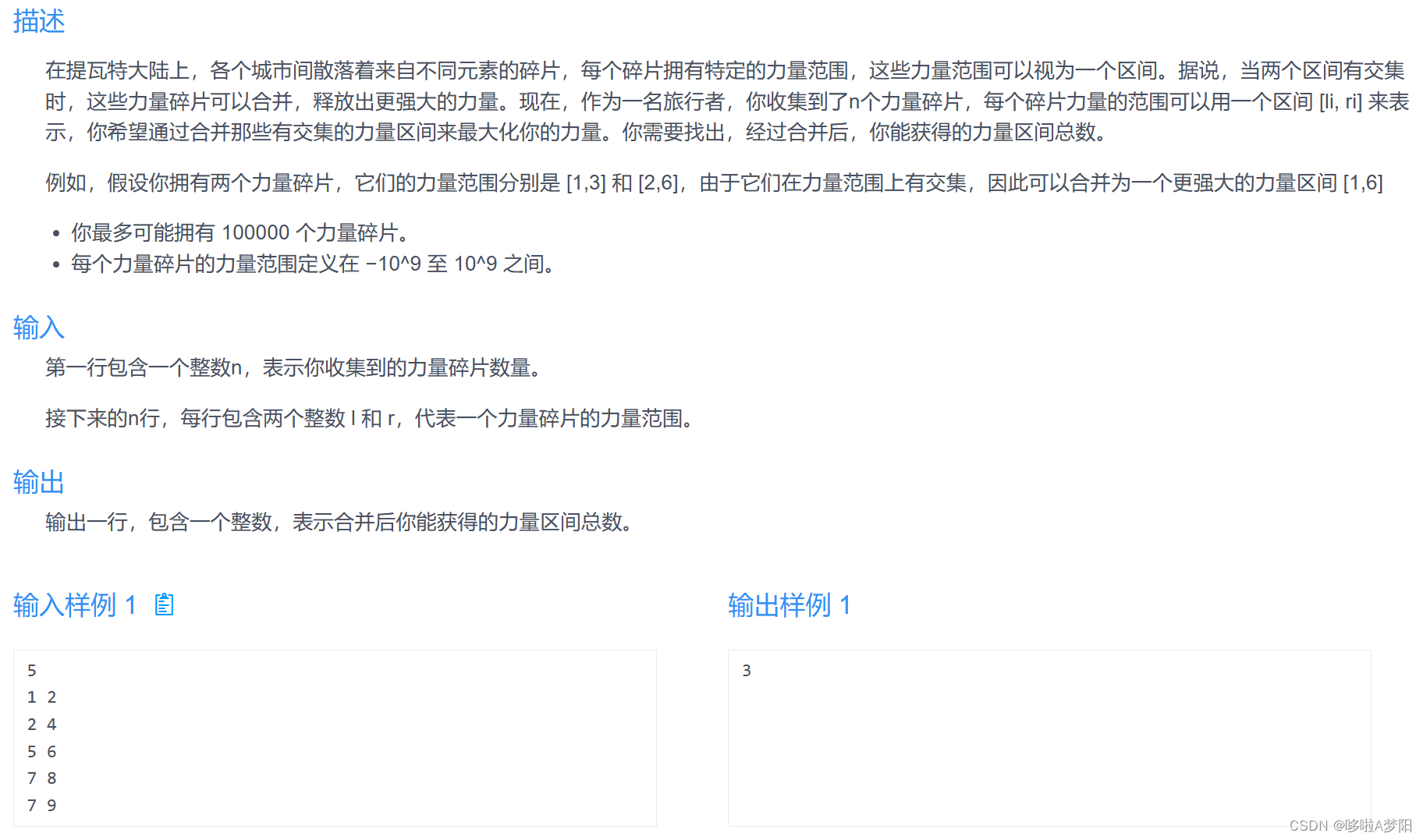
某某某加固系统内核so dump和修复:
某某某加固系统采取了内外两层native代码模式,外层主要为了保护内层核心代码,从分析来看外层模块主要用来反调试,释放内层模块,维护内存模块的某些运行环境达到防止分离内外模块,另外由于内层模块不是通过系统加载的,所以实现了自主的ELF加载,这样就实现内层模块的加密处理。这些实现后就可以依赖内层模块保护dex。从而达到系统保护目的。
对于某某某加固系统的反调试网上已经有很多资料了,就不再作为重点介绍了。下面主要介绍对内层模块的加载,加密,保护。这些外面资料不多的内容。
外层解密内层核心模块的解密算法是使用zlib库的uncompress函数实现的,不过解密函数解密出来的并不是整个的模块,而是被加密了或者说被移除了四个部分的模块,包含:
program_header_table、.rel.dyn、.rel.plt、Dynamic Segment 。由于是自己的加载系统加载,所以这些被move的部分依赖父模块组装,防止内存直接dump出解密的内层模块。
下面给出frida dump这些数据的脚本,并加以说明:
Java.perform(function () {
var i = 0;
var phadd = 0;
var jmprel = 0;
var rel = 0;
var dynadd = 0;
var buff = 0;
console.log("begin")
var fileclass = Java.use("java.io.File");
var mysavePath = "/data/data/" + pkg_name + "/myso";
var pathDir = fileclass.$new(mysavePath);
if (!pathDir.exists()) {
pathDir.mkdirs();
}
console.log("mysavepath:"+pathDir)
Interceptor.attach(Module.getExportByName('libz.so', 'uncompress'), {
onEnter: function (args) {
if (i == 0) {
if (args[2] != null) {
var memcpy_add = Module.findExportByName("libc.so", "memcpy");
console.log("memcpy:" + memcpy_add);
Interceptor.attach(memcpy_add, {
onEnter: function (args) {
console.log("begin:memcpy,len:" + args[2]);
console.log(hexdump(args[1]));
if (args[2] == 0x100) {
// program_header_table 的大小一般是固定的
phadd = args[0];
console.log(hexdump(args[1]))
}
if (args[2] == 0x948) {
//.rel.plt 数据;
jmprel = args[0];
console.log(hexdump(args[1]))
}
if (args[2] == 0x4a58) {
//.rel.dyn 数据
rel = args[0];
console.log(hexdump(args[1]))
}
if (args[2] == 0xd8) {
//Dynamic Segment 数据也是一般固定长度
dynadd = args[0];
