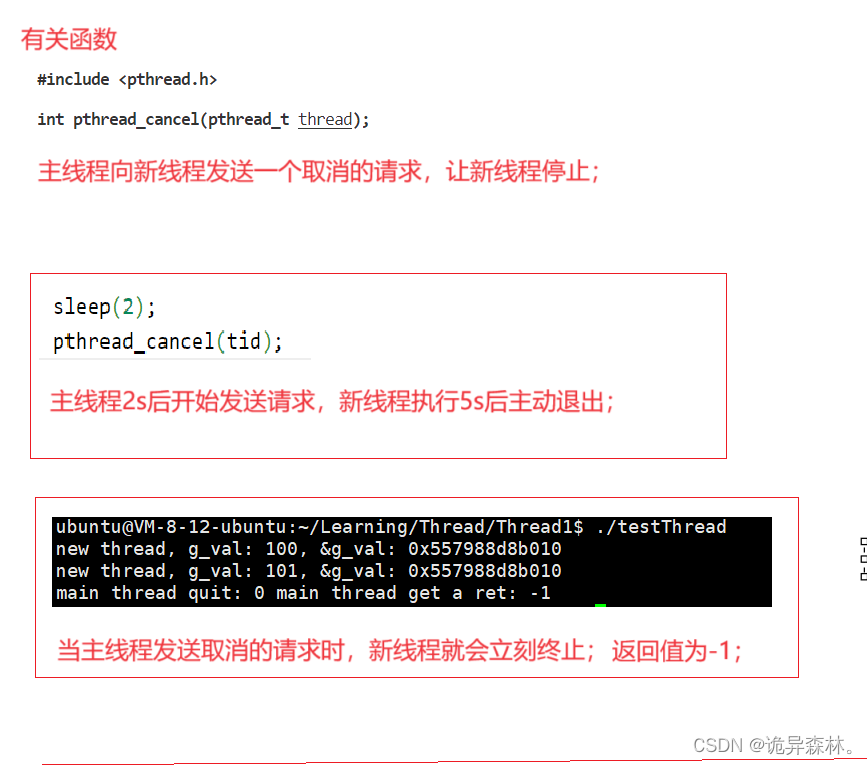
Oracle Graph 入门 - RDF 知识图谱
- 0. 引言
- 1. 查看 RDF Semantic Graph 安装情况
- 2. 创建一个语义网络
- 4. 创建一个模型
- 5. 加载 RDF 文件
- 6. 配置 W3C 标准的 SPARQL 端点
0. 引言
Oracle Graph 的中文资料太少了,只能自己参考英文资料整理一篇吧。
Oracle 数据库包括一个企业级资源描述框架 (RDF) 三元存储,作为空间和图选项的一部分。RDF 是 W3C 标准的图数据模型,用于表示知识图谱,知识图谱越来越多地用于支持智能应用程序。
本文主要介绍如何在 Oracle Database 23ai 上配置 Oracle Spatial and Graph — RDF Semantic Graph。我们将使用 Oracle SQL Developer 进行与 Oracle Database 23ai 实例的大部分交互。
1. 查看 RDF Semantic Graph 安装情况
我们使用 system 用户连接到 Oracle Database,执行下面语句,
SELECT * FROM MDSYS.RDF_PARAMETER;
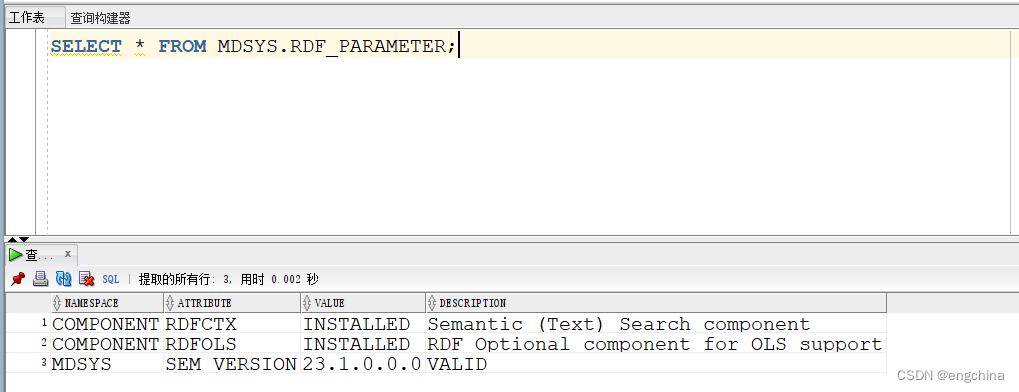
查询结果应显示有效的 RDF Semantic Graph 23.1.0.0.0 安装。
如果没有启用,执行下面语句,
@?/rdf/admin/rdfsqlj.sql
@?/md/admin/catmd.sql
2. 创建一个语义网络
接下来,我们将创建一个语义网络来准备用于存储 RDF 数据的数据库。作为先决条件,我们需要为语义网络创建一个表空间。以 SYSTEM 身份运行以下 SQL 语句,为语义网络创建表空间。
CREATE TABLESPACE rdf_tblspace
DATAFILE 'rdf_tblspace.dat' SIZE 10240M REUSE
AUTOEXTEND ON NEXT 256M MAXSIZE UNLIMITED
SEGMENT SPACE MANAGEMENT AUTO;
创建一个数据库用户以处理数据库中的语义数据,并向数据库用户授予必要的权限。
CREATE USER rdfuser
