains(permission); // 写法二:使用通配符匹配 List<String> allPermissions = Arrays.asList("user:save", "user:delete", "user:edit");// 假设这里是从数据库中获取登录用户的所有权限列表 return allPermissions.stream().anyMatch(item -> PatternMatchUtils.simpleMatch(permission, item)); } }编写控制层代码
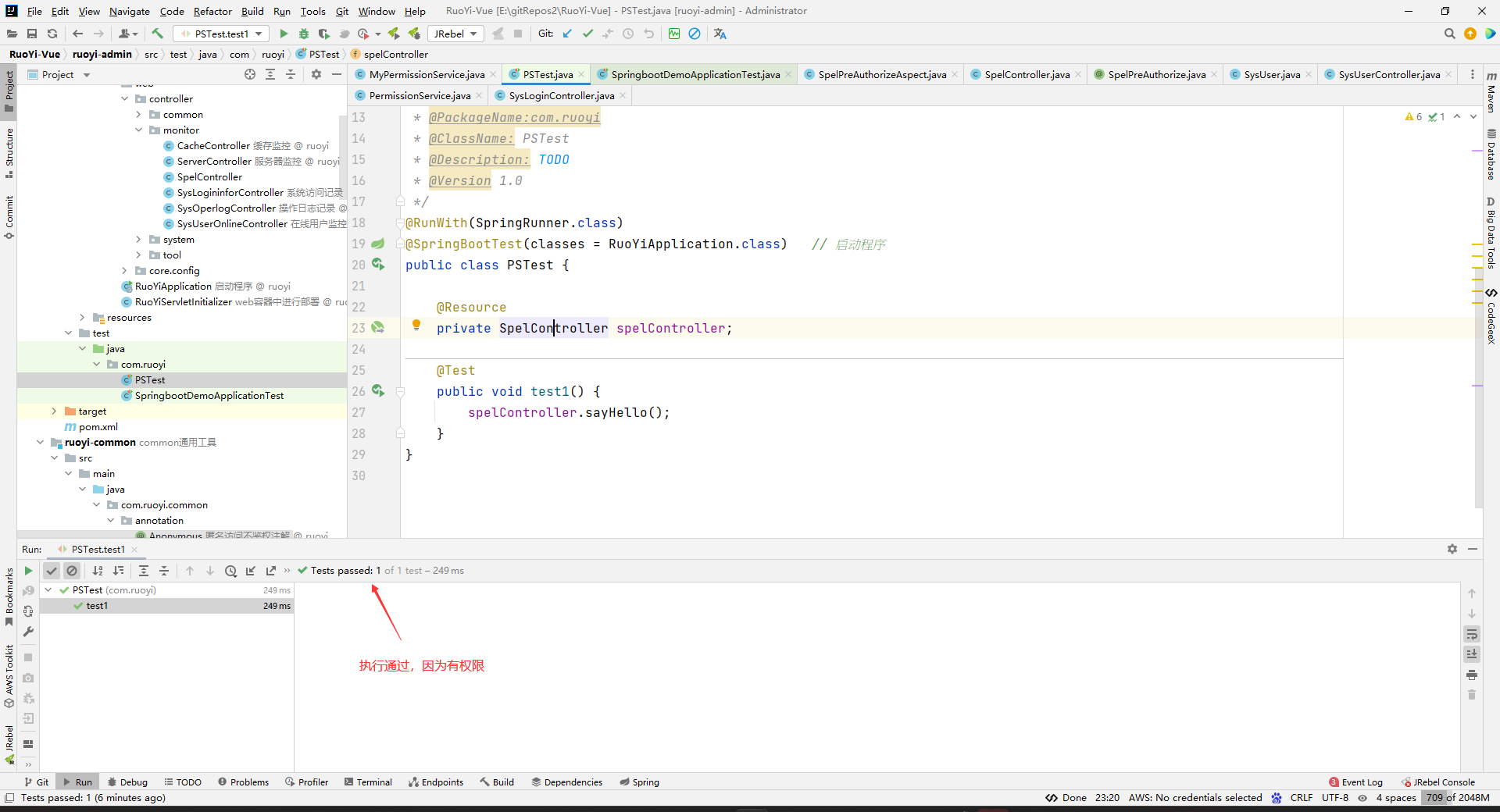
package com.ruoyi.web.controller.monitor; import com.ruoyi.common.annotation.SpelPreAuthorize; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * @Author yimeng * @Date 2024/5/22 21:45 * @PackageName:com.ruoyi.web.controller.monitor * @ClassName: SpelController * @Description: TODO * @Version 1.0 */ @RestController @RequestMapping("/spel") public class SpelController { @GetMapping("/hello") // @SpelPreAuthorize("@mps.hasPermission('user:hello')")//会返回没有权限,因为权限字符的List中没有这个user:hello,你可以理解为权限字符的List就是登录用户从数据库中获取的权限字符串 @SpelPreAuthorize("@mps.hasPermission('user:save')")// 可以执行成功 public String sayHello() { return "hello"; } }测试
package com.ruoyi; import com.ruoyi.web.controller.monitor.SpelController; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import javax.annotation.Resource; /** * @Author yimeng * @Date 2024/5/22 21:53 * @PackageName:com.ruoyi * @ClassName: PSTest * @Description: TODO * @Version 1.0 */ @RunWith(SpringRunner.class) @SpringBootTest(classes = RuoYiApplication.class) public class PSTest { @Resource private SpelController spelController; @Test public void test1() { spelController.sayHello(); } }结果:
如果使用@SpelPreAuthorize(“@mps.hasPermission(‘user:hello’)”),那么会出现没有权限。
执行结果如下:
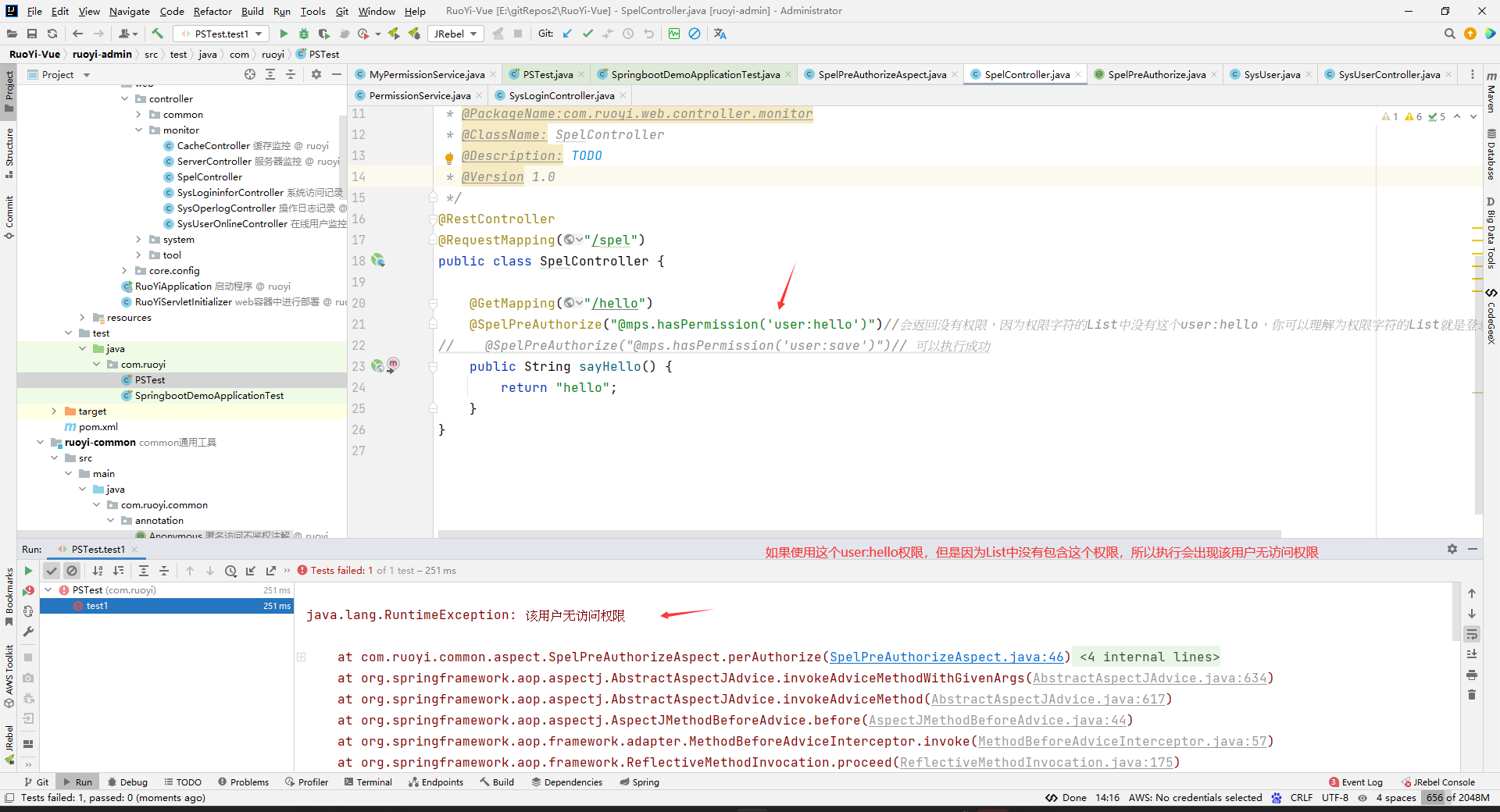
内容2
好,回到正题。前面我们刚讲的是premission变量的值可能会有哪些情况。
我们现在继续看若依做数据权限,去找到那个最关键的方法,dataScopeFilter方法(通过图中可以看到最关键的代码在于dataScopeFilter方法)。
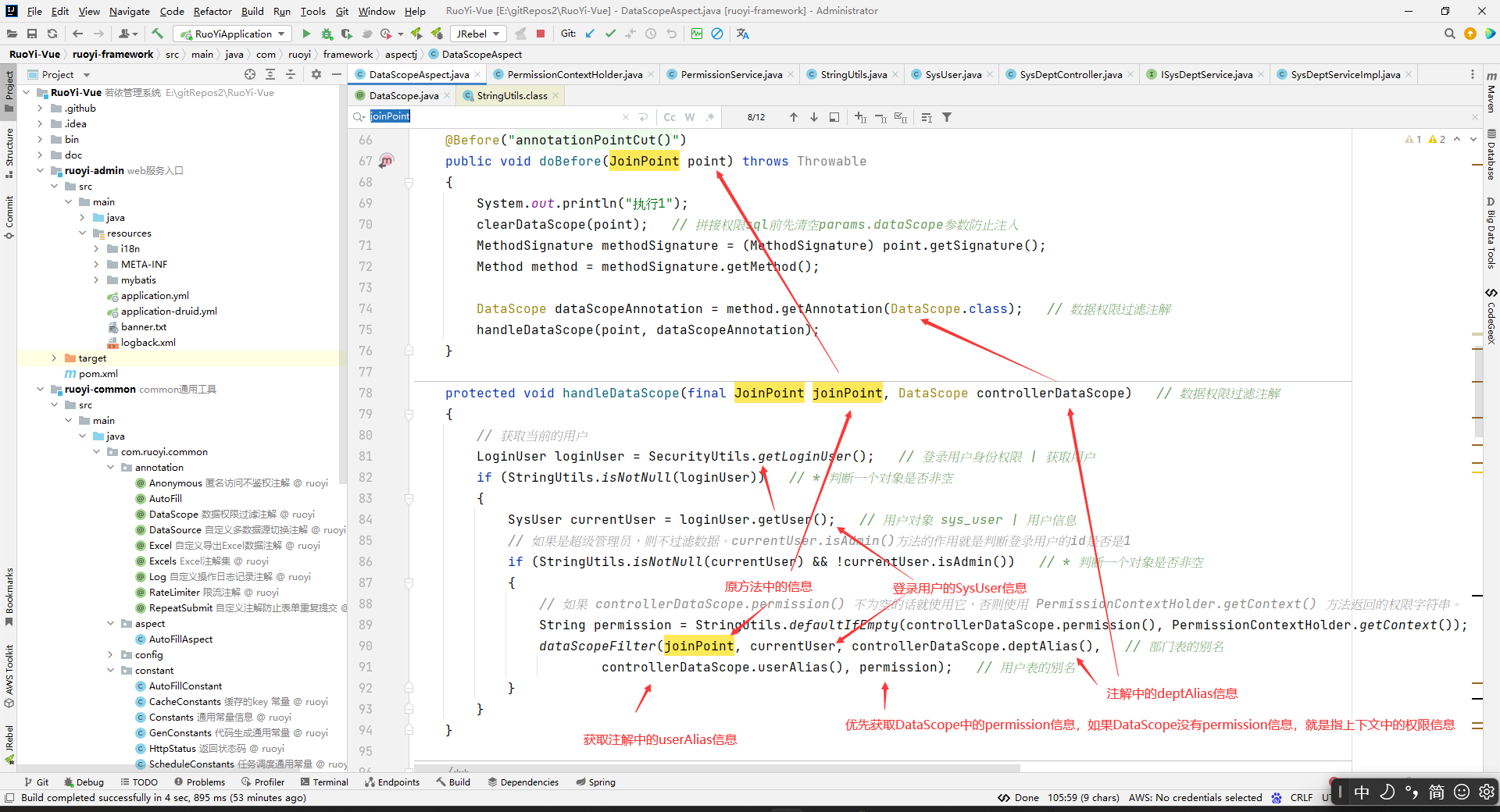
源码如下:
/**
* 数据范围过滤
*
* @param joinPoint 切点
* @param user 用户
* @param deptAlias 部门别名
* @param userAlias 用户别名
* @param permission 权限字符
*/
public static void dataScopeFilter(JoinPoint joinPoint, SysUser user, String deptAlias, String userAlias, String permission)
{
StringBuilder sqlString = new StringBuilder();
List<String> conditions = new ArrayList<String>();
for (SysRole role : user.getRoles())
{
// 获取角色的数据范围。这里我们的数据权限是和角色绑定的,用户是绑定角色的,所以我们要获取当前用户的角色,然后拿到所有权限的并集。
String dataScope = role.getDataScope();
// 为什么这么写,举一个例子。如果这个人有多个角色,其中有两个角色的数据范围都是本部门权限(只要不是自定数据权限),那么就这两个角色能看到的访问就是一样的,所以没有必要多次拼接一样的sql。所以,这里这段代码主要是为了避免重复拼接而已。除了自定义权限外,你多个角色都有设置部门数据权限,其实和一个角色设置了部门数据权限是一样的效果(全部数据权限、部门及以下数据权限、仅本人数据权限也是同样的道理,自己可以理解一下。)。
if (!DATA_SCOPE_CUSTOM.equals(dataScope) && conditions.contains(dataScope))
{
continue;
}
// 如果这里的permission是空,那么都有拼接sql的权限,因为你没有限制嘛。控制层的接口大家都可以访问,这个数据接口大家也都能访问,那么你就拼sql就行了,不限制。
// 如果角色的权限是空,那么不会限制拼接sql。相当于是没有权限限制。但是注意,如果用户只有这个空权限的角色,是那么这个用户是看不到任何菜单的。
// 如果不存在当前遍历的角色中的权限有任何一个权限和permission中的任何一个权限匹配,那么就不拼接sql。注意这个permission字符串可能是有逗号的,逗号的话,我们只要当前遍历角色的所有权限中只有有一个符合permission中逗号分隔的权限的其中一个就行了。
// 总之意思就是,你角色要有权限才能有查看这个数据。比如,你用户有一个角色数据权限是,可以看部门的DATA_SCOPE_ALL权限的,即可以看全部的数据权限,但是这个角色只有一个查看用户管理的菜单权限,没有查看部门list的权限字符,但是DataScope注解又写在查看部门list的service方法上,所以当遍历这个角色的时候,会执行continue,即不会拼接sql,你就看不到全部数据了。你这个用户还有一个角色是,可以看到用户的部门权限(即数据权限是DATA_SCOPE_DEPT),并且是有查看部门list的权限,所以,执行到这里的时候permission中就是system:dept:list,并且你的role.getPermissions()中有对应的权限,那么就会拼接对应的sql,所以就可以看到部门对应的数据。所以这个用户有上面两个角色,就只能看到它所在部门的权限了。
if (StringUtils.isNotEmpty(permission) && StringUtils.isNotEmpty(role.getPermissions())
&& !StringUtils.containsAny(role.getPermissions(), Convert.toStrArray(permission)))
{
continue;
}
// 如果有一个角色有全部权限,就直接退出。就不用拼接查询数据权限限制的sql了。
if (DATA_SCOPE_ALL.equals(dataScope))
{
// 如果有全部的,就清空之前已经拼接的sql,因为已经有全部权限了,所以不需要限制,所以清空。
sqlString = new StringBuilder();
conditions.add(dataScope);
break;
}
// 如果是自定义的数据权限,那么就看你这个角色绑定的部门角色表中的部门id列表,即,查询的时候要加上查询角色部门表的限制条件。
else if (DATA_SCOPE_CUSTOM.equals(dataScope))
{
sqlString.append(StringUtils.format(
" OR {}.dept_id IN ( SELECT dept_id FROM sys_role_dept WHERE role_id = {} ) ", deptAlias,
role.getRoleId()));
}
// 部门数据权限。上面的自定义的数据权限是可以选择某些具体部门下的,这个部门数据权限是能看到用户所在的本部门下的数据。
else if (DATA_SCOPE_DEPT.equals(dataScope))
{
sqlString.append(StringUtils.format(" OR {}.dept_id = {} ", deptAlias, user.getDeptId()));
}
// 部门及以下数据权限。可以看到本部门和本部门的下级部门的数据。部门和部门之间的父子关系是用parentId来维系的。find_in_set中存这这个部门的父级id们。下面拼接的sql意思是,找到部门表所有数据中部门id和当前用户的部门id一样的数据或者ancestors字段包含当前用户的部门id的数据。
else if (DATA_SCOPE_DEPT_AND_CHILD.equals(dataScope))
{
sqlString.append(StringUtils.format(
" OR {}.dept_id IN ( SELECT dept_id FROM sys_dept WHERE dept_id = {} or find_in_set( {} , ancestors ) )",
deptAlias, user.getDeptId(), user.getDeptId()));
}
// 仅本人数据权限。只能看到登录者自己的数据。
else if (DATA_SCOPE_SELF.equals(dataScope))
{
if (StringUtils.isNotBlank(userAlias))
{
sqlString.append(StringUtils.format(" OR {}.user_id = {} ", userAlias, user.getUserId()));
}
else
{
// 数据权限为仅本人,但是给没有userAlias别名。那么不会查询任何数据。
sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));
}
}
conditions.add(dataScope);
}
// 多角色情况下,如果所有角色都没有查看这个数据的权限,这个时候sqlString也会为空,所以要限制一下,不查询任何数据。因为dept_id=0不存在,所以可以用这个方式来让它不查询任何数据。
if (StringUtils.isEmpty(conditions))
{
sqlString.append(StringUtils.format(" OR {}.dept_id = 0 ", deptAlias));
}
// 拿到实体类。然后把数据给到param这个Map<String, Object>中去,到时候会拼接给xml中去的。
if (StringUtils.isNotBlank(sqlString.toString()))
{
// 拿到实体类
Object params = joinPoint.getArgs()[0];
if (StringUtils.isNotNull(params) && params instanceof BaseEntity)
{
BaseEntity baseEntity = (BaseEntity) params;
// 把sqlString从索引位置 4(第五个字符,因为索引从 0 开始)开始,截取到字符串的末尾。这样可以去除“ OR ”
baseEntity.getParams().put(DATA_SCOPE, " AND (" + sqlString.substring(4) + ")");
}
}
}
分析:
下面这个图片里面体现了若依的表设计也是有东西的。设计表时,应该从实际意义看表中每一个字段的意义是否都是依赖于这个表的属性的。但是这个思想应该不是叫三大范式,应该是比三大范式更加基本的原则,就是一个表中的字段至少要是和这个表的意义是搭配的,字段得是这个表代表的东西的一个属性才行。不然你任何不相干的东西都放在一个表里面吗?这是不是就很不合适,所以说这一点是最基本的一点。
当然哈,有些时候,为了少建一张中间表,我们可能还是会不按上面的基本原则走,因为多连一次表性能下降会更多嘛。直接在A表中设计一个B表的Id,虽然B表的id不是A表的任何实际意义的属性,按道理讲应该设置一个AB中间表来绑定他们之间的关系的,但是这样就需要三表连接来整个一个需要的数据了。如果设在A表中加一个B表的id,那么直接两表连接就行了,速度上会快一些。但是一般情况下,你不是A表的属性,就不应该放在A表中,比如,你一个表是user表,然后你user表中加一个海拔的这个属性,你说是不是很不合理。
下面回顾一下三大范式:
- 第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项,即列中的数据不可再分。这确保了数据的原子性,使得数据更容易管理。如果数据表中某个列有多个值时,必须拆分为不同的列。简言之,第一范式要求每一列都不可再拆分。
- 第二范式(2NF):在满足第一范式的基础上,第二范式要求表中的每一个非主键字段都必须完全依赖于主键,而不能只依赖主键的一部分(主要针对复合主键而言)。简而言之,第二范式就是在第一范式的基础上,所有列都完全依赖于主键列,以确保数据表中的每列都和主键相关,并且一张表只描述一件事情,避免数据冗余。
- 第三范式(3NF):在满足第二范式的前提下,第三范式要求表中的每一列都直接依赖于主键,而不是通过其它的非主键列来间接依赖于主键。简而言之,第三范式就是在满足2NF的基础上,任何非主键列不得传递依赖于主键。这确保了数据表中的列都和主键直接相关,进一步减少数据冗余和提高数据一致性。
通俗易懂三大范式
第一范式说的是每个字段不可再分
第二范式说的是不能存在部分依赖(不能由联合主键的部分就可以推出其他字段,必须整个联合主键才能推出其他字段)
第三范式说的是不能存在间接依赖(A(主键)→B,B→C,A→C,就是存在间接依赖),也就是说非主键字段之间不能存在依赖
能被谁推出,就依赖谁 这句话太牛逼太经典了
首先得理清楚四个概念:依赖,完全依赖,部分依赖,间接依赖
什么是依赖关系
对于这张表,学生编号+教师编号作为联合主键
由学生编号1001,可以推出学生姓名是张三
由教师编号是001,可以推出教师的姓名是王老师
这种由”一个字段的值可以推出另一个字段的值",我们说这两个字段之间有依赖关系,而且A可以推出B,A->B,则说B依赖于A,能被谁推出,就依赖谁
因为学生编号可以推出学生姓名,所以说学生姓名字段依赖于学生编号字段
教师编号可以推出教师姓名,所以说教师姓名字段依赖于教师编号字段
什么是完全依赖关系和部分依赖关系?
联合主键其实是一个集合——(教师学生编号,编号),如果必须学生编号+教师编号(即两个字段的值都必须有)才能推出学生姓名,那我们说学生姓名完全依赖于这个集合(学生编号,教师编号)。但是,这里显然只需要这个集合中的一个子集(仅仅一个学生编号)就可以推出学生姓名了,所以学生姓名这个字段是部分依赖于这个集合(教师学生编号,编号)的。
由此我们可以进行抽象总结:
假如一张表有A,B,C,D,E四个字段,而且主键是(A,B,C),D和E是非主键字段,如果必须A+B+C才能推出D,而(A,B,C)的任何一个子集都无法推出D,就可以说D完全依赖于(A,B,C),如果(A,B,C)的一个子集就可以推出D,则说D部分依赖于(A,B,C)
显然,只有联合主键才会存在完全依赖和部份依赖一说,单一主键没有这么一说。
什么是间接依赖?
假设有一个表,里面的字段是学号,姓名,系名,系大楼,
学号可以推出系名,
系名可以推出系大楼,
根据这个关系链可以由学号推出系大楼,就说系大楼字段是间接依赖于学号字段的。
有这样的关系A(主键)→B,B→C,A→C,就是存在间接依赖
但是如果不存在B→C,只有A(主键)→B,A→C就说明不存在间接依赖关系。
也就是说,不存在间接依赖的本质是:非主键之间没有依赖关系,即两个非主键字段之间不存在一个字段可以推出另一个字段的关系!!!