console.log(hexdump(args[1]))
}
if (args[2] == 0xbbff4) {
//这个就是某某某加固的加载,加载基地址就是copy到的空间地址,这个数据是经过解密的移除上面部分的模块数据;
console.log(hexdump(args[1])); //这个hexdump中可以看到ELF头,所以是个标记,上面顺序就可以确定了。
var new_so_base = args[0];
console.log("newso_base:" + args[0])
}
if (args[2] == 0x38fc) {
//到这里上面得到被move的四个部分数据也已经解密出来了,在这里就可以开始dump了
console.log(args[0])
var file_path = pathDir + "/mydump_" +phadd+ ".dat";
console.log("----save begin1-----");
var file_handle = new File(file_path, "wb");
console.log("----save begin2-----");
if (file_handle) {
console.log("----save begin3-----");
Memory.protect(ptr(phadd), 0x100, 'rwx');
var libso_buffer = ptr(phadd).readByteArray(0x100);
file_handle.write(libso_buffer);
file_handle.flush();
file_handle.close();
console.log("[dump]:"+ file_path);
}
var file_path = pathDir + "/mydump_" +jmprel+ ".dat";
console.log("----save begin1-----");
var file_handle = new File(file_path, "wb");
console.log("----save begin2-----");
if (file_handle) {
console.log("----save begin3-----");
Memory.protect(ptr(jmprel), 0x948, 'rwx');
var libso_buffer = ptr(jmprel).readByteArray(0x948);
file_handle.write(libso_buffer);
file_handle.flush();
file_handle.close();
console.log("[dump]:"+ file_path);
}
var file_path = pathDir + "/mydump_" +rel+ ".dat";
console.log("----save begin1-----");
var file_handle = new File(file_path, "wb");
console.log("----save begin2-----");
if (file_handle) {
console.log("----save begin3-----");
Memory.protect(ptr(rel), 0x4a58, 'rwx');
var libso_buffer = ptr(rel).readByteArray(0x4a58);
file_handle.write(libso_buffer);
file_handle.flush();
file_handle.close();
