·前言
本篇文章主要介绍数据库约束以及数据库中有关表设计的一些基础知识,文章会尽量都用实例进行直观的讲解与展示每个知识点的意义,现在就开始今天的学习吧!!
一、数据库约束
1.约束概述
约束,就是在创建表的时候给这个表指定一些规则,在后续插入、修改与删除时都要保证数据能够遵守这些规则,引入这些规则是为了进行更强的数据检查及校验,这是因为数据是非常重要的,所以数据一定要确保正确,规则引入后,再进行插入、修改与删除等操作时,一旦数据不符合规则,就会报错,报错就是把问题提前告诉我们,以免酿成大错。
2.约束类型
| 类型 | 说明 |
|---|---|
| not null | 指示某列不能储存null值 |
| unique | 保证某列的每行必须有唯一值 |
| default | 规定没有给列赋值时的默认值 |
| primary key | not null与unique的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定记录。 |
| foreign key | 保证一个表中的数据匹配另一个表中的值的参照完整性。 |
(1)NOT NULL
创建表时,可以指定某列不为空: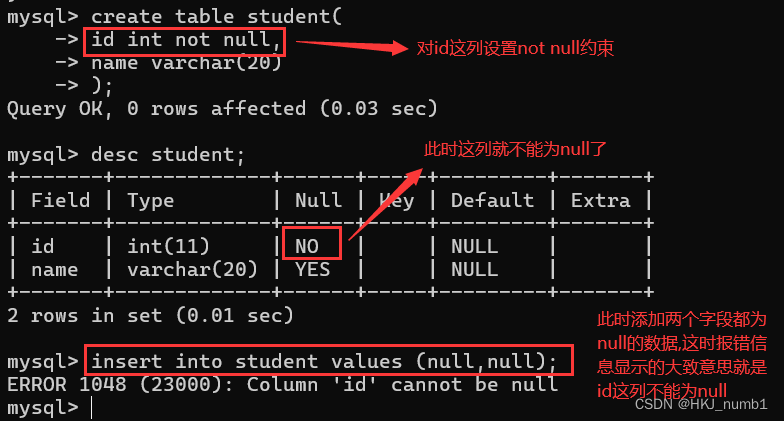
(2)UNIQUE
指定id列为唯一的、不重复的: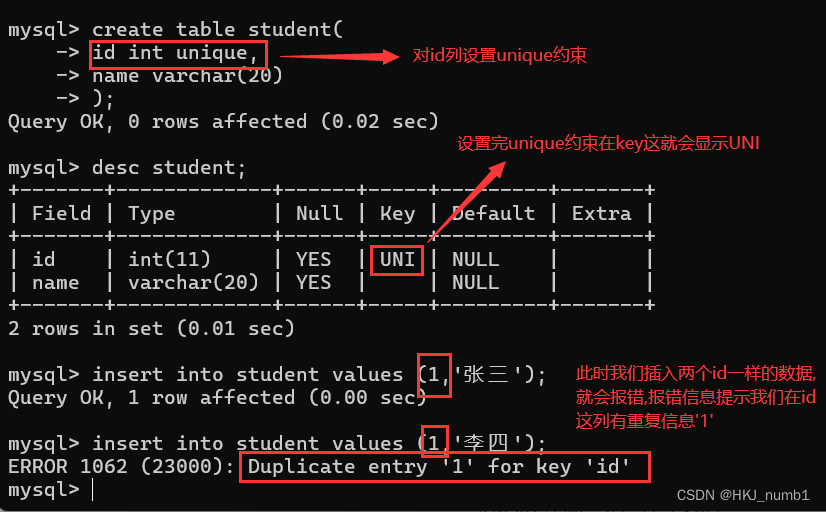
