项目信息
- 项目地址:https://github.com/hpcaitech/Open-Sora
- 技术报告:
- Open-Sora 1:https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_01.md
- Open-Sora 1.1:https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
- 项目介绍:
- Open-Sora 是潞晨科技 (ColossalAI) 团队实现的一个致力于高效生产高质量视频的开源项目,旨在让所有人都能够访问先进的视频生成技术。该项目遵循开源原则,不仅使视频生成技术的访问民主化,还提供了一个简化和用户友好的平台,以简化视频制作的复杂性。Open-Sora 的目标是在内容创作领域激发创新、创造力和包容性。
- 目前发布了两个版本
- Open-Sora 1.0:生成 512x512 的 2s 视频
- Open-Sora 1.1:生成 2s~15s, 144p to 720p, any aspect ratio,支持 text-to-video, image-to-video, video-to-video, infinite time generation 等模式
Open-Sora 1.1 效果

Open-Sora 1.1 技术报告
在 Open-Sora 1.1 版本中,训练了一个700M的模型,使用了 10M 的数据(相较于Open-Sora 1.0使用的40万数据)以及更好的 STDiT 架构。实现了 sora 报告中提到的以下功能:
- 可变的时长、分辨率、纵横比(采样灵活性、改进的框架和构图)
- 用图像和视频提示(动画图像、扩展生成的视频、视频编辑、连接视频)
- 图像生成能力
为实现这一目标,在预训练阶段使用了多任务学习。对于扩散模型,使用不同采样时间步的训练已经是一种多任务学习。进一步将这一理念扩展到多分辨率、纵横比、帧长、帧率以及不同的图像和视频条件生成的掩码策略。模型在 0 到 15 秒,144p 到 720p,各种纵横比的视频上进行训练。尽管由于训练 FLOP 的限制,时间一致性的质量不是很高,但仍能看到模型的潜力。