console.log("[dump]:"+ file_path);
}
var file_path = pathDir + "/mydump_" +dynadd+ ".dat";
console.log("----save begin1-----");
var file_handle = new File(file_path, "wb");
console.log("----save begin2-----");
if (file_handle) {
console.log("----save begin3-----");
Memory.protect(ptr(dynadd), 0xd8, 'rwx');
var libso_buffer = ptr(dynadd).readByteArray(0xd8);
file_handle.write(libso_buffer);
file_handle.flush();
file_handle.close();
console.log("[dump]:"+ file_path);
}
}
if (args[2] == 0xb4) {
//console.log(JSON.stringify(this.context))
console.log(args[0])
var file_path = pathDir + "/mydump_" + buff+".so";
console.log("----save begin1-----");
var file_handle = new File(file_path, "wb");
console.log("----save begin2-----");
if (file_handle) {
console.log("----save begin3-----");
Memory.protect(ptr(buff), 0xc0000, 'rwx');
var libso_buffer = ptr(buff).readByteArray(0xc0000);
file_handle.write(libso_buffer);
file_handle.flush();
file_handle.close();
console.log("[dump]:"+ file_path);
}
}
}
},
onLeave: function (retval) {
// simply replace the value to be returned with 0
}
})
})
上面代码只是说明功能,扣出来的,需要自己整理下可能才能执行。
脚本的原理就是根据某某某加固流程,父模块使用uncompress解压后会把解压出来的被偷走的数据重新解密到新的内存地址,在memcpy时得到内存地址和长度,然后等解密出来后dump数据。
另外是根据数据的大小取相关数据的,每个APP可能会不同,需要先跑下看看。
需要说明下,首先跑下hook uncompress后的memcpy hexdump,memcpy加载的新地址数据出现ELF头数据的,表明加载了。然后向上逆推其他数据,这样就能确定每个的数据大小,然后更改脚本,获取数据,并dump下来。
比如本例:
begin:memcpy,len:0xbbff4
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
c9085589 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
c9085599 03 00 28 00 01 00 00 00 00 00 00 00 34 00 00 00 ..(.........4...
