文章目录
- 1、RAG( Retrieval-Augmented Generation)
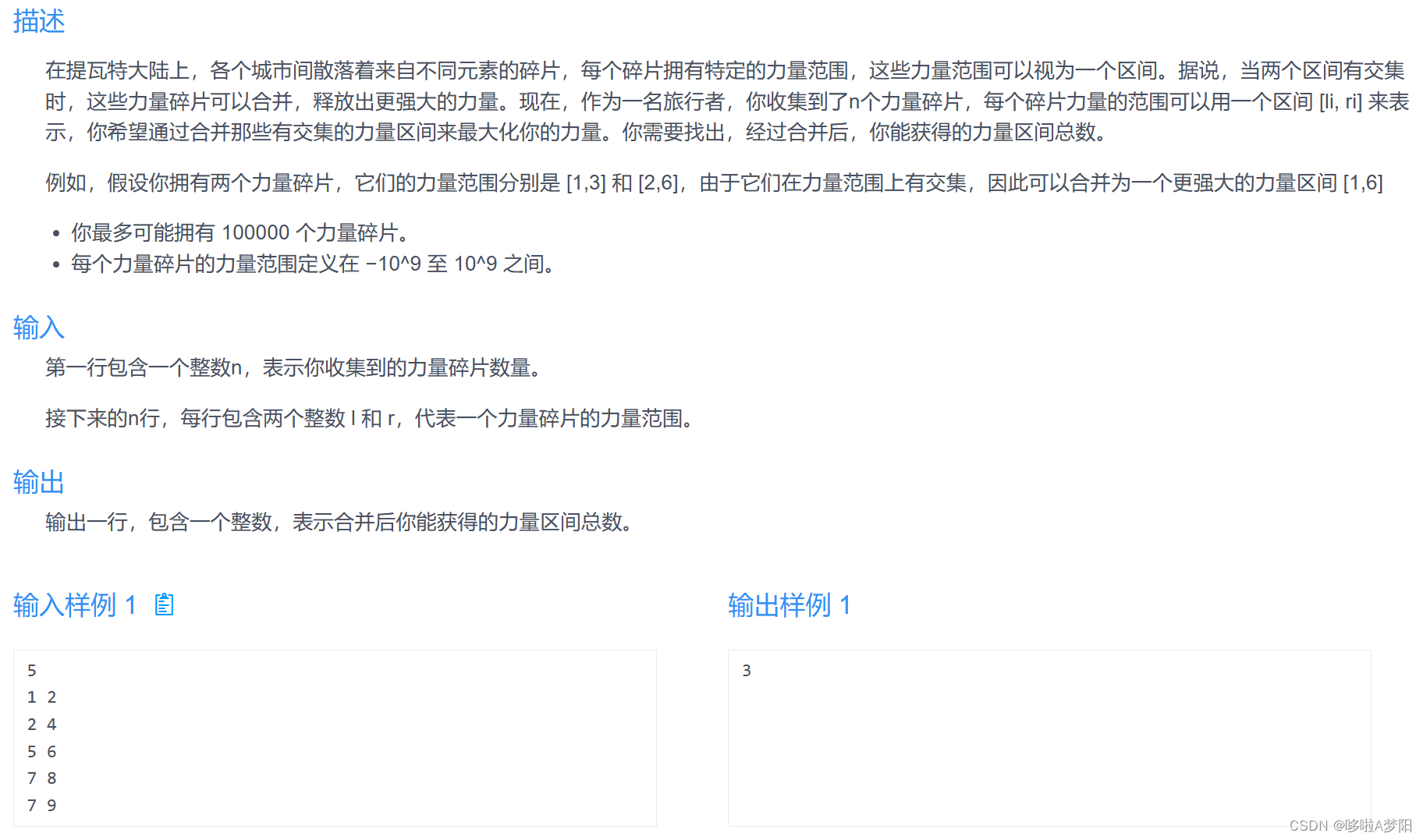
- 2、RAG的基本原理
- 3、简化训练流程
- 4、RAG增强检索原理图
1、RAG( Retrieval-Augmented Generation)
RAG( Retrieval-Augmented Generation)是一种结合了检索和生成两种策略的AI训练方法,旨在通过检索相关信息来增强模型的生成能力,从而提高回答问题或生成文本的质量和准确性。这种方法尤其适用于需要处理大量信息、追求高准确度和上下文相关性的场景,如问答系统、对话系统等。
2、RAG的基本原理
-
检索阶段:建立一个知识库,这个知识库可以是文档集合、数据库条目、预训练语言模型的embedding数据库等(向量数据库)。当接收到一个查询(比如一个问题)时,系统首先在这个知识库中进行检索,找出与查询最相关的少量条目或片段。
-
生成阶段:将检索到的信息作为输入,馈入到一个生成模型(如Transformer)中,该模型基于这些输入信息生成最终的响应。这样,生成的文本不仅依赖于模型本身的参数,还融入了从外部知识库检索到的具体内容,从而增强了生成内容的相关性和准确性。
3、简化训练流程
-
准备知识库:收集并整理你希望AI学习和引用的数据,创建一个结构化的或非结构化的知识库。这一步可能包括文本预处理、语义索引构建等。
-
检索模型训练/选择:如果知识库非常大,你可能需要训练一个高效的检索模型,如使用向量空间模型、TF-IDF、或者更先进的如BERT-based的语义检索模型。对于较小规模或实验性质的项目,可以直接使用现成的检索工具或API。
-
生成模型准备:选择或预训练一个生成模型,如GPT系列、T5等。这些模型通常已经过大规模文本数据训练,具备了一定的语言生成能力。
-
联合训练(可选):在某些情况下,为了更好地融合检索和生成两个阶段,可以进行联合训练。这意味着在训练生成模型时,不仅要考虑生成文本的质量,还要考虑其与检索到的信息的相关性。这通常涉及到设计特定的损失函数来指导训练过程。
-
测试与微调:使用测试集对模型进行评估,根据反馈调整检索模型的参数、知识库的构建方式或生成模型的设置,以优化整体性能。
-
部署应用:将训练好的RAG系统部署到实际应用中,如集成到在线客服系统、智能搜索引擎等,持续监控并根据用户反馈进行迭代优化。
RAG方法的优势在于它能够结合大数据的力量和深度学习模型的灵活性,尤其适合处理需要广泛知识支撑的任务,但同时也带来了计算复杂度增加和训练难度提升的挑战。
4、RAG增强检索原理图


人生从来没有真正的绝境。只要一个人的心中还怀着一粒信念的种子,那么总有一天,他就能走出困境,让生命重新开花结果。