Redis数据结构
- Redis数据结构
- 二、数据结构
- 2.1Redis核心对象
- 2.2底层数据结构
- 2.2.1 SDS-simple dynamic string
- sds内存布局
- sds的操作
- 为什么使用SDS,SDS的优势?
- 2.2.2 list
- list内存布局
- 2.2.3 dict
- dict内存布局
- 2.2.4 zskiplist
- zskiplist内存布局
- 2.2.5 intset
- intset内存布局
- 2.2.6 ziplist
- ziplist内存布局
- ziplist_entry内存布局
- ziplist优缺点
- 2.2.7 quicklist
- quicklist内存布局
- quicklist优缺点
- 2.2.8 zipmap
- zipmap内存布局
- zipmap适用场景
Redis数据结构
二、数据结构
2.1Redis核心对象
对于常用的5种Redis的Value类型:
- String
- Hash
- Set
- List
- ZSet
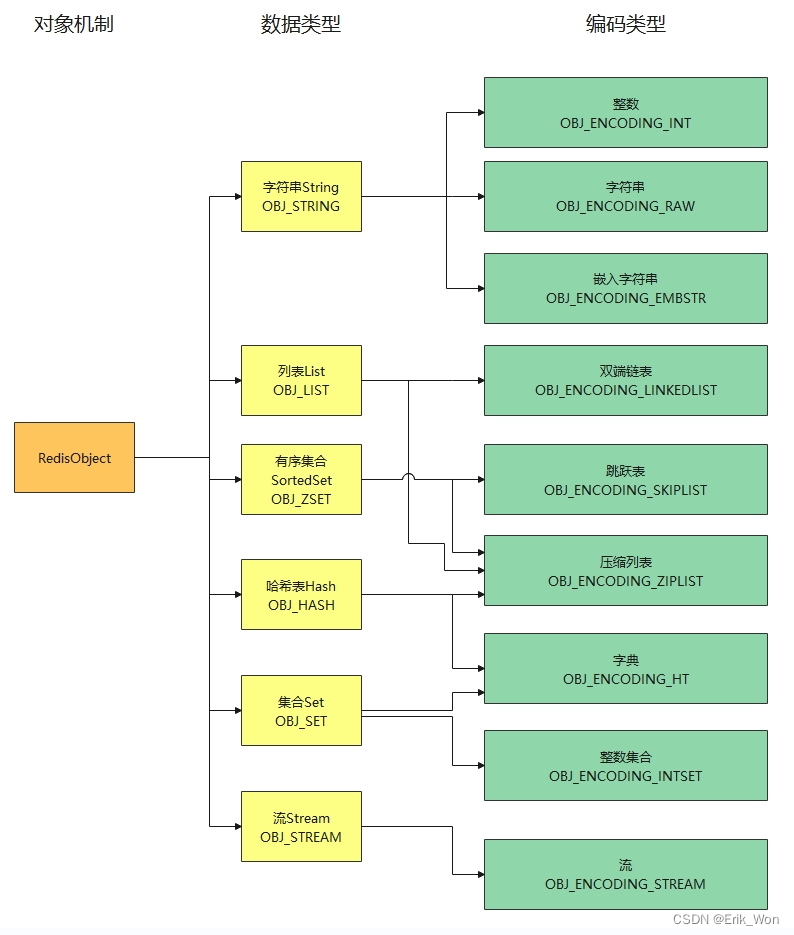
底层存在着8种数据结构,实现了暴露给用户的5种类型:
- SDS: Simple Dynamic String - 支持自动动态扩容的字节数组
- List: 链表
- Dict: 使用双哈希表实现的,支持平滑扩容的字典
- zSkipList: 跳跃表
- intset:用于存储int数值集合的结构
- zipList:实现类似与TLV,用于存储任意数据的有序序列数据结构
- quickList:一种以zipList作为节点的双链表结构。
- zipMap:用于在小规模数据场景使用的轻量级字典结构
Redis核心对象:redisObject作为8种底层数据结构和"Value type"的桥梁。Redis中的Key和Value,在表面上都是一个RedisObject实例,因此,redisObject可以看作一种valueType,对于每一种ValueType类型的redisObject,底层都至少有2种以上的数据结构实现,从而提高redis的运行效率。
注意以下源码都基于redis6.0
redisObject数据结构:
/**
redis6.0
Redis对象
*/
typedef struct redisObject {
//类型
unsigned type:4;
//编码方式
unsigned encoding:4;
//LRU时间(相对于全局的lru_clock)
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
//引用计数
int refcount;
//指向对象的指针
void *ptr;
} robj;
redisObject中有3个重要的属性:
- type
- encoding
- ptr
type记录了对象所保存的值的类型,它的值可能是以下常量中的一种:
//redis6.0
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. 字符串对象*/