c90855a9 bc fa 0b 00 00 00 00 05 34 00 20 00 08 00 28 00 ........4. ...(.
c90855b9 19 00 18 00 11 a6 dd 35 da cf 22 1a 71 b7 8b 08 .......5..".q...
由于父模块需要内存偏移修正,所以完整的模块需要在后面的一次才能dump。
拿到了需要的so模块数据,我们需要修复这个so模块,否则ida无法分析,用010Editor也会打开失败。下面进入so修复:
使用的工具有010Editor和ELFfix
ELFfix 修复原理具体请参考:
https://bbs.pediy.com/thread-192874.htm
用010Editor打开dump的so模块,会提示错误。
我们已我们已经知道被移除了填充杂乱数据的几个关键的部分。所以肯定不能正常加载。当然修复是需要理解下ELF的文件格式和内存加载原理。这样更便于理解为啥需要这样步骤修复。这个各位自己学习学习了。
首先我们需要还原program_header_table ,这个是系统解析加载的关键数据,用010Editor打开我们刚才dump出来的0x100字节的那个数据
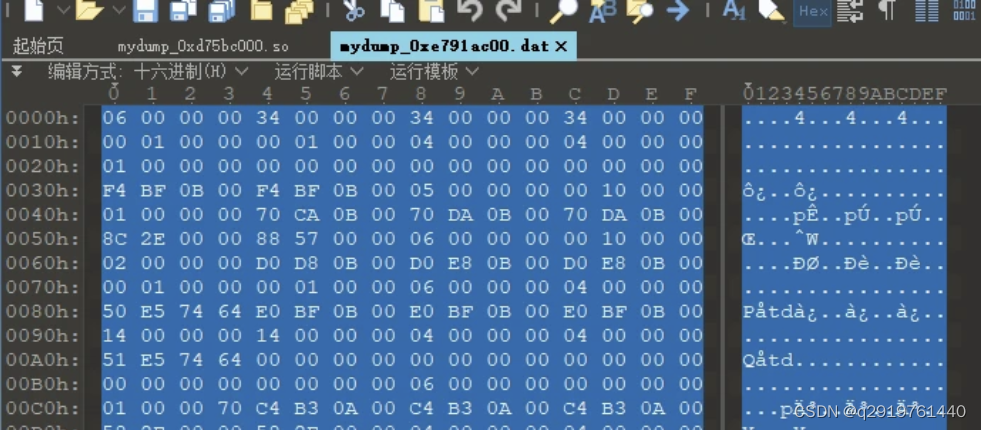
复制并覆盖到dumpso的program_header_table里面,
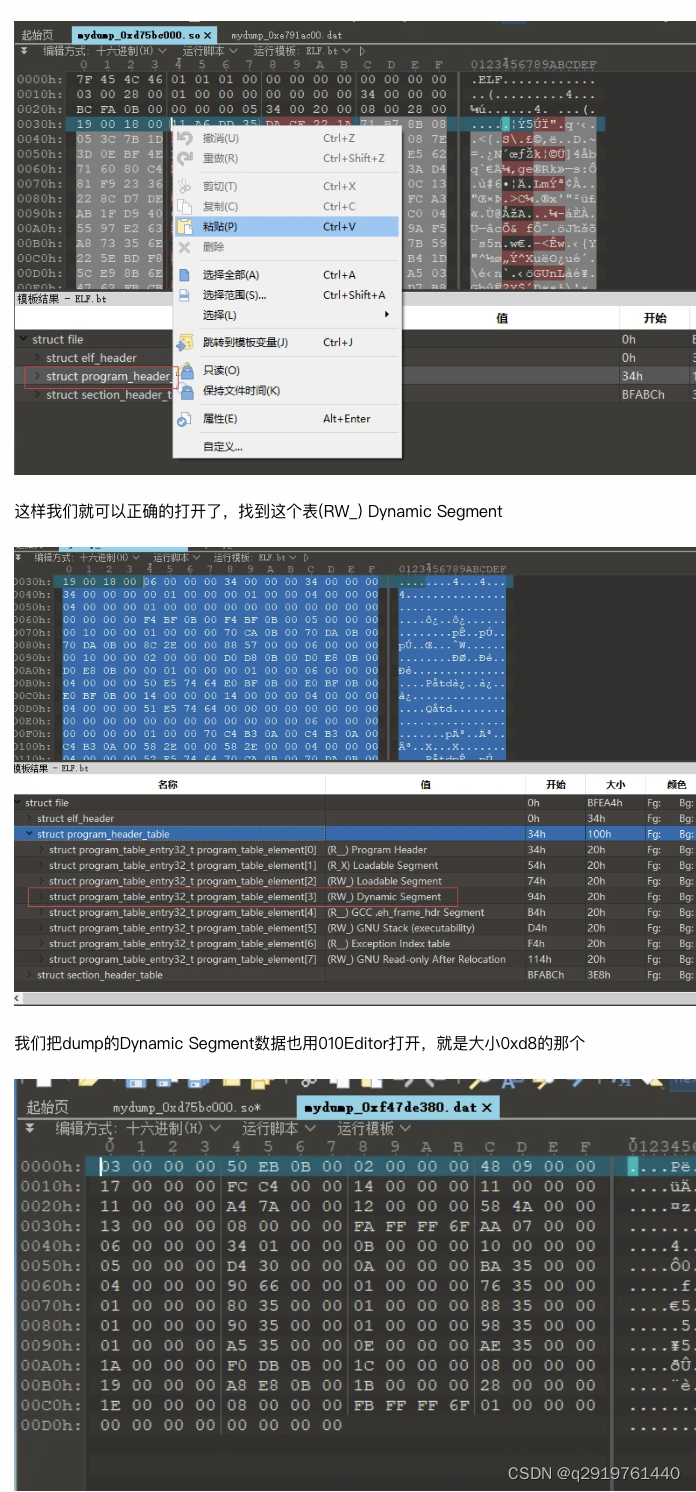
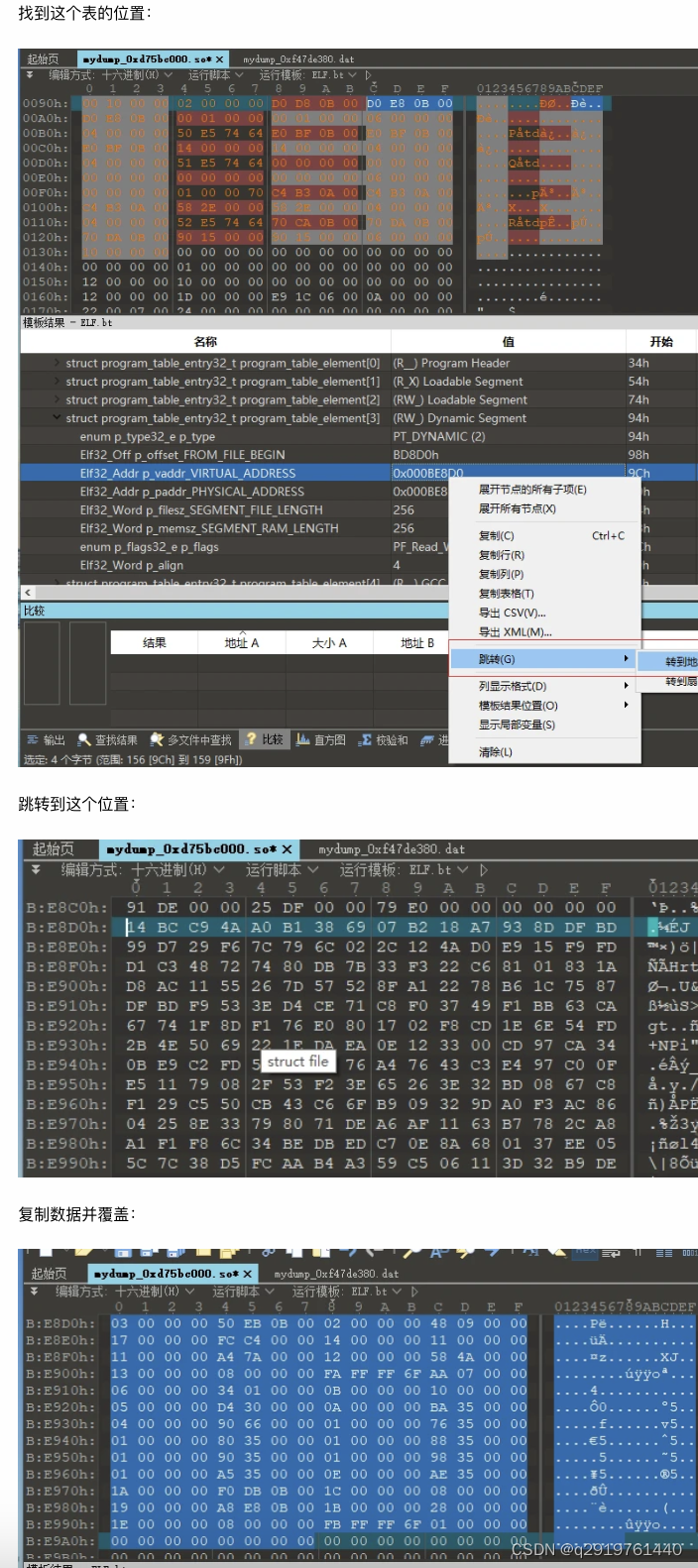
好了,到这里我们完成ELFfix需要的关键数据,保存这个文件,然后可以使用ELFfix工具进行修复了
复制到ELFfix目录下,并执行相关的修复命令会得到修复后的文件:
dump_new_full.so ß修复后的so
再次用010Editor打开这个修复后的so,还是会提示错误。不过打开后section_header_table已经正确了,原来的section_header_table是错误的: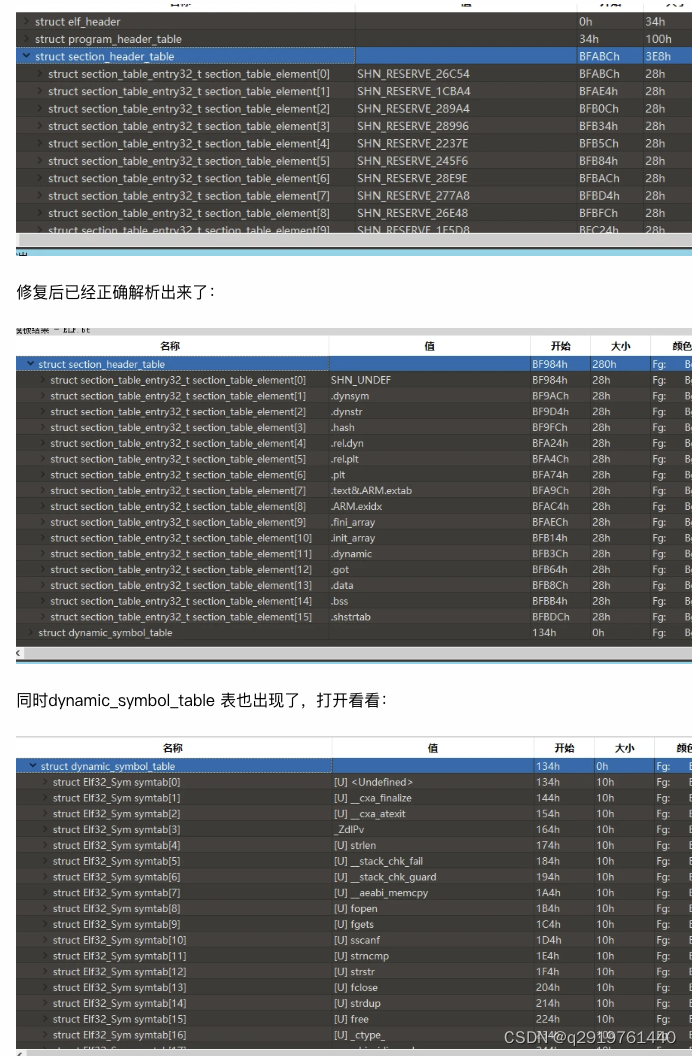
来说下为啥先要修复program_header_table 节和这个段里面的Dynamic Segment,根据ELFfix作者文章里面说明,修复是依赖这两个数据进行解析得到ELF section,所以必须先还原这两个数据块。
下面开始还原rel数据,一个是jmprel,一个是rel
我们打开这两个节: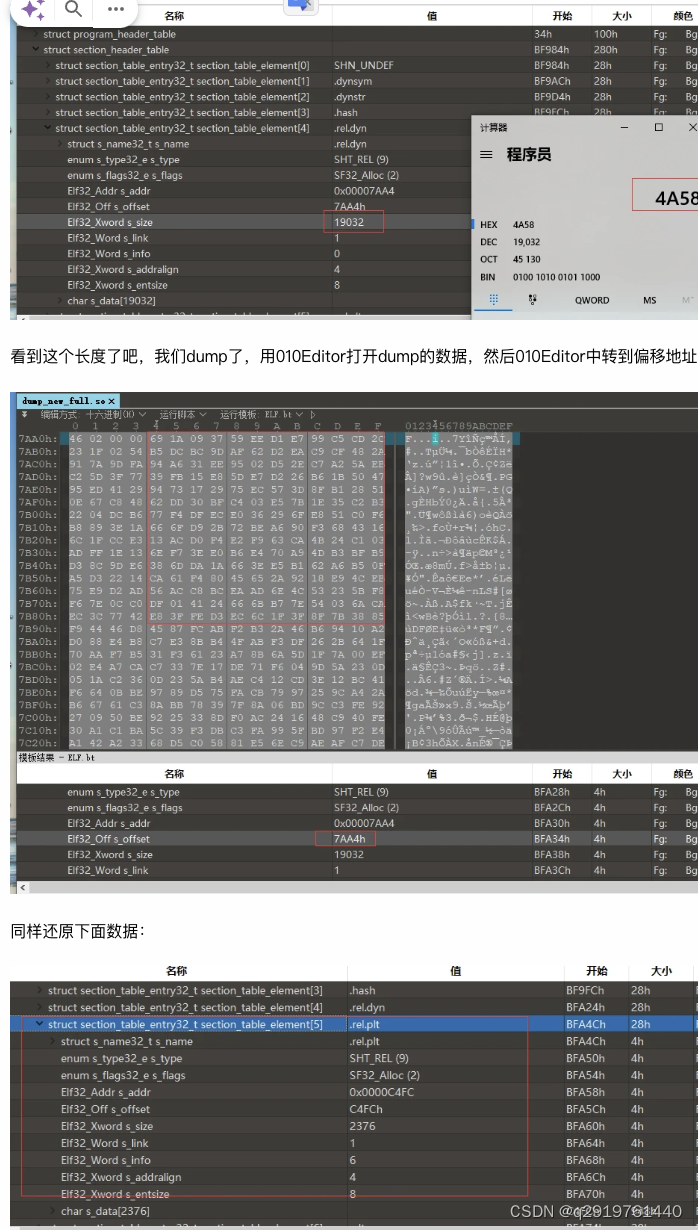
到这里内层的so模块被修复还原出来了,IDA加载完全没问题了,得到这个模块我们就可以用IDA分析调试了。当然也可以脱壳使用了。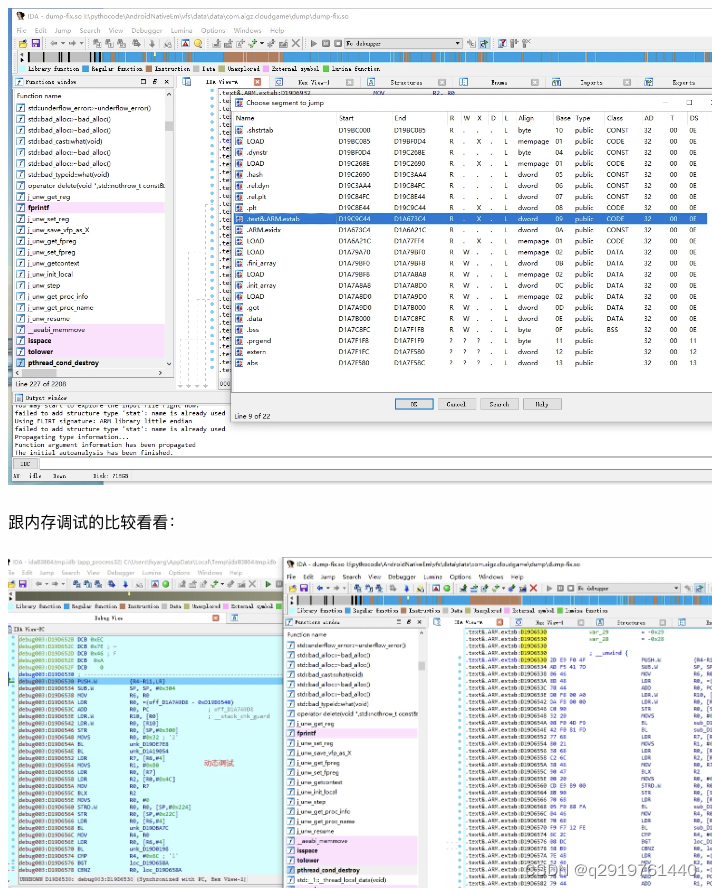
注意:目前这个ELFfix不支持64位程序修复。
好了,有了这个就可以详细的分析某某某内层模块的功能,当然也可以patch代码等操作了。
下面来看看某某某加固系统如何来保护内层so功能模块的。比较有特色
Java层偷Native层代码
某某某加固为了保护内层so不能脱离外层so环境,做了一些防范措施,这种也是,通过移除关键部位的二进制代码,如果脱离了整个环境,那么就会执行错误,被移除的二进制代码丢失。
| 1 2 3 4 |
|
内层在Java层使用getByte这个函数获取被偷走的二进制代码数据,填充回so的执行中。
被偷的数据:
>dump 0x10004b1
010004B1: 00 00 00 00 00 00 00 00 BD 10 B5 4F F6 75 74 E8 ...........O.ut.
