从0开始带你成为Kafka消息中间件高手—第一讲
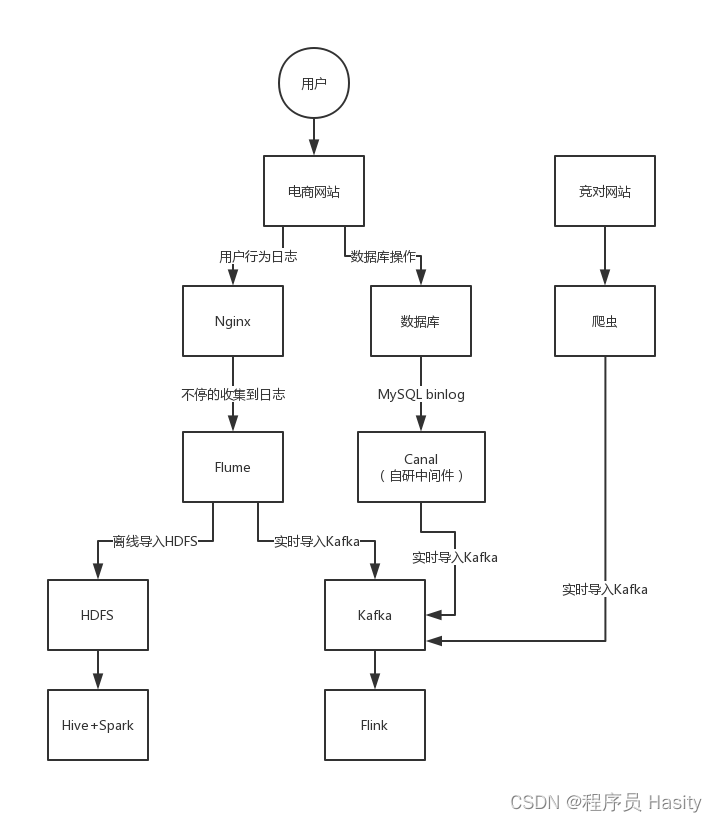
网站的用户行为日志,假设电商网站,我现在需要买一个阅读架,看书的架子
京东,我平时比较喜欢用的是京东,送货很快,自营商品,都是放在自己的仓库里,送货很快,用的比较多的是,直男,买东西都是开门见山的,女孩儿不一样,女同志,喜欢逛网站,她喜欢在网站里上下浏览,看网站推荐的一些东西
用户行为,就是说在一个网站,或者是APP,用户会做很多的行为和操作,比如说搜索一个商品,选择接筛选项来过滤筛选商品,点击一个商品进入他的详情页,加入购物车,进入购物车界面,下订单,对订单进行支付,对商品进行评价
电商网站最核心的链路就是这样的,搜索、筛选、详情页、购物车、下单、支付、评价
用户行为,每个用户每次在电商网站里都会做很多的行为,这些用户行为实际上来说会被电商网站给收集起来你的每个行为,你每次做一个行为的时候,他就会把你的这个行为做一条日志发送到后台
后台每天就会收集大量的用户行为日志
通过对用户行为日志的分析,可以让产品经理(设计网站和app)知道自己设计的网站是否受到用户的喜欢,可以让运营专员知道自己设计推广的某个促销活动他的效果如何,还可以让中高层管理人员,每天看到网站经营的数据
电商网站有1000万注册用户,那么每天会有多少人来逛这个网站呢?每天日活用户300万,平均每个人会在网站上做多少个行为呢?假设平均每个人做的行为有100次,这个算的是比较高的了。
每天就有3亿个行为,每个行为会对应一条用户行为日志,每天的用户行为日志有3亿
用户行为日志,业务数据(数据库,商品、订单、库存、评价、售后,每天都会产生各种各样的变化)
1000万用户,日活300万,每天3亿用户行为日志
对于大数据实时计算来说,数据库的变更操作,增删改的操作,每次增删改操作就算一条数据,数据变更记录,需要交给大数据平台来处理
假设每天有50万个订单,商品(价格、库存、信息),订单,评价,售后,积分,促销,很多其他的数据,每天新增的都是以订单为核心的一些数据,每天都有的增量数据,其他的数据都是围绕订单来的
是在数据库新增的订单,每对应修改,对应多少个增删改数据库操作呢?5个增删改的操作,订单表,每天有250万次操作,变更记录。100张左右的表,平均每张表每天会发生的增删改的操作大概是有200万次,2亿左右的数据
每天数据库有2亿条的变更记录,就是第二种数据了,业务数据
第三种数据,用户行为日志,还有业务库的数据,爬虫抓的竞对网站的商品数据,竞对网站每个商品的销量、价格,就可以跟自己网站的同类商品的销量和价格做一个比对,淘宝上抓数据,几十亿个商品,几亿个商品
假设有三个同类的竞争对手网站,人家每个网站的商品数量在100万左右,每天爬虫就把人家的100万个商品抓取过来就可以了,300万条数据而已,每个商品每天的销量在不停变化,爬虫可能需要不停地抓取对方网站的数据,每个商品每隔10分钟就会抓取一次,6 * 24 = 144 = 150次
300万商品,150次,4.5亿,5亿数据
来算一下,用户行为日志(3亿),业务库变更记录(2亿),竞对数据(5亿) = 10亿
涌入到kafka里去,可以做用户行为分析,网站运营分析,竞争对手分析,协助网站的产品经理、运营人员、企业高层把控网站每天运行的方方面面,以此做出对应的一些决策
研究kafka这个东西,你必须得搞清楚这两个概念,吞吐量,延迟
