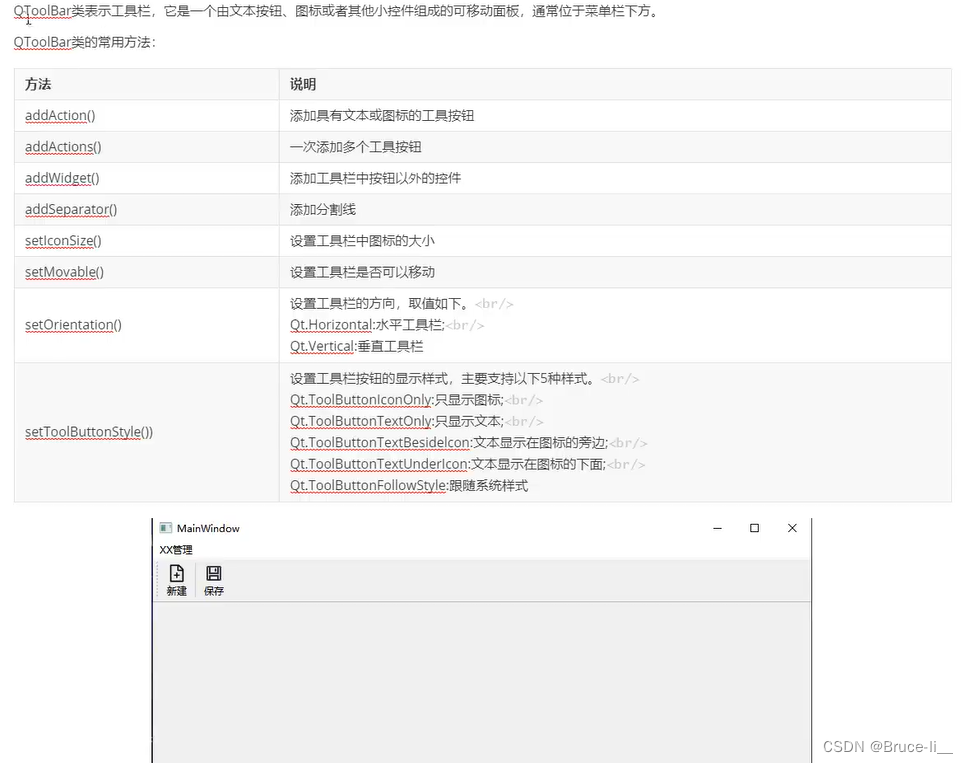
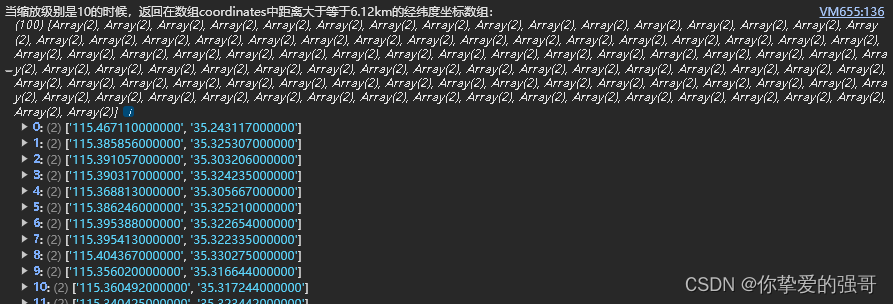
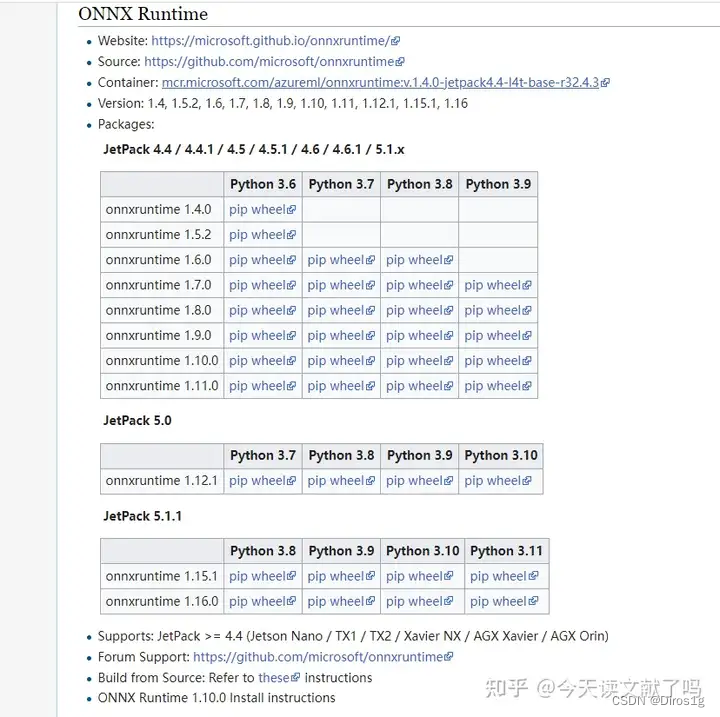
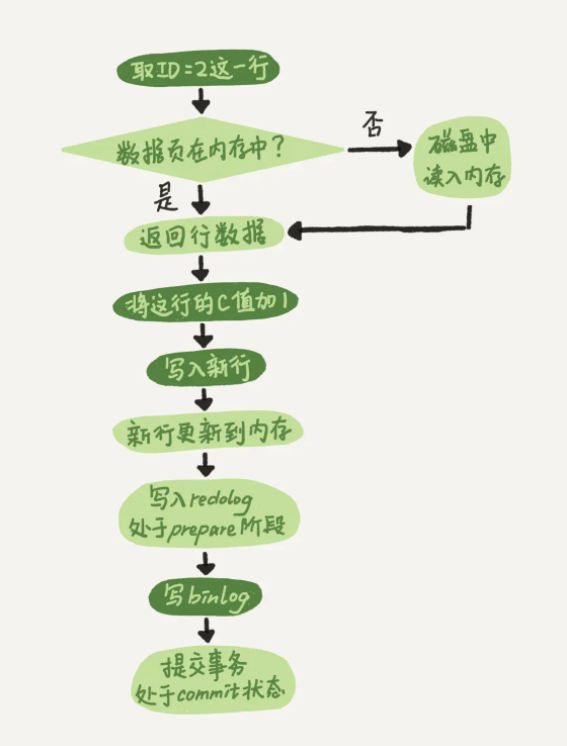
大型语言模型 (LLM) 不值得信任。就是这样。
考虑到它们先进的 AI 能力以及当今强大的基础模型的普遍知识,这似乎是一件令人惊讶的事情。然而,问题的关键在于 LLM 无法解释其输出。你不能信任 LLM 的结果,不是因为它不准确,而是因为它令人费解。没有办法审核答案或检查其工作。
这类似于接受一个人的话,却没有能力验证他们的主张;这对于关键的业务决策来说是行不通的。健康的关系建立在信任的基础上。企业与其 ML 模型的关系也不例外。那么你如何克服你的信任问题呢?
你可能听过这样一句话:“信任,但要核实”。这句古老的谚语是否预示着LLM的到来?虽然你不能完全信任大型语言模型,但这并不意味着你应该完全放弃它们。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、是否有可能超越 LLM 响应猜测?
