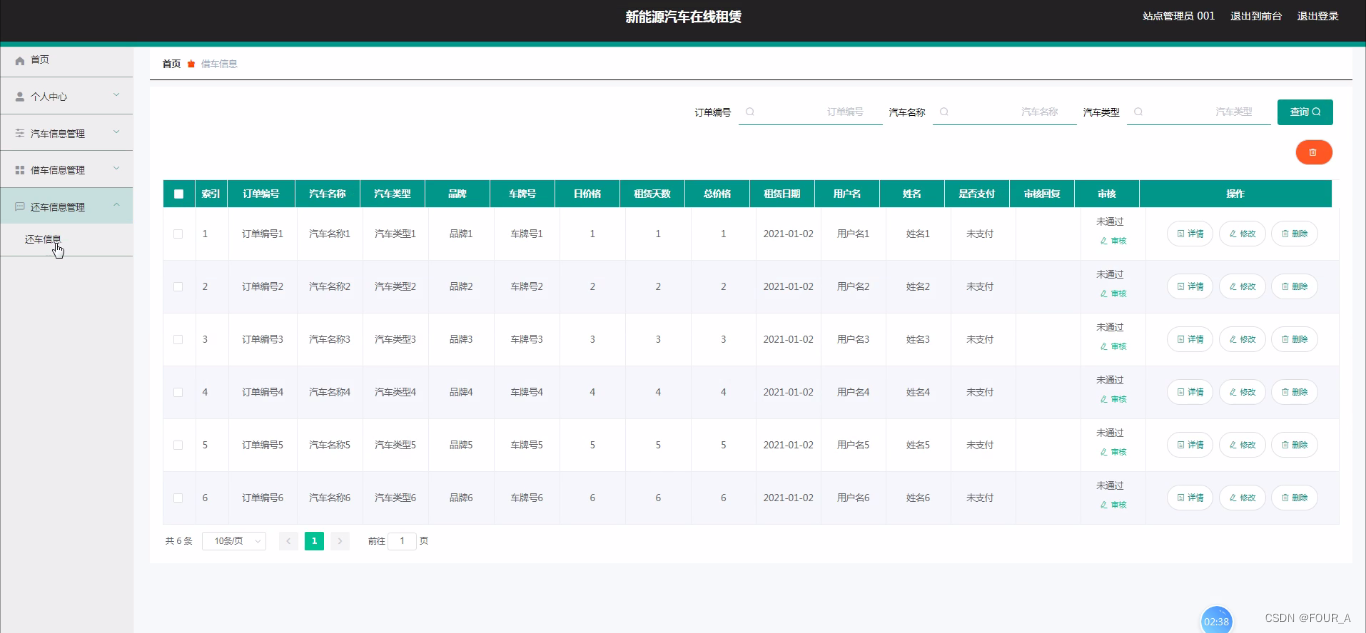
©PaperWeekly 原创 · 作者 | 杨凌霄
单位 | 上海科技大学信息学院

论文标题:
Guidance with Spherical Gaussian Constraint for Conditional Diffusion
论文作者:
杨凌霄、丁枢桐、蔡逸凡、虞晶怡、汪婧雅、石野
通讯作者:
石野
论文链接:
https://arxiv.org/abs/2402.03201
代码链接:
https://github.com/LingxiaoYang2023/DSG2024

摘要
最近的 Guidance 方法试图通过利用预训练的扩散模型实现损失函数引导的、无需训练的条件生成。虽然这些方法取得了一定的成功,但它们通常会损失生成样本的质量,并且只能使用较小的 Guidance 步长,从而导致较长的采样过程。
在本文中,我们揭示了导致这一现象的原因,即采样过程中的流形偏离(Manifold Deviation)。我们通过建立引导过程中估计误差的下界,从理论上证明了流形偏离的存在。
为了解决这个问题,我们提出了基于球形高斯约束的 Guidance 方法(DSG),通过解决一个优化问题将 Guidance 步长约束在中间数据流形内,使得更大的引导步长可以被使用。
此外,我们提出了该 DSG 的闭式解(Closed-Form Solution), 仅用几行代码,就能够使得 DSG 可以无缝 地插入(Plug-and-Play)到现有的无需训练的条件扩散方法,在几乎不产生额外的计算开销的同时大幅改 善了模型性能。我们在各个条件生成任务(Inpainting, Super Resolution, Gaussian Deblurring, Text- Segmentation Guidance, Style Guidance, Text-Style Guidance, and FaceID Guidance)中验证了 DSG 的有效性。