三大范式
当你理解完这四个概念,再看什么是三大范式,简直就是轻松的一批:
第一范式
必须规定一个字段为主键,而且每个主键都不能再分
第二范式
非主键字段必须完全依赖于主键(一般是联合主键而不是单一主键),不能部分依赖于主键
第三范式
不能有依赖传递
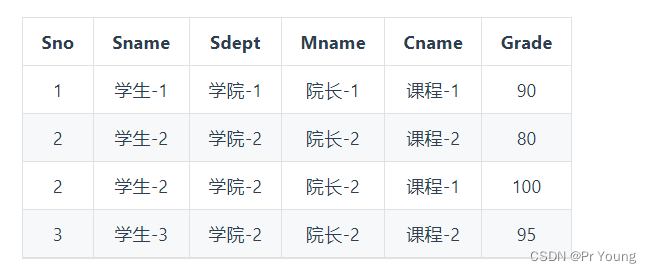
没有分解前的表:
sno学生编号和Cname课程名字组成联合主键,存在以下依赖关系:
(1) 学生编号Sno可以推出学生姓名Sname和学生所属学院Sdept,Sno -> Sname, Sdept,也就是学生姓名Sname和学生所属的学院Sdept依赖于学生编号Sno
(2)学生所属学院Sdept可以推出院长的名字Mname,Sdept -> Mname
(3)学生编号Sno+课程名字Cname两个联合主键可以推出学生成绩Grade,Sno, Cname-> Grade
所以,学生成绩Grade完全依赖于联合主键,学生姓名Sname,学生学院Sdept,院长姓名Mname部分依赖于联合主键
第二范式要求非主键字段必须完全依赖于主键(一般是联合主键而不是单一主键),不能部分依赖于主键,这里有字段部分依赖主键,所以不满足第二范式、
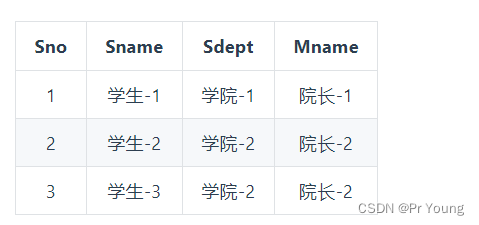
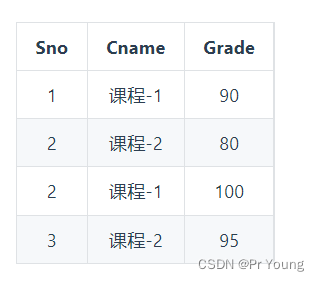
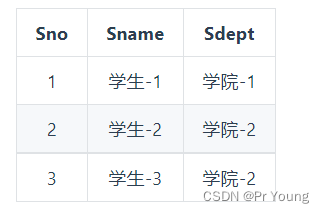
将一张表拆分成两张表:
表一的主键是学生编号Sno,表二的主键是学生编号Sno和课程姓名Cname组成的联合主键
虽然不再存在部份依赖了,但是表一中存在依赖传递,Sno -> Sdept -> Mname,也就是学生编号无法直接推出院长名字,存在依赖传递违反了第三范式,最后分解成以下两张表:
最后每张表中既不存在部分依赖,也不存在间接依赖

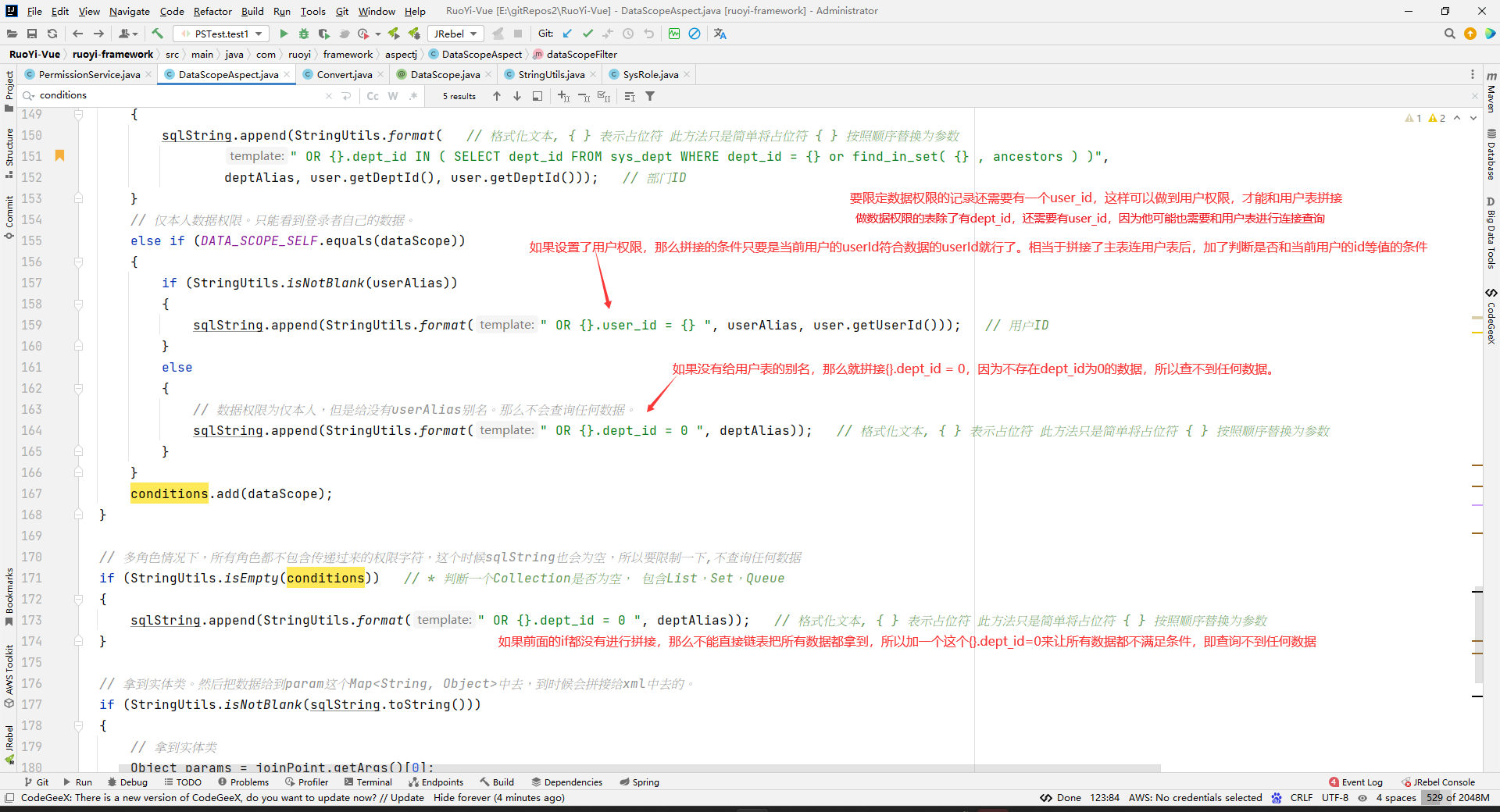
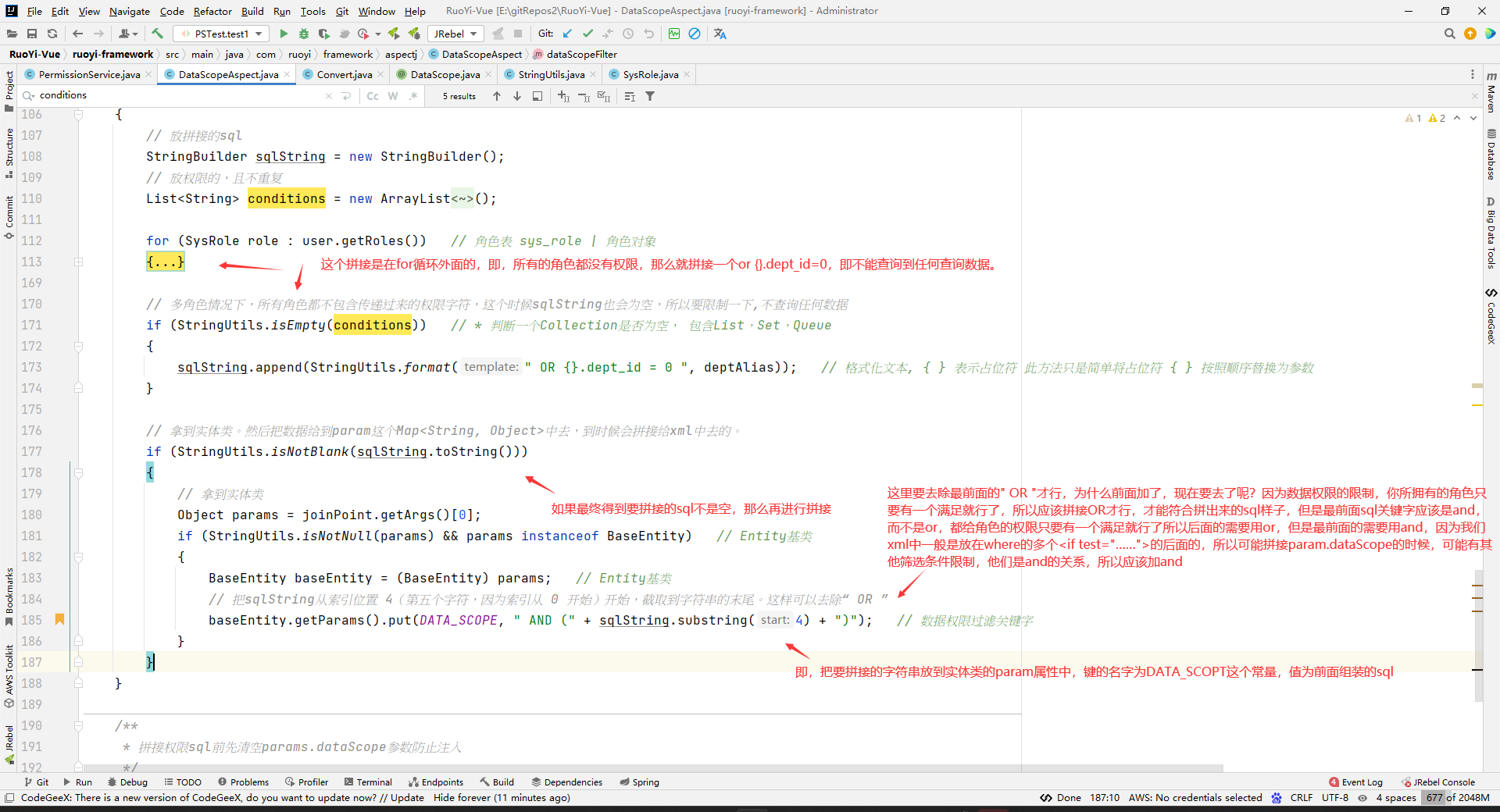
加and相当于是查询的时候多一个要满足的条件,然后and后面的拼接生成的sql,是相当于是在这个多的条件中,只要满足其中之一就可以了,相当于是多的这个条件是每一个角色能访问的数据的并集。
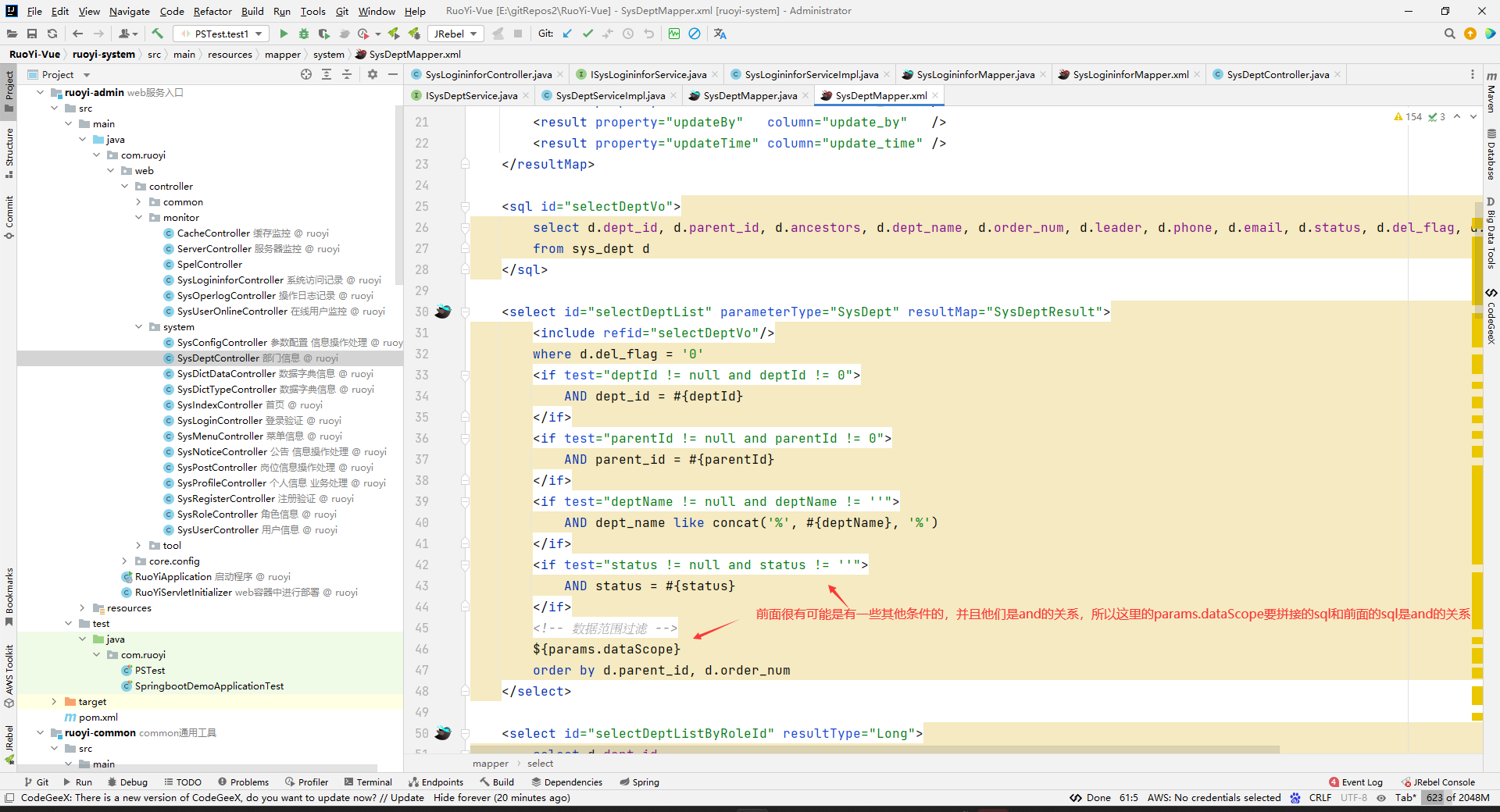
接口的权限是什么样的,怎么生成的,讲过了。要设计为有数据权限的表应该有什么字段,这些字段是怎么被用到数据权限中的,也讲过了。但是这里其实还是漏说了一个,用户有的权限是怎么看的。
即,SysUser中的权限是什么时候设置进去的。
看下面的解析若依权限就行了。
解析若依权限
先看看摘录
摘录1
登录
生产验证码
基本思路就是后端生成一个表达式,1+1=2
1+1=?@2
将1+1=?转换成图片,传给前端展示,把答案2放入redis
根据前端请求路径,以及前端项目部署的url,可以发现该请求其实是请求前端,但我们都知道图片信息是在后端生成的,所以这是怎么回事?
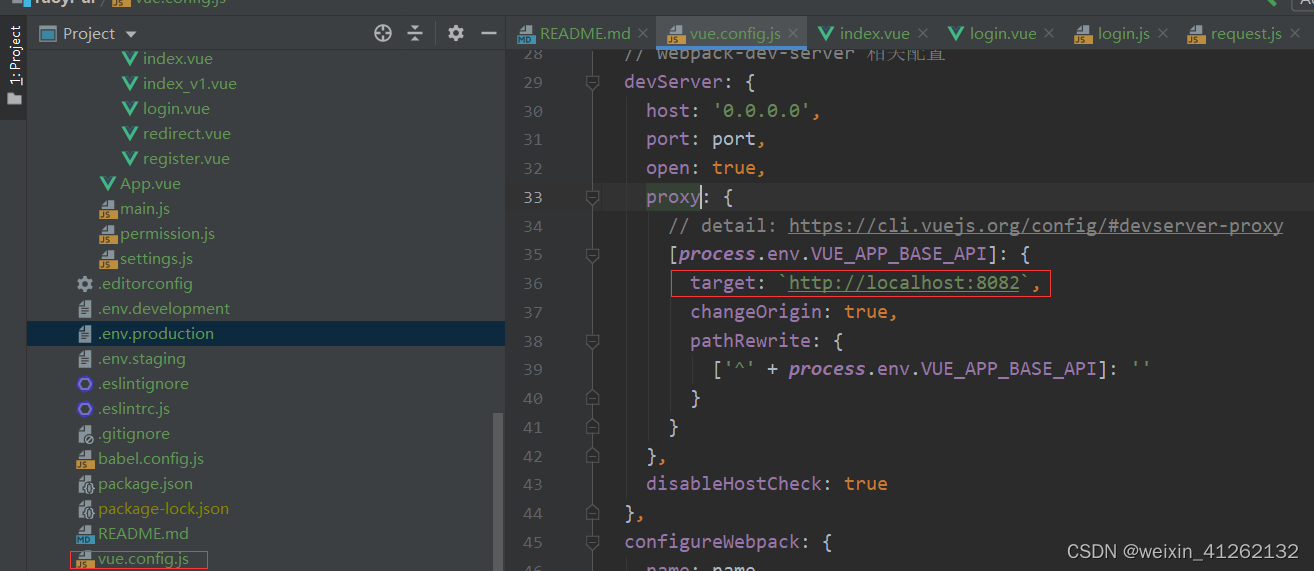
答案是这里用了反向代理,url请求前端,映射到后端,解决跨域问题,我们可以在vue.config文件查看到相关配置:
其中target是我们后端的地址。
pathRewrite指定的内容为'^/dev-api': ''(若依中你使用dev环境启动,那么process.env.VUE_APP_BASE_API就是/dev-api),这意味着当代理服务器接收到请求时,如果请求路径以/dev-api开头,则会将/dev-api替换为空字符串,即去掉/dev-api部分,形成新的路径,然后再转发请求到目标服务器http://localhost:8082。
然后我们可以看下后端代码
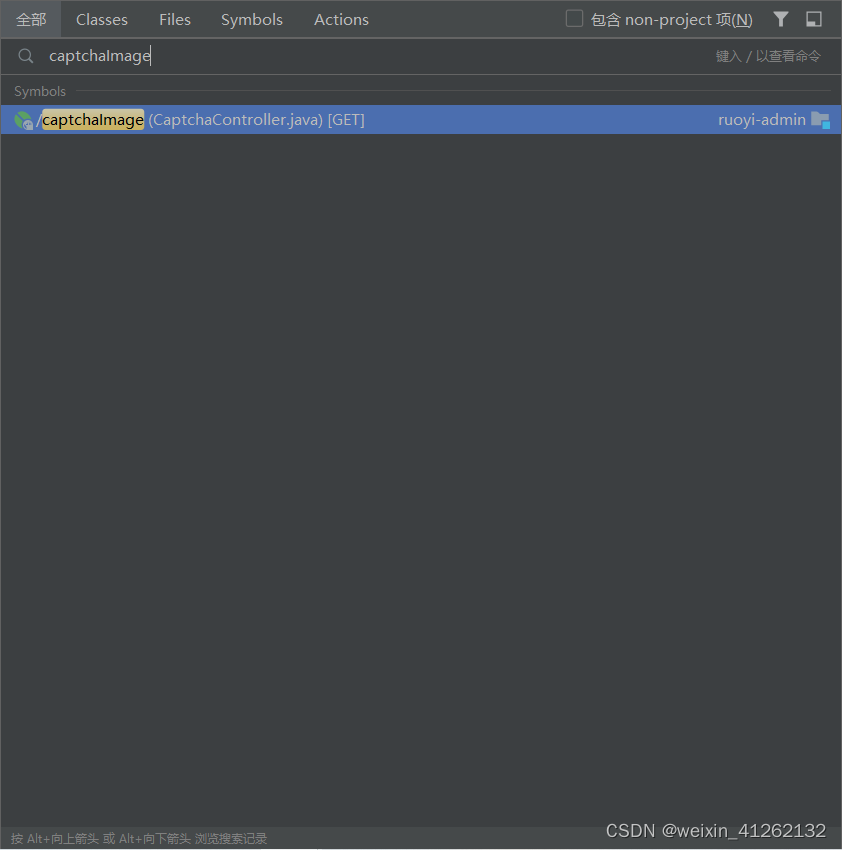
我们根据前端的请求地址中的captchaImage来找后端对应的代码,我们可以用idea自带全局搜索,双击shift打开全局搜索框即可
然后就能找到对应的controller了,在验证码后端主要处理的是
1,判断验证码是否开了
2,生成唯一标识uuid,并于固定值拼接成将要放在redis的key值
3,生成数学表达式,并把答案与表达式分开来,把答案放入uuid对应的值code中。
4,把键值对放入redis
5,把表达式写入图片流
6,用前后端交互的数据模型AjaxResult来封装uuid和图片
7,返回AjaxResult给前端登录功能
基于之前的学习,我们想找相应功能的请求地址就很容易了,我们很快找到了
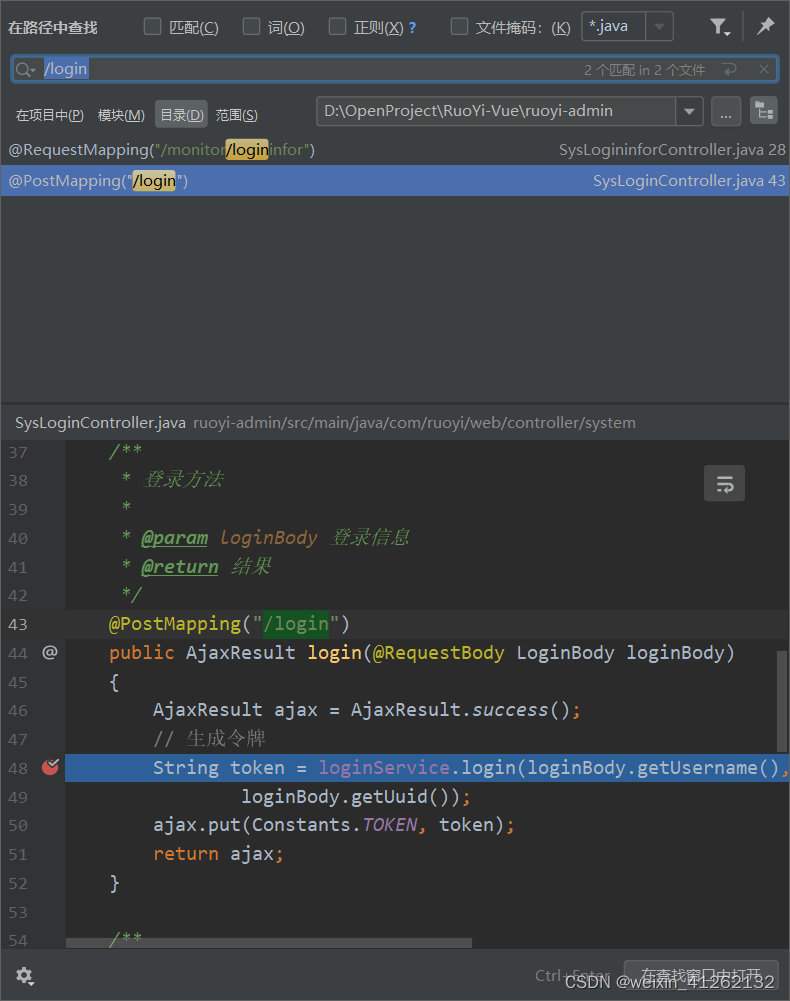
然后通过在当前项目右键点击在路径搜索/login即可找到
接下来就是自己按照断点去调试测试背后的逻辑流程了
