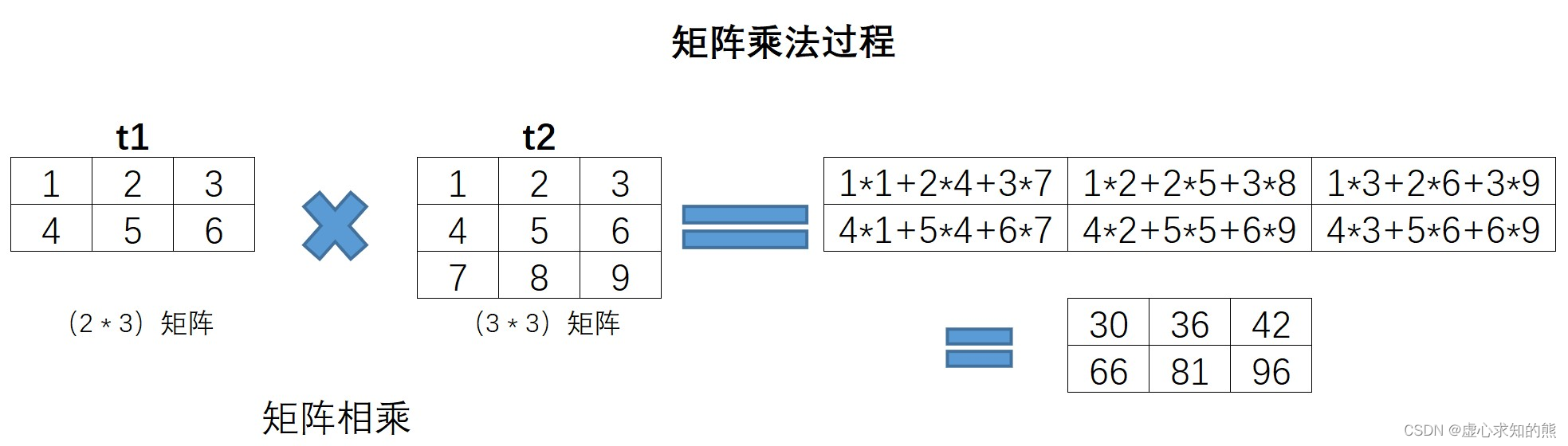
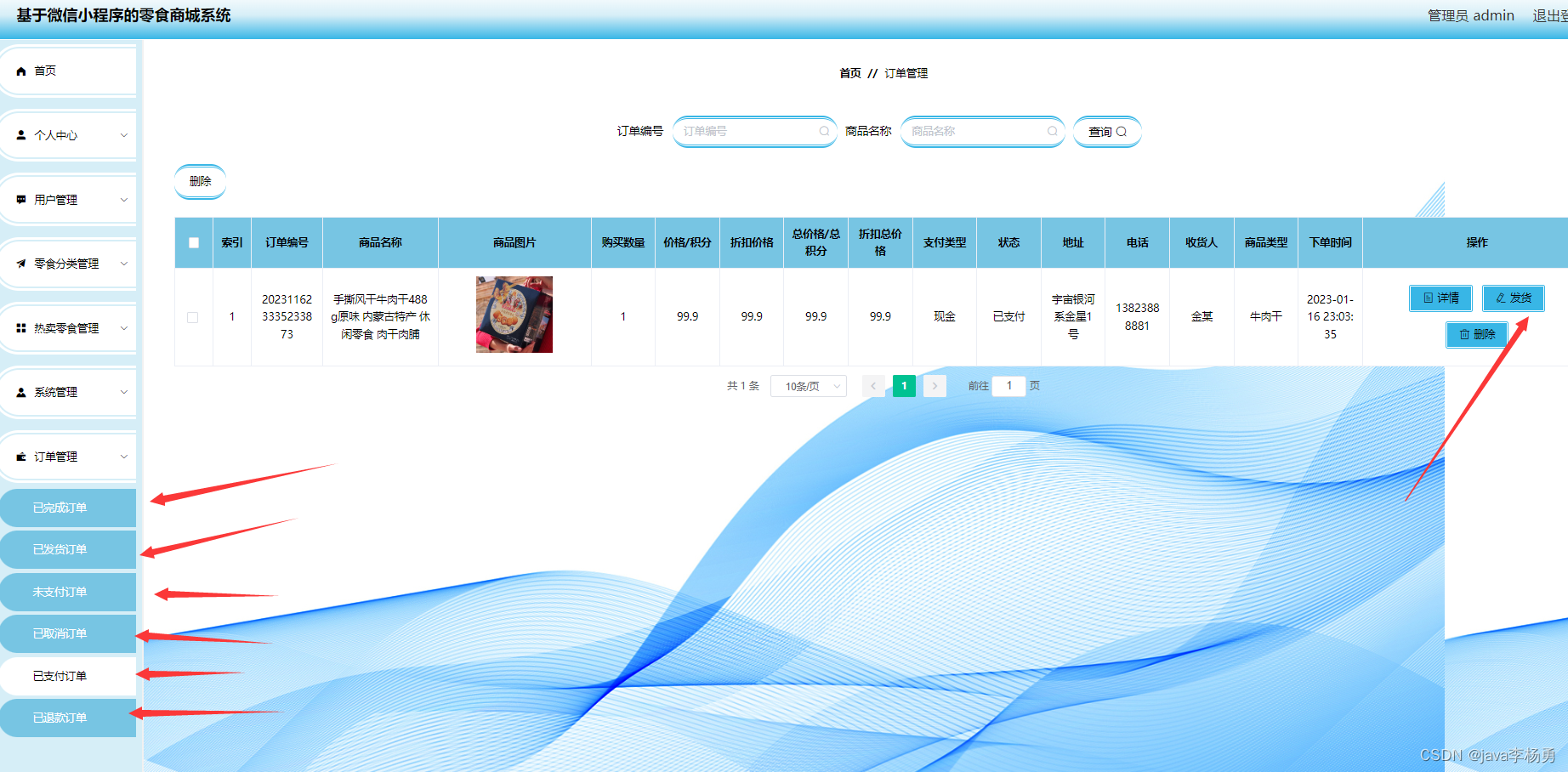
在 Lesson 1 中,我们曾经利用损失函数的偏导函数方程组进行简单线性回归模型参数的求解:
∂
S
S
E
L
o
s
s
∂
(
w
)
=
2
(
2
−
w
−
b
)
∗
(
−
1
)
+
2
(
4
−
3
w
−
b
)
∗
(
−
3
)
=
20
w
+
8
b
−
28
=
0
\begin{aligned} \frac{\partial{SSELoss}}{\partial{(w)}} &= 2(2-w-b)*(-1) + 2(4-3w-b)*(-3)\\ & = 20w+8b-28 \\ & = 0 \end{aligned}
∂(w)∂SSELoss=2(2−w−b)∗(−1)+2(4−3w−b)∗(−3)=20w+8b−28=0
∂
S
S
E
L
o
s
s
∂
(
b
)
=
2
(
2
−
w
−
b
)
∗
(
−
1
)
+
2
(
4
−
3
w
−
b
)
∗
(
−
1
)
=
8
w
+
4
b
−
12
=
0
\begin{aligned} \frac{\partial{SSELoss}}{\partial{(b)}} & = 2(2-w-b)*(-1) + 2(4-3w-b)*(-1)\\ & = 8w+4b-12 \\ & = 0 \end{aligned}
∂(b)∂SSELoss=2(2−w−b)∗(−1)+2(4−3w−b)∗(−1)=8w+4b−12=0
即
X
=
[
w
b
]
=
[
1
1
]
X = \left [\begin{array}{cccc} w \\ b \\ \end{array}\right] =\left [\begin{array}{cccc} 1 \\ 1 \\ \end{array}\right]
X=[wb]=[11]
