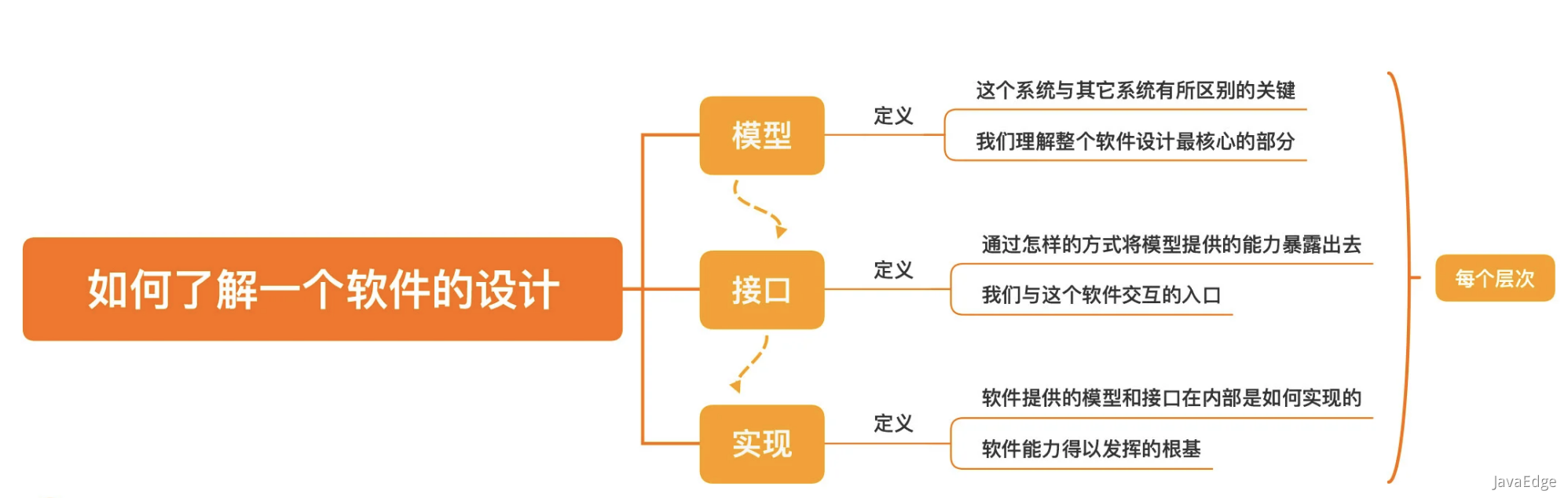
问题
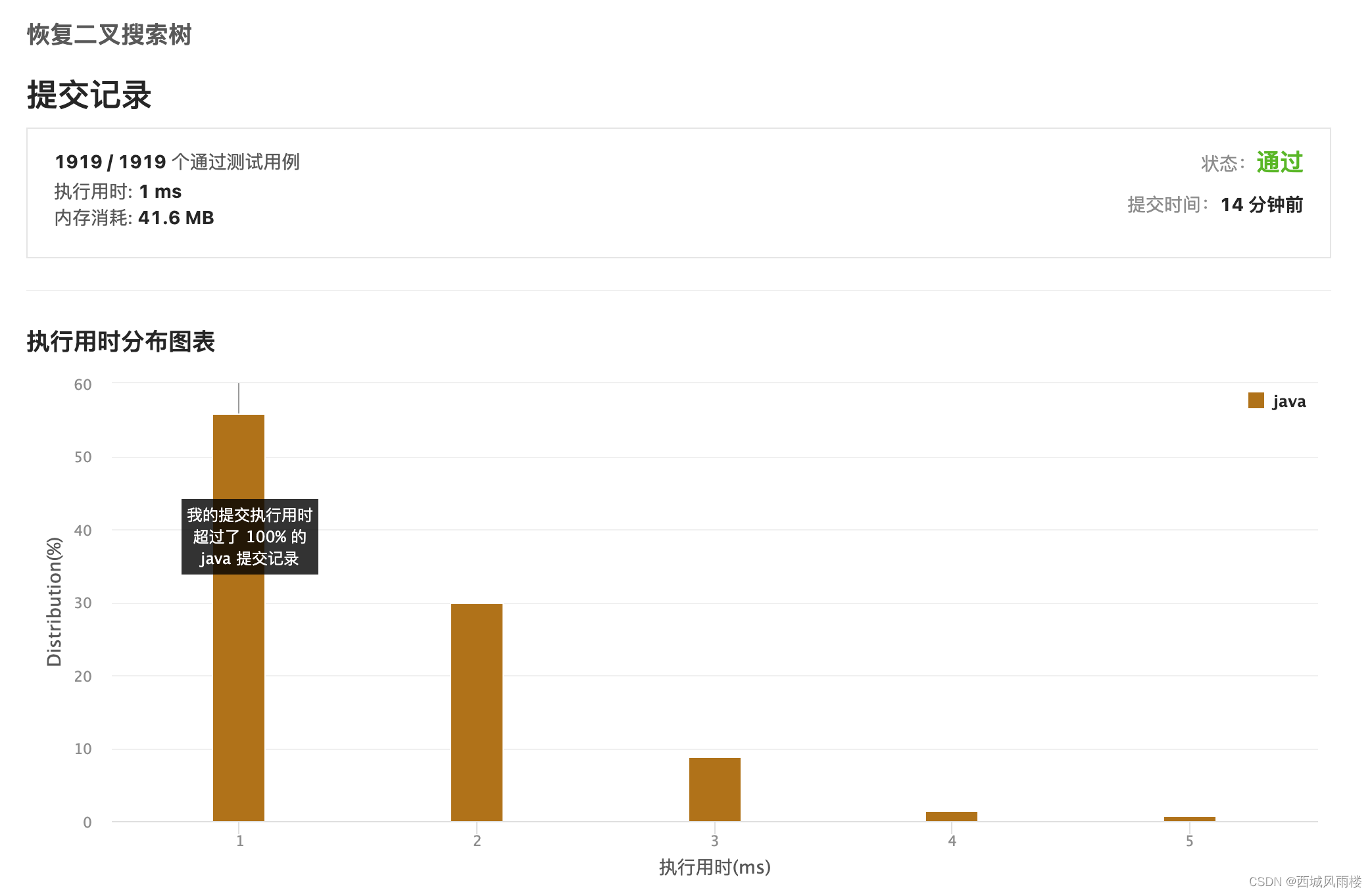
先看数据:deliver 表是主表,一个客户会发生多次投递行为:
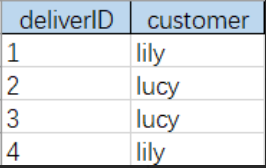
deliverItem 表是从表,一个投递行为有多个投递项,delivered 是投递状态(1 表示未完成,2 表示投递完成):
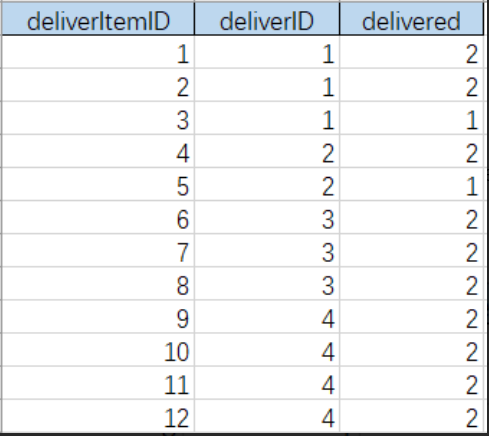
需求是统计每个客户下,全部完成的投递行为有几次,未完成(只要存在未完成的投递项,就算作未完成)的投递行为有几次。
解答
自然思路的解题步骤:
1、 在deliverItem表里统计每个投递行为下未完成投递的项目数notDelivered;
2、 上一步结果和deliver表连接在一起,得到新的结果集[customer,notDelivered]
3、 按照customer分组,统计每个customer里notDelivered=0(已完成)个数 / notDelivered>0(未完成)个数
SQL:
select r1.customer,r1.complete,r2.notComplete
from
(select customer, count(*) as complete
from
(select d.customer, d2.notDelivered
from deliver d
left join
(select deliverID,count(*) as notDelivered
from deliverItem
where delivered==1
group by deliverID) d2
on d.deliverID=d2.deliverID)
where notDelivered is null
group by customer
) r1
join
(select customer, count(*) as notComplete
from
(select d.customer, d2.notDelivered
from deliver d
left join