背景:无需训练的条件扩散模型Classifier guidance 首先提出使用预训练的扩散模型进行条件生成。它利用贝叶斯公式 ,通过引入额外的似然项 来实现条件生成:
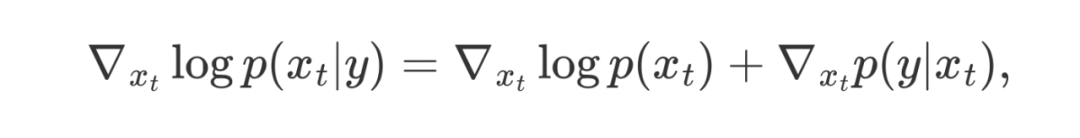
目前无需训练的方法,将 time-dependent classifier 替换成某个定义在 上的可微损失函数 , 并利用 Tweedie’s formula 求解额外的似然项:
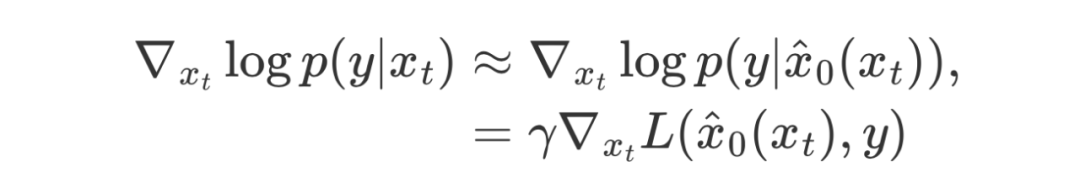
这里 表示加噪 t 步的 data, 表示引导步长。因此,总体的采样过程可以被写成
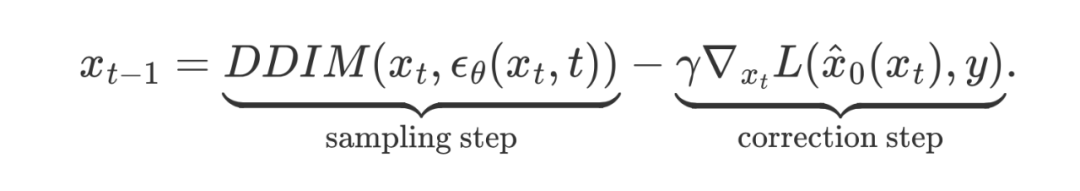