加上unique约束之后,后续进行插入、修改的时候都会先进行查询,看看当前这个值是否已经存在,从此可以看出,约束能够引入更多的检查操作,同时也会增加系统的开销。
(3)DEFAULT
指定插入数据时,当name列为空时默认值是“无名氏”,id列为空时默认值是0: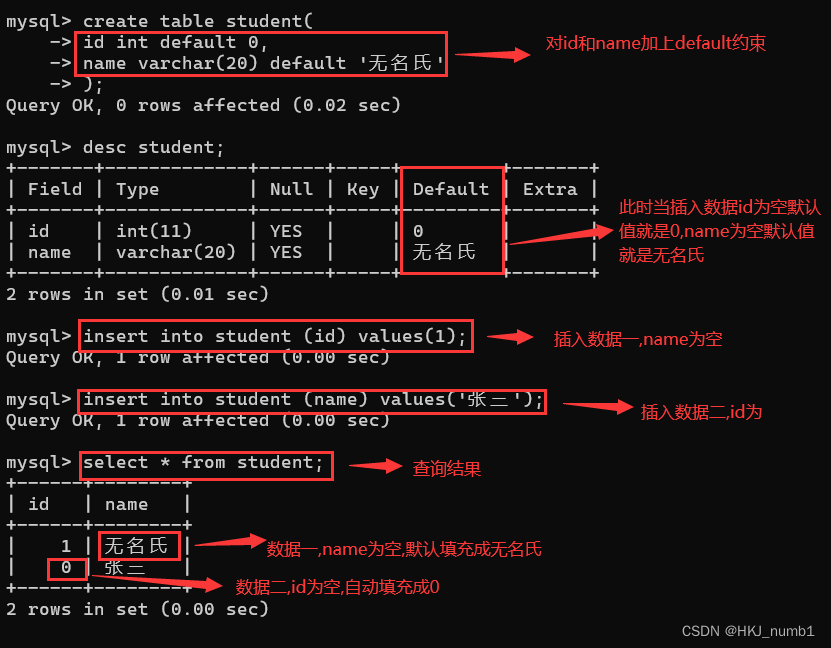
默认情况下,默认值就是NULL,进行指定列插入时,其他未被指定的列就会被设置成默认值,由于在很多时候,返回一个NULL值时是一个不好的体验,所以引入DEFAULT约束对NULL的元素默认值加以调整。
(4)PRIMARY KEY
指定id列为主键: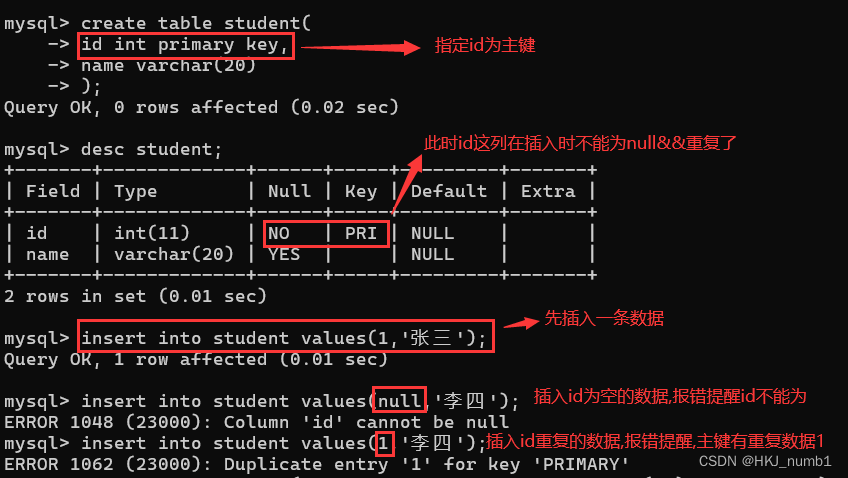
在设置主键的时候,我们往往会使用一个XXX id这样的列作为主键,同时,一个表中只能有一个主键,除了基础的使用之外,还有一种情况是联合主键,就是只有一个主键,这个主键是由多个列联合构成的,在这我就不过多介绍了。
主键不允许重复,那么具体要怎么做才能保证它不重复呢?在MySQL中,提供了一种机制:“自增主键”,具体用法如下: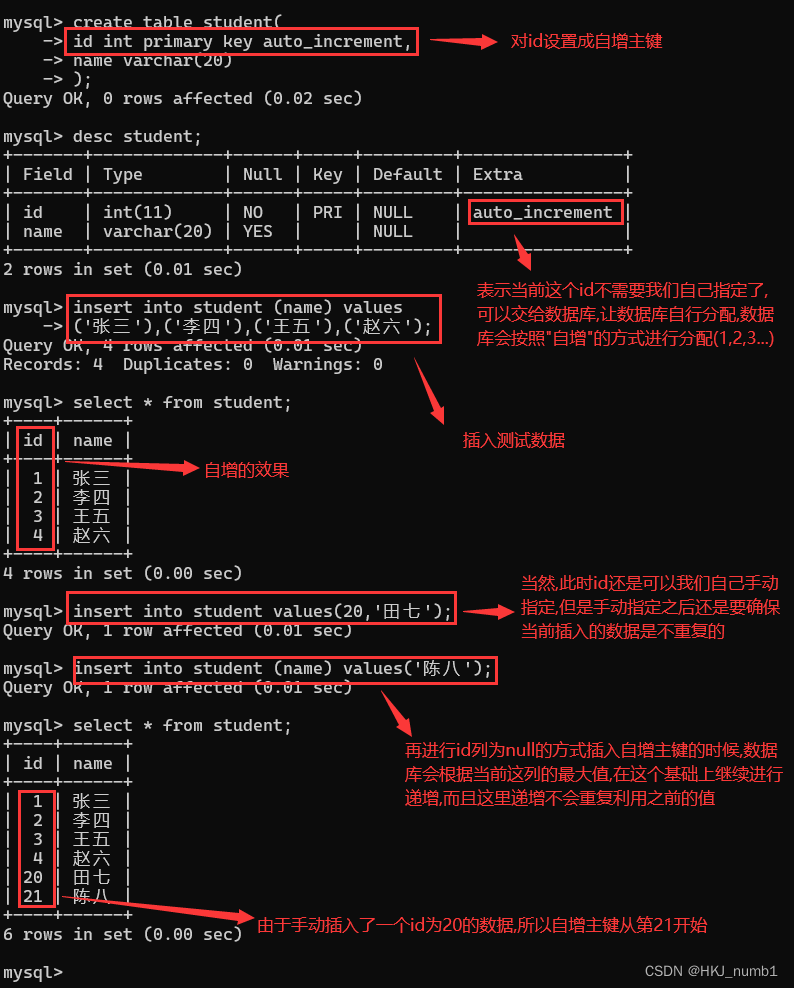
上述的自增主键,只能在单个数据库下生效,如果数据库是由多个MySQL服务器构成的“集群”,此时自增主键就无法生效了,这是因为表中数据特别多的时候,需要多台机器进行储存,此时多台机器的主键就是各自自增各自的了,这就可能导致不同机器中数据的id重复,但实际上我们引入“主键”是不希望会重复的,这时为了确保一个分布式系统中,能够存在唯一id,业界也会有一些分布式系统生成唯一id的算法,当然这类算法有很多,大同小异,基本思路就是将主键设置成字符串类型,然后大致按如下方法:
时间戳(ms,us) + 主机编号 + 随机因子
这里时间戳为了保证不同时刻生成的数据的id是不同的,主机编号是为了在同一时刻生成多个数据时,只要这几个数据是在不同主机上,仍然可以通过主机编号确保不重复,随机因子,预防的就是同一时刻,同一个主机上生成了多个数据,这时候就可以针对这多个数据id再通过随机因子进行区分,当然出现这种情况的数据不会太多,所以也不太会出现重复的情况。
(5)FOREIGN KEY
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
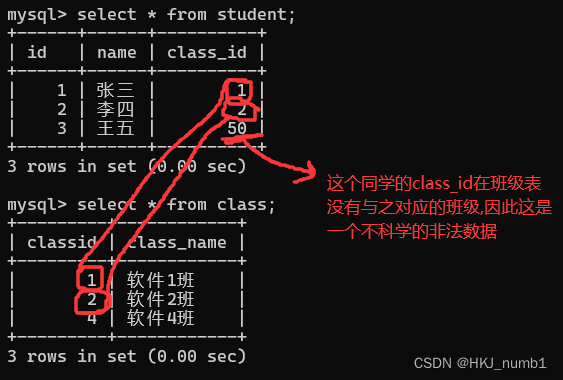
引入外键约束,就是为了解决上面这种问题,希望学生表中的class_id都要在班级表中存在,此时就可以使用外键约束进行校验,这就要求本表中的这个列的数据必须要在引用的外面的表的对应列中存在,详细介绍与具体使用如下所示: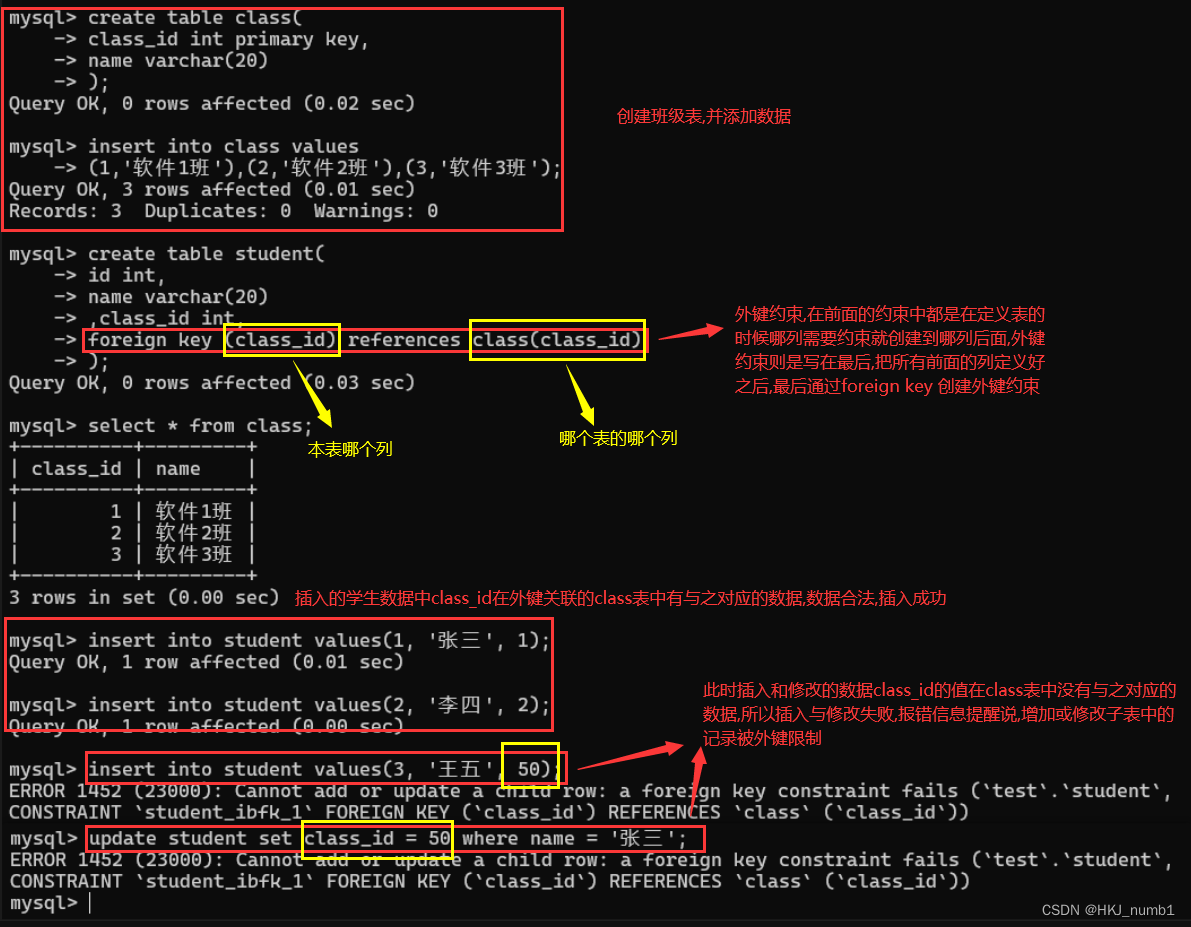
这个情况下,可以认为班级表约束了学生表,此时就把班级表这种约束别人的表,称为“父表”(parent table),把学生这种被别人约束的表,称为“子表”(child table),引入外键约束之后,每新增一条记录就会先在对应的父表中进行查询,看看是否存在,如果不存在就会报错。