IDENTIFIED BY rdfuser
QUOTA 9G ON rdf_tblspace;
GRANT CONNECT, RESOURCE, CREATE VIEW TO rdfuser;
ALTER USER rdfuser QUOTA UNLIMITED ON users;
以网络所有者用户rdfuser身份进行连接。
现在,我们可以执行下面语句来创建语义网络。
EXECUTE SEM_APIS.CREATE_SEM_NETWORK('rdf_tblspace', network_owner=>'rdfuser', network_name=>'rdf_net');
或者,我们可以使用 SQL Developer 的 RDF Semantic Graph 组件来创建语义网络。通过单击连接名称旁边的加号来展开系统连接,然后向下滚动到 “RDF 语义图形” 组件。右键单击 “网络”,然后选择 “创建语义网络”。
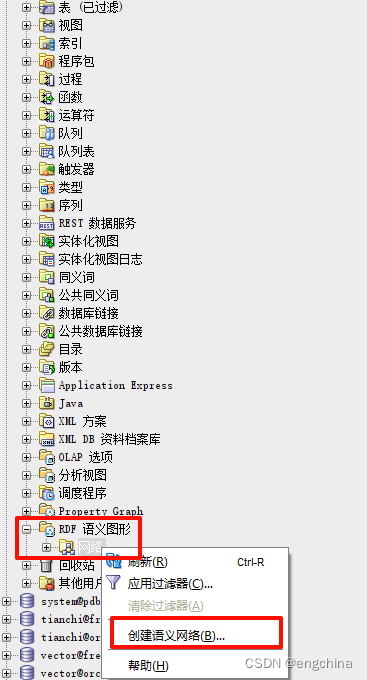
使用下拉菜单选择我们之前创建的表空间,然后单击应用。
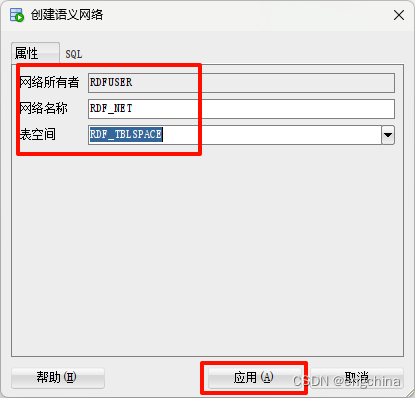
这样,我们已经验证了 RDF Semantic Graph 的安装,并创建了存储 RDF 数据所需的所有必要数据库对象。
4. 创建一个模型
创建模型时,可以指定模型名称、用于保存对模型语义数据的引用的表以及该表中 SDO_RDF_TRIPLE_S 类型的列。
以下命令创建在 net1 schema-private network 中命名 LGC_SPORT 的模型。
EXECUTE SEM_APIS.CREATE_SEM_MODEL('LGC_SPORT', null, null, 'RDF_TBLSPACE',network_owner=>'RDFUSER',network_name=>'RDF_NET');
或者,我们可以使用 SQL Developer 的 RDF Semantic Graph 组件来创建模型。

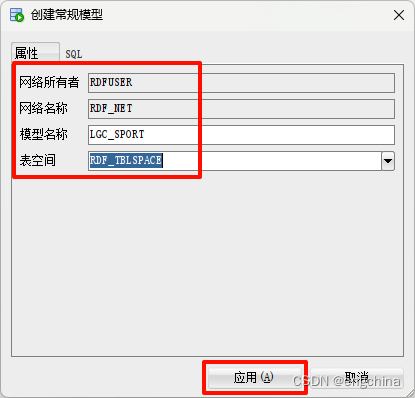
我们现在已经创建了一个模型来保存我们的 RDF 数据。如果在 RDF Semantic Graph 下展开 Models 和 Regular Models,您应该会看到我们创建的 LGD_SPORT 模型。