#define OBJ_LIST 1 /* List object. 列表对象*/
#define OBJ_SET 2 /* Set object. 集合对象*/
#define OBJ_ZSET 3 /* Sorted set object. 有序集合对象*/
#define OBJ_HASH 4 /* Hash object. 哈希对象*/
encoding记录了对象所保存的值的编码,如下:
//redis6.0
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation 编码为字符串*/
#define OBJ_ENCODING_INT 1 /* Encoded as integer 编码为整型*/
#define OBJ_ENCODING_HT 2 /* Encoded as hash table 编码为哈希表*/
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap 编码为zipmap*/
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. 编码为双向链表*/
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist 编码为压缩列表*/
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset 编码为整数集合*/
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist 编码为跳表*/
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding 嵌入sds字符编码*/
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists 编码为压缩双向链表*/列表对象
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks 编码为基数树压缩(或紧凑)表*/streams对象
quickList和listPack两种数据结构,都是为了提高ziplist的效率,从而进行了新设计。
ptr指针,指向实际保存这个值的数据结构,这个数据结构根据type和encoding的属性决定。
例:redisObject的type为REDIS_STRING,encoding为OBJ_ENCODING_INT,则这个对象就是一个String的整数,ptr指针就指向这个整数。
2.2底层数据结构
底层结构包含sds,list,ziplist等结构,这些底层结构构成了常用的5种基本类型。
2.2.1 SDS-simple dynamic string
sds是一种用于存储二进制数据的一种结构,具有动态扩容的特点。源码位置位于sds.h和sds.c中实现:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits 低3位标识头部类型,高5位未使用*/
char buf[];
};
sds内存布局
