【学习笔记】【Pytorch】十六、模型训练套路
- 一、内容概述
- 二、模型训练套路
- 1.代码实现:CPU版本
- 2.代码实现:优先GPU版本a
- 3.代码实现:优先GPU版本b
- 4.计算测试集上的正确率
- 三、使用免费GPU训练模型
一、内容概述
本内容主要是介绍一个完整的模型训练套路,以 CIFAR-10 数据集为例。
模型训练步骤:
- 准备数据:创建 datasets 实例
- 加载数据:创建 DataLoader 实例
- 准备模型:神经网络结构
- 设置损失函数
- 设置优化器
- 开始训练:
- 从 batch_size 个数据中分别取出个图片数据和标签数据
- 图片数据输入到神经网络模型里后输出训练结果
- 将训练结果和标签数据经过损失函数
- 调用优化器实例的梯度清零API
- 调用反向传播API
- 调用优化器实例参数优化API
- 开始测试:(使用每轮训练好、但不进行优化的模型)
- 结果聚合展示
二、模型训练套路
1.代码实现:CPU版本
# CIFAR_model.py
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Model(nn.Module):
def __init__(self) -> None:
super().__init__() # 初始化父类属性
self.conv1 = Conv2d(in_channels=3, out_channels=32,
kernel_size=5, padding=2)
self.maxpool1 = MaxPool2d(kernel_size=2)
self.conv2 = Conv2d(in_channels=32,out_channels=32,
kernel_size=5, padding=2)
self.maxpool2 = MaxPool2d(kernel_size=2)
self.conv3 = Conv2d(in_channels=32, out_channels=64,
kernel_size=5, padding=2)
self.maxpool3 = MaxPool2d(kernel_size=2)
self.flatten = Flatten() # 展平为1维向量,torch.reshape()一样效果
# 若是想检验1024是否正确,可以先写前面的层,看样例的输出大小,即可得到1024
self.linear1 = Linear(in_features=1024, out_features=64)
self.linear2 = Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
if __name__ == '__main__':
model = Model() # 创建实例
# 测试模型样例(也可以测试各层的输出是否正确)
input = torch.ones((64, 3, 32, 32)) # batch_size = 64
print(input.shape) # torch.Size([64, 3, 32, 32])
output = model(input)
print(output.shape) # torch.Size([64, 10]),batch_size=64,10个参数
import time
import torch.optim.optimizer
import torchvision
from torch import nn, optim
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from CIFAR_model import Model # 导入CIFAR_model.py里的Model类定义
# 1.创建 CIFAR10 数据集的训练和测试实例
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# Length 长度
train_data_len = len(train_data)
test_data_len = len(test_data)