不过,更进一步的来看,既然方程组需要改写成向量/矩阵形式,那么原始函数方程其实也同样需要改写成向量/矩阵形式。因此,原方程我们可以改写成。
f
(
x
)
=
A
T
⋅
x
f(x) = A^T \cdot x
f(x)=AT⋅x
其中。
A
=
[
2
,
1
]
T
A = [2, 1]^T
A=[2,1]T
x
=
[
x
1
,
x
2
]
T
x = [x_1, x_2]^T
x=[x1,x2]T
原方程为。
y
=
2
x
1
+
x
2
y = 2x_1+x_2
y=2x1+x2
结合函数求导结果,我们不难发现,
∂
f
(
x
)
∂
x
\frac{\partial f(x)}{\partial x}
∂x∂f(x)最终计算结果就是
A
A
A。
∂
f
(
x
)
∂
x
=
∂
(
A
T
⋅
x
)
∂
x
=
A
\frac{\partial f(x)}{\partial x} = \frac{\partial(A^T \cdot x)}{\partial x} = A
∂x∂f(x)=∂x∂(AT⋅x)=A
设
f
(
x
)
f(x)
f(x) 是一个关于
x
x
x 的函数,其中
x
x
x 是向量变元,并且
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2,...,x_n]^T
x=[x1,x2,...,xn]T
则
∂
f
∂
x
=
[
∂
f
∂
x
1
,
∂
f
∂
x
2
,
.
.
.
,
∂
f
∂
x
n
]
T
\frac{\partial f}{\partial x} = [\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}]^T
∂x∂f=[∂x1∂f,∂x2∂f,...,∂xn∂f]T
而该表达式也被称为向量求导的梯度向量形式。
∇
x
f
(
x
)
=
∂
f
∂
x
=
[
∂
f
∂
x
1
,
∂
f
∂
x
2
,
.
.
.