(select deliverID,count(*) as notDelivered
from deliverItem
where delivered==1
group by deliverID) d2
on d.deliverID=d2.deliverID)
where notDelivered <> null
group by customer
) r2
on r1.customer=r2.customer
按照开始的自然思路编写SQL的时候,发现会遇到各种困难,通过寻找符合SQL语法的替代思路逐一解决,就得到上面的结果。需要绕行的逻辑复杂时,不同的程序员思维方式不一样,考虑的SQL性能优化方案不同,最终利用各种技巧实现的绕行方案也会千差万别。最终SQL的思路变成了这样:
1、 在deliverItem表里过滤出所有未完成的投递项,按照deliverID分组,统计每个分组未完成项的个数netDlivered;
2、 deliver表通过左连接方式连接第一步的结果集得到新结果集[customer,notDelivered];
3、 按照customer分组,统计出每个客户下全部完成(notDlivered=null)的投递行为的个数complete,得到结果集[customer,commplete];
4、 重复第1步;
5、 重复第2步;
6、 重复第3步,但稍有改动,把notDlivered=null条件变成notDlivered>0,统计出每个客户下未完成的投递行为个数notComplete,得到结果集[customer, notComplete];
7、 两个结果集连接,得到答案[customer,complete,notComplete]。
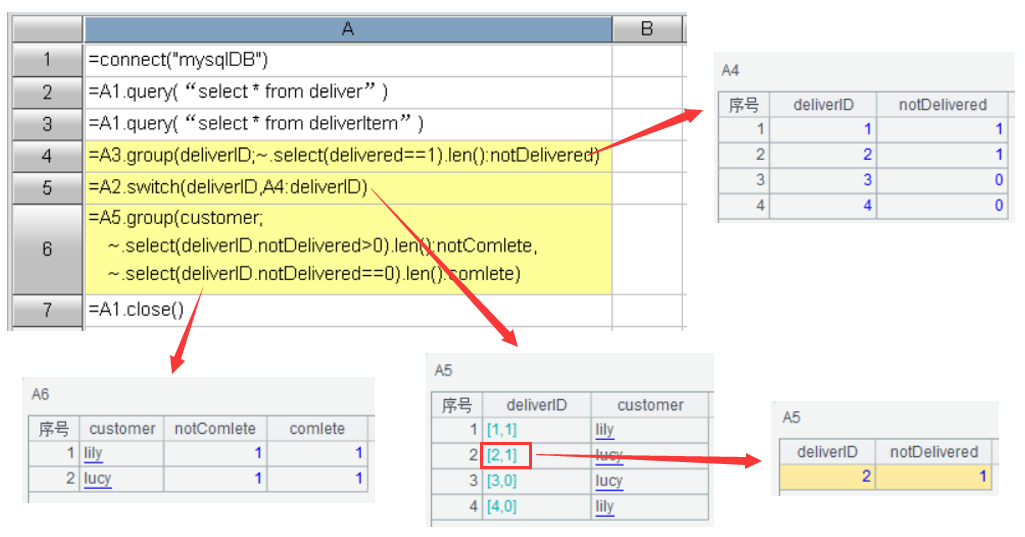
集算器SPL脚本:

| A |
1 | =connect("mysqlDB") |
2 | =A1.query(“select * from deliver”) |
3 | =A1.query(“select * from deliverItem”) |
4 | =A3.group(deliverID;~.select(delivered==1).len():notDelivered) |