print(f"训练数据集的长度:{train_data_len}")
print(f"测试数据集的长度:{test_data_len}")
# 2.利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.搭建神经网络:CIFAR-10模型
model = Model() # 创建实例
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
# 5.优化器
learning_rate = 0.01 # 1e-2 = 1 x (10)^(-2) = 0.01
optimizer = torch.optim.SGD(model.parameters(), learning_rate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
writer = SummaryWriter("./CIFAR_logs") # 创建实例
# 从 DATaLoader 实例取出 batch_size 个数据 -->
# 从 batch_size 个数据中分别取出个图片数据和标签数据 -->
# 图片数据输入到神经网络模型里后输出训练结果 -->
# 将训练结果和标签数据经过损失函数 -->
# 调用优化器实例的梯度清零API -->
# 调用反向传播API -->
# 调用优化器实例参数优化API
start_time = time.time() # 开始时间
for i in range(epoch):
print(f"--------第{i}轮训练开始--------")
# 训练步骤开始
model.train() # 模型进入训练模式(仅针对有Dropout,BatchNorm层的网络结构)
for data in train_dataloader:
imgs, targets = data
outputs = model(imgs)
result_loss = loss_fn(outputs, targets) # 计算每个参数对应的损失
# 优化器优化模型
optimizer.zero_grad() # 每个参数对应的梯度清零
result_loss.backward() # 反向传播,计算每个参数对应的梯度
optimizer.step() # 每个参数根据上一步得到的梯度进行优化
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(f"用时:{end_time - start_time}秒")
print(f"训练次数:{total_train_step},Loss:{result_loss.item()}")
writer.add_scalar("train_loss", result_loss.item(), total_train_step)
# 测试步骤开始(每轮训练好、但不进行优化的模型)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 不进行优化的
for data in test_dataloader:
imgs, targets = data
outputs = model(imgs)
result_loss = loss_fn(outputs, targets)
total_test_loss += result_loss # 损失累加
# 计算标签正确数(取得在 1 方向,概率最大的索引,即得标签输出值;对比标签输出值与目标值+求和:True=1,False=0)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的正确率:{total_accuracy / test_data_len}")
writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)
total_test_step += 1
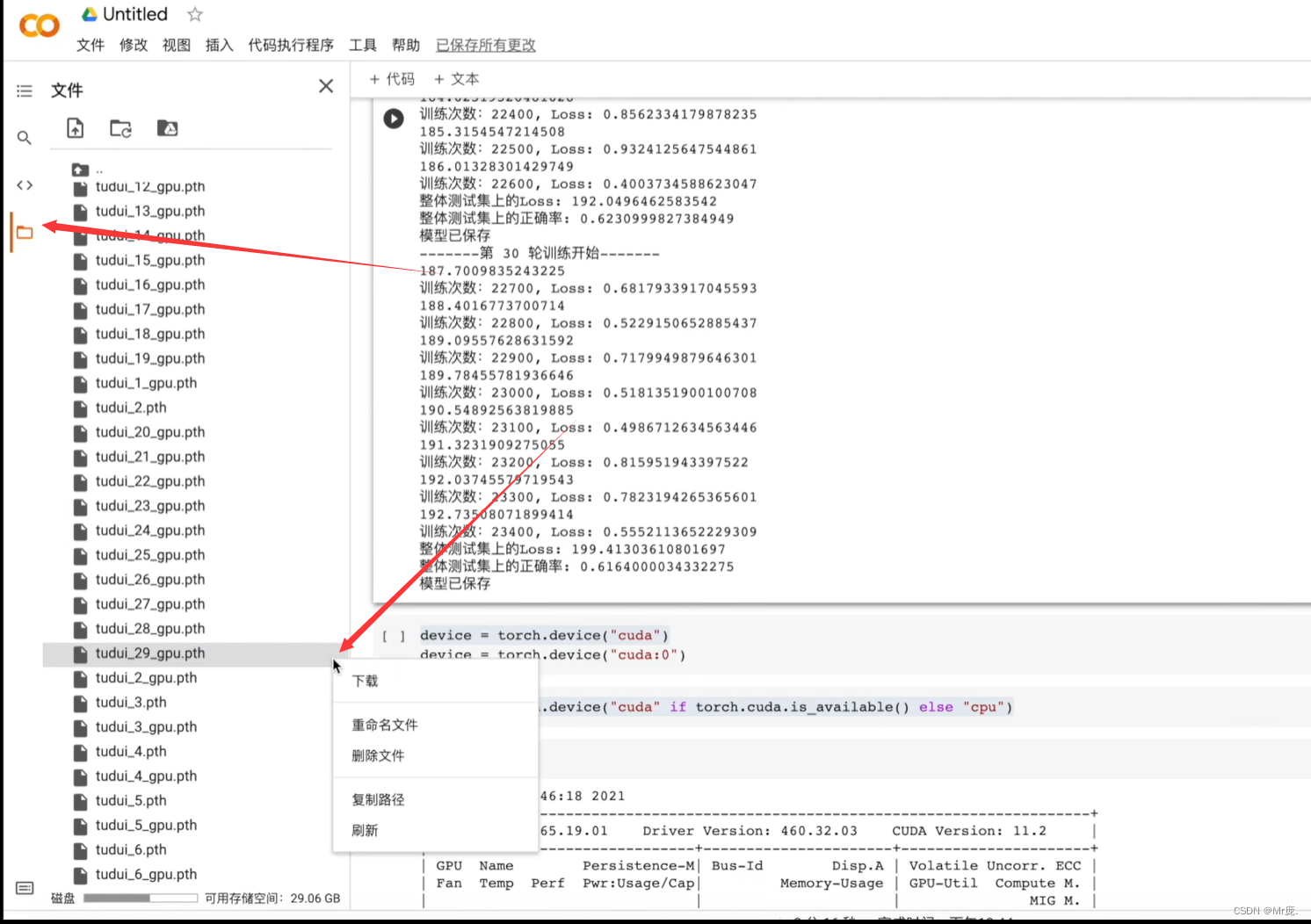
torch.save(model, f"CIFAR_model_{i}.pth")
print("模型已保存!")
