任何事物都有两面性。
一些机器学习问题也是如此。并非每个回归问题(你认为的)都需要回归。仔细考虑和审视问题的业务不仅可以帮助开发更好的模型,还可以找到有效的解决方案。
重构或重新定义(reframing)是一种改变机器学习问题输出表示的策略。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、回归问题重构
例如,我们可以将回归问题转换为分类问题(反之亦然)。
每个机器学习问题都始于范围界定(scoping)。
范围界定涉及从用户的角度思考问题、确定项目范围以及谁将使用它。这可能涉及提出以下问题:
- 这是一个监督问题还是非监督问题?
- 我们服务的最终用户是谁?
- 最终产品对人类生命/财产是否至关重要?
- 多少错误是可以接受的?
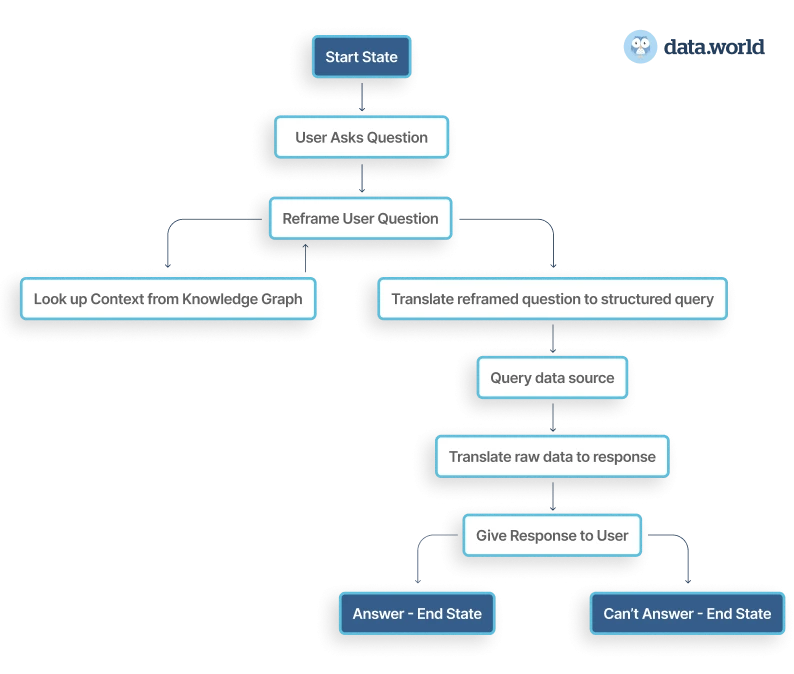
假设,我们想使用线性回归来预测医院每月的运营时间,以便确定医院的人员配备要求。运营时间变量取决于我们数据集的独立变量,例如每月的 X 光检查次数、每月占用的床位天数和/或每月患者的平均住院时间。
因此,这个看似简单的任务看起来是一个回归任务,因为每月的运营时间是一个连续变量。当我们开始构建回归模型时,我们发现这个任务比听起来要难。同一组特征的运营时间会增加,可能是因为一年中某个时期的急性病,或者由于其他一些不一致。我们预测的运营时间可能会有(比如说)10 小时的偏差。但这不会对人员配备要求产生太大影响。
也许我们可以重新构建我们的机器学习目标,以提高性能。
这里的问题是预测运营时间是概率性的。我们可以将目标构建为分类任务,而不是尝试将此变量预测为回归任务。
将实值因变量分解为大小相等的箱/类别:
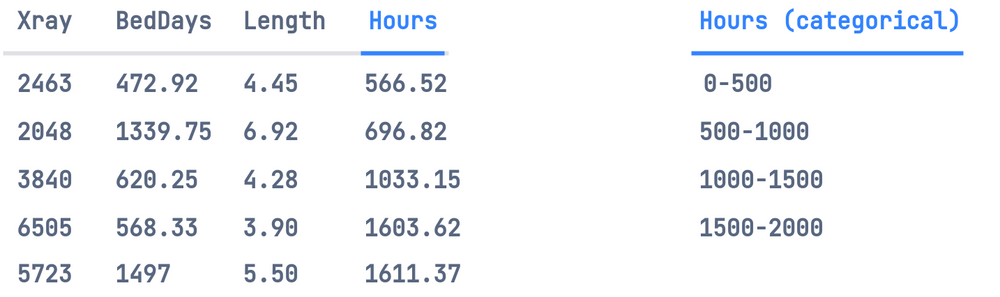
然后,我们将对这些类别进行one-hot处理,并创建一个多类分类模型,该模型将对离散概率分布进行建模。
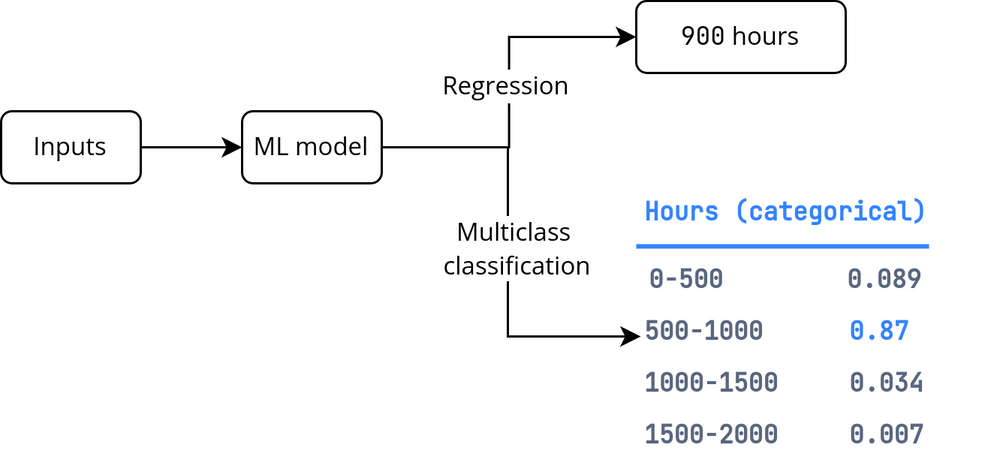