5. 加载 RDF 文件
我们将使用 120 万个体育设施的三重数据集,从这里下载。
现在,我们将批量加载下载的 RDF 文件。批量加载过程包括两个主要步骤:
1,将文件从文件系统加载到数据库中的简单临时表中。
2,将数据从暂存表加载到我们的语义模型中。
第一步涉及从外部表加载,因此我们需要使用 SYSTEM 连接在数据库中创建一个 DIRECTORY,并将该目录的权限授予 RDFUSER。
现在服务器上创建一个目录。
mkdir -p /home/oracle/data/graph_dump
然后,我们可以使用 SQL Developer,展开 SYSTEM 连接并右键单击 Directories。然后选择 Create Directory (创建目录)。
输入数据库服务器上目录的目录名称和完整路径。单击应用。

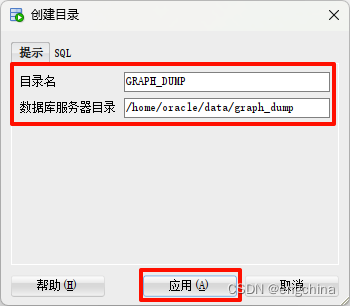
展开“目录”,然后单击目录名称以查看详细信息。

现在我们需要将此目录的权限授予 RDFUSER。单击“操作”,然后选择“授予”。
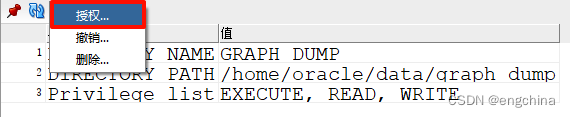
授予 RDFUSER 的 READ 和 WRITE 权限。单击应用。
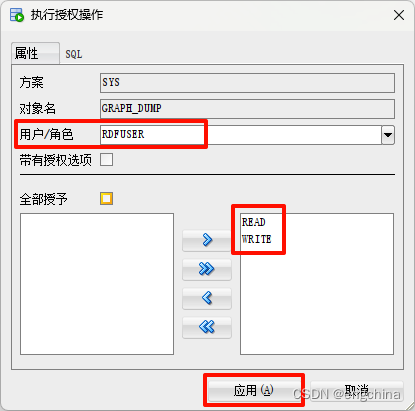
RDFUSER 现在可以访问 Oracle Database 实例上的 /home/oracle/data/graph_dump 目录。
下载的 RDF 文件是压缩的,在加载到暂存表之前,我们在windows系统解压缩之后,在上传到 Oracle Database 实例的 /home/oracle/data/graph_dump 目录。
现在,在 SQL Developer 中展开 RDFUSER 连接,并展开 RDF Semantic Graph 组件。然后右键单击“模型”,然后选择“将RDF数据加载到暂存表(外部表)”。
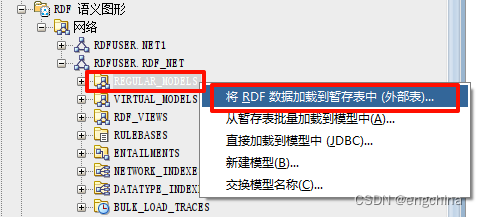
为要创建的外部表选择一个名称(我们正在使用LGD_EXT_TAB),并填写“源外部表”选项卡上的其他字段。
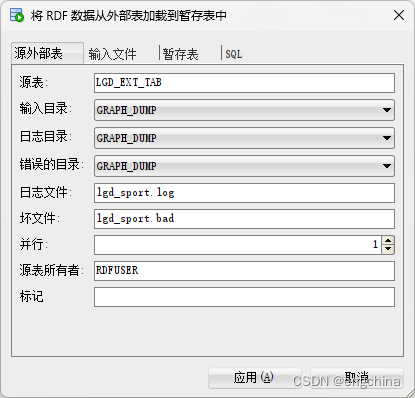