writer.close()
# tensorboard命令:tensorboard --logdir=CIFAR_logs --port=6007
# 使用命令查看GPU使用率:nvidia-smi
输出:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
--------第0轮训练开始--------
用时:6.6066083908081055秒
训练次数:100,Loss:2.289702892303467
用时:13.33405351638794秒
训练次数:200,Loss:2.2909717559814453
用时:19.75460195541382秒
训练次数:300,Loss:2.2741425037384033
用时:26.26621413230896秒
训练次数:400,Loss:2.204988956451416
用时:32.46784520149231秒
训练次数:500,Loss:2.1708924770355225
用时:37.693655014038086秒
训练次数:600,Loss:2.123288631439209
用时:42.99215912818909秒
训练次数:700,Loss:2.0311992168426514
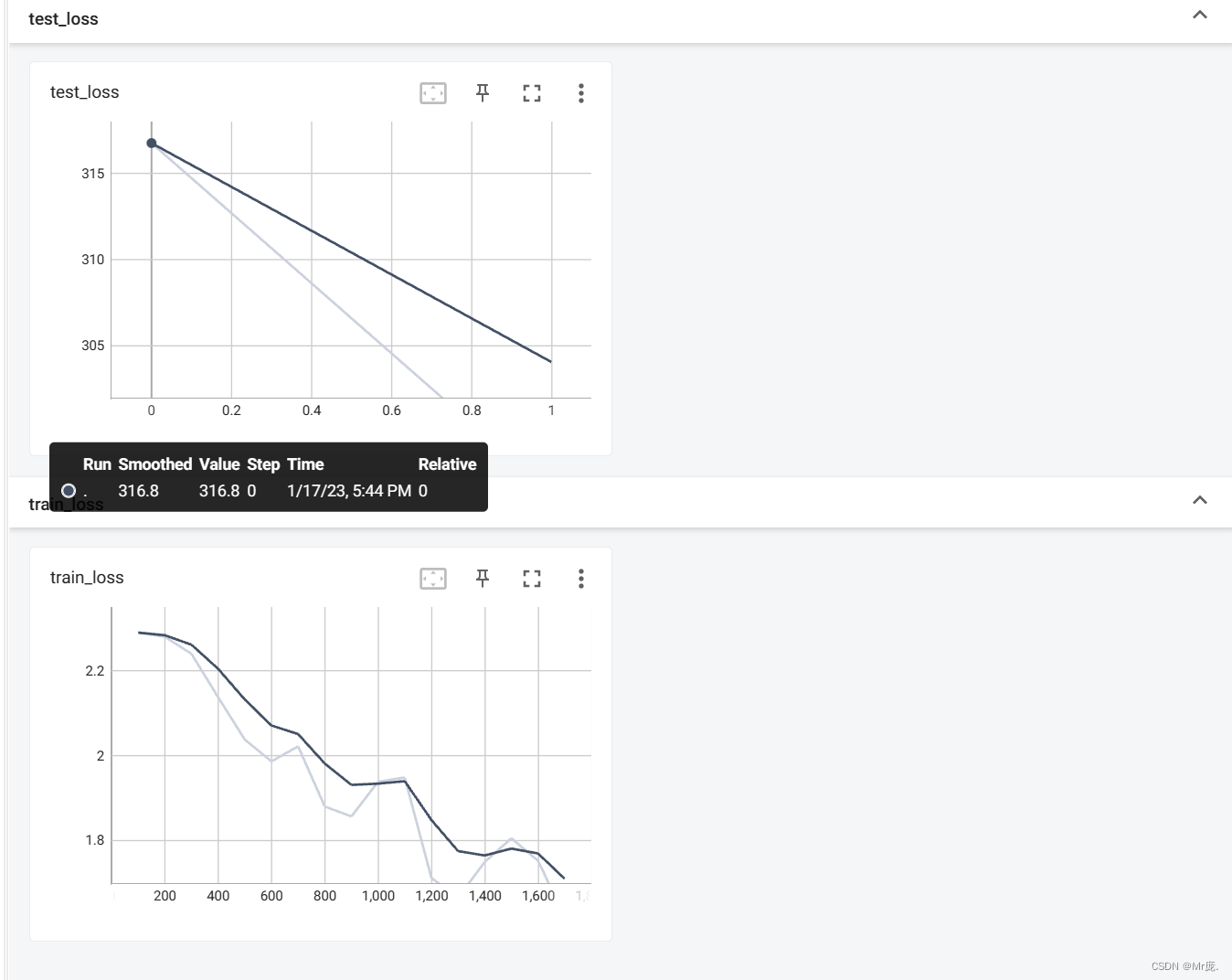
整体测试集上的Loss:316.803642578125
整体测试集上的正确率:0.2874000072479248
模型已保存!