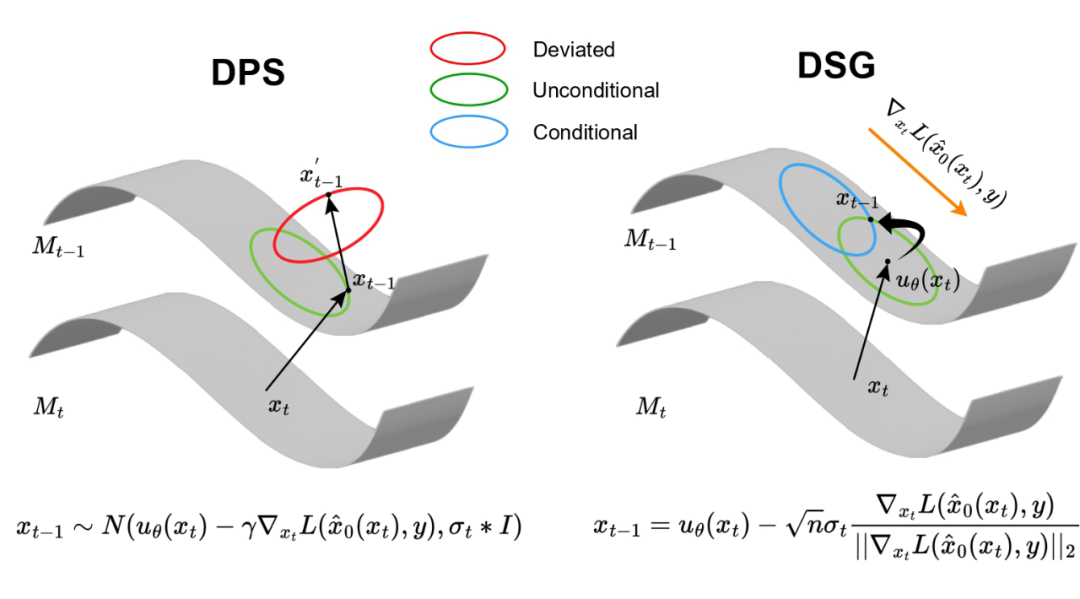
损失函数引导过程中的流形偏离(Manifold Deviation)
尽管先前的工作由于其灵活的特性在各种条件生成任务中取得了巨大成功,但它们会牺牲生成样本的质量。在本文中,我们提出这种现象产生的原因是线性流形假设(Linear Manifold Assumption)和 Jensen Gap 导致的流形偏离:
1. 线性流形假设:线性流形假设是一个相当强的假设,因此在实践中通常会引入误差。
2. Jensen Gap:在实际情况下, 的分布是未知的,将其简单地用 Tweedie’s formula 的估计均值替代会引入 Jensen Gap:

本文指出,即使 DPS 提供了 Jensen Gap 的上界,它仍然具有下界,也会引入估计误差:
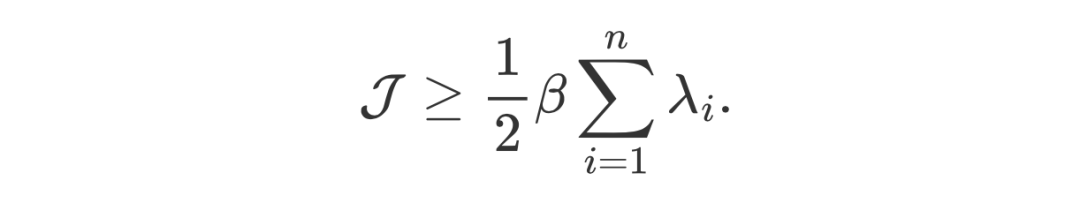