LLM 在统计概率领域运行,没有确定性边界。它们生成解决方案而不引用任何预定义的数据库或“真相来源”。因此,不可能交叉检查 LLM 输出或要求他们证明他们的答案。这就像试图检查一个人的大脑内容一样——你做不到。
用于生成每个 LLM 响应的配方成分无法追踪或解构;配方本质上是一个黑匣子。但这并不是绝望的理由。
LLM 响应上下文中固有的不信任并不意味着组织应该放弃它们。 LLM 就像你听说的那样强大;你只需要正确使用它们。
如果使用得当,它们可以作为自主智能代理的组成部分,用于回答企业问题。诀窍是使用 LLM 将自然语言问题重新定义为结构化查询。当针对受管理和可审计的数据源执行这些查询时,它们会产生准确的答案——最重要的是,可证明的准确答案。
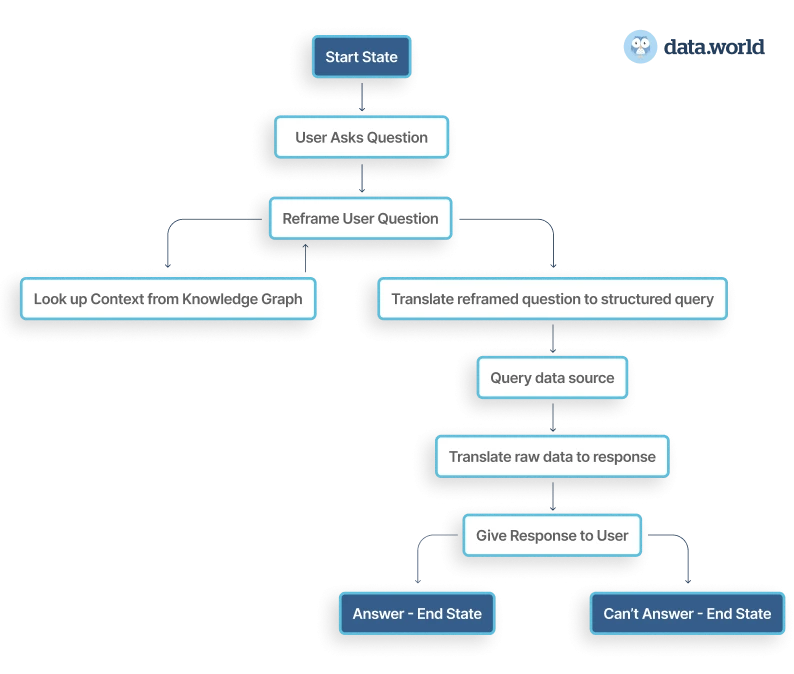
在这个场景中,用户的回答是透明且可审计的,而不是隐藏在黑匣子里。答案满足了用户的需求,但背后一切都是可追溯和可验证的。就像老师要求学生“展示你的作品”一样,答案和答案的路径都是完全可见的。
2、真实用例:人力资源数据代理
假设你是公司的人力运营经理。你无法询问 ChatGPT,“哪些员工受我们的薪资范围政策约束?”
ChatGPT 不知道如何回答这个问题;它不知道你有多少员工,你的薪资范围政策是什么,以及它应该考虑哪些其他参数。这些信息在你组织的数据存储中是分散的;其中一些是私密的,ChatGPT 无法获取。
当然,你可以努力在数据库上训练 ChatGPT;向其提供有关你的薪资范围政策以及员工名册等的信息。但是,你无法验证它的响应是否准确;它们只是最佳猜测。
现在,重新构建你的方法。使用像上面这样的自主代理架构来重新构建你的查询过程。
你问代理,“哪些员工受我们的薪资范围政策约束?”代理可以在知识图谱中查找你的策略,并了解策略的定义方式。
假设此示例为“必须每年审查工资高于其工资范围最高工资 95% 的每个员工”。它可以利用这些知识将问题重新定义为“哪些员工的工资高于其工资范围最高工资的 95%?” 这个问题可以转化为结构化查询。
代理可以运行该查询并得到答案 - 它对问题的答案包含完整而全面的上下文路径以“显示工作”并得出事实的、有数据支持的响应。你(最终用户可以)可以验证它是否查找了正确的策略、正确解释了它并运行了正确的查询。
3、克服 LLM 信任问题
自主代理方法将 AI 问答的强大功能与强大的可解释性和可审计性结合在一起。因此,公司可以依靠这些智能代理进行决策,并确保他们的 AI 驱动的见解是受规则控制且值得信赖的。
尽管 LLM 在管理大量数据和复杂查询方面具有显著优势,但必须严格管理其使用,以确保透明度、可验证性和信任度。归根结底,不仅仅是 LLM,自主代理加上知识图谱和强大的治理框架,才能成为企业可靠的 AI 解决方案。
4、最后的想法
LLM 既不是你可以完全信任的魔盒,也不是混乱的潘多拉魔盒。通过正确的方法和严格的治理,可以有效地利用它们。
通过将自然语言问题重新定义为结构化查询,我们可以确保 AI 驱动的企业解决方案的准确性、可解释性和治理。这不是要丢弃盒子,而是要学习如何明智地补充它。
原文链接:企业利用LLM的正确方法 - BimAnt