--------第1轮训练开始--------
用时:52.013330698013306秒
训练次数:800,Loss:1.872697114944458
用时:57.56292533874512秒
训练次数:900,Loss:1.8300652503967285
用时:61.764703035354614秒
训练次数:1000,Loss:1.9835503101348877
用时:65.52227187156677秒
训练次数:1100,Loss:1.9706411361694336
.....
.....
TensorBoard输出:
2.代码实现:优先GPU版本a
使用GPU训练模型需要在网络模型、数据(输入、标签)、损失函数添加 .cuda()。

# 若是使用GPU可用,则用GPU训练模型,否则使用CPU训练。
import time
import torch.optim.optimizer
import torchvision
from torch import nn, optim
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from CIFAR_model import Model # 导入CIFAR_model.py里的Model类定义
# 1.创建 CIFAR10 数据集的训练和测试实例
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# Length 长度
train_data_len = len(train_data)
test_data_len = len(test_data)
print(f"训练数据集的长度:{train_data_len}")
print(f"测试数据集的长度:{test_data_len}")
# 2.利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.搭建神经网络:CIFAR-10模型
model = Model() # 创建实例
if torch.cuda.is_available(): # GPU是否可用
print("使用GPU训练")
model = model.cuda() # GPU(非必须重赋值)
# model.cuda() # 与上一句效果一样,不用重赋值
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available(): # GPU是否可用
loss_fn = loss_fn.cuda() # GPU(非必须重赋值)
# 5.优化器
learning_rate = 0.01 # 1e-2 = 1 x (10)^(-2) = 0.01
optimizer = torch.optim.SGD(model.parameters(), learning_rate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
writer = SummaryWriter("./CIFAR_logs") # 创建实例
# 从 DATaLoader 实例取出 batch_size 个数据 -->
# 从 batch_size 个数据中分别取出个图片数据和标签数据 -->
# 图片数据输入到神经网络模型里后输出训练结果 -->
# 将训练结果和标签数据经过损失函数 -->
# 调用优化器实例的梯度清零API -->
# 调用反向传播API -->
# 调用优化器实例参数优化API
start_time = time.time() # 开始时间
for i in range(epoch):
print(f"--------第{i}轮训练开始--------")
# 训练步骤开始
model.train() # 模型进入训练模式(仅针对有Dropout,BatchNorm层的网络结构)
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # GPU是否可用
imgs = imgs.cuda() # GPU(必须重赋值)
targets = targets.cuda() # GPU(必须重赋值)
outputs = model(imgs)
result_loss = loss_fn(outputs, targets) # 计算每个参数对应的损失
# 优化器优化模型
optimizer.zero_grad() # 每个参数对应的梯度清零
result_loss.backward() # 反向传播,计算每个参数对应的梯度
optimizer.step() # 每个参数根据上一步得到的梯度进行优化
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(f"用时:{end_time - start_time}秒")
print(f"训练次数:{total_train_step},Loss:{result_loss.item()}")
writer.add_scalar("train_loss", result_loss.item(), total_train_step)
# 测试步骤开始(每轮训练好、但不进行优化的模型)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 不进行优化的
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # GPU是否可用
imgs = imgs.cuda() # GPU(必须重赋值)
targets = targets.cuda() # GPU(必须重赋值)
outputs = model(imgs)
result_loss = loss_fn(outputs, targets)
total_test_loss += result_loss # 损失累加
# 计算标签正确数(取得在 1 方向,概率最大的索引,即得标签输出值;对比标签输出值与目标值+求和:True=1,False=0)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的正确率:{total_accuracy / test_data_len}")
writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)
total_test_step += 1
torch.save(model, f"CIFAR_model_{i}.pth")
print("模型已保存!")