010004C1: BF 10 BD 10 B5 4F F6 76 74 E8 BF 10 BD 10 B5 4F .....O.vt......O
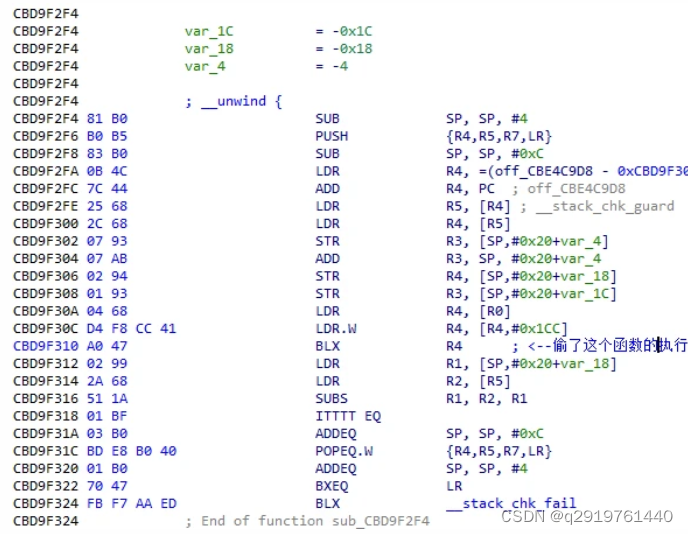
来看看这个是啥函数,原来是:JNIEnv->CallStaticObjectMethodV
这种Java层偷函数二进制执行代码的方式还是比较新颖的。
关键参数放父模块,通过导出函数调用
一般模块的导出函数都是给其他模式引用的接口,某某某这个导出函数却是调用父模块的接口,因为子模块的加载完全是父模块负责的,所以这个接口的填充是父模块做的,所以如果脱离了父模块,这个函数就变成了空的。而且这个函数还是个特别的核心函数,来看看:

获取key,这个函数是获取解密算法rc4的key的,如果没有这个解密key,后面的dex解密都会失败。所以必须到父模块中执行。
通过查询有两个地方调用:
这个就是某某某自己实现的类似乱序处理过的多功能集成函数。
来看看key计算的时候参数是啥:
======================= Registers =======================
R0=0x20917ec R1=0x350 R2=0x2024006 R3=0x2024018
R4=0x2024000 R5=0x2024006 R6=0x0 R7=0xcbcca6e8 R8=0x350
R9=0x350 R10=0x2024018 R11=0x202c350 R12=0x80000000 SP=0x7ffad8
LR=0xcbda5859 PC=0xcbdb08fc
======================= Disassembly =====================
0xcbdb08fc: blx r7
020917EC: 22 39 52 52 54 52 52 52 42 52 52 52 13 02 02 19 "9RRTRRRBRRR....
020917FC: 17 0B 60 30 60 31 6A 61 66 67 33 6A 65 61 64 6A ..`0`1jafg3jeadj
0209180C: 62 34 22 39 52 52 5A 52 52 52 53 52 52 52 01 36 b4"9RRZRRRSRRR.6
0209181C: 39 17 3C 26 20 2B 63 22 39 52 52 5E 52 52 52 4E 9.<& +c"9RR^RRRN
0209182C: 52 52 52 33 31 26 3B 24 3B 26 2B 1C 33 3F 37 31 RRR31&;$;&+.3?71
0209183C: 3D 3F 7C 33 3B 35 28 7C 27 3B 7C 30 33 21 37 7C =?|3;5(|';|03!7|
执行下这个函数,得到的key:
>dump 0x2024006
02024006: 67 5E 7F 35 70 37 78 2E 7D 22 75 27 08 56 4A A1 g^.5p7x.}"u'.VJ.
上面的参数哪里来的呢?
分析发现原来是从原始包里面用libz解压出来的:
Executing syscall openat(ffffff9c, 02029000, 00020000, 00000000) at 0xcbc28be4
path:/data/app/xxxxxxxx-1/base.apk
这个解出来就是原始包里面的classes.dex部分:
另外一个地方的调用参数如下:
======================= Registers =======================
R0=0x7ffbf9 R1=0x0 R2=0x2024040 R3=0x7ffb10
R4=0xcbc761c8 R5=0x7ffbf8 R6=0x202b054 R7=0xcbde56df R8=0xcbc761c8
R9=0x202c34c R10=0x0 R11=0x2024000 R12=0x2024040 SP=0x7ffb08
LR=0xcbcca6e8 PC=0xcbdb0982
======================= Disassembly =====================
0xcbdb0982: blx r2
>dump 0x7ffbf9
007FFBF9: 00 DA CB 54 B0 02 02 DF 56 DE CB C8 61 C7 CB 00 ...T....V...a...
007FFC09: 00 00 00 2D 00 00 00 00 60 02 02 00 70 02 02 F0 ...-....`...p...
这是个校验调用,如果脱离父模块就会死在这个调用里面,堆栈会被破坏掉。
当然还有其他类似的这样调用父模块校验:

DEX文件保护
某某某加固系统最重要的功能应该就是为了对dex文件的保护了,因为一般得到原始的dex后,去掉加固模块就可以直接运行。相当于完整脱壳了。为了达到这个目的,某某某加固系统对dex的保护特别重要。前面的这些对模块的保护最终的目的也是为了保护dex文件。下面来看看他的保护是怎么样的。
某某某加固系统第一次会把原始包中的classes.dex用libz函数解压出来,然后系统会把他重新编译成oat文件,这个文件中的dex头被加密处理了。里面的数据部分也被加密处理。在运行的时候,加固系统直接解内存中加载的classes.oat文件,而不用再次解压原始文件了。这样带来了效率的提升。也保证了没有明文的dex存在磁盘上。
数据的解密用到了rc4算法,算法的key刚才已经说过了是从父模块的函数中获取的,保证了解密的安全性。
rc4算法部分大家可以网上找资料看看,用key生成0x100的解密盒子。然后用这个盒子去解密数据。
nt __fastcall rc4(int result, _BYTE *a2, int a3)
{
int v3; // lr
int v4; // r12
int v5; // r5
if ( a3 )
{
v3 = 0;
v4 = 0;
do
{
--a3;
v3 = (v3 + 1) % 256;
v5 = *(unsigned __int8 *)(result + v3);
v4 = (v4 + v5) % 256;
*(_BYTE *)(result + v3) = *(_BYTE *)(result + v4);
*(_BYTE *)(result + v4) = v5;