当然,我们需要更细粒度的桶。但这只是为了说明目的
分类方法允许模型捕获不同离散范围内的运行时间概率分布,而不必选择分布的平均值。
这在以下情况下非常有用:
- 变量不呈现典型的钟形曲线(可能是 tweedie 分布)。
- 当分布为双峰分布(具有两个峰值的分布)时,或者即使分布为正态但方差较大时。
- 当分布为正态但方差较大时
2、它为什么有效?
我们正在将模型的目标从学习连续值转变为学习离散概率分布;以损失精度为代价,但反过来,我们获得了完整概率密度函数 (PDF) 的表达能力。
这种分类框架的另一个优点是,我们获得了预测值的后验概率分布,这提供了更细微的信息。
3、权衡与替代方案
另一种方法是多任务学习,它使用多个预测头将两个任务(分类和回归)组合成一个模型,但要注意由于数据集的限制而引入标签偏差的风险。
重新构建回归问题是捕捉不确定性的一种非常好的方法。捕捉不确定性的其他方法是进行分位数回归(quantile regression)。
例如,我们可以估计需要预测的条件第 10、20、30、...、90 个百分位数,而不是仅仅预测平均值。分位数回归是线性回归的扩展。另一方面,重新构建可以与更复杂的机器学习模型一起使用。
3.1 预测精度
如上例所示,我们牺牲了精度来获得离散概率分布函数 (PDF) 的表达能力。如果需要更精确,则需要增加分类模型的箱数。
PDF 的锐度表示回归任务的精度。 PDF 越锐利,表示输出分布的标准差越小,而 PDF 越宽,表示标准差越大,因此方差越大。
对于锐利的密度函数,请坚持使用回归模型。
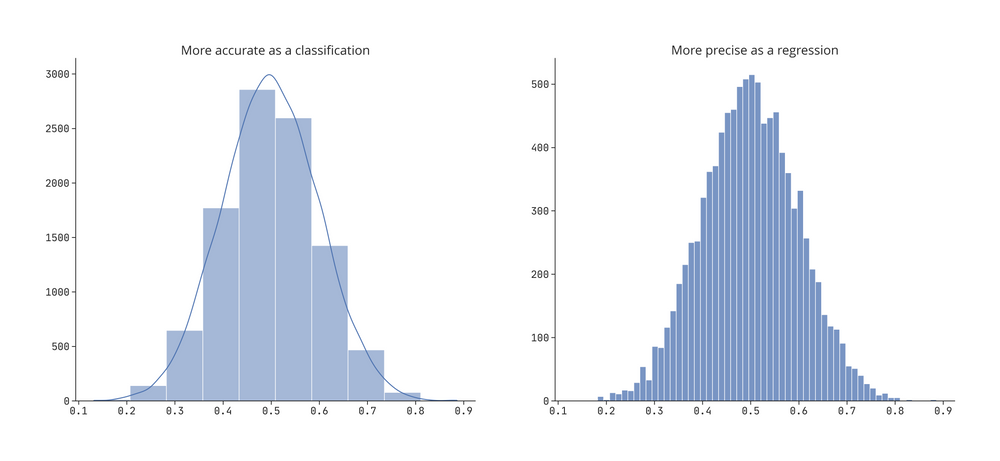
回归的精度由一组固定输入值的概率密度函数的锐度表示
我们可以通过对右侧图中的特征进行分桶处理来获得左侧的相同图。
另外,不要混淆准确度(accuracy)和精确度(precision)的概念:
准确度是测量值与真实值的接近程度。
精确度是(同一项目的)测量值之间的接近程度。
3.2 重构作为限制预测范围的一种方法