writer.close()
# tensorboard命令:tensorboard --logdir=CIFAR_logs --port=6007
# 使用命令查看GPU使用率:nvidia-smi
输出:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
使用GPU训练
--------第0轮训练开始--------
用时:5.071975946426392秒
训练次数:100,Loss:2.2829768657684326
用时:5.656689167022705秒
训练次数:200,Loss:2.282378673553467
用时:6.2110230922698975秒
训练次数:300,Loss:2.2654380798339844
用时:6.7645323276519775秒
训练次数:400,Loss:2.1923139095306396
用时:7.330979585647583秒
训练次数:500,Loss:2.110574960708618
用时:7.897375583648682秒
训练次数:600,Loss:2.0636444091796875
用时:8.450936794281006秒
训练次数:700,Loss:2.002979278564453
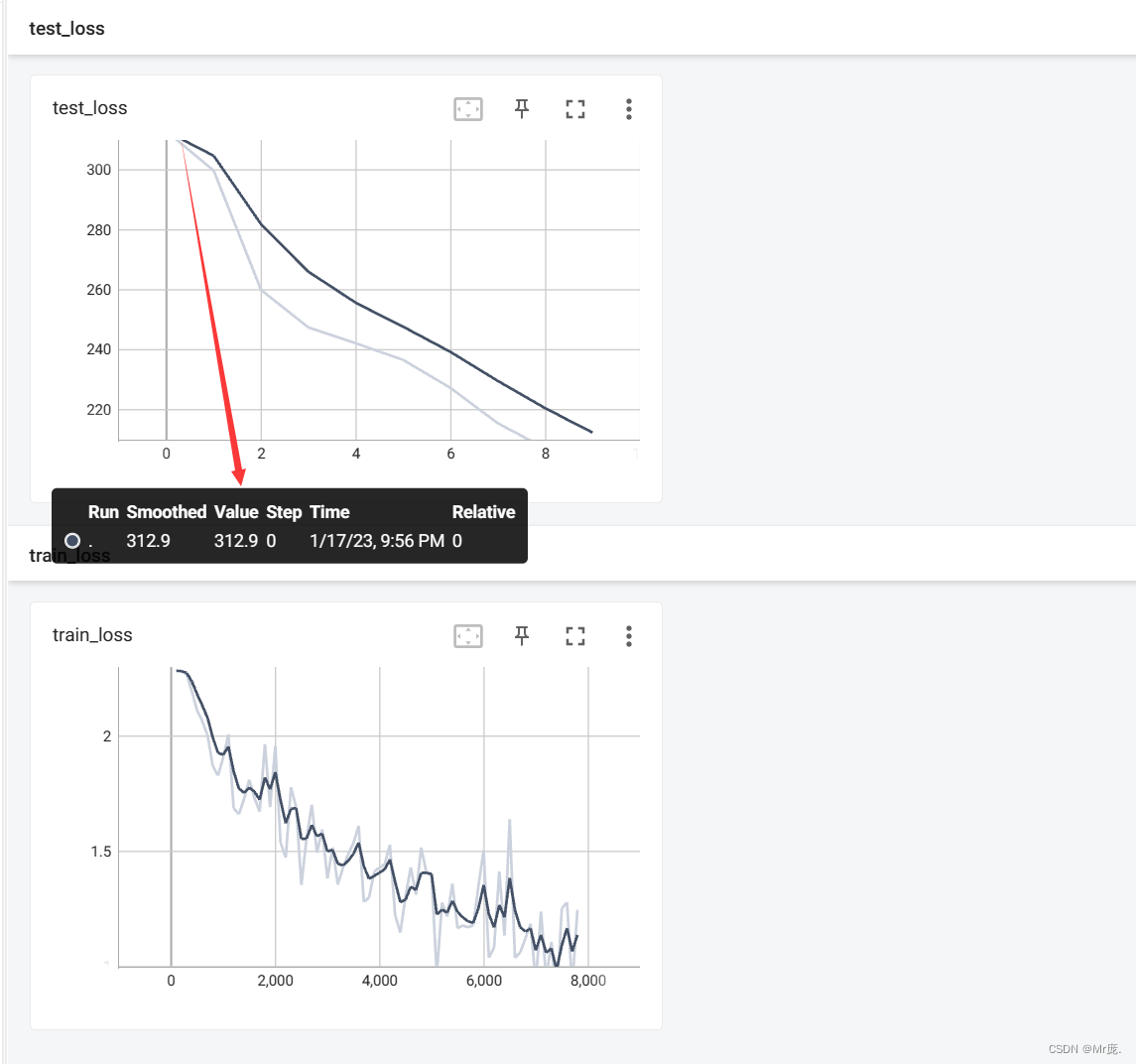
整体测试集上的Loss:312.9119567871094
整体测试集上的正确率:0.27730000019073486
模型已保存!