基于球面高斯约束引导的条件扩散模型(DSG)
既然无论 Jensen Gap 还是线性流形假设都会不可避免地引入估计误差,那么为什么不在已经无条件的中间数据流形(Intermediate Data Manifold)中,找到那个最接近条件采样的点呢?
因此,我们提出了 DSG(Diffusion with Spherical Gaussian constraint);一种在无条件中间流形的高 置信区间内进行 Guidance 的优化方法:
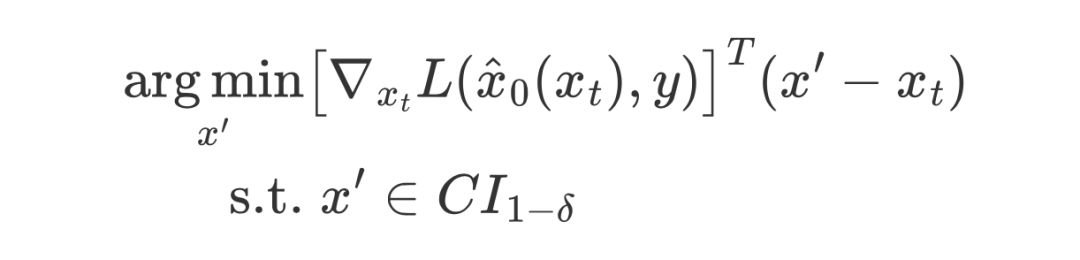
这里 表示高斯分布的概率为()的置信区间。在这个优化问题中目标函数倾向于让采样过程在 梯度下降方向进行,约束则是将采样约束在高斯分布的高置信区间。
然而,当高置信区间包含 n 维空间中时,优化问题就变得具有挑战性。幸运的是,高维各向同性高斯分布的高置信区间集中在一个超球上,我们可以通过用这个超球近似它来简化约束,称为球面高斯约束(Spherical Gaussian Constraint):
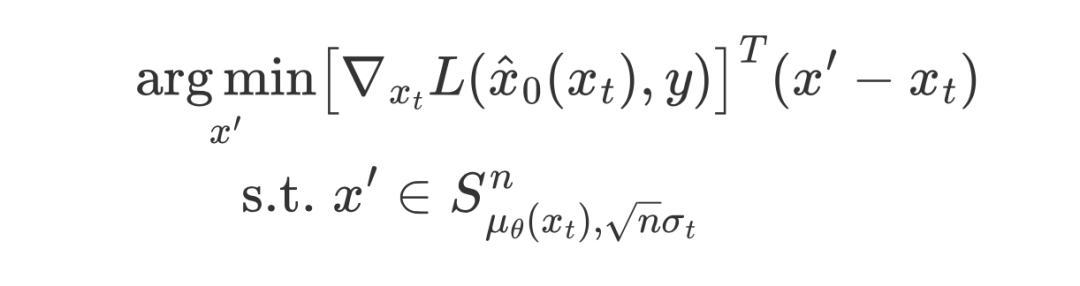
这里
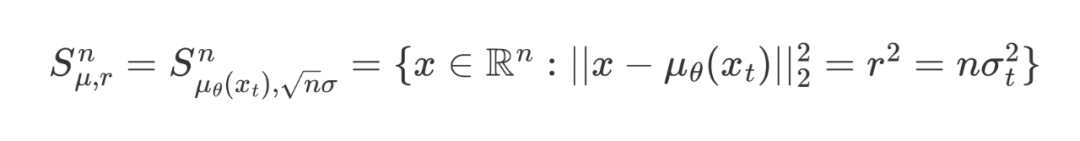
表示 n 维高斯分布近似的超球。通过这种近似方法,我们能够得到优化问题的闭式解:

这个闭式解的求得能够表明,DSG 可以无缝插入目前的无需训练的条件扩散模型,如 DPS、Freedom、UGD,而不造成额外的计算复杂度。并且,只需要修改几行代码就能够产生更好的样本和达到更快的推理速度。
另外,从另一个角度看,DSG 也可以看成在预测均值 上进行梯度下降。而且,由于 与 正相关,DSG 可以看作是自适应的梯度下降方法,在一开始下降步长大,在最后下降步长小。在实验中,我们发现 DSG 最大的步长能够达到 DPS 的 400 倍,因此能够在更小的 DDIM steps 下相比于 DPS 更加鲁棒。
此外,我们发现 DSG 虽然增强了对齐能力和真实性,但是在多样性方面有所损失。因此,我们对原始采样方向和梯度下降方向的进行加权,就像 Classifier-free Guidance 那样:

这里 表示无条件采样方向, 表示最速梯度下降方向。另外, 会被缩放以满足球面高斯约束。
算法流程图如下:


实验结果
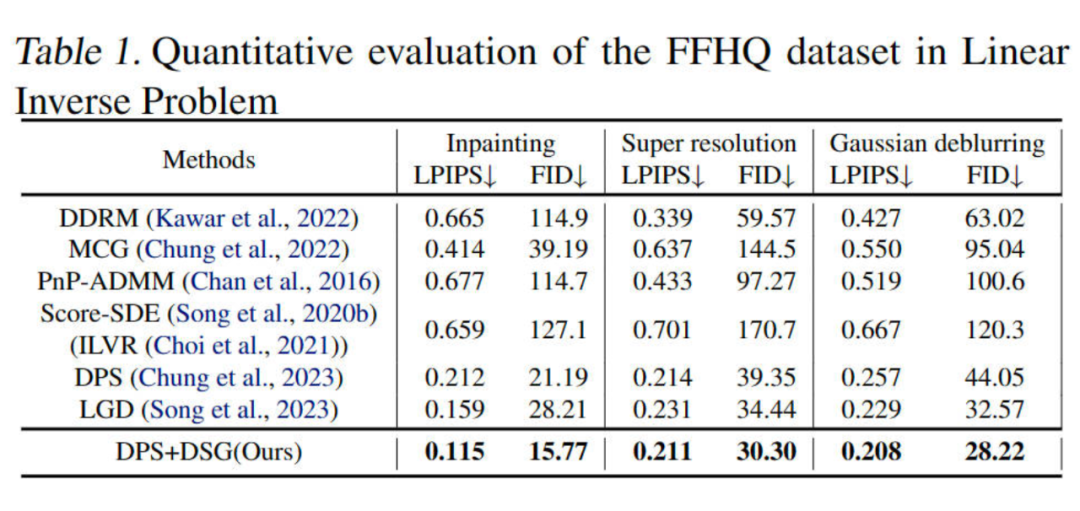
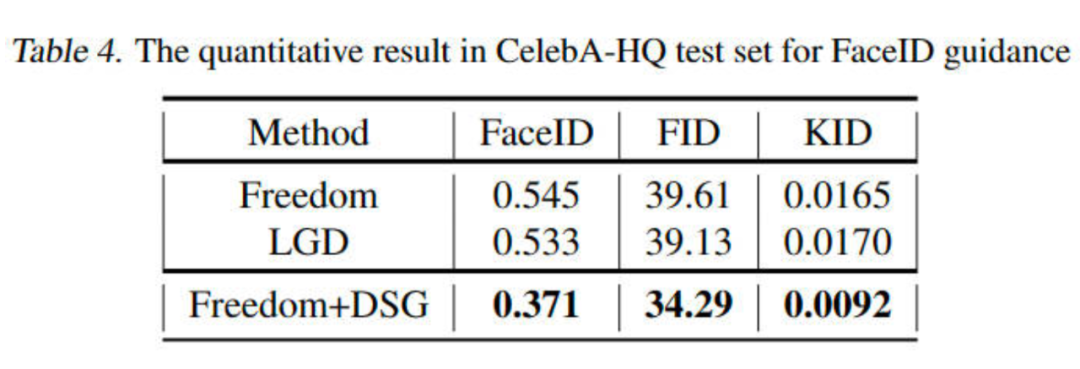
我们验证了 DSG 在各个任务上的性能都能够显著地超过 baseline。
Linear Inverse Problems in FFHQ with DDIM steps=1000
Linear Inverse Problems in FFHQ with DDIM steps=100,50,20
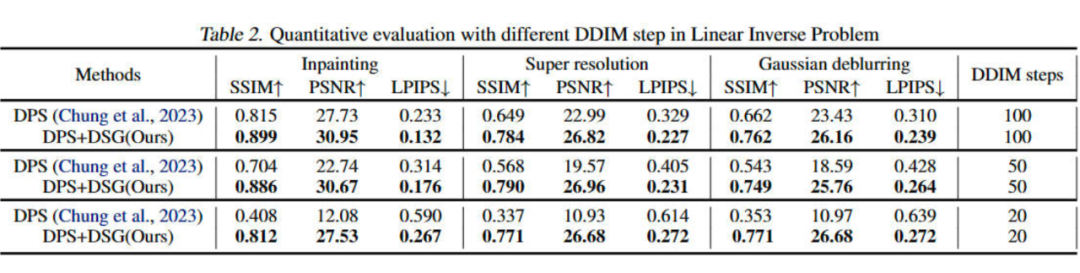


可以看到,DPS+DSG 在 DDIM steps=1000,100,50,20 都远超 DPS,并且在 DDIM steps 较小的时候能够观察到与 DPS 更大的性能差距。这种现象可归因于 DPS 的局限性,即为了不远离流形使用的小步长。因此,随着 guidance 步数的减少,测量结果的对齐变得越来越具有挑战性。
相比之下,我们的模型在性能上只有轻微的下降。这是因为 DSG 允许更大的步长,同时仍然保留在中间流形上。因此,即使减少了去噪步骤,我们仍然可以在生成真实样本的同时实现与测量结果的精确对齐,如图 6 所示。
FaceID Guidance in Celeba-HQ