模型架构修改
对原始 ST-DiT 进行了以下修改,以提高训练稳定性和性能(ST-DiT-2):
- 用于时间注意力的 Rope 嵌入:借鉴 LLM 的最佳实践,将正弦位置编码更改为 Rope 嵌入,用于时间注意力,因为它也是一种序列预测任务。
- AdaIN 和 Layernorm 用于时间注意力:用AdaIN和Layernorm包装时间注意力,就像空间注意力一样,以稳定训练。
- 带有 RMSNorm 的 QK 标准化:借鉴 SD3,将 QK 标准化应用于所有注意力,以提高半精度训练的稳定性。
- 动态输入大小支持和视频信息条件:为了支持多分辨率、纵横比和帧率训练,使 ST-DiT-2 接受任何输入大小,并自动调整位置嵌入。参考 PixArt-alpha 的理念,根据视频的高度、宽度、纵横比、帧长和帧率进行条件设置。
- 将 T5 的 tokens 从 120 扩展到 200:通常 caption 不超过 200 个 tokens,发现模型可以很好地处理较长的文本。
支持多时间/分辨率/纵横比/帧率训练
如 sora 报告中所述,使用原始视频的分辨率、纵横比和长度进行训练可以增加采样灵活性并改进框架和构图。找到三种实现这一目标的方法:
- NaViT:通过掩码支持同一批次内的动态大小,效率损失较小。然而,系统实现有点复杂,可能无法从优化的内核(如 flash-attention)中受益。
- 填充(FiT,Open-Sora-Plan):通过填充支持同一批次内的动态大小。然而,将不同分辨率填充到同一大小效率不高。
- 桶(SDXL,PixArt):通过分桶支持不同批次内的动态大小,但同一批次内的大小必须相同,并且只能应用固定数量的大小。在同一批次中使用相同大小,不需要实现复杂的掩码或填充。
为了实现的简便性,选择了桶方法。预定义了一些固定的分辨率,并将不同的样本分配到不同的桶中。分桶的担忧如下,但在我们的案例中,这些担忧并不大。
- 桶大小的限制
桶大小限制为固定数量:首先,在实际应用中,只有少数纵横比(如9:16,3:4)和分辨率(如 240p,1080p)常用。其次,发现训练好的模型可以很好地泛化到未见过的分辨率。 - 在每个批次中的大小相同,打破了独立同分布假设