,
∂
f
∂
x
n
]
T
\nabla _xf(x) = \frac{\partial f}{\partial x} = [\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}]^T
∇xf(x)=∂x∂f=[∂x1∂f,∂x2∂f,...,∂xn∂f]T
通过求得函数的梯度向量求解向量导数的方法,也被称为定义法求解。
值得注意的是,多元函数是一定能够求得梯度向量的,但梯度向量或者说向量求导结果,能否由一些已经定义的向量解决表示,如
A
A
A 就是
f
(
x
)
f(x)
f(x) 的向量求导结果,则不一定。
同样,此处我们假设 x 为包含 n 各变量的列向量,
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2,...,x_n]^T
x=[x1,x2,...,xn]T。
(1)
∂
a
∂
x
=
0
\frac{\partial a}{\partial x} = 0
∂x∂a=0证明:
∂
a
∂
x
=
[
∂
a
∂
x
1
,
∂
a
∂
x
2
,
.
.
.
,
∂
a
∂
x
n
]
T
=
[
0
,
0
,
.
.
.
,
0
]
T
\frac{\partial a}{\partial x} = [\frac{\partial a}{\partial x_1}, \frac{\partial a}{\partial x_2}, ..., \frac{\partial a}{\partial x_n}]^T = [0,0,...,0]^T
∂x∂a=[∂x1∂a,∂x2∂a,...,∂xn∂a]T=[0,0,...,0]T
(2)
∂
(
x
T
⋅
A
)
∂
x
=
∂
(
A
T
⋅
x
)
∂
x
=
A
\frac{\partial(x^T \cdot A)}{\partial x} = \frac{\partial(A^T \cdot x)}{\partial x} = A
∂x∂(xT⋅A)=∂x∂(AT⋅x)=A
证明,此时 A 为拥有 n 个分量的常数向量,设
A
=
[
a
1
,
a
2
,
.
.
.
,
a
n
]
T
A = [a_1, a_2,...,a_n]^T
A=[a1,a2,...,an]T,则有
∂
(
x
T
⋅
A
)
∂
x
=
∂
(
A
T
⋅
x
)
∂
x
=
∂
(
a
1
⋅
x
1
+
a
2
⋅
x
2
+
.
.
.
+
a
n
⋅
x
n
)
∂
x
=
[
∂
(
a
1
⋅
x
1
+
a
2
⋅
x
2
+
.
.
.
+
a
n
⋅
x
n
)
∂
x
1
∂
(
a
1
⋅
x
1
+
a
2
⋅
x
2
+
.
.
.
+
a
n
⋅
x
n
)
∂
x
2
.
.
.
∂
(
a
1
⋅
x
1
+
a
2
⋅
x
2
+
.
.
.
+
a
n
⋅
x
n
)
∂
x
n
]
=
[
a
1
a
2
.
.
.
a
n
]
=
A
\begin{aligned} \frac{\partial(x^T \cdot A)}{\partial x} & = \frac{\partial(A^T \cdot x)}{\partial x}\\ & = \frac{\partial(a_1 \cdot x_1 + a_2 \cdot x_2 +...+ a_n \cdot x_n)}{\partial x}\\ & = \left [\begin{array}{cccc} \frac{\partial(a_1 \cdot x_1 + a_2 \cdot x_2 +...+ a_n \cdot x_n)}{\partial x_1} \\ \frac{\partial(a_1 \cdot x_1 + a_2 \cdot x_2 +...+ a_n \cdot x_n)}{\partial x_2} \\ . \\ . \\ . \\ \frac{\partial(a_1 \cdot x_1 + a_2 \cdot x_2 +...+ a_n \cdot x_n)}{\partial x_n} \\ \end{array}\right] \\ & =\left [\begin{array}{cccc} a_1 \\ a_2 \\ . \\ . \\ . \\ a_n \\ \end{array}\right] = A \end{aligned}
∂x∂(xT⋅A)=∂x∂(AT⋅x)=∂x∂(a1⋅x1+a2⋅x2+...+an⋅xn)=∂x1∂(a1⋅x1+a2⋅x2+...+an⋅xn)∂x2∂(a1⋅x1+a2⋅x2+...+an⋅xn)...∂xn∂(a1⋅x1+a2⋅x2+...+an⋅xn)=a1a2...an=A
(3)
∂
(
x
T
⋅
x
)
∂
x
=
2
x
\frac{\partial (x^T \cdot x)}{\partial x} = 2x
∂x∂(xT⋅x)=2x
证明:
∂
(
x
T
⋅
x
)
∂
x
=
∂
(
x
1
2
+
x
2
2
+
.
.
.
+
x
n
2
)
∂
x
=
[
∂
(
x
1
2
+
x
2
2
+
.
.
.
+
x
n
2
)
∂
x
1
∂
(
x
1
2
+
x
2
2
+
.
.
.
+
x
n
2
)
∂
x
2
.
.
.
∂
(
x
1
2
+
x
2
2
+
.
.
.
+
x
n
2
)
∂
x
n
]
=
[
2
x
1
2
x
2
.
.
.