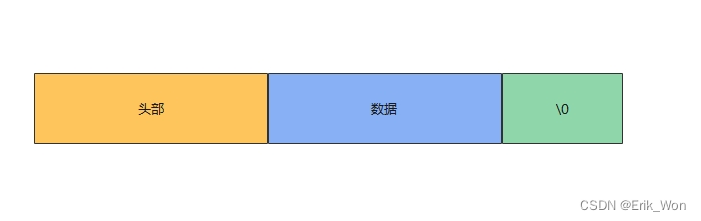
结构体中的sdshdr是头部,buf是存储用户数据的位置。从命名中可见,sds除了能存储二进制数据,还是设计为字符串使用的。所在buf中,用户数据后总会有一个\0。即buf包含了"数据"和"\0"两部分。
SDS定义了5种不同的头部,其中sdshdr5并没有实际投入使用(在源码注释中也可见),所以实际上只有四种不同头部。
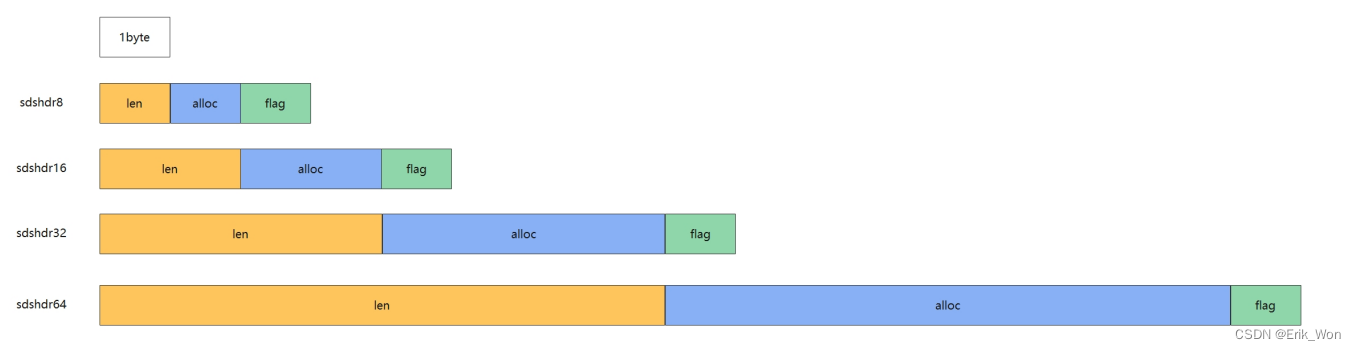
- len:分别以uint8,uint16,uint32,uint64表示用户数据的长度,这里没有包含末尾\0。
- alloc:分别以uint8,uint16,uint32,uint64表示整个SDS中,除了头部和末尾的\0,剩下的字节数,即实际的数据占用的内存。
- flag:1字节,以低3位标识头部类型,高5位未使用。
sds的操作
当程序中持有一个SDS实例时,直接持有的是数据区的头指针。这样,我们就能通过这个头指针,向前偏移一个字节,取到flag,通过判断flag低三位的值,从而判断头部的类型,已经使用的字节数,总字节数,剩余的字节数。因此,sds类型定义为char * 。
创建SDS的三个接口如下:
/*
创建一个不含数据的sds:
头部 3字节 sdshdr8
数据区 0字节
末尾 \0 占1字节
*/
sds sdsempty(void);
/*
创建一个带数据的sds:
头部 按照strlen(init)的值,选择最小的头部类型
数据区 入参指向的字符串中的所有字符,不包括末尾\0
末尾 \0 占1字节
*/
sds sdsnew(const char *init);
/*
创建一个带数据的sds:
头部 按initlen的值,选择最小的头部类型
数据区 从入参指针init处开始,拷贝initlen个字节
末尾 \0 占1字节
*/
sds sdsnewlen(const void *init, size_t initlen);
- 所有创建sds实例的接口,都不会额外分配多的内存空间
- sdsnewlen 用于带二进制数据创建sds实例,sdsnew用于带字符串创建sds实例,接口返回的sds可以直接传入lib中的字符串输出函数进行操作。因为末尾有\0,所以lib中字符串输出函数安全性得以保证。
在对SDS中的数据进行修改时,如果剩余的内存空间不足,会调用如下sdsMakeRoomFor函数用于扩容:
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
//-----关键代码start-----
/* Return ASAP if there is enough space left. */
//保证s至少有addlen的大小可用
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
//获取当前需要的length大小
reqlen = newlen = (len+addlen);
assert(newlen > len); /* Catch size_t overflow */
//如果newlen所需空间不超过阈值SDS_MAX_PREALLOC,则扩容2倍