由于使用多台 GPU,不同 GPU 上的本地批次大小不同。没有观察到由于此问题导致的显著性能下降。 - 样本可能不足以填充每个桶,分布可能有偏差
首先,数据集足够大,当本地批次大小不太大时,可以填充每个桶。其次,应该分析数据在不同大小上的分布,并据此定义桶大小。第三,不平衡的分布没有显著影响训练过程。 - 不同分辨率和帧长度可能具有不同的处理速度
不同于 PixArt,仅处理相似分辨率(类似 token 数量)的纵横比,需要考虑不同分辨率和帧长度的处理速度。可以使用 bucket_config 定义每个桶的批次大小,以确保处理速度相似。

如图所示,桶是(分辨率、帧数、纵横比)的三元组。为不同的分辨率提供了预定义的纵横比,涵盖了大多数常见的视频纵横比。在每个训练周期之前,打乱数据集并将样本分配到不同的桶中,如图所示。将一个样本放入比视频小的最大分辨率和帧长的桶中。
考虑到计算资源有限,为每个(分辨率、帧数)引入了两个属性:keep_prob 和 batch_size,以减少计算成本并实现多阶段训练。具体来说,高分辨率视频将以 1-keep_prob 的概率降采样到较低分辨率,每个桶的批量大小为 batch_size。通过这种方式,可以控制不同桶中的样本数量,并通过搜索合适的批量大小来平衡 GPU 负载。
Masked DiT 作为图像/视频生成模型
Transformer 可以轻松扩展以支持图像到图像和视频到视频的任务。提出了一种掩码策略来支持图像和视频的条件生成。掩码策略如下图所示。
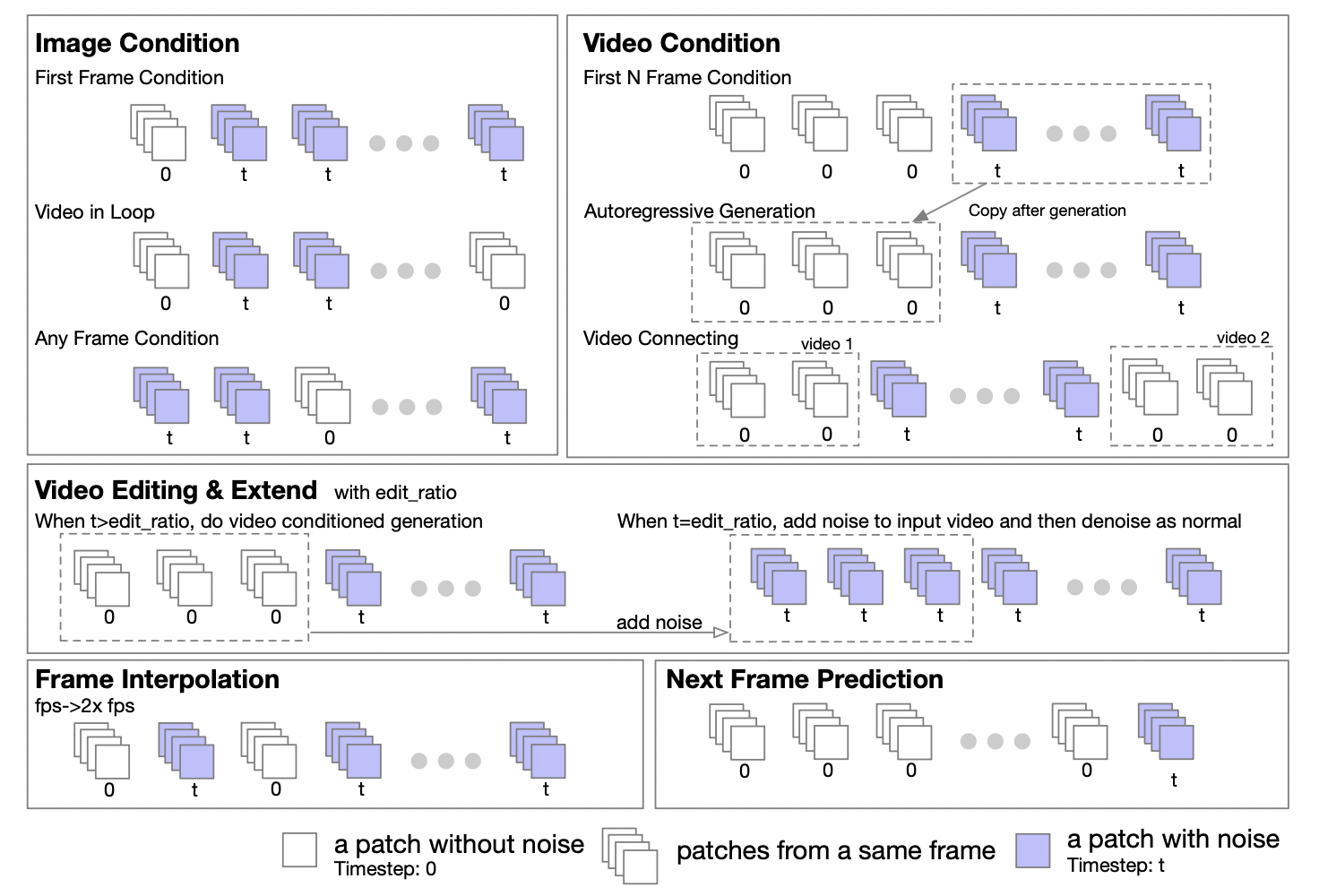
通常情况下,对于图像/视频生成条件,去除作为条件的帧的掩码。在 ST-DiT 前向过程中,未掩码的帧将具有时间步 0,而其他帧保持不变(t)。发现直接将该策略应用于已训练的模型会产生较差的结果,因为扩散模型在训练过程中没有学习在一个样本中处理不同的时间步。