--------第1轮训练开始--------
用时:9.694117307662964秒
训练次数:800,Loss:1.8703418970108032
用时:10.266939401626587秒
训练次数:900,Loss:1.8288105726242065
用时:10.834200620651245秒
训练次数:1000,Loss:1.9075711965560913
用时:11.38311505317688秒
训练次数:1100,Loss:2.0081818103790283
用时:11.949774265289307秒
训练次数:1200,Loss:1.6877559423446655
用时:12.495528936386108秒
训练次数:1300,Loss:1.6612036228179932
用时:13.024411678314209秒
训练次数:1400,Loss:1.727241039276123
用时:13.61475944519043秒
训练次数:1500,Loss:1.8107168674468994
整体测试集上的Loss:299.7525329589844
整体测试集上的正确率:0.3188999891281128
模型已保存!
--------第2轮训练开始--------
用时:14.84033989906311秒
训练次数:1600,Loss:1.7315385341644287
用时:15.40208101272583秒
....
...
...
--------第9轮训练开始--------
用时:52.963948488235474秒
训练次数:7100,Loss:1.2392919063568115
用时:53.64732599258423秒
训练次数:7200,Loss:0.9450228810310364
用时:54.240562438964844秒
训练次数:7300,Loss:1.108464241027832
用时:54.80011343955994秒
训练次数:7400,Loss:0.8460630178451538
用时:55.38365650177002秒
训练次数:7500,Loss:1.2521216869354248
用时:55.92836785316467秒
训练次数:7600,Loss:1.279009222984314
用时:56.472257137298584秒
训练次数:7700,Loss:0.9141138792037964
用时:57.009363412857056秒
训练次数:7800,Loss:1.2461062669754028
整体测试集上的Loss:200.27098083496094
整体测试集上的正确率:0.546999990940094
模型已保存!
TensorBoard输出:
3.代码实现:优先GPU版本b
使用GPU训练模型需要在网络模型、数据(输入、标签)、损失函数添加 .to(device)

# 若是使用GPU可用,则用GPU训练模型,否则使用CPU训练。
import time
import torch.optim.optimizer
import torchvision
from torch import nn, optim
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from CIFAR_model import Model # 导入CIFAR_model.py里的Model类定义