在“输入文件”选项卡上输入要加载的文件的名称(在本例中为 2015-11-02-SportThing.node.sorted.nt)。
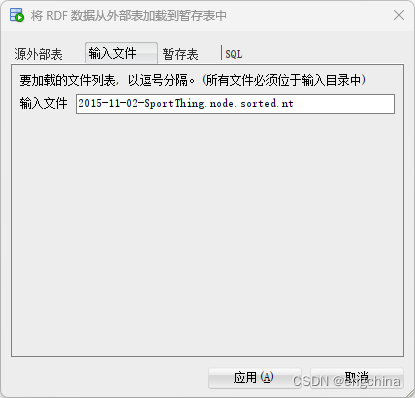
最后,使用“暂存表”选项卡输入将要创建的暂存表的名称(我们正在使用LGD_STG_TAB)并选择适当的格式。
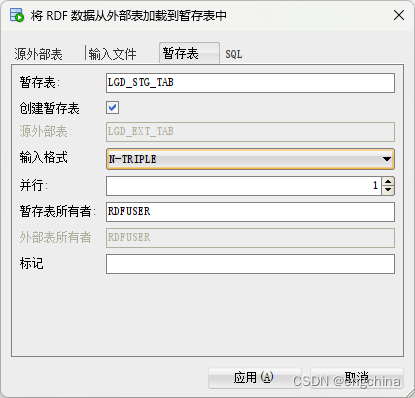
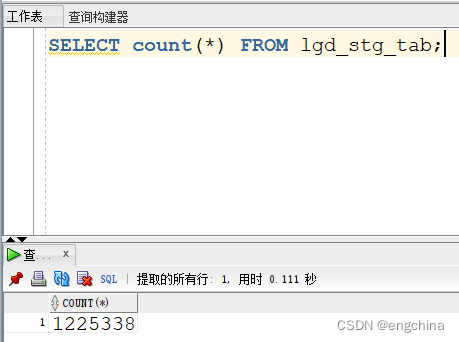
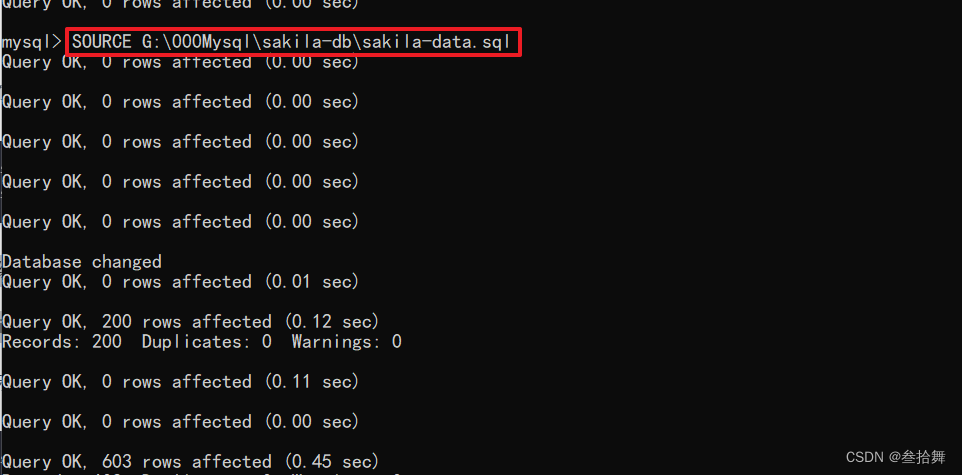
现在,单击“应用”将数据加载到LGD_STG_TAB中。 检查LGD_STG_TAB的内容。
SELECT count(*) FROM lgd_stg_tab;
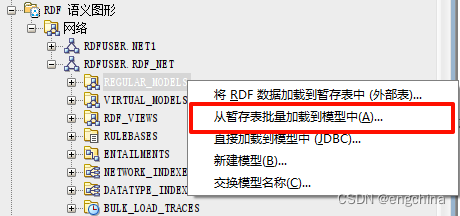
接下来,我们将LGD_STG_TAB的数据加载到LGD_SPORT语义模型中。要启动批量加载接口,请在 RDFUSER 连接下展开 RDF Semantic Graph。然后,右键单击“模型”并选择“从暂存表批量加载到模型中”。
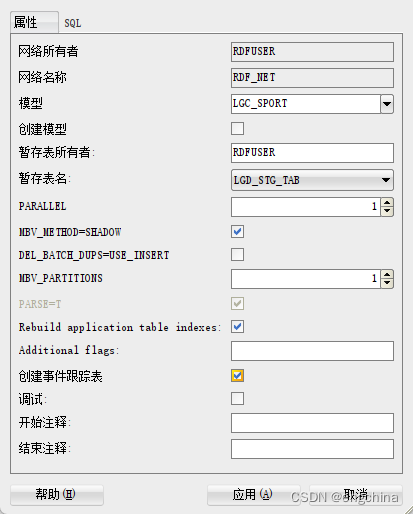
输入 Model 的 LGD_SPORT 并取消选择 Create model 选项,因为我们已经创建了这个语义模型。此外,为暂存表名称选择LGD_STG_TAB。请注意不要选择外部表 (LGD_EXT_TAB),因为它也会被列出。有关批量加载的其他选项的更多信息,请参阅用户指南。单击“应用”,加载将在一分钟左右完成。
现在我们已经完成了批量加载,收集整个RDF网络的统计信息是个好主意。只有特权用户才能收集整个 RDF 网络的统计信息,因此我们需要使用 SYSTEM 用户或其他 DBA 用户。展开 SYSTEM 连接下的 RDF Semantic Graph 组件,右键单击 RDF Semantic Graph 并选择 Gather Statistics。
输入所需的并行度,然后单击应用。
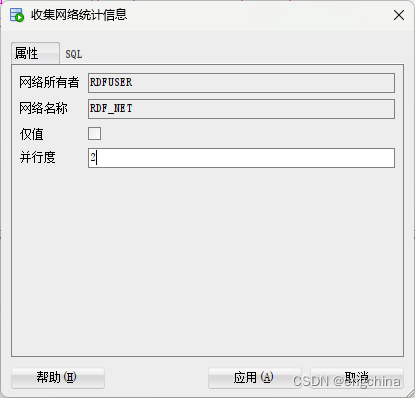
收集统计信息后,数据即可查询。
现在,我们将使用 SQL Developer 的 SPARQL 查询编辑器来查询我们的数据集。返回到 RDFUSER 连接,并在 RDF Semantic Graph 下展开 Models 和 Regular Models。单击“LGD_SPORT”将打开此语义模型的 SPARQL 查询编辑器。