受 UL2 启发,在训练过程中引入随机掩码策略。具体来说,在训练过程中随机去除帧的掩码,包括去除第一帧、前 k 帧、最后一帧、最后 k 帧、前后 k 帧、随机帧等。基于 Open-Sora 1.0,使用 50% 的概率应用掩码,发现模型在 10k 步内可以学习处理图像条件(30%的概率效果较差),同时文本到视频性能略有下降。因此,对于 Open-Sora 1.1,从头开始预训练模型并应用掩码策略。
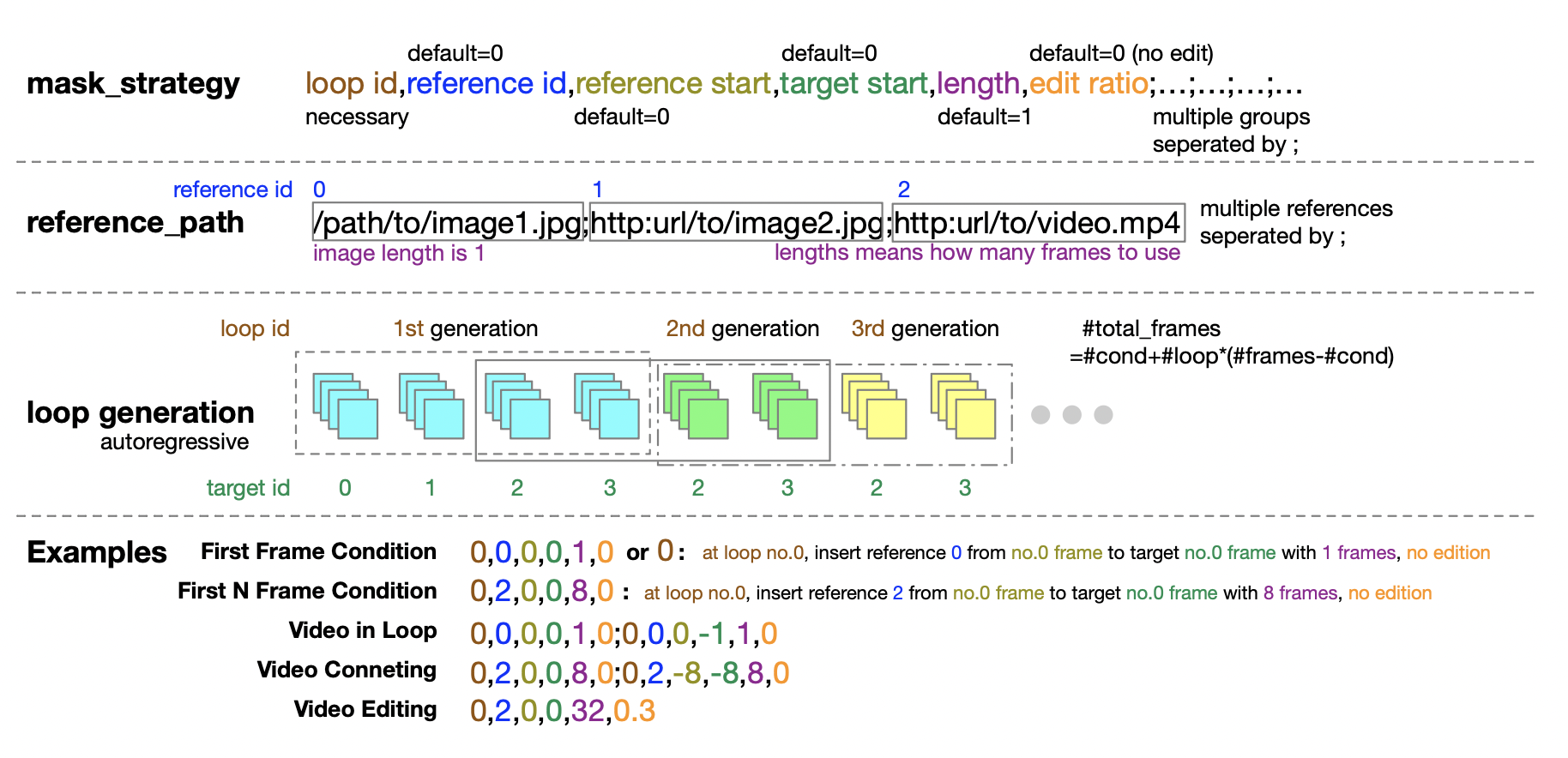
下面提供了一个推理中使用的掩码策略配置示例。一个五元组提供了定义掩码策略的极大灵活性。通过对生成的帧进行条件化,可以自回归地生成无限帧(尽管误差会传播)。
数据收集与处理管道
在 Open-Sora 1.0 中发现,数据数量和质量对于训练一个好的模型至关重要,因此致力于扩大数据集。首先,参考 SVD 创建了一个自动化管道,包括场景切割、字幕生成、各种评分和过滤,以及数据集管理脚本和规范。
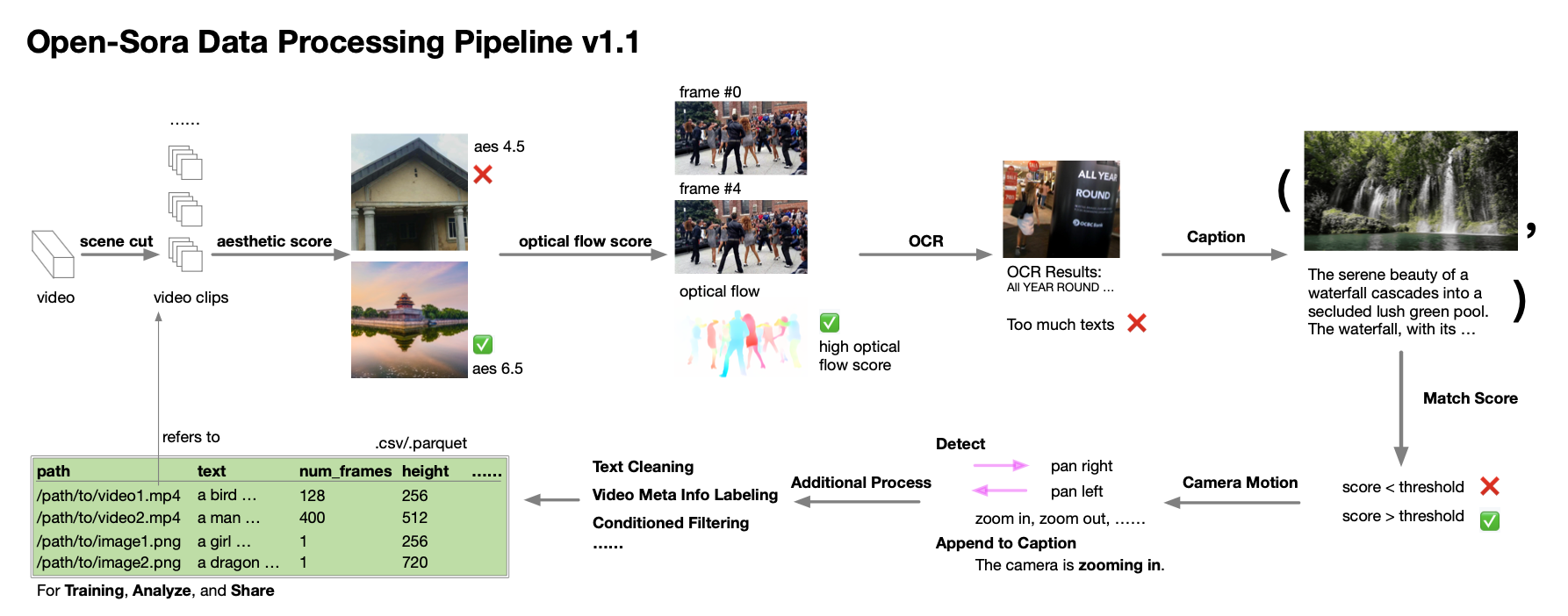
计划使用 panda-70M 和其他数据来训练模型,约为 3000万+ 数据。然而,发现磁盘 IO 在同时进行训练和数据处理时是一个瓶颈。因此,只能准备1000万数据集,并未经过我们构建的所有处理管道。最终使用了 970 万视频 + 260 万图像进行预训练,560k 视频+160 万图像进行微调。预训练数据集统计如下。
-
图像文本 token 长度统计(使用 T5 分词器)
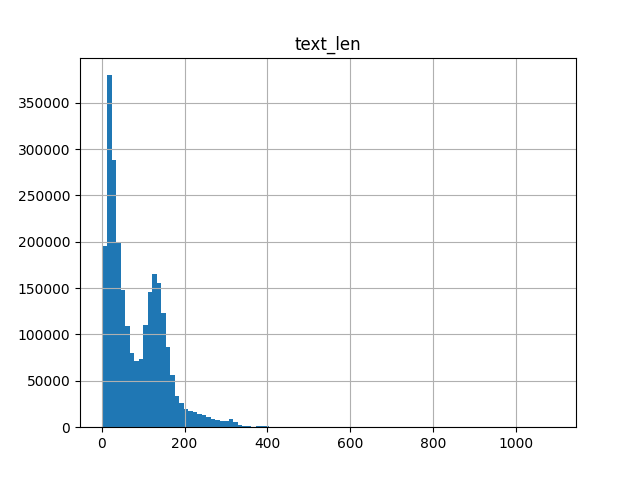
-
视频文本 token 长度统计(使用 T5 分词器)。直接使用 panda 的短字幕进行训练,并为其他数据集生成字幕。生成的字幕通常少于 200 个 token。
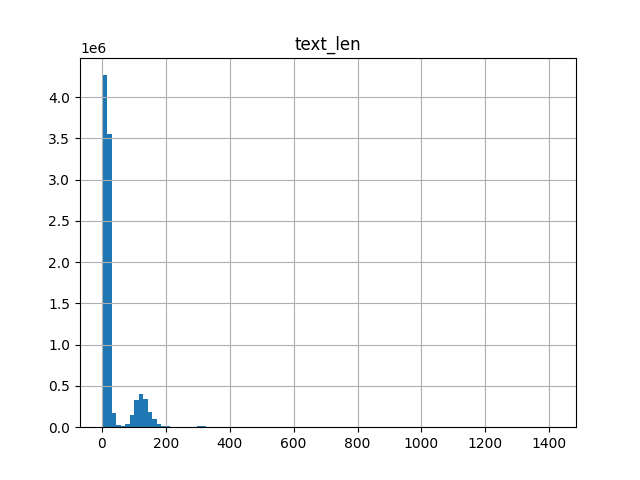
-
视频时长:

训练细节
由于计算资源有限,需要仔细监控训练过程,如果推测模型学习效果不佳,则更改训练策略,因为没有计算消融研究的资源。因此,Open-Sora 1.1 的训练包括多次更改,因此未应用 ema。