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
//如果newlen所需空间>=阈值SDS_MAX_PREALLOC,则增加SDS_MAX_PREALLOC
//SDS_MAX_PREALLOC = (1024*1024)
newlen += SDS_MAX_PREALLOC;
//-----关键代码end-----
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
为什么使用SDS,SDS的优势?
- 常数复杂度获取字符串长度
获取字符串长度操作的时间复杂度为 O(1) ,由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性 - 杜绝缓冲区溢出
字符串拼接前,通过len判断内存空间,如果不够则先扩容再拼接,因此不会出现缓冲区溢出的问题。 - 减少修改字符串的内存重新分配次数
因为Len和alloc属性,修改字符串时,SDS实现了空间预分配和惰性空间释放两种策略:- 空间预分配:对字符串进行扩容时,会多扩容一些内存,减少执行字符串增长的内存重分配次数
- 惰性空间释放:对字符串进行缩短操作,多余的字节不会被内存立即使用,而是使用alloc属性记录,等待后续使用
- 二进制安全
SDS的API都是以处理二进制的方式处理buf中的元素。
2.2.2 list
常规链表实现,链表节点不直接持有数据,通过void * 指针间接指向数据。源码位置位于adlist.h和adlist.c中实现:
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
list内存布局
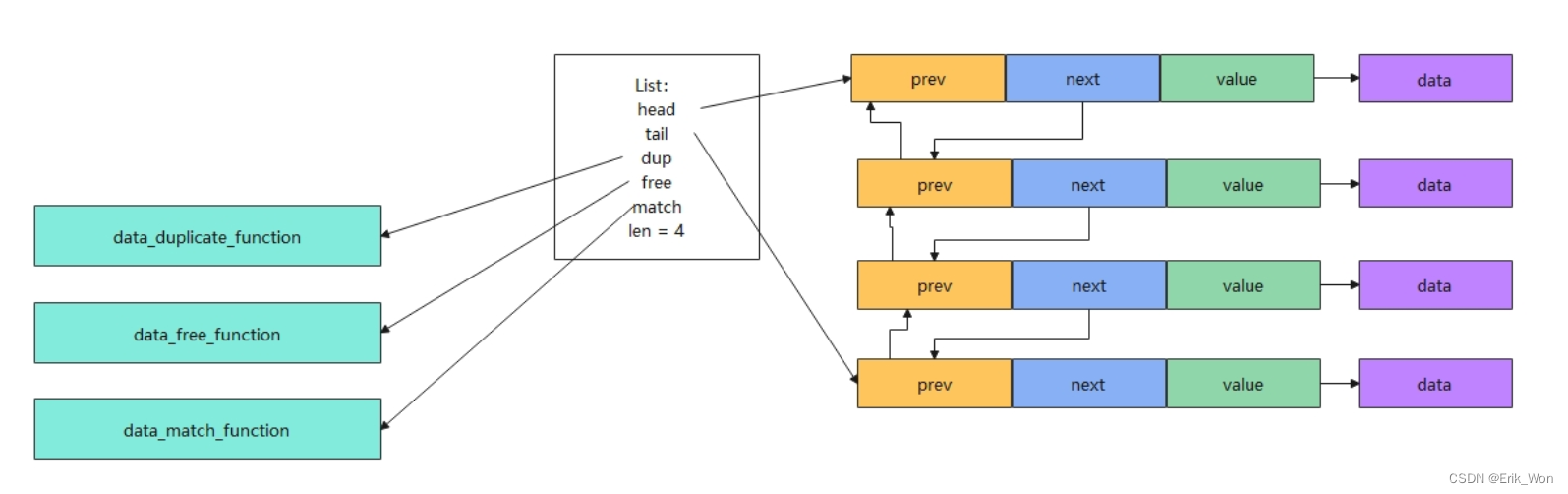
list在redis中除了作为一些Value Type的底层实现,还用于其他功能,作为一种数据结构广泛使用。list的数据结构中,除了链表,还有迭代器。
- 定义了迭代器listIter,及其相关接口实现
- list中的链表节点本身不直接持有数据,通过void * 指针指向value字段,间接持有,所以数据的生命周期并不完全和链表、节点一致。
2.2.3 dict
dict的Redis底层数据结构定义和实现位于dict.h和dict.c之中:
typedef struct dictEntry {
void *key;
//值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //指向下一个哈希表的节点指针
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;//哈希表数组
unsigned long size;//哈希表大小
unsigned long sizemask;//哈希表大小掩码,用于计算索引值,总是等于size - 1
unsigned long used;//哈希表已有节点数量
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
dict内存布局