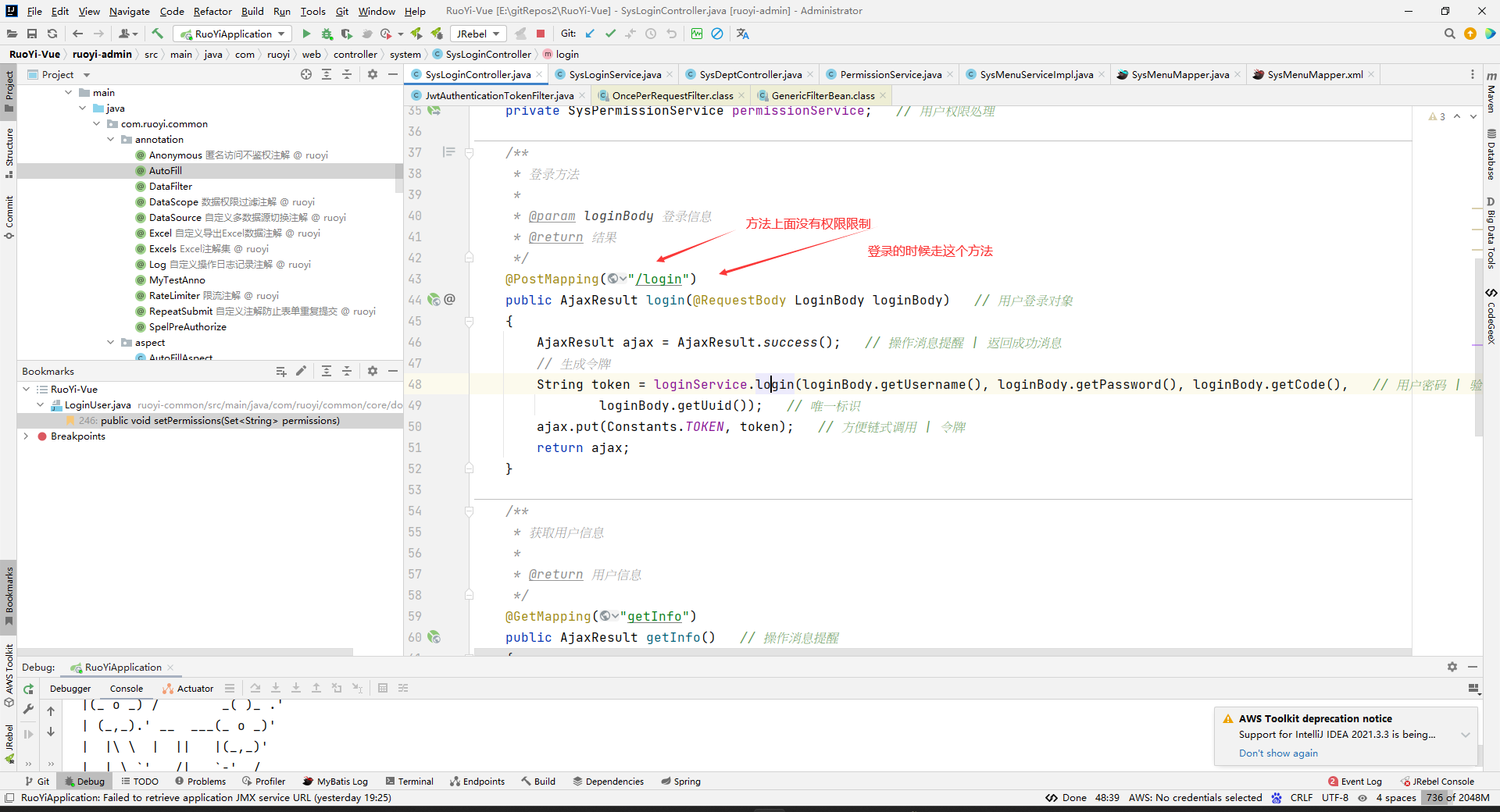
在controller层,登录方法主要是为了生成token,然后放入前后端统一数据类AjaxResult中,返回给前端。
但里面登录方法可封装了好多层,
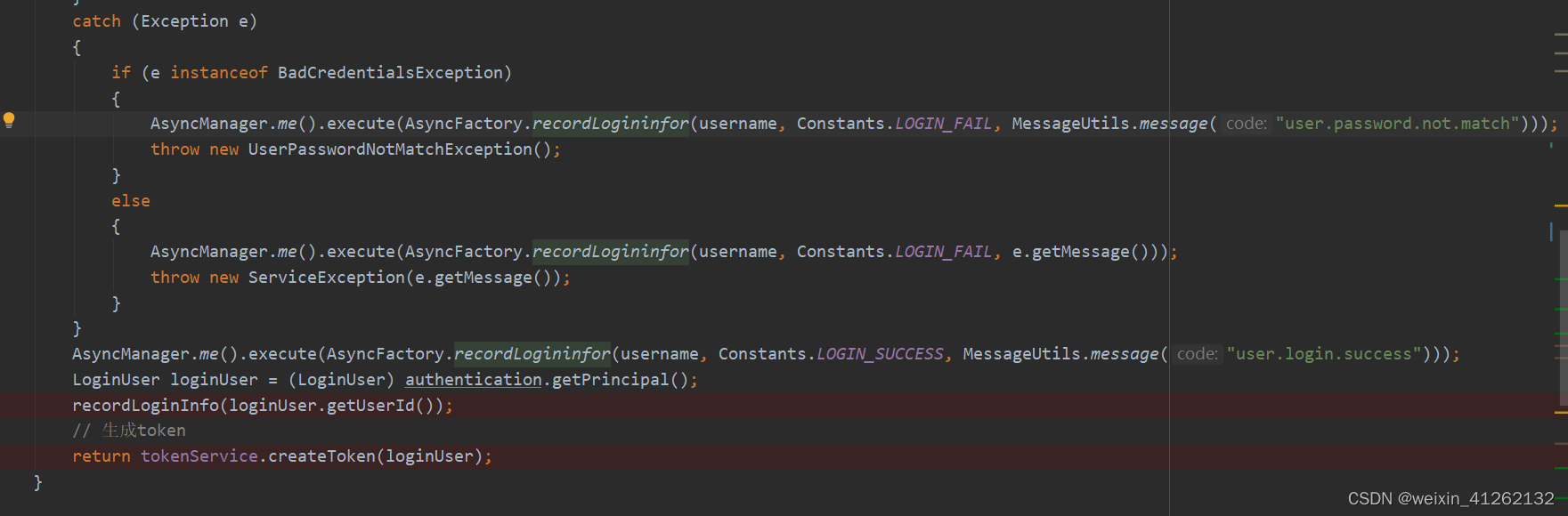
主要有校验验证码,通过springsecurity校验的用户名密码流程,登录成功会查询并记录ip地址,记录用户登录信息过程,根据校验成功后的Authentication来封装成一个登录实体类,根据登录实体类来生成token。下面我们来细讲开发者设计的思想:
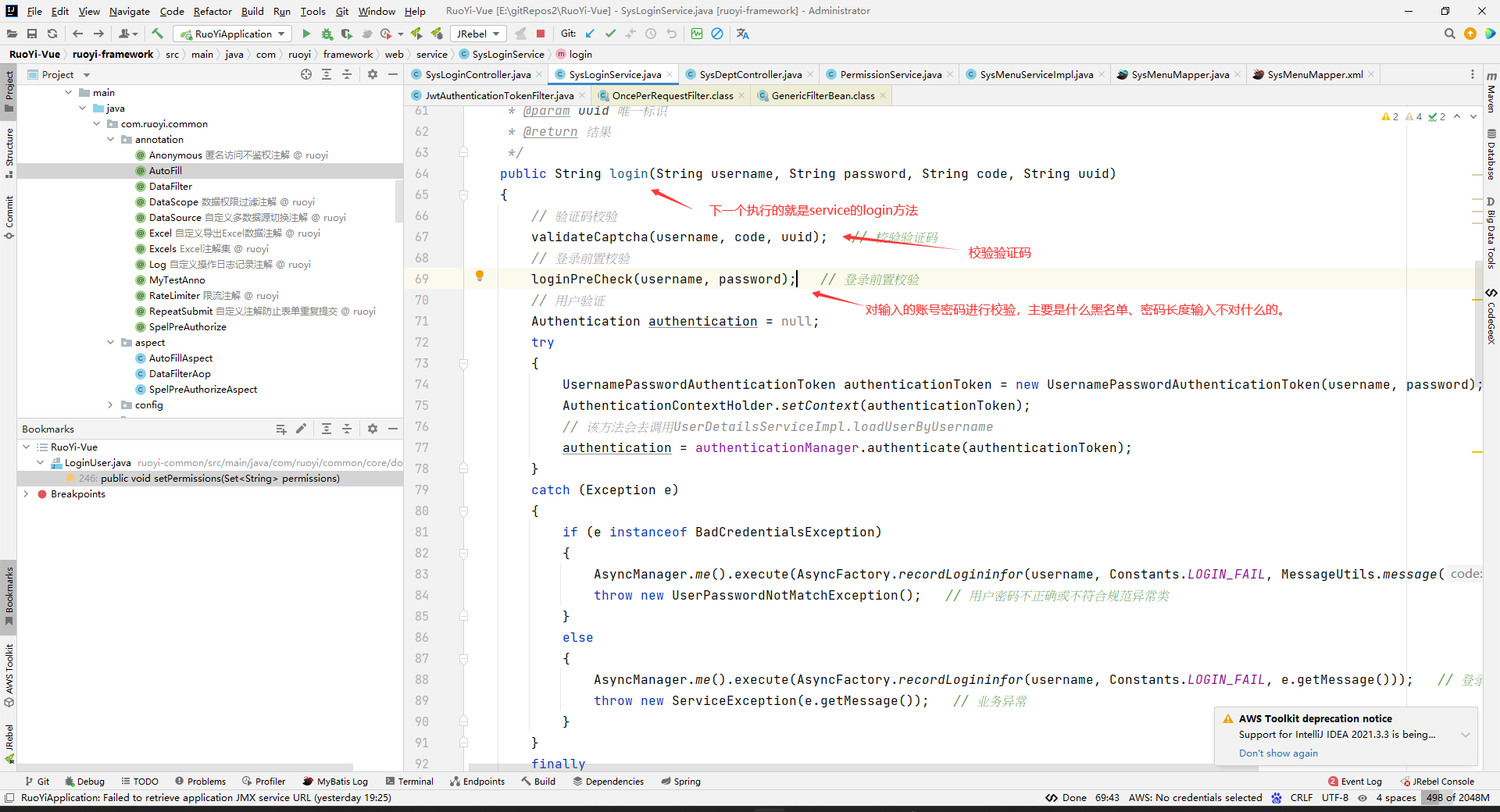
在校验验证码中:
首先拼接入参中的uuid,产生key值,然后从redis中找到对应的验证码答案,与入参的code值进行比较,如果code是null或者不对,会抛异常,否则就过到下面代码。
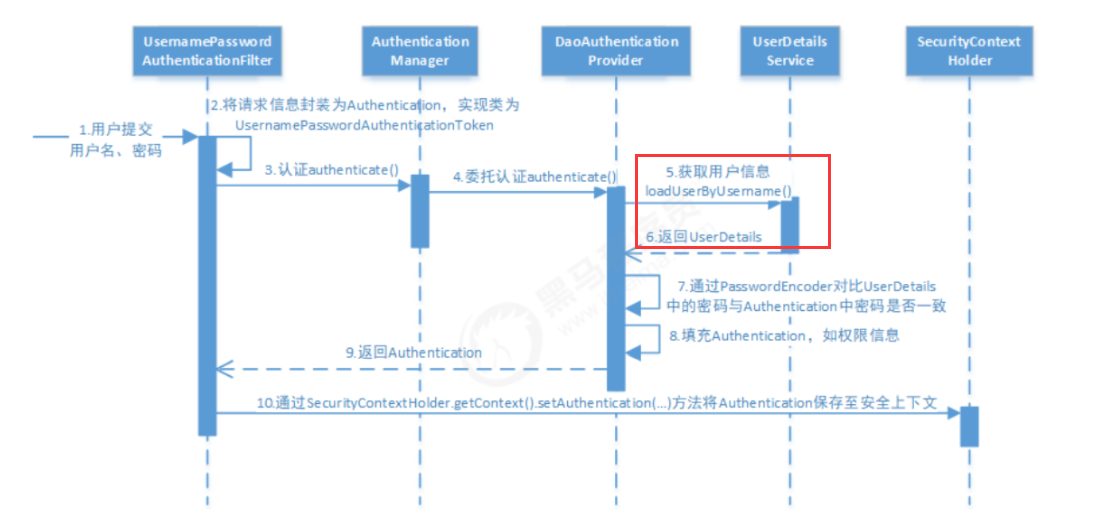
然后是校验用户名密码,该系统用springsecurity来校验,具体可以看下下面这个图
在上诉流程中,
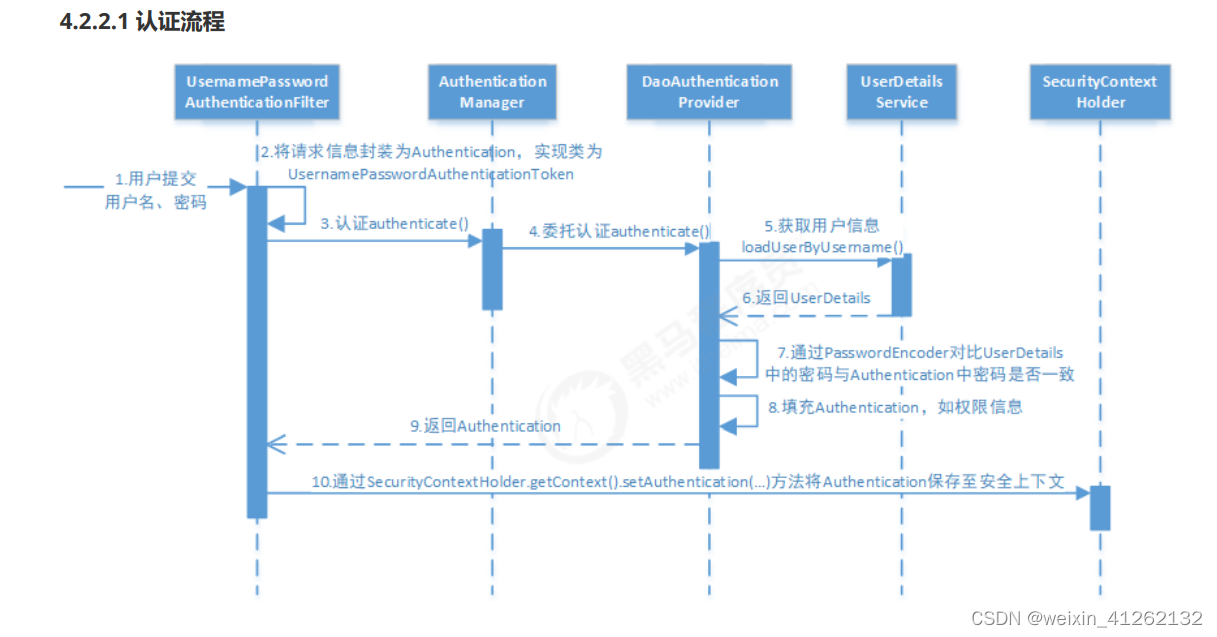
详细的认证流程如下:
- 用户提交用户名、密码被SecurityFilterChain中的 UsernamePasswordAuthenticationFilter 过滤器获取到,
封装为请求Authentication,通常情况下是UsernamePasswordAuthenticationToken这个实现类。- 然后过滤器将Authentication提交至认证管理器(AuthenticationManager)进行认证
- 认证成功后, AuthenticationManager 身份管理器返回一个被填充满了信息的(包括上面提到的权限信息,
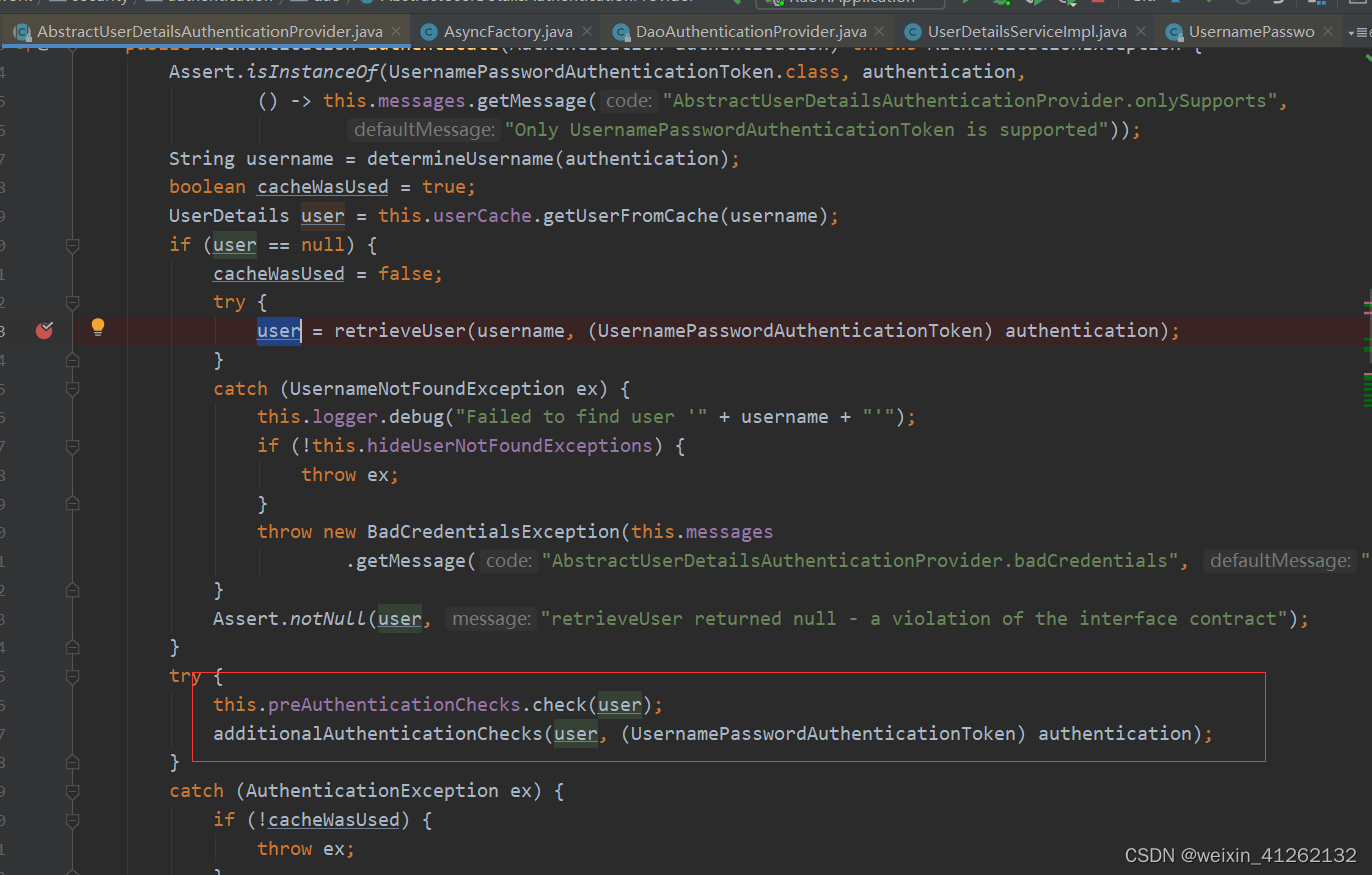
身份信息,细节信息,但密码通常会被移除) Authentication 实例。- SecurityContextHolder 安全上下文容器将第3步填充了信息的 Authentication ,通过SecurityContextHolder.getContext().setAuthentication(…)方法,设置到其中。可以看出AuthenticationManager接口(认证管理器)是认证相关的核心接口,也是发起认证的出发点,它的实现类为ProviderManager。而Spring Security支持多种认证方式,因此ProviderManager维护着一个List 列表,存放多种认证方式,最终实际的认证工作是由AuthenticationProvider完成的。咱们知道web表单的对应的AuthenticationProvider实现类为DaoAuthenticationProvider,它的内部又维护着一个UserDetailsService负责UserDetails的获取。最终
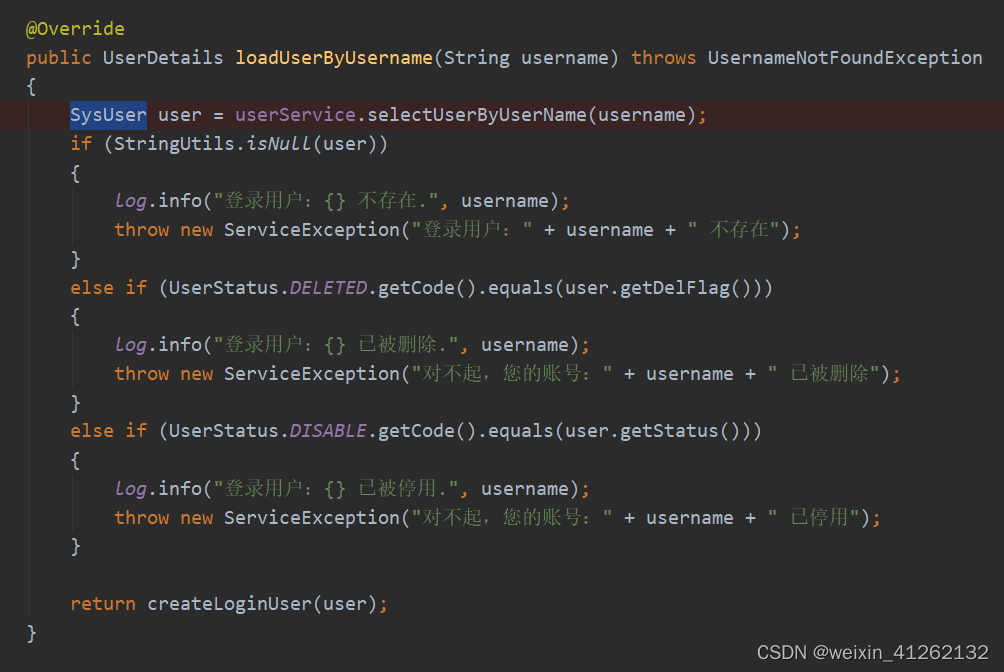
AuthenticationProvider将UserDetails填充至Authentication。我们可以通过重写其中某类的方法来自定义对用户密码校验,但由于springsecurity流程复杂,我们一般重写UserDetelsService的loadUserByUsername方法,在这个方法中,根据用户名在数据库查找后并封装一个SysUser实体类,如果该用户为null,或者用户的状态在数据库中是已删除或者停用,都给各自抛出对应的异常。
如果用户没问题就会生成一个登录实体类LoginUser,在实例化LoginUser时候,会查询该用户的权限(与菜单相关的)并放入permision中,该类的父类是UserDetails,然后返回到某个方法进行密码校验,如下图
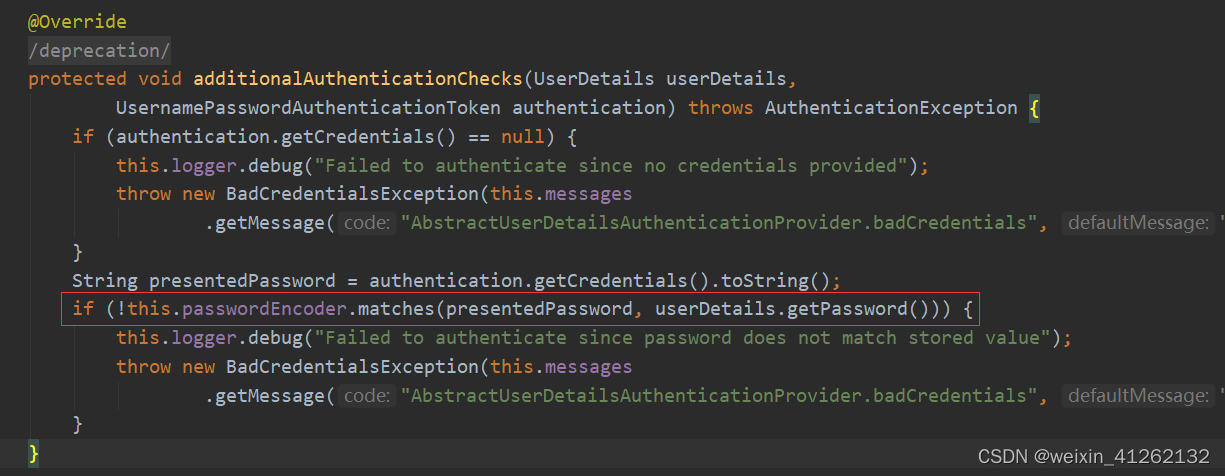
点击查看又发现了
实质上通过match方法进行校验,这里springsecurity官方推荐使用BCryptPasswordEncoder,PasswordEncoder的实现类,这是个强哈希加密算法。不过不重写,按默认就是官方推荐的。
上诉流程如果有出问题的话,登录实现类方法会捕获异常
无论登录是否通过,都会记录登录信息,通过recordLogininfor方法来记录,该方法里面套娃了一些查询ip,并在sys_logininfor表中记录相关记录。
最后如果顺利来到最后一步生成token,该方法里面通过若依自定义随机id工具类生成token值,然后并作为key值将loginUser缓存到redis中,loginUser记录了用户所有信息,有效期为30分钟。
最后把token放入map中,然后将map通过jwt生成token并以String类型返回。

摘录2
????