写数据请求发送给kafka一直到他处理成功,你认为写请求成功,假设是1毫秒,这个就说明性能很高,延迟
kafka,每毫秒可以处理1条数据,每秒可以处理1000条数据,这个单位时间内可以处理多少条数据,就叫做吞吐量,1000条数据,每条数据10kb,10mb,吞吐量相当于是每秒处理10mb的数据
如果来一条数据就处理一条数据,可能会导致每条数据要处理假设1毫秒,那么此时每秒可以处理1000条数据,这就是每秒的吞吐量,但是如果采用微批处理技术呢?比如说把9毫秒内的数据收集起来一共有1000条数据,接着一次性交给引擎来处理 ,1毫秒就把1000条数据给处理完了。
Kafka现在采取batch思路,10毫秒处理了1000条数据,每个系统发送数据过来到处理完成花费10毫秒,延迟提高了10倍,Kafka的吞吐量提高了,每秒可以处理10万条数据,吞吐量是提升了100倍。
那么就相当于是10毫秒处理了1000条数据,每秒可以处理10万条数据,吞吐量是不是就提升了100倍?
这个就是所谓的流式计算采用的微批处理技术,你一条一条处理,每条数据都需要启动新的计算资源,有网络开销,甚至是磁盘开销。但是你一次性处理1000条,跟你一次性处理1条其实是差不多的
因为用的计算资源什么都差不多,但是在内存里一下子可以处理完1000条数据
这就是说,提升了吞吐量,但是计算的延时就增加了,一条数据过来,需要10毫秒之后才能处理完毕。但是你要是降低计算的延时,那么吞吐量就降低了,数据来了1毫秒就处理完毕,但是每秒能处理的数据量太少了
batch微批处理,高吞吐高延迟,kafka相反,高吞吐低延迟
直接写入os的page cache中
文件,kafka仅仅是追加数据到文件末尾,磁盘顺序写,性能极高,几乎跟写内存是一样高的。磁盘随机写,你要随机在文件的某个位置修改数据,这个叫做磁盘随机写,性能是很低的,磁盘顺序写,仅仅追加数据到文件末尾
而且写磁盘的方式是顺序写,不是随机写,性能跟内存写几乎一样。就是仅仅在磁盘文件的末尾追加写,不能在文件随机位置写入
假设基于上面说的os cache写 + 磁盘顺序写,0.01毫秒,低延迟,高吞吐,每毫秒可以处理100条数据,每秒可以处理10万条数据,不需要依托类似spark straeming那种batch微批处理的机制
正是依靠了这个超高的写入性能,单物理机可以做到每秒几十万条消息写入Kafka
这种方式让kafka的写性能极高,最大程度减少了每条数据处理的时间开销,反过来就大幅度提升了每秒处理数据的吞吐量,一般kafka部署在物理机上,单机每秒写入几万到几十万条消息是没问题的
这种方式是不是就兼顾了低延迟和高吞吐两个要求,尽量把每条消息的写入性能压榨到极致,就可以实现低延迟的写入,同时对应的每秒的吞吐量自然就提升了
所以这是kafka非常核心的一个底层机制
而且这里很关键的一点,比如rabbitmq这种消息中间件,他会先把数据写入内存里,然后到了一定时候再把数据一次性从内存写入磁盘里,但是kafka不是这种机制,他收到数据直接写磁盘
只不过是写的page cache,而且是磁盘顺序写,所以写入的性能非常高,而且这样不需要让kafka自身的jvm进程占用过多内存,可以更多的把内存空间留给os的page cache来缓存磁盘文件的数据
只要能让更多的磁盘数据缓存在os cache里,那么后续消费数据从磁盘读的时候,就可以直接走os cache读数据了,性能是非常高的