其实,外键约束也是一个双向约束,也就是父亲在约束孩子时,孩子也同时约束着父亲,这也就是所谓的言传身教,所以这里子表对父表也有约束的,要想删除父表中某条记录,就必须先删除子表中对应的数据,保证子表中没有数据引用父表这条记录,才能真正执行删除,下面进行演示,详细介绍与具体效果如下: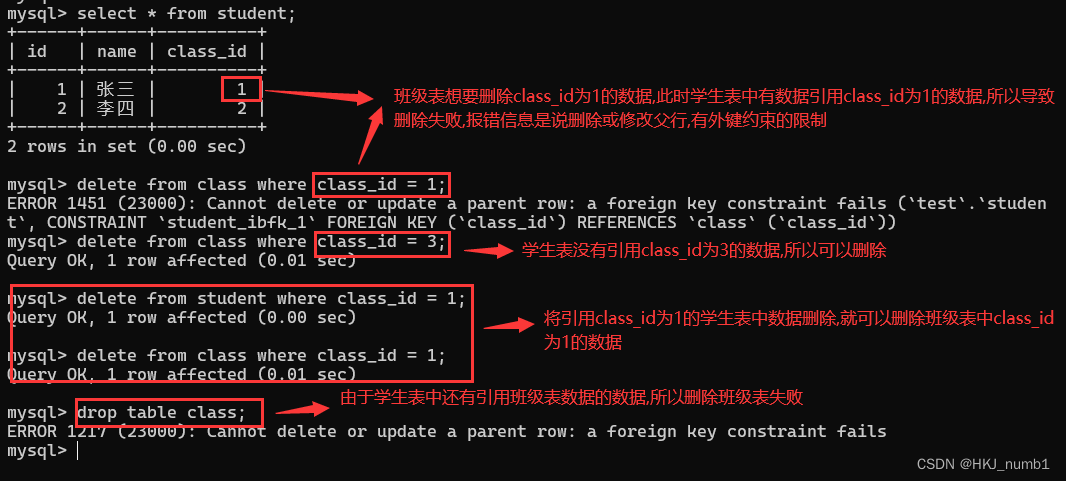
在尝试删除或修改父表中的记录,也会先查询子表,看看当前这个结果是否在子表中被引用,如果被引用,就会删除失败。
使用外键约束的时候,操作子表要查询父表,操作父表也要查询子表,这里就会伴随很多查询操作,如果表中数据非常多,查询操作就会非常低效,为了让上述查询更加高效,往往就需要要求子表中的列和父表中被引用的列,都要带有“索引”,索引可以理解成目录,关于索引的知识,在后续文章会介绍到,下面通过一个简单示例进一步介绍与演示: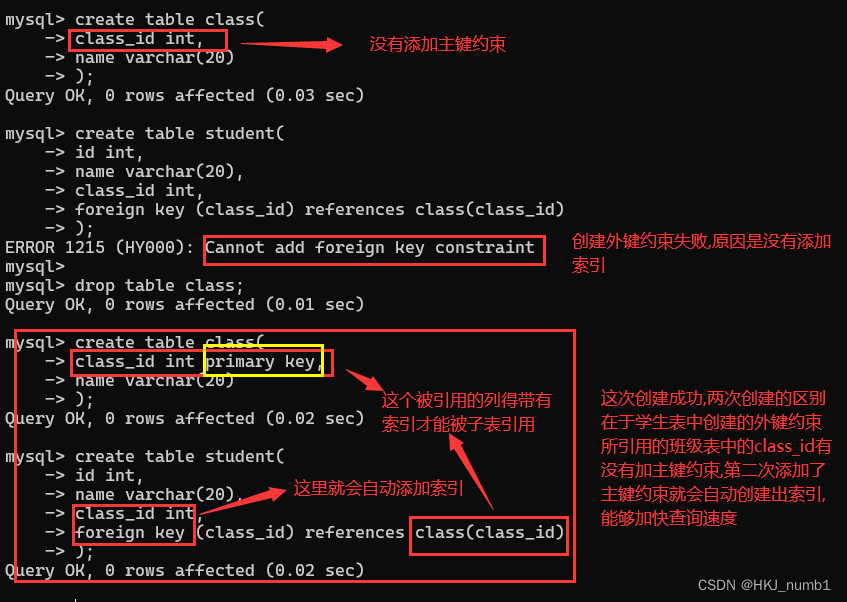
二、表的设计
谈到“数据库设计”,就是根据需求,来把需要的表创建出来(有几个表,每个表中有什么……),设计的一般过程如下:
- 先根据需求,找到实体(一些关键性质的对象)
- 梳理清楚实体之间的关系
在梳理清楚需求后提出关键的名字,一般来说,每个实体都要安排一个表,多个实体之间,需要理清楚关系,不同关系下,有不同的设计表的方式,常见关系可分为四种,有一种关系是没有关系,这种就不进行介绍了,所以下面我会进行三种关系的介绍。
1.一对一