*a2++ ^= *(_BYTE *)(result + (unsigned __int8)(*(_BYTE *)(result + v3) + v5));
}
while ( a3 );
}
return result;
}
算法核心部分。
下面是跟踪的截图和注释:这个循环保证解密oat中的所有dex文件:
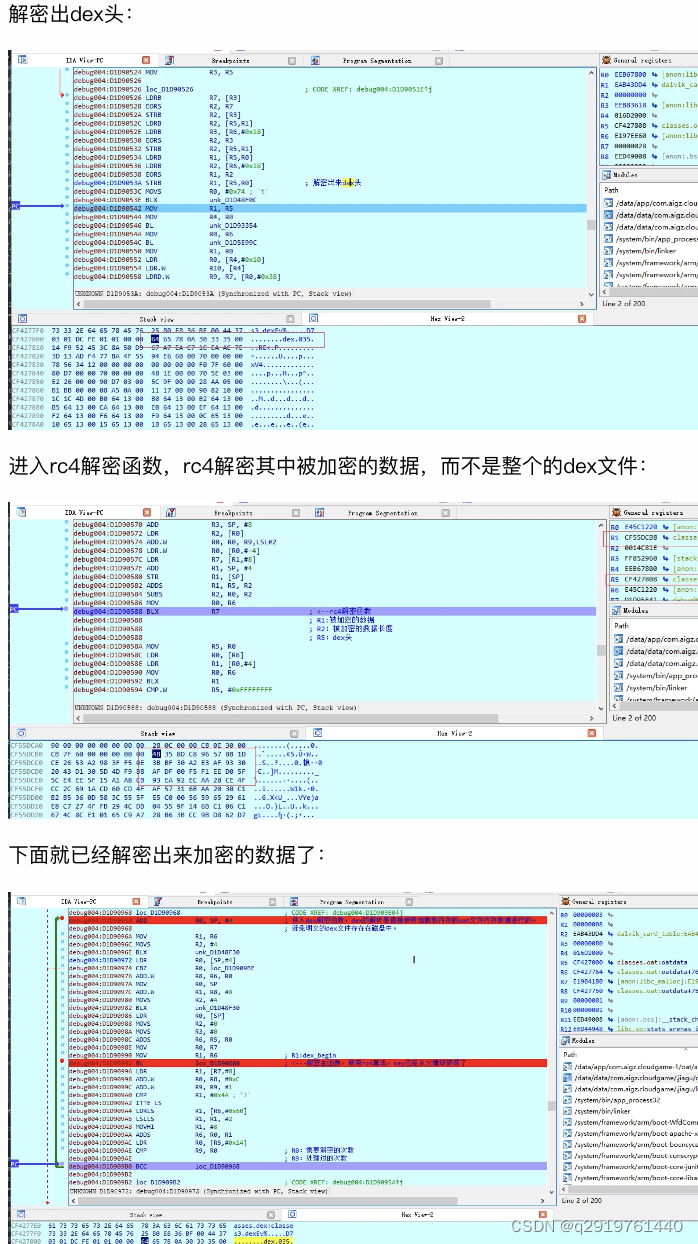
所有的oat文件中的dex都被解密出来后,需要立即保存下来,否则某某某加固系统会把dex的头再次删除,我们在这个地方先dump下来oat文件。
Dump这个已经解密的oat文件后,我们就可以把其中的dex文件都找出来:
根据oat文件结构知道,dex数据是从0x1000开始的,前面是头,后面接着就是dex文件,从我们刚才跟踪的时候知道,这个oat中有三个dex文件。向下找下看看,也可以根据刚才R5中的偏移找到开始的位置,第一个位置偏移是0x1808,这个里面的dex头保存完整: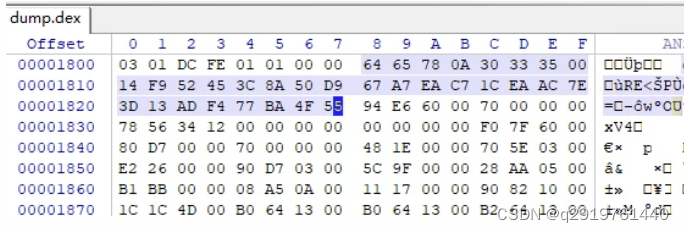
从dex结构我们知道,开始的偏移+0x20 后面的4个字节就是长度,第一个长度为:0x60E694,把这个数据保存出来,然后继续这样找其他的dex:
全部找到后我们用解析工具打开看看: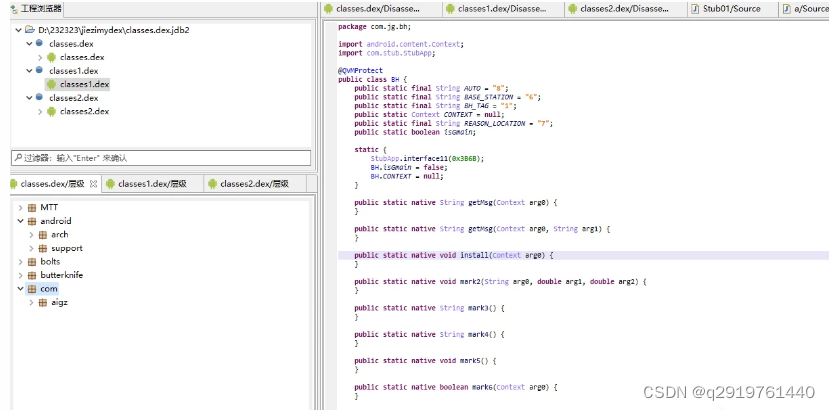
这样原始的dex就被我们抓出来了。
Dump dex原理:
某某某加固通过hook系统的LoadDexFile 在系统加载dex文件之前把修改部分的字节还原后交给系统使用。所以在这个时候获取的dex文件是正确的。
某某某的VMP保护:
某某某加固系统的核心保护就是对dex代码中的onCreate函数进行VMP保护。把原指令用自己实现的指令集替换,并在Native层实现这些指令,达到替换指令集,移除dex代码,加密指令数据等。并且在vmp的代码中还可以插入自己的检测代码。非常有特色,保护能力也非常强,下面就来仔细的研究下某某某vmp的实现原理和具体实现方法。
来看这个app的例子:
通过frida hook RegisterNatives脚本,获取加固系统注册Natives方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
并获取参数打印如下:
这个APP有两个地方被某某某加固使用VMP保护:
[RegisterNatives] java_class: com/aigz/ui/base/BBSAppStart name: onCreate sig: (Landroid/os/Bundle;)V fnPtr: 0xd32fb39c
[RegisterNatives] java_class: com/aigz/ui/base/BBSAppStart name: onCreate sig: (Landroid/os/Bundle;)V fnPtr: 0xe857c39c
来到这两个函数的地方看看:
Method表头中被定义为Native函数:
通过frida的跟踪分析,某某某加固系统还隐藏了真实的vmp处理函数地址,真正的函数是在入口函数中通过地址跳转过去的,可以通过内嵌的capstone引擎反汇编出来,得到真实的函数入口地址:
0xe857c39c : mov r8, r8
0xe857c39e : sub sp, #0xc
0xe857c3a0 : push {r7}
0xe857c3a2 : push {lr}
0xe857c3a4 : sub sp, #4
0xe857c3a6 : mov ip, r0
0xe857c3a8 : add r0, sp, #0xc
0xe857c3aa : stm r0!, {r1, r2, r3}
0xe857c3ac : add r2, sp, #0xc
0xe857c3ae : mov r0, pc
0xe857c3b0 : mov r1, ip
0xe857c3b2 : str r2, [sp]
onCreate_function_address: 0xd2858985 offset: 0x1c985
这样就定位到真实的函数偏移是0x1c985
通过比较长时间的分析,大概的了解了这个函数的参数如下:
R0:加密函数的key,这个key决定了后面的jump table的跳转,也决定了后面使用的参数的计算和资源的获取。也就是说某某某的VMP引擎是同一个,就是通过这个key识别处理不同的函数。
R1:jni_env
R2: 堆栈参数
Vmp函数的大概结构是,通过R0 key值获取需要处理的函数资源,通过函数的参数值生成后面解密的xor_key,这个key还被一个参数值保护,失去这个参数值就会出现错误。另外这个key还被inker:__dl_rtld_db_dlactivity 值处理,如果被调试,inker:__dl_rtld_db_dlactivity值不为0,这个参数也是错误的。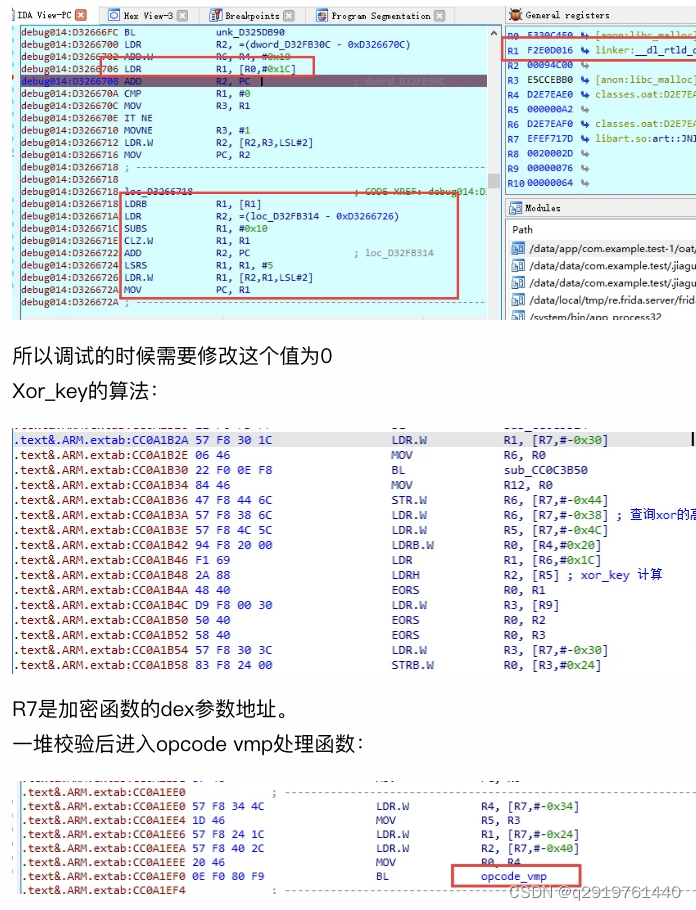
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
下面详细的解释下这个处理函数的过程:

.text&.ARM.extab:CC0B042A LDR.W R0, [R9]
.text&.ARM.extab:CC0B042E LDRB.W R1, [R9,#4]
.text&.ARM.extab:CC0B0432 SUBS R2, R0, R6
.text&.ARM.extab:CC0B0434 LDRH R0, [R0]
.text&.ARM.extab:CC0B0436 ORR.W R1, R1, R1,LSL#8
.text&.ARM.extab:CC0B043A ASRS R4, R2, #1
.text&.ARM.extab:CC0B043C EOR.W R8, R1, R0
.text&.ARM.extab:CC0B0440 MOV R0, R9
.text&.ARM.extab:CC0B0442 UXTH.W R11, R8
.text&.ARM.extab:CC0B0446 MOV R1, R11
上面这段就是整个处理的核心部分,其中R9中是参数:
本次VMP运行参数如下:
02029000: EC 9B E5 D2 95 00 00 00 00 52 C6 E5 50 3B 00 00 .........R..P;..