5 | =A2.switch(deliverID,A4:deliverID) |
6 | =A5.group(customer; ~.select(deliverID.notDelivered>0).len():notComlete, ~.select(deliverID.notDelivered==0).len():comlete) |
7 | =A1.close() |
A1连接数据库;
A2/A3加载两个表的数据(如果换成excel或csv文本等等数据,也有方便的加载函数);
A4/A5/A6是该查询的功能语句,基本能按照自然思路完成编程;
A4把deliverItem表按deliverID分组,汇总出每个投递行为下未完成投递项的个数notDelivered,包括notDelivered=0的组;
A5把A4结果集和deliver表连接起来,把deliver表的deliverID字段值用switch函数替换成A4结果集里相对应的记录,注意SQL表里无法表达这种嵌套,更无法支持这种嵌套结构带来的便捷计算操作。在下面的运行结果截图里能清楚的看到这种结构;
A6以customer分组,查找notDelivered>0的个数得到未完成投递行为个数notComplete,查找notDelivered=0的个数得到完成投递行为个数complete。
总结
稍微复杂点的查询需求,写SQL就会是个烧脑的过程,除了证明我们人脑很聪明,逻辑思维能力强之外,剩余的就全是缺点,每个人经常用不同于其他人思路的方式绕行到同一个结果上,个性化这么强的编程方式,导致编写SQL、阅读SQL、调试SQL都很困难,维护成本也大大增高。
在程序员编程描述计算这件事上,集算器 SPL 语言通过创新的数学理论模型《离散数据集》,大大改善《关系代数》(SQL背后的数学模型)在描述计算时的困难。简单的说是对有序计算、更彻底的集合运算、提倡分步等多方面创新,达到提高程序员描述计算效率的目的。而提高描述计算效率的效果,除了降低开发、维护成本,还有个副作用是提高性能,因为高性能算法的程序也更容易被编写出来了。
这里有更多详细的技术文章:
SPL 语言
SQL 优化
快速上手试试:
下载集算器
如何免费使用润乾集算器