这里我们以学校的教务系统为例,在教务系统中需要表示一个概念,学生(实体),还有一个概念是账号(实体),针对这两个概念可以分别创建两张表:
- 学生表:学号,姓名,班级,联系方式,入学时间……
- 账号表:账户名,密码,登录地点……
这里的一对一关系可以这么理解:
一个学生只能有一个账号(学生不能注册小号)
一个账号只能给一个学生使用(一个账号不能多个学生一起使用)
在一对一的关系下,表结构有以下几种设计方案:
- 方案一:创建一个大表,把所以信息放在一起,当然,这种方案只适合于当两张表都很简单(列很少)可以考虑合并在一起,如果这两张表都比较复杂(列很多)那就不建议合并了。
- 方案二:分成两张表,使用id引用过来,建立联系,例:
student(student_id,student_name,account_id);
account(account_id,user_name,password);
2.一对多
以教务系统为例,有一个实体学生,还有一个实体班级,同样针对这两个实体可以创建两张表,在这里,一对多的关系可以这么理解:
一个班级可以包含多个学生
一个学生只能属于一个班级
针对一对多,设计表也存在两种方案:
- 方案一:如下图,原理就是在班级表中使用一个数组类型字段把班级中学生的学号存在数组中,这样就知道班级中有哪些学生了,这里的问题就在于MySQL中并不支持“数组”这样的类型,所以这个方案这MySQL中行不通。

- 方案二:如下图,原理就是在学生表中添加一个字段存储班级号,这样一个学生就只对应一个班级,而班级表也不需要存储学生的信息了。