- 首先,从 Pixart-alpha-1024 检查点开始,使用不同分辨率的图像进行 6000 步微调。发现模型很容易适应生成不同分辨率的图像。使用 SpeeDiT(iddpm-speed) 加速扩散训练。
- [阶段1] 然后,在 64 台 H800 GPU 上预训练模型 24000 步,耗时 4 天。尽管模型看到的样本数量相同,但发现模型相比于较小的批量大小学习得更慢。推测在早期阶段,步数对训练更重要。大多数视频分辨率为240p,配置与 stage2.py 相似。视频效果良好,但模型对时间知识了解不多。使用 10% 的掩码率。
- [阶段1] 为增加步数,切换到较小的批量大小,不使用梯度检查点 (gradient-checkpointing)。此时还增加了 fps 条件。训练了 40000 步,耗时 2 天。大多数视频分辨率为144p,配置文件为 stage1.py。使用较低分辨率,因为在 Open-Sora 1.0 中发现模型可以在较低分辨率下学习时间知识。
- [阶段1] 发现模型无法很好地学习长视频,生成结果存在噪声,推测是 Open-Sora 1.0 训练中发现的半精度问题。因此,采用 QK 标准化以稳定训练。类似于 SD3,发现模型很快适应了 QK 标准化。还将 iddpm-speed 切换到 iddpm,并将掩码率增加到 25%,因为发现图像条件学习效果不好。训练了 17000 步,耗时 14 小时。大多数视频分辨率为 144p,配置文件为 stage1.py。第一阶段训练持续约一周,总步数为 81000 步。
- [阶段2] 切换到更高分辨率,大多数视频分辨率为 240p 和 480p。在所有预训练数据上训练了 22000 步,耗时一天。
- [阶段3] 切换到更高分辨率,大多数视频分辨率为480p和720p(stage3.py)。在高质量数据上训练了 4000 步,耗时一天。发现加载上一阶段的优化器状态可以帮助模型更快学习。
总结,Open-Sora 1.1 的训练在 64 台 H800 GPU 上大约需要 9 天。
限制与未来工作
在接近 Sora 的复制时,发现当前模型存在许多限制,这些限制指向未来的工作。