分析
两个问题:
- SysUser中的权限登录的时候会被放到哪里?
- 访问接口的时候@ss.hasPermi是怎么读取到权限的
登录接口:
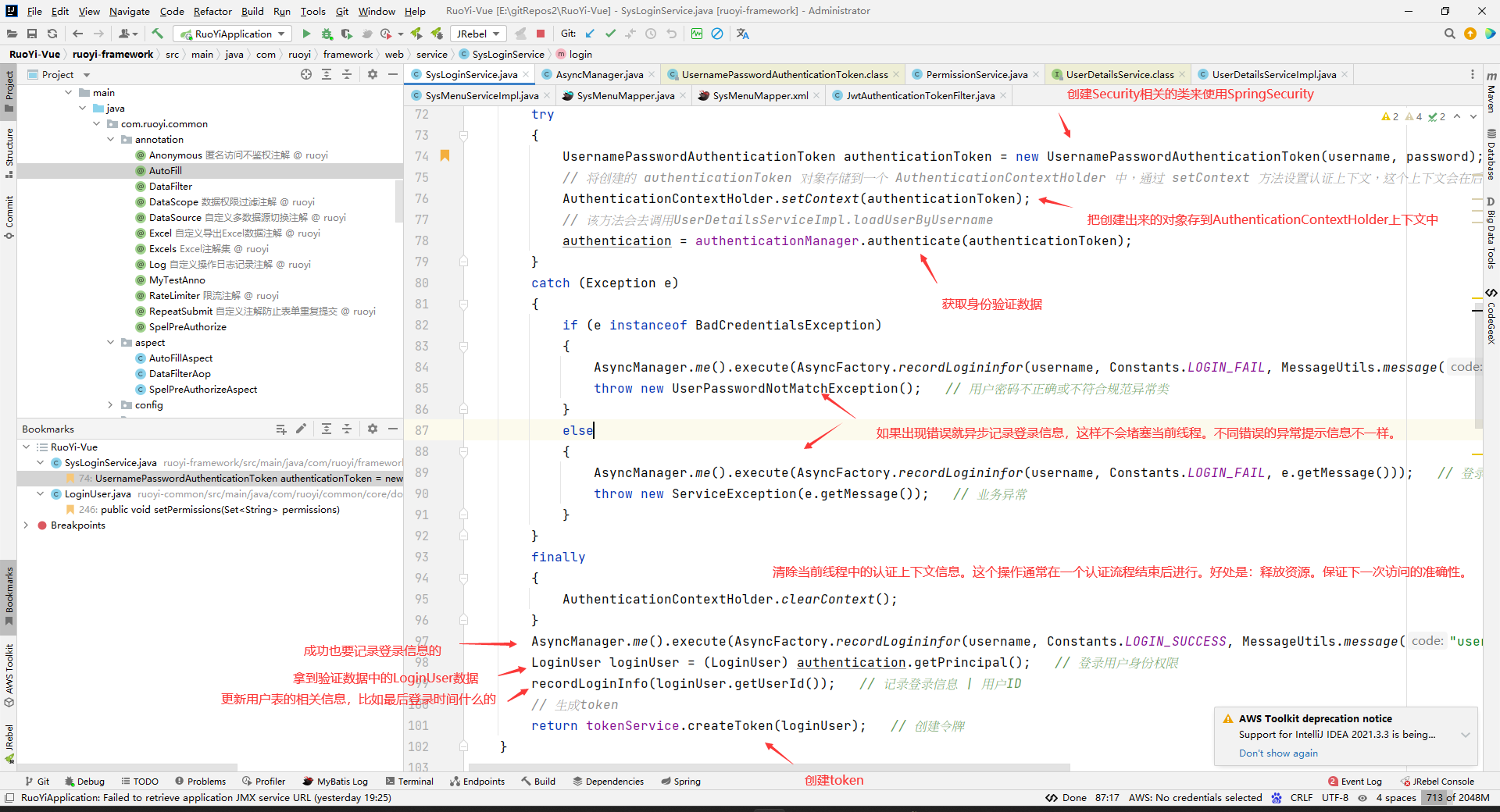
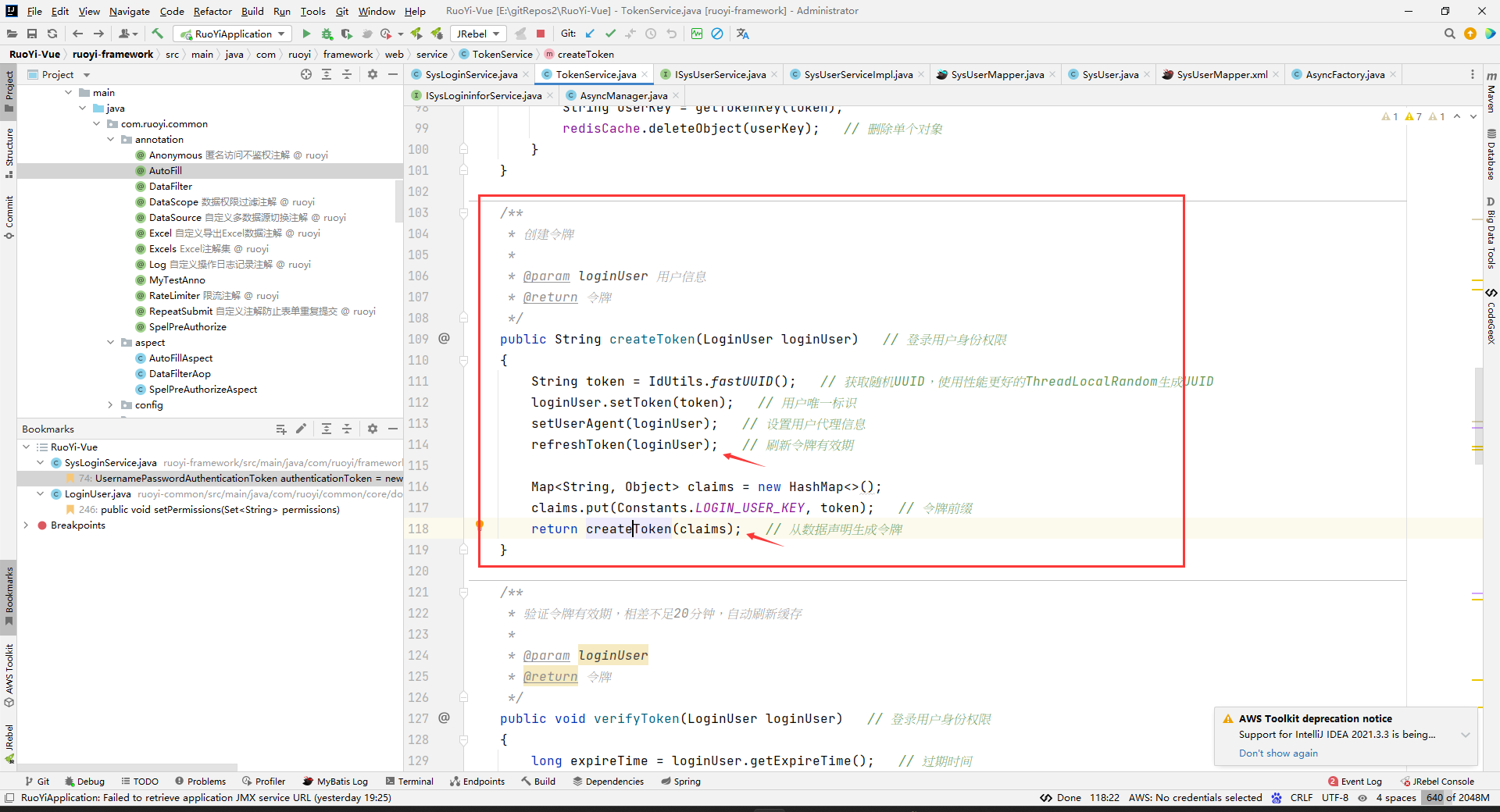
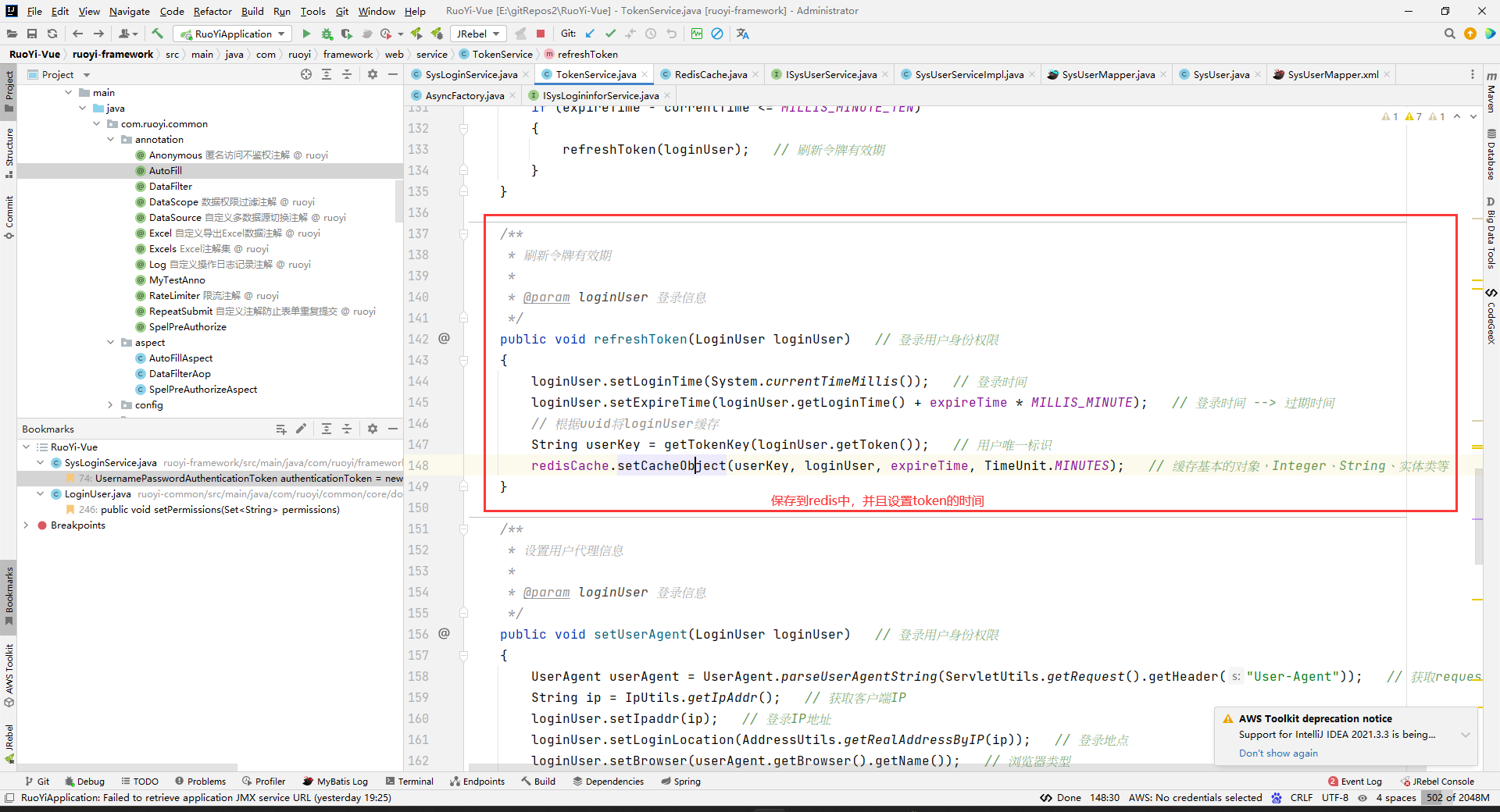
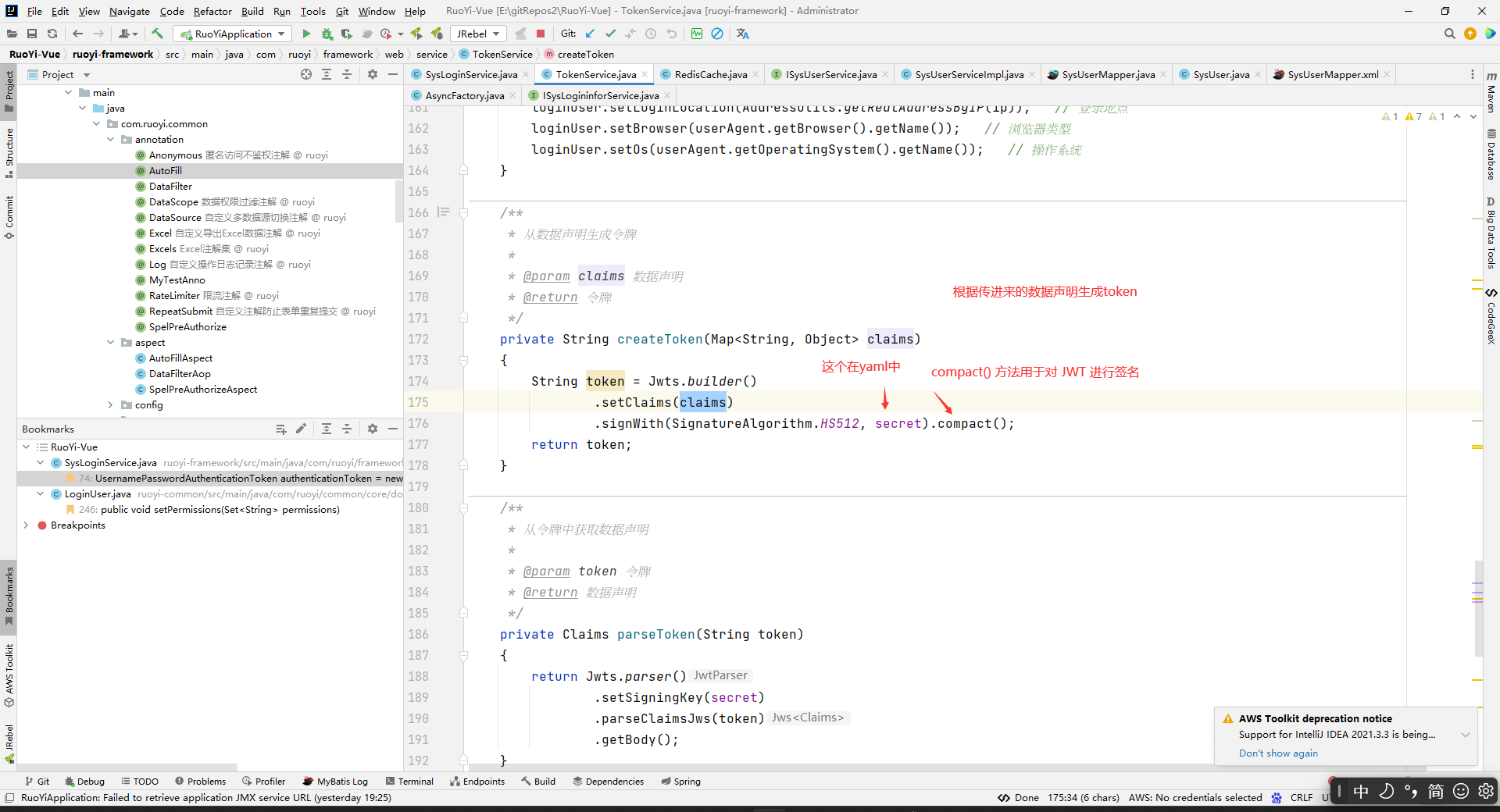
然后给前端进行记录。
上面的分析中authenticationManager.authenticate(authenticationToken),在登录的时候会把数据库中的对应的用户数据找到放到LoginUser中(包括权限数据),并把LoginUser放到authentication中去,然后保存到redis里面。
authenticationManager.authenticate(authenticationToken)方法具体怎么执行,等一下分析。
访问接口的时候@ss.hasPermi是怎么读取到权限的?
答:
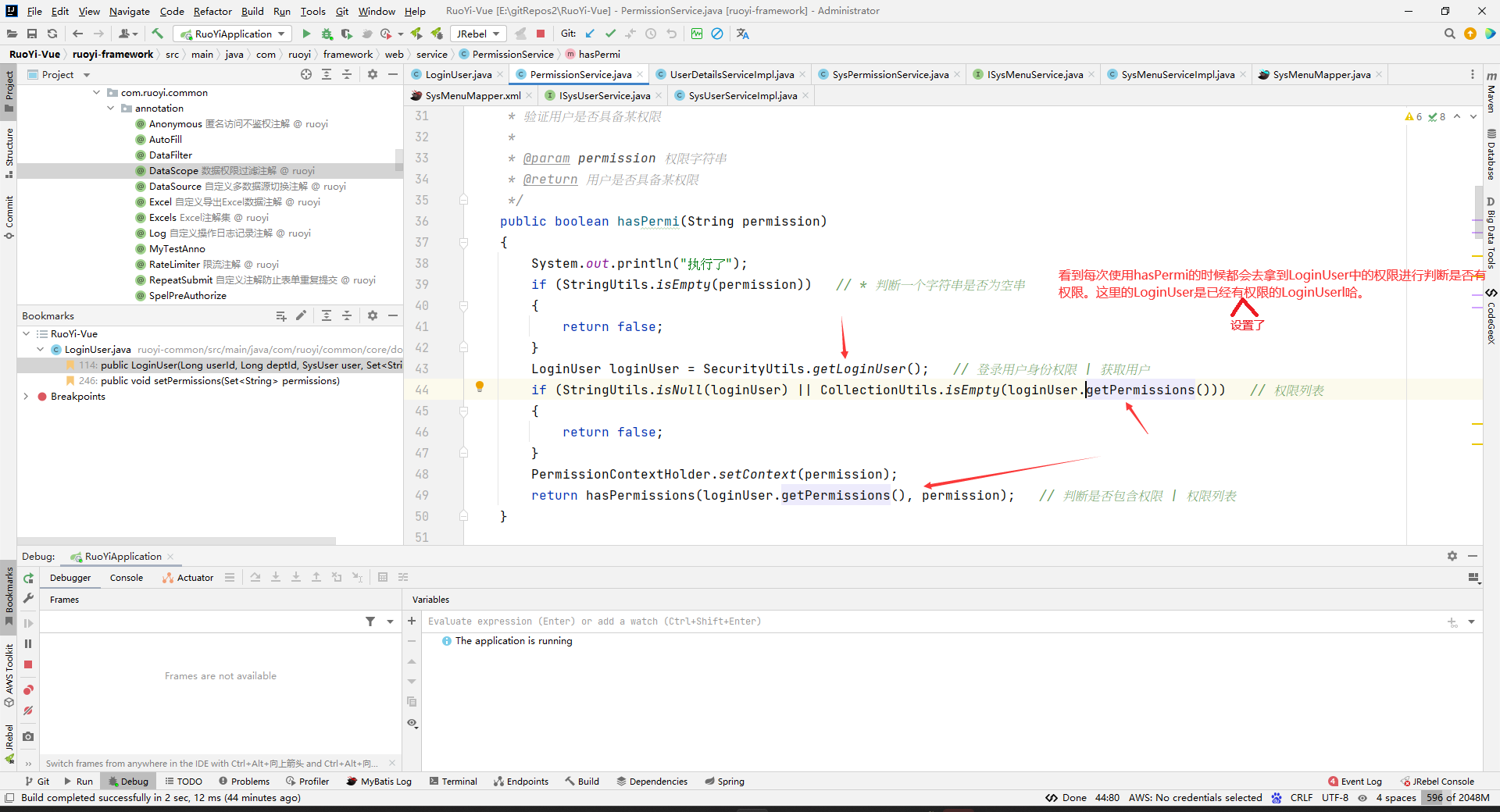
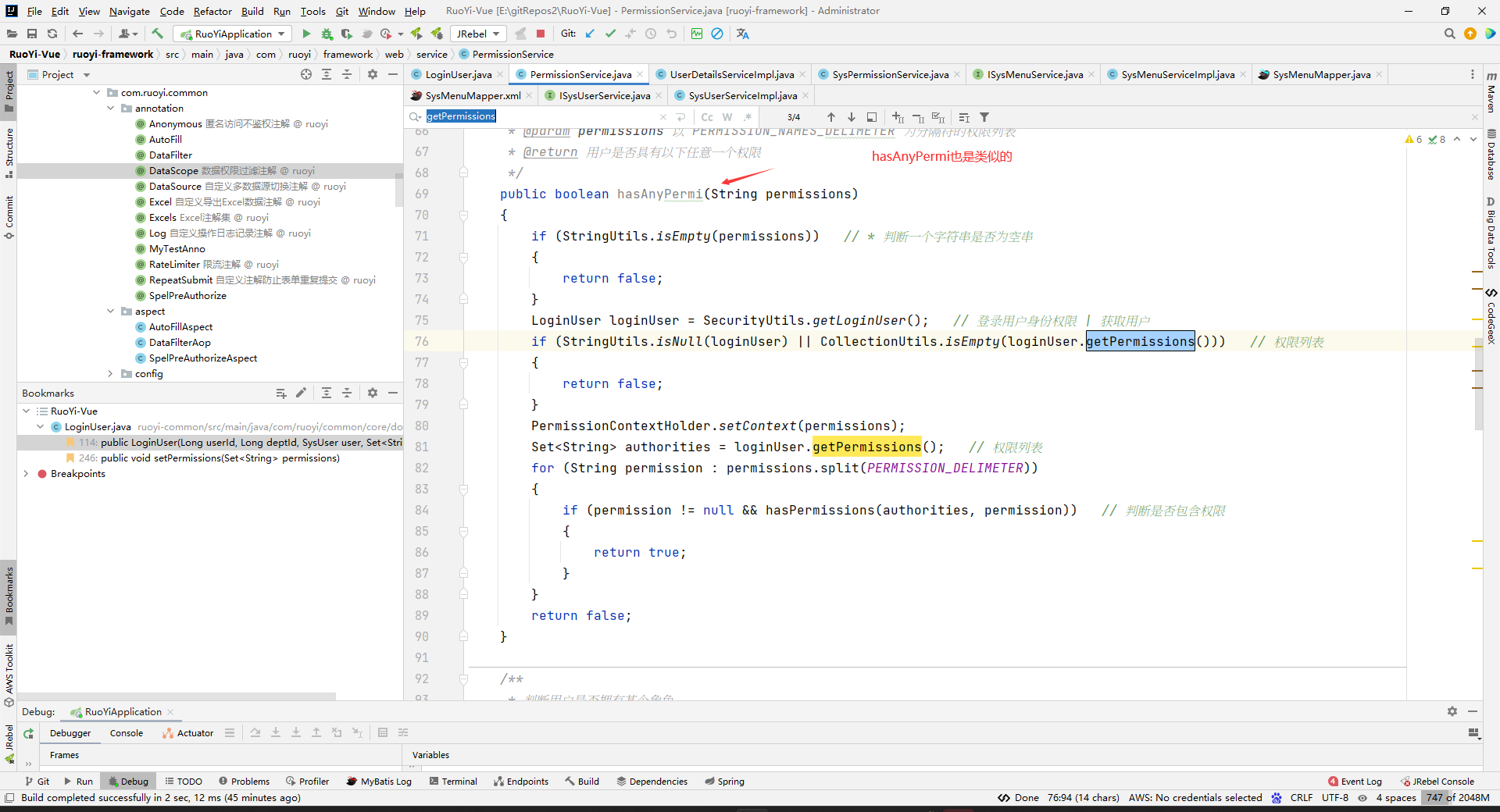
我们看到Security中getLoginUser()是通过getAuthentication().getPrincipal();来获取登录用户数据的:
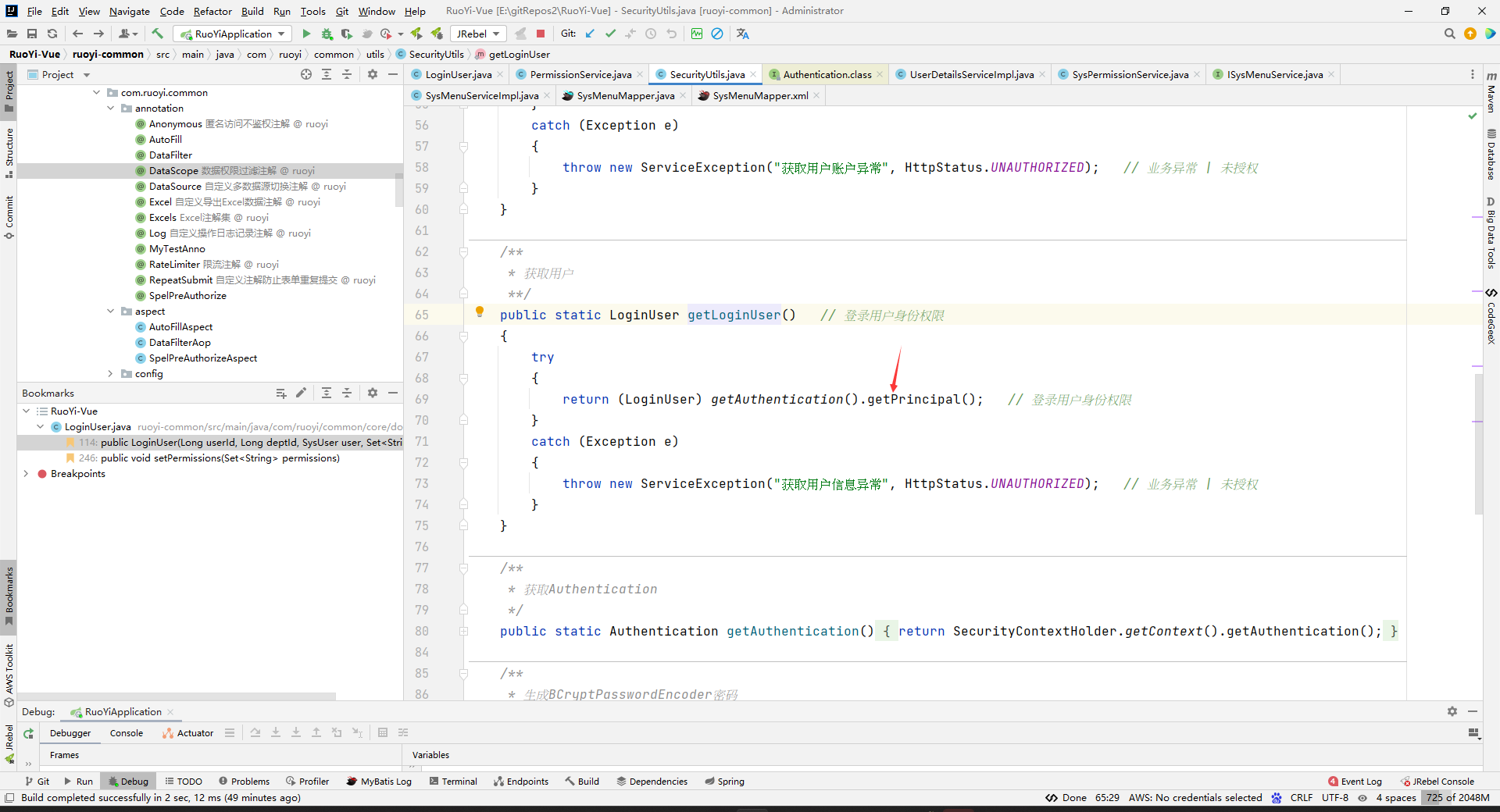
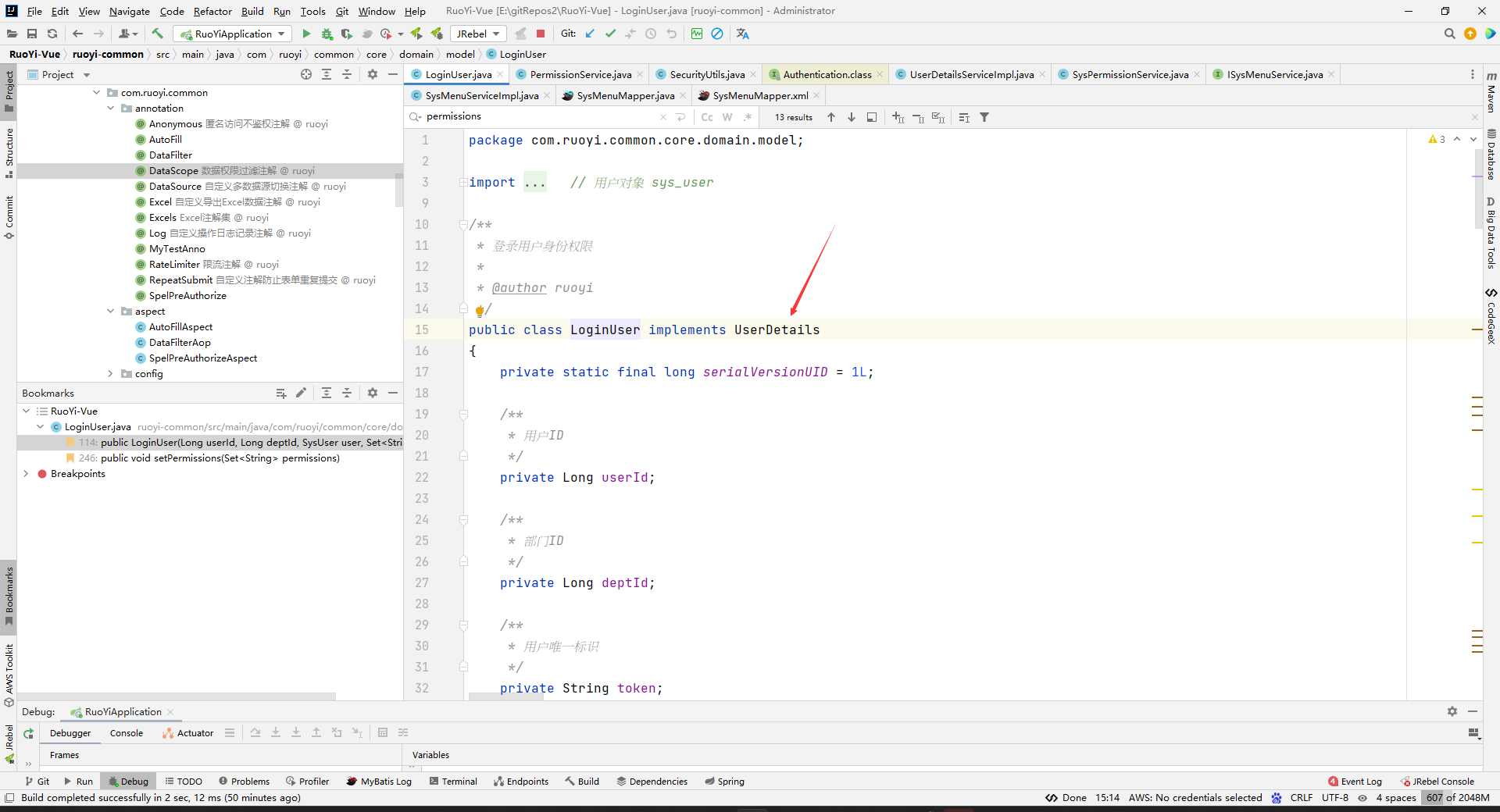