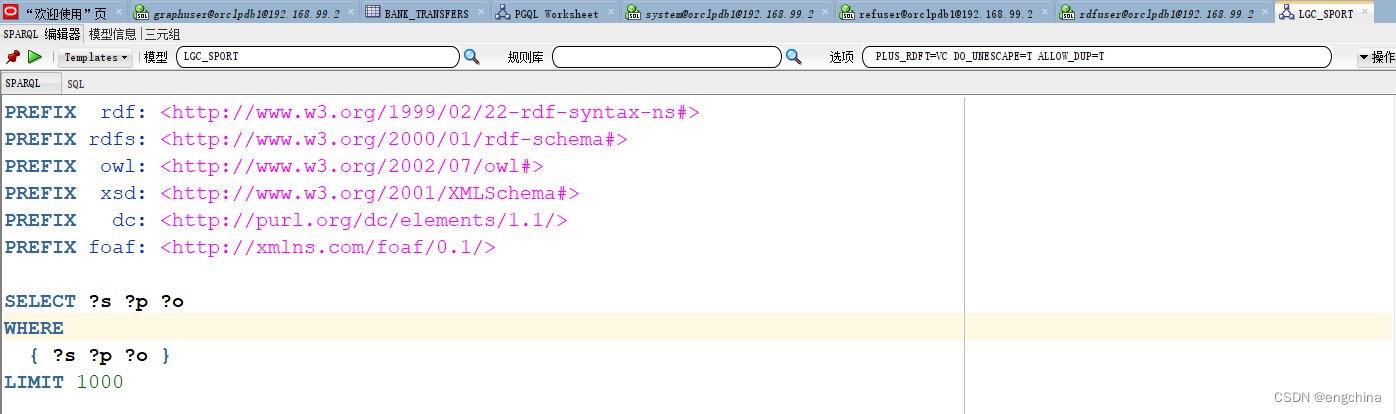
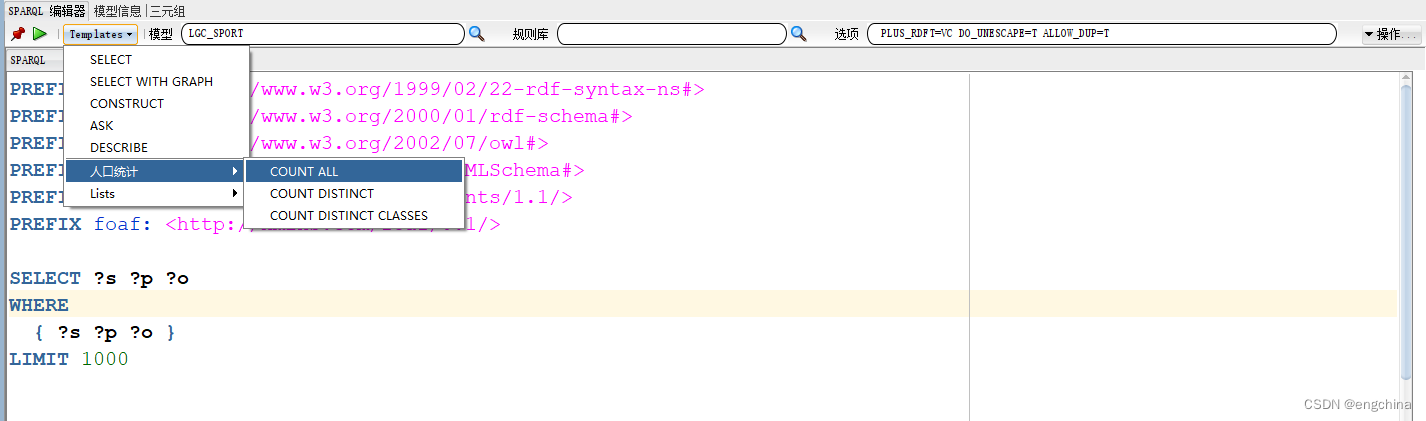
您可以在此处编辑和执行 SPARQL 查询。此外,还提供了几个预先创建的模板。
单击模板 -> 人口统计 -> 全部计数以计算LGD_SPORT模型中的所有三元组。
出现警告时单击“是”。
单击绿色三角形以运行查询。
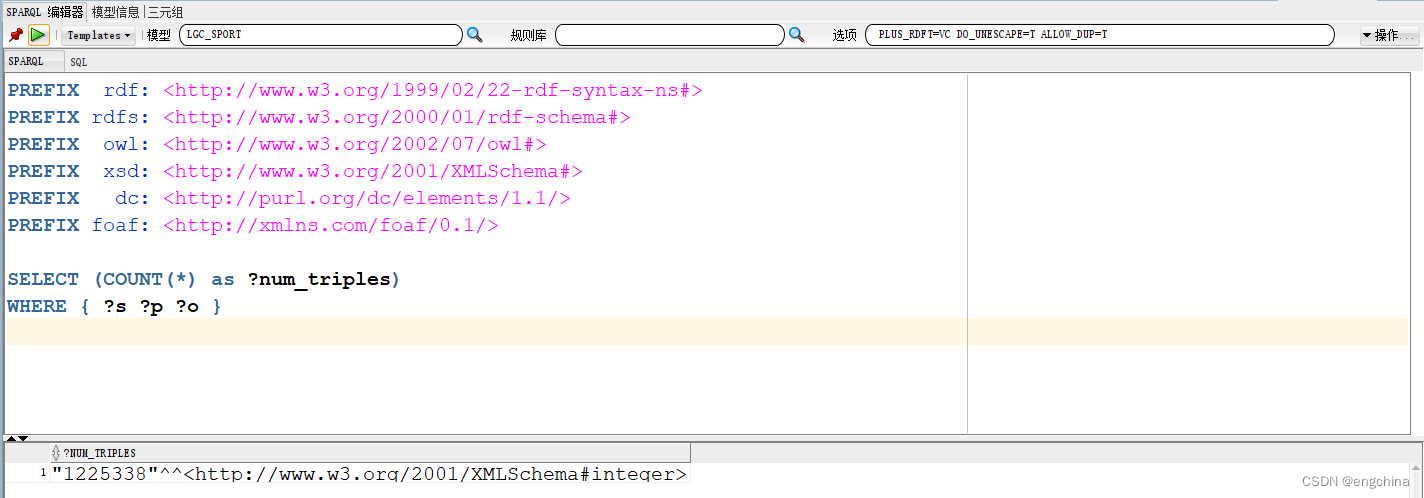
您也可以直接编辑 SPARQL 查询。下面的示例演示一个 SPARQL 查询,用于获取前 10 个属性及其三元组计数。
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?p (COUNT(?o) as ?cnt)
WHERE { ?s ?p ?o }
GROUP BY ?p
ORDER BY DESC (?cnt)
LIMIT 10
除了 SPARQL SELECT 查询之外,还支持 CONSTRUCT 和 DESCRIBE 查询。下面的查询描述了LGD_SPORT模型中的特定资源。请注意,查询中使用的任何命名空间前缀也将用于简化查询结果中的值。在这里,我们又添加了几个前缀。
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
DESCRIBE <http://linkedgeodata.org/triplify/node2872672301>
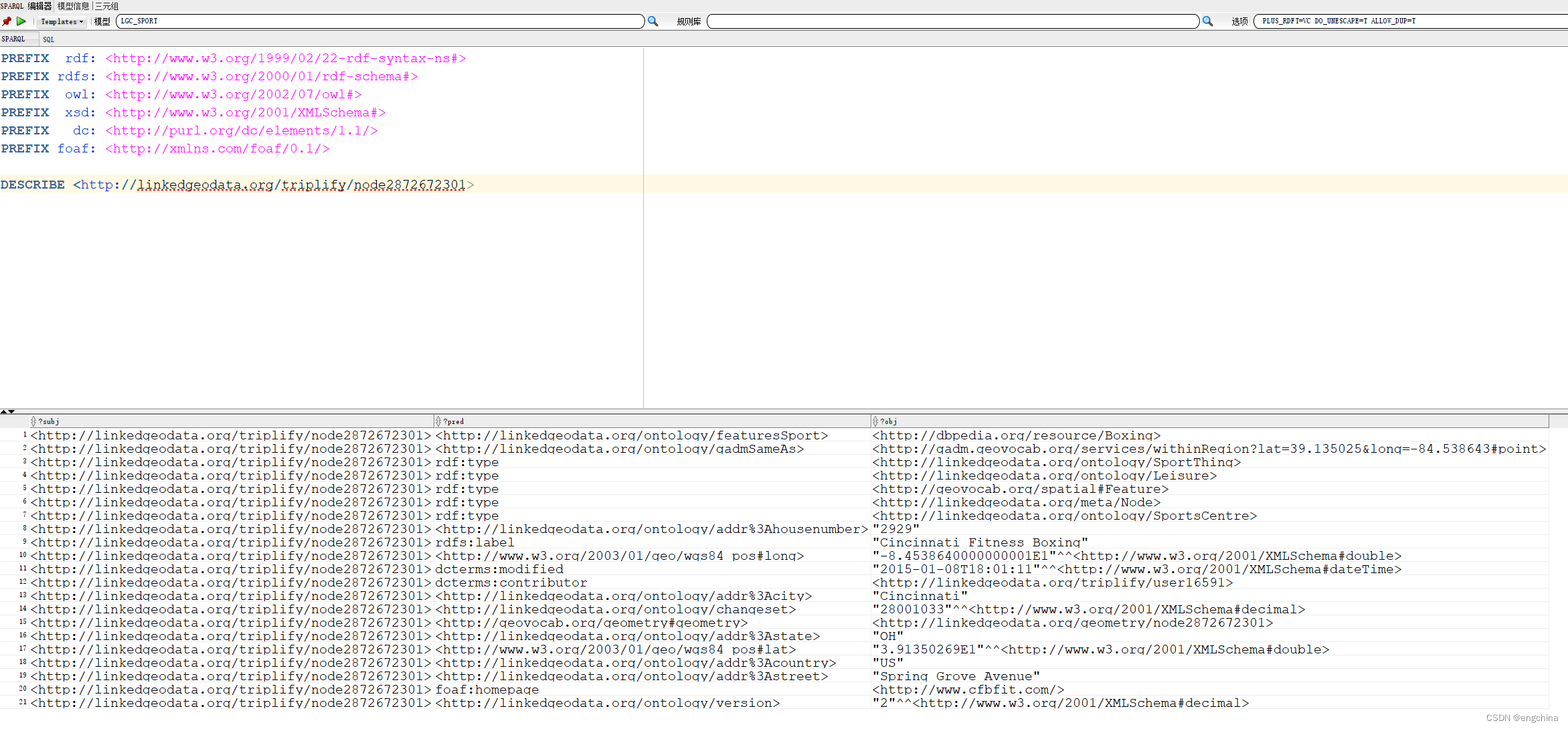
就是这样。我们已经成功地将一个公开可用的 RDF 数据集批量加载到我们的 DBCS 实例中,并使用 SQL Developer 的 SPARQL 查询编辑器执行了一些查询。
6. 配置 W3C 标准的 SPARQL 端点
我们将通过配置 W3C 标准的 SPARQL 端点来完成 Oracle Database 中 RDF 三元组存储的设置。