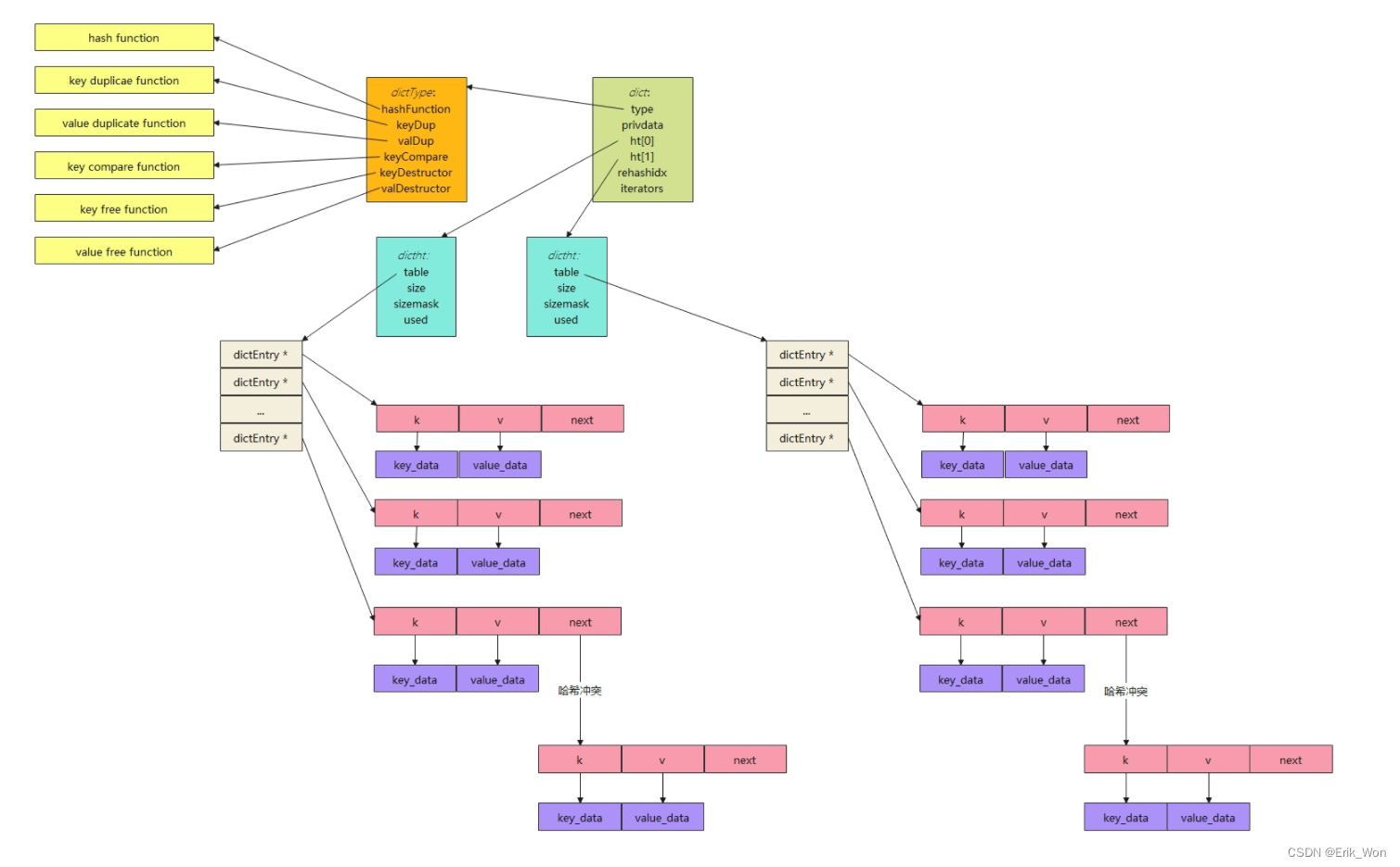
- dict通过dictEntry这个结构间接持有键值对,k通过指针间接持有键,v通过指针间接持有值。注意,如果值是整数值的话,则直接存储在v字段中的,而不是间接持有。 同时,在bucket索引值冲突时,以链式方式解决冲突,next指向同索引的下一个dictEntry结构。
- 在dictht.table中,结点本身是散布在内存中的,顺序表中存储的是dictEntry的指针。
- 哈希表即是dictht结构, 其通过table字段间接的持有顺序表形式的bucket, bucket的容量存储在size字段中, 为了加速将散列值转化为bucket中的数组索引, 引入了sizemask字段, 计算指定键在哈希表中的索引时, 执行的操作类似于dict->type->hashFunction(键) & dict->ht[x].sizemask. 从这里也可以看出来, bucket的容量适宜于为2的幂次, 这样计算出的索引值能覆盖到所有bucket索引位.
- dict即为字典。其中type字段中存储的是本字典使用到的各种函数指针, 包括散列函数, 键与值的复制函数, 释放函数, 以及键的比较函数. privdata是用于存储用户自定义数据。 这样, 字典的使用者可以最大化的自定义字典的实现, 通过自定义各种函数实现, 以及可以附带私有数据, 保证了字典有很大的调优空间.
- 字典为了支持平滑扩容, 定义了ht[2]这个数组字段:
- 一般情况下, 字典dict仅持有一个哈希表dictht的实例, 即整个字典由一个bucket实现.
- 随着插入操作, bucket中出现冲突的概率会越来越大, 当字典中存储的结点数目, 与bucket数组长度的比值达到一个阈值(1:1)时, 字典为了缓解性能下降, 就需要扩容
- 扩容的操作是平滑的, 即在扩容时, 字典会持有两个dictht的实例, ht[0]指向旧哈希表, ht[1]指向扩容后的新哈希表. 平滑扩容的重点在于两个策略:
- 后续每一次的插入, 替换, 查找操作, 都插入到ht[1]指向的哈希表中
- 每一次插入, 替换, 查找操作执行时, 会将旧表ht[0]中的一个bucket索引位持有的结点链表, 迁移到ht[1]中去. 迁移的进度保存在rehashidx这个字段中.在旧表中由于冲突而被链接在同一索引位上的结点, 迁移到新表后, 可能会散布在多个新表索引中去.
- 当迁移完成后, ht[0]指向的旧表会被释放, 之后会将新表的持有权转交给ht[0], 再重置ht[1]指向NULL
- 这种平滑扩容的优点有两个:
- 平滑扩容过程中, 所有结点的实际数据, 即dict->ht[0]->table[rehashindex]->k与dict->ht[0]->table[rehashindex]->v分别指向的实际数据, 内存地址都不会变化. 没有发生键数据与值数据的拷贝或移动, 扩容整个过程仅是各种指针的操作. 速度非常快
- 扩容操作是步进式的, 这保证任何一次插入操作都是顺畅的, dict的使用者是无感知的. 若扩容是一次性的, 当新旧bucket容量特别大时, 迁移所有结点必然会导致耗时陡增.