这个参数的的第一个dword 是被加密函数的加密数据指针,第五个字节是xor_key,被加密数据需要通过xor 这个xor_key来解密。第三个dword是第二参数指针,第二参数包含解密查询指针的低位值和查询表地址。
.text&.ARM.extab:CC0B0448 BL sub_CC0BDEFE //模拟opcode查询算法
.text&.ARM.extab:CC0B044C MOV R10, R0 //返回值就是opcode_v
.text&.ARM.extab:CC0B044E CMP R0, #0x7E ; '~' //后面就是根据这个返回值处理
实现代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
也就是说先把加密函数的两个字节取出来,然后xor xor_key 然后用解密后的前两个字节进入查询函数进行查询计算。得到查询的index,根据index获取模拟的opcode值。
查询表格每个加密函数都有一个属于自己的表:

在上面的查询过程中会使用inker:__dl_rtld_db_dlactivity 值来破坏查询值,所以必须清零。

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|
从这个运行日志中可以看到,某某某加固有两种处理,一种就是对Java class的处理,还有一种就是数值处理。
对Java class的处理日志能明确的打印出结果,根据结果基本上能知晓函数的作用。而对数值的处理比较麻烦,某某某加固的vmp是自己模拟实现的,需要跟踪调试反分析出来函数的作用。
另外opcode的长度是某某某加固vmp自己维护的。也就是根据opcode硬编码的,所以需要记录下来。
现在来总结下某某某加固vmp的处理方法:
1. 用需要加密的onCreate函数的参数+常量参数+anti参数生成的xor_key加密函数数据。
2. 每个opcode的第一个字节被某某某加固vmp的模拟opcode所替换,并被上面的xor_key加密保护。
3. 每个opcode类型自己实现功能。
4. 每个opcode长度在实现代码中自己维护。硬编码实现。
5. 每个函数生成高地位的参数加密,并和密文的opcode 计算获得查询index。
6. 每个函数都拥有一张模拟opcode_v查询表。模拟的opcode是通过这个表查询得到的。
也就是说模拟的opcode是两层加密解密出来的。并且都是自己实现具体功能的。
某某某加固VMP代码还原:
首先要想还原得有一个官方的opcode文档,推荐:
Dalvik opcodes
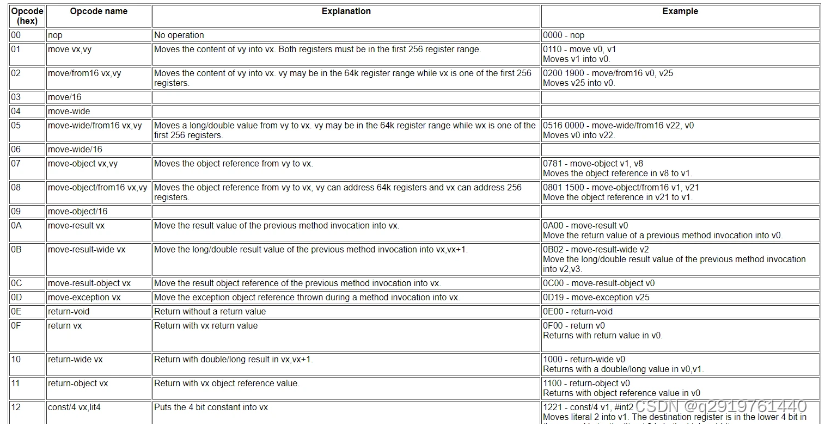
从官方的文档中大致能知道opcode类型和opcode长度定义。
从文档中我们也知道dex的代码分为opcode操作码和后面的操作数组成的。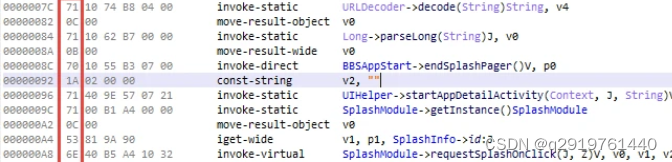
Opcode 占一个字节。后面都是操作数。
而某某某加固的VMP简单的加密了整个代码,就是用xor_key 加密,而重点的保护的就是opcode操作码,还原代码其实也就是找回opcode操作码,替换回去就行。后面的操作数通过xor_key还原出来就可以了。
下面就来重点说说怎么还原操作码的:
从上面的分析来看就是两种类型,处理Java class 的通过打印的日志基本就清楚是啥功能的。然后通过正常的代码结合官方文档大致就能还原出来。
而对数据的处理比较麻烦,因为都是某某某加固系统自己处理的,所以需要到每个处理单元里面跟踪分析。
当然最好是在AndroidNativeEm模拟器中运行,这样能方便跟踪,如果你能用ida动态跟踪也可以。
下面是一个demo加固后的跟踪结果和分析结果:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 |
|
通过上面的日志分析基本上还原出来代码。
opcode_len_dat = [3,3,3,3,3,1,2,3,1,3,1]
xor_key = 0x9595
opcode_操作码: ['0x7a', '0x12', '0x1', '0x12', '0x1', '0x21', '0xa6', '0x1', '0x21', '0x1', '0xc5']
使用的opcode种类: ['0x7a', '0x12', '0x1', '0x21', '0xa6', '0xc5'] 合计个数: 6