2
x
n
]
=
2
x
\begin{aligned} \frac{\partial(x^T \cdot x)}{\partial x} & = \frac{\partial(x_1^2+x_2^2+...+x_n^2)}{\partial x}\\ & = \left [\begin{array}{cccc} \frac{\partial(x_1^2+x_2^2+...+x_n^2)}{\partial x_1} \\ \frac{\partial(x_1^2+x_2^2+...+x_n^2)}{\partial x_2} \\ . \\ . \\ . \\ \frac{\partial(x_1^2+x_2^2+...+x_n^2)}{\partial x_n} \\ \end{array}\right] \\ & =\left [\begin{array}{cccc} 2x_1 \\ 2x_2 \\ . \\ . \\ . \\ 2x_n \\ \end{array}\right] = 2x \end{aligned}
∂x∂(xT⋅x)=∂x∂(x12+x22+...+xn2)=∂x1∂(x12+x22+...+xn2)∂x2∂(x12+x22+...+xn2)...∂xn∂(x12+x22+...+xn2)=2x12x2...2xn=2x
此处
x
T
x
x^Tx
xTx 也被称为向量的交叉乘积(crossprod)。
(4)
∂
(
x
T
A
x
)
x
=
A
x
+
A
T
x
\frac{\partial (x^T A x)}{x} = Ax + A^Tx
x∂(xTAx)=Ax+ATx
其中 A 是一个(n*n)的矩阵,
A
n
∗
n
=
(
a
i
j
)
a
=
1
,
j
=
1
n
,
n
A_{n*n}=(a_{ij})_{a=1,j=1}^{n,n}
An∗n=(aij)a=1,j=1n,n
证明:
首先,
X
T
A
X
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
⋅
[
a
11
a
12
.
.
.
a
1
n
a
21
a
22
.
.
.
a
2
n
.
.
.
.
.
.
.
.
.
.
.
.
a
n
1
a
n
2
.
.
.
a
n
n
]
⋅
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
=
[
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
,
x
1
a
12
+
x
2
a
22
+
.
.
.
+
x
n
a
n
2
,
.
.
.
,
x
1
a
1
n
+
x
2
a
2
n
+
.
.
.
+
x
n
a
n
n
]
⋅
[
x
1
x
2
.
.
.
x
n
]
=
x
1
(
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
)
+
x
2
(
x
1
a
12
+
x
2
a
22
+
.
.
.
+
x
n
a
n
2
)
+
.
.
.
+
x
n
(
x
1
a
1
n
+
x
2
a
2
n
+
.
.
.
+
x
n
a
n
n
)
\begin{aligned} X^TAX &= [x_1, x_2,...,x_n] \cdot \left [\begin{array}{cccc} a_{11} &a_{12} &... &a_{1n}\\ a_{21} &a_{22} &... &a_{2n}\\ ... &... &... &... \\ a_{n1} &a_{n2} &... &a_{nn}\\ \end{array}\right] \cdot [x_1, x_2,...,x_n]^T \\ &=[x_1a_{11}+x_2a_{21}+...+x_na_{n1}, x_1a_{12}+x_2a_{22}+...+x_na_{n2},...,x_1a_{1n}+x_2a_{2n}+...+x_na_{nn}] \cdot \left [\begin{array}{cccc} x_1 \\ x_2 \\ . \\ . \\ . \\ x_n \\ \end{array}\right] \\ &=x_1(x_1a_{11}+x_2a_{21}+...+x_na_{n1})+x_2(x_1a_{12}+x_2a_{22}+...+x_na_{n2})+...+x_n(x_1a_{1n}+x_2a_{2n}+...+x_na_{nn}) \end{aligned}
XTAX=[x1,x2,...,xn]⋅a11a21...an1a12a22...an2............a1na2n...ann⋅[x1,x2,...,xn]T=[x1a11+x2a21+...+xnan1,x1a12+x2a22+...+xnan2,...,x1a1n+x2a2n+...+xnann]⋅x1x2...xn=x1(x1a11+x2a21+...+xnan1)+x2(x1a12+x2a22+...+xnan2)+...+xn(x1a1n+x2a2n+...+xnann)
令
k
(
x
)
=
x
1
(
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
)
+
x
2
(
x
1
a
12
+
x
2
a
22
+
.
.
.
+
x
n
a
n
2
)
+
.
.
.
+
x
n
(
x
1
a
1
n
+
x
2
a
2
n
+
.
.
.
+
x
n
a
n
n
)
k(x) = x_1(x_1a_{11}+x_2a_{21}+...+x_na_{n1})+x_2(x_1a_{12}+x_2a_{22}+...+x_na_{n2})+...+x_n(x_1a_{1n}+x_2a_{2n}+...+x_na_{nn})
k(x)=x1(x1a11+x2a21+...+xnan1)+x2(x1a12+x2a22+...+xnan2)+...+xn(x1a1n+x2a2n+...+xnann)
则有
∂
k
(
x
)
∂
x
1
=
(
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
)
+
(
x
1
a
11
+
x
2
a
12
+
.
.
.