2.2.4 zskiplist
zskiplist是Redis实现的一种特殊的跳跃表。定义在server.h中
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplist内存布局

zskipList的核心要点:
- 头节点不持有任何数据,且其level[]的长度为32
- 每个节点有两个字段,ele字段持有数据,score字段标识节点的得分,节点之间根据score判断先后顺序,跳跃表中的节点按照节点的score升序排列。
- 每个节点持有一个backward指针,指针指向节点的前一个相邻节点
- 每个节点最多持有32个zskiplistLevel结构,实际数量在节点创建时,按照幂次定律随机生成,每个zskiplistLevel有两个字段forward和span
- forward字段指向比自己score高的某个节点。如果当前zskiplistLevel实例在level[]中的索引为x,则其forward字段指向的节点,其level[]字段的容量至少是x+1,所以在内存布局图中,foward指向总是水平的。
- span字段代表forward字段指向的节点,距离当前节点的距离,相邻的两个节点之间的距离定义为1
- zskiplist中持有level字段,用于记录所有节点中,除头节点外的level[]数组最长的长度
2.2.5 intset
intset是一个存储整数的数据结构,定义和实现在intset.h和intset.c中:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
/* Note that these encodings are ordered, so:
* INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
intset中的encoding取值有3个,分别是INTSET_ENC_INT16 (sizeof(int16_t)),INTSET_ENC_INT32 (sizeof(int32_t)),INTSET_ENC_INT64 (sizeof(int64_t)),length表示其中存储的整数个数,contents表示实际存储数值的连续内存区域
intset内存布局

- intset中的字段,包括contents中存储的数值,都是以主机序,即小端字节序存储的。因此redis如果运行在大端字节序的机器上,会有额外开销。
- 当encoding == INTSET_ENC_INT16时,contents中以 int16_t 的形式存储的数值。同理,当encoding==INTSET_ENC_INT32时,contents中以int32_t的形式存储数值。但是如果有1个数值元素超过了int32_t的取值范围,则整个intset都需要进行升级,所有的数值都要以int64_t的形式存储。因此生即的开销很大
- intset中的数值是以升序排列存储的,插入和删除的复杂度均为O(n),查找采用二分查找法,复杂度为O(log_2(n))
- intset的代码实现中,不预留空间,即每一次插入操作都会调用zrealloc接口重新分配内存。删除也会调用zrealloc接口减少占用的内存。节省空间,加大了时间开销。
- intset的编码方式一旦升级,不会再降级。
适用范围
- 所有数据处于一个稳定取值范围,例如位于int16_t的范围中。
- 数据稳定,增删操作不频繁,能够接受O(log_2(n))的查找开销。
2.2.6 ziplist
ziplist的核心设计思想是极致的节省内存
ziplist内存布局
ziplist的内存布局类似于intset,是一块连续的内存空间,如下图:

ziplist_entry内存布局
entry的内存布局如下: 1. 每个entry中用prevlen存储了前一个entry所占用的字节数,支持ziplist反向遍历。
1. 每个entry中用prevlen存储了前一个entry所占用的字节数,支持ziplist反向遍历。
2. 每个entry存储当前节点的类型
prevlen:前一个entry所占用的字节数,本身是一个变长字段,规定如下:
- 若前一个entry占用的字节数<254,则prevlen字段占1byte
- 若前一个entry占用的字节数>=254,则prevlen字段占5bytes,第一个字节值为254,即0xfe,另外4个字节以uint32_t存储着值。