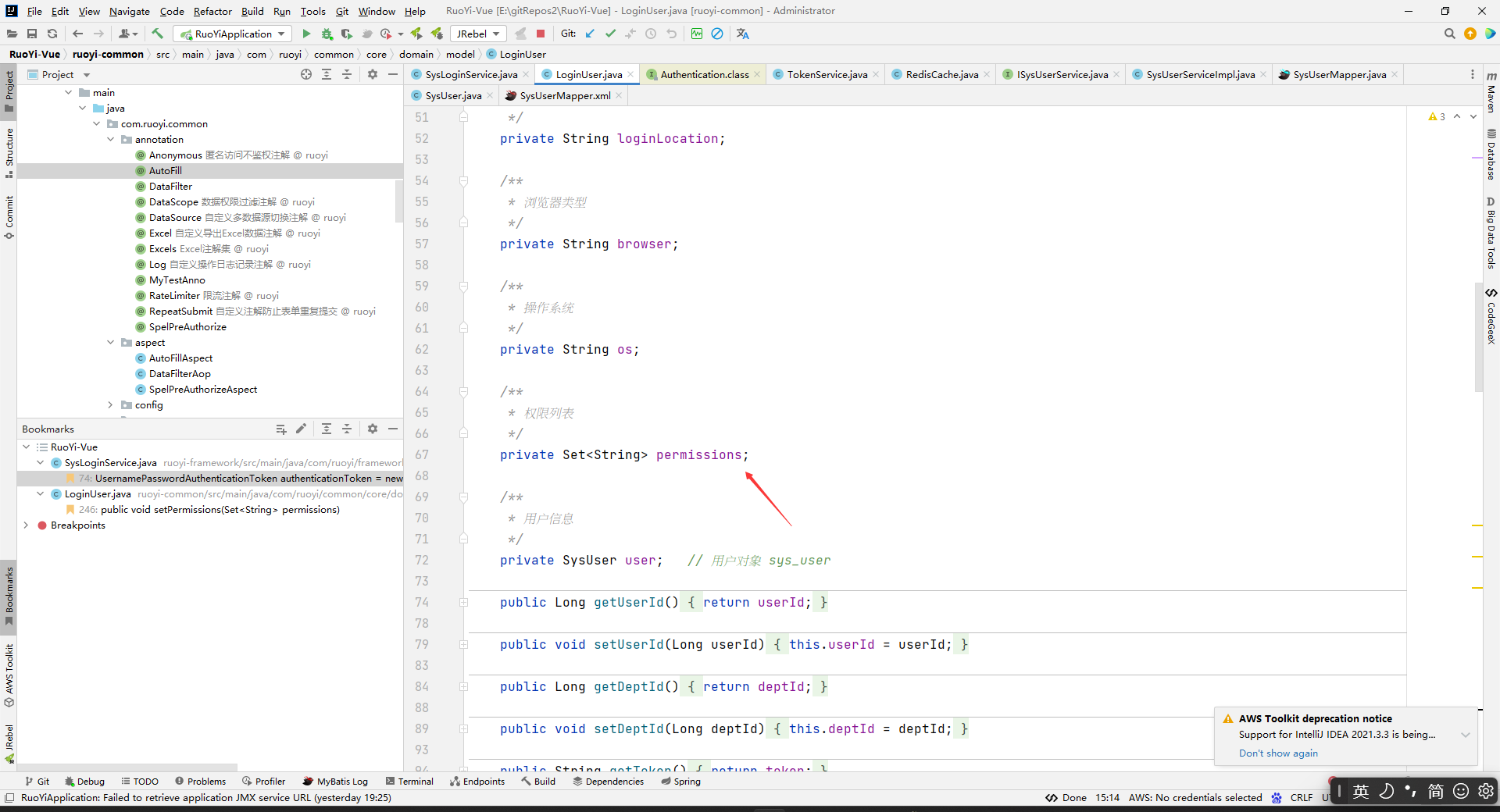
其中LoginUser是继承UserDetails的,LoginUser就是我们登录时候存到redis中的数据,LoginUser中还有权限数据的。
现在就要看(LoginUser) getAuthentication().getPrincipal();是怎么获取到LoginUser了,看是不是从redis中获取的。
不,不是,是从线程上下文中获取的。
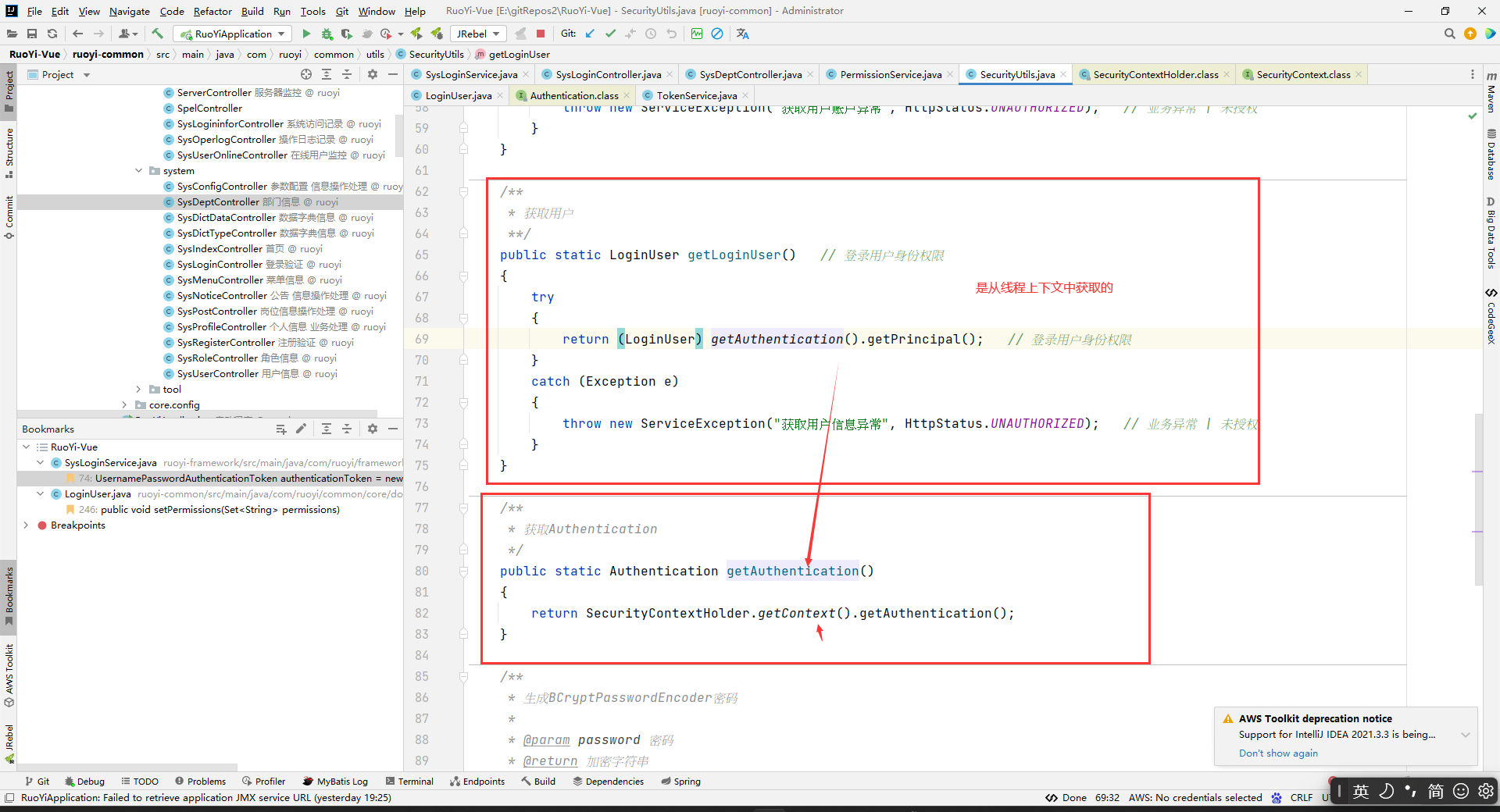
即,你这一次请求结束,那么上下文中就获取不到LoginUser了。
但是你请求执行的时候会去redis中拿LoginUser数据的,然后放到上下文中的,所以相当于你(LoginUser) getAuthentication().getPrincipal();是间接获取的redis中的LoginUser数据的。这个看下面的分析就懂了。
所以SecurityUtils.getLoginUser()就是间接获取的是reids中的LoginUser数据的,LoginUser数据是在登录的时候存到redis中去的。
每一次访问都会执行的方法(这个拦截器每次请求的时候都会执行):
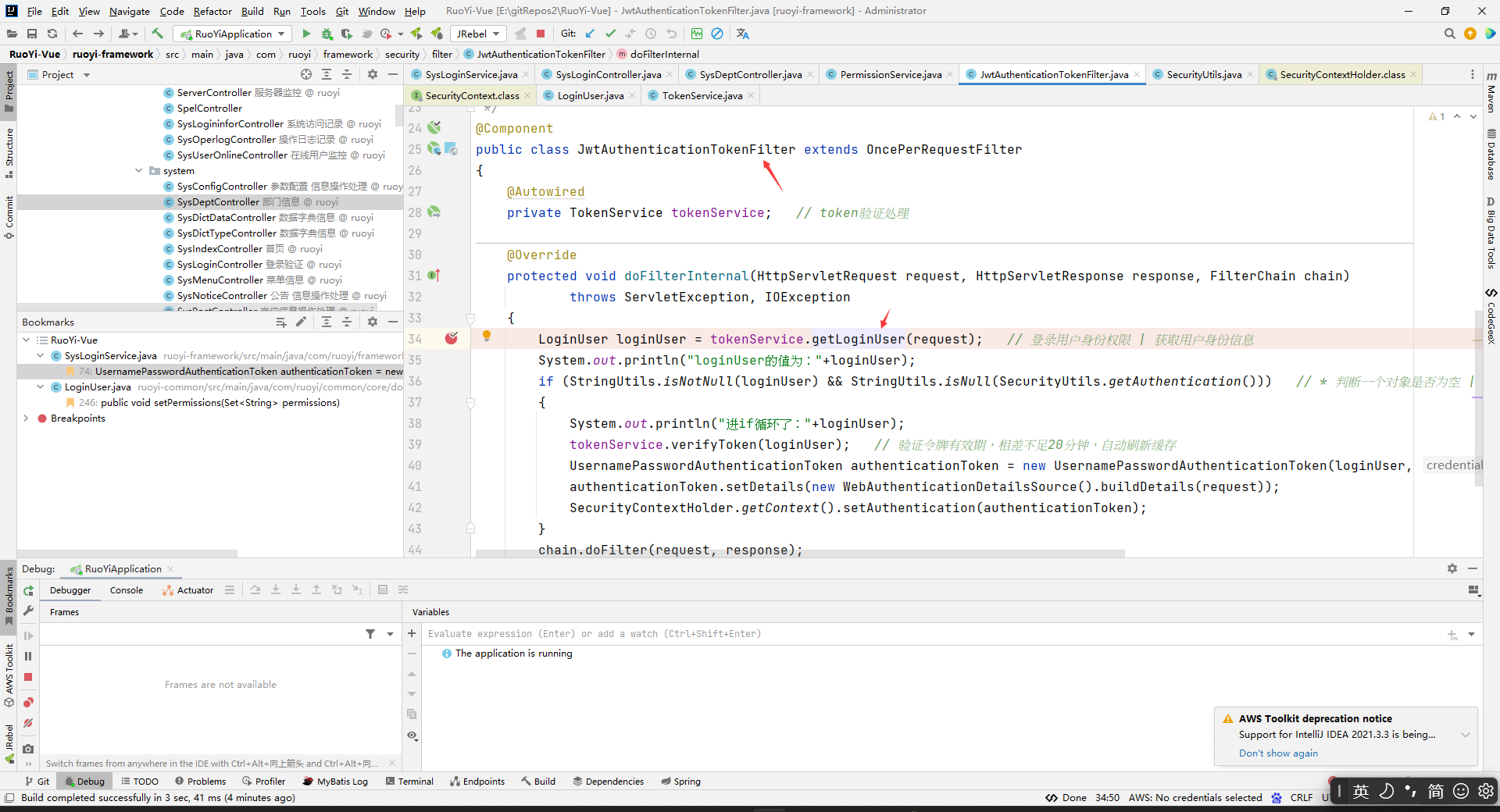
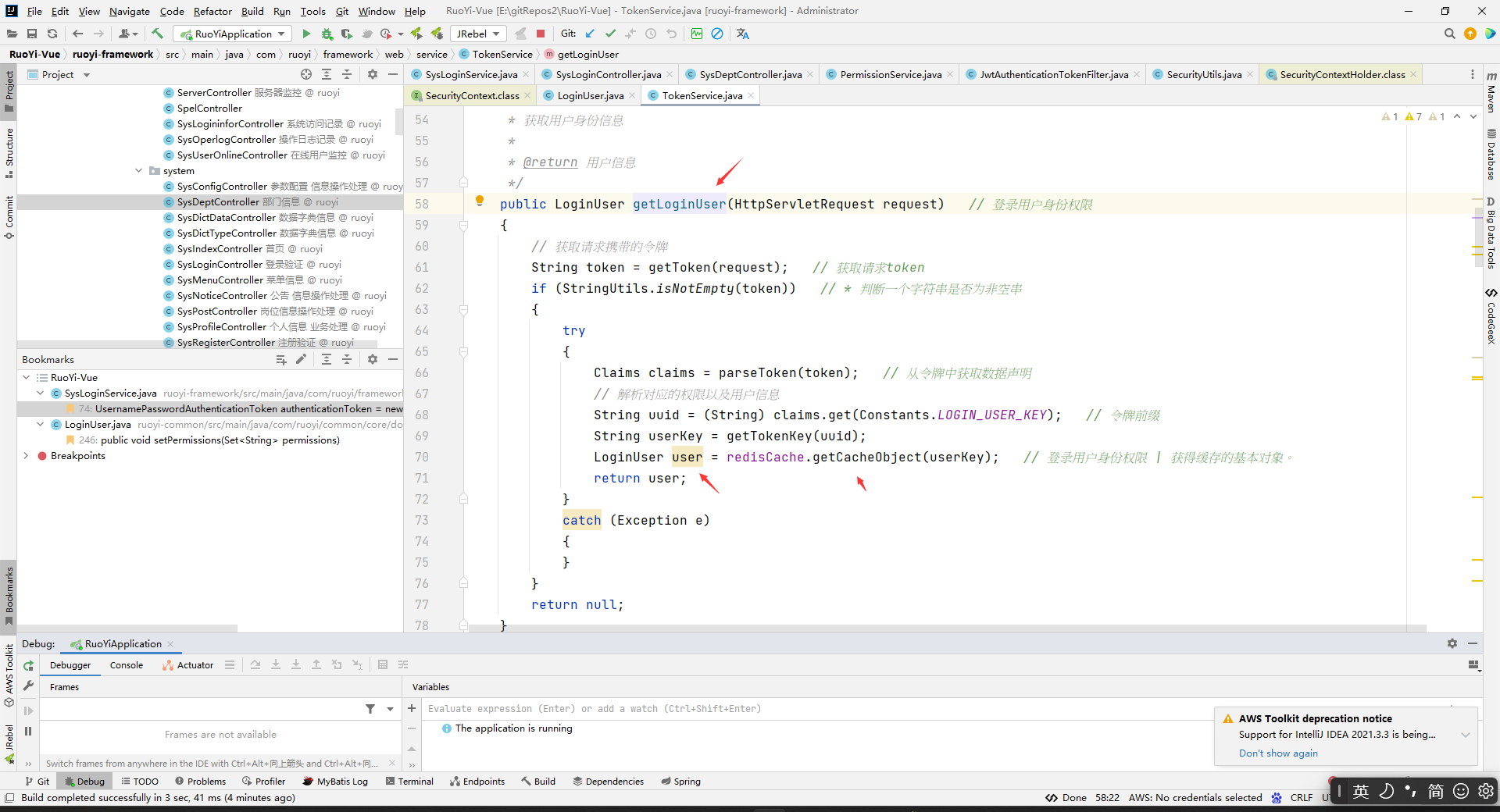
这个方法会去redis中拿LoginUser数据的。并且也验证了每次请求都会去先把redis中的LoginUser数据放到Security上下文中去的。然后之后的每次通过SecurityUtils.getLoginUser()就能间接拿到redis中的LoginUser数据了。
