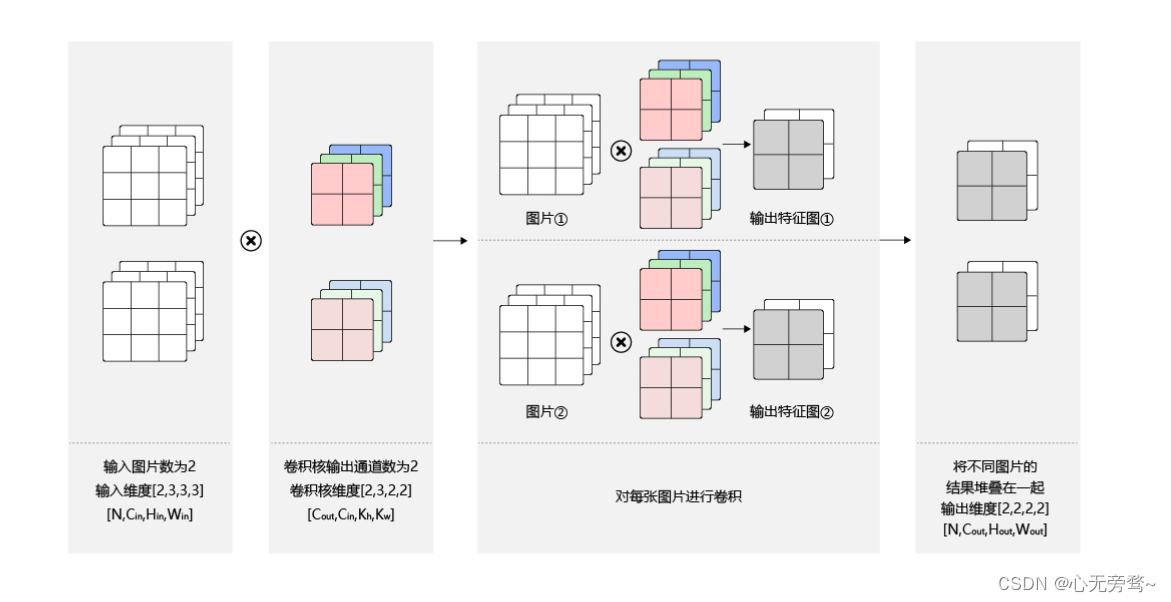
背景
在做客户数据导入任务的时候,需要将客户oracle的数据通过datax导入到 starrocks的表中,但是datax的配置文件中SQL查找客户数据的列数和要导入的starrocks表的列数都是相同且对应的,但是导入结果就是报了列数不对等的错误,Error: Value count does not match column count. Expect 20, but got 21. Row
如图所示:

解决思路:
对于这类问题,由于查找的列的数量很多,我们并不知道客户那边是哪个字段里面有个什么字符,导致本来是一列的结果被datax误判为两列
首先复制一份datax配置文件,执行如下命令(配置文件名字不一定相同):cp abc.json abc_test.json
然后修改 abc_test.json 配置文件中的writer,将写到 storrocks表的数据改为输出到控制台中,如图所示:

修改完成以后,开始从客户那边数据查询出来,并将数据导入到一个临时文件test.log中,执行如下命令:python datax.py abc_test.json >test.log 2>&1
之后编辑 test.log文件,执行如下命令:vim test.log,将test.log文件中的开头和结尾非数据部分给删掉
剩下的test.log中全是同步过来的数据部分,然后将每一行列数同步到另外一个临时文件test2.log中,执行如下命令:awk -F '\t' '{print NF}' >test2.log
此时我们再次编辑test2.log,找到不是正常列数对应的行,记录这是第几行
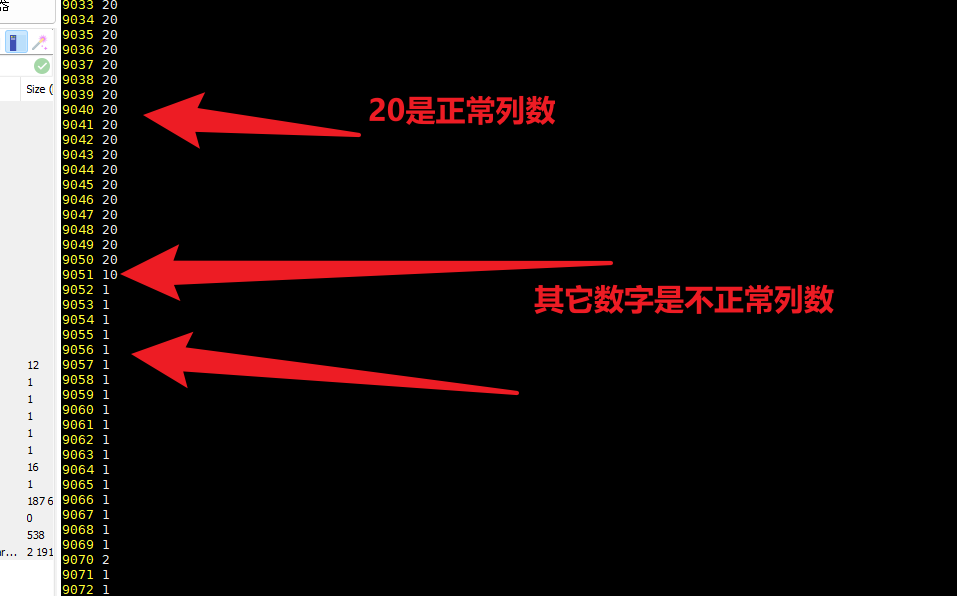
然后在test.log中找到不正常列数的行,查看对应的数据,究竟是那一字段中有特殊字符,例如在客户中发现是字符中同时有 \t 和 \n导致列数不对。
在datax的abc_test.json配置文件中,将查找的SQL,使用替换的方式,将\t和\n分别替换为空格,如图所示:

之后再次测试一遍,执行如下命令:python datax.py abc_test.json >test.log 2>&1
之后编辑 test.log文件,执行如下命令:vim test.log,将test.log文件中的开头和结尾非数据部分给删掉
剩下的test.log中全是同步过来的数据部分,然后将每一行列数同步到另外一个临时文件test2.log中,执行如下命令:awk -F '\t' '{print NF}' >test2.log
此时我们再次编辑test2.log,找到不是正常列数对应的行,直到没有不正常列数对应的行,此时可以正式修改pm_history.json,来进行正常同步数据。