encoding字段的规定如下:
- 若数据是二进制数据,且二进制数据长度<64bytes,那么encoding占1字节,其中高两位值固定为0,低六位值以无符号整数的形式存储着二进制数据的长度。即00xxxxxx,其中低6为bit xxxxxx 是用二进制保存的数据长度
- 若数据是二进制数据,且二进制数据长度>=64bytes,<16384bytes,那么encoding占用2个字节。在这两个字节16位中,第一个字节的高两位固定为01,剩余14个位,以小端序无符号整数的形式存储二进制数据的长度。即 01xxxxxx, yyyyyyyy,其中y是高8位,x是低6位。
- 若数据是二进制数据,且而二进制数据长度>=16384bytes,< 232-1bytes,则encoding占用5个字节。第一个字节是固定值10000000,剩余4个字节,按小端序uint32_t的形式存储二进制数据的长度。这个长度就是ziplist能存储的二进制数据最大长度,超过232-1字节的二进制数据,则ziplist无法存储
- 若数据是整数值,则规则不同:
- 所有存储数值的entry,encoding都仅占用一个字节,最高两位是11
- 若取值范围为 [0,12],则encoding和data放在同一个字节中,即1111 0001 - 1111 1101,高四位是固定值,低四位从 0001 - 1101,分别代表 0 ~ 12这15个数值
- 若取值范围为[-128,-1], [13,127] ,则encoding == 0b 1111 1110,数值存储在相邻的下一个字节,以int8_t形式编码
- 若取值范围为[-32768,-129],[128,32767],则encoding == 0b 1100 0000,数值存储在相邻的后两个字节中,以int16_t形式编码
- 若取值范围为[-8388608,-32769],[32768,8838607],则encoding == 0b 1111 0000,数值存储在相邻的后三个字节中,以小端序存储,占用三个字节
- 若取值范围为[-231,-8838608],[8838608,231-1],则encoding == 0b 1101 0000,数值存储在相邻的后四个字节中,以小端序int32_t形式编码
- 若取值范围超过上述范围,但在int64_t能表达的范围内,则encoding == 0b 1110 0000,数值存储在相邻的后八个字节中,以小端序int64_t形式编码
ziplist优缺点
- 节省空间,增删都不预留内存空间,立即缩容。
- 扩容时,会导致链式反应,一个节点的扩容可能导致每个节点都需要内存重分配。
2.2.7 quicklist
quicklist是一种以ziplist为节点的双端链表结构,它的定义与实现分别在quicklist.h和quicklist.c中,主要数据结构如下:
/* Node, quicklist, and Iterator are the only data structures used currently. */
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistIter {
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction;
} quicklistIter;
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
- quicklistNode,quicklist表面上是一个链表,这个结构体就是用于描述链表中的节点。它通过zl字段持有底层的ziplist。
- quicklistLZF,ziplist是一段连续的内存,用LZ4算法压缩后,就可以包装成一个quicklistLZF结构,是否压缩quicklist中的每个ziplist实例是一个可配置项。如果开启,则quicklistNode.zl字段指向的就是一个压缩后的quicklistLZF实例,否则就是一个ziplist实例。
- quicklist,定义了一个双链表。head,tail分别指向头尾指针。len代表链表中的节点。count指的是整个quicklist中的所有ziplist的entry数目。
- quicklistIter则是一个迭代器
- quicklistEntry是对ziplist中对entry概念的封装。
quicklist内存布局