+
x
n
a
1
n
)
\frac{\partial k(x)}{\partial x_1} = (x_1a_{11}+x_2a_{21}+...+x_na_{n1})+ (x_1a_{11} + x_2a_{12}+...+x_na_{1n})
∂x1∂k(x)=(x1a11+x2a21+...+xnan1)+(x1a11+x2a12+...+xna1n)
类似可得:
∂
k
(
x
)
∂
x
=
[
∂
k
(
x
)
∂
x
1
∂
k
(
x
)
∂
x
2
.
.
.
∂
k
(
x
)
∂
x
n
]
=
[
(
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
)
+
(
x
1
a
11
+
x
2
a
12
+
.
.
.
+
x
n
a
1
n
)
(
x
1
a
12
+
x
2
a
22
+
.
.
.
+
x
n
a
n
2
)
+
(
x
1
a
21
+
x
2
a
22
+
.
.
.
+
x
n
a
2
n
)
.
.
.
(
x
1
a
1
n
+
x
2
a
2
n
+
.
.
.
+
x
n
a
n
n
)
+
(
x
1
a
n
1
+
x
2
a
n
2
+
.
.
.
+
x
n
a
n
n
)
]
=
[
(
x
1
a
11
+
x
2
a
21
+
.
.
.
+
x
n
a
n
1
)
(
x
1
a
12
+
x
2
a
22
+
.
.
.
+
x
n
a
n
2
)
.
.
.
(
x
1
a
1
n
+
x
2
a
2
n
+
.
.
.
+
x
n
a
n
n
)
]
+
[
(
x
1
a
11
+
x
2
a
12
+
.
.
.
+
x
n
a
1
n
)
(
x
1
a
21
+
x
2
a
22
+
.
.
.
+
x
n
a
2
n
)
.
.
.
(
x
1
a
n
1
+
x
2
a
n
2
+
.
.
.
+
x
n
a
n
n
)
]
=
[
a
11
a
21
.
.
.
a
n
1
a
12
a
22
.
.
.
a
n
2
.
.
.
.
.
.
.
.
.
.
.
.
a
1
n
a
2
n
.
.
.
a
n
n
]
[
x
1
x
2
.
.
.
x
n
]
+
[
a
11
a
12
.
.
.
a
1
n
a
21
a
22
.
.
.
a
2
n
.
.
.
.
.
.
.
.
.
.
.
.
a
n
1
a
n
2
.
.
.
a
n
n
]
[
x
1
x
2
.
.
.
x
n
]
=
A
T
x
+
A
x
\begin{aligned} \frac{\partial k(x)}{\partial x} &= \left [\begin{array}{cccc} \frac{\partial k(x)}{\partial x_1} \\ \frac{\partial k(x)}{\partial x_2} \\ . \\ . \\ . \\ \frac{\partial k(x)}{\partial x_n} \\ \end{array}\right] \\ &=\left [\begin{array}{cccc} (x_1a_{11}+x_2a_{21}+...+x_na_{n1})+ (x_1a_{11} + x_2a_{12}+...+x_na_{1n}) \\ (x_1a_{12}+x_2a_{22}+...+x_na_{n2})+ (x_1a_{21} + x_2a_{22}+...+x_na_{2n}) \\ . \\ . \\ . \\ (x_1a_{1n}+x_2a_{2n}+...+x_na_{nn})+ (x_1a_{n1} + x_2a_{n2}+...+x_na_{nn}) \\ \end{array}\right] \\ &=\left [\begin{array}{cccc} (x_1a_{11}+x_2a_{21}+...+x_na_{n1}) \\ (x_1a_{12}+x_2a_{22}+...+x_na_{n2}) \\ . \\ . \\ . \\ (x_1a_{1n}+x_2a_{2n}+...+x_na_{nn}) \\ \end{array}\right] + \left [\begin{array}{cccc} (x_1a_{11}+x_2a_{12}+...+x_na_{1n}) \\ (x_1a_{21}+x_2a_{22}+...+x_na_{2n}) \\ . \\ . \\ . \\ (x_1a_{n1}+x_2a_{n2}+...+x_na_{nn}) \\ \end{array}\right] \\ &=\left [\begin{array}{cccc} a_{11} &a_{21} &... &a_{n1}\\ a_{12} &a_{22} &... &a_{n2}\\ ... &... &... &... \\ a_{1n} &a_{2n} &... &a_{nn}\\ \end{array}\right] \left [\begin{array}{cccc} x_1 \\ x_2 \\ . \\ . \\ . \\ x_n \\ \end{array}\right] +\left [\begin{array}{cccc} a_{11} &a_{12} &... &a_{1n}\\ a_{21} &a_{22} &... &a_{2n}\\ ... &... &... &... \\ a_{n1} &a_{n2} &... &a_{nn}\\ \end{array}\right] \left [\begin{array}{cccc} x_1 \\ x_2 \\ . \\ . \\ . \\ x_n \\ \end{array}\right]\\ &=A^Tx+Ax \end{aligned}
∂x∂k(x)=∂x1∂k(x)∂x2∂k(x)...∂xn∂k(x)=(x1a11+x2a21+...+xnan1)+(x1a11+x2a12+...+xna1n)(x1a12+x2a22+...+xnan2)+(x1a21+x2a22+...+xna2n)...(x1a1n+x2a2n+...+xnann)+(x1an1+x2an2+...+xnann)=(x1a11+x2a21+...+xnan1)(x1a12+x2a22+...+xnan2)...(x1a1n+x2a2n+...+xnann)+(x1a11+x2a12+...+xna1n)(x1a21+x2a22+...+xna2n)...(x1an1+x2an2+...+xnann)=a11a12...a1na21a22...a2n............an1an2...annx1x2...xn+a11a21...an1a12a22...an2............a1na2n...annx1x2...xn=ATx+Ax
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x) = w_1x_1+w_2x_2+...+w_dx_d+b
f(x)=w1x1+w2x2+...+wdxd+b
令
w
=
[
w
1
,
w
2
,
.
