目录标题
- 1,UNION和JOIN的区别
- 2,连续登录问题
- 3,窗口函数和普通聚合函数的区别
- 4,窗口函数的基本用法
- 5,序号函数:row_number(),rank(),dense_rank()的区别
- 6,窗口函数涉及的一些其他函数
- 7,次日留存率
- 8,sql如何进行优化
- 9,SQL常用函数
- 10,SQL掌握运用的程度?--类似概述一下SQL的知识点
- 11,SQL中如何去重?
- 12,SQL代码题:行、列转换
1,UNION和JOIN的区别
UNION是两张表进行上下拼接,JOIN 是两张表进行左右连接。
UNION分为UNION和UNION ALL两种方法,拼接时要求两表的列一样
JOIN是将条件匹配的两表记录将合并产生一个记录集,有LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN等多种方法。
2,连续登录问题

有连续三天以上访问记录的用户id
select distinct usr_id from
(select usr_id,DATE_SUB(log_dte,initerval rank_id DAY) as flg_dte
from
(select usr_id,log_data,dense_rank()over(partition by usr_id order by log_dte) rank_id from log_table)A
group by usr_id,flg_dte
having count(distinct log_dte)>=3) B
思路:select 去重 id
(select 新增一列,原日期+排序 as flg_dte
(select 借用聚合函数分组排序)A
按flg_dte分组 ,筛选计数大于等于3的
) B
3,窗口函数和普通聚合函数的区别
1,聚合函数是将多条记录聚合为⼀条;窗⼝函数是每条记录都会执行,有几条记录执行完还是几条
2,聚合函数也可以⽤于窗⼝函数。
窗⼝函数的执⾏顺序(逻辑上的)是在FROM,JOIN,WHERE, GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT之前
注意:
窗口函数是在where之后执行的,所以如果where子句需要用窗口函数作为条件,需要多⼀层查询,在子查询外面进行
4,窗口函数的基本用法
over关键字用来指定函数执行的窗口范围,若后⾯括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则⽀持以下4中语法来设置窗⼝。
- window_name:给窗口指定⼀个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读
- partition by子句:窗口按照哪些字段进⾏分组,窗⼝函数在不同的分组上分别执⾏
- order by子句:按照哪些字段进⾏排序,窗⼝函数将按照排序后的记录顺序进⾏编号
- frame子句:frame是当前分区的⼀个子集,子句⽤来定义子集的规则,通常⽤来作为滑动窗⼝使⽤
5,序号函数:row_number(),rank(),dense_rank()的区别
ROW_NUMBER():顺序排序——1、2、3 row_number()
RANK():并列排序,跳过重复序号——1、1、3 rank()
DENSE_RANK():并列排序,不跳过重复序号——1、1、2 dense_rank()
6,窗口函数涉及的一些其他函数
分布函数:percent_rank(),cume_dist()
前后函数:lag(expr,n),lead(expr,n)
头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr)
7,次日留存率
次日,7日,30日留存率问题都是重中之重的考点,之前写的问题中分析过
#两次dense_rank()是为了找注册人数,登录人数
with t1 as (
select tu.id,t1.uid,date(tu.register_time) reg_date,date(t1.login_time) log_date,
dense_rank()over(partition by date(tu.register_time) order by tu.id) daily_reg,
dense_rank()over(partition by date(tu.register_time),date(t1.login_time) order by tu.id) daily_login
from t_user tu
left join t_user_login t1 on (t1.uid = tu.id and (date(t1.login_time) = date(tu.register_time)+ interval '1' day
or date(t2.login_time) = date(tu.register_time)+ interval '2' day))
)
t2 as (
select reg_date,login_date,max(daily_reg),max(daily_login)
from t1
group by reg_date,login_date
)
select reg_date,max(daily_reg),
100*max(case when login_date = reg_date +interval '1' day then daily_login end)/max(daily_reg) rr1
from t2
group by reg_date;