W3C 定义了几个用于查询和更新 RDF 数据的标准 REST API。Oracle RDF Semantic Graph 利用 Apache Jena Fuseki 提供这些接口的实现。Oracle 对 Apache Jena 的支持通过特定于 Oracle 的 Apache Jena 接口实现,在 Apache Jena 和 Oracle RDF Semantic Graph 之间实现了紧密集成。
这篇博文将展示如何在 Oracle Database 实例上设置和运行 Apache Jena Fuseki。Fuseki 可以作为独立服务器或 Java Web 应用程序运行。
第一步是从 OTN 下载最新的 Oracle 对 Apache Jena 的支持。打开 Web 浏览器进行 http://www.oracle.com/technetwork/database/options/spatialandgraph/downloads/index-156999.html。选择下载 Oracle Database 12c Release 12.1.0.2 Support for Apache Jena 3.1、Apache Jena Fuseki 2.4 和 Protégé Desktop 5.0。
下载完成后,将下载的 Oracle Support for Apache Jena 文件传输到 Oracle Database 实例。在此示例中,我们将文件复制到 /home/oracle。
以 oracle 用户身份打开与 Oracle Database 实例的 SSH 连接。
在 /home/oracle 中创建一个名为 Jena 的目录。然后将rdf_semantic_graph_support_for_12c_and_jena310_protege_5.0_2017_01_19.zip移动到新创建的 Jena 目录并解压缩文件。
解压缩命令完成后,您将看到几个目录和一个 README 文件。
现在,我们将配置 Fuseki 以访问我们之前创建的LGD_SPORT语义模型。将目录更改为 /fuseki 并编辑 config-oracle.ttl 文件。
将以下默认<#oracle>数据集规范从
<#oracle> rdf:type oracle:Dataset;
oracle:connection
[ a oracle:OracleConnection ;
oracle:jdbcURL “jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=orcl)))”;