.
.
w
d
]
T
w = [w_1,w_2,...w_d]^T
w=[w1,w2,...wd]T,
x
=
[
x
1
,
x
2
,
.
.
.
x
d
]
T
x = [x_1,x_2,...x_d]^T
x=[x1,x2,...xd]T,则上式可写为
并且,假设现在总共有m条观测值,
x
(
i
)
=
[
x
1
(
i
)
,
x
2
(
i
)
,
.
.
.
,
x
d
(
i
)
]
x^{(i)} = [x_1^{(i)}, x_2^{(i)},...,x_d^{(i)}]
x(i)=[x1(i),x2(i),...,xd(i)],则带入模型可构成 m 个方程:
[
w
1
x
1
(
1
)
+
w
2
x
2
(
1
)
+
.
.
.
+
w
d
x
d
(
1
)
+
b
w
1
x
1
(
2
)
+
w
2
x
2
(
2
)
+
.
.
.
+
w
d
x
d
(
2
)
+
b
.
.
.
w
1
x
1
(
m
)
+
w
2
x
2
(
m
)
+
.
.
.
+
w
d
x
d
(
m
)
+
b
]
=
[
y
^
1
y
^
2
.
.
.
y
^
m
]
\left [\begin{array}{cccc} w_1x_1^{(1)}+w_2x_2^{(1)}+...+w_dx_d^{(1)}+b \\ w_1x_1^{(2)}+w_2x_2^{(2)}+...+w_dx_d^{(2)}+b \\ . \\ . \\ . \\ w_1x_1^{(m)}+w_2x_2^{(m)}+...+w_dx_d^{(m)}+b \\ \end{array}\right] = \left [\begin{array}{cccc} \hat y_1 \\ \hat y_2 \\ . \\ . \\ . \\ \hat y_m \\ \end{array}\right]
w1x1(1)+w2x2(1)+...+wdxd(1)+bw1x1(2)+w2x2(2)+...+wdxd(2)+b...w1x1(m)+w2x2(m)+...+wdxd(m)+b=y^1y^2...y^m
然后考虑如何将上述方程组进行改写,我们可令
w
^
=
[
w
1
,
w
2
,
.
.
.
,
w
d
,
b
]
T
\hat w = [w_1,w_2,...,w_d,b]^T
w^=[w1,w2,...,wd,b]T
x
^
=
[
x
1
,
x
2
,
.
.
.
,
x
d
,
1
]
T
\hat x = [x_1,x_2,...,x_d,1]^T
x^=[x1,x2,...,xd,1]T
X
^
=
[
x
1
(
1
)
x
2
(
1
)
.
.
.
x
d
(
1
)
1
x
1
(
2
)
x
2
(
2
)
.
.
.
x
d
(
2
)
1
.
.
.
.
.
.
.
.
.
.
.
.
1
x
1
(
m
)
x
2
(
m
)
.
.
.
x
d
(
m
)
1
]
\hat X = \left [\begin{array}{cccc} x_1^{(1)} &x_2^{(1)} &... &x_d^{(1)} &1 \\ x_1^{(2)} &x_2^{(2)} &... &x_d^{(2)} &1 \\ ... &... &... &... &1 \\ x_1^{(m)} &x_2^{(m)} &... &x_d^{(m)} &1 \\ \end{array}\right]
X^=x1(1)x1(2)...x1(m)x2(1)x2(2)...x2(m)............xd(1)xd(2)...xd(m)1111
y
=
[
y
1
y
2
.
.
.
y
m
]
y = \left [\begin{array}{cccc} y_1 \\ y_2 \\ . \\ . \\ . \\ y_m \\ \end{array}\right]
y=y1y2...ym
y
^
=
[
y
^
1
y
^
2
.
.