8,sql如何进行优化
sql优化看运⾏环境,可以分为mysql和Hive,前者是数据库查询优化,后者基于MapReduce。互联⽹分析师更多是基于Hive查询数据,所以下⽂针对Hive如何优化进⾏分析。
(1) 理解数据仓库的分层和数据粒度是⾸要的。因为相⽐于与数据库是为了数据的储存,更新⽽设计的,数据仓库则是更多为了数据的查询。针对具体的业务需求,选择合适的数据粒度,是sql优化的基础。例如选择⽤户粒度的Hive表,比起访问pv粒度的Hive表,数据量要⼩很多,sql查询也更快。
(2) 针对典型的问题,例如数据倾斜。
产⽣原因
1.group by维度过小,某值的数量过多(后果:处理某值的reduce⾮常耗时)
2.去重
distinct count(distinct xx) 某特殊值过多(后果:处理此特殊值的reduce耗时)
3.连接
join,count(distinct),group by,join等操作,这些都会触发Shuffle动作,⼀旦触发,所有相同key的值就会拉到⼀个或⼏个节点上,就容易发⽣单点问题。
(2)解决方案
1.业务逻辑:例如我们从业务上就知道在做group by时某些key对应数据量很⼤,我们可以单独对这些key做计算,再与其他key进行join
2.Hive参数设置:
设置hive.map.aggr = true 在map中会做部分聚集操作,效率更高但需要更多的内存设置hive.groupby.skewindata=true 数据倾斜时负载均衡,当选项设定为true,⽣成的查询计划会有两个MRJob。第⼀个MRJob中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从⽽达到负载均衡的⽬的;第⼆个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同⼀个Reduce中),最后完成最终的聚合操作。
(3)查询语句优化:
1.在count(distinct) 操作前先进⾏⼀次group by,把key先进⾏⼀次reduce,去重
2.map join:使⽤map join让⼩的维度表(1000 条以下的记录条数)先进内存,在map端完成reduce
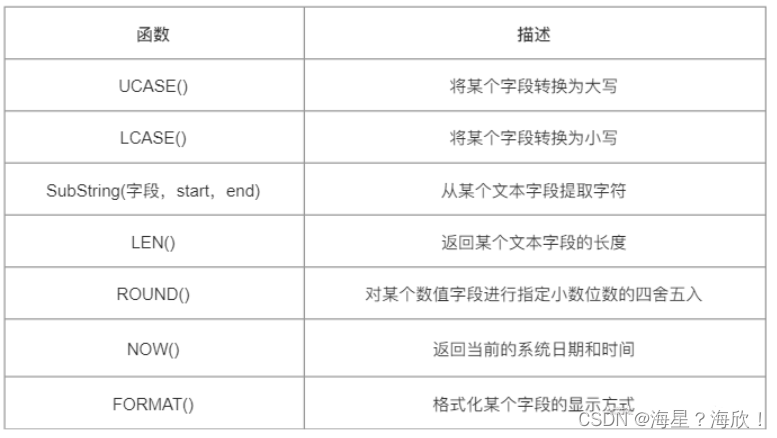
9,SQL常用函数
1,常用聚合函数
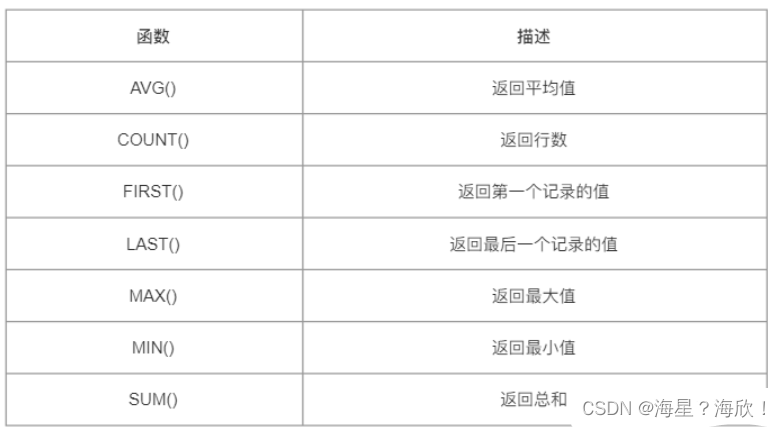
2,常用其他函数
10,SQL掌握运用的程度?–类似概述一下SQL的知识点
1) 基本操作
掌握增删改查等SQL基本语法:
–增(insert into)
INSERT INTO <表名> (字段名) VALUES (值);
–删(delete)
DELETE FROM <表名> WHERE <筛选条件>;
–改 (update)
UPDATE <表名> SET <字段名=值> WHERE <筛选条件>;
–查
SELECT * FROM <表名> WHERE <筛选条件>;
2) 查询
SQL中的查询操作相当重要,关系着数据分析的效率高低,查询的基本语法是:
SELECT * FROM <表名>
WHERE <筛选条件>
GROUP BY <字段名>
HAVING <条件>
3)在此基本语法上衍生出许多知识点:
- 嵌套查询:WHERE筛选条件中使用嵌套查询,将(SELECT-FROM-WHERE)的查询语句作为子查询嵌套进去;
- 组合查询:使用UNION/UNION ALL对多个查询结果进行组合,其中UNION将对结果进行去重;
- 表连接:表连接中根据使用场景选择INEER/LEFT/RIGHT/FULL JOIN;
- 聚合函数:使用MAX/MIN/SUM/AVG/COUNT对查询数据进行聚合;
- 窗口函数:多查询数据排序或多样性聚合
11,SQL中如何去重?
假设table表中有字段a、b、c,现需要对字段a、b进行去重,在SQL中通常有三种方法能够实现去重的功能:
1) DISTINCT 关键字
使用DISTINCT去重的方法很简单,在查询数据时在字段前增加DISTINCT关键字既可对字段内容进行去重。
SELECT DISTINCT a,b
FROM table;
2) GROUP BY关键字
使用GROUP BY进行去重的方法和DISTINCT类似,仅需在查询语句末端增加GROUP BY即可,而且能够对分组数据进行筛选。
SELECT a, b
FROM table
GROUP BY a, b;
3) 窗口函数
使用窗口函数进行去重时,比DISTINCT和GROUP BY稍微复杂些,可以采用窗口函数+over(partition by 去重字段)的方式。
-- 窗口函数+over(partition by 去重字段),其中窗口函数可采用row_number
SELECT a, b
FROM(
SELECT *, row_number() over(partition by a, b order by c) rank_id
FROM table
) A
WHERE rank_id = 1;
12,SQL代码题:行、列转换
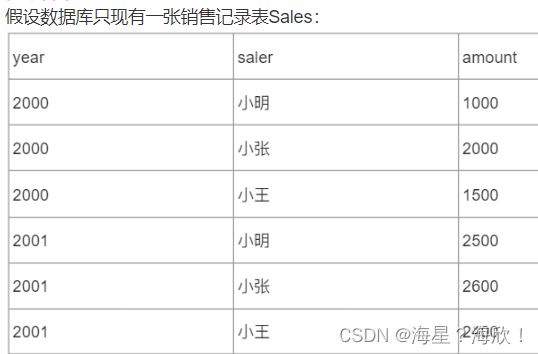
SELECT
year,
sum( CASE WHEN saler = '小明' THEN amount ELSE 0 END ) AS '小明',
sum( CASE WHEN saler = '小张' THEN amount ELSE 0 END ) AS '小张',
sum( CASE WHEN saler = '小王' THEN amount ELSE 0 END ) AS '小王'
FROM
sale
GROUP BY
year