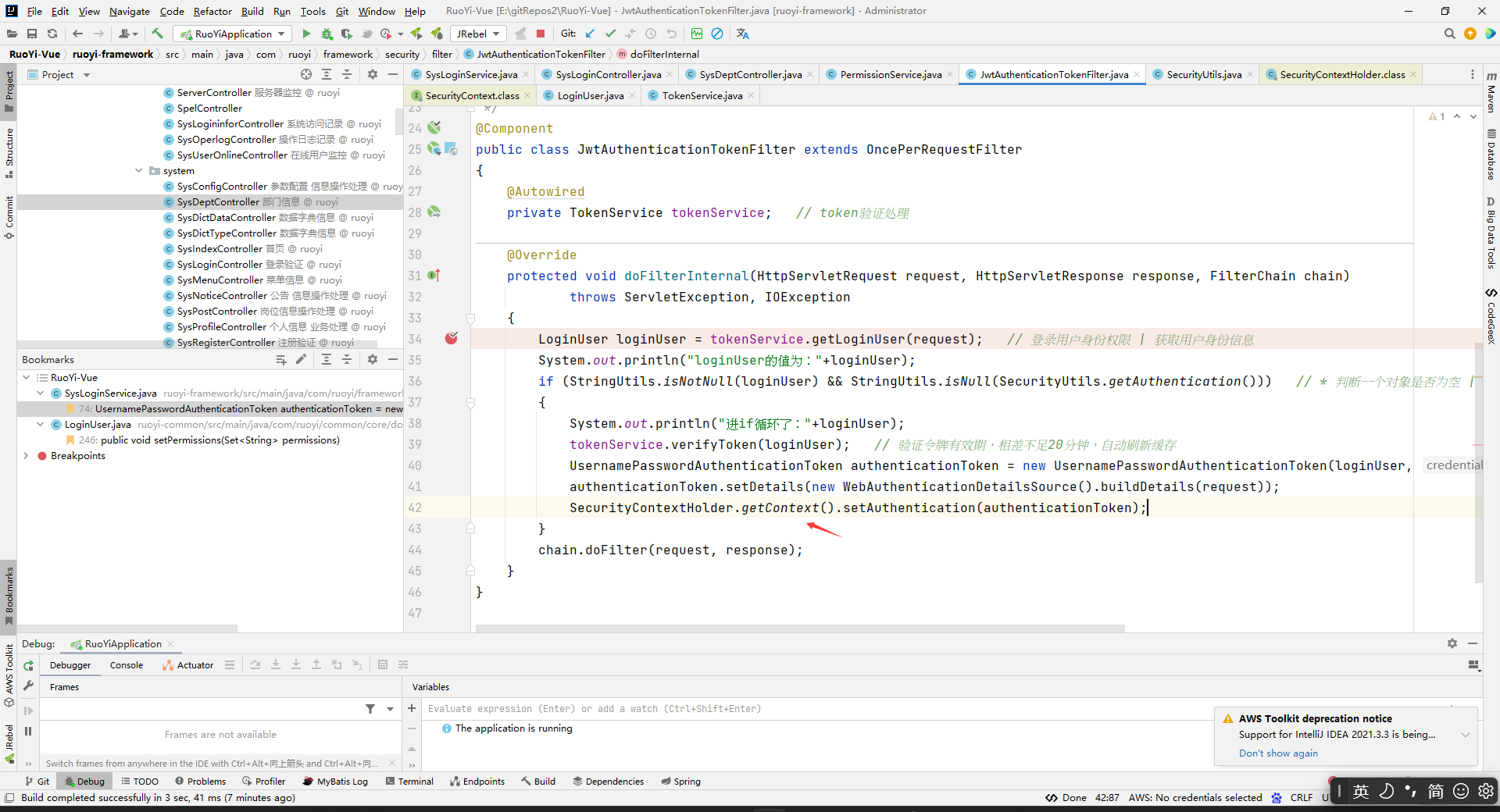
注意哈,这里看到每次访问的时候,如果redis中有LoginUser,那么都会去执行tokenService.verifyToken(loginUser);刷新token的,这个我之前还没有注意到。
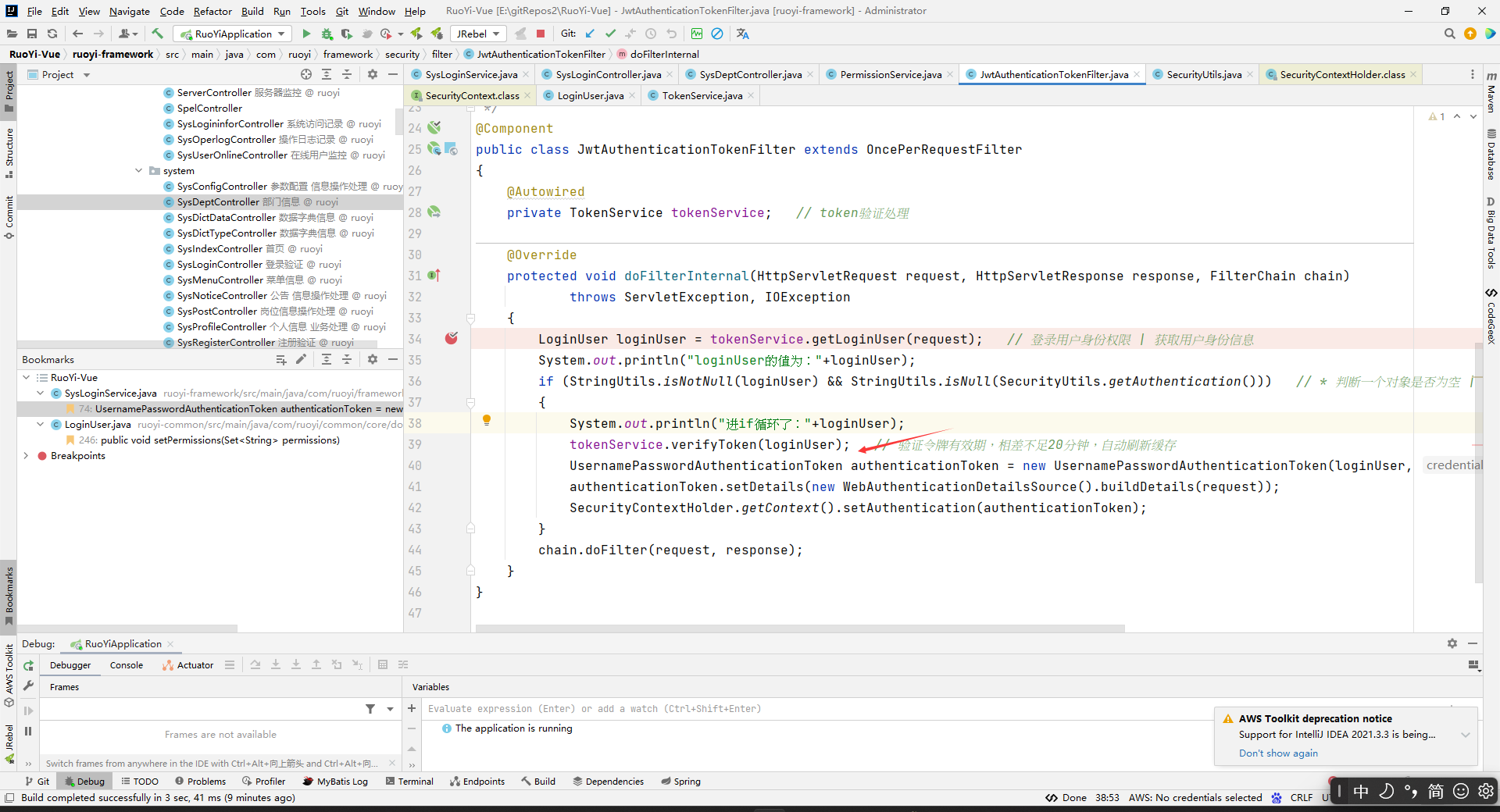
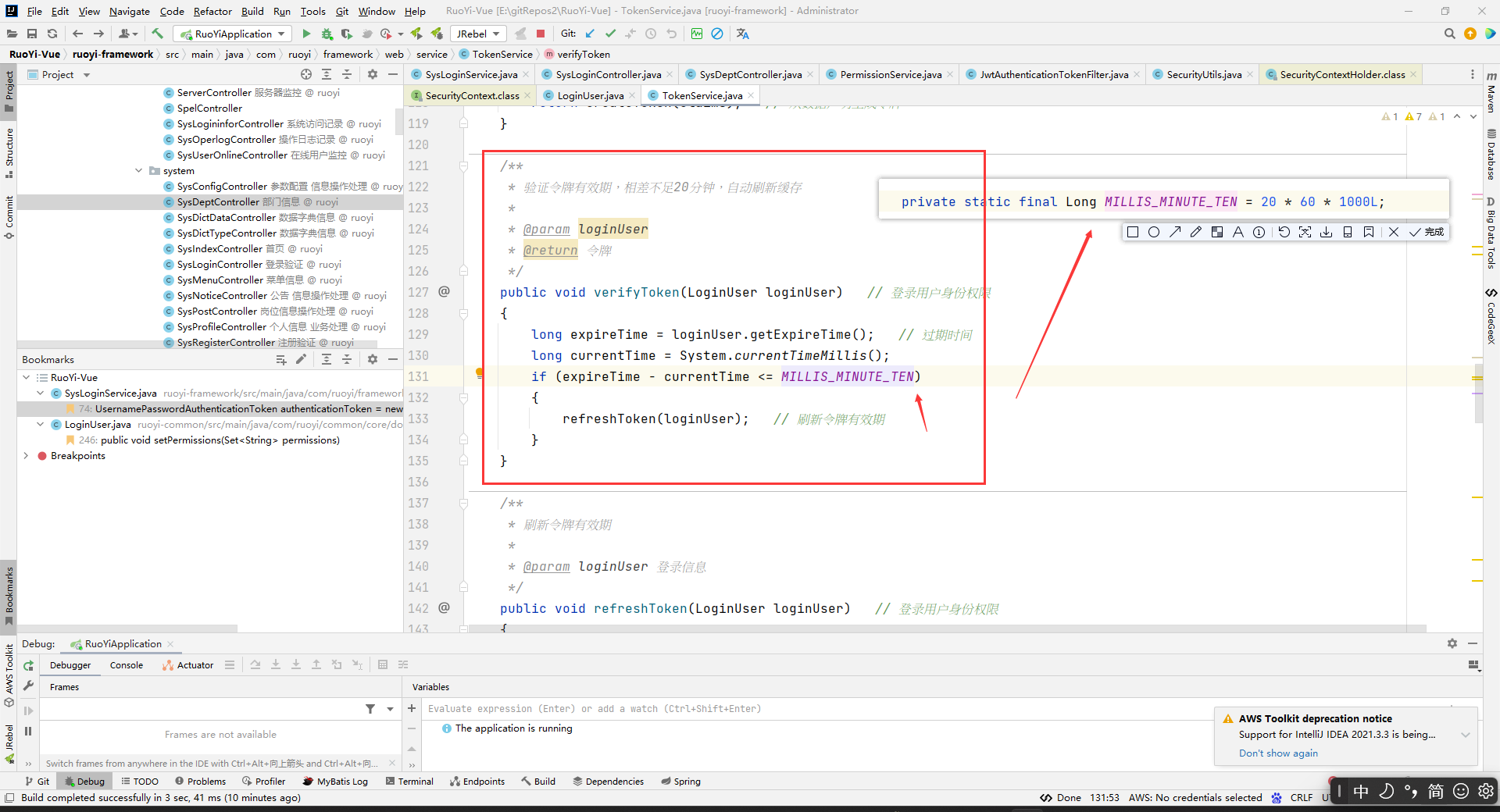
authenticationManager.authenticate(authenticationToken)
前面说的authenticationManager.authenticate(authenticationToken)等一下分析,现在来分析一下。
我们来论证一下“authenticationManager.authenticate(authenticationToken)执行的时候会把数据库中的对应的用户数据找到放到LoginUser中”
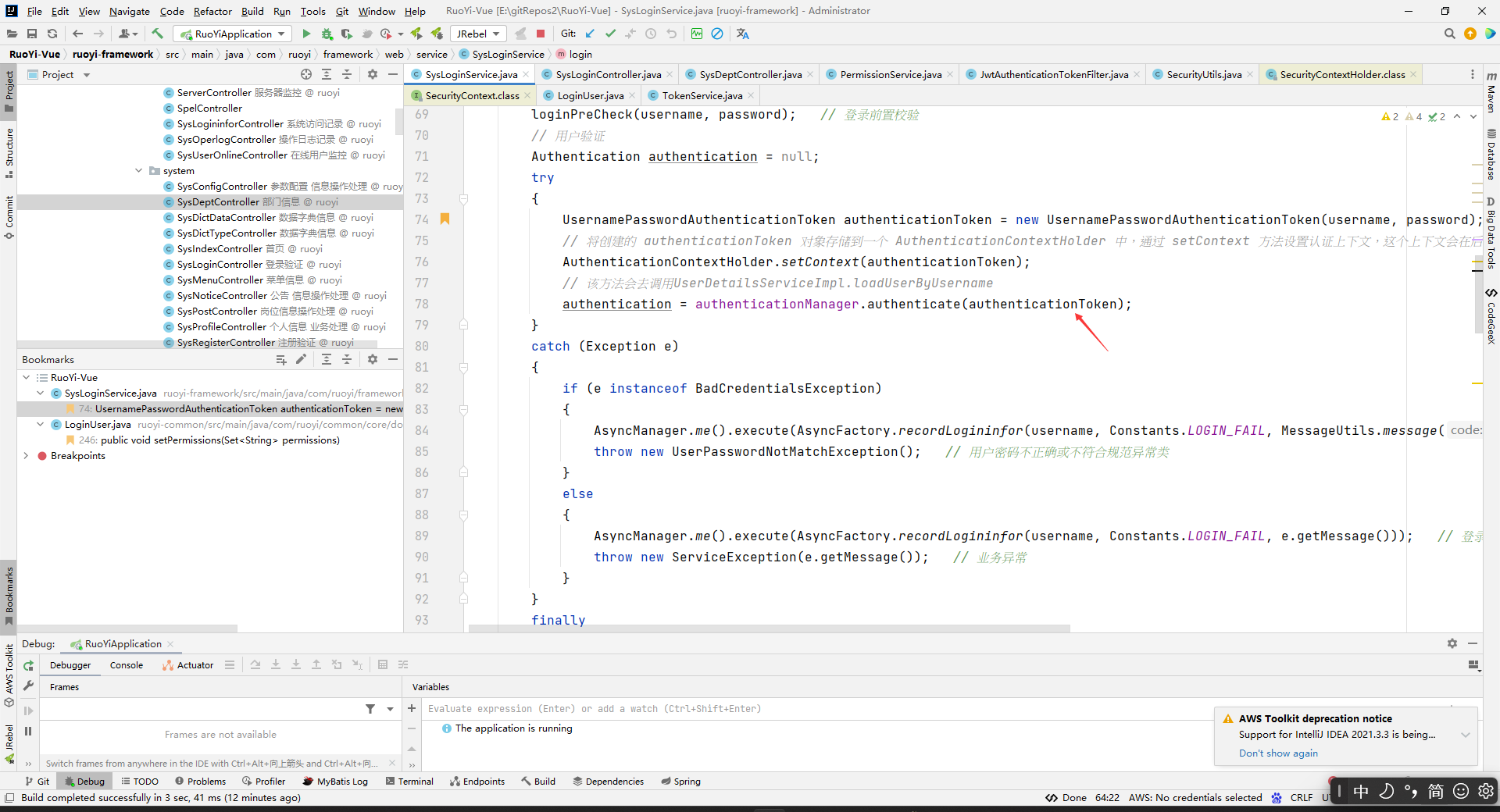
分析:
security的执行逻辑如下
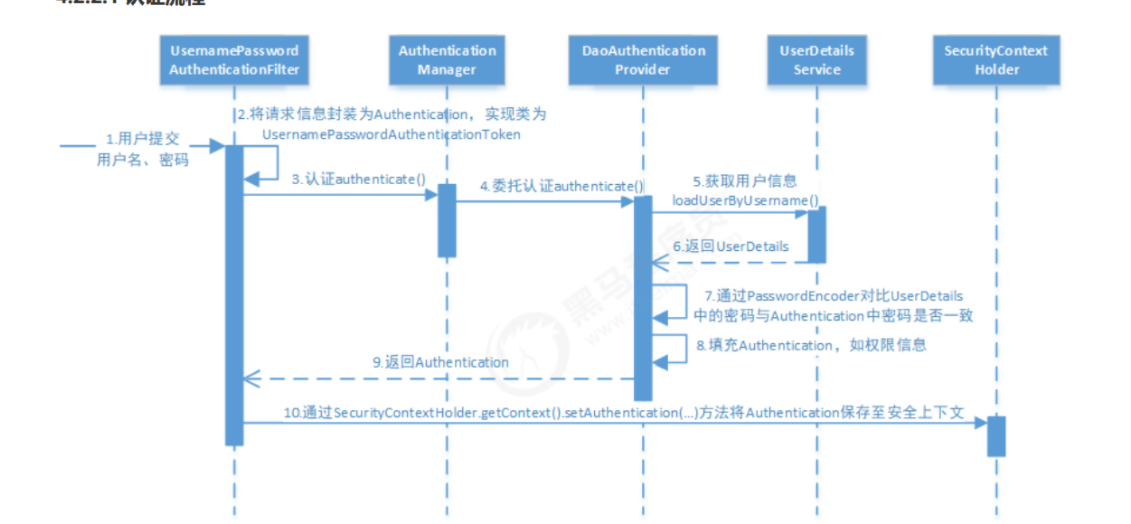
相当于没有UsernamePasswordAuthenticationFilter,但是有的是SysLoginService的login去封装为UsernamePasswordAuthenticationToken,并且使用AuthenticationManager调用authenticate去认证。