.
y
^
m
]
\hat y = \left [\begin{array}{cccc} \hat y_1 \\ \hat y_2 \\ . \\ . \\ . \\ \hat y_m \\ \end{array}\right]
y^=y^1y^2...y^m
其中
w
^
\hat w
w^:方程系数所组成的向量,并且我们将自变量系数和截距放到了一个向量;
x
^
\hat x
x^:方程自变量和1共同组成的向量;
X
^
\hat X
X^:样本数据特征构成的矩阵,并在最后一列添加一个全为1的列;
y
y
y:样本数据标签所构成的列向量;
y
^
\hat y
y^:预测值的列向量。
因此,上述方程组可表示为
X
^
⋅
w
^
=
y
^
\hat X \cdot \hat w = \hat y
X^⋅w^=y^
在改写了
x
^
\hat x
x^ 和
w
^
\hat w
w^ 之后,线性模型也可以按照如下形式进行改写:
f
(
x
^
)
=
w
^
T
⋅
x
^
f(\hat x) = \hat w^T \cdot \hat x
f(x^)=w^T⋅x^
2. 构造损失函数
在方程组的矩阵表示基础上,我们可以以 SSE 作为损失函数基本计算流程构建关于
w
^
\hat w
w^ 的损失函数:
S
S
E
L
o
s
s
(
w
^
)
=
∣
∣
y
−
X
w
^
∣
∣
2
2
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
SSELoss(\hat w) = ||y - X\hat w||_2^2 = (y - X\hat w)^T(y - X\hat w)
SSELoss(w^)=∣∣y−Xw^∣∣22=(y−Xw^)T(y−Xw^)
需要补充两点基础知识:
向量的 2- 范数计算公式 上式中,
∣
∣
y
−
X
w
^
T
∣
∣
2
||y - X\hat w^T||_2
∣∣y−Xw^T∣∣2为向量的 2- 范数的计算表达式。向量的 2- 范数计算过程为各分量求平方和再进行开平方。例如
a
=
[
1
,
−
1
,
]
a=[1, -1,]
a=[1,−1,],则
∣
∣
a
∣
∣
2
=
1
2
+
(
−
1
)
2
=
2
||a||_2= \sqrt{1^2+(-1)^2}=\sqrt{2}
∣∣a∣∣2=12+(−1)2=2。
在此之前,需要补充两点矩阵转置的运算规则:
(
A
−
B
)
T
=
A
T
−
B
T
(A-B)^T=A^T-B^T
(A−B)T=AT−BT
(
A
B
)
T
=
B
T
A
T
(AB)^T=B^TA^T
(AB)T=BTAT
接下来,对
S
S
E
L
o
s
s
(
w
)
SSELoss(w)
SSELoss(w) 求导并令其等于 0。
S
S
E
L
o
s
s
(
w
^
)
∂
w
^
=
∂
∣
∣
y
−
X
w
^
∣
∣
2
2
∂
w
^
=
∂
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
∂
w
^
=
∂
(
y
T
−
w
^
T
X
T
)
(
y
−
X
w
^
)
∂
w
^
=
∂
(
y
T
y
−
w
^
T
X
T
y
−
y
T
X
w
^
+
w
^
T
X
T
X
w
^
)
∂
w
^
=
0
−
X
T
y
−
X
T
y
+
X
T
X
w
^
+
(
X
T
X
)
T
w
^
=
0
−
X
T
y
−
X
T
y
+
2
X
T
X
w
^
=
2
(
X
T
X
w
^
−
X
T
y
)
=
0
\begin{aligned} \frac{SSELoss(\hat w)}{\partial{\boldsymbol{\hat w}}} &= \frac{\partial{||\boldsymbol{y} - \boldsymbol{X\hat w}||_2}^2}{\partial{\boldsymbol{\hat w}}} \\ &= \frac{\partial(\boldsymbol{y} - \boldsymbol{X\hat w})^T(\boldsymbol{y} - \boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}} \\ & =\frac{\partial(\boldsymbol{y}^T - \boldsymbol{\hat w^T X^T})(\boldsymbol{y} - \boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}}\\ &=\frac{\partial(\boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{\hat w^T X^Ty}-\boldsymbol{y}^T\boldsymbol{X \hat w} +\boldsymbol{\hat w^TX^T}\boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}}\\ & = 0 - \boldsymbol{X^Ty} - \boldsymbol{X^Ty}+X^TX\hat w+(X^TX)^T\hat w \\ &= 0 - \boldsymbol{X^Ty} - \boldsymbol{X^Ty} + 2\boldsymbol{X^TX\hat w}\\ &= 2(\boldsymbol{X^TX\hat w} - \boldsymbol{X^Ty}) = 0 \end{aligned}