# 定义训练的设备GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # ”cuda:0“ 等效 ”cuda“
print(device)
# 1.创建 CIFAR10 数据集的训练和测试实例
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# Length 长度
train_data_len = len(train_data)
test_data_len = len(test_data)
print(f"训练数据集的长度:{train_data_len}")
print(f"测试数据集的长度:{test_data_len}")
# 2.利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.搭建神经网络:CIFAR-10模型
model = Model() # 创建实例
model = model.to(device) # GPU(非必须重赋值)
# model.to(device) # 与上一句效果一样,不用重赋值
# 4.损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # GPU(非必须重赋值)
# 5.优化器
learning_rate = 0.01 # 1e-2 = 1 x (10)^(-2) = 0.01
optimizer = torch.optim.SGD(model.parameters(), learning_rate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
writer = SummaryWriter("./CIFAR_logs") # 创建实例
# 从 DATaLoader 实例取出 batch_size 个数据 -->
# 从 batch_size 个数据中分别取出个图片数据和标签数据 -->
# 图片数据输入到神经网络模型里后输出训练结果 -->
# 将训练结果和标签数据经过损失函数 -->
# 调用优化器实例的梯度清零API -->
# 调用反向传播API -->
# 调用优化器实例参数优化API
start_time = time.time() # 开始时间
for i in range(epoch):
print(f"--------第{i}轮训练开始--------")
# 训练步骤开始
model.train() # 模型进入训练模式(仅针对有Dropout,BatchNorm层的网络结构)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # GPU
targets = targets.to(device) # GPU
outputs = model(imgs)
result_loss = loss_fn(outputs, targets) # 计算每个参数对应的损失
# 优化器优化模型
optimizer.zero_grad() # 每个参数对应的梯度清零
result_loss.backward() # 反向传播,计算每个参数对应的梯度
optimizer.step() # 每个参数根据上一步得到的梯度进行优化