oracle:User “rdfuser” ;
oracle:Password “rdfuser”
];
oracle:allGraphs [ oracle:firstModel “TEST_MODEL” ] .
改为,
<#oracle> rdf:type oracle:Dataset;
oracle:connection
[ a oracle:OracleConnection ;
oracle:jdbcURL “jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=PDB1.uspm020.oraclecloud.internal)))”;
oracle:User “rdfuser” ;
oracle:Password “rdfuser”
];
oracle:allGraphs [ oracle:firstModel “LGD_SPORT” ] .
请注意,根据特定 Oracle Database 实例的设置,SERVICE_NAME会有所不同。
接下来,我们将更改默认的 shiro.ini 配置以允许非本地主机连接。首先,我们需要启动 Fuseki 来创建一个 /run 目录。只需在当前 /fuseki 目录中执行以下命令即可。
./fuseki-server
看到 Fuseki 已在端口 3030 上启动的消息后,使用 Ctrl-C 终止该进程。
现在应该创建 /run 目录。将目录更改为 /run 并编辑shiro.ini。
Replace
/$/** = localhostFilter
with
/$/server = anon
$/** = localhostFilter
将目录更改回 /fuseki 并通过运行以下命令启动 Fuseki 服务:
nohup ./fuseki-server — config config-oracle.ttl > fuseki_out.log &
请注意,我们使用 nohup 来防止 Fuseki 进程在连接关闭时终止。
就是这样。Fuseki SPARQL 端点现已在我们的 Oracle Database 实例上启动并运行。
现在,Fuseki 服务器已在 DBCS 实例的端口 3030 上启动并运行,有两种连接选项:
单击“查询”,打开 SPARQL 查询界面。