很多时候,预测范围是一个实值变量。 仅使用一个神经元的密集层可能会使预测输出超出可接受/可解释的范围。
重构可以在这里起到救援作用。
为了限制预测范围,将倒数第二层的激活函数设为 S 型函数(通常与分类相关),使其在 [0, 1] 范围内,并让最后一层将这些值缩放到所需范围:
MIN_Y = 3
MAX_Y = 20
input_size = 10
inputs = keras.layers.Input(shape=(input_size,))
h1 = keras.layers.Dense(20, 'relu')(inputs)
h2 = keras.layers.Dense(1, 'sigmoid')(h1) # a sigmoid layer
output = keras.layers.Lambda(
lambda y: (y*(MAX_Y-MIN_Y) + MIN_Y)
)(h2) # a custom layer for scaling
model = keras.Model(inputs, output)
由于输出是 S 型函数,因此模型实际上永远不会达到范围的最小值或最大值,只是接近它。
3.3 标签偏差
基于神经网络的推荐系统被设计为回归或分类模型,比矩阵分解更具优势,因为它们可以结合矩阵分解中学习到的用户和项目嵌入之外的更多附加特征。
但是,将目标设计为分类问题(观众是否会点击)可能会导致推荐系统优先考虑点击诱饵。
在这种情况下,最好将目标重新定义为回归问题,预测将观看的视频部分,或视频观看时间,甚至预测用户观看至少一半视频片段的可能性。
3.4 多任务学习
我们甚至可以尝试两者,而不是将任务重新设计为回归或分类,这称为多任务学习。
多任务学习是指优化多个损失函数的任何机器学习模型。
神经网络中多任务学习最常见的两个分支是:
- 硬参数共享——当模型的隐藏层在所有输出任务之间共享时。
- 软参数共享——当每个标签都有自己的神经网络和自己的参数时,通过某种形式的正则化鼓励不同模型的参数相似。

多任务学习的两种常见实现
原文链接:机器学习问题的重新定义 - BimAnt