面试这个领域最近环境不行,所以卷起来流量挺大
关于K8s
其实看我之前的博客,k8s刚有点苗头的时候我就研究过,然后工作的时候间接接触 也自己玩过 但是用的不多就忘记了,正苦于不知道写什么,水一篇 用来面试应该是够了
clickhouse
kafka
搭建:
总体来说 比较简单,主要是配置文件,命令的话分开了producer /consumer/ topic 大概这么个意思。具体可以看里面的博客
#host配置
#安装包
wget https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
#压缩 配置系统变量
#zk集群搭建 当然kafka自带zk 这都行,集群中zk的配置是都需要改的
#3.x kafka提供了kraft取代zk
https://blog.csdn.net/qq_41865652/article/details/126588263
点对点:生产者 发送 消息 到队列,消费者从队列 取出 并 消费(消费后不再储存)
一条消息 只会被一个消费者消费,想发给多个消费者 多次发送
发布/订阅:一对多,多个订阅者消费 消息,数据保留指定期限,默认7天
同一个消费组 中消费者 不能消费同一个partition中的数据
一个消费者一个分区(消费组)
0.9 偏移量储存在kafka的topic中
0.9将offset保存在zk中,0.9及后保存在Kafka“__consumer_offsets”主题
生产者
生产消息追加到log文件,采用分片/索引机制,将每个partition 分为多个segment,每个segment对应2个文件 index log,同一文件夹(topic名称+分区序号)。
同步
同步:ISR列表(同步副本 里面的follow与leader同步,选择从这个里面选 H W/LEO)
HW:消费者能看到的offset,isr队列min的LED ,hw-led待同步的消息
选leader (epoch,offset)二位数组,前面是任期 后面是标识大小谁最新
follower故障,从isr剔除,恢复后读取上一次HW高于的截取掉 从hw开始向leader同步 加入isr
- ack-1 数据不丢但会重,生产者pid消息seqnumber 如pid partion seqnumber一样,重复数据
- 0不重复 丢失
消费者
拉取pull,无消息 死循环,消费者 消费数据时传递timeout参数,当时无数据 等待一段时间再返回
topic多个partion
- 轮询rountRobin对topic组生效,一个消费组内all消费者订阅主题是一样的
- rang单个topic生效,数据不均衡
消费者不能同时消费 同组的 同一个分区
分区策略:消费者组 消费者个数 发生变化
offset维护
断电 宕机,消费者恢复后 记录的offset(zk/kafka)
消费者/topic/partion 确定offset
流程
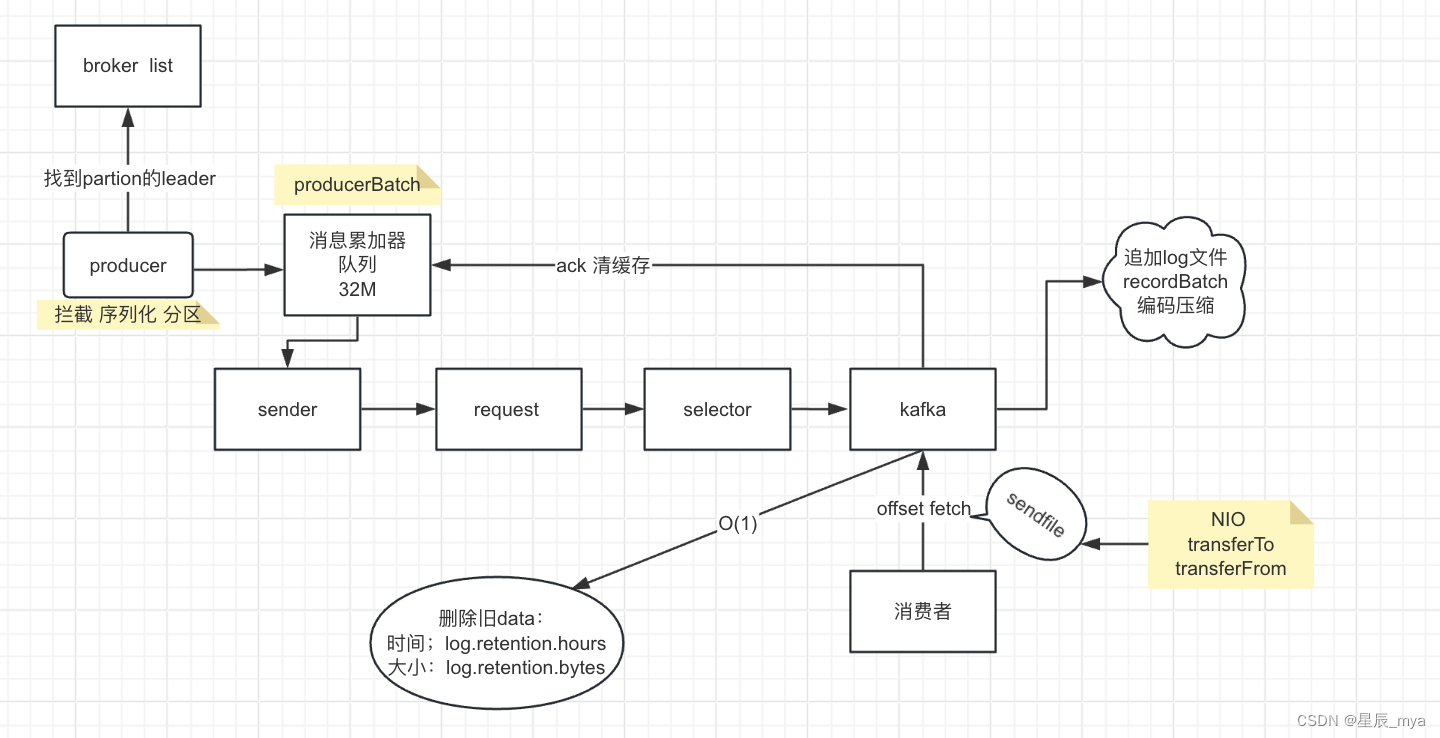
producer两个线程,主线程 拦截/序列化/分区==》处理消息 到 消息累加器(32M / 队列) producerBatch批量发送到sender线程,批量组织request 给selector 送到kafka
kafka的pageCache 异步刷盘 flusher 追加到日志文件
partition . segment:
log 存储数据 位置:offset
index索引,相对位移:物理位置;稀疏索引 msg设置指针 mmap进行内存操作
被消费ack 清缓存
消费者带着offset,去fetch 利用sendfile底层NIO(transferTo/transferFrom)
消费者能力不足:
增加消费者数量
主题增加分区,消费者并行处理能力
优化消费逻辑,多线程
max.poll.interval.msrang消费者更长时间处理消息
监控 报警 /及时调整
kafka内置指标
kafka stream:内置了自适应调节机制
数据清理策略:及时清理
启动kafka压缩
compression.type,none不压缩/lz4压缩 加大cpu开销
升级版本
命令
topic的./bin/kafka-topics.sh
生产者./bin/kafka-console-producer.sh
消费者./bin/kafka-console-consumer.sh
大数据之Kafka(心得)_集群级kafka数据消费的挑战与实践-CSDN博客
Kafka集群搭建及生产者消费者案例_kafka 消费者组 多机器-CSDN博客

![Weblogic XML反序列化漏洞 [CVE-2017-10271]](https://img-blog.csdnimg.cn/direct/78d132001adf45bc8599128c1fec9a49.png)