∂w^SSELoss(w^)=∂w^∂∣∣y−Xw^∣∣22=∂w^∂(y−Xw^)T(y−Xw^)=∂w^∂(yT−w^TXT)(y−Xw^)=∂w^∂(yTy−w^TXTy−yTXw^+w^TXTXw^)=0−XTy−XTy+XTXw^+(XTX)Tw^=0−XTy−XTy+2XTXw^=2(XTXw^−XTy)=0
即
X
T
X
w
^
=
X
T
y
X^TX\hat w = X^Ty
XTXw^=XTy
要使得此式有解,等价于
X
T
X
X^TX
XTX(也被称为矩阵的交叉乘积 crossprod 存在逆矩阵,若存在,则可解出
w
^
=
(
X
T
X
)
−
1
X
T
y
\hat w = (X^TX)^{-1}X^Ty
w^=(XTX)−1XTy
标签数组:
y
=
[
2
4
]
y = \left [\begin{array}{cccc} 2 \\ 4 \\ \end{array}\right]
y=[24]
参数向量:
w
^
=
[
w
b
]
\hat w = \left [\begin{array}{cccc} w \\ b \\ \end{array}\right]
w^=[wb]
求解公式为:
w
^
=
(
X
T
X
)
−
1
X
T
y
=
(
[
1
1
3
1
]
T
[
1
1
3
1
]
)
−
1
[
1
1
3
1
]
T
[
2
4
]
\begin{aligned} \hat w &= (X^TX)^{-1}X^Ty \\ &= (\left [\begin{array}{cccc} 1 &1 \\ 3 &1 \\ \end{array}\right]^{T} \left [\begin{array}{cccc} 1 &1 \\ 3 &1 \\ \end{array}\right])^{-1} \left [\begin{array}{cccc} 1 &1 \\ 3 &1 \\ \end{array}\right]^{T} \left [\begin{array}{cccc} 2 \\ 4 \\ \end{array}\right] \\ \end{aligned}
w^=(XTX)−1XTy=([1311]T[1311])−1[1311]T[24]
代码实现过程:
X = np.array([[1,1],[3,1]])
X
#array([[1, 1],# [3, 1]])
y = np.array([2,4]).reshape(2,1)
y
#array([[2],# [4]])
np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)#array([[1.],# [1.]])
即解得
w
=
1
,
b
=
1
w=1,b=1
w=1,b=1,即模型方程为
y
=
x
+
1
y=x+1
y=x+1。至此,我们即完成了最小二乘法的推导以及简单实现。
1.Set集合
1.1Set集合概述和特点【应用】
不可以存储重复元素没有索引,不能使用普通for循环遍历
1.2Set集合的使用【应用】
存储字符串并遍历
public class MySet1 {public static void main(String[] args) {//创建集合对象Set<String> set new TreeSet<>()…
名字:阿玥的小东东 学习:python、正在学习c 主页:阿玥的小东东 目录
判断字符串 a “welcome to my world” 是否包含单词 b “world”,包含返回 True,不包含返回 False。 从 0 开始计数,输出指定字符串…
一、Bean的概念
由 Spring IoC 容器负责创建、管理所有的Java对象,这些管理的对象称为 Bean,Bean 根据 Spring 配置文件中的信息创建。
二、基于XML方式管理bean对象
eg:
<?xml version"1.0" encoding"UTF-8"?&…
大家好,才是真的好。
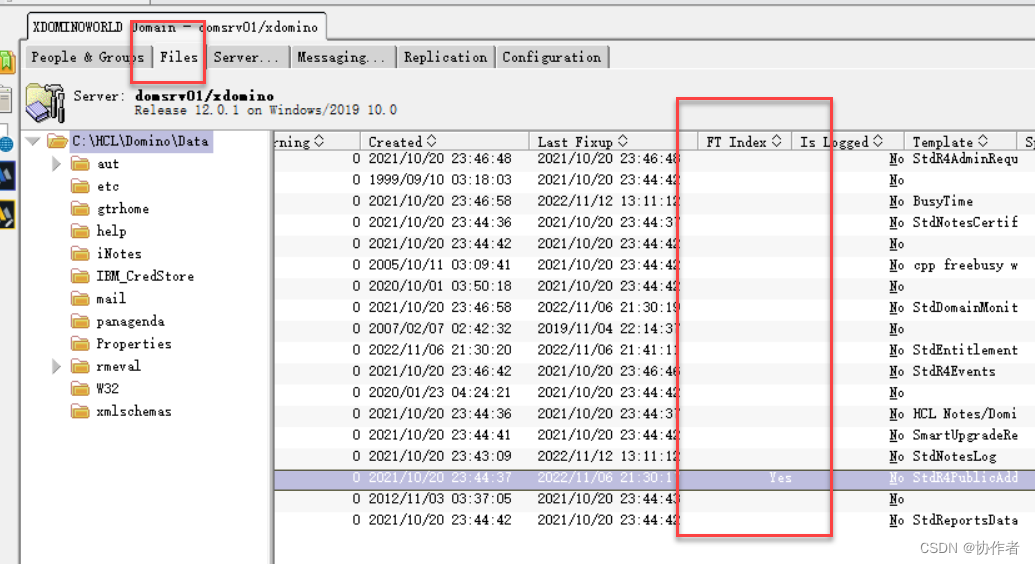
今天我们讨论Domino运维管理问题:哪些数据库开启了全文索引?
在前面的某些篇章中,我们介绍过什么是Notes应用的全文索引Full Text Index,以下简称FTI。它是Notes库中的单词的文本索引或列表&…