恢复的代码: 6f20e70d210014021c000a7f6e20513b210014027e00077f6e204f3b21000c021c0200026e10523b01000c006e20fe0b02000e00
用这个还原的代码修复dex文件就可以实现剥离某某某加固,还原原程序了。
Dex 二进制修改方法:
用IDA打开dex文件,搜索class名称,找到要修改的方法的地方:
看到Native函数定义的数据了吧。比较下正常的public函数定义,知道类型应该是0004,而不是0284,后面跟着的是code地址,修改这个数据:
直接到IDA的Hex View页中按F2修改: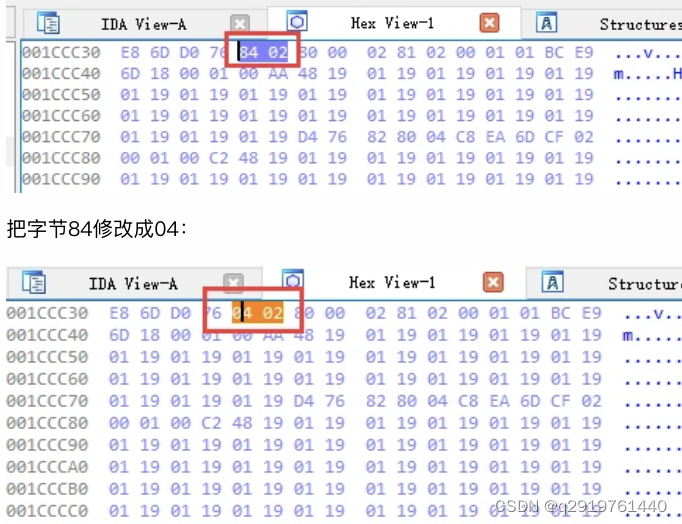
下面修改code offset,这个地址是LEB128编码,编码介绍:
https://berryjam.github.io/2019/09/LEB128(Little-Endian-Base-128)格式介绍/
Andorid系统在Dex文件采用LEB128变长编码格式,相对固定长度的编码格式,leb128编码存储利用率比较高,能让Dex文件尽可能的小。对于存储空间比较紧缺的移动设备,这非常有用。就是在字节的第七位插入1,计算地址时,去掉这个第七位的1再组合。
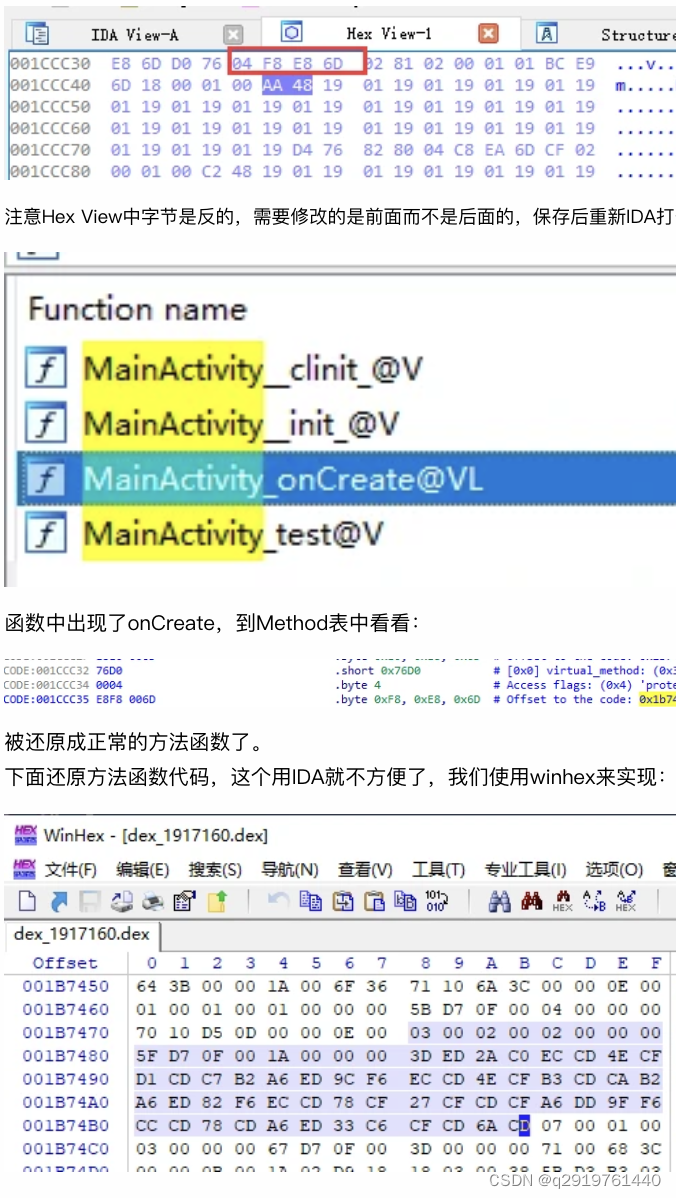 来的偏移地址:0x1b7478处,从IDA中也可以看到前面0x10是函数头参数,后面就是代码了:
来的偏移地址:0x1b7478处,从IDA中也可以看到前面0x10是函数头参数,后面就是代码了:
保存,用IDA重新打开:
除了偏移地址发生改变,基本上一样。说明还原成功。
某某某加固修正重新打包技术要点如下:
1. 首先需要使用自己编写的某某某_jiagu_info 脚本跑出oat文件的dex,dump出来oat文件后用winhex把dex头前面的数据去掉就是dex文件。
2.一般dump 多个dex文件,需要处理所有的oat文件得到所有的dex
3.一般被加固的apk的原始入口在Manifest xml中已经改变,需要找回原来的入口,这个尤其重要,这个坑踩了好久。这个入口中脚本中会打印出来,App_Application_Entry is:
4.由于Java vm并不能运行nop指令,一般也不可能出现这个指令,所以清除某某某加固的SDK时,如果不能进行code对齐,中间有nop 时Java vm会执行错误。所以建议保留SDK,但是修改SDK代码为返回原值就行。
某某某加固一般有三种SDK插入:
主onCreate函数的 stub->Mark() 这个少,一般只有一个,反编译后直接在smile中可以去掉,搜索dex中的mark就能找到地方。
onCreate 的interface11() 这个由于是在函数的开头插入,所以可以写代码清除并进行code对齐。 需要写代码修复。先用winhex通过特征码搜索所有的调用地址,然后导出这个搜索结果给下面修复脚本用就能修复好。
脚本见附件:某某某加固dex嵌入SDK修复脚本。
invoke-static/range StubApp->getOrigApplicationContext(Context)Context, v0 .. v0 这种数量巨大,一般都是在调用getcontext函数的后面,所以建议保留,请修改StubApp里面的函数代码,直接返回原值即可。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
5. 用dextools工具dump的dex存在问题,需要用自己写的某某某_info脚本跑出来的oat修复的dex才可以。
把上面修改后的classes文件和dump的所有其他dex文件一起放到apk包中,用apktool工具反编译后修改mark的地方,就是去掉就行。然后修改Manifest xml中application 选项中的android:name 为 Python 跑出来的App_Application_Entry
6. 如果存在onCreate VMP 那就复杂,需要修复vmp后才能进行上面的反编译修改再打包。vmp的修复最好是用AndroidNativeEmu 模拟器修复。修复过程在某某某加固分析文档中有。参数和数据需要自己到内存中去抓。
附录1 获取某某某加固信息脚本:
本脚本用来获取某某某加固系统关键数据,包含dump so,查询apk的原始入口,根据特征码搜索onCreate vmp处理函数等。