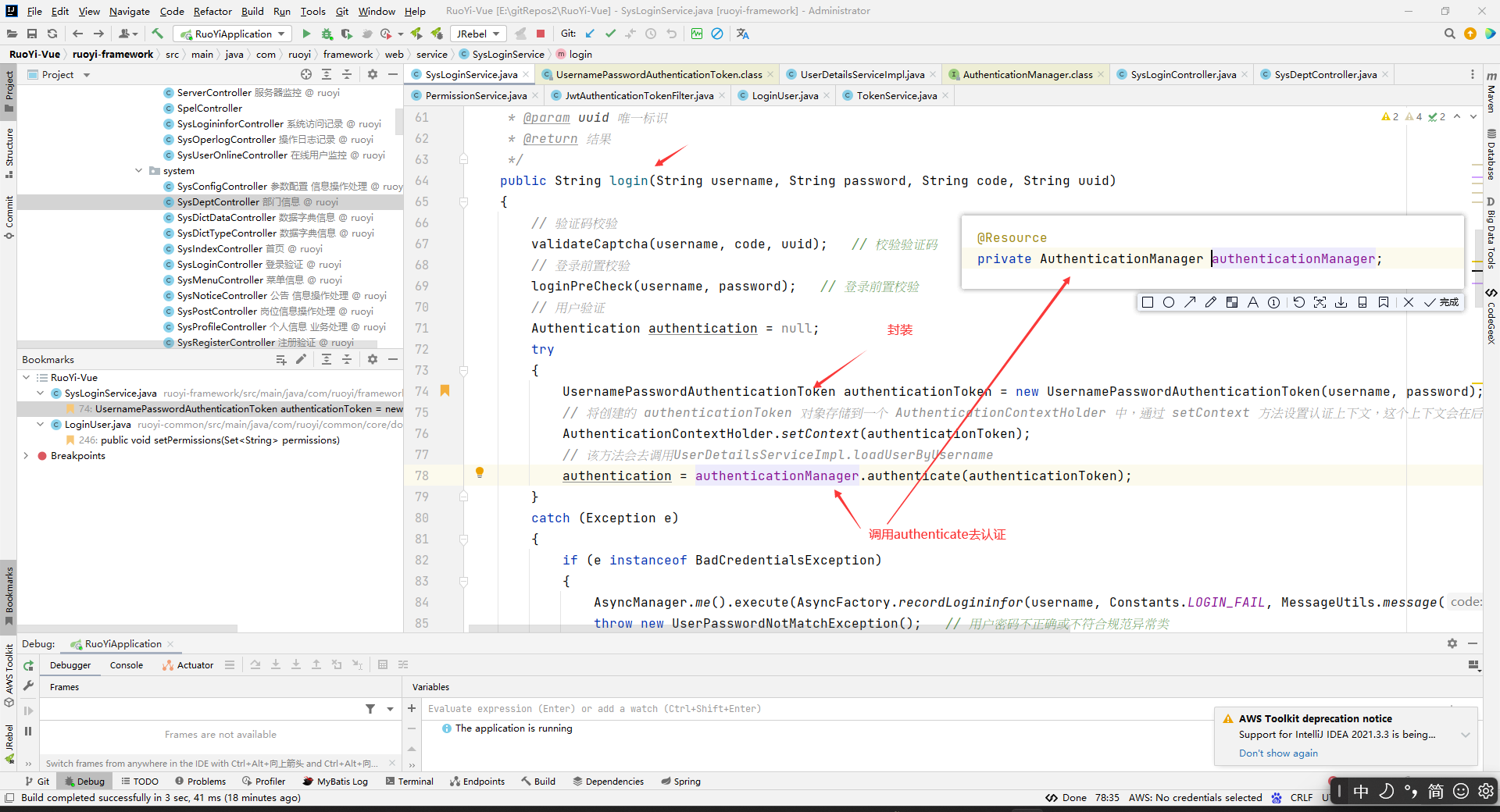
然后这个authenticationManager.authenticate(authenticationToken);方法内部会去调用我们写的UserDetailsServiceImpl的loadUserByUsername方法。具体是怎么去调用这个方法的我就不研究了。
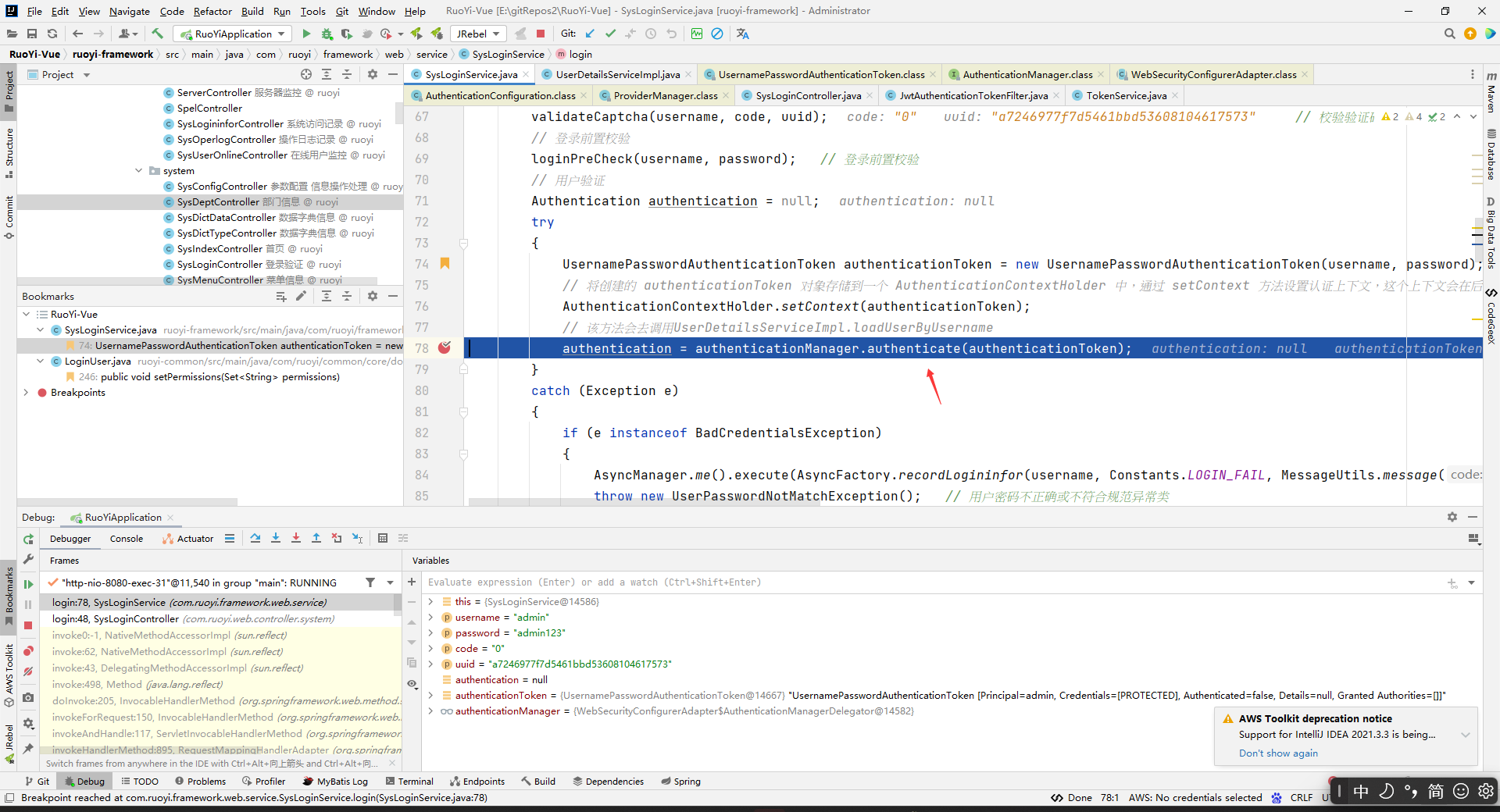
反正我在authenticationManager.authenticate(authenticationToken);和loadUserByUsername(String username)方法上面打了断点,debug的时候会看到先执行authenticationManager.authenticate(authenticationToken);,然后再执行loadUserByUsername(String username)方法,然后再执行authenticationManager.authenticate(authenticationToken);后面的语句。所以已经可以论证上面的结论了。
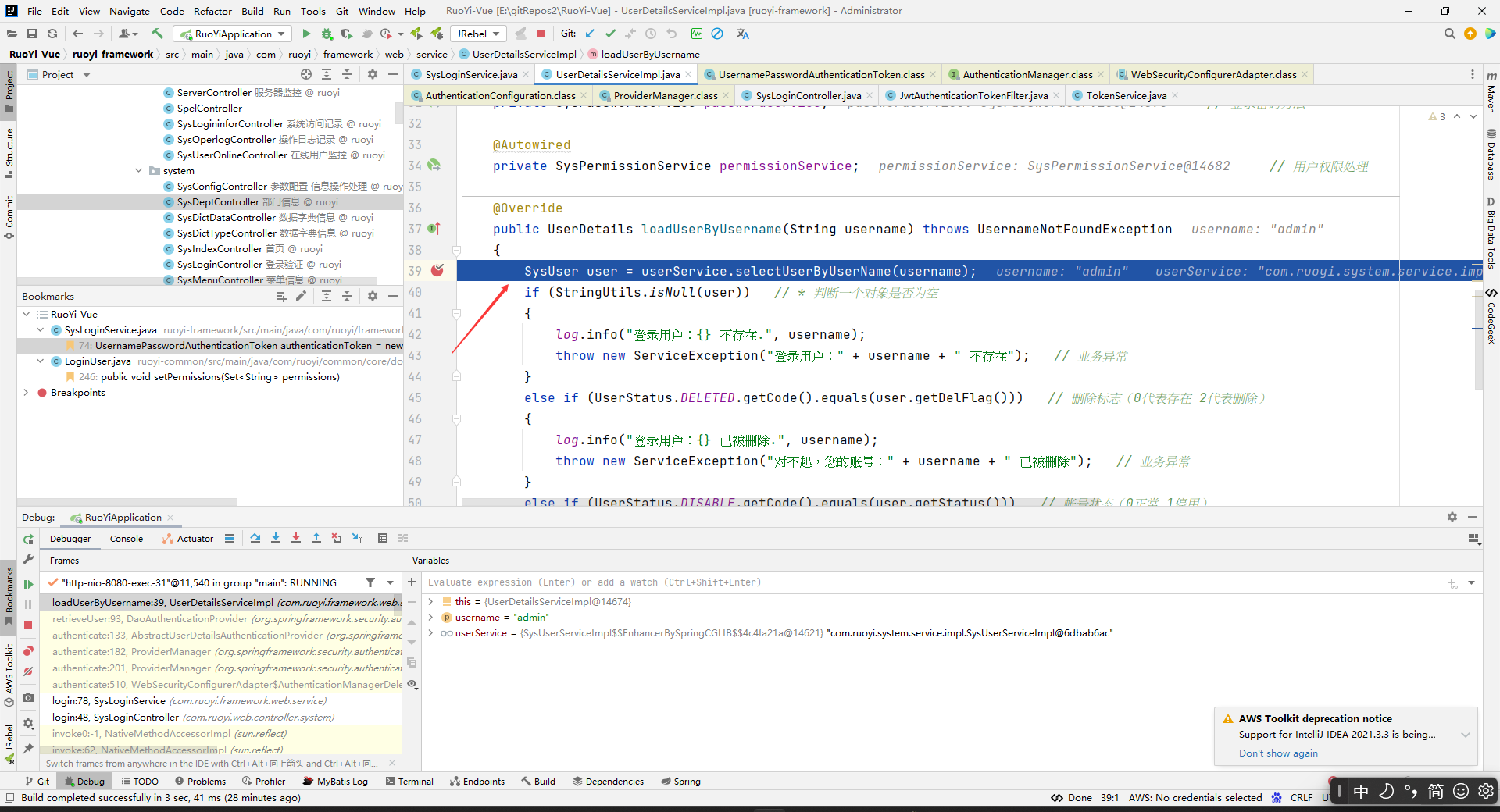
接下来我们看看这个loadUserByUserName方法。
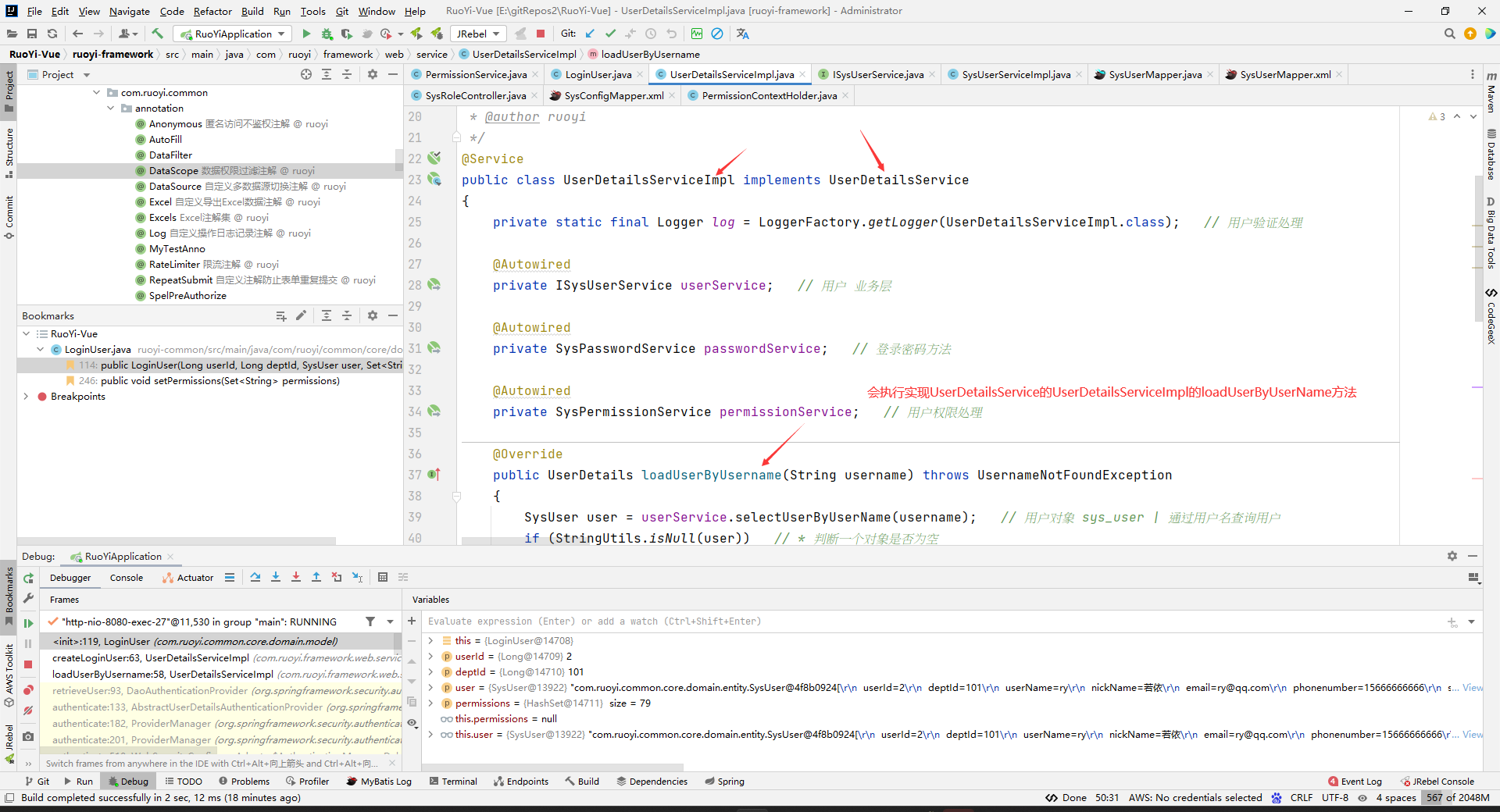
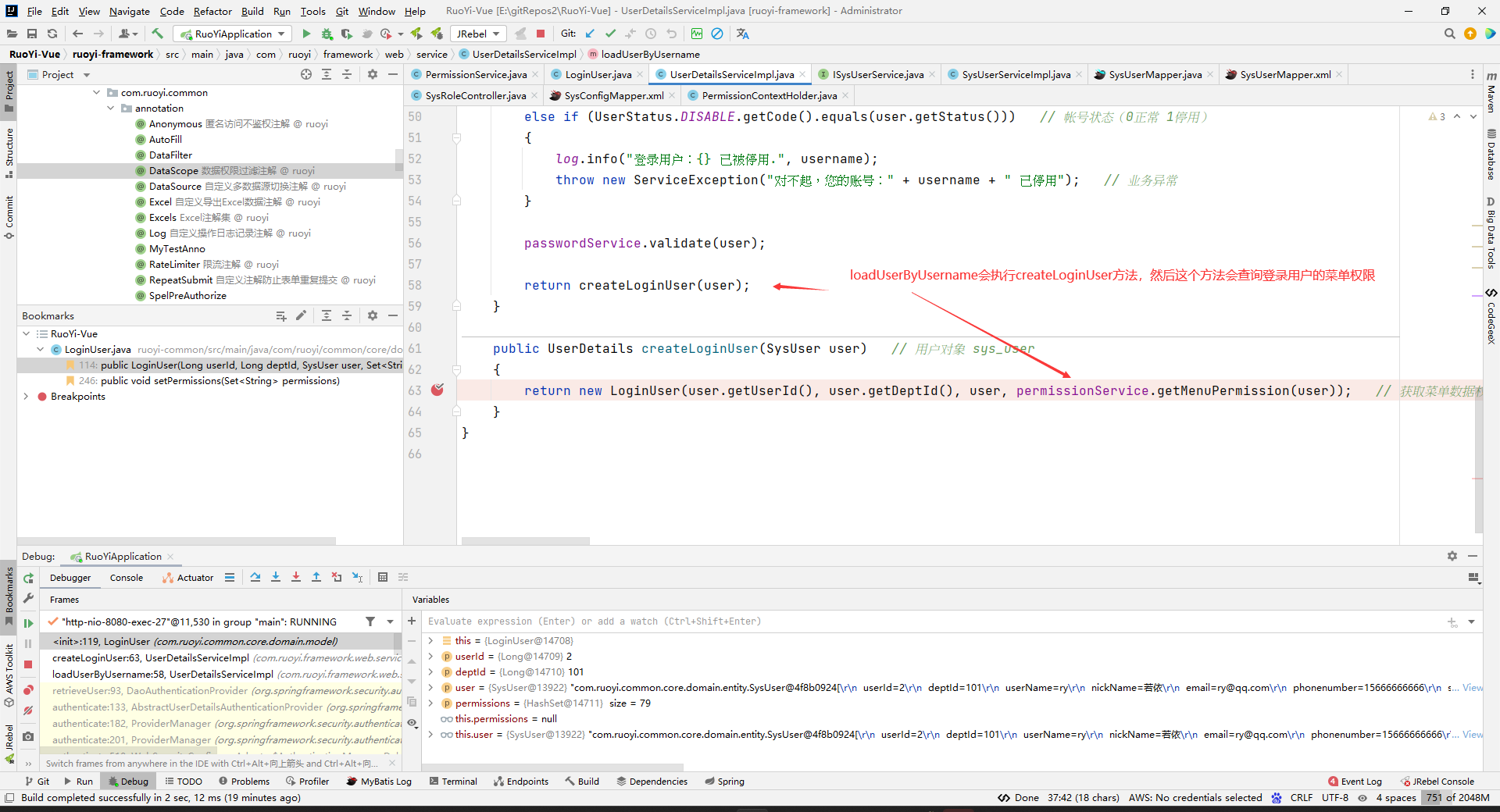