单击“信息”可查看所有可用的 REST 端点。
我们还可以使用 curl 测试 SPARQL REST 接口。在此示例中,我们在 Windows 客户端计算机上使用 Cygwin 终端。以下 curl 命令会将文件 test_query.rq 中的 SPARQL 查询发送到 DBCS 实例上运行的 Fuseki 端点,并将结果打印到 stdout。
curl –X POST –data-binary “@test_quey.rq” –H “Content-Type: application/sparql-query” –H “Accept: application/sparql-results+json” “http://localhost:3030/sparql"
大功告成!我们已成功访问在 Oracle Database 实例上运行的 W3C 标准 SPARQL REST 端点。
“Oracle Graph 入门 — RDF 知识图谱”文章到此结束。
reference:
- https://docs.oracle.com/en/database/oracle/oracle-database/23/rdfrm/getting-started-rdf-data-schema-private-network.html
- https://medium.com/oracledevs/getting-started-with-oracle-spatial-and-graph-rdf-knowledge-graph-part-1-fa400427c6bd
- https://medium.com/oracledevs/getting-started-with-oracle-spatial-and-graph-rdf-knowledge-graph-part-2-2def0bc08a5c
- https://medium.com/oracledevs/getting-started-with-oracle-spatial-and-graph-rdf-knowledge-graph-part-3-ce40edc4b1f5










![[集群聊天服务器]----(一)项目简介](https://img-blog.csdnimg.cn/direct/14f7c781e31543f49dbf8b6b7f75e0d0.png)