3.多对多
以教务系统为例,学生是一个实体,课程也是一个实体,同样针对这两个实体可以创建两张表,在这里,多对多的关系可以这么理解:
一个学生可以选择多门课程
一门课程可以被多个学生选择
这里创建多对多关系时需要引入一个关联表,用于把两张表联系到一起,具体如下:
通过关联表就可以知道某个同学都选择了哪些课程。
在设计表时,我们就可以按上面的示例,确定每个实体的关系,然后往里面套,能套上哪个,就用哪种方式创建表。
·尾声
文章到这里就接要结束了,本篇文章分为两个部分,分别是对约束的介绍,还有对表设计的介绍,对于约束这里我只是简单的介绍了约束的一些基础用法,但实际添加约束还有其他方式,约束的使用也还有很多方式,如果有机会,我会在后续文章继续进行补充,对于表的设计,这里谈到设计,往往是与“经验”有一定关联的,我在这只是对表设计的基础进行了简单的介绍,实际上,关于设计这是一个非常复杂的问题,这需要考虑的东西有很多,原谅博主能力有限只能介绍这么多,如果这篇文章对你有所帮助,希望能多多支持咯,您的支持就是我最大的动力~~~~



![[书生·浦语大模型实战营]——第二节:课后作业](https://img-blog.csdnimg.cn/direct/174aa99b82284f6abafe6b229e8cec99.png)


![虚拟化技术[2]之存储虚拟化](https://img-blog.csdnimg.cn/direct/4e35488024ff49558ada985ff9feb0ad.png)