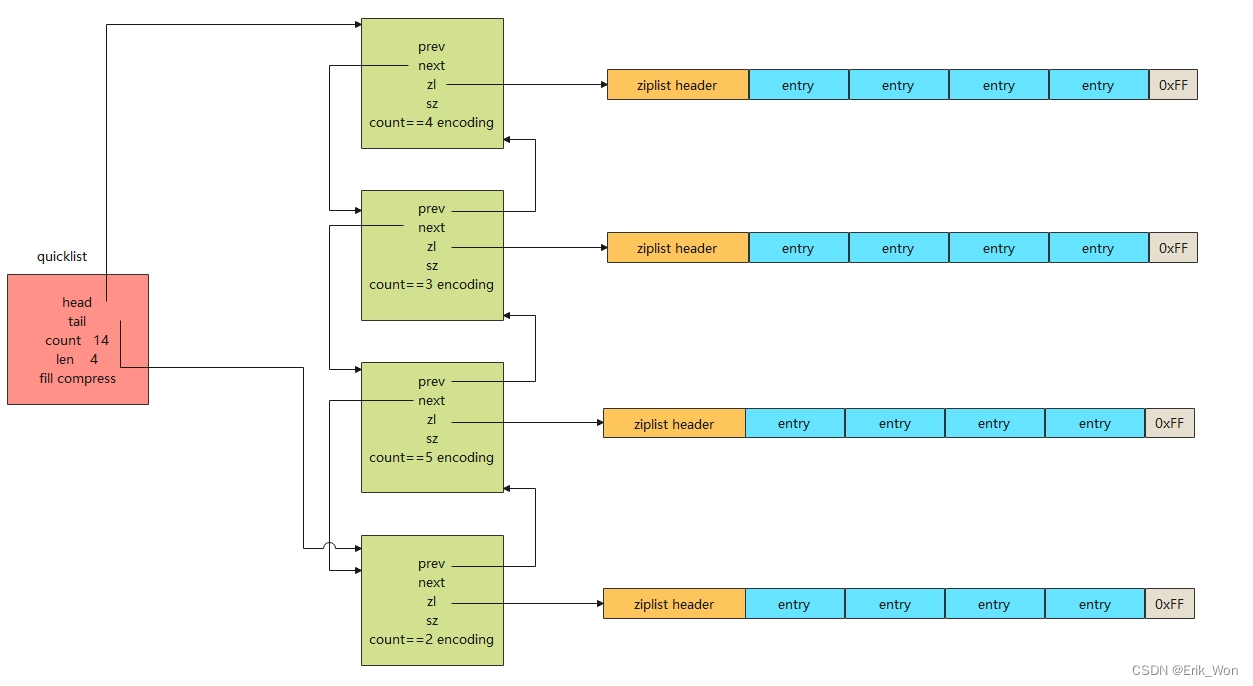 1. quicklist.fill的值影响着每个链表节点中,ziplist的长度
1. quicklist.fill的值影响着每个链表节点中,ziplist的长度
- 当数值为负时,代表以字节数限制单个ziplist的最大长度,具体是:
- -1 不超过4kb
- -2 不超过8kb
- -3 不超过16kb
- -4 不超过32kb
- -5 不超过64kb
- 当数值为正数时,代表以entry数目限制单个ziplist的长度,值即为数目。该字段仅占16位,因此最大值位2^15个
- quicklist.compress的值影响着quicklistNode.zl字段指向的是原来的ziplist,也是经过压缩包装后的quicklistLZF
- 0表示不压缩,zl字段直接指向ziplist
- 1表示quicklist的链表头尾节点不压缩,其余节点的zl字段指向时经过压缩后的quicklistLZF
- 2表示quciklist的链表头两个和末两个节点不压缩,其余节点的zl字段指向的都是经过压缩后的quicklistLZF
- 最大值为2^16
- quicklistNode.encoding字段,可以指示本链表节点所持有的ziplist是否经过了压缩,1表示未压缩,持有的是原生的ziplist,2代表压缩过
- quicklistNode.container字段表示每个链表节点所持有的数据类型是什么。默认实现的是ziplist,对应该字段的值是2。
- quicklistNode.recompress字段表示当前节点所持有的ziplist是否被解压过,1代表之前被解压过,且在下一次操作时重新压缩。
quicklist优缺点
优点:quicklist可以通过指向ziplist解决了耗费内存的问题;可以通过自定义quicklist.fill 根据经验调参
缺点:每次增删操作整个ziplist的内存都需要重新分配。
2.2.8 zipmap
zipmap是redis实现的轻量级字典。
zipmap的定义与实现在zipmap.h与zipmap.c两个文件中, 其定义与实现均未定义任何struct结构体, 因为zipmap的内存布局就是一块连续的内存空间。
zipmap内存布局
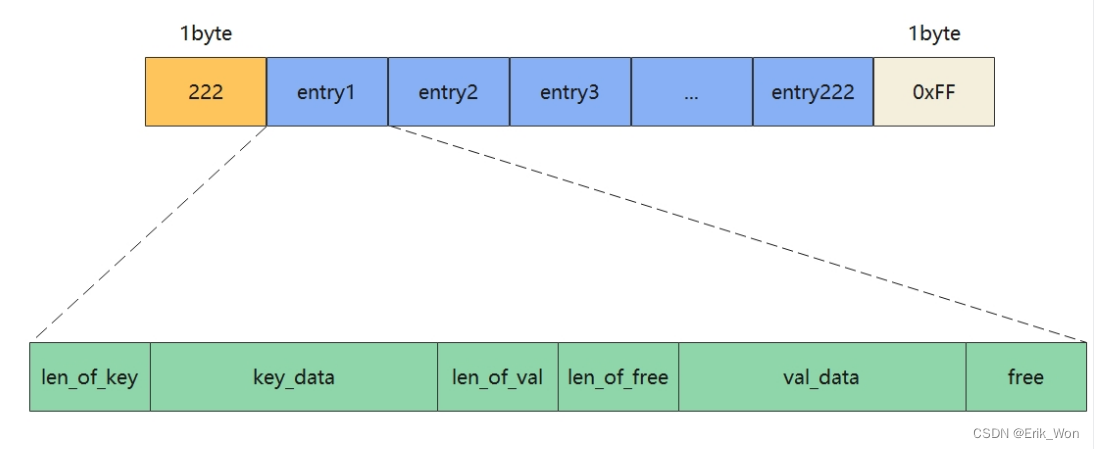
- zipmap的第一个字节存储的是zipmap的键值对个数,如果个数>254的话,那么这个字节的值就固定为254,需要遍历才知道真实键值对数量
- zipmap最后一个字节固定为0xFF
- zipmap中的每一个键值对称为一个entry,其内存占用如图所示:
- len_of_key 一字节或五字节,存储的是键的二进制长度,如果长度<254,则用1字节存储,否则用5字节存储,第一个字节的值固定为0xFE,后4个字节以小端序uint32_t类型存储着键的二进制长度
- key_data为键的数据
- len_of_val,一字节或五字节,存储的是值的二进制长度,编码方式同len_of_key
- len_of_free,固定为1字节,存储的是entry中未使用的空间的字节数,未使用的空间即为图中的free字段,一般是由于键值对中的值被替换所发生的。例如:键值对 <hello,word> 修改为 <hello,w> 就会产生限制空间
- val_data,为值的数据
- free,为闲置空间,由于len_of_free的值最大只能是254,所以如果值的变更导致闲置空间大于254的话,zipmap就会回收内存空间
zipmap适用场景
- 键值对量不大,单个键,单个值长度小
- 键值均是二进制数据,而不是复合结构或者复杂结构,zipmap直接持有数据
参考文章:
https://www.cnblogs.com/gaopengfirst/p/10072680.html
https://blog.csdn.net/weixin_51281362/article/details/125447084?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-125447084-blog-119769496.pc_relevant_3mothn_strategy_and_data_recovery&spm=1001.2101.3001.4242.1&utm_relevant_index=3