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(f"用时:{end_time - start_time}秒")
print(f"训练次数:{total_train_step},Loss:{result_loss.item()}")
writer.add_scalar("train_loss", result_loss.item(), total_train_step)
# 测试步骤开始(每轮训练好、但不进行优化的模型)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 不进行优化的
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device) # GPU
targets = targets.to(device) # GPU
outputs = model(imgs)
result_loss = loss_fn(outputs, targets)
total_test_loss += result_loss # 损失累加
# 计算标签正确数(取得在 1 方向,概率最大的索引,即得标签输出值;对比标签输出值与目标值+求和:True=1,False=0)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的正确率:{total_accuracy / test_data_len}")
writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)
total_test_step += 1
torch.save(model, f"CIFAR_model_{i}.pth")
print("模型已保存!")
writer.close()
# tensorboard命令:tensorboard --logdir=CIFAR_logs --port=6007
# 使用命令查看GPU使用率:nvidia-smi
4.计算测试集上的正确率
argmax():参数说明


代码实现:
import torch
output = torch.tensor( [[0.1, 0.2],
[0.05, 0.4]] )
print(output.argmax(1)) # tensor([1, 1])
print(output.argmax(0)) # tensor([0, 1])
preds = output.argmax(1) # 1.取得在 1 方向,概率最大的索引,即得标签输出值
targets = torch.tensor([0, 1])
print(preds == targets)
print((preds == targets).sum()) # 2.对比标签输出值与目标值+求和:True=1,False=0
输出:
tensor([1, 1])
tensor([0, 1])
tensor([False, True])
tensor(1)
三、使用免费GPU训练模型
国内阿里云天池也是免费的、Colaboratory、腾讯GPU云、飞桨。
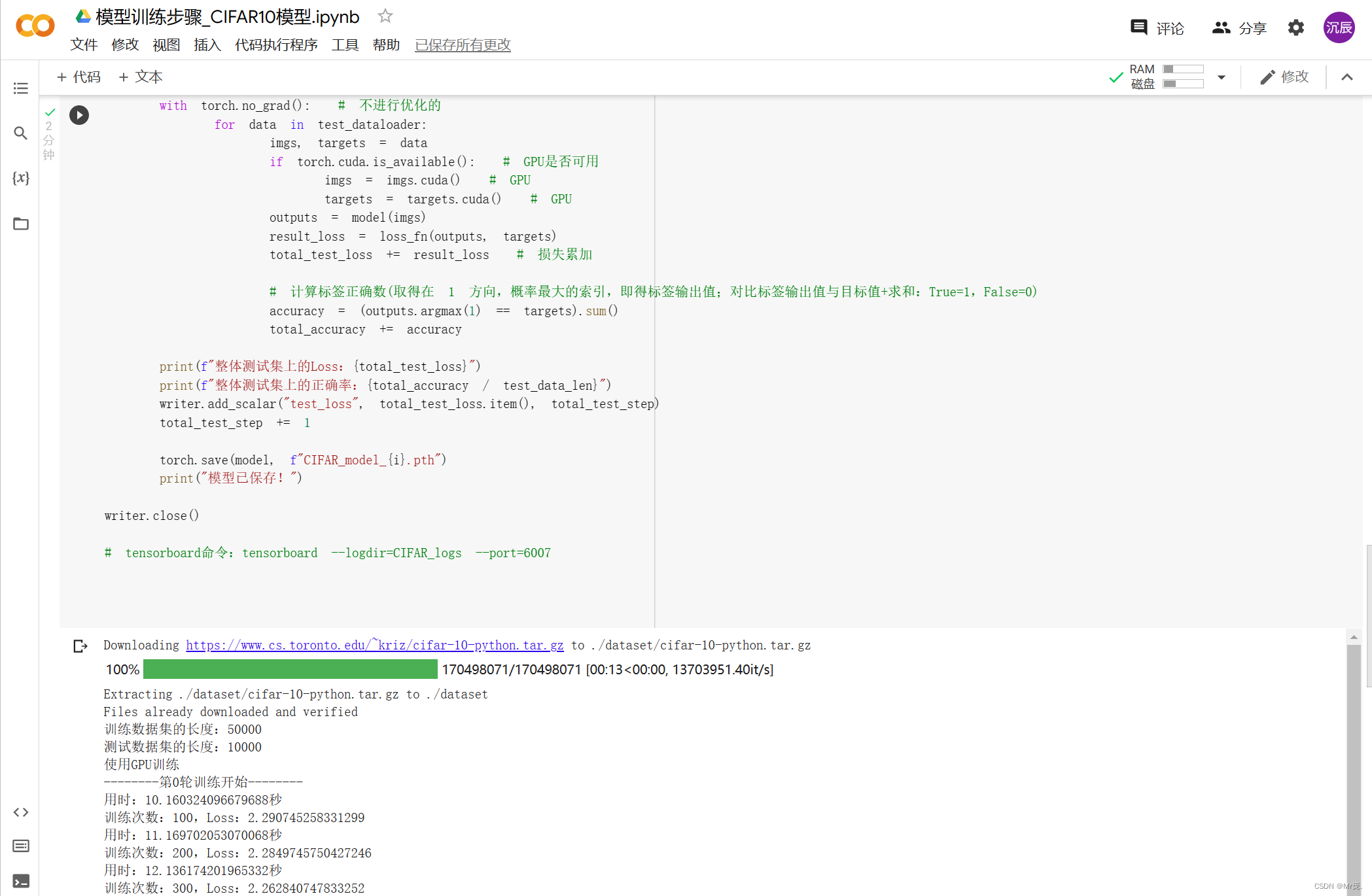
1.使用GPU训练

2.模型训练
3.查看GPU使用率
使用命令查看GPU使用率:!nvidia-smi
功率70W 15G显存
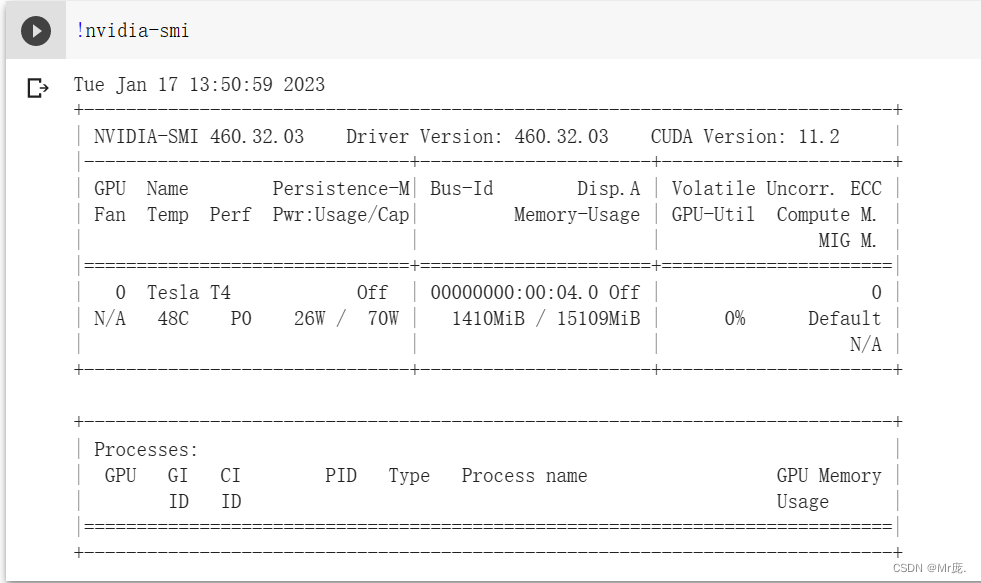
4.模型保存位置