- 生成失败:发现许多情况下(尤其是 token 数量大或内容复杂时),模型无法生成场景。可能是时间注意力崩溃,已在代码中发现潜在错误,正在努力修复。此外,将在下一版本中增加模型大小和训练数据以提高生成质量。
- 生成的内容有噪声和不连贯:发现生成的模型有时有噪声且不连贯,尤其是长视频。认为问题在于未使用时间 VAE。Pixart-Sigma 发现适应新 VAE 很简单,计划在下一版本中为模型开发时间 VAE。
- 缺乏时间一致性:发现模型无法生成时间一致性高的视频。认为问题在于训练 FLOP 不足。计划收集更多数据并继续训练模型以提高时间一致性。
- 人类视频生成质量差:发现模型无法生成高质量的人类视频。认为问题在于缺乏人类数据。计划收集更多人类数据并继续训练模型以提高人类视频生成质量。
- 美学评分低:发现模型的美学评分不高。问题在于缺乏美学评分过滤,因 IO 瓶颈未进行。计划通过美学评分过滤数据并微调模型以提高美学评分。
- 长视频生成质量较差:发现使用相同提示,长视频质量较差。这意味着图像质量未能同样适应不同长度的序列。
总结
- 在 open-sora 1.1 上的更新还是挺多的,在多分辨率、变长方面的支持已经是能实现 sora 的基本功能了,对于开源领域的视频生成是个很大的进展
- 目前训练量并不大,64 台 H800 GPU 上大约需要 9 天。下个版本模型感觉有很大可能能修复一些 bug 后 scale 到更大的集群规模,可以期待效果会有显著提升。优质数据后续可能对开源领域来说瓶颈很大。
- 依然没有上时序压缩的 VAE,时序压缩有限。不过看起来下个版本应该要用了。
- 分 stage 训练时加载上一阶段的优化器状态有助于训练应该是基操
- 长视频效果不好看起来可能是和 frame 分布有关,frame 多的视频看数据分布本来就占比较少
![[书生·浦语大模型实战营]——第二节:课后作业](https://img-blog.csdnimg.cn/direct/174aa99b82284f6abafe6b229e8cec99.png)


![虚拟化技术[2]之存储虚拟化](https://img-blog.csdnimg.cn/direct/4e35488024ff49558ada985ff9feb0ad.png)