Text-Segmentation Guidance

Style Guidance
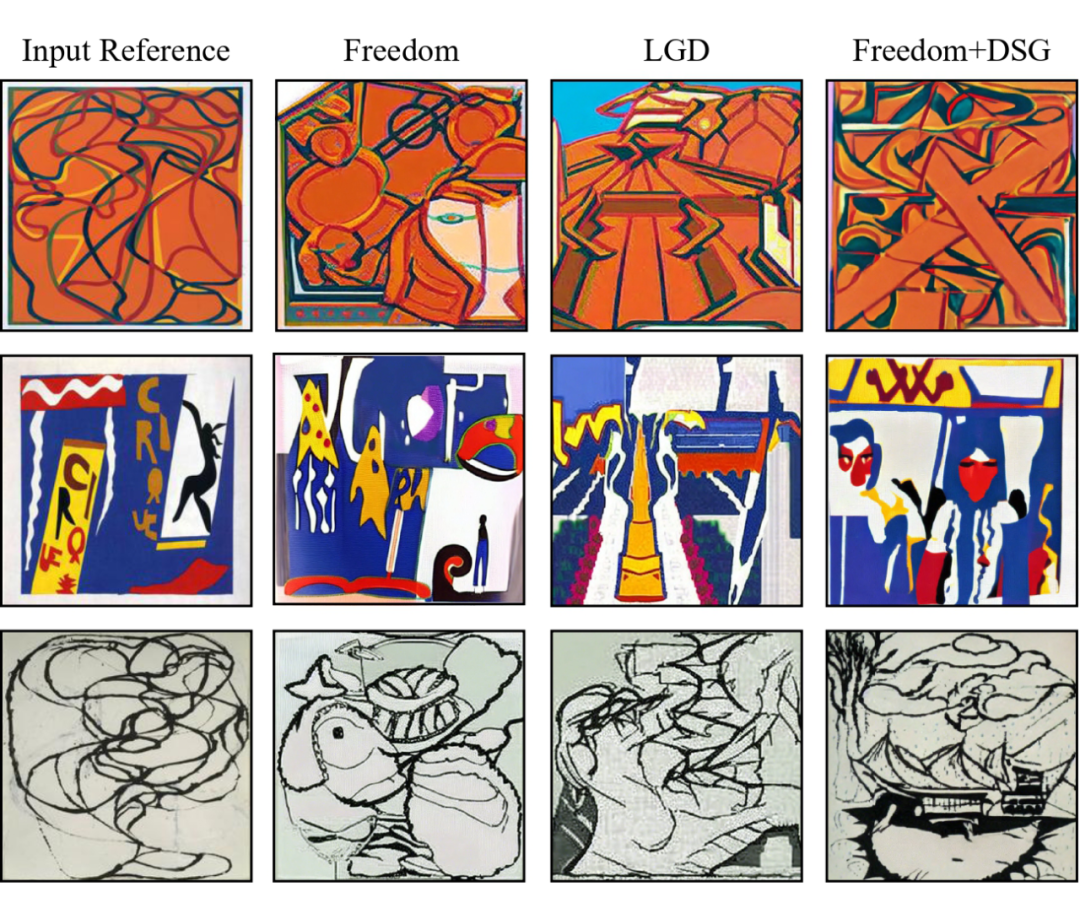
Text-Style Guidance

Other Tasks
由于篇幅限制,更多实验结果、实验设置请查看原文以获取更多细节。
总结
在本文中,我们揭示了无需训练的条件扩散模型中的一个关键问题:在使用基于损失函数的引导时,在采样过程中会出现流形偏移现象。为解决这一问题,我们提出了一种基于球面高斯约束引导的条件扩散(DSG)方法,灵感来源于高维高斯分布中的集中现象。DSG 通过优化有效地限制引导步骤在中间数据流形内,从而减轻流形偏移问题,并能够使用更大的引导步长。
此外,我们为基于球形高斯约束的 DSG 去噪过程提供了一个封闭形式的解决方案。(CDM)。将 DSG 整合到这些 CDM 中,仅涉及修改几行代码,几乎不增加额外的计算成本,但却显著提高了性能。我们已将 DSG 整合到几个最新的 CDM 中,用于各种条件生成任务。实验结果验证了 DSG 在样本质量和时间效率方面的优越性和适应性。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·