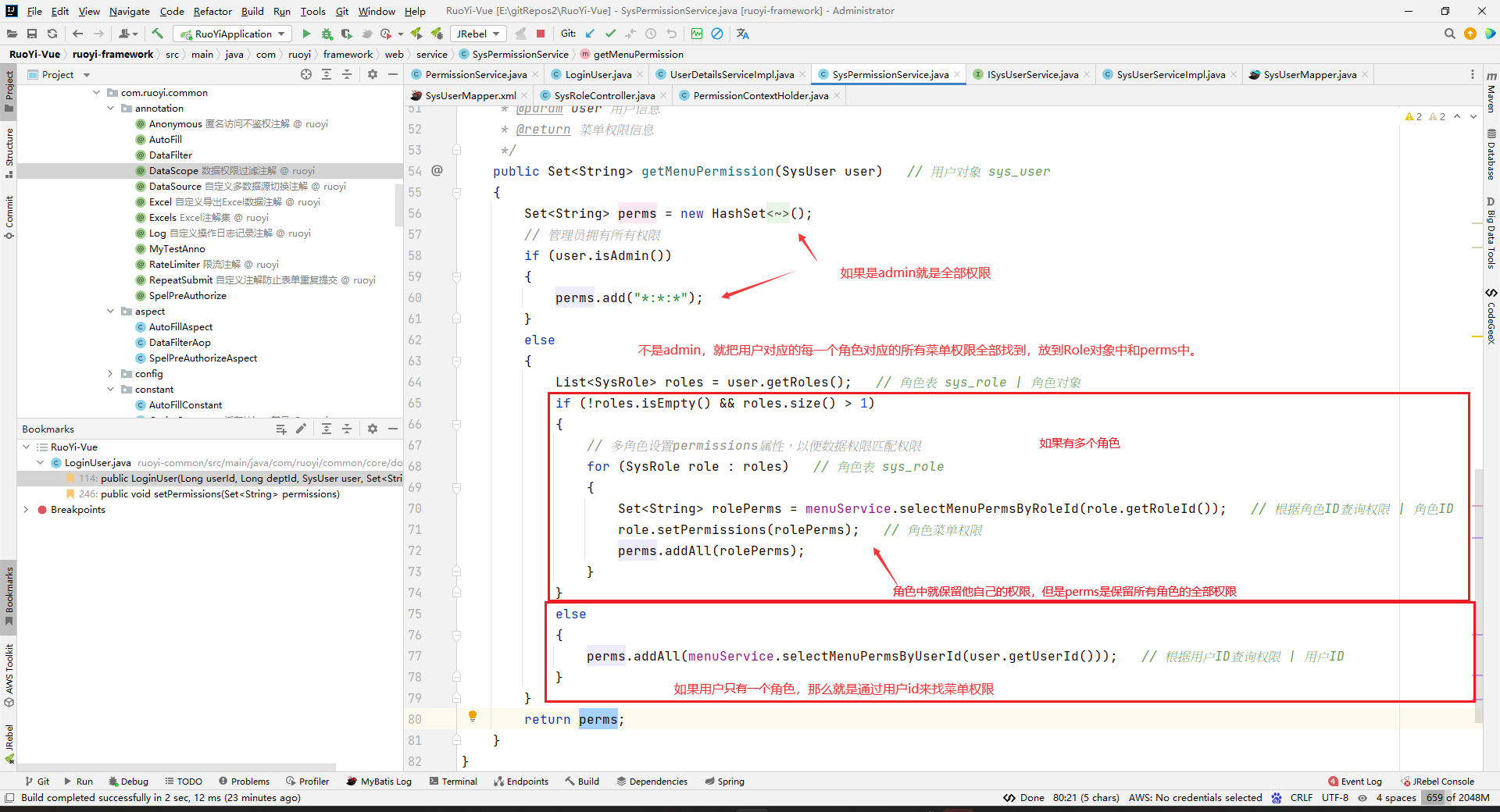
逗号可能是,因为ruoyi考虑到勾选某个多选框后可以拥有多个权限吧,然后多个权限之间用逗号分隔开。
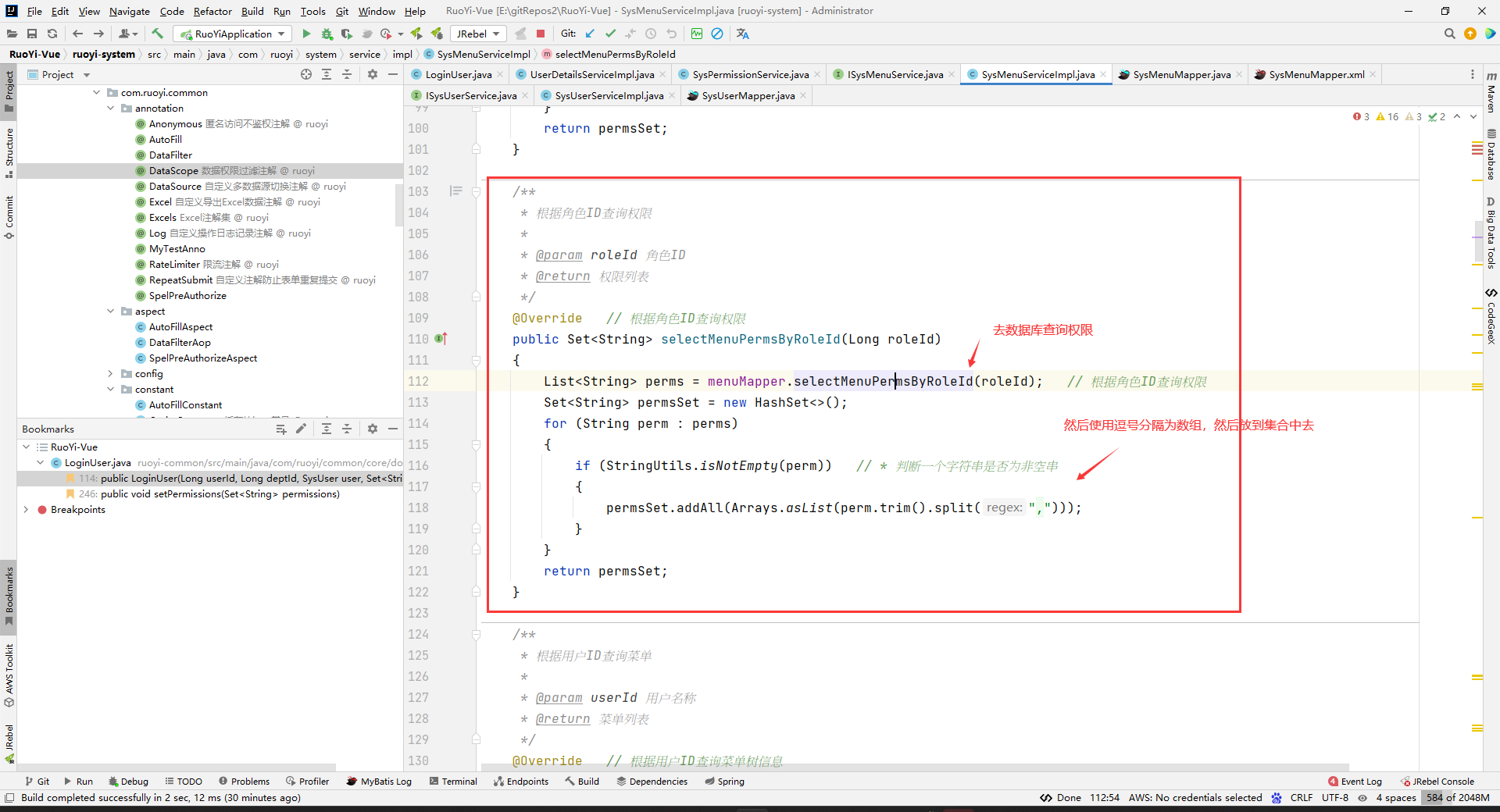
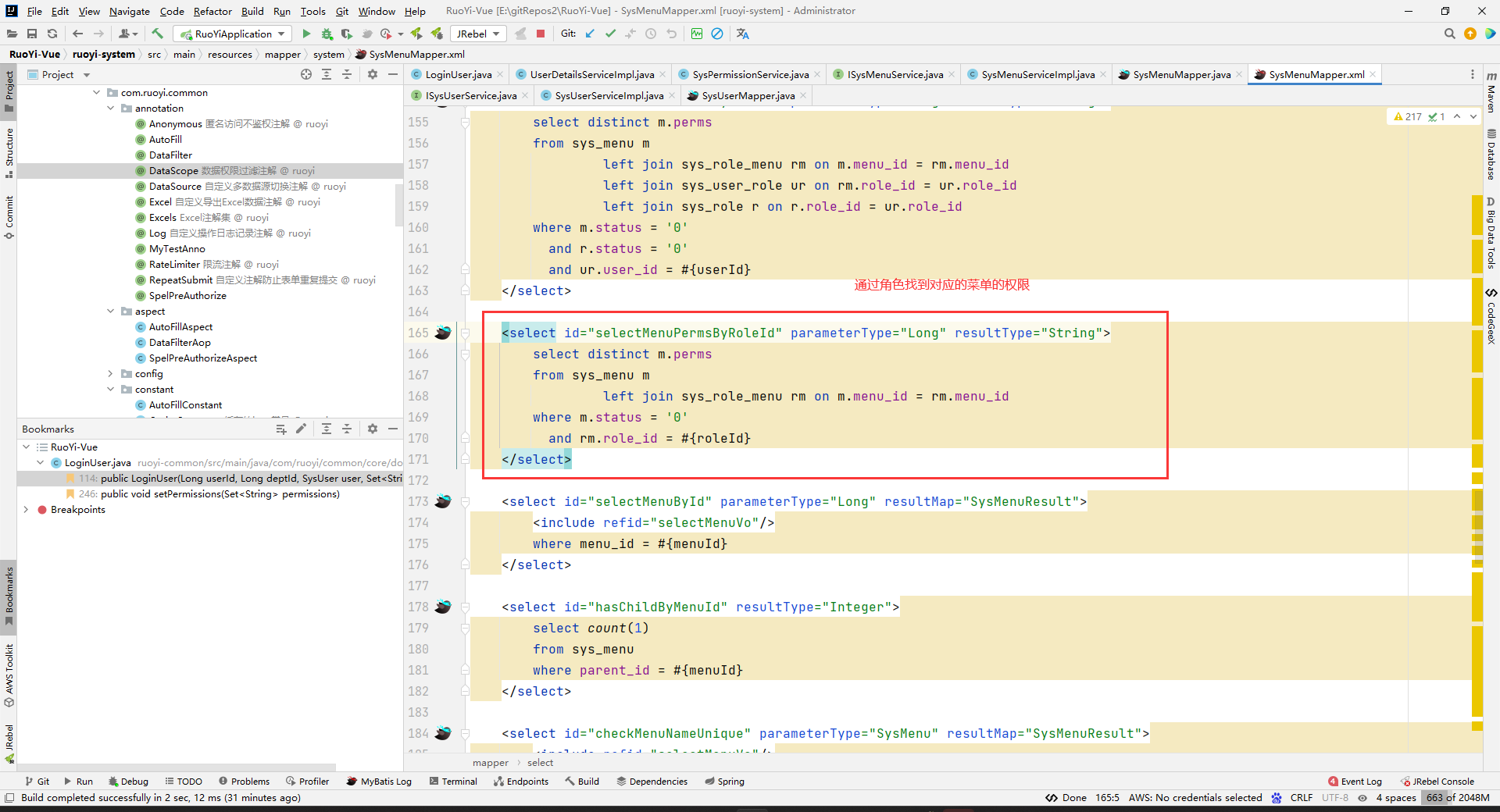
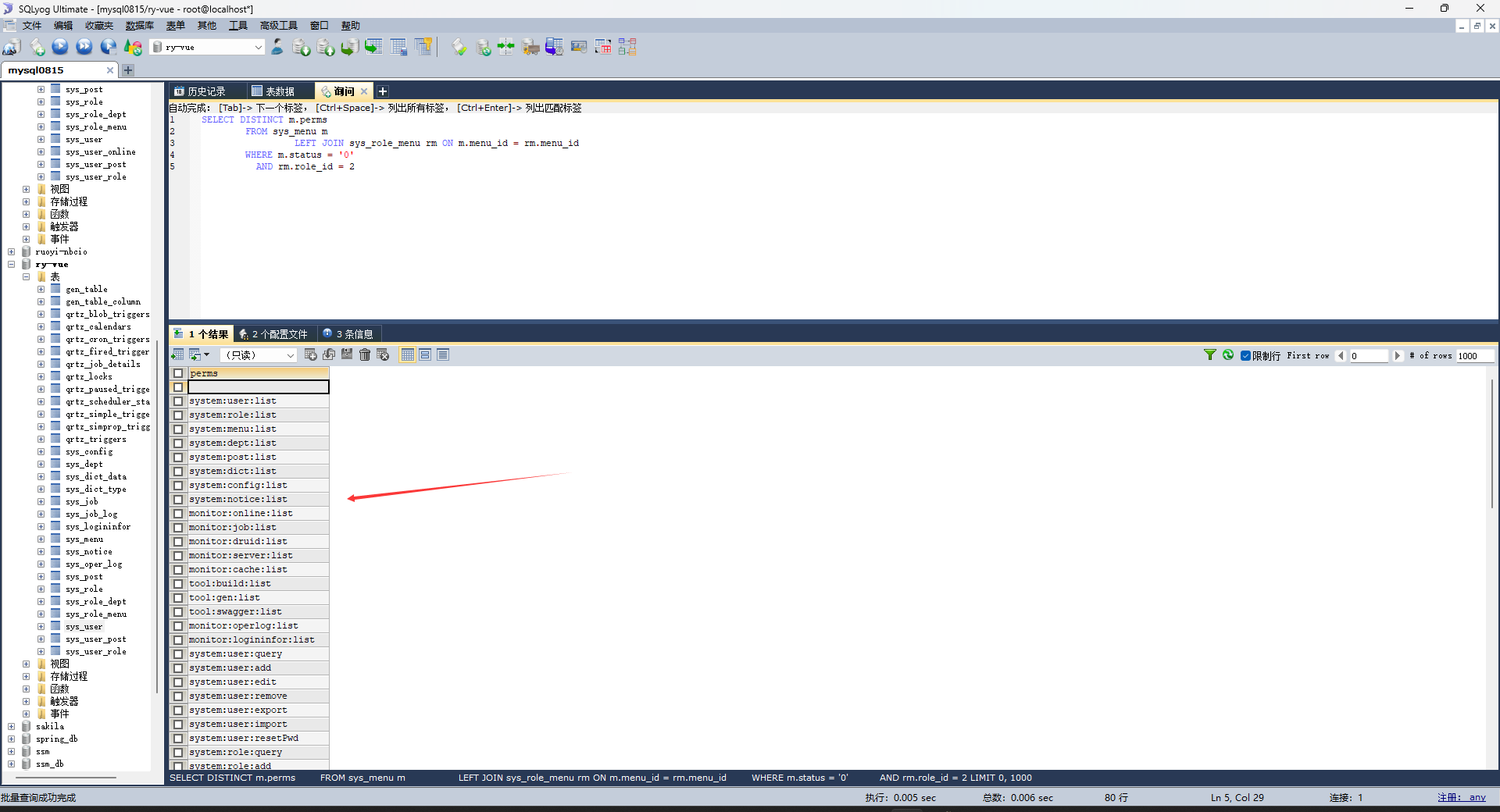
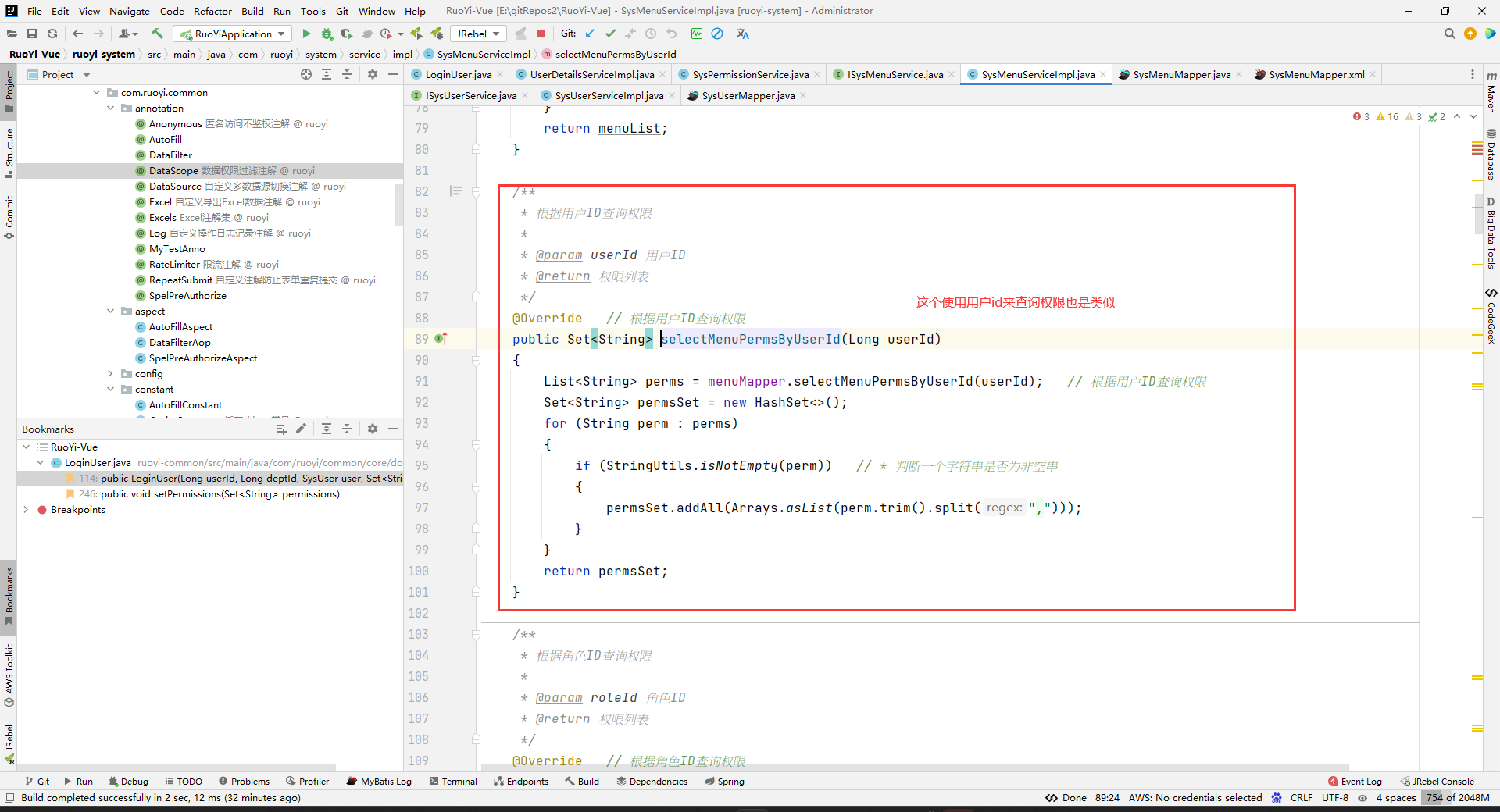
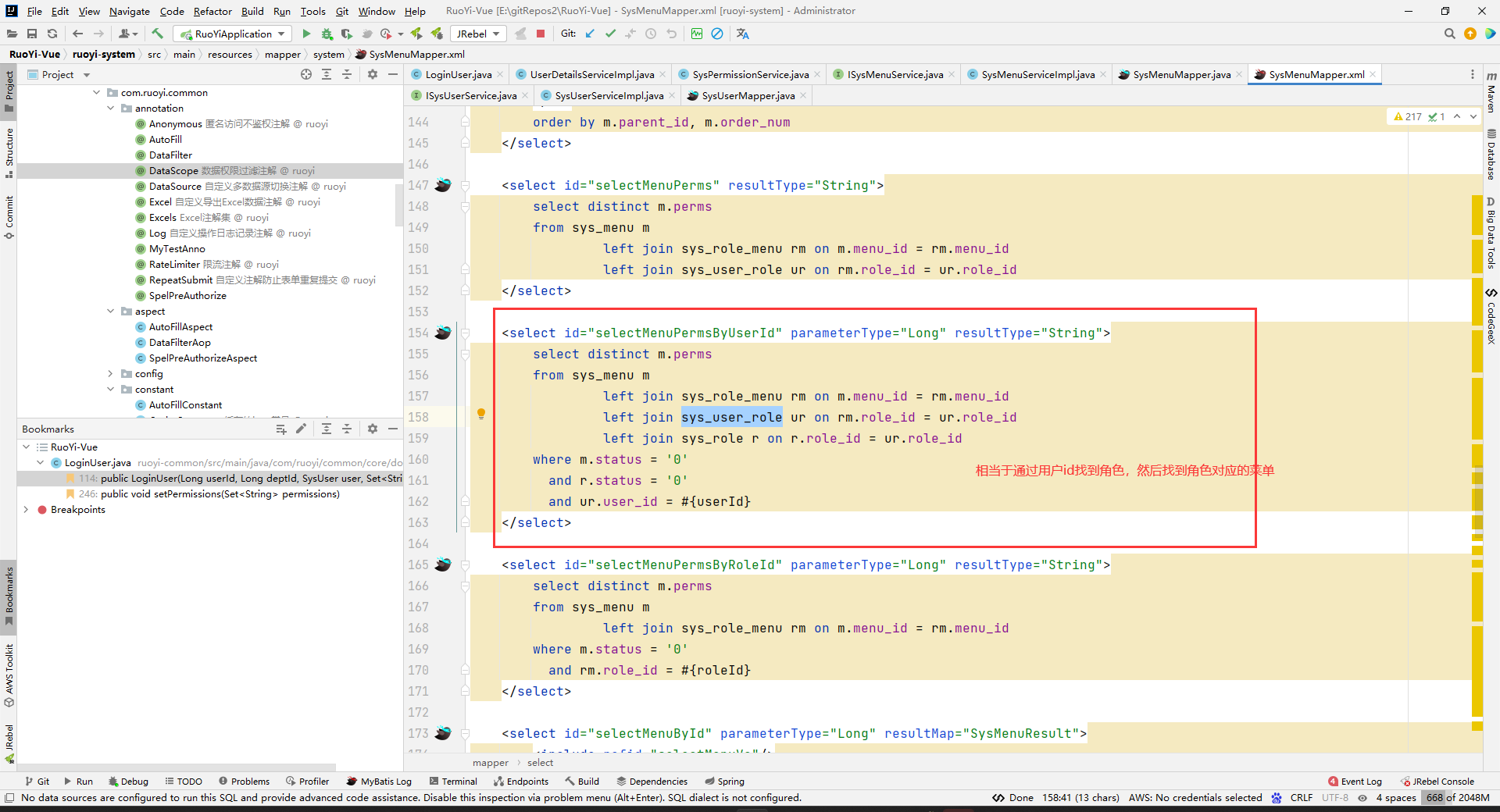
然后就拿到这个用户对应的所有权限了(菜单权限和操作权限都有):
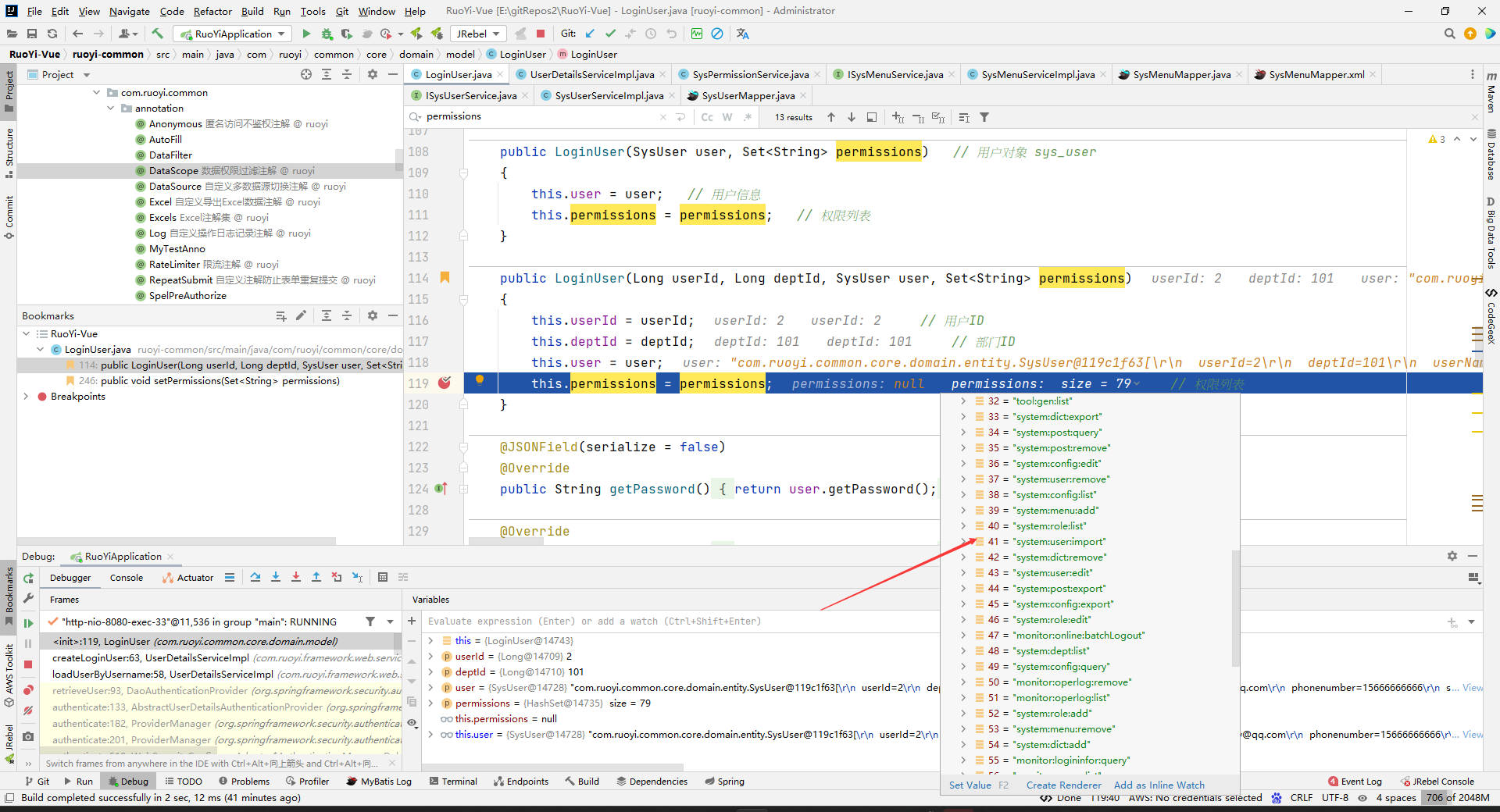
并且保存到LoginUser中去了(是指把所有角色的所有权限,都保存到这个LoginUser的permissions中去)。
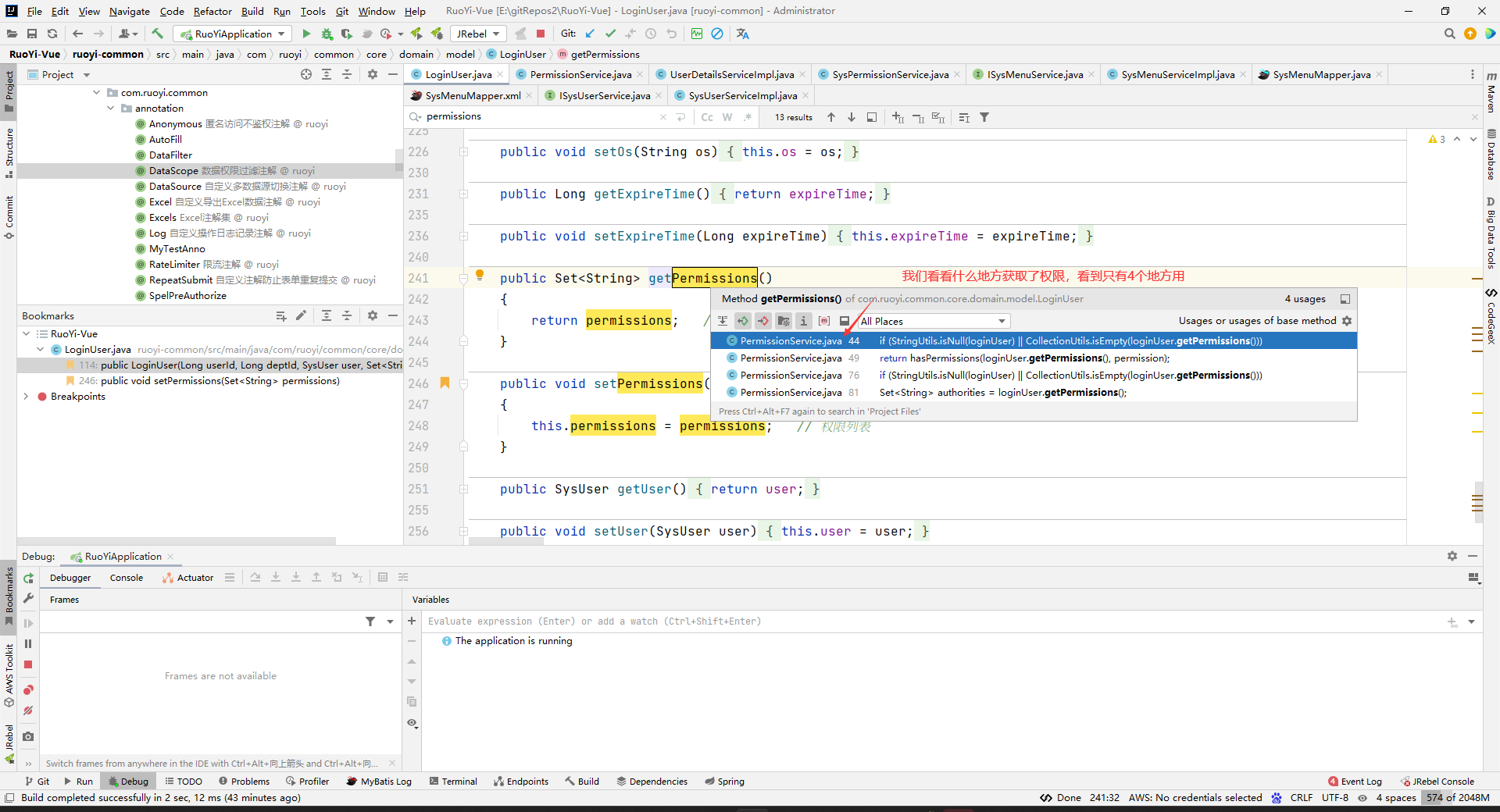
这样,loadUserByUsername方法就返回了一个带权限的LoginUser了。
这里说的LoginUser其实就是UserDetail,下面这个loadUserByUsername()方法的执行:
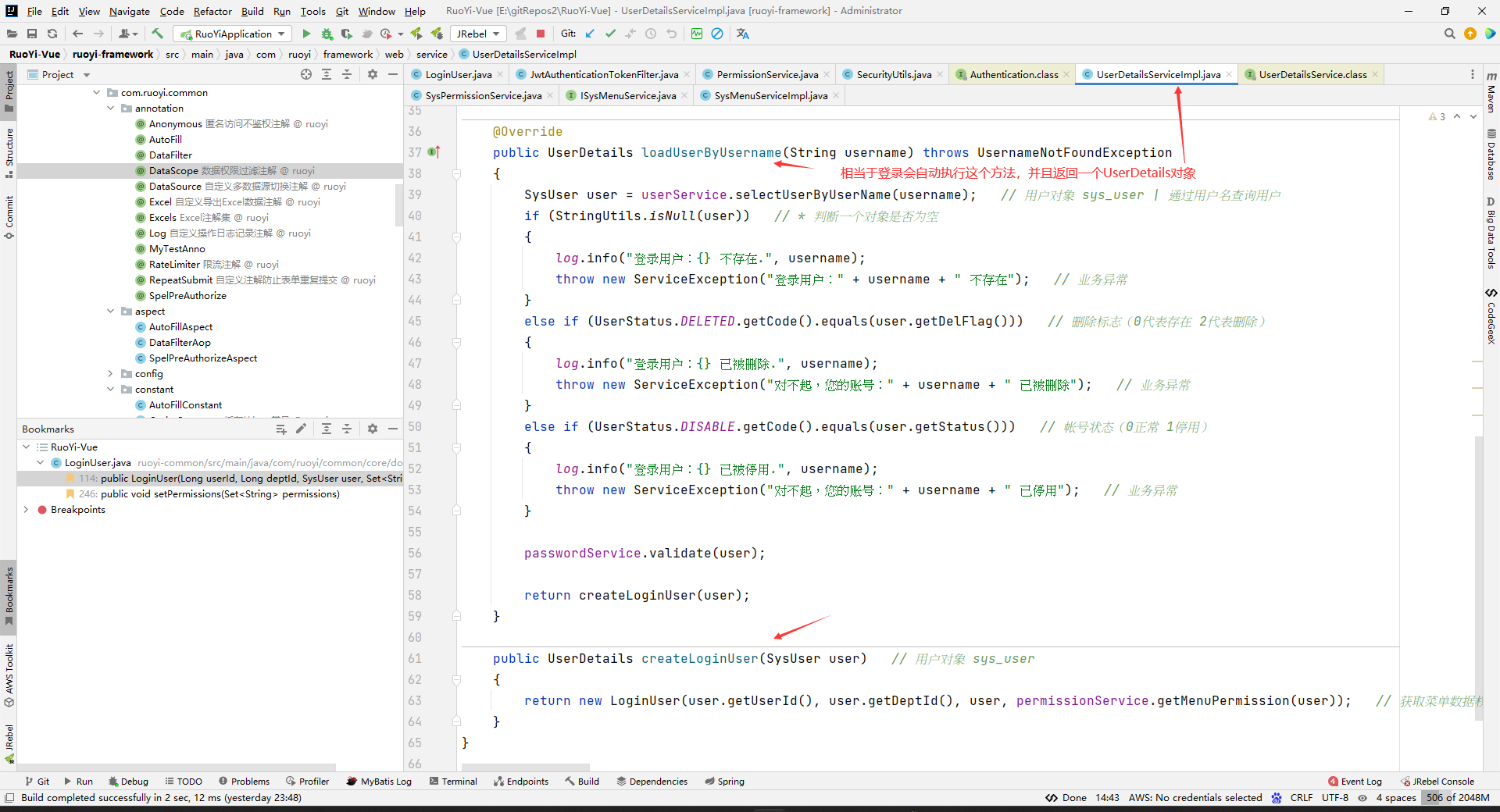
其实就是相当于下面这一步:
ok,就得到论证了我们的结论,即“authenticationManager.authenticate(authenticationToken)执行的时候会把数据库中的对应的用户数据找到放到LoginUser中”。